
 Technologie-Peripheriegeräte
KI
Die Vorhersagegenauigkeit beträgt bis zu 0,98. Die Tsinghua-Universität, Shenzhen Technology und andere haben ein multifunktionales Vorhersage-Framework für MOF-Materialien auf Basis von Transformer vorgeschlagen.
Technologie-Peripheriegeräte
KI
Die Vorhersagegenauigkeit beträgt bis zu 0,98. Die Tsinghua-Universität, Shenzhen Technology und andere haben ein multifunktionales Vorhersage-Framework für MOF-Materialien auf Basis von Transformer vorgeschlagen.
Die Vorhersagegenauigkeit beträgt bis zu 0,98. Die Tsinghua-Universität, Shenzhen Technology und andere haben ein multifunktionales Vorhersage-Framework für MOF-Materialien auf Basis von Transformer vorgeschlagen.


Herausgeber |
Herkömmliche Simulationsmethoden wie die Molekulardynamik sind zwar komplex und rechenintensiv, aber bei der Simulation des Systemverhaltens äußerst genau. Im Gegensatz dazu sind auf Feature Engineering basierende Methoden des maschinellen Lernens bei komplexen Systemen leistungsfähiger. Aufgrund der Knappheit gekennzeichneter Daten kann es jedoch leicht zu Überanpassungsproblemen kommen. Darüber hinaus sind diese Methoden des maschinellen Lernens in der Regel auf die Lösung einer einzelnen Aufgabe ausgelegt und bieten keine Unterstützung für das Lernen mehrerer Aufgaben. Daher müssen bei der Auswahl einer geeigneten Methode Faktoren wie Genauigkeit, Datenanforderungen und Aufgabenkomplexität abgewogen werden, um die Lösung zu finden, die am besten zum spezifischen Problem passt.
Um diese Herausforderungen anzugehen, hat ein multiinstitutionelles Team bestehend aus der Tsinghua-Universität, der University of California, der Sun Yat-sen-Universität, der Suzhou-Universität, Shenzhen Technology und dem AI for Science Institute (Peking, AISI) gemeinsam Uni-MOF vorgeschlagen. ein innovatives Framework für das groß angelegte 3D-MOF-Darstellungslernen, das für die vielseitige Gasvorhersage konzipiert ist. Uni-MOFs eignen sich sowohl für die wissenschaftliche Forschung als auch für praktische Anwendungen.
Uni-MOF kann als multifunktionaler Gasadsorptionsprädiktor für MOF-Materialien angesehen werden, der eine hervorragende Vorhersagegenauigkeit in Simulationsdaten zeigt und eine wichtige Anwendung des maschinellen Lernens in der Gasadsorptionsforschung darstellt.
Die Studie trug den Titel „Ein umfassender transformatorbasierter Ansatz für hochpräzise Gasadsorptionsvorhersagen in metallorganischen Gerüsten“ und wurde am 1. März 2024 in „Nature Communications“ veröffentlicht.
 Link zum Papier: https://www.nature.com/articles/s41467-024-46276-x
Link zum Papier: https://www.nature.com/articles/s41467-024-46276-x
Ein einheitliches Adsorptionsgerüst ist erforderlich
Metallorganische Gerüste (MOFs) aufgrund ihrer einstellbaren Struktureigenschaften und chemische Komponenten werden häufig in Bereichen wie der Gastrennung eingesetzt.
Während MOFs ein großes Potenzial für die Gasadsorption haben, bleibt die genaue Vorhersage ihrer Adsorptionskapazität eine Herausforderung.
Rechenmethoden wie Molekulardynamik und Monte Carlo (MC) haben hohe Rechenkosten und eine komplexe Implementierung, was ihre Verwendung in groß angelegten Mehrgas- und Hochdurchsatzberechnungen einschränkt. Darüber hinaus funktioniert die Gasadsorption unter einem breiten Spektrum von Bedingungen, was Vorhersagen komplexer macht.
Graphische neuronale Netze und Transformatoren können MOF-Eigenschaften nachweislich erfolgreich vorhersagen.
Obwohl bestehende Modelle zur Vorhersage von Adsorptionseigenschaften über eine hohe Leistung und starke Vorhersagefähigkeiten verfügen, sind sie normalerweise für eine einzelne Aufgabe konzipiert, nämlich die Vorhersage der Adsorptions- und Absorptionsrate eines bestimmten Gases unter bestimmten Bedingungen. Allerdings sind die verfügbaren Datensätze für diese Einzelaufgabenvorhersagen oft begrenzt, was die Generalisierbarkeit der Modelle behindert.
Andererseits kann durch die Kombination markierter Daten verschiedener adsorbierter Gase in verschiedenen Temperatur- und Druckumgebungen ein großer Datensatz erstellt werden, der für das Training über die gesamten Betriebsbedingungen hinweg geeignet ist. Die erhöhte Datenmenge kann auch die Generalisierungsfähigkeiten des Modells verbessern und seinen praktischen industriellen Einsatz verbessern. Daher ist ein einheitliches Adsorptionsgerüst erforderlich, um diese Modelle voranzutreiben.
Darüber hinaus kann das Ensemble-Darstellungslernen oder Vortraining für große, unbeschriftete MOF-Strukturen die Modellleistung und Darstellungsfähigkeiten weiter verbessern.
Uni-MOF-Framework: Sowohl für wissenschaftliche Forschung als auch für praktische Anwendungen geeignet
Davon inspiriert schlug das Forschungsteam das Uni-MOF-Framework als vielseitige Lösung vor, die das Lernen struktureller Darstellung nutzt, um die Gasadsorption von MOFs unter verschiedenen Bedingungen vorherzusagen.
Im Vergleich zu anderen Transformer-basierten Modellen (wie MOFormer und MOFTransformer) kann Uni-MOF als Transformer-basiertes Framework nicht nur die dreidimensionale Struktur nanoporöser Materialien im Vortraining identifizieren und wiederherstellen und somit erheblich verbessern die Leistung nanoporöser Materialien. Darüber hinaus berücksichtigt die Feinabstimmungsaufgabe Betriebsbedingungen wie Temperatur, Druck und unterschiedliche Gasmoleküle, sodass Uni-MOF sowohl für die wissenschaftliche Forschung als auch für praktische Anwendungen geeignet ist.
Uni-MOF benötigt als umfassender Gasadsorptionsschätzer für MOF-Materialien lediglich die Kristallinformationsdatei (CIF) des MOF und zugehörige Gas-, Temperatur- und Druckparameter, um die Gasadsorptionseigenschaften nanoporöser Materialien in einem breiten Spektrum vorherzusagen Betriebsbedingungen. . Das Uni-MOF-Framework ist einfach zu bedienen und ermöglicht die Modulauswahl.
Darüber hinaus wird das Problem der Überanpassung effektiv gelöst, indem verschiedene systemübergreifende Absorptionskennzeichnungsdaten mit dem Repräsentationslernen einer großen Menge unbeschrifteter Strukturdaten kombiniert werden. Dadurch werden sowohl qualitativ hochwertige Daten als auch Datendefizite ausgeglichen und letztendlich die Genauigkeit der Gasadsorptionsvorhersagen verbessert.
Das Uni-MOF-Framework ermöglicht eine Materialidentifizierungsgenauigkeit auf atomarer Ebene, während integrierte Modelle Uni-MOF besser auf technische Probleme anwendbar machen. Es besteht kein Zweifel daran, dass die Entwicklung wirklich einheitlicher Modelle die zukünftige Ausrichtung des Werkstoffbereichs ist und nicht nur die Konzentration auf Spezialbereiche. Uni-MOF ist eine bahnbrechende Praxis des maschinellen Lernens im Bereich der Gasadsorption.
Übersicht über das Uni-MOF-Framework
Das Uni-MOF-Framework umfasst das Vortraining dreidimensionaler nanoporöser Kristalle und die Feinabstimmung von Multitask-Vorhersagen in nachgelagerten Anwendungen.
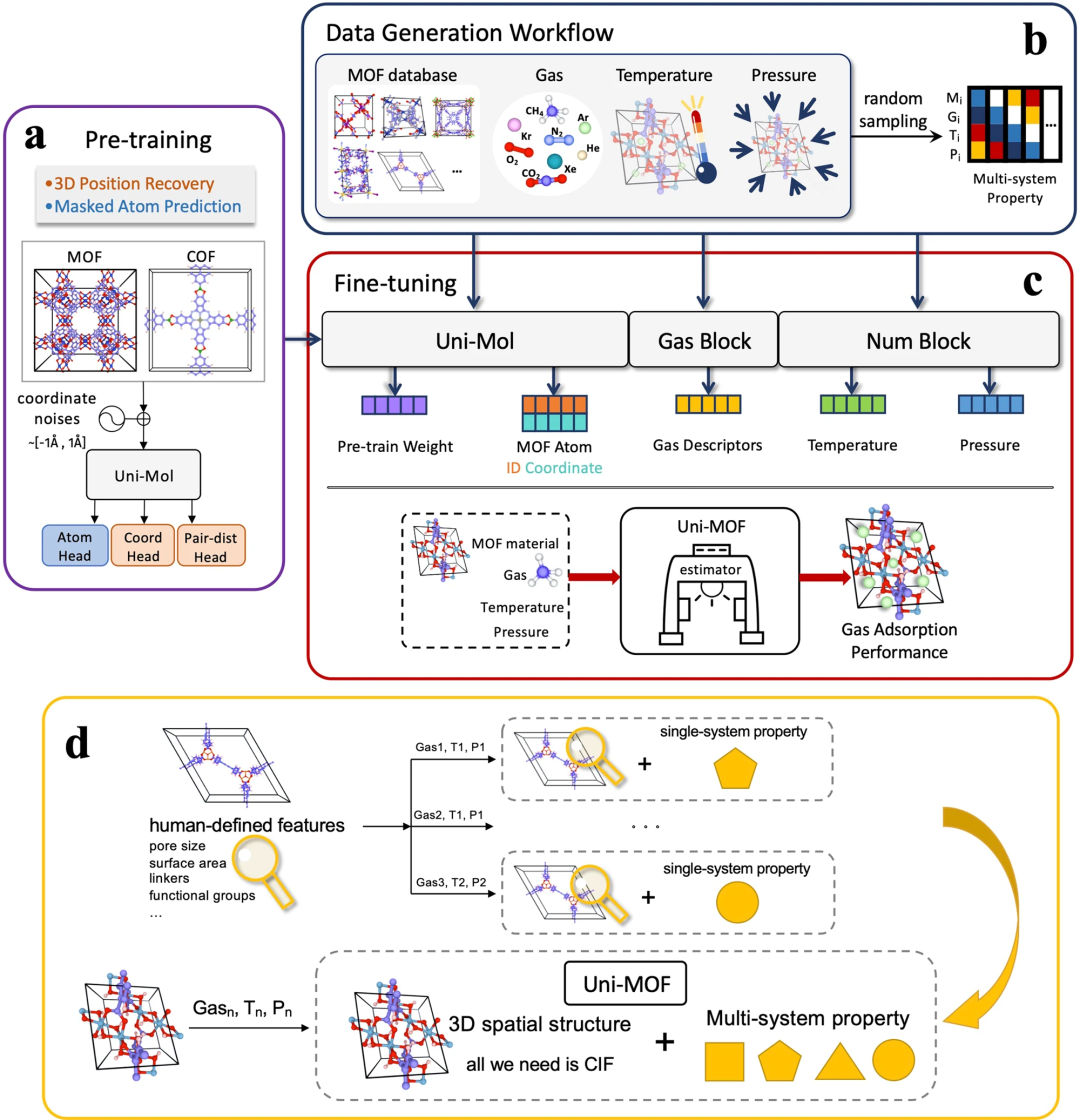
Abbildung 1: Schematische Darstellung des Uni-MOF-Frameworks. (Quelle: Papier)
Vorabtraining an kristallinen 3D-Materialien verbessert die Vorhersageleistung nachgelagerter Aufgaben erheblich, insbesondere bei großen, unbeschrifteten Daten.
Um das Problem der unzureichenden Überwachung von Trainingsdatensätzen zu lösen, sammelten Forscher eine große Anzahl von MOF-Strukturdatensätzen und generierten mit ToBaCCo.3.0 mehr als 300.000 MOFs. Die Hochdurchsatzkonstruktion von COFs auf der Grundlage von Materials Genome Strategies und Quasi-Reactive Assembly Algorithm (QReaxAA) ist möglich, um eine umfassende COF-Bibliothek aufzubauen. Durch die räumliche Konfiguration des Materials ist Uni-MOF in der Lage, die strukturellen Eigenschaften des Materials gut zu erlernen, und das Wichtigste sind die Informationen zur chemischen Bindung.
Um Uni-MOF in die Lage zu versetzen, ein vielfältigeres Materialspektrum zu erlernen und so die Generalisierungsfähigkeit auf ein breiteres Materialspektrum zu verbessern, wurden MOF und COF während des Vortrainingsprozesses virtuell und experimentell eingeführt. Ähnlich wie die maskierte Markierungsaufgabe in BERT und Uni-Mol übernimmt Uni-MOF die Vorhersageaufgabe maskierter Atome und erleichtert so vorab trainierte Modelle, um ein tiefgreifendes Verständnis der räumlichen Struktur des Materials zu erlangen.
Um die Robustheit des Vortrainings zu verbessern und die erlernten Darstellungen zu verallgemeinern, führten die Forscher Rauschen in die ursprünglichen Koordinaten der MOFs ein. In der Vorbereitungsphase werden zwei Aufgaben entworfen. (1) Original-3D-Positionen aus verrauschten Daten rekonstruieren und (2) abgeschirmte Atome vorhersagen. Diese Aufgaben können die Modellrobustheit verbessern und die nachgelagerte Vorhersageleistung verbessern.
Neben vielfältigen räumlichen Konfigurationen ist auch ein umfassender Satz an Materialeigenschaftsdatenpunkten für das Modelltraining von entscheidender Bedeutung. Um den Datensatz anzureichern, richteten die Forscher einen benutzerdefinierten Datengenerierungsprozess ein (dargestellt in Abbildung 1b).
Die Feinabstimmung von Uni-MOF basiert auf der Extraktion von Darstellungen, die durch Vortraining erhalten wurden, und der Verwendung selbst erstellter Arbeitsabläufe zum Generieren und Sammeln großer Datensätze. Während des Feinabstimmungsprozesses wurden etwa 3.000.000 markierte Datenpunkte unter verschiedenen Adsorptionsbedingungen für MOFs und COFs verwendet, um das Modell zu trainieren und so eine genaue Vorhersage der Adsorptionskapazität zu ermöglichen.
Mit einer vielfältigen Datenbank systemübergreifender Zieldaten kann ein fein abgestimmtes Uni-MOF die Multisystem-Adsorptionseigenschaften von MOFs in jedem Zustand vorhersagen. Daher ist Uni-MOF ein einheitliches und benutzerfreundliches Framework zur Vorhersage der Adsorptionsleistung von MOF-Adsorbentien.
Das Beste ist, dass Uni-MOF keinen zusätzlichen Arbeitsaufwand erfordert, um vom Menschen definierte Strukturmerkmale zu identifizieren. Stattdessen reichen der CIF des MOF und die zugehörigen Gas-, Temperatur- und Druckparameter aus. Die selbstüberwachte Lernstrategie und die umfangreiche Datenbank stellen sicher, dass Uni-MOF in der Lage ist, die Gasadsorptionseigenschaften nanoporöser Materialien unter verschiedenen Betriebsparametern vorherzusagen, was es zu einem kompetenten Schätzer der Gasadsorption für MOF-Materialien macht.
Vorhersagegenauigkeit bis zu 0,98, systemübergreifende Vorhersagen
Diese Studie führte selbstüberwachtes Lernen auf einer Datenbank mit mehr als 631.000 MOFs und COFs mit einer Vorhersagegenauigkeit von bis zu 0,98 durch. Dies zeigt, dass das auf 3D-Vortraining basierende Repräsentationslernframework die komplexen Strukturinformationen von MOF effektiv lernt und gleichzeitig eine Überanpassung vermeidet.
Verwendung von Uni-MOF zur Vorhersage der Gasadsorptionsleistung von drei großen Datenbanken (hMOF_MOFX-DB, CoRE_MOFX-DB und CoRE_MAP_DB), wodurch eine Vorhersagegenauigkeit von bis zu 0,98 in Datenbanken mit ausreichenden Daten erreicht wird.
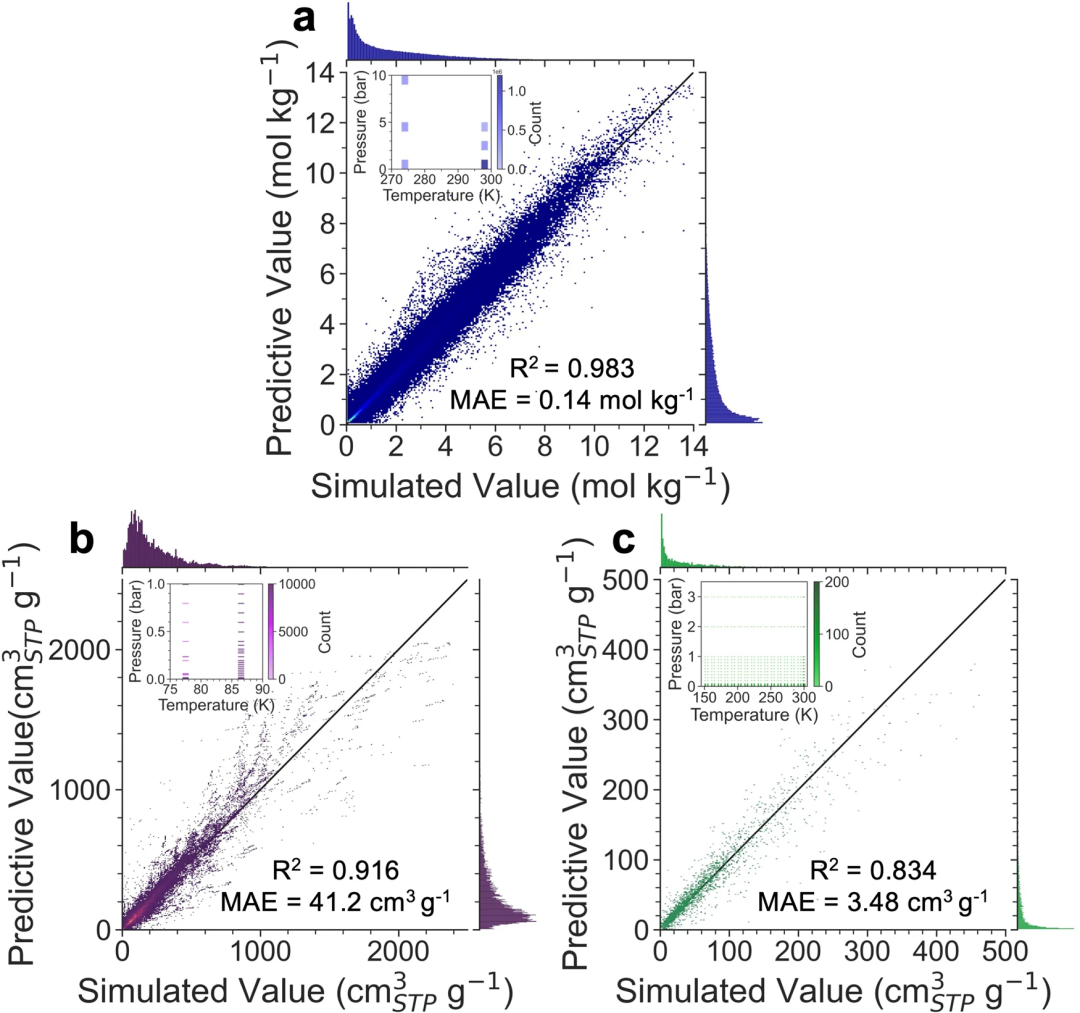
Abbildung 2: Gesamtleistung von Uni-MOF in großen Datenbanken. (Quelle: Papier)
Wenn der Datensatz vollständig abgetastet ist, behält Uni-MOF nicht nur eine Vorhersagegenauigkeit von mehr als 0,83 bei, sondern kann auch Hochleistungsadsorptionsmittel unter hohem Druck nur durch Vorhersage der Adsorption bei niedrigem Druck genau auswählen Die experimentellen Screening-Ergebnisse sind konsistent. Uni-MOF stellt daher einen großen Durchbruch bei der Anwendung maschineller Lerntechniken im Bereich der Materialwissenschaften dar.
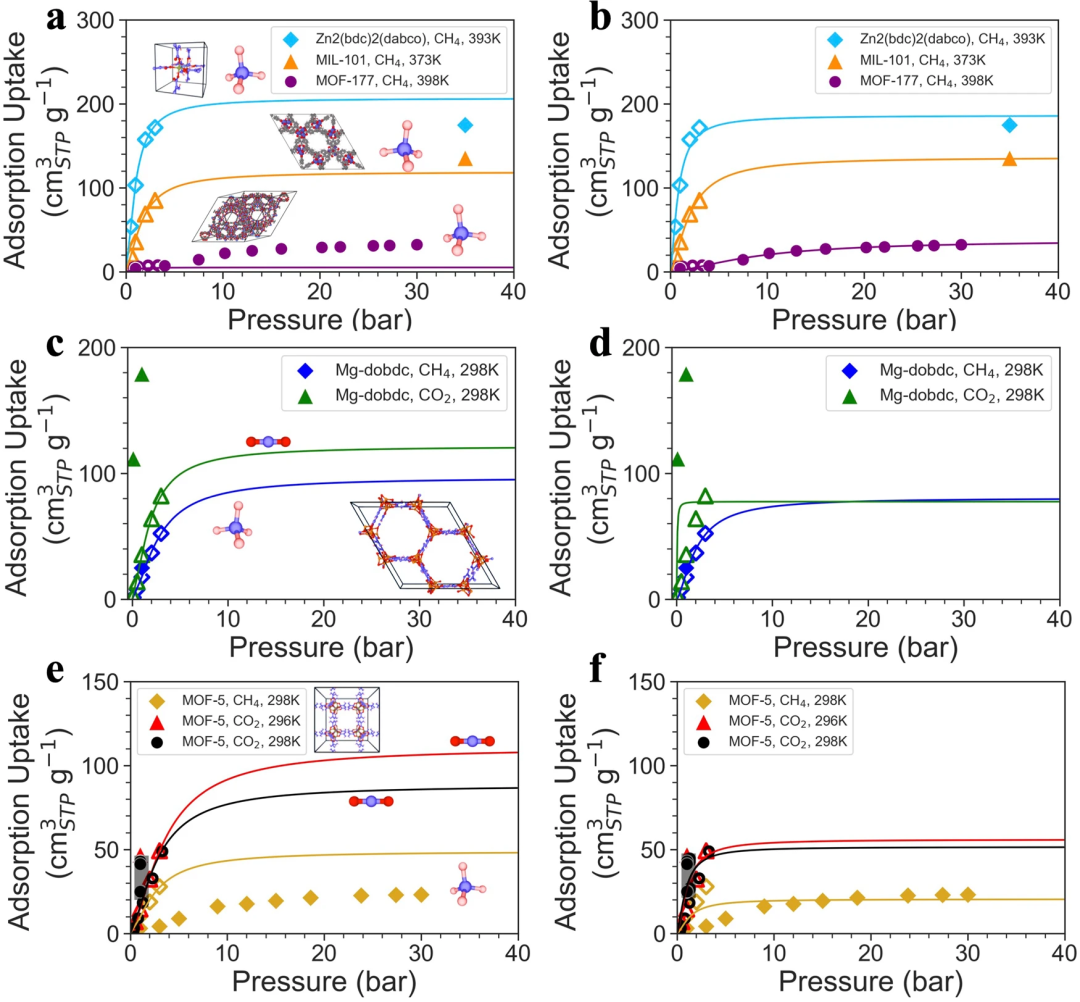
Abbildung 3: Adsorptionsisothermen basierend auf Niederdruckvorhersagen und Hochdruck-Versuchswerten, jede Kurve stellt eine Langmuir-Anpassung dar. (Quelle: Papier)
Darüber hinaus zeigt das Uni-MOF-Framework im Vergleich zu Einzelsystemaufgaben eine überlegene Leistung bei systemübergreifenden Datensätzen und kann die Adsorptionseigenschaften unbekannter Gase mit einer Vorhersagegenauigkeit von bis zu 0,85 genau vorhersagen. demonstriert seine Vorhersagekraft und Vielseitigkeit.
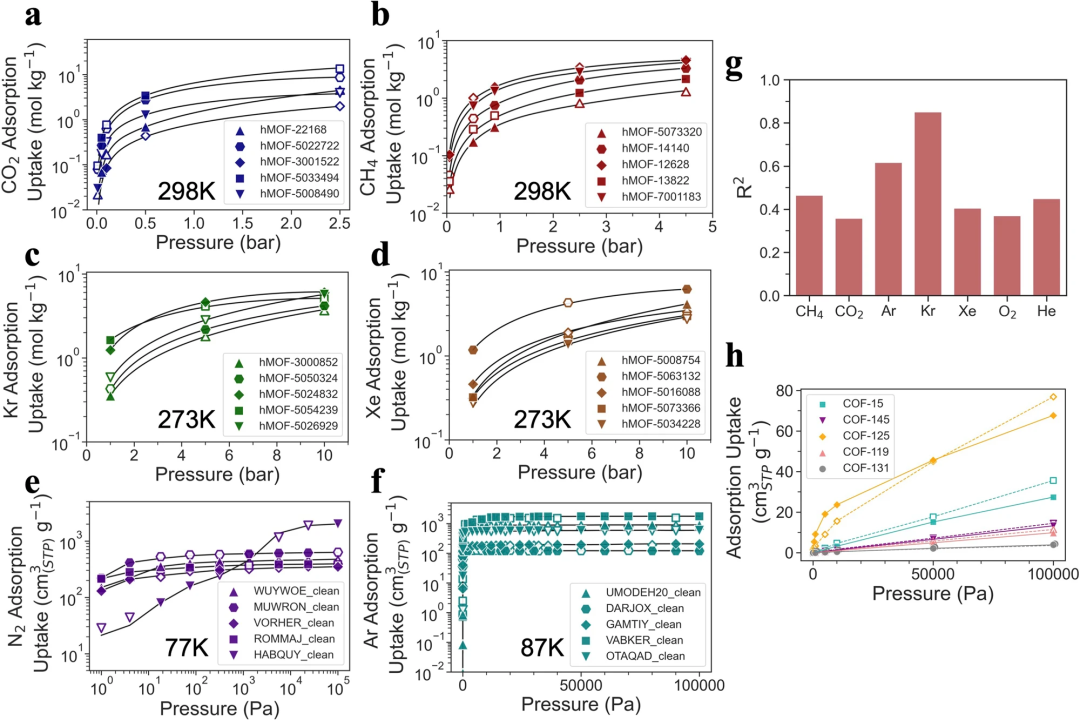
Abbildung 4: Uni-MOF-Cross-System-Vorhersagefall. (Quelle: Papier)
Untersuchungen zeigen, dass vorab trainierte selbstüberwachte Lernstrategien die Robustheit und die nachgelagerte Vorhersageleistung von Uni-MOF effektiv verbessern können.
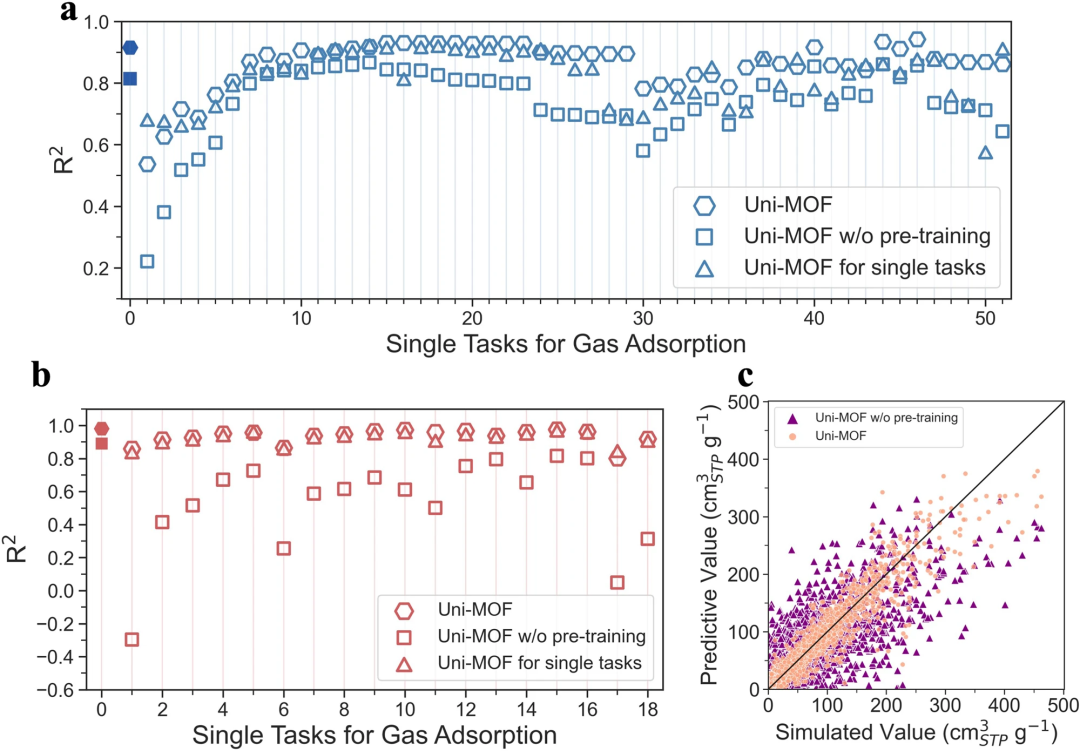
Abbildung 5: Vergleich von Uni-MOF und Uni-MOF ohne Vortraining. (Quelle: Papier)
Durch umfangreiches Vortraining zu dreidimensionalen Strukturen lernt Uni-MOF effektiv die Strukturmerkmale von MOFs und erreicht einen hohen Bestimmtheitskoeffizienten von 0,99 für hMOFs.
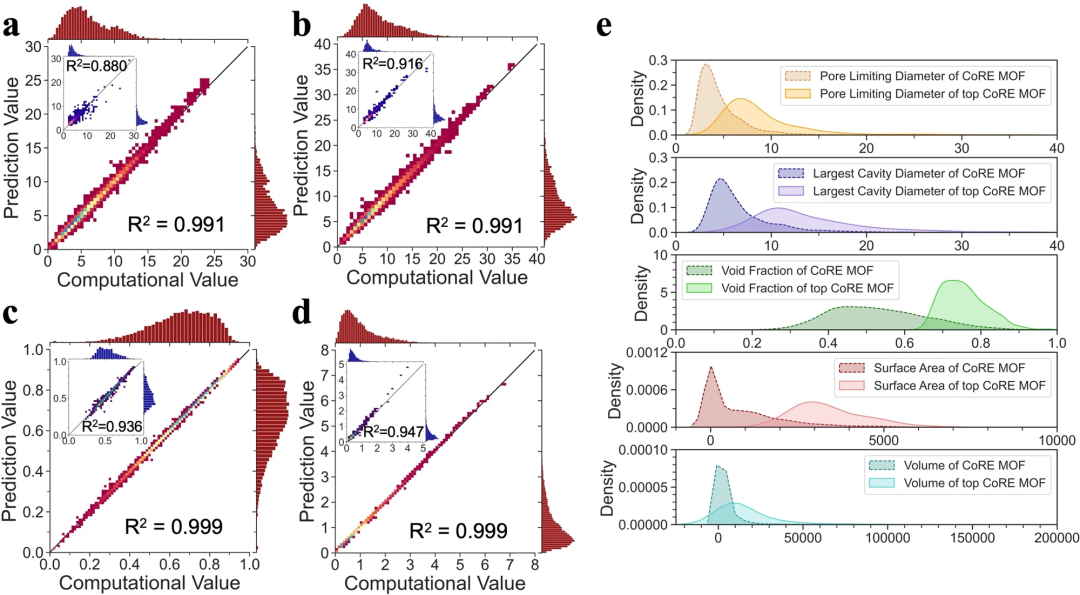
Abbildung 6: Vorhersage und Analyse struktureller Merkmale. (Quelle: Papier)
Darüber hinaus bestätigte die t-SNE-Analyse (t-verteilte stochastische Nachbareinbettung), dass die Feinabstimmungsphase Strukturmerkmale weiter lernen und Strukturen mit unterschiedlichem Adsorbatverhalten gut identifizieren kann, was darauf hinweist, dass die erlernte Darstellung vorhanden ist eine starke Korrelation mit Gasadsorptionszielen.
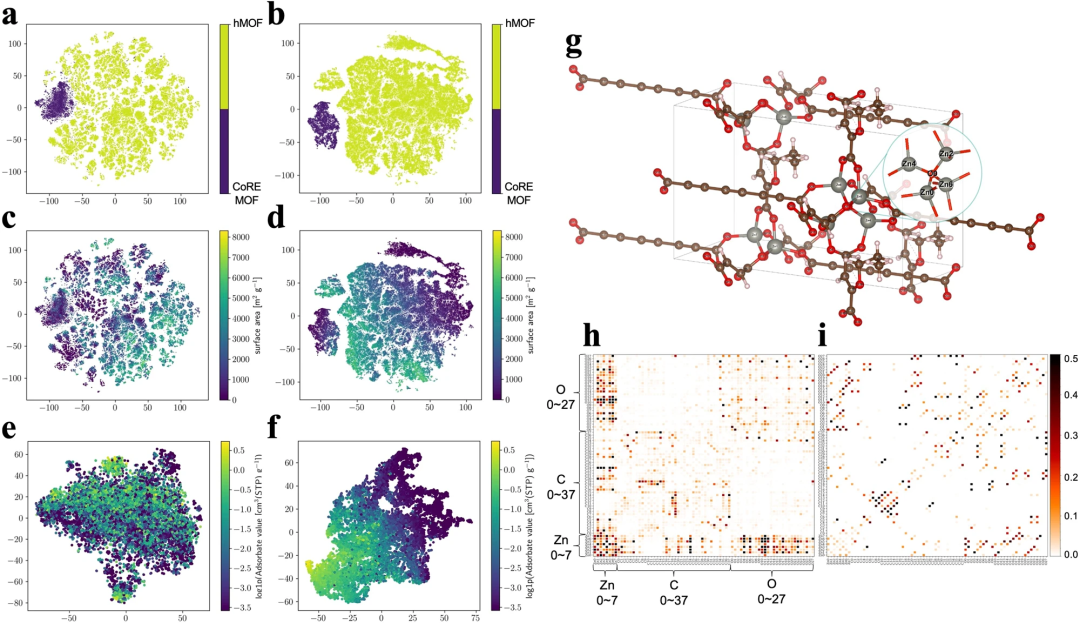
Abbildung 7: Visualisierung der MOF-Strukturdarstellung in hMOF- und CoRE_MOF-Datensätzen, niedrigdimensionale Einbettungen, berechnet mit der t-SNE-Methode. (Quelle: Papier)
Zusammenfassend dient das Uni-MOF-Framework als multifunktionale Vorhersageplattform für MOF-Materialien und fungiert als Gasadsorptionsschätzer für MOFs mit hoher Genauigkeit bei der Vorhersage der Gasadsorption unter verschiedenen Betriebsbedingungen im Feld der Materialwissenschaften. Es hat breite Anwendungsaussichten.
Das obige ist der detaillierte Inhalt vonDie Vorhersagegenauigkeit beträgt bis zu 0,98. Die Tsinghua-Universität, Shenzhen Technology und andere haben ein multifunktionales Vorhersage-Framework für MOF-Materialien auf Basis von Transformer vorgeschlagen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 „Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
„Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
In der modernen Fertigung ist die genaue Fehlererkennung nicht nur der Schlüssel zur Sicherstellung der Produktqualität, sondern auch der Kern für die Verbesserung der Produktionseffizienz. Allerdings mangelt es vorhandenen Datensätzen zur Fehlererkennung häufig an der Genauigkeit und dem semantischen Reichtum, die für praktische Anwendungen erforderlich sind, was dazu führt, dass Modelle bestimmte Fehlerkategorien oder -orte nicht identifizieren können. Um dieses Problem zu lösen, hat ein Spitzenforschungsteam bestehend aus der Hong Kong University of Science and Technology Guangzhou und Simou Technology innovativ den „DefectSpectrum“-Datensatz entwickelt, der eine detaillierte und semantisch reichhaltige groß angelegte Annotation von Industriedefekten ermöglicht. Wie in Tabelle 1 gezeigt, bietet der Datensatz „DefectSpectrum“ im Vergleich zu anderen Industriedatensätzen die meisten Fehleranmerkungen (5438 Fehlerproben) und die detaillierteste Fehlerklassifizierung (125 Fehlerkategorien).
 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Für KI ist die Mathematikolympiade kein Problem mehr. Am Donnerstag hat die künstliche Intelligenz von Google DeepMind eine Meisterleistung vollbracht: Sie nutzte KI, um meiner Meinung nach die eigentliche Frage der diesjährigen Internationalen Mathematikolympiade zu lösen, und war nur einen Schritt davon entfernt, die Goldmedaille zu gewinnen. Der IMO-Wettbewerb, der gerade letzte Woche zu Ende ging, hatte sechs Fragen zu Algebra, Kombinatorik, Geometrie und Zahlentheorie. Das von Google vorgeschlagene hybride KI-System beantwortete vier Fragen richtig und erzielte 28 Punkte und erreichte damit die Silbermedaillenstufe. Anfang dieses Monats hatte der UCLA-Professor Terence Tao gerade die KI-Mathematische Olympiade (AIMO Progress Award) mit einem Millionenpreis gefördert. Unerwarteterweise hatte sich das Niveau der KI-Problemlösung vor Juli auf dieses Niveau verbessert. Beantworten Sie die Fragen meiner Meinung nach gleichzeitig. Am schwierigsten ist es meiner Meinung nach, da sie die längste Geschichte, den größten Umfang und die negativsten Fragen haben
 Der Standpunkt der Natur: Die Erprobung künstlicher Intelligenz in der Medizin ist im Chaos. Was ist zu tun?
Aug 22, 2024 pm 04:37 PM
Der Standpunkt der Natur: Die Erprobung künstlicher Intelligenz in der Medizin ist im Chaos. Was ist zu tun?
Aug 22, 2024 pm 04:37 PM
Herausgeber | ScienceAI Basierend auf begrenzten klinischen Daten wurden Hunderte medizinischer Algorithmen genehmigt. Wissenschaftler diskutieren darüber, wer die Werkzeuge testen soll und wie dies am besten geschieht. Devin Singh wurde Zeuge, wie ein pädiatrischer Patient in der Notaufnahme einen Herzstillstand erlitt, während er lange auf eine Behandlung wartete, was ihn dazu veranlasste, den Einsatz von KI zu erforschen, um Wartezeiten zu verkürzen. Mithilfe von Triage-Daten aus den Notaufnahmen von SickKids erstellten Singh und Kollegen eine Reihe von KI-Modellen, um mögliche Diagnosen zu stellen und Tests zu empfehlen. Eine Studie zeigte, dass diese Modelle die Zahl der Arztbesuche um 22,3 % verkürzen können und die Verarbeitung der Ergebnisse pro Patient, der einen medizinischen Test benötigt, um fast drei Stunden beschleunigt. Der Erfolg von Algorithmen der künstlichen Intelligenz in der Forschung bestätigt dies jedoch nur
 Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Herausgeber |KX Bis heute sind die durch die Kristallographie ermittelten Strukturdetails und Präzision, von einfachen Metallen bis hin zu großen Membranproteinen, mit keiner anderen Methode zu erreichen. Die größte Herausforderung, das sogenannte Phasenproblem, bleibt jedoch die Gewinnung von Phaseninformationen aus experimentell bestimmten Amplituden. Forscher der Universität Kopenhagen in Dänemark haben eine Deep-Learning-Methode namens PhAI entwickelt, um Kristallphasenprobleme zu lösen. Ein Deep-Learning-Neuronales Netzwerk, das mithilfe von Millionen künstlicher Kristallstrukturen und den entsprechenden synthetischen Beugungsdaten trainiert wird, kann genaue Elektronendichtekarten erstellen. Die Studie zeigt, dass diese Deep-Learning-basierte Ab-initio-Strukturlösungsmethode das Phasenproblem mit einer Auflösung von nur 2 Angström lösen kann, was nur 10 bis 20 % der bei atomarer Auflösung verfügbaren Daten im Vergleich zur herkömmlichen Ab-initio-Berechnung entspricht
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Identifizieren Sie automatisch die besten Moleküle und reduzieren Sie die Synthesekosten. Das MIT entwickelt ein Algorithmus-Framework für die Entscheidungsfindung im molekularen Design
Jun 22, 2024 am 06:43 AM
Identifizieren Sie automatisch die besten Moleküle und reduzieren Sie die Synthesekosten. Das MIT entwickelt ein Algorithmus-Framework für die Entscheidungsfindung im molekularen Design
Jun 22, 2024 am 06:43 AM
Herausgeber |. Der Einsatz von Ziluo AI bei der Rationalisierung der Arzneimittelforschung nimmt explosionsartig zu. Durchsuchen Sie Milliarden von Kandidatenmolekülen nach solchen, die möglicherweise über Eigenschaften verfügen, die für die Entwicklung neuer Medikamente erforderlich sind. Es sind so viele Variablen zu berücksichtigen, von Materialpreisen bis hin zum Fehlerrisiko, dass es keine leichte Aufgabe ist, die Kosten für die Synthese der besten Kandidatenmoleküle abzuwägen, selbst wenn Wissenschaftler KI einsetzen. Hier entwickelten MIT-Forscher SPARROW, ein quantitatives Entscheidungsalgorithmus-Framework, um automatisch die besten molekularen Kandidaten zu identifizieren und so die Synthesekosten zu minimieren und gleichzeitig die Wahrscheinlichkeit zu maximieren, dass die Kandidaten die gewünschten Eigenschaften aufweisen. Der Algorithmus bestimmte auch die Materialien und experimentellen Schritte, die zur Synthese dieser Moleküle erforderlich sind. SPARROW berücksichtigt die Kosten für die gleichzeitige Synthese einer Charge von Molekülen, da häufig mehrere Kandidatenmoleküle verfügbar sind
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
