
 Technologie-Peripheriegeräte
KI
Atemberaubend! ! ! End-to-End-Demonstrationsvideoanalyse von Tesla
Technologie-Peripheriegeräte
KI
Atemberaubend! ! ! End-to-End-Demonstrationsvideoanalyse von Tesla
Atemberaubend! ! ! End-to-End-Demonstrationsvideoanalyse von Tesla

Ein Benutzer hat ein Video von Tesla FSD v12 im Internet gepostet und jemand hat es auf Seite B verschoben:
https://www.bilibili.com/video/BV1Z6421M797www.bilibili.com/video/BV1Z6421M797
Diesmal Es handelt sich um eine rein visuell komplexe Szene: Es regnet und es gibt Wasser auf dem Boden, und verschiedene Muster spiegeln sich auf dem Wasser, was zu seltsamen visuellen Effekten führen kann. Tesla hat letztes Jahr keine KI-Tag-Veranstaltung abgehalten, angeblich weil die Konkurrenten oft ihre Ausfälle provozierten, und hat sie deshalb einfach abgesagt. Da keine Details vorliegen, bietet das Ansehen des Videos einen Einblick in einige der End-to-End-Funktionen. Lassen Sie uns als Nächstes einige der interessanten Punkte analysieren.
01:57, habe fälschlicherweise erkannt, dass die Autotür offen war, und habe einen großen Umweg gemacht:

Das ist hier kein großes Problem, auf der linken Seite ist relativ viel Platz, also spielt es keine Rolle wenn du noch etwas länger herumläufst.
02:09, Fehlerkennung von Occ führte fast zu einem Stopp:

Die Fußgänger sind weg, wir können losfahren. Allerdings befand sich auf dem Boden viel stehendes Wasser, das das Bild des Objekts reflektierte, was zu Fehlerkennungen führen konnte, also hielten wir an und warteten eine Weile, bevor wir weitergingen.
04:40, das Nahbereichs-Einschaltfahrzeug wurde übersehen


Das sehr nahbereichsrückwärts einschneidende Fahrzeug auf der linken Seite wurde übersehen, die Planung schien aber nicht die Absicht dazu zu geben Start, der das Ende widerspiegelt. Ein großer Vorteil von End-to-End: Die Ergebnisse von Upstream-Fehlern führen nicht zwangsläufig zu falschem Fahrverhalten. Weitere ähnliche Beispiele werden wir später sehen.
05:37 Fehlerkennung von Occ


Dies kann auch ein Occ sein, der durch Wasseransammlungen auf dem Boden verursacht wurde. Ich habe dieses Ergebnis durchgehend akzeptiert und das Lenkrad nach links und rechts gedreht, manchmal auch nach links und manchmal auch nach rechts.
05:48, OCC-Fehlerkennung im Nahbereich links und rechts
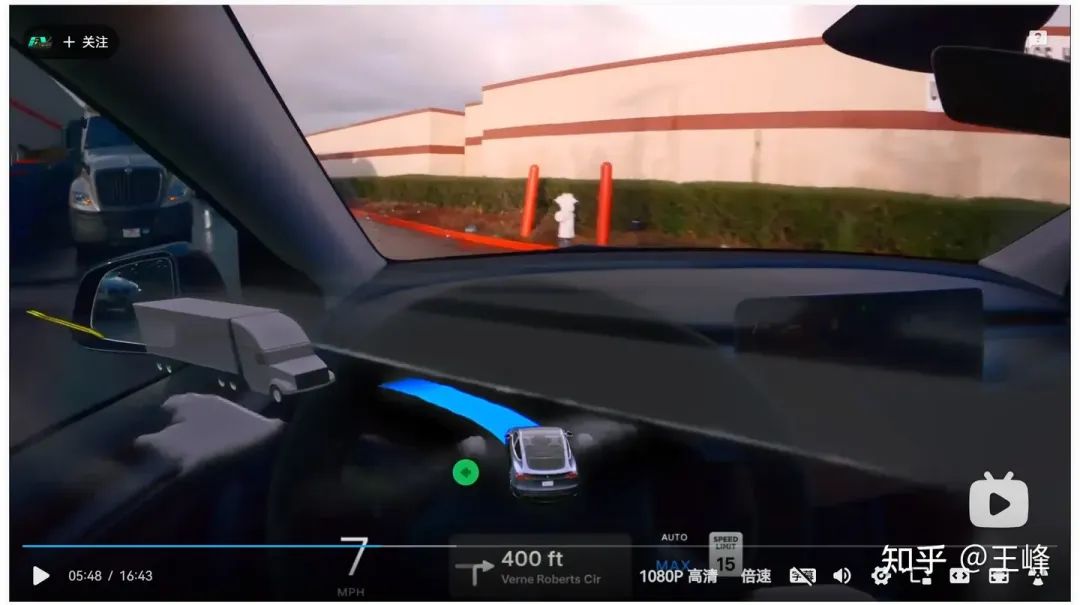
Es gab eine Fehlerkennung von OCC an einer sehr nahen Position links und rechts. Wer sich trotzdem an die Regeln hält, muss sich möglicherweise melden es zu übernehmen (nicht unbedingt, schließlich ist es kein Fahren auf der Strecke), hier ignoriere ich diese beiden OCCs direkt von Ende zu Ende und fahre weiter.
06:57, Fußgänger-Fehlerkennung aus nächster Nähe vor Ihnen
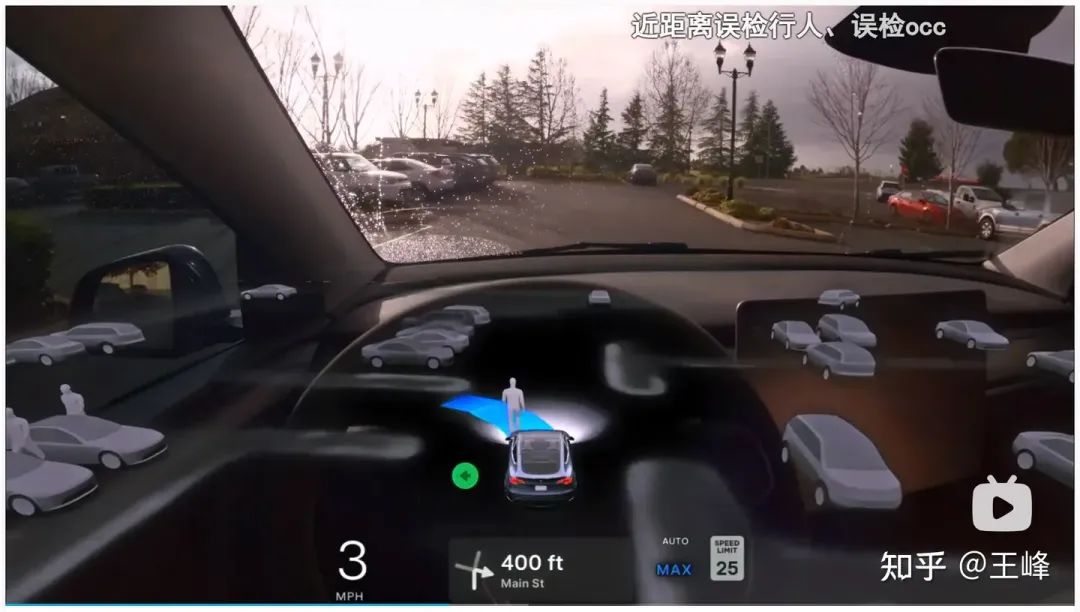
Das ist wirklich cool, ein Fußgänger erscheint im Gesicht, alle regelbasierten Steuerungen werden zu diesem Zeitpunkt definitiv bremsen + alarmieren, aber das Ende Das End-End-Modell erkennt die Upstream-Ergebnisse nicht und läuft wie gewohnt.
14 Punkte: Ich drehte mich auf einem privaten Parkplatz und konnte nicht raus
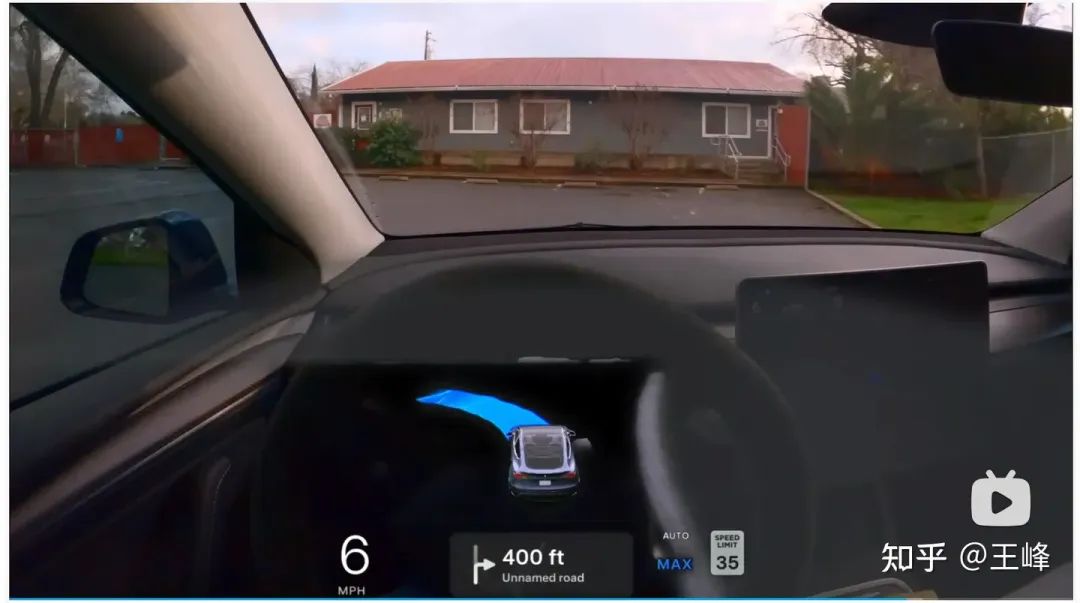
Dies könnte an der unzureichenden Reichweite des BEV liegen. Ich konnte die Ausfahrt nicht finden und drehte mich auf einem Parkplatz . .
In den anderen Clips dreht sich alles um das Fahren auf der Hauptstraße. Auf der Hauptstraße ist die Leistung von FSD v12 sehr flüssig, es gibt kein großes Problem, insbesondere die Erkennung von Fahrspurlinien bei Nacht ist auch sehr stabil, aber ich denke Die meisten Hersteller können auch dieses Niveau erreichen, ich werde es nicht viel erwähnen.
Wenn man sich nur den Abschnitt des Parkplatzes ansieht und sich die Upstream-Ergebnisse nicht ansieht, ist die Flugbahn von FSD v12 immer noch relativ, abgesehen von der Fehlerkennung des vorderen OCC, die dazu führte, dass sich das Lenkrad nach links und rechts drehte reibungslos, und selbst wenn es Fehler gibt, gibt es keine Situation, in der es hängen bleibt. In einer solchen Szene mit Fußgängern, sich unregelmäßig bewegenden Hindernissen (Trolleys) und Wasser auf dem Boden ist die Leistung tatsächlich in Ordnung.
Tesla verwendet immer noch Multitasking-End-to-End mit Zwischenmodulüberwachung, sodass das Front-End weiterhin die Ergebnisse von obj det und occ anzeigen kann. Die End-to-End-Regelung akzeptiert jedoch nicht unbedingt die vorgelagerten Ergebnisse. Eine verpasste Erkennung aus nächster Nähe muss nicht unbedingt zu einem Start und einem Unfall führen, und eine falsche Erkennung aus nächster Nähe muss nicht unbedingt dazu führen, dass das Fahrzeug anfährt Alle Ergebnisse werden zur umfassenden Beurteilung in den PNC eingegeben. Dies ist in der Tat ein interessanter Punkt. Sicher ist, dass Musk nicht lügt. Dies ist tatsächlich die Leistung eines End-to-End-Systems.
Das obige ist der detaillierte Inhalt vonAtemberaubend! ! ! End-to-End-Demonstrationsvideoanalyse von Tesla. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Tesla ergreift endlich Maßnahmen! Werden bald selbstfahrende Taxis vorgestellt? !
Apr 08, 2024 pm 05:49 PM
Tesla ergreift endlich Maßnahmen! Werden bald selbstfahrende Taxis vorgestellt? !
Apr 08, 2024 pm 05:49 PM
Laut Nachrichten vom 8. April gab Tesla-CEO Elon Musk kürzlich bekannt, dass Tesla sich der vollständigen Entwicklung selbstfahrender Autotechnologie verschrieben hat. Das mit Spannung erwartete unbemannte selbstfahrende Taxi Robotaxi wird am 8. August auf den Markt kommen. Offizielles Debüt. Der Datenredakteur erfuhr, dass Musks Aussage auf Zuvor berichtete Reuters, dass Teslas Plan, Autos anzutreiben, sich auf die Produktion von Robotaxi konzentrieren würde. Musk wies dies jedoch zurück und warf Reuters vor, Pläne zur Entwicklung von Billigautos abgesagt und erneut Falschmeldungen veröffentlicht zu haben, während er gleichzeitig klarstellte, dass es sich um Billigautos wie Model 2 und Robotax handelte
 Tesla Dojo-Supercomputing-Debüt, Musk: Die Rechenleistung der Trainings-KI wird bis Ende des Jahres etwa 8.000 NVIDIA H100-GPUs entsprechen
Jul 24, 2024 am 10:38 AM
Tesla Dojo-Supercomputing-Debüt, Musk: Die Rechenleistung der Trainings-KI wird bis Ende des Jahres etwa 8.000 NVIDIA H100-GPUs entsprechen
Jul 24, 2024 am 10:38 AM
Laut Nachrichten dieser Website vom 24. Juli erklärte Tesla-CEO Elon Musk (Elon Musk) in der heutigen Telefonkonferenz zu den Ergebnissen, dass das Unternehmen kurz vor der Fertigstellung des bisher größten Schulungsclusters für künstliche Intelligenz stehe, das mit 2.000 NVIDIA H100 ausgestattet sein werde GPUs. Musk teilte den Anlegern bei der Gewinnmitteilung des Unternehmens auch mit, dass Tesla an der Entwicklung seines Dojo-Supercomputers arbeiten werde, da GPUs von Nvidia teuer seien. Diese Seite übersetzte einen Teil von Musks Rede wie folgt: Der Weg, über Dojo mit NVIDIA zu konkurrieren, ist schwierig, aber ich denke, wir haben keine andere Wahl. Wir sind jetzt zu sehr auf NVIDIA angewiesen. Aus der Sicht von NVIDIA werden sie den Preis für GPUs unweigerlich auf ein Niveau erhöhen, das der Markt ertragen kann, aber
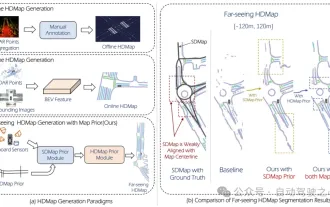 Massenproduktionskiller! P-Mapnet: Durch die vorherige Verwendung der Karte SDMap mit niedriger Genauigkeit wird die Kartenleistung deutlich um fast 20 Punkte verbessert!
Mar 28, 2024 pm 02:36 PM
Massenproduktionskiller! P-Mapnet: Durch die vorherige Verwendung der Karte SDMap mit niedriger Genauigkeit wird die Kartenleistung deutlich um fast 20 Punkte verbessert!
Mar 28, 2024 pm 02:36 PM
Wie oben geschrieben, besteht einer der Algorithmen, mit denen aktuelle autonome Fahrsysteme die Abhängigkeit von hochpräzisen Karten loswerden, darin, die Tatsache auszunutzen, dass die Wahrnehmungsleistung im Fernbereich immer noch schlecht ist. Zu diesem Zweck schlagen wir P-MapNet vor, wobei sich „P“ auf die Fusion von Kartenprioritäten konzentriert, um die Modellleistung zu verbessern. Konkret nutzen wir die Vorinformationen in SDMap und HDMap aus: Einerseits extrahieren wir schwach ausgerichtete SDMap-Daten aus OpenStreetMap und kodieren sie in unabhängige Begriffe, um die Eingabe zu unterstützen. Es besteht das Problem der schwachen Ausrichtung zwischen der streng modifizierten Eingabe und der tatsächlichen HD+Map. Unsere auf dem Cross-Attention-Mechanismus basierende Struktur kann sich adaptiv auf das SDMap-Skelett konzentrieren und erhebliche Leistungsverbesserungen bringen.
 LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
May 09, 2024 pm 04:55 PM
LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
May 09, 2024 pm 04:55 PM
Oben geschrieben und persönliches Verständnis des Autors: Dieses Papier widmet sich der Lösung der wichtigsten Herausforderungen aktueller multimodaler großer Sprachmodelle (MLLMs) in autonomen Fahranwendungen, nämlich dem Problem der Erweiterung von MLLMs vom 2D-Verständnis auf den 3D-Raum. Diese Erweiterung ist besonders wichtig, da autonome Fahrzeuge (AVs) genaue Entscheidungen über 3D-Umgebungen treffen müssen. Das räumliche 3D-Verständnis ist für AVs von entscheidender Bedeutung, da es sich direkt auf die Fähigkeit des Fahrzeugs auswirkt, fundierte Entscheidungen zu treffen, zukünftige Zustände vorherzusagen und sicher mit der Umgebung zu interagieren. Aktuelle multimodale große Sprachmodelle (wie LLaVA-1.5) können häufig nur Bildeingaben mit niedrigerer Auflösung verarbeiten (z. B. aufgrund von Auflösungsbeschränkungen des visuellen Encoders und Einschränkungen der LLM-Sequenzlänge). Allerdings erfordern autonome Fahranwendungen
