
 Technologie-Peripheriegeräte
KI
Neues Werk des Autors von ControlNet: KI-Malerei kann in Ebenen unterteilt werden! Das Projekt erhielt 660 Sterne, ohne Open Source zu sein
Technologie-Peripheriegeräte
KI
Neues Werk des Autors von ControlNet: KI-Malerei kann in Ebenen unterteilt werden! Das Projekt erhielt 660 Sterne, ohne Open Source zu sein
Neues Werk des Autors von ControlNet: KI-Malerei kann in Ebenen unterteilt werden! Das Projekt erhielt 660 Sterne, ohne Open Source zu sein

„Es ist keineswegs ein einfacher Ausschnitt.“
ControlNet-Autor Die neueste Forschung hat eine Welle hoher Aufmerksamkeit erhalten –
Geben Sie mir eine Aufforderung, Sie können Stable Diffusion verwenden, um direkt einzelne oder mehrere zu generieren transparente Ebenen (PNG) !
Zum Beispiel:
Eine Frau mit unordentlichen Haaren im Schlafzimmer.
Frau mit unordentlichen Haaren, im Schlafzimmer.

Sie können sehen, dass die KI nicht nur ein vollständiges Bild erzeugt hat, das der Eingabeaufforderung entspricht, sondern sogar der Hintergrund und die Zeichen können getrennt werden.
Und wenn Sie das Charakter-PNG-Bild vergrößern und genauer betrachten, können Sie erkennen, dass die Haarsträhnen klar definiert sind.

Schauen Sie sich ein anderes Beispiel an:
Brennendes Brennholz, auf einem Tisch, auf dem Land.
Brennendes Brennholz, auf einem Tisch, auf dem Land.

In ähnlicher Weise kann durch Vergrößern des PNG des „brennenden Streichholzes“ sogar der schwarze Rauch um die Flamme herum abgetrennt werden:

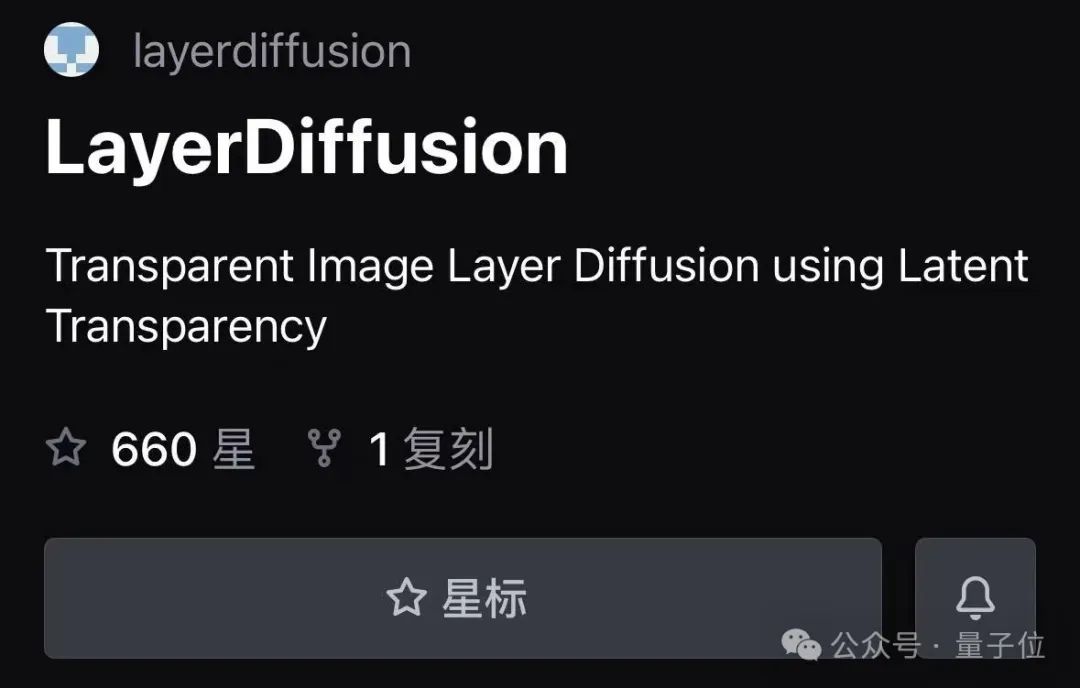
Das ist das Autor von ControlNet Die vorgeschlagene neue Methode LayerDiffusion ermöglicht es groß angelegten vorab trainierten latenten Diffusionsmodellen, transparente Bilder zu erzeugen.

Es lohnt sich noch einmal zu betonen, dass LayerDiffusion keineswegs so einfach ist wie das Ausschneiden von Bildern, der Fokus liegt auf der Generierung.
Wie Internetnutzer sagten:
Dies ist heutzutage einer der Kernprozesse in der Animations- und Videoproduktion. Wenn dieser Schritt bestanden werden kann, kann man sagen, dass die SD-Konsistenz kein Problem mehr darstellt.
Einige Internetnutzer dachten, dass eine solche Arbeit nicht schwierig sei, es gehe nur darum, „übrigens einen Alphakanal hinzuzufügen“, aber was ihn überraschte, war:
Es dauerte so lange, bis die Ergebnisse herauskamen.
Wie wird LayerDiffusion implementiert?
PNG beginnt nun mit der Erzeugungsroute
Der Kern von LayerDiffusion ist eine Methode namens latente Transparenz(latente Transparenz).
Einfach ausgedrückt ermöglicht es das Hinzufügen von Transparenz zum Modell, ohne die latente Verteilung des vorab trainierten latenten Diffusionsmodells (z. B. Stable Diffusion) zu zerstören.
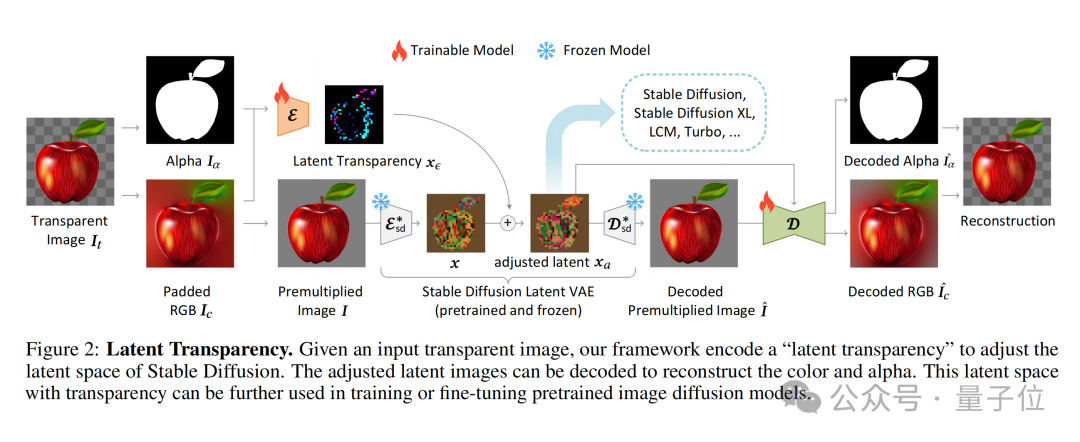
In Bezug auf die konkrete Implementierung kann es als Hinzufügen einer sorgfältig entworfenen kleinen Störung (Offset) zum latenten Bild verstanden werden. Diese Störung wird als zusätzlicher Kanal codiert, der zusammen mit dem RGB-Kanal ein vollständiges latentes Bild darstellt.
Um die Kodierung und Dekodierung von Transparenz zu erreichen, hat der Autor zwei unabhängige neuronale Netzwerkmodelle trainiert: eines ist der Latent-Transparenz-Encoder(Latent-Transparenz-Encoder) und das andere ist der Latent-Transparenz-Decoder(Latent Transparenzdecoder).
Der Encoder empfängt den RGB-Kanal und den Alpha-Kanal des Originalbilds als Eingabe und wandelt die Transparenzinformationen in einen Offset im latenten Raum um.
Der Decoder empfängt das angepasste latente Bild und das rekonstruierte RGB-Bild und extrahiert die Transparenzinformationen aus dem latenten Raum, um das ursprüngliche transparente Bild zu rekonstruieren.
Um sicherzustellen, dass die zusätzliche potenzielle Transparenz die zugrunde liegende Verteilung des vorab trainierten Modells nicht zerstört, schlagen die Autoren eine „Harmlosigkeit“-Metrik (Harmlosigkeit) vor.
Diese Metrik bewertet die Auswirkung der latenten Transparenz, indem sie die Decodierungsergebnisse des angepassten latenten Bildes durch den Decoder des ursprünglichen vorab trainierten Modells mit dem Originalbild vergleicht.
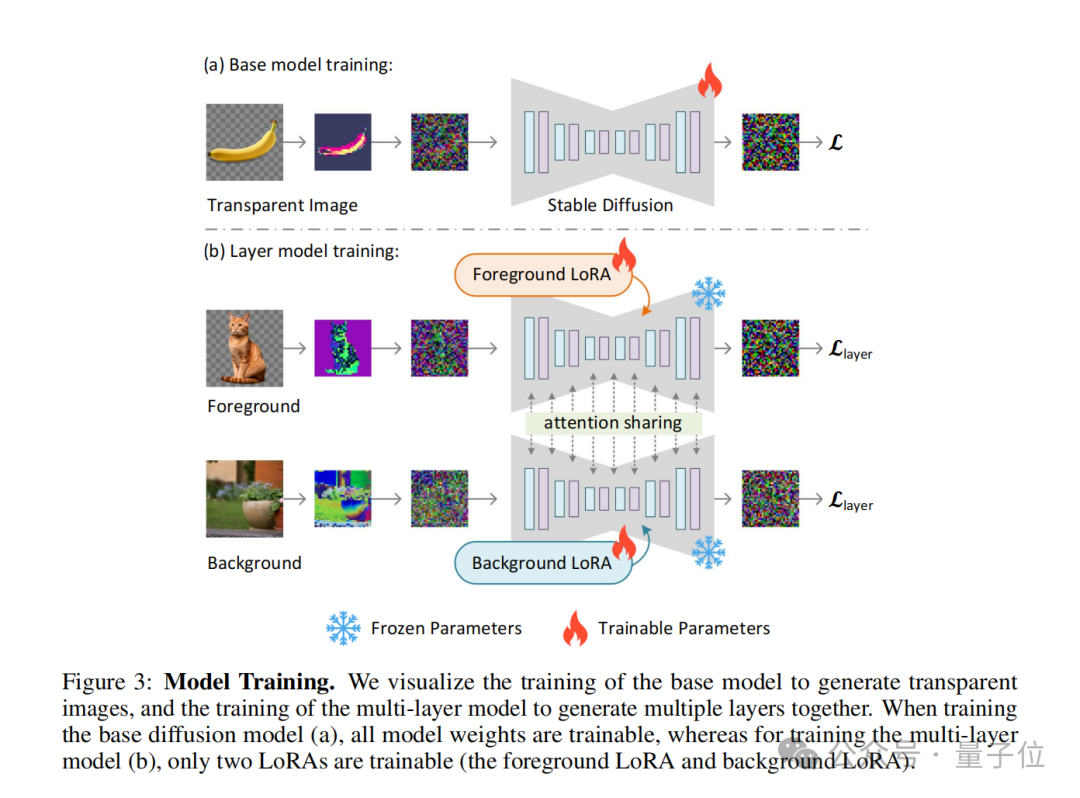
Während des Trainingsprozesses verwendet der Autor auch eine Gelenkverlustfunktion (Gelenkverlustfunktion) , die Rekonstruktionsverlust (Rekonstruktionsverlust) , Identitätsverlust (Identitätsverlust) und Diskriminatorverlust (Diskriminatorverlust) kombiniert ).
Ihre Funktionen sind:
- Rekonstruktionsverlust: wird verwendet, um sicherzustellen, dass das dekodierte Bild dem Originalbild so ähnlich wie möglich ist;
- Identitätsverlust: wird verwendet, um sicherzustellen, dass das angepasste latente Bild vom Vorbild korrekt dekodiert werden kann; trainierter Decoder ;
- Diskriminatorverlust: Wird verwendet, um den Realismus des erzeugten Bildes zu verbessern.
Mit diesem Ansatz kann jedes latente Diffusionsmodell in einen transparenten Bildgenerator umgewandelt werden, indem es einfach an den angepassten latenten Raum angepasst wird.

Das Konzept der latenten Transparenz kann auch erweitert werden, um mehrere transparente Ebenen zu generieren, und mit anderen bedingten Kontrollsystemen kombiniert werden, um komplexere Bildgenerierungsaufgaben zu erfüllen, wie z. B. die Generierung von Vordergrund-/Hintergrundbedingungen, die Generierung gemeinsamer Ebenen und die Inhaltsstruktur von Ebenen Kontrolle usw. Es ist erwähnenswert, dass der Autor auch zeigt, wie man ControlNet einführt, um die Funktionen von LayerDiffusion zu bereichern: in den folgenden Punkten zusammengefasst werden.
 Native Generierung vs. Nachbearbeitung
Native Generierung vs. Nachbearbeitung
LayerDiffusion ist eine native Methode zur Generierung transparenter Bilder, die Transparenzinformationen direkt während des Generierungsprozesses berücksichtigt und kodiert. Das bedeutet, dass das Modell beim Generieren des Bildes einen Alphakanal  erstellt und so ein Bild mit Transparenz erzeugt.
erstellt und so ein Bild mit Transparenz erzeugt.
Traditionelle Ausschnittmethoden umfassen in der Regel zunächst das Erzeugen oder Erhalten eines Bildes und das anschließende Trennen von Vorder- und Hintergrund mithilfe von Bildbearbeitungstechniken
(z. B. Chroma Key, Kantenerkennung, benutzerdefinierte Masken usw.). Dieser Ansatz erfordert häufig zusätzliche Schritte zur Handhabung der Transparenz und kann bei komplexen Hintergründen oder Kanten zu unnatürlichen Übergängen führen. 
Latente Raumoperationen vs. Pixelraumoperationen
LayerDiffusion arbeitet im latenten Raum (latenter Raum), einer Zwischendarstellung, die es dem Modell ermöglicht, komplexere Bildmerkmale zu lernen und zu generieren. Durch die Kodierung der Transparenz im latenten Raum kann das Modell die Transparenz während der Generierung auf natürliche Weise verarbeiten, ohne dass komplexe Berechnungen auf Pixelebene erforderlich sind.
Traditionelle Ausschnitttechnologie wird normalerweise im Pixelraum durchgeführt, was eine direkte Bearbeitung des Originalbildes beinhalten kann, wie z. B. Farbersetzung, Kantenglättung usw. Bei diesen Methoden kann es zu Schwierigkeiten bei der Handhabung durchscheinender Effekte (z. B. Feuer, Rauch) oder komplexer Kanten kommen.
Datensatz und Training
LayerDiffusion verwendet für das Training einen großen Datensatz, der transparente Bildpaare enthält, sodass das Modell die komplexe Verteilung erlernen kann, die zum Generieren hochwertiger transparenter Bilder erforderlich ist.
Herkömmliche Mattierungsmethoden stützen sich möglicherweise auf kleinere Datensätze oder spezifische Trainingssätze, was ihre Fähigkeit zur Bewältigung verschiedener Szenarien einschränken kann.
Flexibilität und Kontrolle
LayerDiffusion bietet mehr Flexibilität und Kontrolle, da es dem Benutzer ermöglicht, die Generierung von Bildern durch Textaufforderungen zu steuern und mehrere Ebenen generieren kann, die gemischt und kombiniert werden können, um komplexe Szenen zu erstellen.
Herkömmliche Ausschneidemethoden haben möglicherweise eine eingeschränktere Kontrolle, insbesondere wenn es um komplexe Bildinhalte und Transparenz geht.Qualitätsvergleich
Benutzeruntersuchungen zeigen, dass von LayerDiffusion generierte transparente Bilder in den meisten Fällen von Benutzern bevorzugt werden(97 %) , was darauf hindeutet, dass der generierte transparente Inhalt optisch mit kommerziellen transparenten Assets vergleichbar und möglicherweise sogar besser ist .
Herkömmliche Ausschneidemethoden erzielen in manchen Fällen möglicherweise nicht die gleiche Qualität, insbesondere bei schwierigen Transparenzen und Kanten. Alles in allem bietet LayerDiffusion eine fortschrittlichere und flexiblere Methode zum Generieren und Verarbeiten transparenter Bilder. Es kodiert Transparenz direkt während des Generierungsprozesses und ist in der Lage, qualitativ hochwertige Ergebnisse zu erzielen, die mit herkömmlichen Ausschnittmethoden nur schwer zu erreichen sind. Über den AutorWie wir gerade erwähnt haben, ist einer der Autoren dieser Studie der Erfinder des berühmten ControlNet –Zhang Lumin.
Er schloss sein Bachelor-Studium an der Universität Suzhou ab. Als Student im ersten Jahr veröffentlichte er zehn hochkarätige Arbeiten. Zhang Lumin studiert derzeit an der Stanford University für seinen Doktortitel, aber man kann sagen, dass er sehr zurückhaltend ist und sich noch nicht einmal bei Google Scholar registriert hat.
Das obige ist der detaillierte Inhalt vonNeues Werk des Autors von ControlNet: KI-Malerei kann in Ebenen unterteilt werden! Das Projekt erhielt 660 Sterne, ohne Open Source zu sein. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
