

Erstellen Sie ein ERP-System für Vertrieb und Service

Da die Datenmenge nicht groß war, war die Systemleistung zunächst recht gut und verschiedene Listenabfragen, Berichtsabfragen, Excel-Datenexportfunktionen usw. konnten reibungslos verwendet werden. Als sich jedoch das Geschäft des Unternehmens entwickelte und das Auftragsvolumen von Tag zu Tag wuchs und die Nachfrage nach Berichtsabfragen und Datenexporten aus verschiedenen Geschäftsabteilungen in der späteren Zeit immer weiter zunahm, hatten wir allmählich das Gefühl, dass das System immer langsamer lief. Die erste Lösung, die uns einfällt, ist also die Optimierung der Systemengpassdatenbank. Einer unserer möglichen Versuche besteht darin, die Datenbank separat auf einem Server zu platzieren, um die Datenbank und die Anwendung zu trennen, oder verschiedene Datenbanktabellenindizes einzurichten, Programmcode zu optimieren usw. Nach einer solchen Forschung und Optimierung kann die Leistung einiger Funktionen des Systems zwar erheblich verbessert werden, wir haben jedoch dennoch festgestellt, dass die Datenabfrage und der Export einiger Funktionslisten immer noch sehr langsam sind, oder wenn sich die Datenmenge weiter ansammelt Die ursprünglich schnellere Listenexportfunktion wurde auch immer langsamer. Wir haben verschiedene Methoden ausprobiert, aber am Ende konnten wir nicht die ideale Systemleistungsgeschwindigkeit erreichen.
Um die Systemleistung zu verbessern, ergreifen wir möglicherweise die Initiative, aus den technischen Erfahrungen einiger Internetunternehmen zu lernen, wie z. B. hohe Parallelität, hohe Leistung, Big Data, Lese-/Schreibtrennung und andere Lösungen, stellen jedoch fest, dass wir keine Möglichkeit haben anfangen. Wir gehen davon aus, dass die Geschäftsmerkmale des Systems unterschiedlich sind. Die Parallelität des ERP-Systems ist nicht hoch, was hauptsächlich auf die Komplexität des Geschäfts zurückzuführen ist. Der Kopplungsgrad verschiedener Unternehmen ist viel höher als der von Internetanwendungen, was die Aufteilung der Datenabfrage viel komplizierter macht Die Daten, die von einer Listenseite abgefragt werden, sind häufig erforderlich. Das Ergebnis kann durch Korrelation von 4 oder 5 Tabellen erhalten werden. Einige Berichte enthalten sogar noch mehr. In Verbindung mit der transaktionalen Natur verschiedener Geschäftsabläufe und den hohen Anforderungen an die Datenkonsistenz waren wir oft überrascht und konnten das System nicht weiter optimieren.
Einmal war ich aus dem einen oder anderen Grund frustriert und dachte, das ERP-System sei etwas ganz Besonderes und unheilbar, aber später. . .
Das glaube ich nicht mehr, es scheint eine neue Lösung zu geben O(∩_∩)O haha~
Bevor ich den konkreten Plan beschreibe, möchte ich zunächst meine Gedanken mitteilen. Zunächst denke ich, dass wir, bevor wir ein ERP-System aufbauen, über das heutige Internet-Denken verfügen müssen. Wir wollen kein einheitliches System mehr aufbauen. Wir müssen ein großes System in kleine Systeme aufteilen. Diese kleinen Systeme können dann über Systemschnittstellen miteinander kommunizieren. Dies bildet ein großes System, insbesondere das „verteilte“ und „serviceorientierte“ Internet-Denken. Lassen Sie das System ein System sein, das von Natur aus eine hohe Skalierbarkeit im Hinblick auf das Architekturdesign unterstützt.
Wie geht das? Insbesondere ist es notwendig, Auftragsverwaltung, Warenwirtschaft, Produktion und Beschaffung, Lagerverwaltung, Logistikverwaltung und Finanzverwaltung in ein Subsystem aufzuteilen. Diese Subsysteme können unabhängig voneinander entworfen und entwickelt werden, und die von verschiedenen anderen Subsystemen benötigten Datenschnittstellen können der Außenwelt zugänglich gemacht werden. Jedes Subsystem verfügt über eine separate Datenbank. Sogar diese Subsysteme können von verschiedenen Teams entwickelt und gewartet werden, die unterschiedliche technische Systeme und unterschiedliche Datenbanken verwenden. Anstatt sie wie bisher in dasselbe große und umfassende System, eine große und umfassende Datenbank, zu integrieren.
Was sind die Vorteile des neuen Architektursystems?
Das erste und wichtigste ist die Lösung des Systemleistungsproblems. In der Vergangenheit gab es nur eine Datenbankinstanz und eine Erweiterung auf mehrere Instanzen war nicht möglich, so dass bei eingeschränkter Leistung ein Lastausgleich durch Hinzufügen weiterer Datenbankinstanzen erreicht werden konnte. Manche Leute mögen sagen, dass eine Lösung zur Lese-/Schreibtrennung verwendet werden kann, aber aufgrund der Eigenschaften des ERP-Systems ist diese Lösung oft unrealistisch. Wenn Sie beispielsweise eine Inventur durchführen, können Sie die Inventur nicht aus der Lesebibliothek lesen und sie dann in die Schreibbibliothek schreiben. Da die Master-Slave-Replikation zeitkritisch ist, kann der geschriebene Bestand nicht sofort in die Slave-Datenbank geschrieben werden. Es gibt viele solcher Szenarien im ERP. Darüber hinaus ist die Schreibbibliothek nicht erweiterbar, es kann nur eine vorhanden sein. Die neue Designlösung besteht darin, die Schreibbibliothek zu trennen und jedes Subsystem über eine eigene Datenbank zu verfügen.
Zweitens ist die Aktualisierung sehr bequem und jedes Subsystem existiert als Hintergrund-Mikrodienst. Im Frontend gibt es ein eigenes Webprojekt, das im Hintergrund die Serviceschnittstellen dieser Subsysteme aufruft. Wenn bei diesem Design ein bestimmtes Geschäftssubsystem aktualisiert werden muss, kann es unabhängig aktualisiert werden. Im Gegensatz zur vorherigen Einzelprozessarchitektur erforderte ein kleines Update einen Neustart des gesamten Systems, was dazu führte, dass die Benutzersitzung verloren ging und sich der Benutzer erneut anmelden musste. Beim aktuellen Design tritt dieses Problem nicht auf.
Ansicht der physischen Systembereitstellung
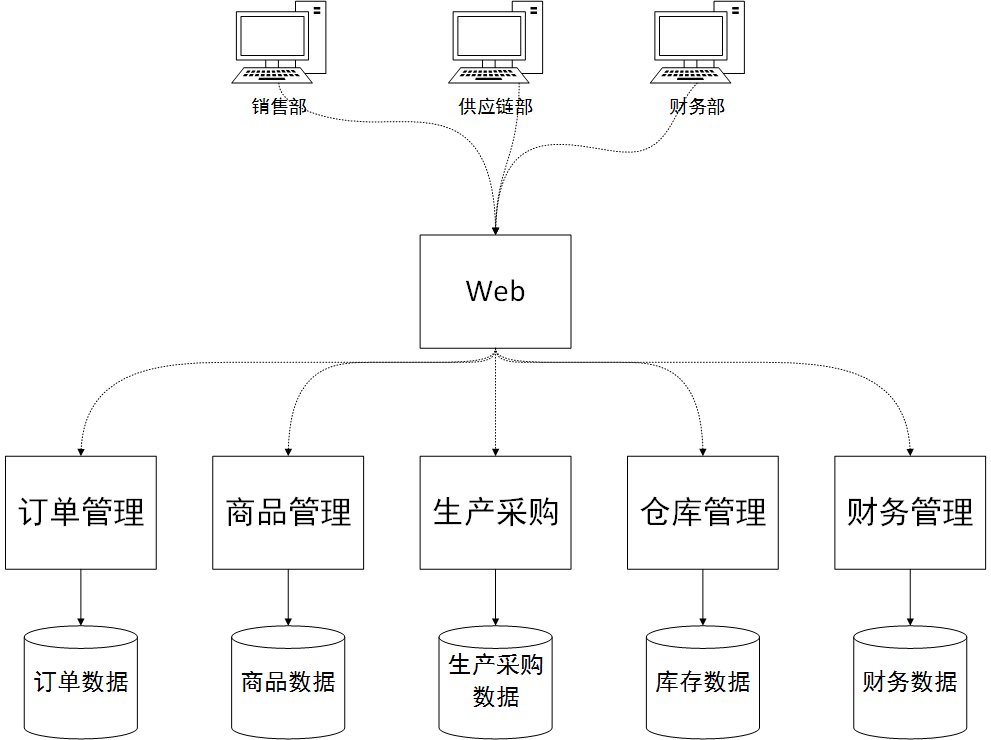
Die Aufteilung der Anwendungsschicht ist die Umsetzung des Konzepts der „Microservice“-Architektur. Teilen Sie die ursprüngliche große und umfassende Einzelprozessarchitektur entsprechend den Geschäftsmodulen in unabhängig einsetzbare Anwendungen auf, um reibungslose Systemaktualisierungen und -upgrades zu erreichen und die Lasterweiterung zu erleichtern. Genauer gesagt können Sie technisch gesehen eine Schnittstelle im Restfull-Stil verwenden oder ein Framework wie Dubbo in Java verwenden, um die Entwicklungskomplexität zu vereinfachen. Das ERP-Web oder ein anderes mobiles Endgerät ist ebenfalls eine separate Anwendung, die als Präsentationsebene fungiert. Es ist sehr dünn, es akzeptiert einfach Parameter und ruft im Hintergrund die Schnittstellen verschiedener anderer Microservice-Programme auf, um die anzuzeigenden Daten zu erhalten. Microservices fungieren als Geschäftslogikschicht. Jeder Microservice ist ein Programm, das unabhängig bereitgestellt werden kann und externe Datenzugriffsschnittstellen bereitstellt.
Microservices können verschiedene gängige RPC-Frameworks wie Dubbo verwenden, die mehrere Aufrufprotokolle wie HTTP, TCP usw. unterstützen können. Diese Frameworks erleichtern die Codierung. Das Framework kapselt die zugrunde liegenden Datenkommunikationsdetails und ermöglicht es dem Client, Remote-Methoden so auszuführen, als ob es so wäre waren lokale Methoden genauso einfach.
Die Dubbo-Microservice-Architektur unterstützt auch Service-Governance, Lastausgleich und andere Funktionen. Dies kann nicht nur die Verfügbarkeit des Systems verbessern, sondern auch die Leistung der Systemanwendungsschicht dynamisch verbessern. In der Lagerverwaltung ist das Lagergeschäft beispielsweise sehr ausgelastet und beansprucht viele CPU- und Speicherressourcen. Wir können eine weitere Maschine hinzufügen und einen separaten Lagerverwaltungsdienst bereitstellen. Dadurch können im gesamten System zwei Lagerverwaltungsdienste gleichzeitig arbeiten, um die Last auszugleichen. Und das alles geschieht automatisch im Service-Registrierungscenter, wie zum Beispiel Zookeeper.
Die Microservice-Struktur unterstützt natürlich Systemaktualisierungs- und Upgrade-Vorgänge. Wenn beispielsweise für das Finanzmodul eine neue Anforderung besteht und es online gehen muss, müssen wir nur den Dienst des Finanzmoduls ersetzen und neu starten. Für Benutzer, die sich bereits am System angemeldet haben, hat dies keine großen Auswirkungen. Sie müssen sich nicht erneut am System anmelden und die Nutzung anderer Moduldienste wird nicht beeinträchtigt.
Datenbankengpässe sind eine dauerhafte Schädigung des ERP-Systems. Eine große Menge komplexer Datenabfragetabellen-Verbindungslogik überschwemmt das gesamte System. Der Schlüssel zum Erfolg der vertikalen Datenbankaufteilung liegt in der Neugestaltung der gegenseitigen Kopplung verschiedener Module in der Systemdatenschicht. Wenn Sie dieses Problem lösen können, kann der bleibende Schaden behoben werden.
Sehen wir uns zunächst ein typisches Problem bei der Kopplung von Datenschichtmodulen an. Voraussetzung ist die Anzeige des Materialbestands, Listenfelder: Materialnummer, Materialname, Kategorie, Lager, Menge
Materialliste:
Inventartabelle:
Kategorie- und Lagertabellen entfallen. . .
Natürlich benötigen wir in einer herkömmlichen Datenbank nur eine einfache Verknüpfungsoperation, um diese beiden Tabellen zu verknüpfen und die Kategorie- und Warehouse-Tabellen zu verknüpfen, um die gewünschten Daten abzufragen. Aber jetzt befinden sich in unserer Architektur die Materialtabelle und die Produkttabelle nicht in derselben Datenbankinstanz und wir können die Verknüpfungsoperation nicht verwenden. Wie können wir die Anforderungen realisieren?
Die neue Architektur ermöglicht es uns nur, Daten über die Dienstschnittstelle der anderen Partei abzurufen und kann keine direkte Verbindung zur privaten Datenbank des Dienstes der anderen Partei herstellen. Zumindest aus architektonischer Sicht und aus serviceorientierter Sicht können Sie nicht direkt auf die Datenbank des Dienstes der anderen Partei zugreifen. In diesem Fall müssen wir unter der Annahme, dass das Webmodul-Subsystem das Warehouse-Subsystem aufruft, um Daten abzurufen, eine Servicemethode im Warehouse-Modul erstellen, um die Daten zusammenzustellen. Anschließend wird es an das Web-Subsystem zurückgegeben. Wie in der folgenden Abbildung dargestellt, ruft die Lagerverwaltungsmethode zunächst den Materialcode der lokalen Lagerbestandstabelle und die Lagernamensfeldinformationen der Lagerhaustabelle ab. Nach dem Paging ist sie schließlich bereit, 20 Daten an das Webmodul zurückzugeben. Die Material-ID in diesen 20 Datenteilen dient als Parameter zum Anfordern des Warenmodul-Subsystems. Das Waren-Subsystem gibt die Wareninformationen zu diesen 20 Material-IDs an das Lagerverwaltungsmodul zurück, und dann setzt das Lagerverwaltungsmodul die beiden Felddaten wieder zusammen des Materialnamens und der Kategorie, die in der oberen Liste erforderlich sind, um die endgültige Anforderung zu erfüllen. Daten, die an das Web-Subsystem zurückgegeben werden.
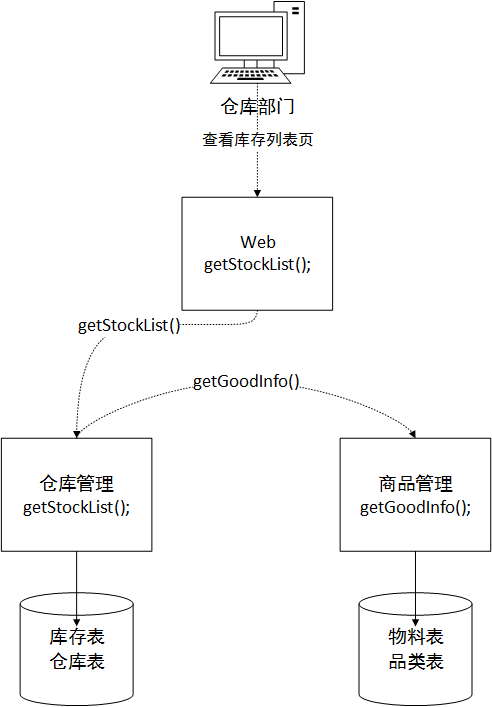
Vielleicht werden Sie sagen, dass die Leistung dieser Methode definitiv nicht so hoch ist wie die der direkten Verknüpfung und dass sie das Leistungsproblem nicht lösen kann. Dies scheint der Fall zu sein, aber wenn Sie sorgfältig darüber nachdenken, ist die Leistung in einer Umgebung mit geringer Systemparallelität, geringem Datenvolumen und geringer Auslastung des Unternehmens tatsächlich nicht so schnell wie bei der herkömmlichen Verknüpfung Methode in einem Daten. Aber denken wir später darüber nach! Unser aktuelles Architekturdesign besteht darin, eine Datenbank in mehrere Datenbanken aufzuteilen, und jede Datenbank kann auf einem separaten Server ausgeführt werden, sodass der Druck auf die Datenbank in Zukunft erhöht werden kann. Insgesamt wird dadurch verhindert, dass die Datenbank in Zukunft zu einem Leistungsengpass wird, wenn das Geschäft ausgelastet ist. Es ist aufregend, nur darüber nachzudenken, nicht wahr?
Zu diesem Zeitpunkt werden einige Leute erneut fragen: Was ist, wenn das Systemdatenvolumen und das Geschäft in Zukunft größer werden und selbst die Aufteilung in mehrere Datenbanken nicht ausreicht? Meine Methode basiert auf einer geteilten Datenbank, und jede Bibliothek kann Lesen und Schreiben trennen, Caching verwenden usw. Sie können das Subsystem sogar wieder in mehrere Subsysteme aufteilen. Es hängt davon ab, wie ausgelastet das Geschäftsmodul ist.
Einige Leute fragen sich vielleicht noch einmal: Einige Listenabfragelogiken sind sehr komplex und umfassen mehr als zehn Tabellen. Wenn die Daten gemäß der oben genannten Methode aufgeteilt werden, ist dies eine Katastrophe! Ja, du hast recht. In diesem Fall möchte ich diese komplexere Datenabfrage auf Berichtsebene verwenden, um die Anforderungen anzuzeigen, und ich kann ein separates Berichtssystem erstellen. Das Design der Berichtsdatenbank basiert auf einem Data-Warehouse-Ansatz. Für eine höhere Leseleistung können wir die Datenbanktabelle in viele redundante Felder entwerfen, was einem Anti-Paradigmen-Design entspricht, und viele kombinierte Indizes erstellen.
Der Schlüssel zum Erfolg dieses Systems ist die Synchronisierung von Daten und der Hauptgeschäftsbibliothek des ERP-Systems. Im Allgemeinen können Sie ein geplantes Synchronisierungsprogramm schreiben, um die für Berichtsansichten erforderlichen End- oder Zwischendaten durch Auswahl, Transformation usw. der Daten im ERP-Hauptgeschäftssystem direkt zu generieren und damit verbundene Abfragen zu vereinfachen. Das Reportingsystem kann auch mithilfe einer Microservice-Architektur gestaltet werden. Wie im Bild unten gezeigt:
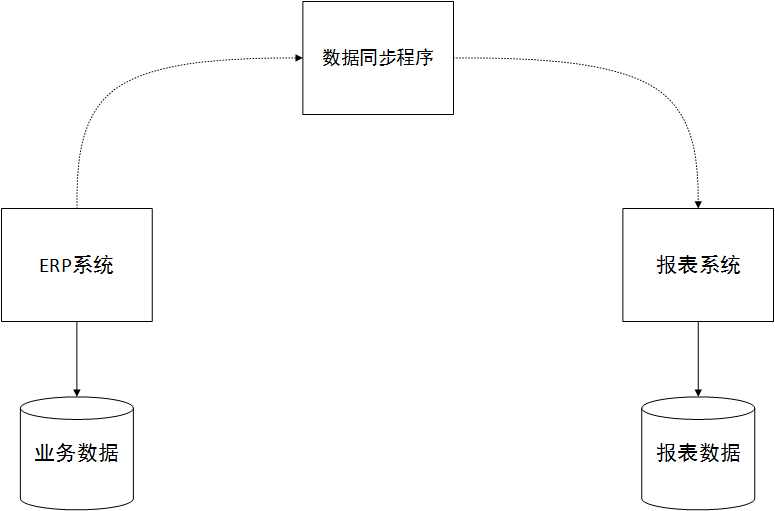
Wenn die für den Bericht erforderlichen Daten Echtzeit erfordern, können wir dem ERP-System erlauben, während des Geschäftsbetriebs eine Datensynchronisierungsanforderung auszulösen und diese in Echtzeit mit der Berichtsbibliothek zu synchronisieren.
Jemand fragt sich vielleicht noch einmal: Viele Vorgänge im ERP-System erfordern Transaktionalität und stellen die Datenkonsistenz nach der Aufteilung des Systems sicher.
Das ist eine gute Frage und es ist auch die letzte Frage, über die ich nachgedacht habe, bevor ich mich entschieden habe, diesen Artikel zu schreiben. In einer Microservice-Architektur ist es nicht einfach, Dienste zu implementieren, die über Dienste verfügen, die zumindest nicht so praktisch sind wie lokale Anwendungen, die lokale Datenbanktransaktionen verwenden, mit effizienter Leistung und guter Datenkonsistenz.
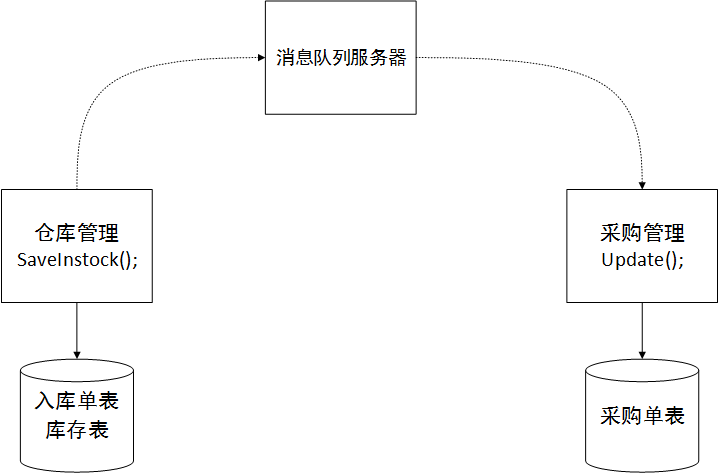
Vielleicht haben Sie vom Konzept verteilter Transaktionen gehört. Es gibt zwei Szenarien, in denen mehrere Datenbanken in einer Anwendung verwendet werden. Um die Datenkonsistenz sicherzustellen, müssen verteilte Transaktionen verwendet werden. Es gibt noch eine weitere Situation, die spezifisch für unsere Architektur ist. Insbesondere bei verteilten Transaktionen in einer Microservice-Umgebung wird eine Analogie verwendet. Der Betrieb des Einkaufs und der Lagerhaltung ist im Lagerverwaltungsdienst gestaltet. Nach der Lagerhaltung muss die Lagermenge in der Bestellung im Beschaffungssubsystem aktualisiert werden. Dieser Prozess erfordert Datenkonsistenz, d. h. die Menge in der Bestandstabelle wird in die Bestandstabelle geschrieben, nachdem die Bestellung erfolgreich in das Lager gestellt wurde, und die Menge in der Bestelltabelle muss gleichzeitig aktualisiert werden. Wir können nicht direkt auf die Datenbank im Beschaffungsdienst im Lagerdienst zugreifen. Wir müssen die vom Beschaffungsdienst bereitgestellte Serviceschnittstelle verwenden. Wenn ja, wie können wir die Datenkonsistenz sicherstellen? Denn es ist sehr wahrscheinlich, dass die Inventartabelle erfolgreich geschrieben wurde, der Aufruf an den Beschaffungsdienst zum Schreiben der Bestelldaten jedoch fehlschlägt. Möglicherweise liegen Netzwerkprobleme vor, sodass die Daten inkonsistent sind.
In der verteilten Transaktionstechnologie gibt es so etwas wie das Erreichen einer letztendlichen Konsistenz. Das heißt, solange ich sicherstellen kann, dass die Daten auf beiden Seiten konsistent sind, ist es nicht erforderlich, Transaktionen zu verwenden. Es gibt also einen Plan. Wenn das Lagersubsystem beispielsweise Einkäufe und Lagerhaltung verarbeitet, muss es Lagerauftragsdaten hinzufügen und Bestandsdaten und andere Tabellen aktualisieren. Diese mehreren Tabellen befinden sich alle im Warehouse-Subsystem, und wir können eine lokale Transaktion verwenden, um die Konsistenz der Tabellendaten im Warehouse-Subsystem sicherzustellen. Rufen Sie dann das Beschaffungssubsystem auf, um die Lagermenge in der Bestellung zu aktualisieren. Um zu verhindern, dass dieser Prozess plötzlich unterbrochen wird und der Aufruf fehlschlägt, erwägen wir das Hinzufügen einer Nachrichtenwarteschlangen-Middleware wie ActiveMQ. Wenn die Schnittstelle nicht zurückkehrt, schreiben wir die Verarbeitungsanforderung an MQ. Nachdem das Beschaffungssubsystem wieder normal ist, benachrichtigt MQ das Beschaffungssubsystem, um den Aktualisierungsvorgang zu verarbeiten. Da es nach der Verarbeitung der Nachricht keine weiteren Benachrichtigungen mehr gibt, ist während der Verarbeitung des Beschaffungssubsystems eine Ausnahme aufgetreten, die dazu geführt hat, dass die Aktualisierung fehlschlägt. Das Problem muss in die lokale Protokollbibliothek geschrieben werden, um den Administrator über eine spätere Entschädigung zu informieren wird bearbeitet. Auf diese Weise können verschiedene Methoden eingesetzt werden, um die endgültige Konsistenz der Daten zu erreichen. Auch wenn es etwas verwirrend klingt, ist dies die Lösung. Es gibt nichts Besseres. Oder rufen Sie das Lagersubsystem erneut auf, nachdem die Aktualisierung fehlgeschlagen ist, um die Lagereingangs- und Bestandsdaten zurückzusetzen und eine endgültige Konsistenz zu erreichen! Wie im Bild gezeigt:
Ich fühle mich sehr geehrt, Wissen und Erfahrungen mit allen teilen zu können. Durch den selbstlosen Austausch aller können wir in den letzten Jahren nur selten etwas teilen, manchmal weil ich bei der Arbeit sehr beschäftigt bin Zeit, etwas zu schreiben, manchmal liegt es daran, dass ich faul bin oder nichts Neues mitzuteilen habe. Abschließend hoffe ich, dass jeder meine Mängel beim Teilen kritisiert und korrigiert, damit wir gemeinsam Fortschritte machen können!
Das obige ist der detaillierte Inhalt vonErstellen Sie ein ERP-System für Vertrieb und Service. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
Die Schritte zum Starten von Apache sind wie folgt: Installieren Sie Apache (Befehl: sudo apt-Get-Get-Installieren Sie Apache2 oder laden Sie ihn von der offiziellen Website herunter). (Optional, Linux: sudo systemctl
 Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Wenn der Port -80 -Port der Apache 80 besetzt ist, lautet die Lösung wie folgt: Finden Sie den Prozess, der den Port einnimmt, und schließen Sie ihn. Überprüfen Sie die Firewall -Einstellungen, um sicherzustellen, dass Apache nicht blockiert ist. Wenn die obige Methode nicht funktioniert, konfigurieren Sie Apache bitte so, dass Sie einen anderen Port verwenden. Starten Sie den Apache -Dienst neu.
 So überwachen Sie die NGINX SSL -Leistung auf Debian
Apr 12, 2025 pm 10:18 PM
So überwachen Sie die NGINX SSL -Leistung auf Debian
Apr 12, 2025 pm 10:18 PM
In diesem Artikel wird beschrieben, wie die SSL -Leistung von NGINX -Servern auf Debian -Systemen effektiv überwacht wird. Wir werden Nginxexporter verwenden, um Nginx -Statusdaten in Prometheus zu exportieren und sie dann visuell über Grafana anzeigen. Schritt 1: Konfigurieren von Nginx Erstens müssen wir das Modul stub_status in der nginx -Konfigurationsdatei aktivieren, um die Statusinformationen von Nginx zu erhalten. Fügen Sie das folgende Snippet in Ihre Nginx -Konfigurationsdatei hinzu (normalerweise in /etc/nginx/nginx.conf oder deren inklusive Datei): location/nginx_status {stub_status
 So richten Sie im Debian -System einen Recyclingbehälter ein
Apr 12, 2025 pm 10:51 PM
So richten Sie im Debian -System einen Recyclingbehälter ein
Apr 12, 2025 pm 10:51 PM
In diesem Artikel werden zwei Methoden zur Konfiguration eines Recycling -Bin in einem Debian -System eingeführt: eine grafische Schnittstelle und eine Befehlszeile. Methode 1: Verwenden Sie die grafische Schnittstelle Nautilus, um den Dateimanager zu öffnen: Suchen und starten Sie den Nautilus -Dateimanager (normalerweise als "Datei") im Menü Desktop oder Anwendungen. Suchen Sie den Recycle Bin: Suchen Sie nach dem Ordner recycelner Behälter in der linken Navigationsleiste. Wenn es nicht gefunden wird, klicken Sie auf "Andere Speicherort" oder "Computer", um sie zu suchen. Konfigurieren Sie Recycle Bin-Eigenschaften: Klicken Sie mit der rechten Maustaste auf "Recycle Bin" und wählen Sie "Eigenschaften". Im Eigenschaftenfenster können Sie die folgenden Einstellungen einstellen: Maximale Größe: Begrenzen Sie den im Recycle -Behälter verfügbaren Speicherplatz. Aufbewahrungszeit: Legen Sie die Erhaltung fest, bevor die Datei automatisch im Recyclingbehälter gelöscht wird
 Die Bedeutung von Debian Sniffer für die Netzwerküberwachung
Apr 12, 2025 pm 11:03 PM
Die Bedeutung von Debian Sniffer für die Netzwerküberwachung
Apr 12, 2025 pm 11:03 PM
Obwohl in den Suchergebnissen "Debiansniffer" und ihre spezifische Anwendung bei der Netzwerküberwachung nicht direkt erwähnt werden, können wir schließen, dass sich "Sniffer" auf ein Tool für Netzwerkpaket -Capture -Analyse bezieht, und seine Anwendung im Debian -System unterscheidet sich nicht wesentlich von anderen Linux -Verteilungen. Die Netzwerküberwachung ist entscheidend für die Aufrechterhaltung der Netzwerkstabilität und die Optimierung der Leistung, und Tools für die Analyse der Paketerfassung spielen eine Schlüsselrolle. Im Folgenden werden die wichtige Rolle von Tools zur Netzwerküberwachung (z. B. in Debian-Systemen ausgeführt) erklärt: Der Wert von Netzwerküberwachungstools: Schneller Fehlerstandort: Echtzeitüberwachung von Netzwerkmetriken, wie z.
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 So starten Sie den Apache -Server neu
Apr 13, 2025 pm 01:12 PM
So starten Sie den Apache -Server neu
Apr 13, 2025 pm 01:12 PM
Befolgen Sie die folgenden Schritte, um den Apache -Server neu zu starten: Linux/MacOS: Führen Sie sudo systemCTL RESTART APache2 aus. Windows: Net Stop Apache2.4 und dann Net Start Apache2.4 ausführen. Führen Sie Netstat -a | Findstr 80, um den Serverstatus zu überprüfen.
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
