
 Technologie-Peripheriegeräte
KI
Neue Arbeit von Chen Danqis Team: Der Llama-2-Kontext wird auf 128.000 erweitert, der 10-fache Durchsatz erfordert nur 1/6 des Speichers
Technologie-Peripheriegeräte
KI
Neue Arbeit von Chen Danqis Team: Der Llama-2-Kontext wird auf 128.000 erweitert, der 10-fache Durchsatz erfordert nur 1/6 des Speichers
Neue Arbeit von Chen Danqis Team: Der Llama-2-Kontext wird auf 128.000 erweitert, der 10-fache Durchsatz erfordert nur 1/6 des Speichers

Das Team von Chen Danqi hat gerade eine neue Methode zur LLM-Kontextfenstererweiterung veröffentlicht:
Sie kann das Llama-2-Fenster auf 128.000 erweitern, indem nur 8.000 Token-Dokumente für das Training verwendet werden. Das Wichtigste ist, dass das Modell in diesem Prozess nur1/6 des ursprünglichen Speichers benötigt und das Modell den 10-fachen Durchsatz erreicht.
Um das 7B-Alpaka 2 mit dieser Methode umzuwandeln, ist nur ein Stück A100 erforderlich
.Das Team sagte:
Wir hoffen, dass diese Methode nützlich und einfach zu verwenden ist und
günstige und effektiveLong-Context-Funktionen für zukünftige LLMs bietet.Derzeit werden Modell und Code auf HuggingFace und GitHub veröffentlicht.
Fügen Sie einfach zwei Komponenten hinzu
CEPE
, der vollständige Name lautet „Context Expansion with Parallel Encoding(Context Expansion with Parallel Encoding)“. Als leichtgewichtiges Framework kann es verwendet werden, um das Kontextfenster jedes vorab trainierten und durch Anweisungen fein abgestimmten Modells zu erweitern.
Für jedes vorab trainierte Nur-Decoder-Sprachmodell erweitert CEPE es um zwei kleine Komponenten:
Eine ist ein kleiner Encoderfür die Blockkodierung von langen Kontexten
Eine ist das Cross-Attention-Force-Modul , eingefügt in jede Schicht des Decoders, wird verwendet, um sich auf die Encoderdarstellung zu konzentrieren.
Die vollständige Architektur sieht wie folgt aus:
In diesem Schema codiert das Encodermodell drei zusätzliche Kontextblöcke parallel und wird mit der endgültigen versteckten Darstellung verkettet, die dann als Eingabe für die Queraufmerksamkeit des Decoders verwendet wird Schicht.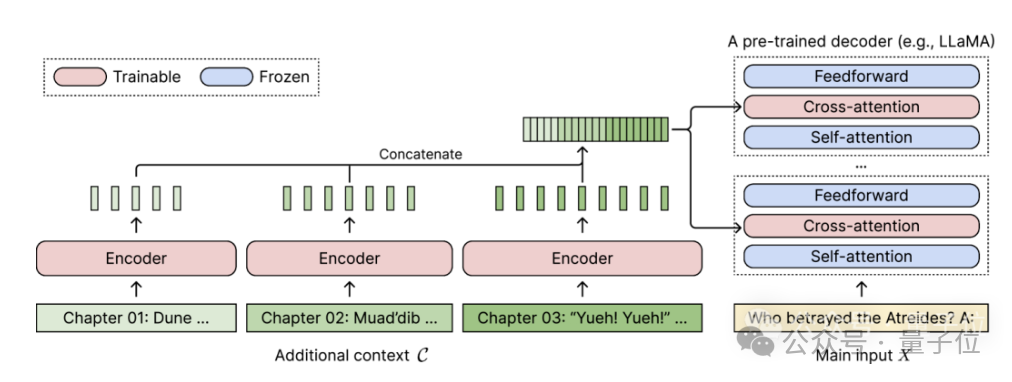 Hier konzentriert sich die Queraufmerksamkeitsschicht hauptsächlich auf die Encoderdarstellung zwischen der Selbstaufmerksamkeitsschicht und der Feed-Forward-Schicht im Decodermodell.
Hier konzentriert sich die Queraufmerksamkeitsschicht hauptsächlich auf die Encoderdarstellung zwischen der Selbstaufmerksamkeitsschicht und der Feed-Forward-Schicht im Decodermodell.
Durch die sorgfältige Auswahl von Trainingsdaten, die keiner Kennzeichnung bedürfen, trägt CEPE dazu bei, dass das Modell über lange Kontextfähigkeiten verfügt und eignet sich auch gut zum Abrufen von Dokumenten.
Der Autor führt ein, dass ein solches CEPE hauptsächlich drei Hauptvorteile bietet:
(1) Die Länge ist verallgemeinerbar, da sie nicht durch die Positionskodierung eingeschränkt ist. Im Gegenteil, ihr Kontext ist segmentiert und kodiert und jedes Segment Es verfügt über eine eigene Standortkodierung.
(2) Hohe EffizienzDurch die Verwendung kleiner Encoder und paralleler Codierung zur Verarbeitung des Kontexts können die Rechenkosten gesenkt werden.Gleichzeitig konzentriert sich die Queraufmerksamkeit nur auf die Darstellung der letzten Ebene des Encoders und das Sprachmodell, das nur den Decoder verwendet, muss die Schlüssel-Wert-Paare jedes Tokens in jeder Ebene zwischenspeichern Im Vergleich dazu erfordert CEPE eine große Speicherreduzierung.
(3) Reduzieren Sie die Schulungskosten
Im Gegensatz zu vollständigen Feinabstimmungsmethoden passt CEPE nur den Encoder und die Queraufmerksamkeit an, während das große Decodermodell eingefroren bleibt. Der Autor stellte vor, dass durch die Erweiterung des 7B-Decoders zu einem Modell
eine 80-GB-A100-GPU vervollständigt werden kann.
Die Ratlosigkeit nimmt weiter abDas Team wendete CEPE auf Llama-2 an und trainierte mit einer 20 Milliarden Token-gefilterten Version von RedPajama
(nur 1 % des Llama-2-Vortrainingsbudgets).
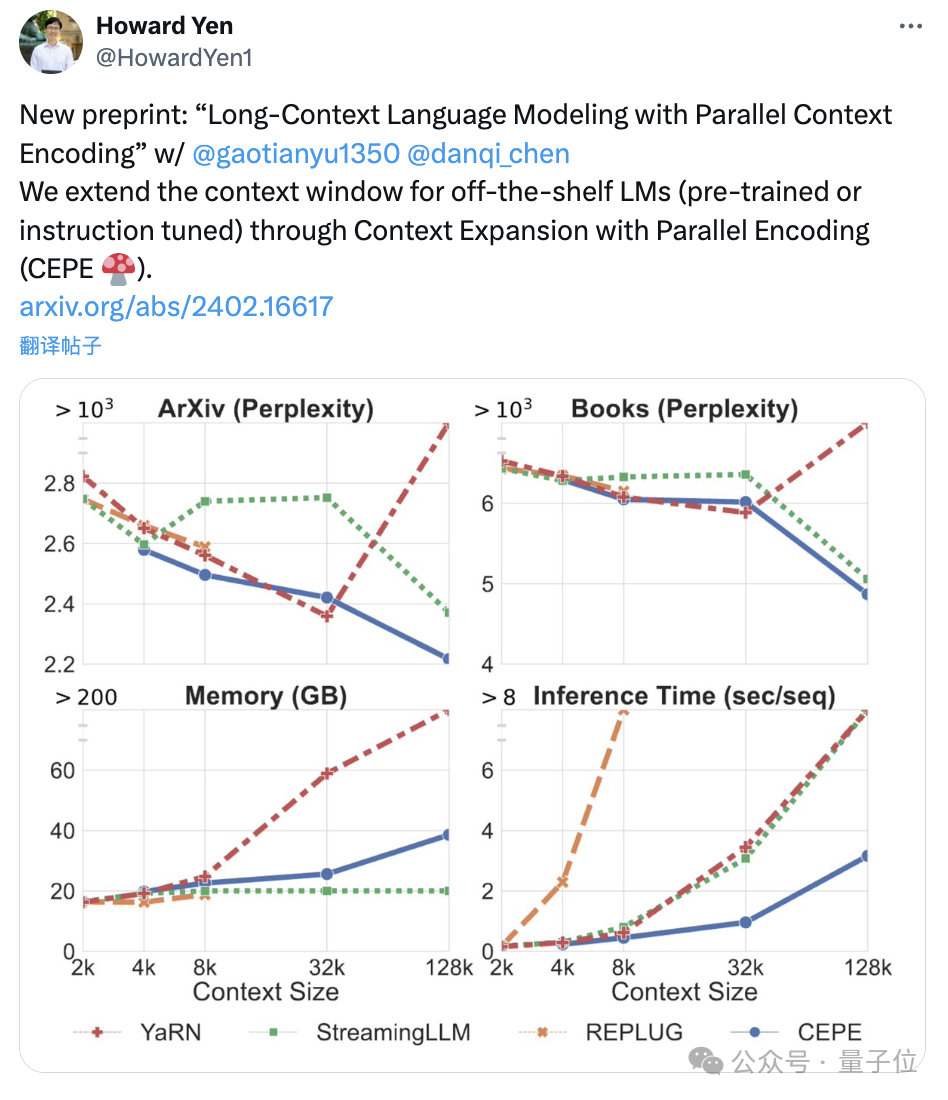
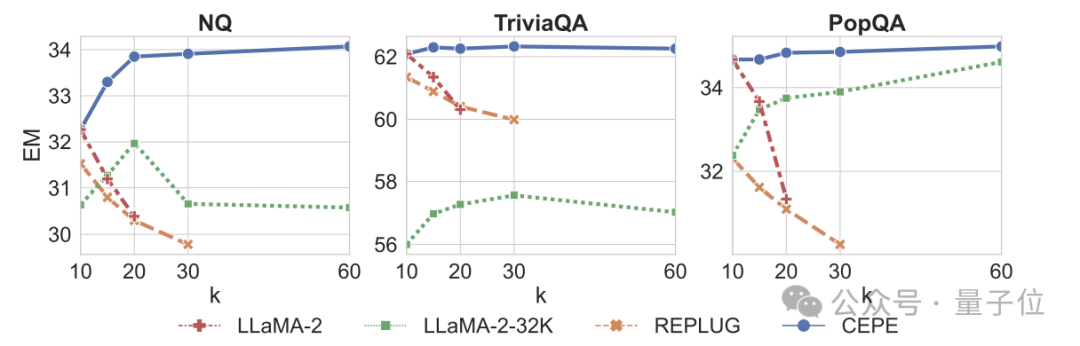
Erstens erreicht CEPE im Vergleich zu zwei vollständig fein abgestimmten Modellen, LLAMA2-32K und YARN-64K, bei allen Datensätzen eine geringere oder vergleichbare Perplexität
bei gleichzeitig geringerer Speichernutzungsrate und höherem Durchsatz.
Wenn der Kontext auf 128.000 erhöht wird (wobei die Trainingslänge von 8.000 bei weitem überschritten wird), nimmt die Verwirrung von CEPE weiter ab, während gleichzeitig ein niedriger Speicherstatus aufrechterhalten wird. 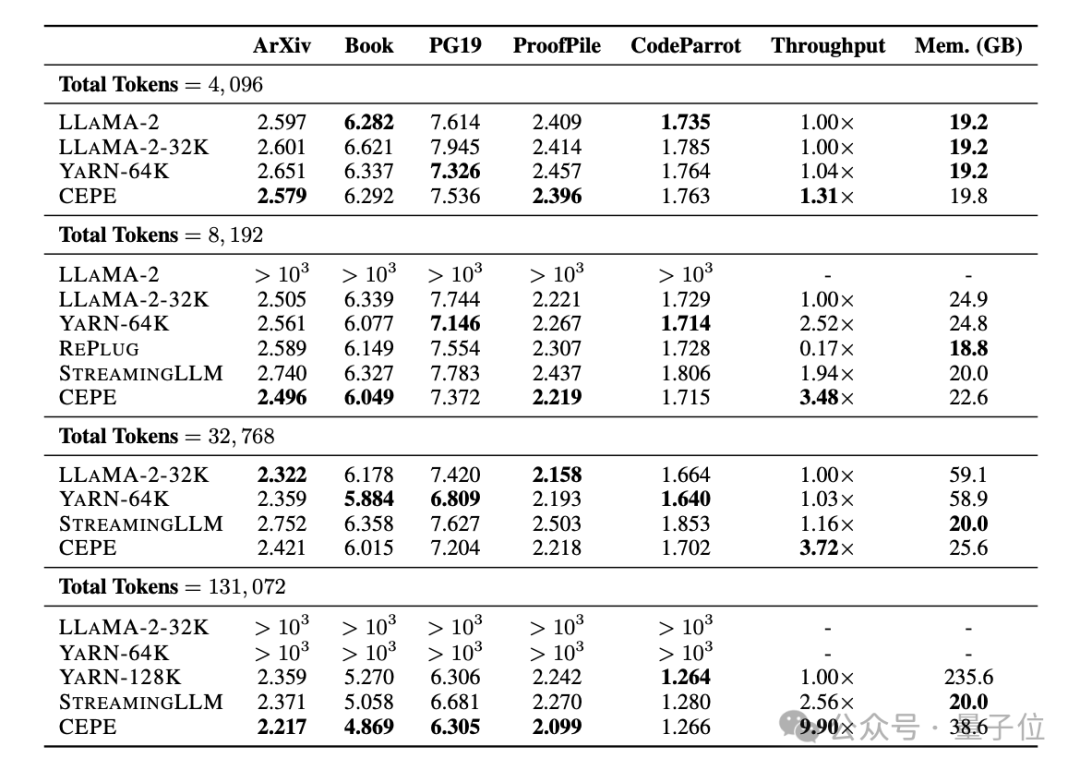
Zweitens werden die
Abruffähigkeiten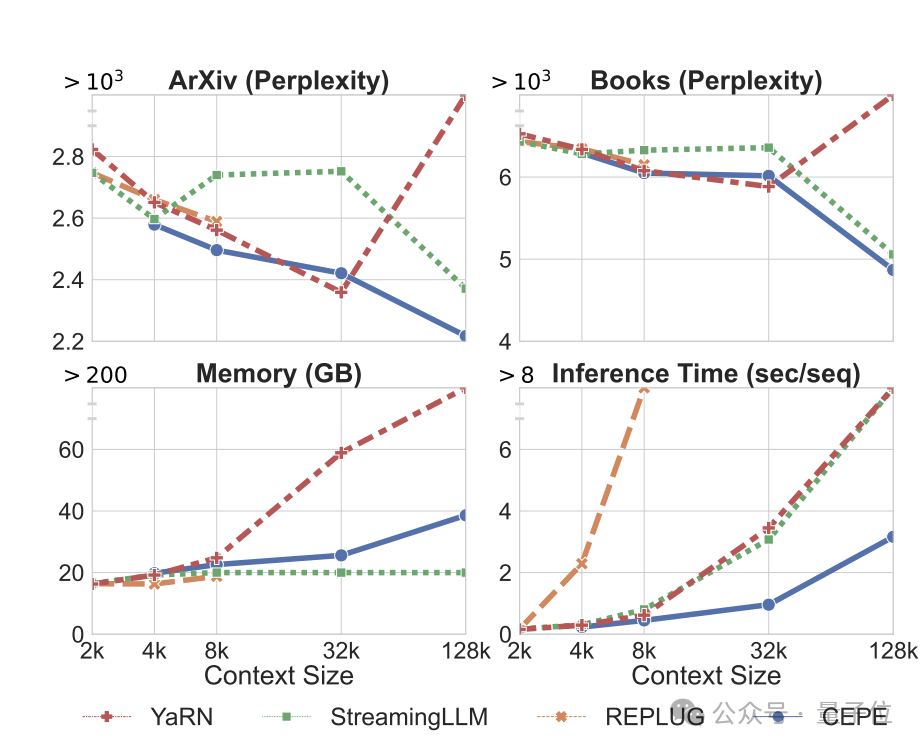
Wie in der folgenden Tabelle gezeigt: Durch die Verwendung des abgerufenen Kontexts kann CEPE die Ratlosigkeit des Modells effektiv verbessern und eine bessere Leistung als RePlug erbringen.
Es ist erwähnenswert, dass CEPE die Verwirrung weiter verbessern wird, selbst wenn Absatz k = 50 (Training ist 60).
Dies zeigt, dass CEPE sich gut auf eine Einstellung mit verbessertem Abruf übertragen lässt, während das Vollkontext-Decodermodell in dieser Fähigkeit nachlässt.
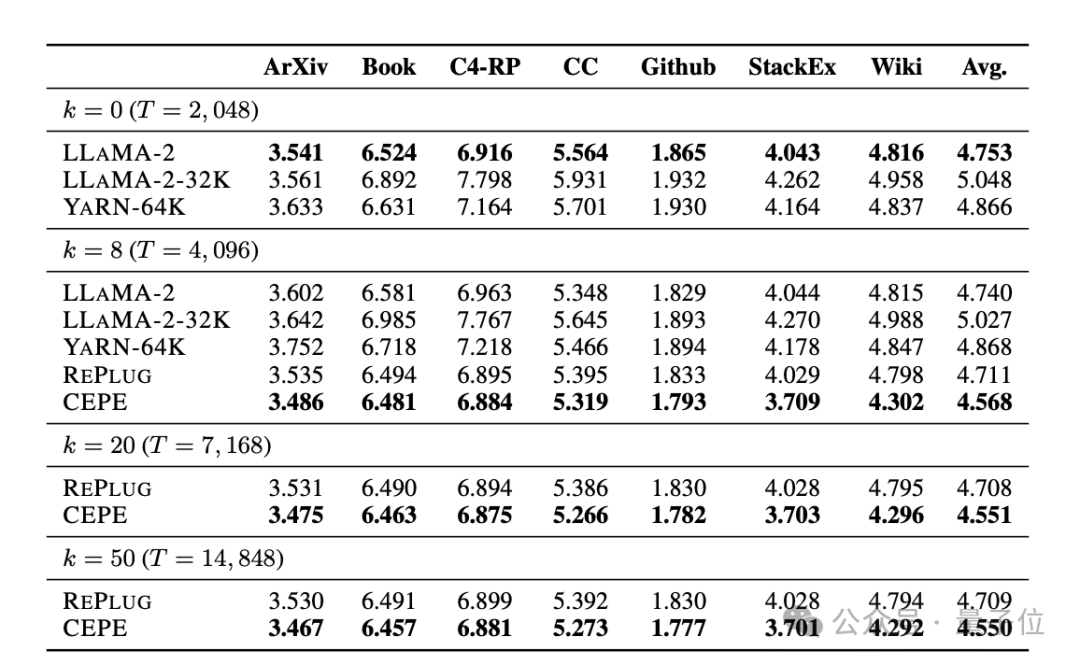
Drittens: Frage- und Antwortmöglichkeiten im offenen Bereichdeutlich übertroffen.
Wie in der Abbildung unten gezeigt, ist CEPE in allen Datensätzen und Absatz-k-Parametern deutlich besser als andere Modelle, und im Gegensatz zu anderen Modellen sinkt die Leistung erheblich, wenn der k-Wert immer größer wird.
Dies zeigt auch, dass CEPE nicht empfindlich auf große Mengen redundanter oder irrelevanter Absätze reagiert.
Zusammenfassend lässt sich sagen, dass CEPE bei allen oben genannten Aufgaben mit viel geringerem Speicher- und Rechenaufwand im Vergleich zu den meisten anderen Lösungen überlegen ist.
Auf der Grundlage dieser Grundlagen schlug der Autor schließlich CEPE-Distilled (CEPED) speziell für Instruktions-Tuning-Modelle vor.
Es werden nur unbeschriftete Daten verwendet, um das Kontextfenster des Modells zu erweitern, wodurch das Verhalten des ursprünglichen anweisungsabgestimmten Modells durch unterstützten KL-Divergenzverlust in eine neue Architektur destilliert wird, wodurch die Notwendigkeit entfällt, teure Daten zur Befehlsverfolgung mit langem Kontext zu verwalten.
Letztendlich kann CEPED das Kontextfenster von Llama-2 erweitern und die Langtextleistung des Modells verbessern, während die Fähigkeit, Anweisungen zu verstehen, erhalten bleibt.
Teamvorstellung
CEPE hat insgesamt 3 Autoren.
Einer ist Yan Heguang(Howard Yen), ein Masterstudent in Informatik an der Princeton University.
Die zweite Person ist Gao Tianyu, ein Doktorand an derselben Schule und Absolvent der Tsinghua-Universität.
Sie sind alle Schüler des korrespondierenden Autors Chen Danqi.

Originaltext des Papiers: https://arxiv.org/abs/2402.16617
Referenzlink: https://twitter.com/HowardYen1/status/1762474556101661158
Das obige ist der detaillierte Inhalt vonNeue Arbeit von Chen Danqis Team: Der Llama-2-Kontext wird auf 128.000 erweitert, der 10-fache Durchsatz erfordert nur 1/6 des Speichers. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
