
 Technologie-Peripheriegeräte
KI
DeepMind CEO: LLM+Tree Search ist die AGI-Technologielinie für wissenschaftliche Forschung, die auf technischen Fähigkeiten basiert. Closed-Source-Modelle sind sicherer als Open-Source-Modelle.
Technologie-Peripheriegeräte
KI
DeepMind CEO: LLM+Tree Search ist die AGI-Technologielinie für wissenschaftliche Forschung, die auf technischen Fähigkeiten basiert. Closed-Source-Modelle sind sicherer als Open-Source-Modelle.
DeepMind CEO: LLM+Tree Search ist die AGI-Technologielinie für wissenschaftliche Forschung, die auf technischen Fähigkeiten basiert. Closed-Source-Modelle sind sicherer als Open-Source-Modelle.

Google wechselte nach Februar plötzlich in den 996-Modus und brachte in weniger als einem Monat fünf Modelle auf den Markt.
Und DeepMind-CEO Hassabis selbst hat auch für seine eigene Produktplattform geworben und viele Insiderinformationen hinter den Kulissen der Entwicklung preisgegeben.
Obwohl noch technologische Durchbrüche nötig sind, ist seiner Ansicht nach der Weg zur AGI für den Menschen jetzt geebnet.
Der Zusammenschluss von DeepMind und Google Brain markiert, dass die Entwicklung der KI-Technologie in eine neue Ära eingetreten ist.
F: DeepMind war schon immer an der Spitze der Technologie. In einem System wie AlphaZero kann der interne intelligente Agent beispielsweise das Endziel durch eine Reihe von Gedanken erreichen. Bedeutet das, dass auch große Sprachmodelle (LLM) in die Riege dieser Art von Forschung aufgenommen werden können?
Hassabis glaubt, dass großmaßstäbliche Modelle ein enormes Potenzial haben und weiter optimiert werden müssen, um ihre Vorhersagegenauigkeit zu verbessern und dadurch zuverlässigere Weltmodelle zu erstellen. Obwohl dieser Schritt von entscheidender Bedeutung ist, reicht er möglicherweise nicht aus, um ein vollständiges System der künstlichen allgemeinen Intelligenz (AGI) aufzubauen.
Auf dieser Basis entwickeln wir einen Planungsmechanismus ähnlich AlphaZero, um Pläne zur Erreichung spezifischer Weltziele durch das Weltmodell zu formulieren.
Dazu gehört das Aneinanderreihen verschiedener Denk- oder Argumentationsketten oder die Verwendung von Baumsuchen, um einen riesigen Raum an Möglichkeiten zu erkunden.
Das sind die fehlenden Glieder in unseren aktuellen Großmodellen.
F: Ist es möglich, ausgehend von reinen Reinforcement-Learning-Methoden (RL) direkt zu AGI überzugehen?
Es scheint, dass große Sprachmodelle das grundlegende Vorwissen bilden werden und dann auf dieser Grundlage weitere Forschungen durchgeführt werden können.
Theoretisch ist es möglich, die Methode zur Entwicklung von AlphaZero vollständig zu übernehmen.
Einige Leute in DeepMind und der RL-Community arbeiten in diese Richtung. Sie fangen bei Null an und verlassen sich nicht auf Vorkenntnisse oder Daten, um ein neues Wissenssystem aufzubauen.
Ich glaube, dass die Nutzung des vorhandenen Weltwissens – wie Informationen im Internet und Daten, die wir bereits sammeln – der schnellste Weg zur Erreichung von AGI sein wird.
Wir verfügen nun über skalierbare Algorithmen – Transformer – die diese Informationen aufnehmen können. Wir können diese vorhandenen Modelle vollständig als Vorwissen für Vorhersagen und Lernen nutzen.
Daher glaube ich, dass das endgültige AGI-System auf jeden Fall die heutigen großen Modelle als Teil der Lösung einbeziehen wird.
Aber ein großes Modell allein reicht nicht aus, wir müssen es auch um weitere Planungs- und Suchfunktionen erweitern.
F: Wie können wir angesichts der enormen Rechenressourcen, die diese Methoden erfordern, einen Durchbruch erzielen?
Sogar ein System wie AlphaGo ist ziemlich teuer, da Berechnungen für jeden Knoten des Entscheidungsbaums durchgeführt werden müssen.
Wir engagieren uns für die Entwicklung stichprobeneffizienter Methoden und Strategien zur Wiederverwendung vorhandener Daten, wie z. B. Experience Replay, sowie für die Erforschung effizienterer Methoden.
Tatsächlich kann Ihre Suche effizienter sein, wenn das Weltmodell gut genug ist.
Nehmen Sie Alpha Zero als Beispiel. Seine Leistung in Spielen wie Go und Schach übertrifft das Weltmeisterschaftsniveau, aber sein Suchbereich ist viel kleiner als bei herkömmlichen Brute-Force-Suchmethoden.
Dies zeigt, dass eine Verbesserung des Modells die Suche effizienter machen und so weitere Ziele erreichen kann.
Aber bei der Definition der Belohnungsfunktion und des Belohnungsziels wird es eine der Herausforderungen sein, vor denen wir stehen, wie wir sicherstellen können, dass sich das System in die richtige Richtung entwickelt.
Warum kann Google in einem halben Monat 5 Modelle produzieren?
F: Können Sie uns erklären, warum Google und DeepMind gleichzeitig an so vielen verschiedenen Modellen arbeiten?
Da wir Grundlagenforschung betreiben, verfügen wir über eine große Menge an Grundlagenforschungsarbeiten, die eine Vielzahl unterschiedlicher Innovationen und Richtungen abdecken.
Das bedeutet, dass während wir die Hauptmodellstrecke – das Kernmodell von Gemini – aufbauen, auch viele weitere Erkundungsprojekte im Gange sind.
Wenn diese Explorationsprojekte einige Ergebnisse haben, werden wir sie im Hauptzweig der nächsten Version von Gemini zusammenführen, weshalb 1.5 unmittelbar nach 1.0 veröffentlicht wird, da wir bereits an der nächsten Version arbeiten. Ja, Da wir mehrere Teams haben, die in unterschiedlichen Zeiträumen arbeiten und abwechselnd arbeiten, können wir auf diese Weise weiterhin Fortschritte machen.
Ich hoffe, dass dies unsere neue Normalität wird und wir Produkte mit dieser hohen Geschwindigkeit auf den Markt bringen, aber natürlich gehen wir auch sehr verantwortungsbewusst vor und bedenken, dass die Veröffentlichung sicherer Modelle für uns oberste Priorität hat.
F: Ich wollte nach Ihrer neuesten großen Veröffentlichung, Gemini 1.5 Pro, fragen. Ihr neues Gemini Pro 1.5-Modell kann bis zu einer Million Token verarbeiten. Können Sie erklären, was das bedeutet und warum das Kontextfenster ein wichtiger technischer Indikator ist?
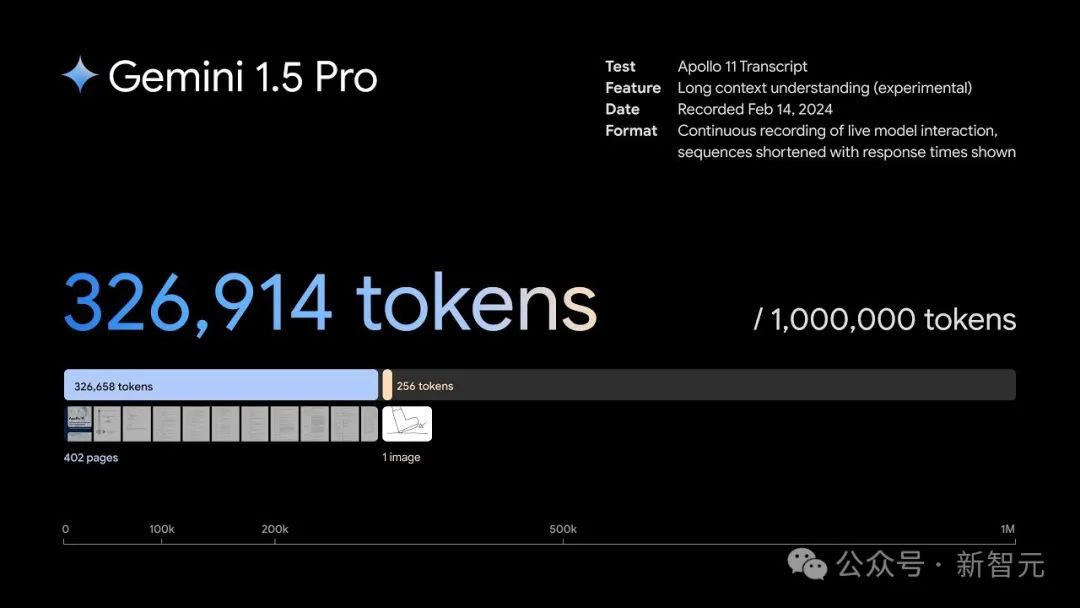
Ja, das ist sehr wichtig. Der lange Kontext kann als Arbeitsgedächtnis des Modells betrachtet werden, d. h. wie viele Daten es sich gleichzeitig merken und verarbeiten kann.
Je länger der Kontext ist, dessen Genauigkeit ebenfalls wichtig ist. Die Genauigkeit beim Abrufen von Dingen aus dem langen Kontext ist ebenfalls wichtig. Je mehr Daten und Kontext Sie berücksichtigen können.
Eine Million bedeutet also, dass Sie mit riesigen Büchern, ganzen Filmen, Tonnen von Audioinhalten und vollständigen Codebasen umgehen können.
Wenn Sie ein kürzeres Kontextfenster haben, sagen wir nur einhunderttausend Ebenen, dann können Sie nur Fragmente davon verarbeiten, und das Modell kann nicht den gesamten Korpus, an dem Sie interessiert sind, begründen oder abrufen.
Das eröffnet also tatsächlich Möglichkeiten für alle Arten neuer Anwendungsfälle, die mit kleinen Kontexten nicht möglich sind.
F: Ich habe von KI-Forschern gehört, dass das Problem mit diesen großen Kontextfenstern darin besteht, dass sie sehr rechenintensiv sind. Wenn Sie beispielsweise einen ganzen Film oder ein Biologielehrbuch hochladen und Fragen dazu stellen würden, wäre mehr Rechenleistung erforderlich, um all diese Informationen zu verarbeiten und zu beantworten. Wenn das viele machen, können sich die Kosten schnell summieren. Hat sich Google DeepMind eine clevere Innovation einfallen lassen, um diese riesigen Kontextfenster effizienter zu machen, oder hat Google nur die Kosten für all diese zusätzlichen Berechnungen getragen?
Ja, das ist eine völlig neue Innovation, denn ohne Innovation kann man keinen so langen Kontext haben.
Da dies jedoch immer noch einen hohen Rechenaufwand erfordert, arbeiten wir hart daran, es zu optimieren.
Wenn Sie das gesamte Kontextfenster ausfüllen. Die erstmalige Verarbeitung der hochgeladenen Daten kann mehrere Minuten dauern.
Aber es ist nicht so schlimm, wenn man bedenkt, dass es so ist, als würde man in ein oder zwei Minuten einen ganzen Film ansehen oder „Krieg und Frieden“ vollständig lesen und dann alle Fragen dazu beantworten können.
Dann möchten wir sicherstellen, dass nach dem Hochladen und Bearbeiten eines Dokuments, Videos oder Audios schneller weitere Fragen und Antworten gestellt werden.
Daran arbeiten wir derzeit und wir sind sehr zuversichtlich, dass wir es auf eine Frage von Sekunden bringen können.
F: Sie sagten, Sie hätten das System mit bis zu 10 Millionen Token getestet.
Hat in unseren Tests wirklich gut funktioniert. Da der Rechenaufwand noch relativ hoch ist, ist der Dienst derzeit nicht verfügbar.
Aber in Bezug auf Genauigkeit und Erinnerung schneidet es sehr gut ab.
F: Ich möchte Sie zu Gemini fragen. Welche besonderen Dinge können Gemini, die frühere Google-Sprachmodelle oder andere Modelle nicht konnten?
Nun, ich denke, das Spannende an Gemini, insbesondere an Version 1.5, ist, dass es von Natur aus multimodal ist und wir es von Grund auf so entwickelt haben, dass es jede Art von Eingabe verarbeiten kann: Text, Bilder, Code, Video.
Wenn Sie es mit einem langen Kontext kombinieren, können Sie sein Potenzial erkennen. Sie können sich zum Beispiel vorstellen, dass Sie sich eine ganze Vorlesung anhören oder dass Sie ein wichtiges Konzept verstehen möchten und schnell dorthin vorspulen möchten.
Jetzt können wir also die gesamte Codebasis in ein Kontextfenster einfügen, was für neue Programmierer, die gerade anfangen, sehr nützlich ist. Nehmen wir an, Sie sind ein neuer Ingenieur, der am Montag mit der Arbeit beginnt. Normalerweise müssen Sie sich Hunderttausende Zeilen Code ansehen.
Sie müssen die Experten zur Codebasis fragen. Aber jetzt können Sie Gemini auf diese unterhaltsame Weise tatsächlich als Codierungsassistenten verwenden. Es wird eine Zusammenfassung zurückgegeben, die Ihnen sagt, wo sich die wichtigen Teile des Codes befinden, und Sie können mit der Arbeit beginnen.
Ich denke, diese Fähigkeit ist sehr hilfreich und macht Ihren täglichen Arbeitsablauf effizienter.
Ich freue mich wirklich darauf zu sehen, wie sich Gemini schlägt, wenn es in etwas wie Slack und Ihren allgemeinen Arbeitsablauf integriert wird. Wie wird der Workflow der Zukunft aussehen? Ich denke, wir fangen gerade erst an, die Veränderungen zu erleben.
Googles oberste Priorität für Open Source ist Sicherheit
F: Ich möchte mich jetzt Gemma zuwenden, einer Reihe leichter Open-Source-Modelle, die Sie gerade veröffentlicht haben. Heutzutage scheint die Frage, ob zugrunde liegende Modelle über Open Source veröffentlicht oder geschlossen bleiben sollen, eines der umstrittensten Themen zu sein. Bisher hat Google sein zugrunde liegendes Modell Closed Source beibehalten. Warum jetzt Open Source wählen? Was halten Sie von der Kritik, dass die Bereitstellung zugrunde liegender Modelle über Open Source das Risiko und die Wahrscheinlichkeit erhöht, dass sie von böswilligen Akteuren genutzt werden?
Ja, ich habe dieses Thema tatsächlich schon oft öffentlich diskutiert.
Eines der Hauptanliegen ist, dass Open Source und Open Research im Allgemeinen eindeutig von Vorteil sind. Aber hier gibt es ein spezifisches Problem, und das hängt mit AGI- und KI-Technologien zusammen, weil sie universell sind.
Sobald Sie sie veröffentlichen, können böswillige Akteure sie für schädliche Zwecke verwenden.
Natürlich haben Sie, sobald Sie etwas als Open-Source-Lösung geöffnet haben, keine wirkliche Möglichkeit, es zurückzugewinnen, im Gegensatz zu Dingen wie dem API-Zugriff, den Sie einfach sperren können, wenn Sie feststellen, dass es nachgelagerte schädliche Anwendungsfälle gibt, an die noch niemand gedacht hat . Zugang.
Ich denke, das bedeutet, dass die Messlatte für Sicherheit, Robustheit und Verantwortlichkeit noch höher liegt. Je näher wir AGIs kommen, desto leistungsfähiger werden sie. Wir müssen daher vorsichtiger sein, wofür sie von böswilligen Akteuren verwendet werden könnten.
Ich habe noch kein gutes Argument von denen gehört, die Open Source unterstützen, wie zum Beispiel die Open-Source-Extremisten, von denen viele meine angesehenen Kollegen in der Wissenschaft sind, wie sie diese Frage beantworten – im Einklang mit der Verhinderung von Open-Source-Modellen mehr böswilligen Akteuren Zugriff auf das Modell gewähren?
Wir müssen mehr über diese Probleme nachdenken, da diese Systeme immer leistungsfähiger werden.
F: Warum hat Gemma Sie wegen dieses Problems nicht beunruhigt?

Ja natürlich, wie Sie feststellen werden, bietet Gemma nur leichte Versionen an, die also relativ klein sind.
Tatsächlich ist die kleinere Größe für Entwickler nützlicher, da normalerweise einzelne Entwickler, Akademiker oder kleine Teams schnell an ihren Laptops arbeiten möchten und daher dafür optimiert sind.
Da es sich nicht um Spitzenmodelle, sondern um kleine Modelle handelt, sind wir beruhigt, dass mit einem Modell keine großen Risiken verbunden sind, da die Fähigkeiten dieser Modelle gründlich getestet wurden und wir sehr gut wissen, wozu sie fähig sind dieser Größe.
Warum DeepMind mit Google Brain fusioniert
F: Letztes Jahr, als Google Brain und DeepMind fusionierten, waren einige Leute, die ich aus der KI-Branche kenne, besorgt. Sie befürchten, dass Google DeepMind in der Vergangenheit beträchtlichen Spielraum für die Arbeit an verschiedenen Forschungsprojekten eingeräumt hat, die das Unternehmen für wichtig hält.
Mit der Fusion muss DeepMind möglicherweise auf Dinge umgelenkt werden, die kurzfristig für Google von Nutzen sind, und nicht auf diese längerfristigen Grundlagenforschungsprojekte. Seit der Fusion ist ein Jahr vergangen. Hat diese Spannung zwischen kurzfristigem Interesse an Google und möglichen langfristigen KI-Fortschritten Ihre Arbeitsmöglichkeiten verändert?
Ja, dieses erste Jahr war alles großartig, wie du erwähnt hast. Ein Grund dafür ist, dass wir denken, dass jetzt der richtige Zeitpunkt ist, und ich denke, dass es aus Forschersicht der richtige Zeitpunkt ist.
Vielleicht gehen wir fünf oder sechs Jahre zurück, als wir Dinge wie AlphaGo machten, im KI-Bereich haben wir explorativ untersucht, wie wir zu AGI gelangen, welche Durchbrüche erforderlich sind, worauf man setzen sollte usw Es gibt ein breites Spektrum an Dingen, die man tun möchte. Ich denke, das ist eine sehr explorative Phase.
Ich denke, in den letzten zwei, drei Jahren ist klar geworden, was die Hauptbestandteile von AGI sein werden, wie ich bereits erwähnt habe, obwohl wir immer noch neue Innovationen brauchen.

Ich denke, Sie haben gerade den langen Kontext von Gemini1.5 gesehen, und ich denke, dass viele neue Innovationen wie diese erforderlich sein werden, daher ist Grundlagenforschung immer noch so wichtig wie eh und je.
Aber jetzt müssen wir auch hart in die technische Richtung arbeiten, das heißt, bekannte Technologien erweitern und nutzen und sie an ihre Grenzen bringen. Dies erfordert sehr kreatives Engineering im Maßstab, von der Hardware auf Prototypenebene bis hin zum Rechenzentrumsmaßstab. und die damit verbundenen Effizienzprobleme.
Ein weiterer Grund ist, dass man, wenn man vor fünf oder sechs Jahren KI-gesteuerte Produkte herstellen würde, eine KI hätte entwickeln müssen, die sich völlig von der AGI-Forschungsstrecke unterschied.
Es kann nur Aufgaben in speziellen Szenarien für bestimmte Produkte ausführen. Es handelt sich um eine Art maßgeschneiderte KI, „handgemachte KI“.
Aber heute ist alles anders. Um KI für Produkte einzusetzen, ist es jetzt am besten, allgemeine KI-Technologien und -Systeme zu nutzen, da diese ein ausreichendes Maß an Komplexität und Leistungsfähigkeit erreicht haben.
Das ist also tatsächlich ein Konvergenzpunkt, sodass Sie jetzt sehen können, dass der Forschungs-Track und der Produkt-Track zusammengeführt wurden.
Zum Beispiel werden wir jetzt einen KI-Sprachassistenten entwickeln, und das Gegenteil ist ein Chatbot, der Sprache wirklich versteht. Sie sind jetzt integriert, sodass keine Notwendigkeit besteht, diese Dichotomie oder koordinierte und angespannte Beziehung zu berücksichtigen.
Der zweite Grund ist, dass eine enge Rückkopplungsschleife zwischen Forschung und realer Anwendung für die Forschung tatsächlich sehr vorteilhaft ist.
Aufgrund der Art und Weise, wie das Produkt es Ihnen ermöglicht, wirklich zu verstehen, wie gut Ihr Modell funktioniert, können Sie akademische Metriken verwenden, aber der eigentliche Test besteht darin, dass Millionen von Benutzern Ihr Produkt verwenden. Finden sie es nützlich? Ist es nützlich? Ist es hilfreich und ist es gut für die Welt?
Man wird natürlich viel Feedback bekommen und das wird dann zu sehr schnellen Verbesserungen des zugrunde liegenden Modells führen, daher denke ich, dass wir uns gerade in dieser sehr, sehr aufregenden Phase befinden.
Das obige ist der detaillierte Inhalt vonDeepMind CEO: LLM+Tree Search ist die AGI-Technologielinie für wissenschaftliche Forschung, die auf technischen Fähigkeiten basiert. Closed-Source-Modelle sind sicherer als Open-Source-Modelle.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
