Mona Lisa gähnt, ein Huhn lernt, ein Bügeleisen zu heben ... Das große Modell von Google VideoPoet schlägt sich sehr gut.
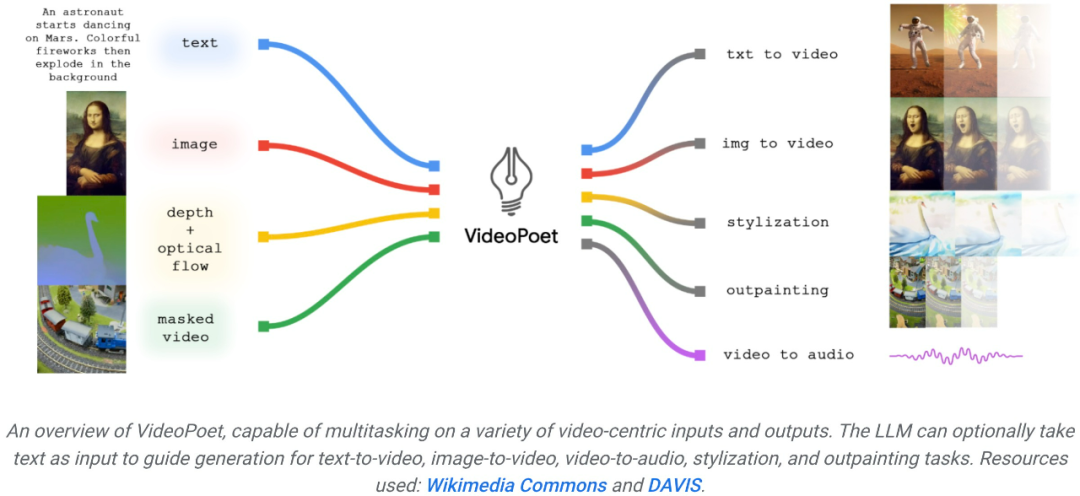
Ende 2023 prägen Technologieunternehmen die letzte Stufe der generativen KI – die Videogenerierung. An diesem Dienstag ging das von Google vorgeschlagene große Videogenerierungsmodell online und erregte sofort die Aufmerksamkeit der Menschen. Dieses große Sprachmodell namens VideoPoet gilt als revolutionäres Tool zur Zero-Shot-Videogenerierung. VideoPoet kann nicht nur Videos aus Text und Bildern generieren, sondern auch Stile übertragen und Videos in Sprache umwandeln. Tatsächlich können dadurch vielfältige und sanfte Bewegungen aufgebaut werden. 
Sobald die Nachricht herauskam, begrüßten viele Menschen sie: Schauen Sie sich die derzeit wenigen fertigen Produkte mit guten Ergebnissen an, und die Entwicklung der Großmodelltechnologie ist zu schnell.
Jemand zeigte sich überrascht über die Länge des von diesem großen Modell generierten Videos:
Quelle: https://twitter.com/cybersphere_ai/status/1737257729167966353 Außerdem sagen einige Leute, dass dies ein revolutionäres großes Sprachmodell ist.
Einige Leute forderten auch Google auf, VideoPoet schnell zu öffnen. Der allgemeine Trend wartet auf niemanden. Mit der Entwicklung der generativen KI gab es in letzter Zeit eine Welle neuer Videogenerationsmodelle, die eine atemberaubende Bildqualität aufweisen. Einer der aktuellen Engpässe bei der Videogenerierung ist die Erzeugung kohärenter großer Bewegungen. Aber selbst führende Modelle können in vielen Fällen nur kleinere Bewegungen erzeugen oder weisen bei größeren Bewegungen auffällige Artefakte auf. Um die Anwendung von Sprachmodellen bei der Videogenerierung zu untersuchen, haben Forscher von Google ein großes Sprachmodell (LLM) VideoPoet eingeführt, das verschiedene Videogenerierungsaufgaben ausführen kann, darunter Text zu Video, Bild zu Video und Videostilisierung , Videoreparatur und -erweiterung sowie Video-zu-Audio-Konvertierung. Tipps (von links nach rechts): Ein Teddybär, der an einem regnerischen Tag Laserstrahlen aus seinem Maul schießt; Tipps (von links nach rechts): Ein brüllender Löwe aus gelben Löwenzahnblättern; ein Pferd, das durch Van Goghs Sternennacht galoppiert; ein gepanzertes Eichhörnchen, das auf einer Gans reitet; ein Selfie. Bild zum Generieren von Videos
Für Bild zu Video kann VideoPoet das Eingabebild nehmen und es mit Eingabeaufforderungen animieren.
Um das Gähnen der Mona Lisa zu starten, geben Sie einfach ein Bild und eine Eingabeaufforderung ein: Eine Frau gähnt. Sie erhalten den folgenden Effekt.
Tipps (von links nach rechts): Ein Schiff, das auf rauer See mit Gewittern und Blitzen segelt, im Stil eines Ölgemäldes; ein Wanderer, der an einem windigen Tag mit einem Stock auf einer Klippe steht; Wolkenmeer, das unten schwebt.
VideoPoet ist auch in der Lage, das Eingabevideo basierend auf Textaufforderungen zu stilisieren. Tipps (von links nach rechts): Ein Teddybär läuft auf einem sauberen Eissee Schlittschuh; ein metallischer Löwe brüllt im Schein eines Ofens.
VideoPoet kann auch Audio generieren. Das Modell wird zunächst gebeten, einen 2-Sekunden-Clip zu generieren und versucht dann, den Ton des Frames ohne jegliche Textanleitung vorherzusagen. Auf diese Weise ist VideoPoet in der Lage, Video und Audio aus einem einzigen Modell zu generieren. VideoPoet kann auch lange Videos generieren, der Standardwert ist 2 Sekunden. Dieser Vorgang kann unendlich oft wiederholt werden, um Videos beliebiger Länge zu erstellen, indem die letzte Sekunde des Videos angepasst und die nächste Sekunde vorhergesagt wird. Unten sehen Sie eine Beispieldemonstration, wie VideoPoet aus Texteingaben ein langes Video generiert. Tipp: FPV-Aufnahmen zeigen eine sehr scharfe Elfstone-Stadt im Dschungel mit einem leuchtend blauen Fluss, Wasserfällen und großen, steilen vertikalen Felswänden.
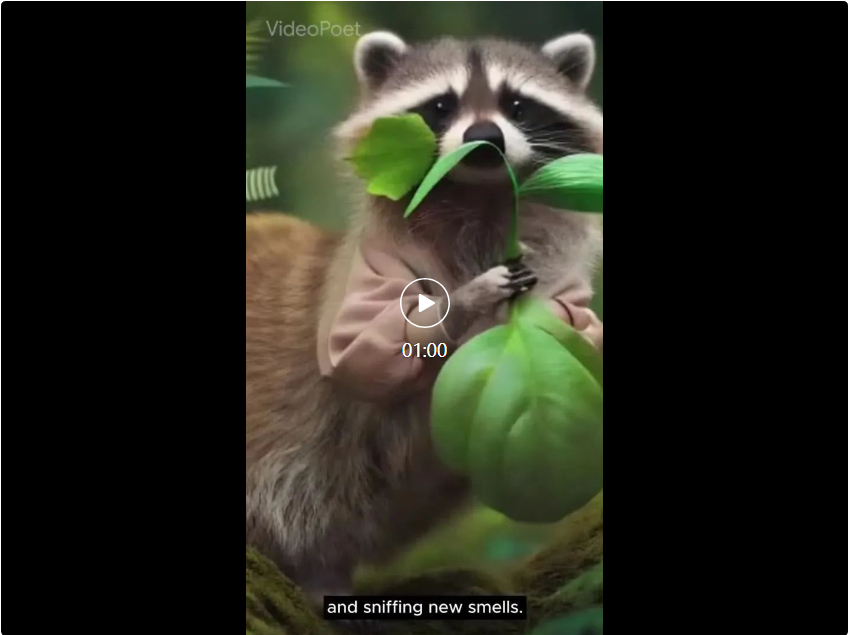
Benutzer können die Eingabeaufforderung ändern und so das Video erweitern. Originalvideo von zwei Waschbären, die auf einem Motorrad auf einer von Pinien umgebenen Bergstraße fahren, 8k. Das erweiterte Video zeigt zwei Waschbären auf einem Motorrad. Ein Meteor fällt hinter die Waschbären, der Meteor trifft auf die Erde und explodiert.
Interaktive VideobearbeitungFür das bereitgestellte Eingabevideo (ganz links) kann der Benutzer die Bewegung des Objekts ändern, um verschiedene Aktionen auszuführen. Wie unten gezeigt, haben die mittleren drei keine Textaufforderungen und die letzte Textaufforderung lautet: Beginnen Sie mit einem Rauchhintergrund.
VideoPoet kann Details zu den verdeckten Teilen des Videos hinzufügen, oder Sie können es durch Textführung reparieren.
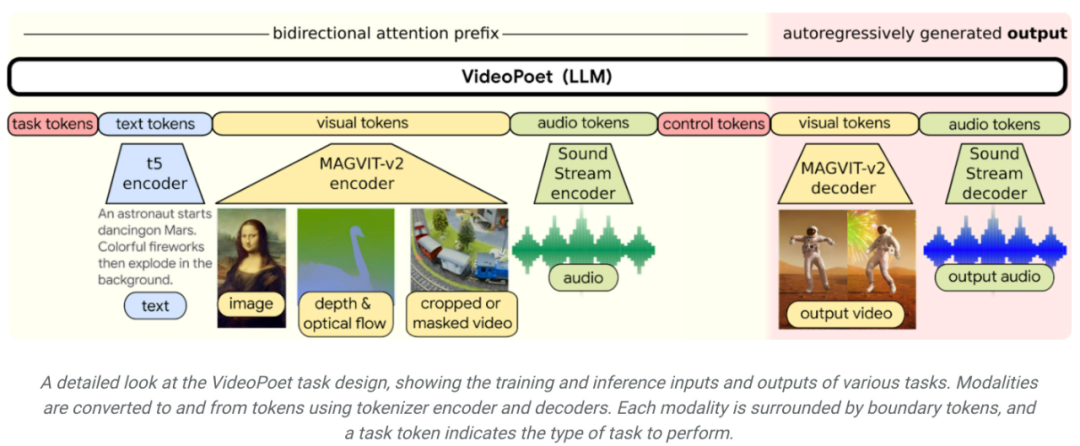
Um die Fähigkeiten von VideoPoet zu demonstrieren, hat Google auch einen kurzen Kurzfilm produziert, der aus mehreren von VideoPoet generierten Kurzvideos besteht. Das von Bard geschriebene Drehbuch ist eine Kurzgeschichte über einen reisenden Waschbären, komplett mit einer Szene-für-Szene-Aufschlüsselung und einer dazugehörigen Aufforderungsliste. Google hat dann für jede Eingabeaufforderung Videoclips erstellt und alle generierten Clips zusammengefügt, um das endgültige Video unten zu erstellen. Einführung in die MethodeWie in der Abbildung unten gezeigt, kann VideoPoet das Eingabebild animieren, um ein Video zu generieren, und das Video bearbeiten oder erweitern.
In Bezug auf die Stilisierung erhält das Modell Videos, die Tiefe und optischen Fluss charakterisieren, um Inhalte in einem textgesteuerten Stil zu zeichnen. Ein wesentlicher Vorteil der Verwendung von LLM für Schulungen besteht darin, dass viele der skalierbaren Effizienzverbesserungen, die in der bestehenden LLM-Schulungsinfrastruktur eingeführt wurden, wiederverwendet werden können. Allerdings arbeitet LLM mit diskreten Token, was die Videogenerierung zu einer Herausforderung macht. Video- und Audio-Tokenizer können verwendet werden, um Video- und Audioclips in Sequenzen diskreter Token zu kodieren und können auch wieder in die ursprüngliche Darstellung zurückkonvertiert werden. Durch die Verwendung mehrerer Tokenizer (MAGVIT V2 für Videos und Bilder und SoundStream für Audio) trainiert VideoPoet autoregressive Sprachmodelle, um mehrere Modalitäten für Video, Bilder, Audio und Text zu lernen. Sobald das Modell kontextabhängige Token generiert, kann es sie mithilfe eines Tokenizer-Decoders wieder in eine visuelle Darstellung umwandeln.
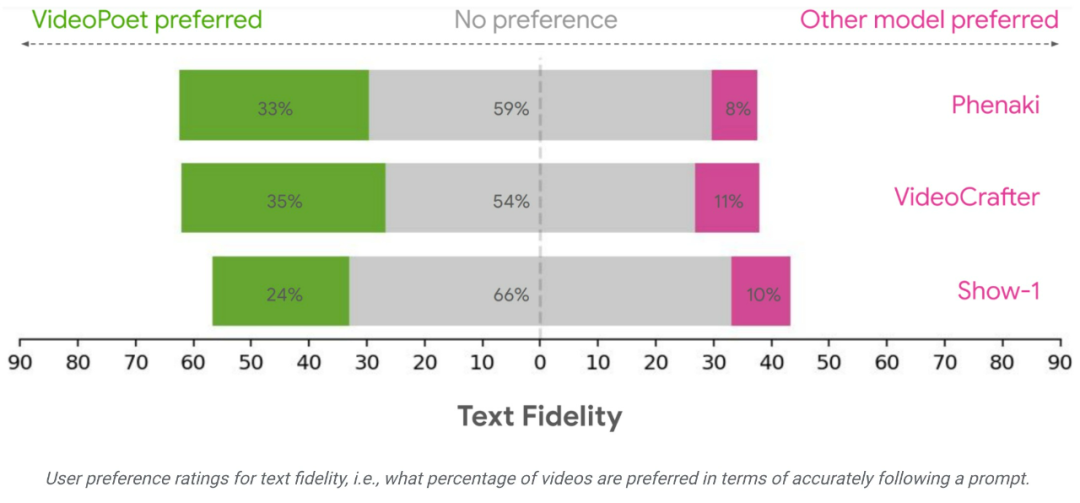
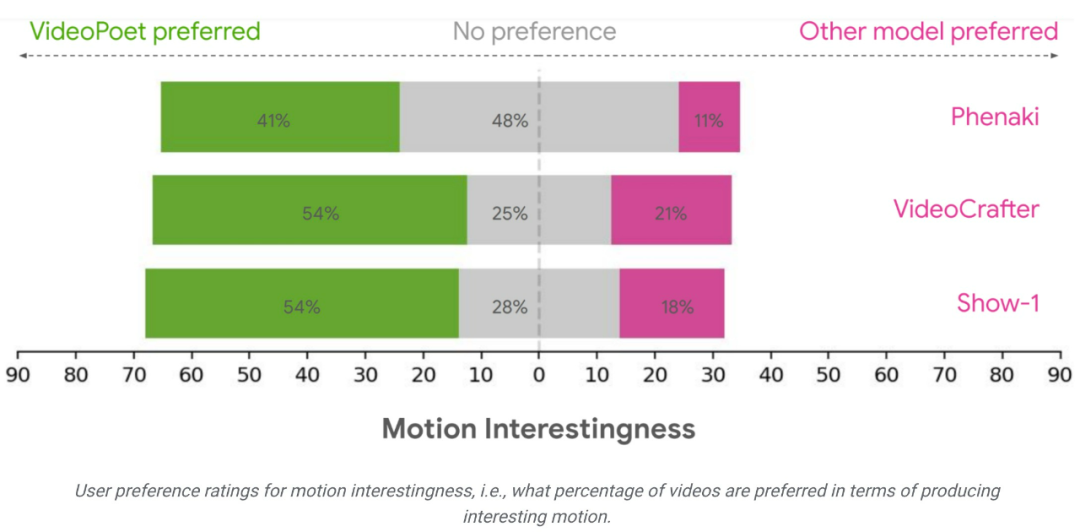
Das Forschungsteam bewertete die Leistung von VideoPoet bei der Text-zu-Video-Generierung anhand verschiedener Benchmarks, um die Ergebnisse mit anderen Methoden zu vergleichen. Um eine neutrale Bewertung zu gewährleisten, ließ die Studie alle Modelle unter verschiedenen Eingabeaufforderungen laufen, ohne Beispiele herauszupicken, und forderte menschliche Bewerter auf, Präferenzbewertungen abzugeben.
Im Durchschnitt wurden 24–35 % der Beispiele in VideoPoet bei der Befolgung von Aufforderungen besser bewertet als Konkurrenzmodelle, verglichen mit 8–11 % der Konkurrenzmodelle. Die Bewerter bevorzugten außerdem 41–54 % der Beispiele in VideoPoet, weil die Aktionen, die die Videos generierten, interessanter waren, im Vergleich zu 11–21 % der anderen Modelle. 🔜 ://sites.research.google/videopoet/stylization/Das obige ist der detaillierte Inhalt vonKann die Videogenerierung unendlich lang sein? Das große Google VideoPoet-Modell ist online, Internetnutzer: revolutionäre Technologie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!


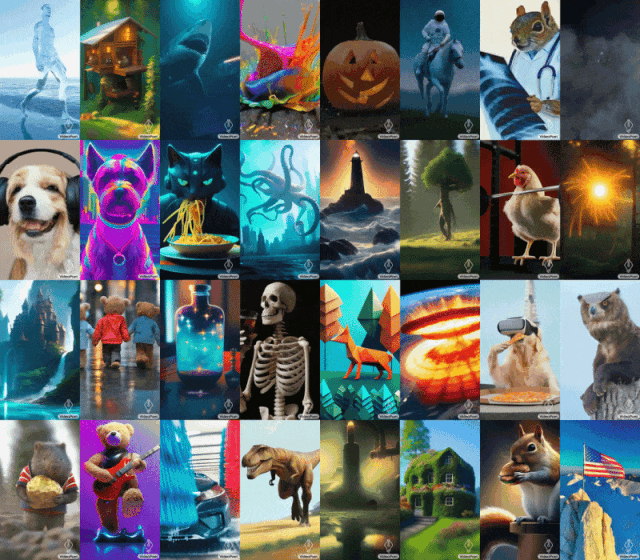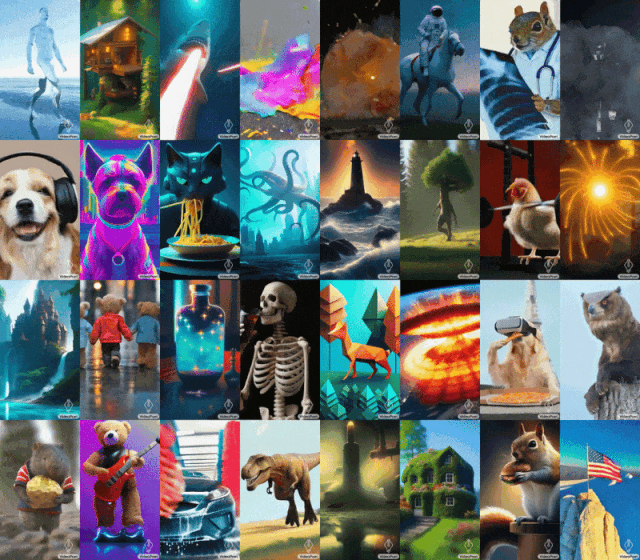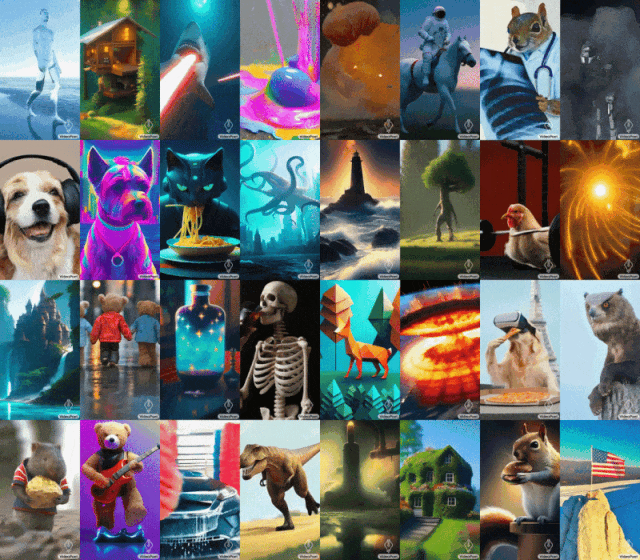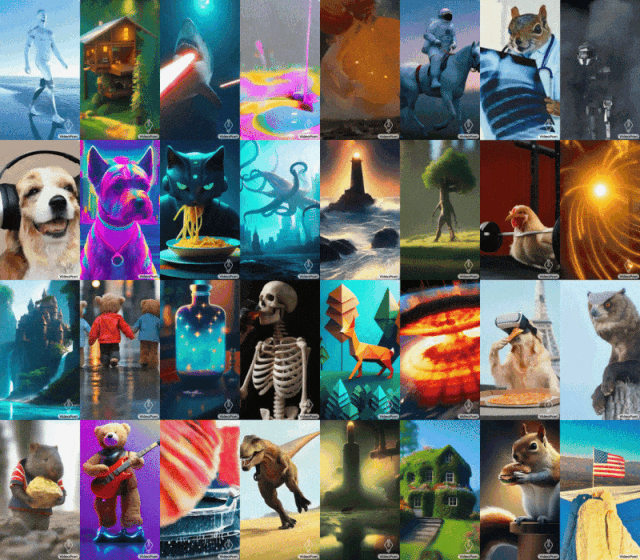












 Was bedeutet Intervall?
Was bedeutet Intervall?
 Was beinhaltet die Datenverschlüsselungsspeicherung?
Was beinhaltet die Datenverschlüsselungsspeicherung?
 Verwendung von setInterval in JS
Verwendung von setInterval in JS
 Was sind die Javabean-Attribute?
Was sind die Javabean-Attribute?
 Was sind die Marquee-Parameter?
Was sind die Marquee-Parameter?
 Wo Sie Douyin-Live-Wiederholungen sehen können
Wo Sie Douyin-Live-Wiederholungen sehen können
 Lösung für das Problem, dass exe-Dateien im Win10-System nicht geöffnet werden können
Lösung für das Problem, dass exe-Dateien im Win10-System nicht geöffnet werden können
 Teambition
Teambition
 Tutorial zur Konfiguration von Java-Umgebungsvariablen
Tutorial zur Konfiguration von Java-Umgebungsvariablen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



