
 Technologie-Peripheriegeräte
KI
Visualisieren Sie den FAISS-Vektorraum und passen Sie die RAG-Parameter an, um die Ergebnisgenauigkeit zu verbessern
Technologie-Peripheriegeräte
KI
Visualisieren Sie den FAISS-Vektorraum und passen Sie die RAG-Parameter an, um die Ergebnisgenauigkeit zu verbessern
Visualisieren Sie den FAISS-Vektorraum und passen Sie die RAG-Parameter an, um die Ergebnisgenauigkeit zu verbessern

Da sich die Leistung groß angelegter Open-Source-Sprachmodelle weiter verbessert, hat sich auch die Leistung beim Schreiben und Analysieren von Code, Empfehlungen, Textzusammenfassungen und Frage-Antwort-Paaren (QA) erheblich verbessert. Aber wenn es um die Qualitätssicherung geht, mangelt es LLM oft an Problemen im Zusammenhang mit ungeschulten Daten, und viele interne Dokumente werden im Unternehmen aufbewahrt, um Compliance, Geschäftsgeheimnisse oder Datenschutz zu gewährleisten. Wenn diese Dokumente abgefragt werden, kann LLM Halluzinationen hervorrufen und irrelevante, erfundene oder inkonsistente Inhalte produzieren.

Eine mögliche Technik zur Bewältigung dieser Herausforderung ist Retrieval Augmentation Generation (RAG). Dabei geht es darum, die Antworten durch Verweise auf maßgebliche Wissensdatenbanken über die Trainingsdatenquelle hinaus zu verbessern, um die Qualität und Genauigkeit der Generierung zu verbessern. Das RAG-System besteht aus einem Abrufsystem, das relevante Dokumentfragmente aus dem Korpus abruft, und einem LLM-Modell, das die abgerufenen Fragmente als Kontext zur Generierung von Antworten nutzt. Daher sind die Qualität des Korpus und die im Vektorraum eingebettete Darstellung entscheidend für die Leistung von RAG.
In diesem Artikel werden wir die Visualisierungsbibliothek renumics-spotlight verwenden, um die mehrdimensionale Einbettung des FAISS-Vektorraums in 2D zu visualisieren und nach Möglichkeiten suchen, die Genauigkeit der RAG-Antwort durch die Änderung einiger wichtiger Vektorisierungsparameter zu verbessern. Als LLM verwenden wir den TinyLlama 1.1B Chat, ein kompaktes Modell mit der gleichen Architektur wie der Llama 2. Der Vorteil liegt darin, dass weniger Ressourcen benötigt werden und die Laufzeiten schneller sind, ohne dass die Genauigkeit proportional abnimmt, was es ideal für schnelle Experimente macht.
Systemdesign
Das QA-System besteht aus zwei Modulen, wie in der Abbildung dargestellt.
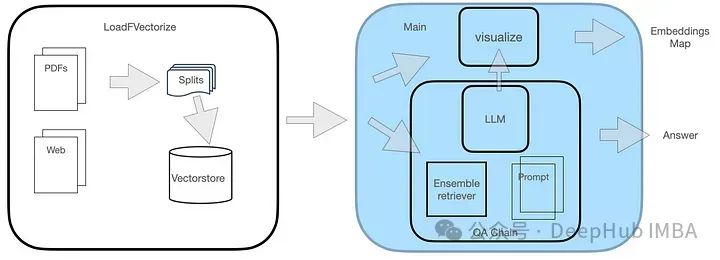
Das LoadFVectorize-Modul wird zum Laden von PDF- oder Webdokumenten sowie zur Durchführung vorläufiger Tests und Visualisierung verwendet. Ein weiteres Modul ist für das Laden von LLM und die Instanziierung des FAISS-Suchers sowie für den anschließenden Aufbau einer Suchkette einschließlich LLM, Sucher und benutzerdefinierten Abfrageaufforderungen verantwortlich. Schließlich visualisieren wir den Vektorraum.
Code-Implementierung
1. Installieren Sie die erforderlichen Bibliotheken. Die Renomics-Spotlight-Bibliothek verwendet eine umap-ähnliche Visualisierungsmethode, um hochdimensionale Einbettungen in überschaubare 2D-Visualisierungen zu reduzieren und gleichzeitig wichtige Attribute beizubehalten. Wir haben die Verwendung von umap bereits kurz vorgestellt, jedoch nur die Grundfunktionen. Dieses Mal haben wir es im Rahmen des Systemdesigns in ein reales Projekt integriert. Zunächst müssen Sie die erforderlichen Bibliotheken installieren.
pip install langchain faiss-cpu sentence-transformers flask-sqlalchemy psutil unstructured pdf2image unstructured_inference pillow_heif opencv-python pikepdf pypdf pip install renumics-spotlight CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir
2. Das LoadFVectorize-Modul
enthält 3 Funktionen:
load_doc übernimmt das Laden von Online-PDF-Dokumenten, jeder Block ist in 512 Zeichen unterteilt, überlappt sich mit 100 Zeichen und gibt die Dokumentliste zurück.
vectorize ruft die obige Funktion „load_doc“ auf, um die Blockliste des Dokuments abzurufen, die Einbettung zu erstellen, sie im lokalen Verzeichnis opdf_index zu speichern und die FAISS-Instanz zurückzugeben.
load_db prüft, ob sich die FAISS-Bibliothek auf der Festplatte im Verzeichnis opdf_index befindet, versucht, sie zu laden und gibt schließlich ein FAISS-Objekt zurück.
Der vollständige Code dieses Modulcodes lautet wie folgt:
# LoadFVectorize.py from langchain_community.embeddings import HuggingFaceEmbeddings from langchain_community.document_loaders import OnlinePDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.vectorstores import FAISS # access an online pdf def load_doc() -> 'List[Document]':loader = OnlinePDFLoader("https://support.riverbed.com/bin/support/download?did=7q6behe7hotvnpqd9a03h1dji&versinotallow=9.15.0")documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100)docs = text_splitter.split_documents(documents)return docs # vectorize and commit to disk def vectorize(embeddings_model) -> 'FAISS':docs = load_doc()db = FAISS.from_documents(docs, embeddings_model)db.save_local("./opdf_index")return db # attempts to load vectorstore from disk def load_db() -> 'FAISS':embeddings_model = HuggingFaceEmbeddings()try:db = FAISS.load_local("./opdf_index", embeddings_model)except Exception as e:print(f'Exception: {e}\nNo index on disk, creating new...')db = vectorize(embeddings_model)return dbVerwenden Sie dann das vom LoadFVectorize-Modul zurückgegebene FAISS-Objekt, erstellen Sie einen FAISS-Retriever, instanziieren Sie RetrievalQA und verwenden Sie es für die Abfrage.
{context}{question}
visualize_distance greift auf das Attribut __dict__ des FAISS-Objekts zu, index_to_docstore_id selbst ist das Schlüsselindexwörterbuch für den Wert docstore -ids, verwendet Die vektorisierte Gesamtdokumentanzahl wird durch das ntotal-Attribut des Indexobjekts dargestellt.
# main.py from langchain.chains import RetrievalQA from langchain.prompts import PromptTemplate from langchain_community.llms import LlamaCpp from langchain_community.embeddings import HuggingFaceEmbeddings import LoadFVectorize from renumics import spotlight import pandas as pd import numpy as np # Prompt template qa_template = """ You are a friendly chatbot who always responds in a precise manner. If answer is unknown to you, you will politely say so. Use the following context to answer the question below: {context} {question} """ # Create a prompt instance QA_PROMPT = PromptTemplate.from_template(qa_template) # load LLM llm = LlamaCpp(model_path="./models/tinyllama_gguf/tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf",temperature=0.01,max_tokens=2000,top_p=1,verbose=False,n_ctx=2048 ) # vectorize and create a retriever db = LoadFVectorize.load_db() faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000) # Define a QA chain qa_chain = RetrievalQA.from_chain_type(llm,retriever=faiss_retriever,chain_type_kwargs={"prompt": QA_PROMPT} ) query = 'What versions of TLS supported by Client Accelerator 6.3.0?' result = qa_chain({"query": query}) print(f'--------------\nQ: {query}\nA: {result["result"]}') visualize_distance(db,query,result["result"])
vs = db.__dict__.get("docstore")index_list = db.__dict__.get("index_to_docstore_id").values()doc_cnt = db.index.ntotal
Mit der Docstore-ID-Liste als index_list können Sie das relevante Dokumentobjekt finden und zum Erstellen von A Liste mit der Docstore-ID, Dokumentmetadaten, Dokumentinhalt und deren Einbettung in den Vektorraum aller IDs:
embeddings_vec = db.index.reconstruct_n()
Dann verwenden wir die Liste, um eine DF mit den Spaltenüberschriften zu erstellen. Diese DF verwenden wir schließlich zur Visualisierung
doc_list = list() for i,doc-id in enumerate(index_list):a_doc = vs.search(doc-id)doc_list.append([doc-id,a_doc.metadata.get("source"),a_doc.page_content,embeddings_vec[i]])在继续进行可视化之前,还需要将问题和答案结合起来,我们创建一个单独的问题以及答案的DF,然后与上面的df进行合并,这样能够显示问题和答案出现的地方,在可视化时我们可以高亮显示:
# add rows for question and answerembeddings_model = HuggingFaceEmbeddings()question_df = pd.DataFrame({"id": "question","question": question,"embedding": [embeddings_model.embed_query(question)],})answer_df = pd.DataFrame({"id": "answer","answer": answer,"embedding": [embeddings_model.embed_query(answer)],})df = pd.concat([question_df, answer_df, df])这里使用使用np.linalg.norm在文件和问题嵌入上的进行距离大小的计算:
question_embedding = embeddings_model.embed_query(question)# add column for vector distancedf["dist"] = df.apply( lambda row: np.linalg.norm(np.array(row["embedding"]) - question_embedding),axis=1,)
因为spotlight可以对df进行可视化,所有我们直接调用即可
spotlight.show(df)
Durch diesen Schritt wird Spotlight im Browserfenster gestartet. 、 Test ausführen 基 1. Basistest
Unten ist das Beispielproblem, das wir ausgewählt haben:
Welche Versionen von tls werden von Client Accelerator 6.3.0 unterstützt? Ja:
Client Accelerator 6.3.0 unterstützt TLS 1.1 oder 1.2.
Die folgenden zusätzlichen Informationen können in der Antwort enthalten sein.
Sie müssen diese Funktion mit dem folgenden CLI-Befehl auf dem Client Accelerator aktivieren: (config) # Policy ID
(config) # Policy-ID```
Beachten Sie, dass dieser Befehl nur für TLS 1.1 oder TLS```
1.2 gilt. Wenn Sie ältere TLS-Versionen unterstützen müssen, können Sie den SSL-Backend-Befehl mit client-tlss1.0 verwenden oder client-tlss1.1 option.
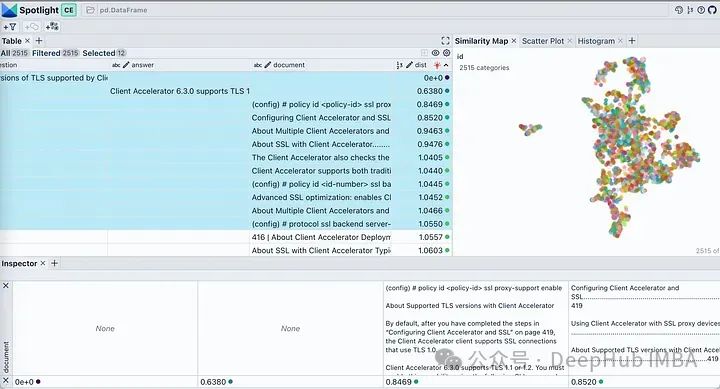
sieht der tatsächlichen Antwort sehr ähnlich, ist aber nicht ganz korrekt, da diese TLS-Versionen nicht ihre Standardversionen sind. Mal sehen, aus welchen Passagen er die Antwort gefunden hat? Verwenden Sie die sichtbare Schaltfläche im Spotlight, um die angezeigten Spalten zu steuern. Sortieren Sie die Tabelle nach „dist“, um Fragen, Antworten und die relevantesten Dokumentausschnitte oben anzuzeigen. Wenn wir uns die Einbettung unseres Dokuments ansehen, werden fast alle Teile des Dokuments als ein einziger Cluster beschrieben. Dies ist sinnvoll, da es sich bei unserem Original-PDF um einen Bereitstellungsleitfaden für ein bestimmtes Produkt handelt, sodass es kein Problem darstellt, es als Cluster zu betrachten. Klicken Sie auf das Filtersymbol auf der Registerkarte „Ähnlichkeitskarte“. Dadurch wird nur die ausgewählte Dokumentliste hervorgehoben, die dicht gruppiert ist. Der Rest wird grau angezeigt, wie im Bild unten dargestellt.
2. Blockgröße und Überlappungsparameter testen
Da der Retriever ein Schlüsselfaktor für die RAG-Leistung ist, werfen wir einen Blick auf mehrere Parameter, die sich auf den Einbettungsraum auswirken. Die Parameter für die Blockgröße (1000, 2000) und/oder die Überlappung (100, 200) von TextSplitter sind während der Dokumentaufteilung unterschiedlich.
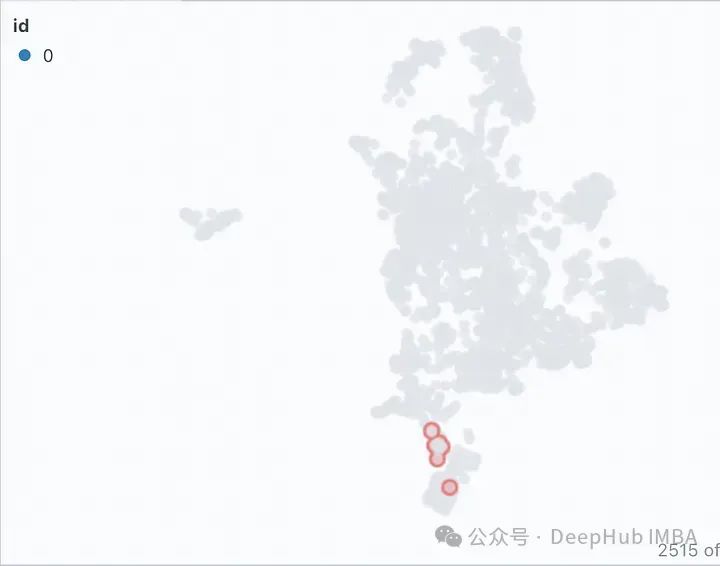
Die Ausgabe scheint für alle Kombinationen ähnlich zu sein, aber wenn wir sorgfältig die richtige Antwort mit jeder Antwort vergleichen, ist die genaue Antwort (1000.200). Falsche Angaben in anderen Antworten wurden rot hervorgehoben. Versuchen wir, dieses Verhalten mithilfe visueller Einbettungen zu erklären:
Wenn wir von links nach rechts schauen, können wir mit zunehmender Blockgröße beobachten, dass der Vektorraum dünner wird und die Blöcke kleiner werden. Von unten nach oben nimmt die Überlappung allmählich zu, ohne dass sich die Eigenschaften des Vektorraums wesentlich ändern. In all diesen Zuordnungen erscheint die gesamte Menge immer noch mehr oder weniger als ein einzelner Cluster, wobei nur wenige Ausreißer vorhanden sind. Dies lässt sich an den generierten Antworten erkennen, da die generierten Antworten alle sehr ähnlich sind.
如果查询位于簇中心等位置时由于最近邻可能不同,在这些参数发生变化时响应很可能会发生显著变化。如果RAG应用程序无法提供预期答案给某些问题,则可以通过生成类似上述可视化图表并结合这些问题进行分析,可能找到最佳划分语料库以提高整体性能方面优化方法。
为了进一步说明,我们将两个来自不相关领域(Grammy Awards和JWST telescope)的维基百科文档的向量空间进行可视化展示。
def load_doc():loader = WebBaseLoader(['https://en.wikipedia.org/wiki/66th_Annual_Grammy_Awards','https://en.wikipedia.org/wiki/James_Webb_Space_Telescope'])documents = loader.load()...
只修改了上面代码其余的代码保持不变。运行修改后的代码,我们得到下图所示的向量空间可视化。
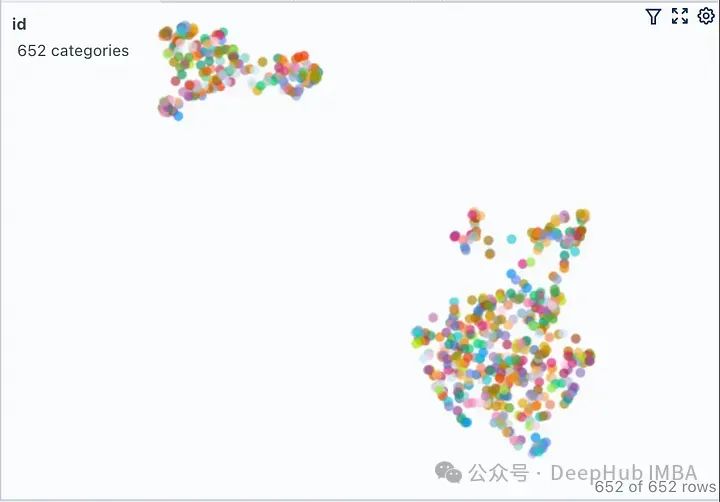
这里有两个不同的不重叠的簇。如果我们要在任何一个簇之外提出一个问题,那么从检索器获得上下文不仅不会对LLM有帮助,而且还很可能是有害的。提出之前提出的同样的问题,看看我们LLM产生什么样的“幻觉”
Client Accelerator 6.3.0 supports the following versions of Transport Layer Security (TLS):
- TLS 1.2\2. TLS 1.3\3. TLS 1.2 with Extended Validation (EV) certificates\4. TLS 1.3 with EV certificates\5. TLS 1.3 with SHA-256 and SHA-384 hash algorithms
这里我们使用FAISS用于向量存储。如果你正在使用ChromaDB并想知道如何执行类似的可视化,renumics-spotlight也是支持的。
总结
检索增强生成(RAG)允许我们利用大型语言模型的能力,即使LLM没有对内部文档进行训练也能得到很好的结果。RAG涉及从矢量库中检索许多相关文档块,然后LLM将其用作生成的上下文。因此嵌入的质量将在RAG性能中发挥重要作用。
在本文中,我们演示并可视化了几个关键矢量化参数对LLM整体性能的影响。并使用renumics-spotlight,展示了如何表示整个FAISS向量空间,然后将嵌入可视化。Spotlight直观的用户界面可以帮助我们根据问题探索向量空间,从而更好地理解LLM的反应。通过调整某些矢量化参数,我们能够影响其生成行为以提高精度。
Das obige ist der detaillierte Inhalt vonVisualisieren Sie den FAISS-Vektorraum und passen Sie die RAG-Parameter an, um die Ergebnisgenauigkeit zu verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Warum stürzt der Chrome-Browser ab? Wie kann das Problem gelöst werden, dass Google Chrome beim Öffnen abstürzt?
Mar 13, 2024 pm 07:28 PM
Warum stürzt der Chrome-Browser ab? Wie kann das Problem gelöst werden, dass Google Chrome beim Öffnen abstürzt?
Mar 13, 2024 pm 07:28 PM
Google Chrome bietet hohe Sicherheit und hohe Stabilität und wird von den meisten Nutzern geliebt. Einige Benutzer stellen jedoch fest, dass Google Chrome abstürzt, sobald sie es öffnen. Was ist los? Möglicherweise sind zu viele Tabs geöffnet oder die Browserversion ist zu alt. Schauen wir uns die detaillierten Lösungen unten an. Wie kann das Absturzproblem von Google Chrome gelöst werden? 1. Schließen Sie einige unnötige Tabs. Wenn zu viele offene Tabs vorhanden sind, versuchen Sie, einige unnötige Tabs zu schließen. Dies kann die Ressourcenbelastung von Google Chrome wirksam verringern und die Möglichkeit eines Absturzes verringern. 2. Aktualisieren Sie Google Chrome. Wenn die Version von Google Chrome zu alt ist, führt dies auch zu Abstürzen und anderen Fehlern. Es wird empfohlen, Chrome auf die neueste Version zu aktualisieren. Klicken Sie oben rechts auf [Anpassen und steuern]-[Einstellungen].
 Windows auf Ollama: Ein neues Tool zum lokalen Ausführen großer Sprachmodelle (LLM).
Feb 28, 2024 pm 02:43 PM
Windows auf Ollama: Ein neues Tool zum lokalen Ausführen großer Sprachmodelle (LLM).
Feb 28, 2024 pm 02:43 PM
Vor kurzem haben sowohl OpenAITranslator als auch NextChat damit begonnen, umfangreiche Sprachmodelle zu unterstützen, die lokal in Ollama ausgeführt werden, was eine neue Spielweise für „Neulinge“-Enthusiasten bietet. Darüber hinaus hat die Einführung von Ollama unter Windows (Vorschauversion) die Art und Weise der KI-Entwicklung auf Windows-Geräten völlig auf den Kopf gestellt. Es hat Forschern auf dem Gebiet der KI und gewöhnlichen „Wassertestspielern“ einen klaren Weg gewiesen. Was ist Ollama? Ollama ist eine bahnbrechende Toolplattform für künstliche Intelligenz (KI) und maschinelles Lernen (ML), die die Entwicklung und Verwendung von KI-Modellen erheblich vereinfacht. In der technischen Gemeinschaft waren die Hardwarekonfiguration und der Umgebungsaufbau von KI-Modellen schon immer ein heikles Thema.
 So lösen Sie einen Pycharm-Absturz
Apr 25, 2024 am 05:09 AM
So lösen Sie einen Pycharm-Absturz
Apr 25, 2024 am 05:09 AM
Zu den Lösungen für PyCharm-Abstürze gehören: Überprüfen Sie die Speichernutzung und erhöhen Sie das Speicherlimit von PyCharm. Überprüfen Sie die Plug-Ins und deaktivieren Sie die Hardwarebeschleunigung für Hilfe.
 Warum verwenden große Sprachmodelle SwiGLU als Aktivierungsfunktion?
Apr 08, 2024 pm 09:31 PM
Warum verwenden große Sprachmodelle SwiGLU als Aktivierungsfunktion?
Apr 08, 2024 pm 09:31 PM
Wenn Sie sich mit der Architektur großer Sprachmodelle befasst haben, ist Ihnen möglicherweise der Begriff „SwiGLU“ in den neuesten Modellen und Forschungsarbeiten aufgefallen. Man kann sagen, dass SwiGLU die am häufigsten verwendete Aktivierungsfunktion in großen Sprachmodellen ist. Wir werden sie in diesem Artikel ausführlich vorstellen. SwiGLU ist eigentlich eine von Google im Jahr 2020 vorgeschlagene Aktivierungsfunktion, die die Eigenschaften von SWISH und GLU kombiniert. Der vollständige chinesische Name von SwiGLU lautet „bidirektionale Gated Linear Unit“. Es optimiert und kombiniert zwei Aktivierungsfunktionen, SWISH und GLU, um die nichtlineare Ausdrucksfähigkeit des Modells zu verbessern. SWISH ist eine sehr häufige Aktivierungsfunktion, die in großen Sprachmodellen weit verbreitet ist, während GLU bei Aufgaben zur Verarbeitung natürlicher Sprache eine gute Leistung gezeigt hat.
 Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Übersetzer |. Bugatti Review |. Chonglou Dieser Artikel beschreibt, wie man die GroqLPU-Inferenz-Engine verwendet, um ultraschnelle Antworten in JanAI und VSCode zu generieren. Alle arbeiten daran, bessere große Sprachmodelle (LLMs) zu entwickeln, beispielsweise Groq, der sich auf die Infrastrukturseite der KI konzentriert. Die schnelle Reaktion dieser großen Modelle ist der Schlüssel, um sicherzustellen, dass diese großen Modelle schneller reagieren. In diesem Tutorial wird die GroqLPU-Parsing-Engine vorgestellt und erläutert, wie Sie mithilfe der API und JanAI lokal auf Ihrem Laptop darauf zugreifen können. In diesem Artikel wird es auch in VSCode integriert, um uns dabei zu helfen, Code zu generieren, Code umzugestalten, Dokumentation einzugeben und Testeinheiten zu generieren. In diesem Artikel erstellen wir kostenlos unseren eigenen Programmierassistenten für künstliche Intelligenz. Einführung in die GroqLPU-Inferenz-Engine Groq
 Empfohlener Android-Emulator, der flüssiger ist (wählen Sie den Android-Emulator, den Sie verwenden möchten)
Apr 21, 2024 pm 06:01 PM
Empfohlener Android-Emulator, der flüssiger ist (wählen Sie den Android-Emulator, den Sie verwenden möchten)
Apr 21, 2024 pm 06:01 PM
Es kann Benutzern ein besseres Spiel- und Nutzungserlebnis bieten. Ein Android-Emulator ist eine Software, die die Ausführung des Android-Systems auf einem Computer simulieren kann. Es gibt viele Arten von Android-Emulatoren auf dem Markt, deren Qualität jedoch unterschiedlich ist. Um den Lesern bei der Auswahl des für sie am besten geeigneten Emulators zu helfen, konzentriert sich dieser Artikel auf einige reibungslose und benutzerfreundliche Android-Emulatoren. 1. BlueStacks: Hohe Laufgeschwindigkeit und ein reibungsloses Benutzererlebnis. BlueStacks ist ein beliebter Android-Emulator. Es ermöglicht Benutzern das Spielen einer Vielzahl mobiler Spiele und Anwendungen und kann Android-Systeme auf Computern mit extrem hoher Leistung simulieren. 2. NoxPlayer: Unterstützt mehrere Eröffnungen und macht das Spielen angenehmer. Sie können verschiedene Spiele in mehreren Emulatoren gleichzeitig ausführen
 Muss ich die GPU-Hardwarebeschleunigung aktivieren?
Feb 26, 2024 pm 08:45 PM
Muss ich die GPU-Hardwarebeschleunigung aktivieren?
Feb 26, 2024 pm 08:45 PM
Ist es notwendig, die hardwarebeschleunigte GPU zu aktivieren? Bei der kontinuierlichen Weiterentwicklung und Weiterentwicklung der Technologie spielt die GPU (Graphics Processing Unit) als Kernkomponente der Computergrafikverarbeitung eine entscheidende Rolle. Einige Benutzer haben jedoch möglicherweise Fragen dazu, ob die Hardwarebeschleunigung aktiviert werden muss. In diesem Artikel werden die Notwendigkeit der Hardwarebeschleunigung für die GPU und die Auswirkungen der Aktivierung der Hardwarebeschleunigung auf die Computerleistung und das Benutzererlebnis erörtert. Zunächst müssen wir verstehen, wie hardwarebeschleunigte GPUs funktionieren. GPU ist spezialisiert
 Was soll ich tun, wenn ein WPS-Formular langsam reagiert? Warum bleibt das WPS-Formular hängen und reagiert langsam?
Mar 14, 2024 pm 02:43 PM
Was soll ich tun, wenn ein WPS-Formular langsam reagiert? Warum bleibt das WPS-Formular hängen und reagiert langsam?
Mar 14, 2024 pm 02:43 PM
Was soll ich tun, wenn ein WPS-Formular sehr langsam reagiert? Benutzer können versuchen, andere Programme zu schließen oder die Software zu aktualisieren, um den Vorgang auszuführen. Lassen Sie diese Website den Benutzern sorgfältig erklären, warum das WPS-Formular langsam reagiert. Warum reagiert die WPS-Tabelle langsam? 1. Schließen Sie andere Programme: Schließen Sie andere laufende Programme, insbesondere solche, die viele Systemressourcen beanspruchen. Dies kann WPS Office mit mehr Rechenressourcen versorgen und Verzögerungen und Verzögerungen reduzieren. 2. WPSOffice aktualisieren: Stellen Sie sicher, dass Sie die neueste Version von WPSOffice verwenden. Durch das Herunterladen und Installieren der neuesten Version von der offiziellen WPSOffice-Website können einige bekannte Leistungsprobleme behoben werden. 3. Reduzieren Sie die Dateigröße
