
 Technologie-Peripheriegeräte
KI
Die Tsinghua-Universität und das Harbin Institute of Technology haben große Modelle auf 1 Bit komprimiert, und der Wunsch, große Modelle auf Mobiltelefonen auszuführen, wird bald wahr!
Technologie-Peripheriegeräte
KI
Die Tsinghua-Universität und das Harbin Institute of Technology haben große Modelle auf 1 Bit komprimiert, und der Wunsch, große Modelle auf Mobiltelefonen auszuführen, wird bald wahr!
Die Tsinghua-Universität und das Harbin Institute of Technology haben große Modelle auf 1 Bit komprimiert, und der Wunsch, große Modelle auf Mobiltelefonen auszuführen, wird bald wahr!

Seitdem große Modelle in der Branche populär wurden, hat der Wunsch der Menschen, große Modelle zu komprimieren, nie nachgelassen. Denn obwohl große Modelle in vielerlei Hinsicht hervorragende Fähigkeiten aufweisen, erhöhen die hohen Bereitstellungskosten die Hemmschwelle für ihren Einsatz erheblich. Diese Kosten ergeben sich hauptsächlich aus der Raumbelegung und dem Berechnungsbetrag. „Modellquantisierung“ spart Platz, indem die Parameter großer Modelle in Darstellungen mit geringer Bitbreite umgewandelt werden. Derzeit können gängige Methoden vorhandene Modelle nahezu ohne Verlust der Modellleistung auf 4 Bit komprimieren. Allerdings ist eine Quantisierung unter 3 Bit wie eine unüberwindbare Mauer, die Forscher abschreckt.
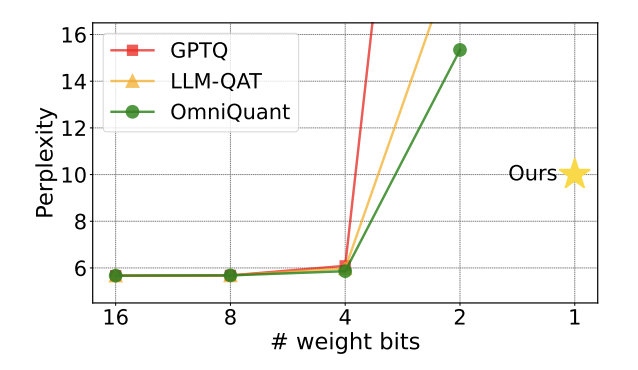
Abbildung 1: Die Verwirrung des quantitativen Modells steigt schnell um 2 Bits an
Kürzlich brachte ein gemeinsam von der Tsinghua-Universität und dem Harbin Institute of Technology auf arXiv veröffentlichter Artikel neue Ideen, um dieses Hindernis zu überwinden Hope hat in akademischen Kreisen im In- und Ausland große Aufmerksamkeit erregt. Dieses Papier wurde vor einer Woche auch als Hot Paper auf Huggingface gelistet und vom berühmten Paper Recommender AK empfohlen. Das Forschungsteam ging direkt über die 2-Bit-Quantifizierungsebene hinaus und versuchte mutig die 1-Bit-Quantifizierung, was das erste Mal in der Modellquantifizierungsforschung war.

Papiertitel: OneBit: Towards Extremely Low-bit Large Language Models
Papieradresse: https://arxiv.org/pdf/2402.11295.pdf
Die vom Autor vorgeschlagene Methode heißt „OneBit“ und beschreibt die Essenz dieser Arbeit sehr treffend: Komprimieren Sie das vorab trainierte große Modell auf ein echtes 1bit. Dieser Artikel schlägt eine neue Methode zur 1-Bit-Darstellung von Modellparametern sowie eine Initialisierungsmethode für quantisierte Modellparameter vor und migriert die Fähigkeiten hochpräziser vorab trainierter Modelle durch quantisierungsbewusstes Training auf 1-Bit-quantisierte Modelle ( QAT). Experimente zeigen, dass diese Methode die Modellparameter stark komprimieren kann und gleichzeitig eine Leistung von mindestens 83 % des LLaMA-Modells gewährleistet.
Der Autor wies darauf hin, dass bei der Komprimierung der Modellparameter auf 1 Bit die „Elementmultiplikation“ in der Matrixmultiplikation nicht mehr existiert und durch eine schnellere „Bitzuweisung“-Operation ersetzt wird, was die Berechnung erheblich verbessern wird Effizienz. Die Bedeutung dieser Forschung besteht darin, dass sie nicht nur die 2-Bit-Quantifizierungslücke schließt, sondern auch die Bereitstellung großer Modelle auf PCs und Smartphones ermöglicht.
Einschränkungen bestehender Arbeiten
Die Modellquantisierung erreicht hauptsächlich eine räumliche Komprimierung durch Konvertieren der nn.Linear-Schicht des Modells (mit Ausnahme der Einbettungsschicht und der Lm_head-Schicht) in eine Darstellung mit niedriger Genauigkeit. Die Grundlage früherer Arbeiten [1,2] ist die Verwendung der Round-To-Nearest (RTN)-Methode, um hochpräzise Gleitkommazahlen näherungsweise auf ein nahegelegenes ganzzahliges Gitter abzubilden. Dies kann als 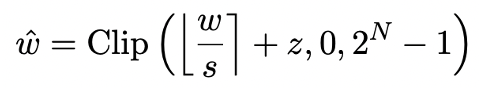 ausgedrückt werden.
ausgedrückt werden.
Allerdings weist die auf RTN basierende Methode bei extrem geringer Bitbreite (unter 3 Bit) ein ernstes Problem mit dem Genauigkeitsverlust auf, und der Verlust der Modellfähigkeit nach der Quantisierung ist sehr schwerwiegend. Insbesondere wenn die quantisierten Parameter in 1 Bit ausgedrückt werden, verlieren der Skalierungskoeffizient s und der Nullpunkt z in RTN ihre praktische Bedeutung. Dies führt dazu, dass die RTN-basierte Quantisierungsmethode bei 1-Bit-Quantisierung nahezu wirkungslos ist, was es schwierig macht, die Leistung des ursprünglichen Modells effektiv beizubehalten.
Darüber hinaus wurde in früheren Untersuchungen auch untersucht, welche Struktur das 1-Bit-Modell annehmen könnte. Die Arbeit von vor ein paar Monaten an BitNet [3] implementiert die 1-Bit-Darstellung, indem Modellparameter durch die Funktion Sign (・) übergeben und in + 1/-1 konvertiert werden. Diese Methode weist jedoch erhebliche Leistungseinbußen und einen instabilen Trainingsprozess auf, was ihre praktische Anwendung einschränkt.
OneBit Framework
Das Methoden-Framework von OneBit umfasst eine neue 1-Bit-Schichtstruktur, eine SVID-basierte Parameterinitialisierungsmethode und einen Wissenstransfer basierend auf einer quantisierungsbewussten Wissensdestillation.
1. Neue 1-Bit-Struktur
Das ultimative Ziel von OneBit ist es, die Gewichtsmatrix von LLMs auf 1 Bit zu komprimieren. Echtes 1-Bit erfordert, dass jeder Gewichtswert nur durch 1-Bit dargestellt werden kann, dh es gibt nur zwei mögliche Zustände. Der Autor ist der Ansicht, dass bei den Parametern großer Modelle zwei wichtige Faktoren berücksichtigt werden müssen, nämlich die hohe Präzision der Gleitkommazahlen und der hohe Rang der Parametermatrix.
Daher führt der Autor zwei Wertevektoren im FP16-Format ein, um den Genauigkeitsverlust aufgrund der Quantisierung auszugleichen. Dieses Design behält nicht nur den hohen Rang der ursprünglichen Gewichtsmatrix bei, sondern sorgt durch den Wertevektor auch für die erforderliche Gleitkomma-Präzision, was das Modelltraining und den Wissenstransfer erleichtert. Der Vergleich zwischen der Struktur der linearen 1-Bit-Schicht und der Struktur der hochpräzisen linearen FP16-Schicht ist wie folgt:
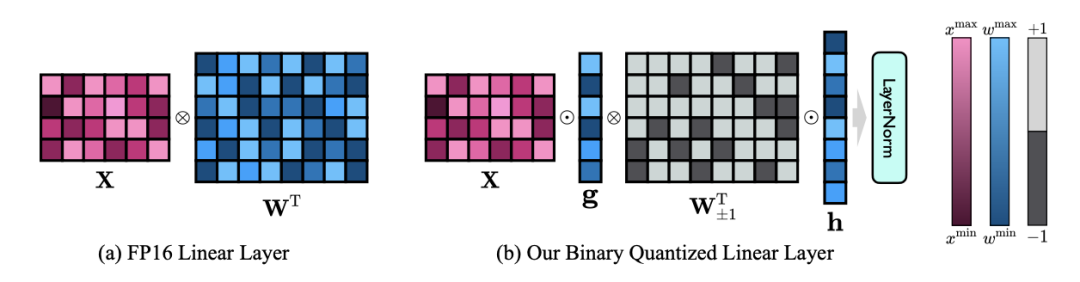
Abbildung 3: Vergleich zwischen der linearen FP16-Schicht und der linearen OneBit-Schicht
(a) auf Links ist die FP16-Präzisionsmodellstruktur, (b) rechts ist die lineare Schicht des OneBit-Frameworks. Es ist ersichtlich, dass im OneBit-Framework nur die Wertevektoren g und h im FP16-Format verbleiben, während die Gewichtsmatrix vollständig aus ±1 besteht. Eine solche Struktur berücksichtigt sowohl Genauigkeit als auch Rang und ist für die Gewährleistung eines stabilen und qualitativ hochwertigen Lernprozesses von großer Bedeutung.
Wie stark komprimiert OneBit das Modell? Der Autor gibt in der Arbeit eine Berechnung an. Unter der Annahme, dass eine 4096*4096 lineare Schicht komprimiert wird, benötigt OneBit eine 4096*4096 1-Bit-Matrix und zwei 4096*1 16-Bit-Wertvektoren. Die Gesamtzahl der Bits beträgt 16.908.288 und die Gesamtzahl der Parameter beträgt 16.785.408. Im Durchschnitt belegt jeder Parameter nur etwa 1,0073 Bits. Diese Art der Komprimierung ist beispiellos und man kann sagen, dass es sich um ein wirklich 1-Bit-großes Modell handelt.
2. Initialisieren Sie das quantisierte Modell basierend auf SVID
Um das vollständig trainierte Originalmodell zu verwenden, um das quantisierte Modell besser zu initialisieren und dadurch einen besseren Wissenstransfereffekt zu fördern, schlägt der Autor einen neuen Parameter vor: Die Matrix Die Faktorisierungsmethode wird als „wertzeichenunabhängige Matrixfaktorisierung (SVID)“ bezeichnet. Diese Matrixzerlegungsmethode trennt Symbole und absolute Werte und führt eine Rang-1-Approximation für absolute Werte durch. Die Methode zur Approximation der ursprünglichen Matrixparameter kann wie folgt ausgedrückt werden:
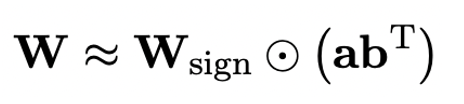
Die Rang-1-Approximation kann hier verwendet werden von Die übliche Matrixfaktorisierung ist implementiert, beispielsweise die Singularwertzerlegung (SVD) und die nichtnegative Matrixfaktorisierung (NMF). Anschließend zeigt der Autor mathematisch, dass diese SVID-Methode durch Austauschen der Operationsreihenfolge mit dem 1-Bit-Modellrahmen übereinstimmen und so eine Parameterinitialisierung erreichen kann. Darüber hinaus beweist die Arbeit auch, dass die symbolische Matrix während des Zerlegungsprozesses eine Rolle bei der Annäherung an die ursprüngliche Matrix spielt.
3. Migrieren Sie die Fähigkeiten des Originalmodells durch Wissensdestillation
Der Autor wies darauf hin, dass ein effektiver Weg zur Lösung der Quantisierung mit extrem niedriger Bitbreite großer Modelle das quantisierungsbewusste Training von QAT sein könnte. Im Rahmen der OneBit-Modellstruktur wird die Wissensdestillation verwendet, um aus dem unquantisierten Modell zu lernen und die Migration von Fähigkeiten zum quantisierten Modell zu realisieren. Insbesondere orientiert sich das Schülermodell hauptsächlich an den Logits und dem verborgenen Zustand des Lehrermodells. Beim Training werden die Werte des Wertevektors und der Wertematrix aktualisiert. Nachdem die Modellquantifizierung abgeschlossen ist, werden die Parameter nach Sign (・) direkt gespeichert und direkt während der Inferenz und Bereitstellung verwendet.
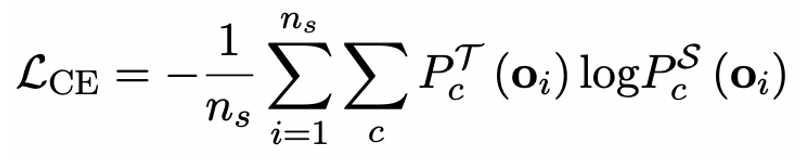 Experimente und Ergebnisse
Experimente und Ergebnisse
OneBit wurde mit FP16 Transformer, dem klassischen Post-Training-Quantisierungs-Stark-Baseline-GPTQ, dem quantisierungsbewussten Training-Stark-Baseline-LLM-QAT und dem neuesten 2-Bit-Gewichtsquantisierungs-Stark-Baseline-OmniQuant verglichen . Da es derzeit keine Forschung zur 1-Bit-Gewichtsquantisierung gibt, verwendet der Autor außerdem nur die 1-Bit-Gewichtsquantisierung für sein OneBit-Framework und übernimmt 2-Bit-Quantisierungseinstellungen für andere Methoden, was eine typische „Schwachstelle“ darstellt zu den Starken“.
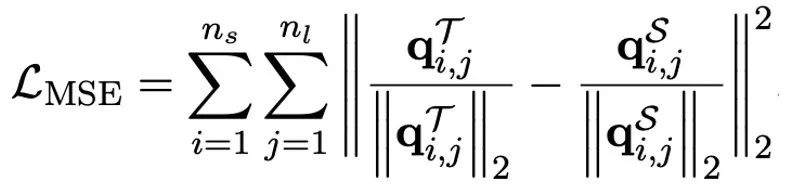
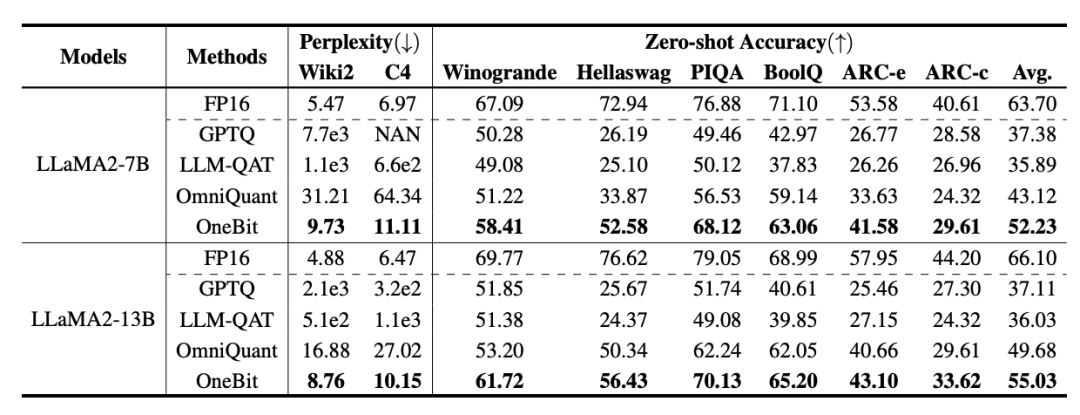
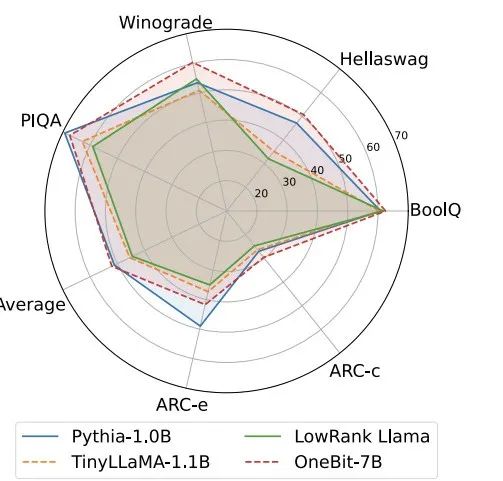
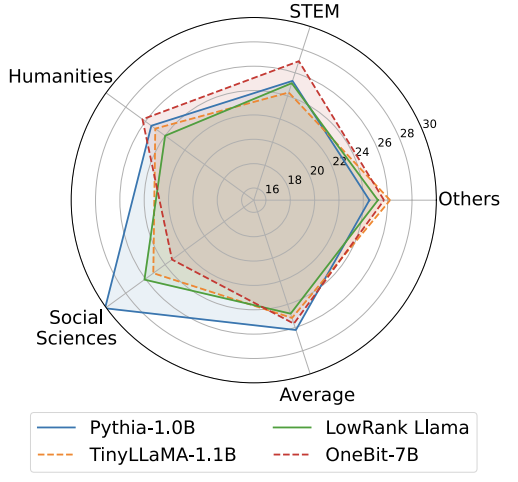
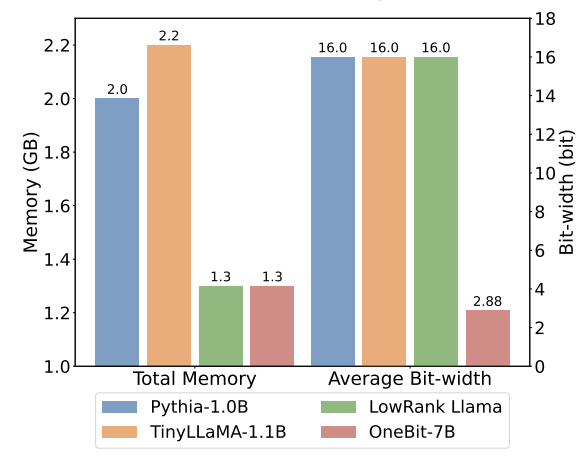
Tabelle 1: Vergleich der Wirkung von OneBit und der Basismethode (OPT-Modell und LLaMA-1-Modell) Tabelle 2: Vergleich der Wirkung von OneBit und der Basismethode (LLaMA- 2-Modell) Tabelle 1 und Tabelle 2 zeigen die Vorteile von OneBit im Vergleich zu anderen Methoden bei der 1-Bit-Quantisierung. In Bezug auf die Quantifizierung der Ratlosigkeit des Modells im Validierungssatz kommt OneBit dem FP16-Modell am nächsten. Bezüglich der Zero-Shot-Genauigkeit erzielte das OneBit-Quantisierungsmodell bis auf die einzelnen Datensätze des OPT-Modells nahezu die beste Leistung. Die verbleibenden 2-Bit-Quantisierungsverfahren zeigen größere Verluste bei beiden Bewertungsmetriken. Es ist erwähnenswert, dass OneBit tendenziell eine bessere Leistung erbringt, wenn das Modell größer ist. Das heißt, mit zunehmender Modellgröße hat das FP16-Präzisionsmodell kaum Auswirkungen auf die Reduzierung der Verwirrung, OneBit zeigt jedoch eine stärkere Reduzierung der Verwirrung. Darüber hinaus weisen die Autoren auch darauf hin, dass für die Quantisierung mit extrem niedriger Bitbreite möglicherweise ein quantisierungsbewusstes Training erforderlich ist. ? Abbildung 4 – Abbildung 6 vergleicht auch die Raumbelegung und den Leistungsverlust mehrerer Arten kleiner Modelle, die über verschiedene Kanäle erhalten werden: einschließlich der beiden vollständig trainierten Modelle Pythia-1.0B und TinyLLaMA-1.1B sowie über Low-Rank LowRank Llama und OneBit-7B erhalten durch Zerlegung. Es ist ersichtlich, dass OneBit-7B zwar die kleinste durchschnittliche Bitbreite aufweist und den kleinsten Platz einnimmt, in Bezug auf die Denkfähigkeit des gesunden Menschenverstandes jedoch immer noch besser ist als andere Modelle. Der Autor weist auch darauf hin, dass Modelle im Bereich der Sozialwissenschaften ernsthaftem Wissensvergessen ausgesetzt sind. Insgesamt beweist das OneBit-7B seinen praktischen Nutzen. Wie in Abbildung 7 dargestellt, demonstriert das OneBit-quantisierte LLaMA-7B-Modell nach der Feinabstimmung der Anweisungen eine reibungslose Textgenerierung. Abbildung 7: Fähigkeiten des LLaMA-7B-Modells quantifiziert durch das OneBit-Framework Diskussion und Analyse 1. Effizienz
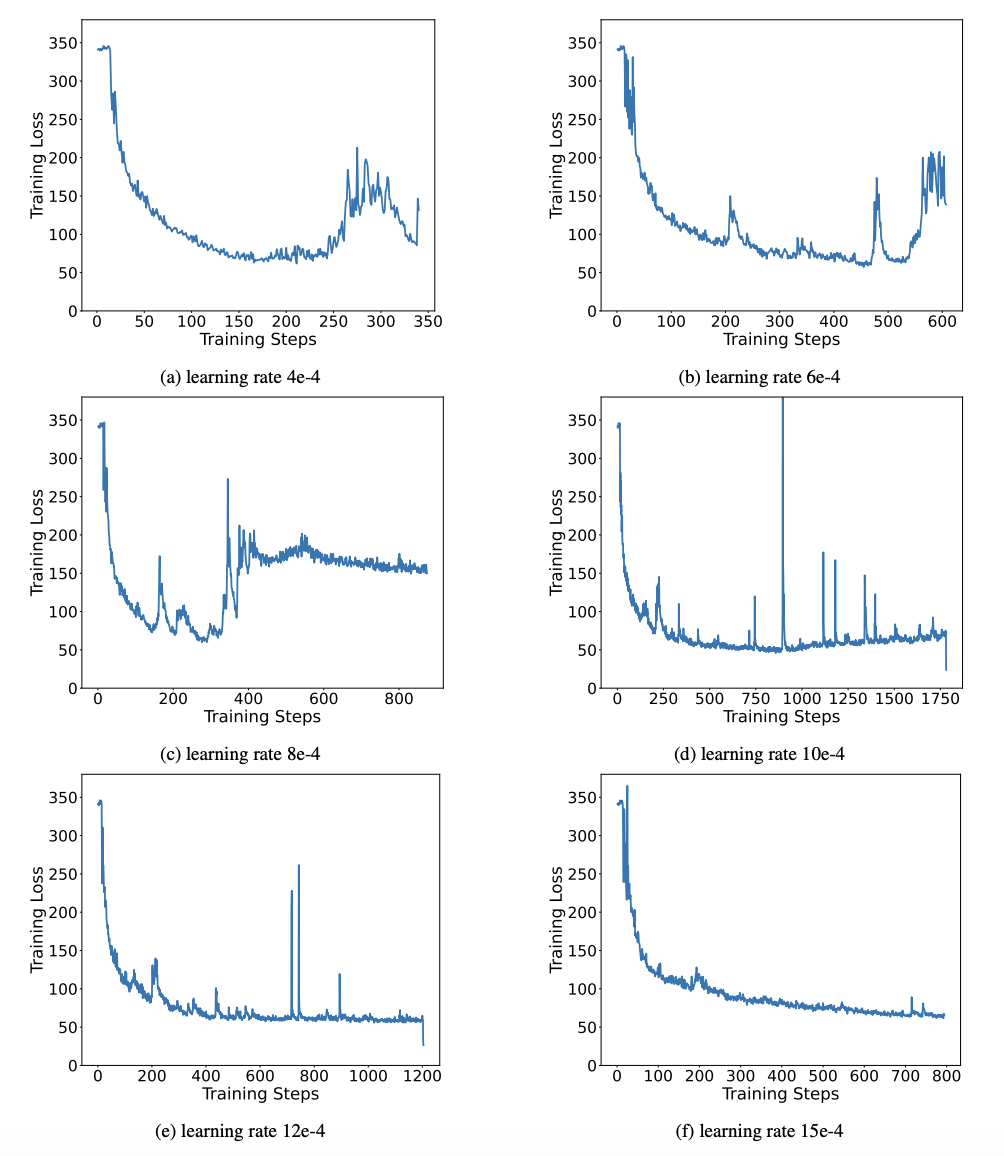
Tabelle 3 zeigt das Komprimierungsverhältnis von OneBit für LLaMA-Modelle unterschiedlicher Größe. Es ist ersichtlich, dass die Komprimierungsrate von OneBit für Modelle 90 % übersteigt, was beispiellos ist. Es ist zu beachten, dass mit zunehmendem Modell das Komprimierungsverhältnis von OneBit höher wird. Dies liegt daran, dass der Anteil der Parameter in der Einbettungsschicht, die nicht an der Quantisierung beteiligt sind, immer kleiner wird. Wie bereits erwähnt, ist der Leistungsgewinn durch OneBit umso größer, je größer das Modell ist, was den Vorteil von OneBit bei größeren Modellen zeigt. Abbildung 8: Kompromiss zwischen Modellgröße und Leistung . Die Autoren glauben, dass die Komprimierung der Modellgröße wichtig ist, insbesondere bei der Bereitstellung von Modellen auf mobilen Geräten. Darüber hinaus wies der Autor auch auf die rechnerischen Vorteile des 1-Bit-Quantisierungsmodells hin. Da die Parameter rein binär sind, können sie durch 0/1 in 1 Bit dargestellt werden, was zweifellos viel Platz spart. Die Elementmultiplikation der Matrixmultiplikation in hochpräzisen Modellen kann in effiziente Bitoperationen umgewandelt werden. Matrixprodukte können nur durch Bitzuweisungen und -additionen vervollständigt werden, was große Anwendungsaussichten bietet. 2. Robustheit Binäre Netzwerke stehen im Allgemeinen vor den Problemen eines instabilen Trainings und einer schwierigen Konvergenz. Dank des vom Autor eingeführten hochpräzisen Wertevektors sind sowohl die Vorwärtsberechnung als auch die Rückwärtsberechnung des Modelltrainings sehr stabil. BitNet hat früher eine 1-Bit-Modellstruktur vorgeschlagen, diese Struktur hat jedoch Schwierigkeiten, Fähigkeiten von vollständig trainierten hochpräzisen Modellen zu übertragen. Wie in Abbildung 9 dargestellt, hat der Autor verschiedene Lernraten ausprobiert, um die Transferlernfähigkeit von BitNet zu testen, und festgestellt, dass die Konvergenz unter Anleitung eines Lehrers schwierig ist, was auch den stabilen Trainingswert von OneBit beweist. Abbildung 9: Quantifizierungsfunktionen von BitNet nach dem Training bei verschiedenen Lernraten Am Ende des Papiers schlug der Autor auch mögliche zukünftige Forschungsrichtungen für extrem niedrige Bitbreiten vor. Finden Sie beispielsweise eine bessere Parameterinitialisierungsmethode, geringere Schulungskosten oder ziehen Sie die Quantisierung von Aktivierungswerten weiter in Betracht. Weitere technische Details finden Sie im Originalpapier. 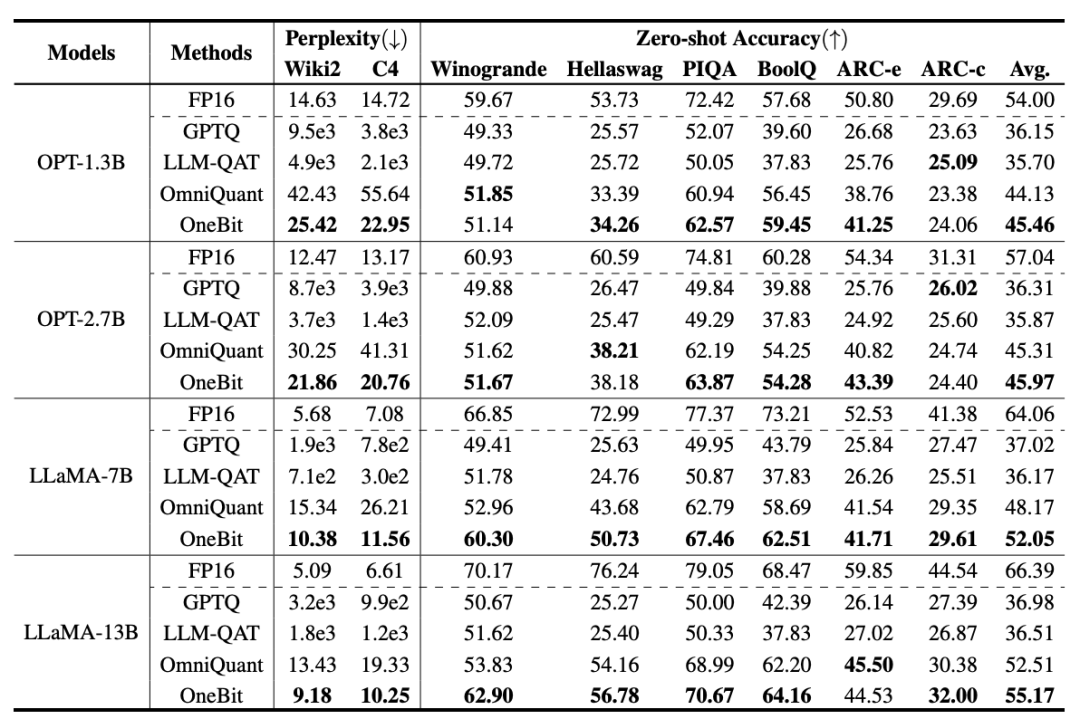

Das obige ist der detaillierte Inhalt vonDie Tsinghua-Universität und das Harbin Institute of Technology haben große Modelle auf 1 Bit komprimiert, und der Wunsch, große Modelle auf Mobiltelefonen auszuführen, wird bald wahr!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
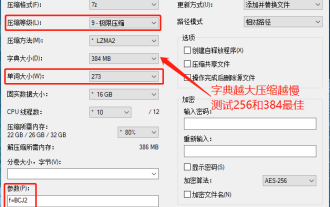 Einstellung der maximalen Komprimierungsrate von 7-zip, wie man 7zip auf das Minimum komprimiert
Jun 18, 2024 pm 06:12 PM
Einstellung der maximalen Komprimierungsrate von 7-zip, wie man 7zip auf das Minimum komprimiert
Jun 18, 2024 pm 06:12 PM
Ich habe festgestellt, dass das von einer bestimmten Download-Website heruntergeladene komprimierte Paket nach der Dekomprimierung größer ist als das ursprüngliche komprimierte Paket. Der Unterschied beträgt mehrere zehn KB und mehrere zehn MB. Wenn es auf eine Cloud-Festplatte oder einen kostenpflichtigen Speicherplatz hochgeladen wird, spielt es keine Rolle Wenn die Datei klein ist und viele Dateien vorhanden sind, erhöhen sich die Speicherkosten erheblich. Ich habe einige Recherchen dazu durchgeführt und kann bei Bedarf daraus lernen. Komprimierungsstufe: 9-extreme Komprimierung. Wörterbuchgröße: 256 oder 384. Je stärker das Wörterbuch komprimiert ist, desto langsamer ist der Unterschied in der Komprimierungsrate vor 256 MB. Nach 384 MB gibt es keinen Unterschied in der Komprimierungsrate Parameter: f=BCJ2, die Komprimierungsrate für Test- und Add-Parameter ist höher
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
In diesem Artikel wird das Problem der genauen Erkennung von Objekten aus verschiedenen Blickwinkeln (z. B. Perspektive und Vogelperspektive) beim autonomen Fahren untersucht, insbesondere wie die Transformation von Merkmalen aus der Perspektive (PV) in den Raum aus der Vogelperspektive (BEV) effektiv ist implementiert über das Modul Visual Transformation (VT). Bestehende Methoden lassen sich grob in zwei Strategien unterteilen: 2D-zu-3D- und 3D-zu-2D-Konvertierung. 2D-zu-3D-Methoden verbessern dichte 2D-Merkmale durch die Vorhersage von Tiefenwahrscheinlichkeiten, aber die inhärente Unsicherheit von Tiefenvorhersagen, insbesondere in entfernten Regionen, kann zu Ungenauigkeiten führen. Während 3D-zu-2D-Methoden normalerweise 3D-Abfragen verwenden, um 2D-Features abzutasten und die Aufmerksamkeitsgewichte der Korrespondenz zwischen 3D- und 2D-Features über einen Transformer zu lernen, erhöht sich die Rechen- und Bereitstellungszeit.
