

Während sich die technische Analyse von Sora entfaltet, wird die Bedeutung der KI-Infrastruktur immer wichtiger.
Ein neuer Artikel von Byte und der Peking-Universität erregte zu diesem Zeitpunkt Aufmerksamkeit:
Der Artikel enthüllte, dass der von Byte gebaute Wanka-Cluster das GPT-3-Maßstabsmodell (175B) in 1,75 Tagen ) Training fertigstellen kann .
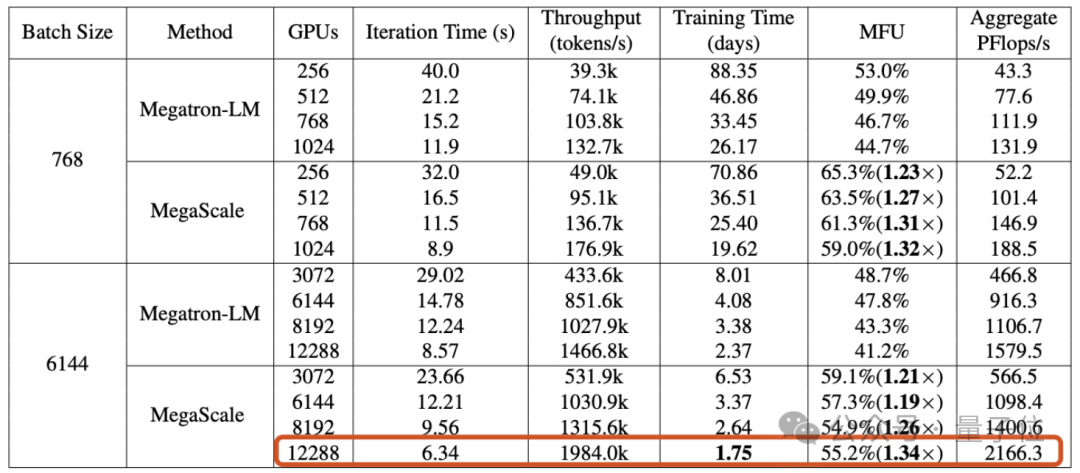
Konkret schlug Byte ein Produktionssystem namens MegaScale vor, das darauf abzielt, die Effizienz- und Stabilitätsherausforderungen zu lösen, die beim Training großer Modelle auf dem Wanka-Cluster auftreten.
Beim Training eines großen Sprachmodells mit 175 Milliarden Parametern auf 12288 GPUs erreichte MegaScale eine Rechenleistungsauslastung von 55,2 % (MFU) , was dem 1,34-fachen von NVIDIA Megatron-LM entspricht.
Das Papier enthüllte auch, dass Byte seit September 2023 einen GPU-Cluster mit Ampere-Architektur (A100/A800) mit mehr als 10.000 Karten eingerichtet hat und derzeit eine groß angelegte Hopper-Architektur (H100/H800) aufbaut Cluster.
Im Zeitalter großer Modelle muss die Bedeutung der GPU nicht mehr näher erläutert werden.
Aber das Training großer Modelle kann nicht direkt gestartet werden, wenn die Anzahl der Karten voll ist – wenn die Skalierung des GPU-Clusters das „10.000“-Niveau erreicht, ist es eine Herausforderung für sich, ein „effizientes und stabiles“ Training zu erreichen technische Probleme.
 Die erste Herausforderung: Effizienz.
Die erste Herausforderung: Effizienz.
Das Training eines großen Sprachmodells ist keine einfache parallele Aufgabe. Es erfordert die Verteilung des Modells auf mehrere GPUs, und diese GPUs erfordern häufige Kommunikation, um den Trainingsprozess gemeinsam voranzutreiben. Neben der Kommunikation haben Faktoren wie Bedieneroptimierung, Datenvorverarbeitung und GPU-Speicherverbrauch alle einen Einfluss auf die Rechenleistungsauslastung
(MFU), ein Indikator, der die Trainingseffizienz misst.
MFU ist das Verhältnis des tatsächlichen Durchsatzes zum theoretischen Maximaldurchsatz.Die zweite Herausforderung: Stabilität.
Wir wissen, dass das Training großer Sprachmodelle oft sehr lange dauert, was auch bedeutet, dass Fehler und Verzögerungen während des Trainingsprozesses keine Seltenheit sind.
Die Kosten eines Ausfalls sind hoch, daher ist es besonders wichtig, die Wiederherstellungszeit nach einem Ausfall zu verkürzen.
Um diese Herausforderungen zu bewältigen, haben die Forscher von ByteDance MegaScale entwickelt und es im Rechenzentrum von Byte bereitgestellt, um das Training verschiedener großer Modelle zu unterstützen.
MegaScale wurde auf Basis von NVIDIA Megatron-LM verbessert.
 Zu den spezifischen Verbesserungen gehören das gemeinsame Design von Algorithmen und Systemkomponenten, die Optimierung von Kommunikations- und Rechenüberschneidungen, die Betreiberoptimierung, die Optimierung der Datenpipeline und die Optimierung der Netzwerkleistung usw.:
Zu den spezifischen Verbesserungen gehören das gemeinsame Design von Algorithmen und Systemkomponenten, die Optimierung von Kommunikations- und Rechenüberschneidungen, die Betreiberoptimierung, die Optimierung der Datenpipeline und die Optimierung der Netzwerkleistung usw.:
In dem Artikel wurde erwähnt, dass MegaScale mehr als 90 % der Software- und Hardwarefehler automatisch erkennen und reparieren kann.
Experimentelle Ergebnisse zeigen, dass MegaScale beim Training eines 175B großen Sprachmodells auf 12288 GPUs 55,2 % MFU erreichte, was dem 1,34-fachen der Rechenleistungsauslastung von Megatrion-LM entspricht.
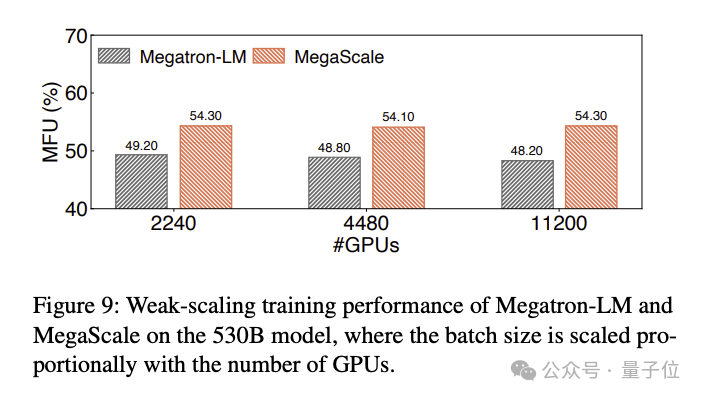
Die MFU-Vergleichsergebnisse des Trainings eines großen 530B-Sprachmodells lauten wie folgt:
Gerade als dieses technische Papier eine Diskussion auslöste, kamen neue Neuigkeiten über das bytebasierte Sora-Produkt heraus:
Screenshot Sein KI-Videotool ähnlich wie Sora hat einen Betatest nur auf Einladung gestartet.

Der Grundstein scheint gelegt zu sein, freuen Sie sich also auf die großen Modellprodukte von Byte?
Papieradresse: https://arxiv.org/abs/2402.15627
Das obige ist der detaillierte Inhalt vonDie technischen Details des Byte Wanka-Clusters werden bekannt gegeben: Das GPT-3-Training wurde in 2 Tagen abgeschlossen und die Rechenleistungsauslastung übertraf NVIDIA Megatron-LM. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Spielleiste
Spielleiste
 So entfernen Sie die Firefox-Sicherheitssperre
So entfernen Sie die Firefox-Sicherheitssperre
 Ethereum-Preisangebote
Ethereum-Preisangebote
 Wie lautet die Website-Adresse von Ouyi?
Wie lautet die Website-Adresse von Ouyi?
 Window.setInterval()-Methode
Window.setInterval()-Methode
 Pycharm-Methode zum Öffnen einer neuen Datei
Pycharm-Methode zum Öffnen einer neuen Datei
 Was ist Localstorage?
Was ist Localstorage?
 Einführung in allgemeine Befehle von Postgresql
Einführung in allgemeine Befehle von Postgresql
 So registrieren Sie sich bei Matcha Exchange
So registrieren Sie sich bei Matcha Exchange








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



