
 Technologie-Peripheriegeräte
KI
Das 6-seitige Papier von Microsoft explodiert: Ternäres LLM, so lecker!
Technologie-Peripheriegeräte
KI
Das 6-seitige Papier von Microsoft explodiert: Ternäres LLM, so lecker!
Das 6-seitige Papier von Microsoft explodiert: Ternäres LLM, so lecker!

Dies ist die Schlussfolgerung, die Microsoft und die Universität der Chinesischen Akademie der Wissenschaften in der neuesten Studie vorbringen:
Alle LLMs werden 1,58 Bit sein.

Konkret heißt die in dieser Studie vorgeschlagene Methode BitNet b1.58, von der man sagen kann, dass sie von den Parametern der „Wurzel“ des großen Sprachmodells ausgeht.
Der traditionelle Speicher in Form von 16-Bit-Gleitkommazahlen (wie FP16 oder BF16) wurde in ternär geändert, was {-1, 0, 1} ist.
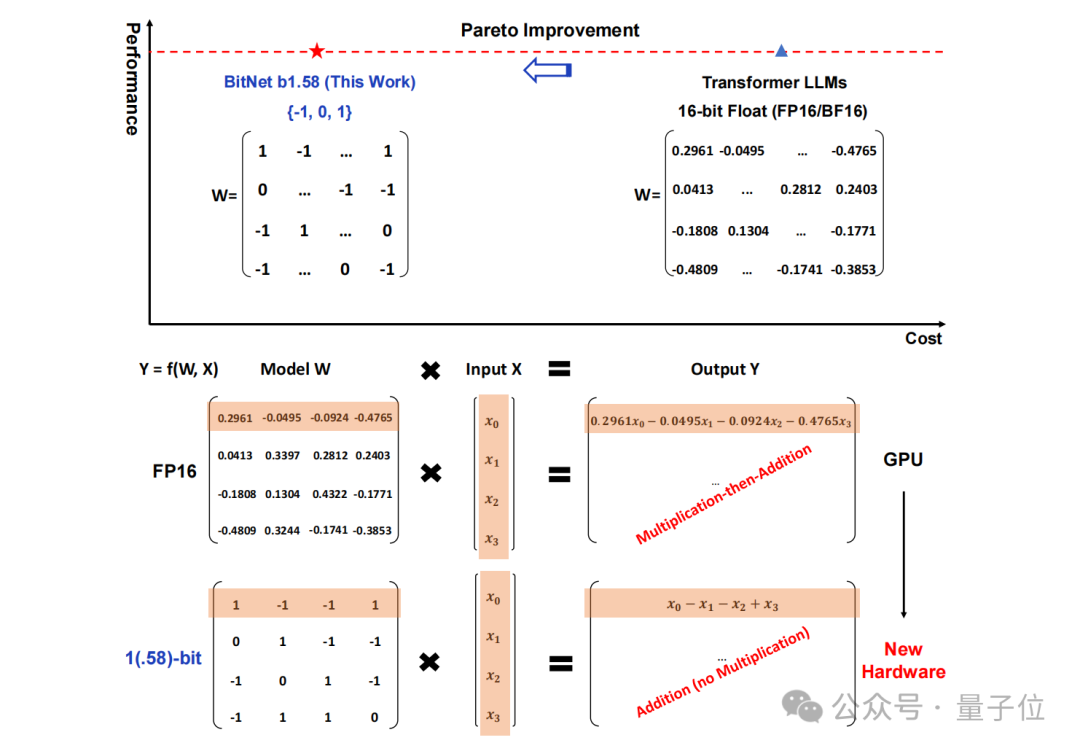
Es ist zu beachten, dass „1,58 Bit“ nicht bedeutet, dass jeder Parameter 1,58 Byte Speicherplatz belegt, sondern dass jeder Parameter mit 1,58 Bit an Informationen kodiert werden kann.
Nach einer solchen Konvertierung umfasst die Berechnung in der Matrix nur die Addition ganzer Zahlen, sodass große Modelle den erforderlichen Speicherplatz und die Rechenressourcen erheblich reduzieren und gleichzeitig eine gewisse Genauigkeit beibehalten können.
Zum Beispiel wird BitNet b1.58 mit Llama verglichen, wenn die Modellgröße 3B beträgt. Während die Geschwindigkeit um das 2,71-fache erhöht wird, beträgt die GPU-Speichernutzung fast nur ein Viertel des Originals.
Und wenn das Modell größer ist (z. B. 70B) , sind die Geschwindigkeitsverbesserung und die Speichereinsparung deutlicher!
Diese subversive Idee hat die Internetnutzer wirklich beeindruckt, und das Papier erhielt auch große Aufmerksamkeit. Der alte Witz des Papiers:
 1 Bit ist alles, was SIE brauchen.
1 Bit ist alles, was SIE brauchen.
Wie wird also BitNet b1.58 implementiert? Lesen wir weiter.
Konvertieren Sie alle Parameter in ternäre 
Insgesamt basiert BitNet b1.58 immer noch auf der BitNet-Architektur
(einem Transformer) und ersetzt nn.Linear durch BitLinear. 
Gewichtsquantisierung(Gewichtsquantisierung)
.Die Gewichte des BitNet b1.58-Modells werden in ternäre Werte {-1, 0, 1} quantisiert, was der Verwendung von 1,58 Bit zur Darstellung jedes Gewichts im Binärsystem entspricht. Diese Quantifizierungsmethode reduziert den Speicherbedarf des Modells und vereinfacht den Berechnungsprozess.
Zweitens verwendeten die Forscher im Hinblick auf das
Quantisierungsfunktionsdesign, um die Gewichtung auf -1, 0 oder +1 zu begrenzen, eine Quantisierungsfunktion namens Absmean. 
Diese Funktion skaliert zunächst entsprechend dem durchschnittlichen Absolutwert der Gewichtsmatrix und rundet dann jeden Wert auf die nächste ganze Zahl (-1, 0, +1).
Der nächste Schritt ist 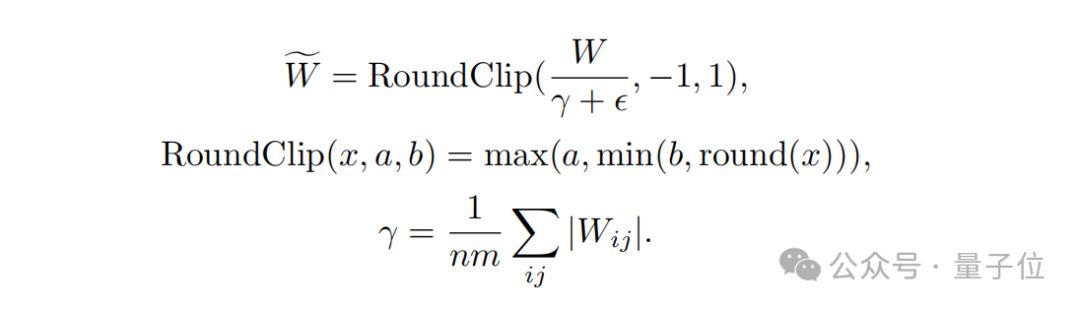 Aktivierungsquantisierung
Aktivierungsquantisierung
(Aktivierungsquantisierung)
.Die Quantisierung der Aktivierungswerte ist dieselbe wie bei der Implementierung in BitNet, die Aktivierungswerte werden jedoch nicht auf den Bereich [0, Qb] vor der nichtlinearen Funktion skaliert. Stattdessen werden die Aktivierungen auf den Bereich [−Qb, Qb] skaliert, um eine Nullpunktquantisierung zu vermeiden.
Es ist erwähnenswert, dass das Forschungsteam Komponenten des LLaMA-Modells wie RMSNorm, SwiGLU usw. übernommen hat, um BitNet b1.58 mit der Open-Source-Community kompatibel zu machen, sodass es problemlos in Mainstream-Open integriert werden kann Quellsoftware.
Abschließend verglich das Team im Rahmen eines experimentellen Leistungsvergleichs BitNet b1.58 und FP16 LLaMA LLM auf Modellen unterschiedlicher Größe.
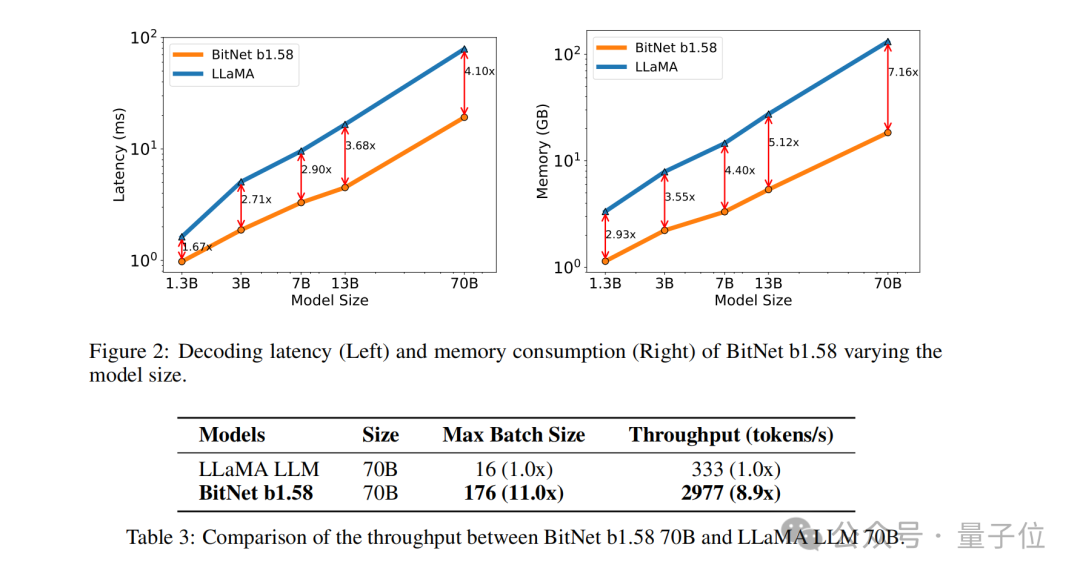
Die Ergebnisse zeigen, dass BitNet b1.58 bei der Modellgröße 3B beginnt, mit dem vollpräzisen LLaMA LLM mithalten zu können, und gleichzeitig erhebliche Verbesserungen bei Latenz, Speichernutzung und Durchsatz erzielt.
Und wenn die Modellgröße größer wird, wird diese Leistungsverbesserung noch bedeutender.
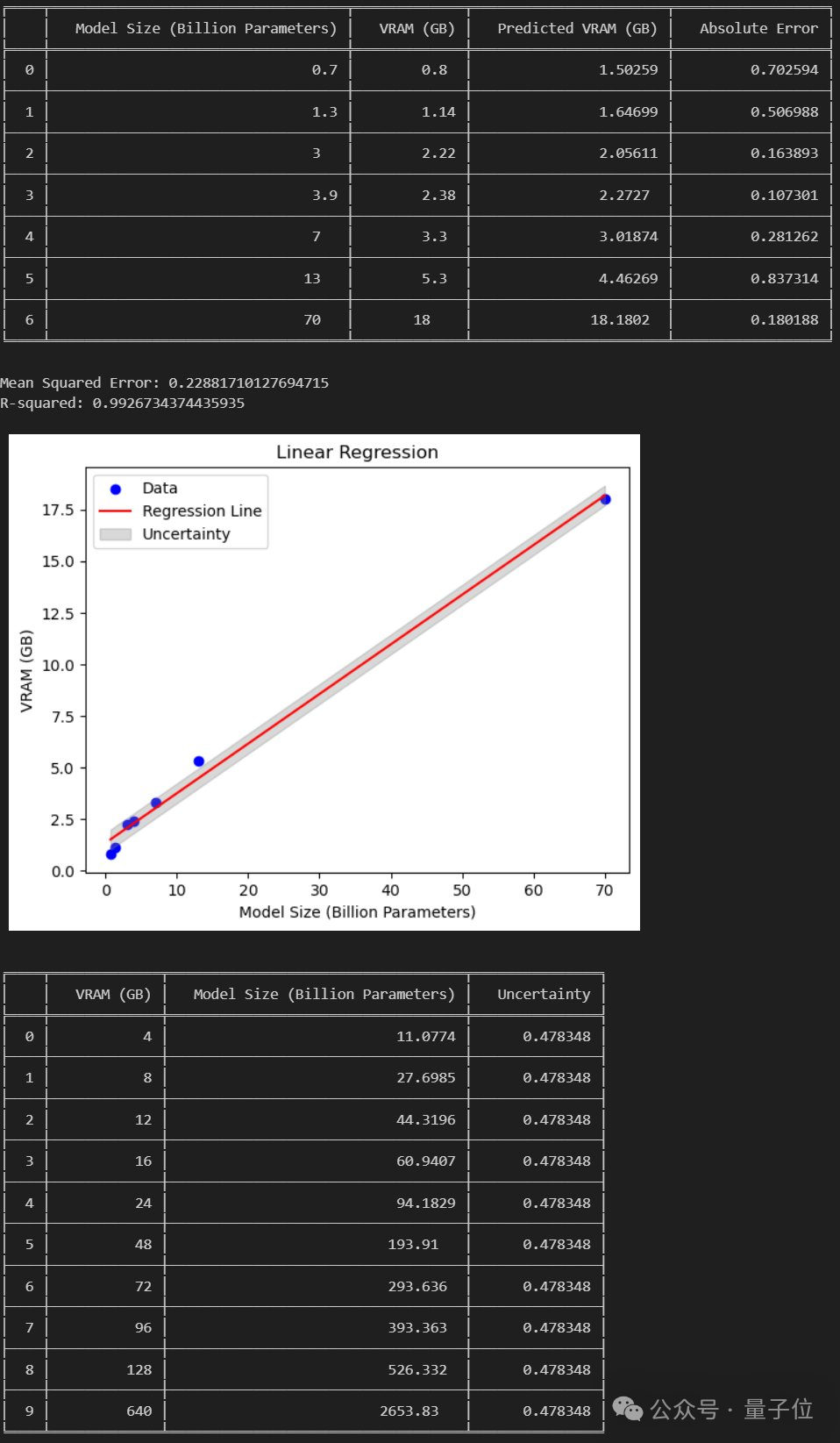
Netizen: Es ist möglich, 120 Milliarden große Modelle auf GPUs der Verbraucherklasse auszuführen.
Wie oben erwähnt, hat die einzigartige Methode dieser Studie im Internet für viele hitzige Diskussionen gesorgt.
DeepLearning.scala-Autor Yang Bo sagte:
Im Vergleich zum ursprünglichen BitNet besteht das größte Merkmal von BitNet b1.58 darin, dass es 0 Parameter zulässt. Ich denke, dass wir durch eine leichte Änderung der Quantisierungsfunktion möglicherweise den Anteil der 0-Parameter steuern können. Wenn der Anteil von 0 Parametern groß ist, können die Gewichte in einem spärlichen Format gespeichert werden, sodass der durchschnittliche von jedem Parameter belegte Videospeicher sogar weniger als 1 Bit beträgt. Dies entspricht einem MoE auf Gewichtsebene. Ich denke, es ist eleganter als normales MoE.
Gleichzeitig wies er auch auf die Mängel von BitNet hin:
Der größte Nachteil von BitNet besteht darin, dass es zwar den Speicheraufwand während der Inferenz reduzieren kann, der Zustand und der Gradient des Optimierers jedoch immer noch Gleitkommazahlen verwenden und das Training immer noch sehr schwierig ist speicherintensiv. Ich denke, wenn BitNet mit einer Technologie kombiniert werden kann, die beim Training Videospeicher spart, dann kann es im Vergleich zu herkömmlichen Netzwerken mit halber Präzision mehr Parameter bei gleicher Rechenleistung und gleichem Videospeicher unterstützen, was große Vorteile haben wird.
Die aktuelle Möglichkeit, den Grafikspeicher-Overhead des Optimierungsstatus zu sparen, ist das Auslagern. Eine Möglichkeit, den Speicherverbrauch von Farbverläufen zu sparen, könnte ReLoRA sein. Allerdings wurde im ReLoRA-Papierexperiment nur ein Modell mit einer Milliarde Parametern verwendet, und es gibt keinen Beweis dafür, dass es auf Modelle mit Dutzenden oder Hunderten Milliarden Parametern verallgemeinert werden kann.

△Bildquelle: Zhihu, zitiert mit Genehmigung
Einige Internetnutzer haben jedoch Folgendes analysiert:
Wenn das Papier etabliert ist, können wir ein 120-B-Großmodell auf einer 24-GB-GPU der Verbraucherklasse ausführen.
Was haltet ihr von dieser neuen Methode?
Das obige ist der detaillierte Inhalt vonDas 6-seitige Papier von Microsoft explodiert: Ternäres LLM, so lecker!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Gibt es ein kostenloses XML -zu -PDF -Tool für Mobiltelefone?
Apr 02, 2025 pm 09:12 PM
Gibt es ein kostenloses XML -zu -PDF -Tool für Mobiltelefone?
Apr 02, 2025 pm 09:12 PM
Es gibt kein einfaches und direktes kostenloses XML -zu -PDF -Tool auf Mobilgeräten. Der erforderliche Datenvisualisierungsprozess beinhaltet komplexes Datenverständnis und Rendering, und die meisten sogenannten "freien" Tools auf dem Markt haben schlechte Erfahrung. Es wird empfohlen, Computer-Seiten-Tools zu verwenden oder Cloud-Dienste zu verwenden oder Apps selbst zu entwickeln, um zuverlässigere Conversion-Effekte zu erhalten.
 Warum werden alle Werte das letzte Element, wenn sie für den Bereich in der GO -Sprache verwendet werden, um Scheiben zu durchqueren und Karten zu speichern?
Apr 02, 2025 pm 04:09 PM
Warum werden alle Werte das letzte Element, wenn sie für den Bereich in der GO -Sprache verwendet werden, um Scheiben zu durchqueren und Karten zu speichern?
Apr 02, 2025 pm 04:09 PM
Warum bewirkt die Kartendiseration in Go alle Werte zum letzten Element? In Go -Sprache begegnen Sie, wenn Sie einige Interviewfragen konfrontiert sind, häufig Karten ...
 So verschönern Sie das XML -Format
Apr 02, 2025 pm 09:57 PM
So verschönern Sie das XML -Format
Apr 02, 2025 pm 09:57 PM
Die XML -Verschönerung verbessert im Wesentlichen seine Lesbarkeit, einschließlich angemessener Einkerbung, Zeilenpausen und Tag -Organisation. Das Prinzip besteht darin, den XML -Baum zu durchqueren, die Eindrücke entsprechend der Ebene hinzuzufügen und leere Tags und Tags, die Text enthalten, zu verarbeiten. Pythons xml.etree.elementtree -Bibliothek bietet eine bequeme Funktion hübsch_xml (), die den oben genannten Verschönerungsprozess implementieren kann.
 Warum führt der Code, der mit Sperren in Go gelegentlich zu Panik führt?
Apr 02, 2025 pm 04:36 PM
Warum führt der Code, der mit Sperren in Go gelegentlich zu Panik führt?
Apr 02, 2025 pm 04:36 PM
Warum verursachen die Verwendung von Schlösser gelegentlich Panik? Schauen wir uns eine interessante Frage an: Warum in Go, auch wenn Schlösser im Code hinzugefügt werden, manchmal ...
 So fügen Sie neue Knoten in XML hinzu
Apr 02, 2025 pm 07:15 PM
So fügen Sie neue Knoten in XML hinzu
Apr 02, 2025 pm 07:15 PM
XML -Knoten -Additionstipps: Erstellen Sie einen neuen Knoten mit der Unterelementfunktion der ElementTree -Bibliothek, indem Sie die Baumstruktur verstehen und den entsprechenden Insertionspunkt finden. Komplexere Szenarien erfordern eine selektive Insertion oder Stapel -Addition basierend auf Knotenattributen oder Inhalten, die logisch beurteilt und schleifen. Für große Dateien sollten Sie eine schnellere LXML -Bibliothek verwenden. Nach einem guten Codestil helfen klare Anmerkungen zur Lesbarkeit und Wartbarkeit des Codes.
 So überprüfen Sie das XML -Format
Apr 02, 2025 pm 10:00 PM
So überprüfen Sie das XML -Format
Apr 02, 2025 pm 10:00 PM
Die Validierung des XML -Formats umfasst die Überprüfung der Struktur und der Einhaltung von DTD oder Schema. Ein XML -Parser ist erforderlich, wie z. Der Überprüfungsprozess umfasst das Parsen der XML -Datei, das Laden des XSD -Schemas und das Ausführen der AssertValid -Methode, um eine Ausnahme auszuführen, wenn ein Fehler erkannt wird. Das Überprüfen des XML -Formats erfordert auch die Handhabung verschiedener Ausnahmen und einen Einblick in die Sprache des XSD -Schemas.
 Wie kann in Go Language das Problem verschiedener Parametertypen verschiedener Schnittstellen im Fabrikmodus gelöst werden?
Apr 02, 2025 pm 04:39 PM
Wie kann in Go Language das Problem verschiedener Parametertypen verschiedener Schnittstellen im Fabrikmodus gelöst werden?
Apr 02, 2025 pm 04:39 PM
In der GO -Sprache definieren Sie eine gemeinsame Schnittstelle und beschränken die von der Schnittstelle implementierten Methoden und verarbeiten gleichzeitig dieselben Methoden verschiedener Schnittstellen, aber unterschiedliche Parametertypen ...
 So ändern Sie den Inhalt mit SAX in XML
Apr 02, 2025 pm 06:39 PM
So ändern Sie den Inhalt mit SAX in XML
Apr 02, 2025 pm 06:39 PM
Das Ändern von XML mit SAX ist eine ereignisbasierte Strategie, die die folgenden Schritte umfasst: XML-Inhalt lesen und auf Elementereignisse anhören. Stellen Sie fest, ob das Element geändert werden muss. Ändern Sie in Textereignissen. Schreiben Sie den geänderten Inhalt im Endelementereignis.
