
 Technologie-Peripheriegeräte
IT Industrie
Intel Open-Source-NPU-Beschleunigungsbibliothek, Core-Ultra-Prozessor AI-PC kann leichte, große Sprachmodelle ausführen
Technologie-Peripheriegeräte
IT Industrie
Intel Open-Source-NPU-Beschleunigungsbibliothek, Core-Ultra-Prozessor AI-PC kann leichte, große Sprachmodelle ausführen
Intel Open-Source-NPU-Beschleunigungsbibliothek, Core-Ultra-Prozessor AI-PC kann leichte, große Sprachmodelle ausführen

Laut Nachrichten vom 4. März hat Intel kürzlich seine NPU-Beschleunigungsbibliothek auf GitHub veröffentlicht. Dieser Schritt ermöglicht es KI-PCs, die mit Core-Ultra-Prozessoren ausgestattet sind, leichte, große Sprachmodelle wie TinyLlama und Gemma-2b reibungsloser auszuführen.

Die Core Ultra-Serie integriert zum ersten Mal die NPU-KI-Engine. Diese Engine kann einige leichte KI-Inferenzaufgaben bewältigen und mit der CPU und der GPU zusammenarbeiten, um die Anforderungen verschiedener KI-Anwendungen zu erfüllen.
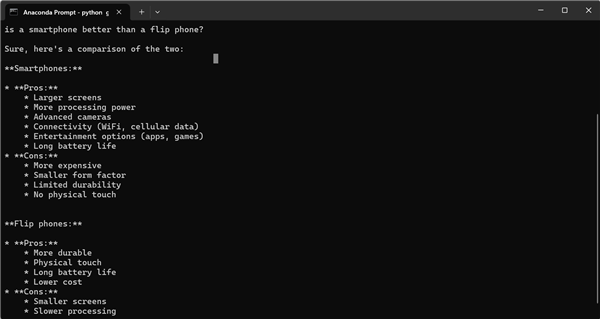
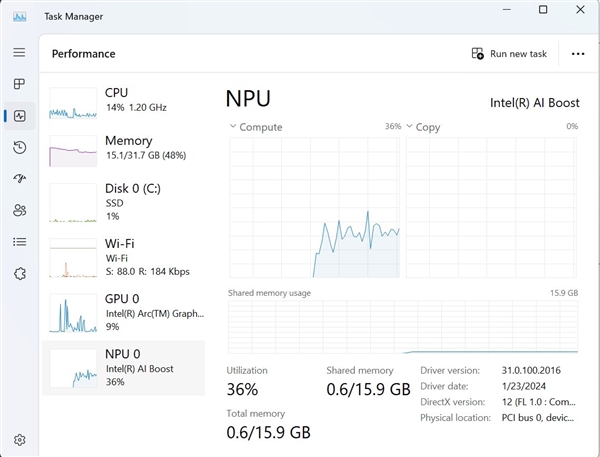
Es versteht sich, dass die diesmal veröffentlichte NPU-Beschleunigungsbibliothek zwar hauptsächlich für Entwickler gedacht ist, Benutzer mit gewisser Programmiererfahrung jedoch auch versuchen können, sie zu verwenden. Tony Mongkolsmai, ein Softwarearchitekt bei Intel, demonstrierte, wie man einen KI-Chatbot basierend auf dem 1,1 Milliarden Parameter umfassenden TinyLlama-Großmodell auf einem MSI Monarch 14 AI Evo-Laptop ausführt, der einfache Gespräche führen kann. Gleichzeitig zeigt der Windows Task-Manager auch gültige Aufrufe an die NPU an.
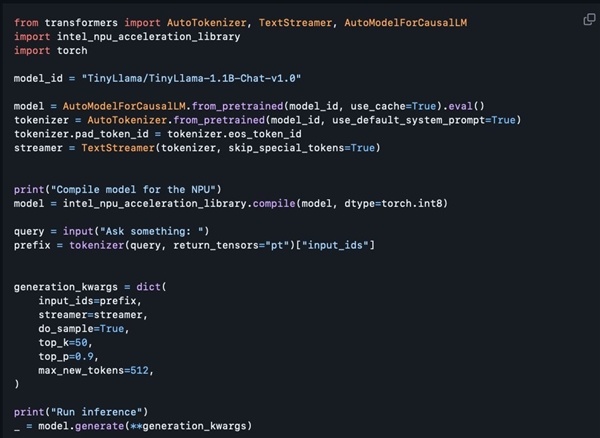
Die aktuelle Open-Source-NPU-Beschleunigungsbibliothek weist jedoch noch einige Funktionsmängel auf. Sie unterstützt 8-Bit-Quantisierung und FP16-Präzision, unterstützt jedoch noch keine erweiterten Funktionen wie 4-Bit-Quantisierung, BF16-Präzision und NPU /GPU-Hybrid-Computing und entsprechende technische Dokumentation wurden noch nicht bereitgestellt. Allerdings hat Intel versprochen, seine Funktionen in Zukunft schrittweise zu erweitern, wodurch die bestehenden Funktionen voraussichtlich verdoppelt werden, was den KI-Entwicklern zweifellos mehr Komfort und Möglichkeiten bringen wird.
Das obige ist der detaillierte Inhalt vonIntel Open-Source-NPU-Beschleunigungsbibliothek, Core-Ultra-Prozessor AI-PC kann leichte, große Sprachmodelle ausführen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Leak enthüllt wichtige Spezifikationen von Intel Arrow Lake-U, -H, -HX und -S
Jun 15, 2024 pm 09:49 PM
Leak enthüllt wichtige Spezifikationen von Intel Arrow Lake-U, -H, -HX und -S
Jun 15, 2024 pm 09:49 PM
Intel Arrow Lake wird voraussichtlich auf der gleichen Prozessorarchitektur wie Lunar Lake basieren, was bedeutet, dass Intels brandneue Lion Cove-Leistungskerne mit den wirtschaftlichen Skymont-Effizienzkernen kombiniert werden. Während Lunar Lake nur als Ava verfügbar ist
 Was ist Intel TXT?
Jun 11, 2023 pm 06:57 PM
Was ist Intel TXT?
Jun 11, 2023 pm 06:57 PM
IntelTXT ist eine von Intel eingeführte hardwaregestützte Sicherheitstechnologie, die die Integrität und Sicherheit des Servers während des Startvorgangs gewährleisten kann, indem ein geschützter Bereich zwischen CPU und BIOS eingerichtet wird. Der vollständige Name von TXT lautet TrustedExecutionTechnology, also Trusted Execution Technology. Einfach ausgedrückt handelt es sich bei TXT um eine Sicherheitstechnologie, die Schutz auf Hardwareebene bietet, um sicherzustellen, dass der Server beim Start nicht durch Schadprogramme oder nicht autorisierte Software verändert wurde. Dieses hier
 Beelink EQi12 kommt als leistungsstärkerer Mini-PC auf den Markt als der EQ12
Aug 21, 2024 pm 08:37 PM
Beelink EQi12 kommt als leistungsstärkerer Mini-PC auf den Markt als der EQ12
Aug 21, 2024 pm 08:37 PM
Beelink hat einen neuen Mini-PC auf den Markt gebracht, den EQi12. Es handelt sich um eine aktualisierte Version des EQ12, den die Marke letztes Jahr eingeführt hat und der mit dem Intel N100 geliefert wurde. Der neuere Computer kann mit bis zu Intel Core i7 12650H ausgestattet werden, einem der High-End-Chips
 LG stellt mit LG Gram 16 Pro Refresh den bisher dünnsten und leichtesten Intel Lunar Lake Laptop vor
Sep 10, 2024 am 06:44 AM
LG stellt mit LG Gram 16 Pro Refresh den bisher dünnsten und leichtesten Intel Lunar Lake Laptop vor
Sep 10, 2024 am 06:44 AM
LG bietet das Gram 16 Pro bereits mit Intel Meteor Lake-Prozessoren an (aktuell 1.699,99 $ bei Amazon). Allerdings hat sich das Unternehmen entschieden, die Meteor-Lake-Architektur von Intel durch Lunar Lake zu ersetzen, das Intel letzte Woche auf der IFA 2024 in Berlin vorgestellt hat. Th
 Intel Open-Source-NPU-Beschleunigungsbibliothek, Core-Ultra-Prozessor AI-PC kann leichte, große Sprachmodelle ausführen
Mar 05, 2024 am 11:13 AM
Intel Open-Source-NPU-Beschleunigungsbibliothek, Core-Ultra-Prozessor AI-PC kann leichte, große Sprachmodelle ausführen
Mar 05, 2024 am 11:13 AM
Laut Nachrichten vom 4. März hat Intel kürzlich seine NPU-Beschleunigungsbibliothek auf GitHub veröffentlicht. Dieser Schritt ermöglicht es AIPCs, die mit Core Ultra-Prozessoren ausgestattet sind, leichte, große Sprachmodelle wie TinyLlama und Gemma-2b reibungsloser auszuführen. Die Core Ultra-Serie integriert zum ersten Mal die NPUAI-Engine. Diese Engine kann einige leichte KI-Inferenzaufgaben bewältigen und mit der CPU und der GPU zusammenarbeiten, um die Anforderungen verschiedener KI-Anwendungen zu erfüllen. Es versteht sich, dass die dieses Mal veröffentlichte NPU-Beschleunigungsbibliothek zwar hauptsächlich für Entwickler gedacht ist, Benutzer mit gewisser Programmiererfahrung jedoch auch versuchen können, sie zu verwenden. Der Intel-Softwarearchitekt Tony Mongkolsmai zeigt, wie es geht
 Yoga Slim 7i Aura Edition: Lenovo unterbietet Samsung mit der neuen Version eines leichten Intel Lunar Lake-Laptops
Sep 11, 2024 am 06:41 AM
Yoga Slim 7i Aura Edition: Lenovo unterbietet Samsung mit der neuen Version eines leichten Intel Lunar Lake-Laptops
Sep 11, 2024 am 06:41 AM
Lenovo hat jetzt das Yoga Slim 7i Aura Edition herausgebracht, weniger als eine Woche nach der ersten Präsentation des Intel Lunar Lake-basierten Laptops. Bitte beachten Sie, dass das Unternehmen zwar auf der IFA 2024 in Berlin zahlreiche Details zum Laptop enthüllte, sich aber dafür entschieden hat
 Arc Battlemage: Leaks deuten auf drei GPUs für Intels Gaming-Grafikkarten der nächsten Generation hin
Jul 02, 2024 am 09:44 AM
Arc Battlemage: Leaks deuten auf drei GPUs für Intels Gaming-Grafikkarten der nächsten Generation hin
Jul 02, 2024 am 09:44 AM
Intels GPU-Architektur der nächsten Generation wird voraussichtlich im September als Teil von Intel Lunar Lake auf den Markt kommen. Wie die Arc Alchemist iGPU von Meteor Lake verfügt die iGPU über bis zu 8 Xe-Kerne, die neue Architektur soll jedoch eine um 50 % höhere Leistung erzielen
 IFA 2024 | Lenovo ThinkPad X1 Carbon Gen 13 Aura Edition: Lenovos erstes Lunar Lake ThinkPad, fast so leicht wie das X1 Nano
Sep 06, 2024 am 06:50 AM
IFA 2024 | Lenovo ThinkPad X1 Carbon Gen 13 Aura Edition: Lenovos erstes Lunar Lake ThinkPad, fast so leicht wie das X1 Nano
Sep 06, 2024 am 06:50 AM
Dreizehn ist bekanntermaßen ein schlimmer Mangel. Aberglaube ist im Technologiegeschäft jedoch keine Tugend. Für Lenovo dürfte die 13. Generation des Premium-Laptops genauso erfolgreich werden wie die zwölf Vorgänger. Auf der IFA, dem größten PC-Hersteller
