
 Technologie-Peripheriegeräte
KI
Der Durchsatz wird um das Fünffache erhöht. Die LLM-Schnittstelle zum gemeinsamen Entwerfen des Back-End-Systems und der Front-End-Sprache ist vorhanden.
Technologie-Peripheriegeräte
KI
Der Durchsatz wird um das Fünffache erhöht. Die LLM-Schnittstelle zum gemeinsamen Entwerfen des Back-End-Systems und der Front-End-Sprache ist vorhanden.
Der Durchsatz wird um das Fünffache erhöht. Die LLM-Schnittstelle zum gemeinsamen Entwerfen des Back-End-Systems und der Front-End-Sprache ist vorhanden.

Große Sprachmodelle (LLMs) werden häufig bei komplexen Aufgaben verwendet, die mehrere verkettete Generierungsaufrufe, erweiterte Hinweistechniken, Kontrollfluss und Interaktion mit der externen Umgebung erfordern. Dennoch weisen aktuelle effiziente Systeme zur Programmierung und Ausführung dieser Anwendungen erhebliche Mängel auf.
Forscher haben kürzlich eine neue strukturierte Generationssprache namens SGLang vorgeschlagen, die darauf abzielt, die Interaktivität mit LLM zu verbessern. Durch die Integration des Designs des Back-End-Laufzeitsystems und der Front-End-Sprache macht SGLang LLM leistungsfähiger und einfacher zu steuern. Diese Forschung wurde auch von Chen Tianqi vorangetrieben, einem bekannten Wissenschaftler auf dem Gebiet des maschinellen Lernens und CMU-Assistenzprofessor.
Im Allgemeinen umfassen die Beiträge von SGLang hauptsächlich:
Im Backend schlug das Forschungsteam RadixAttention vor, eine KV-Cache-Wiederverwendungstechnologie (KV-Cache) über mehrere LLM-Generierungsaufrufe hinweg, automatisch und effizient.
In der Frontend-Entwicklung entwickelte das Team eine flexible domänenspezifische Sprache, die in Python eingebettet werden kann, um den Generierungsprozess zu steuern. Diese Sprache kann im Interpretermodus oder Compilermodus ausgeführt werden.
Back-End- und Front-End-Komponenten arbeiten zusammen, um die Ausführung und Programmiereffizienz komplexer LLM-Programme zu verbessern.
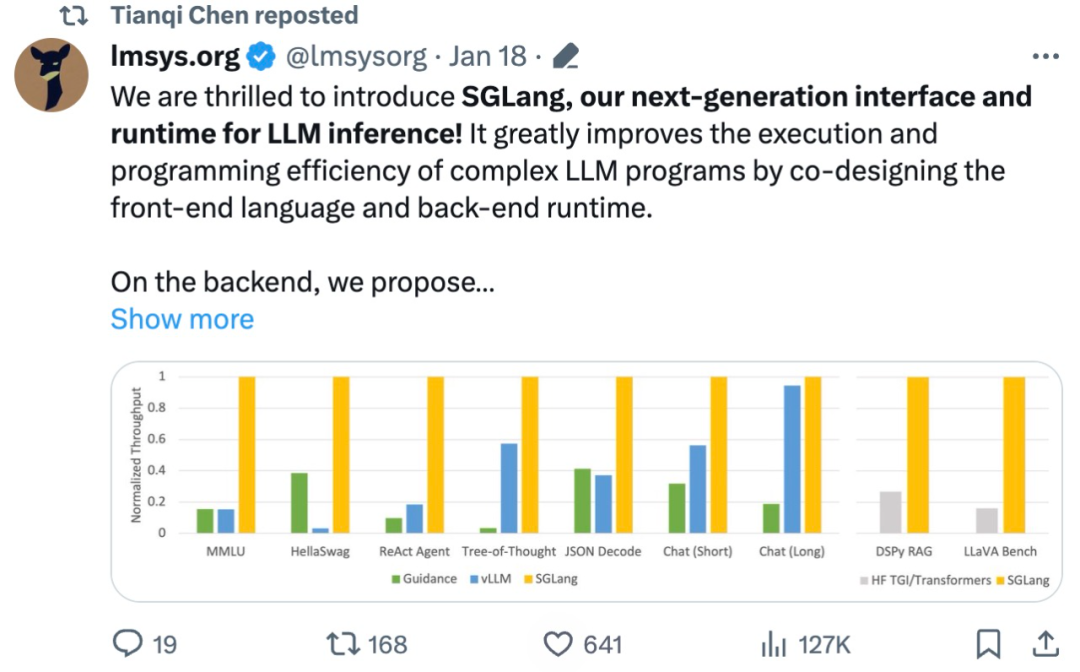
Diese Studie verwendet SGLang zur Implementierung gängiger LLM-Workloads, einschließlich Agenten-, Inferenz-, Extraktions-, Dialog- und Wenig-Schuss-Lernaufgaben, und übernimmt die Modelle Llama-7B und Mixtral-8x7B auf der NVIDIA A10G-GPU. Wie in Abbildung 1 und Abbildung 2 unten dargestellt, ist der Durchsatz von SGLang im Vergleich zu bestehenden Systemen (d. h. Guidance und vLLM) um das Fünffache erhöht.

Abbildung 1: Durchsatz verschiedener Systeme bei LLM-Aufgaben (A10G, Llama-7B bei FP16, Tensorparallelität = 1)
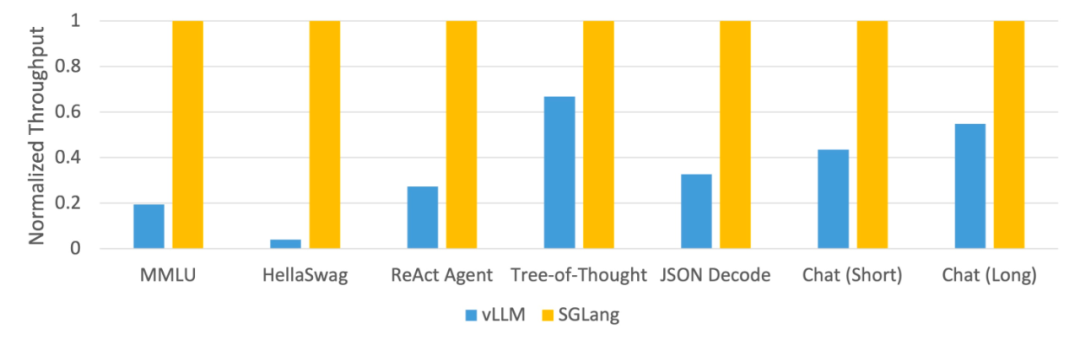
Abbildung 2: Durchsatz verschiedener Systeme bei LLM-Aufgaben ( Mixtral-8x7B auf A10G, FP16, Tensorparallelität = 8)
Backend: Automatische KV-Cache-Wiederverwendung mit RadixAttention
Während der Entwicklung der SGLang-Laufzeit entdeckte diese Studie den Schlüssel zur Optimierung komplexer LLM-Programme – die KV-Cache-Wiederverwendung , was von aktuellen Systemen nicht gut gehandhabt wird. Die Wiederverwendung des KV-Cache bedeutet, dass verschiedene Eingabeaufforderungen mit demselben Präfix den zwischengeschalteten KV-Cache gemeinsam nutzen können, wodurch redundanter Speicher und Berechnungen vermieden werden. In komplexen Programmen mit mehreren LLM-Aufrufen können verschiedene Modi der KV-Cache-Wiederverwendung vorhanden sein. Abbildung 3 unten zeigt vier solcher Muster, die häufig in LLM-Workloads vorkommen. Während einige Systeme in bestimmten Szenarien die Wiederverwendung von KV-Cache bewältigen können, sind häufig manuelle Konfigurationen und Ad-hoc-Anpassungen erforderlich. Darüber hinaus können sich bestehende Systeme aufgrund der Vielfalt möglicher Wiederverwendungsmuster auch durch manuelle Konfiguration nicht automatisch an alle Szenarien anpassen.
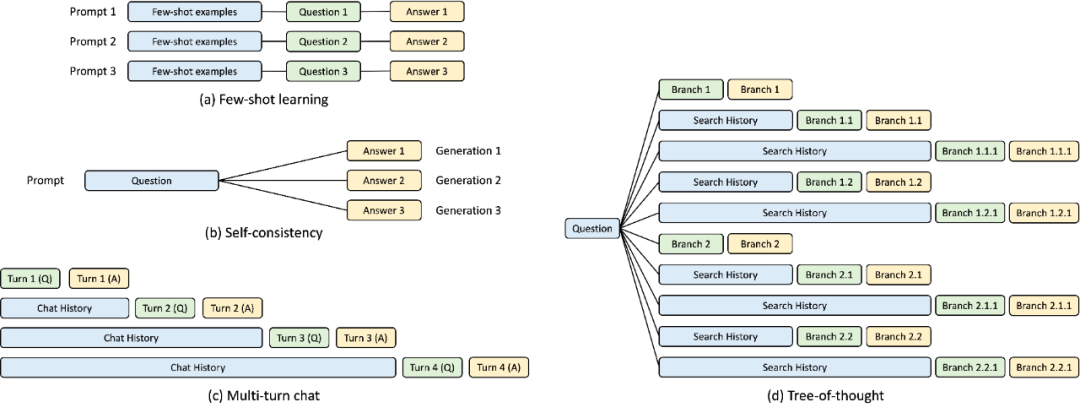
Abbildung 3: KV-Cache-Sharing-Beispiel. Das blaue Kästchen ist der teilbare Eingabeaufforderungsteil, das grüne Kästchen ist der nicht teilbare Teil und das gelbe Kästchen ist die nicht teilbare Modellausgabe. Zu den gemeinsam nutzbaren Teilen gehören kleine Lernbeispiele, Fragen zur Selbstkonsistenz, der Gesprächsverlauf über mehrere Dialogrunden hinweg und der Suchverlauf im Gedankenbaum.
Um diese Wiederverwendungsmöglichkeiten systematisch zu nutzen, schlägt diese Studie eine neue Methode zur automatischen KV-Cache-Wiederverwendung zur Laufzeit vor – RadixAttention. Anstatt den KV-Cache nach Abschluss der Build-Anfrage zu verwerfen, behält diese Methode die Eingabeaufforderung und den KV-Cache des Build-Ergebnisses in einem Basisbaum. Diese Datenstruktur ermöglicht eine effiziente Suche, Einfügung und Entfernung von Präfixen. Diese Studie implementiert eine Räumungsrichtlinie, die am wenigsten kürzlich verwendet wurde (LRU), ergänzt durch eine Cache-bewusste Planungsrichtlinie, um die Cache-Trefferquote zu verbessern.
Radixbäume können als platzsparende Alternative zu Versuchen (Präfixbäume) verwendet werden. Im Gegensatz zu typischen Bäumen können die Kanten von Radixbäumen nicht nur mit einem einzelnen Element, sondern auch mit Sequenzen von Elementen unterschiedlicher Länge markiert werden, was die Effizienz von Radixbäumen verbessert.
Diese Forschung verwendet einen Basisbaum, um die Zuordnung zwischen Token-Sequenzen, die als Schlüssel fungieren, und entsprechenden KV-Cache-Tensoren, die als Werte fungieren, zu verwalten. Diese KV-Cache-Tensoren werden auf der GPU in einem Seitenlayout gespeichert, wobei jede Seite die Größe eines Tokens hat.
Da die GPU-Speicherkapazität begrenzt ist und unbegrenzte KV-Cache-Tensoren nicht neu trainiert werden können, ist eine Räumungsstrategie erforderlich. Diese Studie verwendet die LRU-Räumungsstrategie, um Blattknoten rekursiv zu entfernen. Darüber hinaus ist RadixAttention mit bestehenden Technologien wie Continuous Batching und Paged Attention kompatibel. Für multimodale Modelle kann RadixAttention problemlos um die Verarbeitung von Bildtokens erweitert werden.
Das Diagramm unten zeigt, wie ein Basisbaum bei der Bearbeitung mehrerer eingehender Anfragen verwaltet wird. Das Frontend sendet immer die vollständige Eingabeaufforderung an die Laufzeit, und die Laufzeit führt automatisch den Präfixabgleich, die Wiederverwendung und das Caching durch. Die Baumstruktur wird auf der CPU gespeichert und verursacht einen geringen Wartungsaufwand.
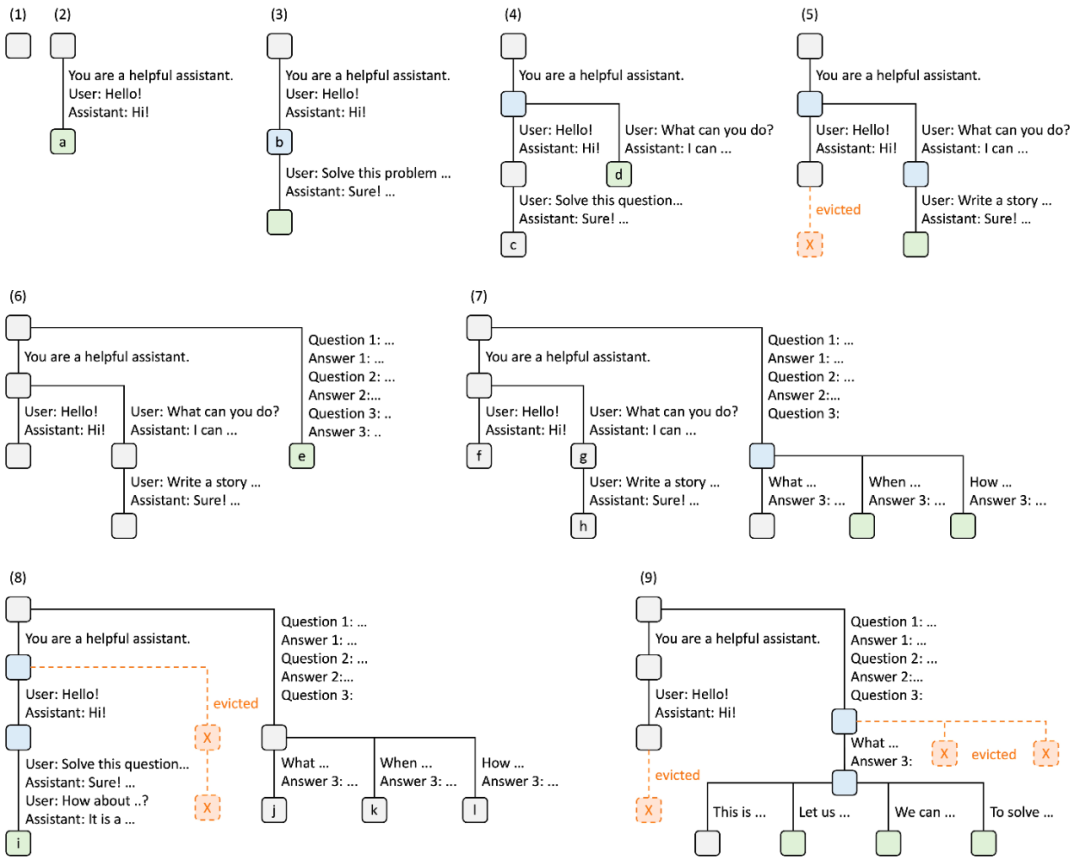
Abbildung 4. RadixAttention-Betriebsbeispiel unter Verwendung der LRU-Räumungsrichtlinie, erklärt in neun Schritten.
Abbildung 4 zeigt die dynamische Entwicklung des Basisbaums als Reaktion auf verschiedene Anfragen. Zu diesen Anfragen gehören zwei Chat-Sitzungen, eine Reihe von Lernabfragen mit wenigen Schüssen und selbstkonsistente Stichproben. Jede Baumkante ist mit einer Beschriftung gekennzeichnet, die einen Teilstring oder eine Folge von Token darstellt. Knoten sind farblich gekennzeichnet, um unterschiedliche Zustände widerzuspiegeln: Grün zeigt neu hinzugefügte Knoten an, Blau zeigt zwischengespeicherte Knoten an, auf die zu diesem Zeitpunkt zugegriffen wurde, und Rot zeigt Knoten an, die entfernt wurden.
Frontend: LLM-Programmierung leicht gemacht mit SGLang
Auf dem Frontend schlägt die Forschung SGLang vor, eine in Python eingebettete domänenspezifische Sprache, die den Ausdruck fortgeschrittener Eingabeaufforderungstechniken, Kontrollfluss und Multimodalität ermöglicht , Dekodierung von Einschränkungen und externen Interaktionen. SGLang-Funktionen können über verschiedene Backends wie OpenAI, Anthropic, Gemini und native Modelle ausgeführt werden.
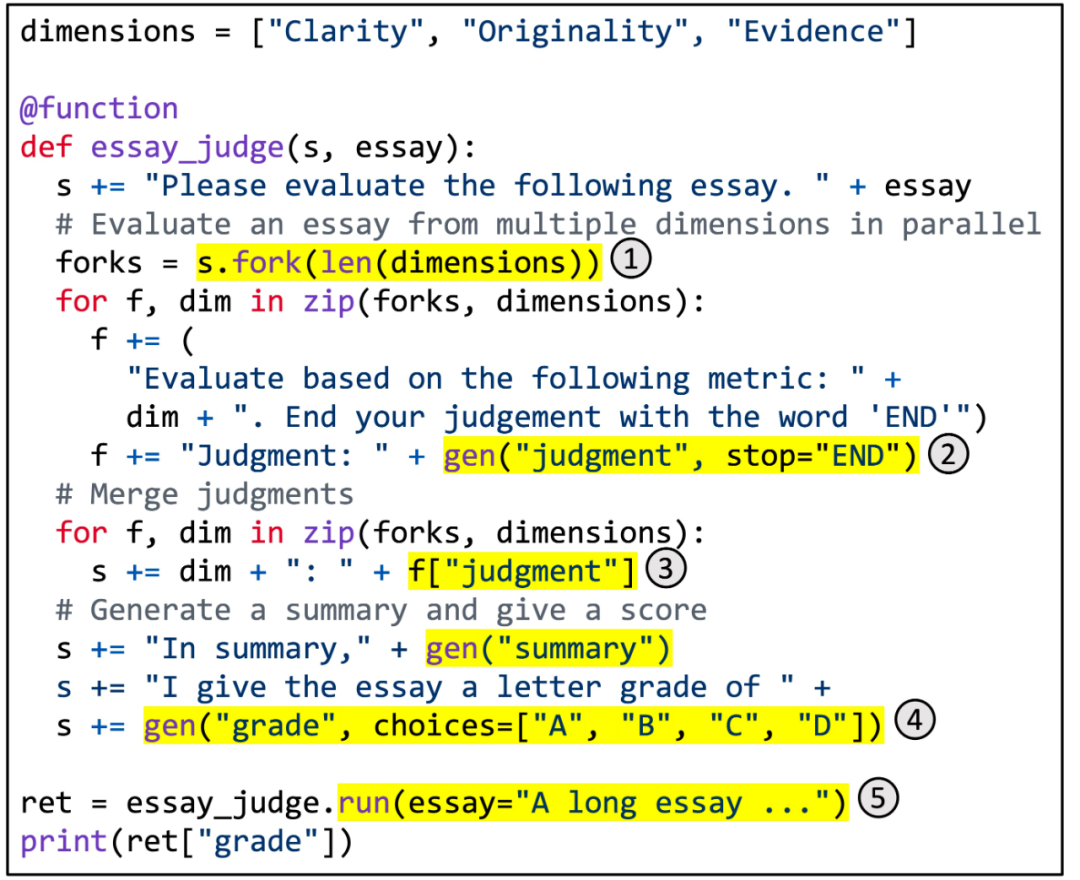
Abbildung 5. Verwendung von SGLang zur Implementierung der mehrdimensionalen Artikelbewertung.
Abbildung 5 zeigt ein konkretes Beispiel. Es nutzt die Branch-Resolve-Merge-Prompt-Technologie, um eine mehrdimensionale Artikelbewertung zu erreichen. Diese Funktion nutzt LLM, um die Qualität eines Artikels in mehreren Dimensionen zu bewerten, Beurteilungen zu kombinieren, eine Zusammenfassung zu erstellen und eine Abschlussnote zu vergeben. Der hervorgehobene Bereich veranschaulicht die Verwendung der SGLang-API. (1) Fork erstellt mehrere parallele Kopien der Eingabeaufforderung. (2) gen ruft die LLM-Generierung auf und speichert die Ergebnisse in Variablen. Dieser Aufruf ist nicht blockierend, sodass mehrere Build-Aufrufe gleichzeitig im Hintergrund ausgeführt werden können. (3) [Variablenname] ruft die generierten Ergebnisse ab. (4) Wählen Sie, ob Sie der Generierung Einschränkungen auferlegen möchten. (5) run führt die SGLang-Funktion unter Verwendung ihrer Parameter aus.
Bei einem solchen SGLang-Programm können wir es entweder über den Interpreter ausführen oder es als Datenflussdiagramm verfolgen und es mit einem Diagramm-Executor ausführen. Die letztere Situation eröffnet Raum für einige potenzielle Compiler-Optimierungen, wie z. B. Codeverschiebung, Befehlsauswahl und automatische Optimierung.
SGLangs Syntax ist stark von Guidance inspiriert und führt neue Grundelemente ein, die auch in-prozedurale Parallelität und Stapelverarbeitung verarbeiten. All diese neuen Funktionen tragen zur hervorragenden Leistung von SGLang bei.
Benchmarks
Das Forschungsteam testete sein System auf gängige LLM-Workloads und berichtete über den erreichten Durchsatz.
Konkret wurden in der Studie Llama-7B auf 1 NVIDIA A10G-GPU (24 GB), Mixtral-8x7B auf 8 NVIDIA A10G-GPUs mit Tensorparallelität und FP16-Genauigkeit sowie vllm v0.2.5, Guidance v0.1.8 und Hugging Face TGI v1 getestet .3.0 als Basissysteme.
Wie in Abbildung 1 und Abbildung 2 dargestellt, übertrifft SGLang das Basissystem in allen Benchmarks und erreicht eine 5-fache Steigerung des Durchsatzes. Auch im Hinblick auf die Latenz schneidet es gut ab, insbesondere bei der Latenz des ersten Tokens, wo Präfix-Cache-Treffer erhebliche Vorteile bringen können. Diese Verbesserungen sind auf die automatische KV-Cache-Wiederverwendung von RadixAttention, die durch den Interpreter ermöglichte programminterne Parallelität und das gemeinsame Design von Front-End- und Back-End-Systemen zurückzuführen. Darüber hinaus zeigen Ablationsstudien, dass kein nennenswerter Overhead entsteht, der dazu führt, dass RadixAttention zur Laufzeit immer aktiviert ist, auch wenn keine Cache-Treffer vorliegen.
Referenzlink: https://lmsys.org/blog/2024-01-17-sglang/
Das obige ist der detaillierte Inhalt vonDer Durchsatz wird um das Fünffache erhöht. Die LLM-Schnittstelle zum gemeinsamen Entwerfen des Back-End-Systems und der Front-End-Sprache ist vorhanden.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Im Entwicklungsprozess der künstlichen Intelligenz war die Steuerung und Führung großer Sprachmodelle (LLM) schon immer eine der zentralen Herausforderungen, um sicherzustellen, dass diese Modelle beides sind kraftvoll und sicher dienen der menschlichen Gesellschaft. Frühe Bemühungen konzentrierten sich auf Methoden des verstärkenden Lernens durch menschliches Feedback (RL
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Zeigen Sie LLM die Kausalkette und es lernt die Axiome. KI hilft Mathematikern und Wissenschaftlern bereits bei der Forschung. Beispielsweise hat der berühmte Mathematiker Terence Tao wiederholt seine Forschungs- und Forschungserfahrungen mit Hilfe von KI-Tools wie GPT geteilt. Damit KI in diesen Bereichen konkurrenzfähig sein kann, sind starke und zuverlässige Fähigkeiten zum kausalen Denken unerlässlich. Die in diesem Artikel vorgestellte Forschung ergab, dass ein Transformer-Modell, das auf die Demonstration des kausalen Transitivitätsaxioms für kleine Graphen trainiert wurde, auf das Transitivitätsaxiom für große Graphen verallgemeinern kann. Mit anderen Worten: Wenn der Transformer lernt, einfache kausale Überlegungen anzustellen, kann er für komplexere kausale Überlegungen verwendet werden. Der vom Team vorgeschlagene axiomatische Trainingsrahmen ist ein neues Paradigma zum Erlernen des kausalen Denkens auf der Grundlage passiver Daten, nur mit Demonstrationen
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
 LLM eignet sich wirklich nicht für die Vorhersage von Zeitreihen. Es nutzt nicht einmal seine Argumentationsfähigkeit.
Jul 15, 2024 pm 03:59 PM
LLM eignet sich wirklich nicht für die Vorhersage von Zeitreihen. Es nutzt nicht einmal seine Argumentationsfähigkeit.
Jul 15, 2024 pm 03:59 PM
Können Sprachmodelle wirklich zur Zeitreihenvorhersage verwendet werden? Gemäß Betteridges Gesetz der Schlagzeilen (jede Schlagzeile, die mit einem Fragezeichen endet, kann mit „Nein“ beantwortet werden) sollte die Antwort „Nein“ lauten. Die Tatsache scheint wahr zu sein: Ein so leistungsstarkes LLM kann mit Zeitreihendaten nicht gut umgehen. Zeitreihen, also Zeitreihen, beziehen sich, wie der Name schon sagt, auf eine Reihe von Datenpunktsequenzen, die in der Reihenfolge ihres Auftretens angeordnet sind. Die Zeitreihenanalyse ist in vielen Bereichen von entscheidender Bedeutung, einschließlich der Vorhersage der Ausbreitung von Krankheiten, Einzelhandelsanalysen, Gesundheitswesen und Finanzen. Im Bereich der Zeitreihenanalyse haben viele Forscher in letzter Zeit untersucht, wie man mithilfe großer Sprachmodelle (LLM) Anomalien in Zeitreihen klassifizieren, vorhersagen und erkennen kann. Diese Arbeiten gehen davon aus, dass Sprachmodelle, die gut mit sequentiellen Abhängigkeiten in Texten umgehen können, auch auf Zeitreihen verallgemeinert werden können.
