
 Technologie-Peripheriegeräte
KI
Der technische Bericht zu Stable Diffusion 3 ist durchgesickert, die Sora-Architektur hat wieder großartige Erfolge erzielt! Schlägt die Open-Source-Community gewaltsam gegen Midjourney und DALL·E 3 vor?
Technologie-Peripheriegeräte
KI
Der technische Bericht zu Stable Diffusion 3 ist durchgesickert, die Sora-Architektur hat wieder großartige Erfolge erzielt! Schlägt die Open-Source-Community gewaltsam gegen Midjourney und DALL·E 3 vor?
Der technische Bericht zu Stable Diffusion 3 ist durchgesickert, die Sora-Architektur hat wieder großartige Erfolge erzielt! Schlägt die Open-Source-Community gewaltsam gegen Midjourney und DALL·E 3 vor?

Stability AI hat heute nach der Veröffentlichung von Stable Diffusion 3 einen detaillierten technischen Bericht veröffentlicht.
Das Papier bietet eine eingehende Analyse der Kerntechnologie von Stable Diffusion 3 – eine verbesserte Version des Diffusionsmodells und eine neue Architektur vinzentinischer Diagramme basierend auf DiT!

Meldeadresse:
https://www.php.cn/link/e5fb88b398b042f6cccce46bf3fa53e8
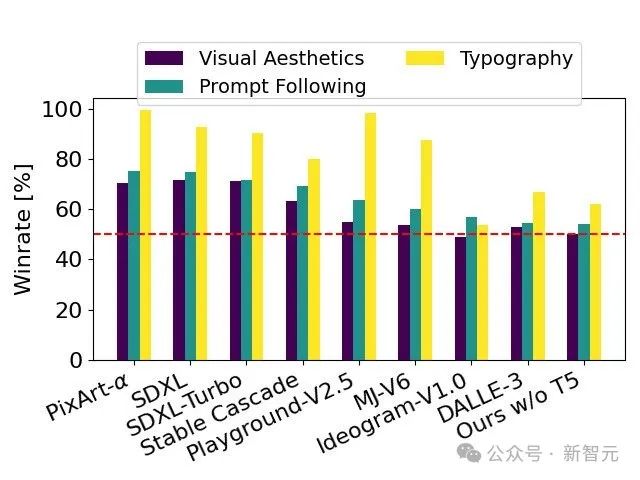
Bestandener Humantest, stabil Verbreitung 3. Im Schriftdesign und in der präzisen Reaktion auf Aufforderungen In puncto Leistung übertrifft es DALL·E 3, Midjourney v6 und Ideogram v1.
Die neu entwickelte Multi-modal Diffusion Transformer (MMDiT)-Architektur von Stability AI verwendet unabhängige Gewichtssätze speziell für die Bild- und Sprachdarstellung. Im Vergleich zu früheren Versionen von SD 3 hat MMDiT deutliche Verbesserungen beim Textverständnis und der Rechtschreibung erzielt.

Leistungsbewertung
Basierend auf menschlichem Feedback vergleicht der technische Bericht SD 3 mit einer großen Anzahl von Open-Source-Modellen SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 und Pixart-α, as sowie die Closed-Source-Modelle DALL·E 3, Midjourney v6 und Ideogram v1 wurden detailliert evaluiert.
Gutachter wählen die beste Ausgabe für jedes Modell basierend auf der Konsistenz der angegebenen Eingabeaufforderungen, der Klarheit des Textes und der Gesamtästhetik der Bilder aus.

Die Testergebnisse zeigen, dass Stable Diffusion 3 das höchste Niveau der aktuellen Technologie zur Generierung vincentischer Diagramme erreicht oder übertroffen hat, sei es in Bezug auf die Genauigkeit beim Befolgen von Eingabeaufforderungen, die klare Darstellung von Text oder die visuelle Schönheit von Bildern.
Das vollständig nicht hardwareoptimierte SD 3-Modell verfügt über 8B-Parameter, kann auf einer RTX 4090 Consumer-GPU mit 24 GB Videospeicher ausgeführt werden und erzeugt eine Auflösung von 1024 x 1024 mit 50 Abtastschritten. Das Bild dauert 34 Sekunden .
Darüber hinaus wird Stable Diffusion 3 bei Veröffentlichung mehrere Versionen mit Parametern im Bereich von 800 Millionen bis 8 Milliarden bereitstellen, was die Hardware-Nutzungsschwelle weiter senken kann.

Architektonische Details offengelegt
Beim Generieren des Vincent-Diagramms muss das Modell zwei verschiedene Arten von Informationen, Text und Bild, gleichzeitig verarbeiten. Deshalb nennt der Autor dieses neue Framework MMDiT.
Im Prozess der Text-zu-Bild-Generierung muss das Modell zwei verschiedene Informationstypen, Text und Bild, gleichzeitig verarbeiten. Aus diesem Grund nennen die Autoren diese neue Technologie MMDiT (kurz für Multimodal Diffusion Transformer).
Wie frühere Versionen von Stable Diffusion verwendet SD 3 ein vorab trainiertes Modell, um geeignete Ausdrücke von Text und Bildern zu extrahieren.
Konkret verwendeten sie drei verschiedene Text-Encoder – zwei CLIP-Modelle und einen T5 – zur Verarbeitung von Textinformationen, während sie ein fortschrittlicheres Autoencoding-Modell zur Verarbeitung von Bildinformationen verwendeten.
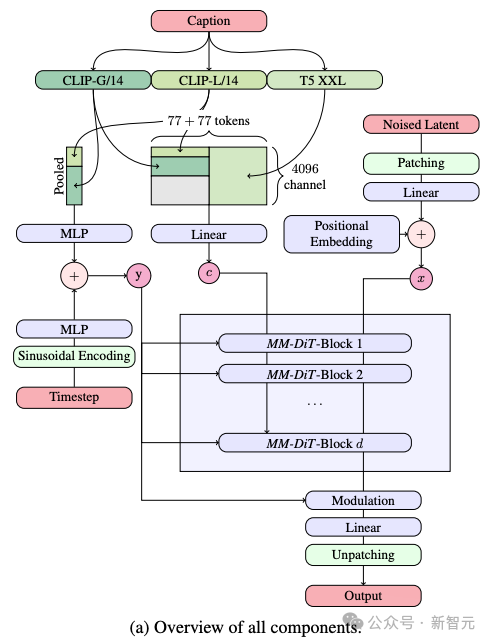
Die Architektur von SD 3 basiert auf Diffusion Transformer (DiT). Aufgrund des Unterschieds zwischen Text- und Bildinformationen legt SD 3 für jede dieser beiden Informationsarten unabhängige Gewichtungen fest.
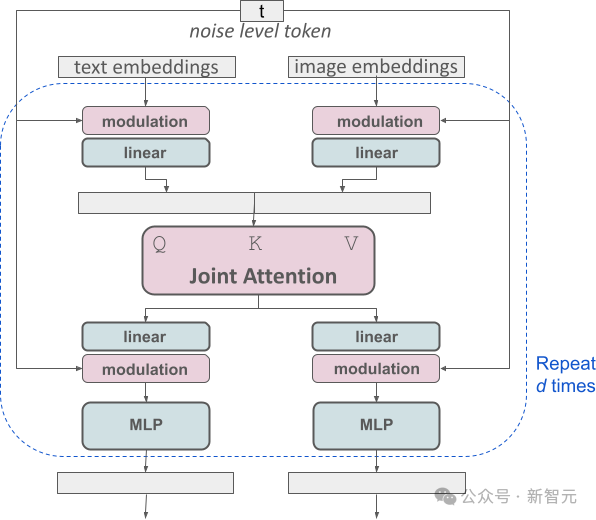
Dieses Design entspricht der Ausstattung zweier unabhängiger Transformatoren für jeden Informationstyp. Bei der Ausführung des Aufmerksamkeitsmechanismus werden jedoch die Datensequenzen der beiden Informationstypen zusammengeführt, sodass sie unabhängig voneinander in ihren jeweiligen Bereichen arbeiten können gegenseitige Referenz und Integration.
Durch diese einzigartige Architektur können Bild- und Textinformationen fließen und miteinander interagieren, wodurch das Gesamtverständnis des Inhalts und die visuelle Darstellung in den generierten Ergebnissen verbessert werden.
Darüber hinaus kann diese Architektur in Zukunft problemlos auf andere Modalitäten, einschließlich Video, erweitert werden.

Dank der Verbesserungen von SD 3 beim Befolgen von Eingabeaufforderungen ist das Modell in der Lage, Bilder präzise zu generieren, die sich auf eine Vielzahl verschiedener Themen und Funktionen konzentrieren, und gleichzeitig ein hohes Maß an Flexibilität im Bildstil beizubehalten.

Verbesserter gleichgerichteter Fluss durch die Neugewichtungsmethode
Neben der neuen Diffusion Transformer-Architektur hat SD 3 auch erhebliche Verbesserungen am Diffusionsmodell vorgenommen.
SD 3 nutzt die Rectified Flow (RF)-Strategie, um Trainingsdaten und Rauschen entlang einer geraden Flugbahn zu verbinden.
Diese Methode macht den Inferenzpfad des Modells direkter, sodass die Probengenerierung in weniger Schritten abgeschlossen werden kann.
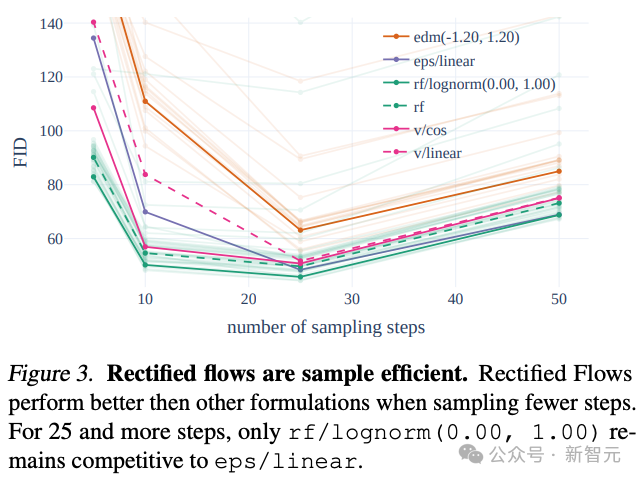
Der Autor führte im Trainingsprozess einen innovativen Trajektorien-Sampling-Plan ein, der insbesondere das Gewicht auf den mittleren Teil der Trajektorie erhöhte, wo die Vorhersageaufgabe anspruchsvoller ist.
Durch den Vergleich mit 60 anderen Diffusionstrajektorien (wie LDM, EDM und ADM) stellten die Autoren fest, dass die vorherige RF-Methode zwar bei der Abtastung in wenigen Schritten eine bessere Leistung erbrachte, die Leistung jedoch mit zunehmender Anzahl der Abtastschritte langsam abnahm. .
Um diese Situation zu vermeiden, kann die vom Autor vorgeschlagene gewichtete RF-Methode die Modellleistung weiter verbessern.
Erweitertes RF-Transformator-Modell
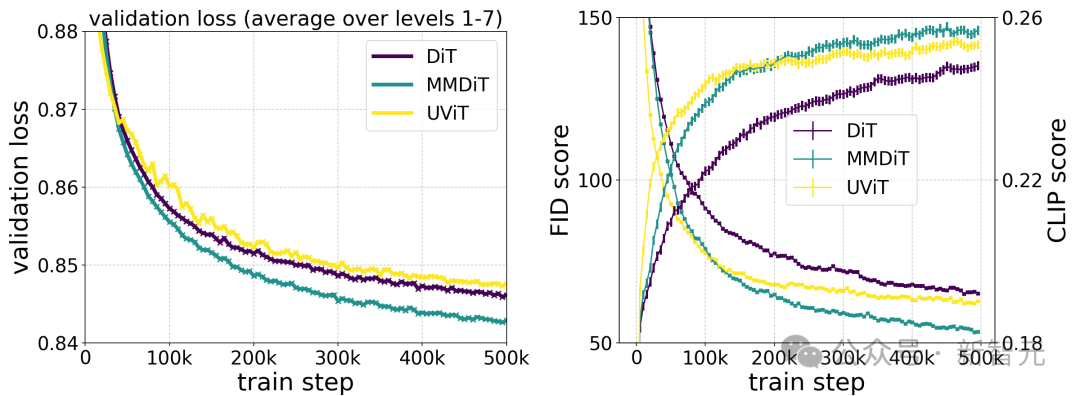
Stabilitäts-KI trainierte mehrere Modelle unterschiedlicher Größe, von 15 Modulen und 450 Millionen Parametern bis hin zu 38 Modulen und 8B Parametern, und stellte fest, dass sowohl die Modellgröße als auch die Trainingsschritte den Verifizierungsverlust reibungslos reduzieren können.
Um zu überprüfen, ob dies eine wesentliche Verbesserung der Modellausgabe bedeutete, bewerteten sie auch automatische Bildausrichtungsmetriken und menschliche Präferenzwerte.
Die Ergebnisse zeigen, dass diese Bewertungsindikatoren stark mit dem Verifizierungsverlust korrelieren, was darauf hinweist, dass der Verifizierungsverlust ein wirksamer Indikator zur Messung der Gesamtleistung des Modells ist.
Darüber hinaus hat dieser Expansionstrend noch keinen Sättigungspunkt erreicht, was uns optimistisch stimmt, dass wir die Modellleistung in Zukunft weiter verbessern können.
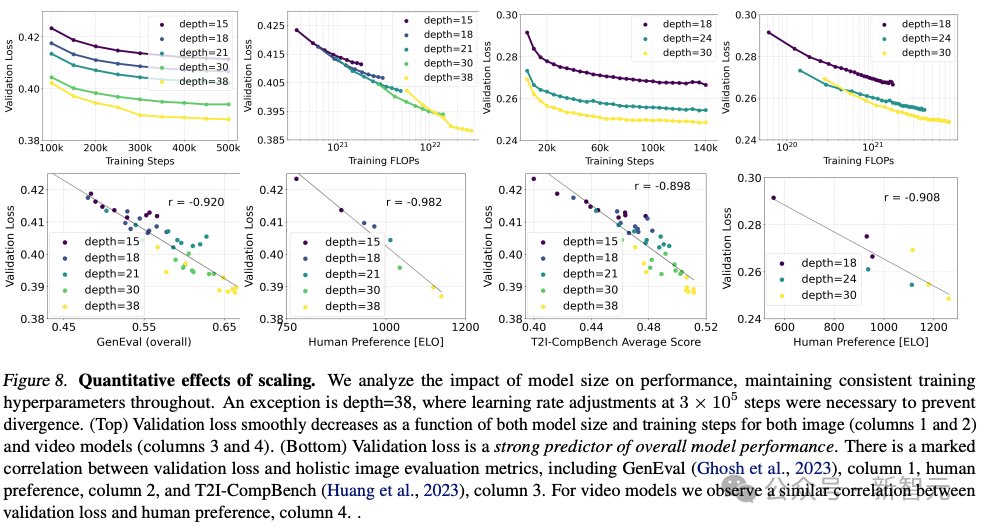
Der Autor hat das Modell für 500.000 Schritte mit unterschiedlicher Anzahl von Parametern bei einer Auflösung von 256 * 256 Pixeln und einer Stapelgröße von 4096 trainiert.

Die obige Abbildung veranschaulicht die Auswirkungen des Trainings eines größeren Modells über einen langen Zeitraum auf die Probenqualität.
Die obige Tabelle zeigt die Ergebnisse von GenEval. Bei Verwendung der von den Autoren vorgeschlagenen Trainingsmethode und Erhöhung der Auflösung der Trainingsbilder schnitt das größte Modell in den meisten Kategorien gut ab und übertraf DALL·E in der Gesamtpunktzahl um 3.
Laut dem Testvergleich verschiedener Architekturmodelle durch den Autor ist MMDiT sehr effektiv und übertrifft DiT, Cross DiT, UViT und MM-DiT.
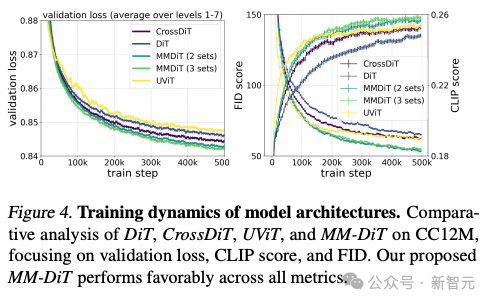
Flexibler Text-Encoder
Durch das Entfernen des speicherintensiven 4,7-B-Parameter-T5-Text-Encoders während der Inferenzphase werden die Speicheranforderungen von SD 3 bei minimalem Leistungsverlust erheblich reduziert.
Das Entfernen dieses Textencoders hat keinen Einfluss auf die visuelle Schönheit des Bildes (50 % Gewinnrate ohne T5), verringert jedoch nur geringfügig die Fähigkeit des Textes, genau zu folgen (46 % Gewinnrate).
Um jedoch die Fähigkeit von SD 3 zur Textgenerierung voll auszuschöpfen, empfiehlt der Autor dennoch die Verwendung des T5-Encoders.
Weil der Autor festgestellt hat, dass die Leistung beim Setzen von generiertem Text ohne sie stärker sinken würde (Gewinnquote 38 %).

Heiße Diskussion unter Internetnutzern
Die Internetnutzer sind ein wenig ungeduldig angesichts der ständigen Bemühungen von Stability AI, Benutzer zu ärgern, verweigern ihnen jedoch die Nutzung und fordern alle auf, es so schnell wie möglich online zu stellen.
Nachdem die Internetnutzer die technische Anwendung gelesen hatten, sagten sie, dass es den Anschein habe, dass der Fotografiekreis nun der erste Weg sein wird, in dem Open Source Closed Source vernichten wird!
Das obige ist der detaillierte Inhalt vonDer technische Bericht zu Stable Diffusion 3 ist durchgesickert, die Sora-Architektur hat wieder großartige Erfolge erzielt! Schlägt die Open-Source-Community gewaltsam gegen Midjourney und DALL·E 3 vor?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Mar 18, 2024 am 09:20 AM
Mar 18, 2024 am 09:20 AM
Heute möchte ich eine aktuelle Forschungsarbeit der University of Connecticut vorstellen, die eine Methode zum Abgleichen von Zeitreihendaten mit großen NLP-Modellen (Natural Language Processing) im latenten Raum vorschlägt, um die Leistung von Zeitreihenprognosen zu verbessern. Der Schlüssel zu dieser Methode besteht darin, latente räumliche Hinweise (Eingabeaufforderungen) zu verwenden, um die Genauigkeit von Zeitreihenvorhersagen zu verbessern. Titel des Papiers: S2IP-LLM: SemanticSpaceInformedPromptLearningwithLLMforTimeSeriesForecasting Download-Adresse: https://arxiv.org/pdf/2403.05798v1.pdf 1. Hintergrundmodell für große Probleme
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
