

Das Papier für Stable Diffusion 3 ist endlich da!
Dieses Modell wurde vor zwei Wochen veröffentlicht und nutzte die gleiche DiT-Architektur (Diffusion Transformer) wie Sora. Bei seiner Veröffentlichung sorgte es für großes Aufsehen.
Im Vergleich zur Vorgängerversion wurde die Qualität der von Stable Diffusion 3 generierten Bilder erheblich verbessert. Es unterstützt jetzt Eingabeaufforderungen mit mehreren Themen und der Textschreibeffekt wurde ebenfalls verbessert, sodass keine verstümmelten Zeichen mehr vorhanden sind.
Stability AI wies darauf hin, dass es sich bei Stable Diffusion 3 um eine Reihe von Modellen mit Parametergrößen im Bereich von 800M bis 8B handelt. Dieser Parameterbereich bedeutet, dass das Modell direkt auf vielen tragbaren Geräten ausgeführt werden kann, wodurch die Schwelle für die Verwendung großer KI-Modelle deutlich gesenkt wird.
In einem neu veröffentlichten Artikel sagt Stability AI, dass Stable Diffusion 3 bei auf menschlichen Präferenzen basierenden Bewertungen aktuelle hochmoderne Text-zu-Bild-Generierungssysteme wie DALL・E 3, Midjourney v6 übertrifft. und Ideogramm v1. In Kürze werden sie die experimentellen Daten, den Code und die Modellgewichte der Studie öffentlich zugänglich machen.
In dem Artikel enthüllte Stability AI weitere Details zu Stable Diffusion 3.

Für die Text-zu-Bild-Generierung muss das Stable Diffusion 3-Modell sowohl Text- als auch Bildmodi berücksichtigen. Daher nennen die Autoren des Papiers diese neue Architektur MMDiT und beziehen sich auf ihre Fähigkeit, mehrere Modalitäten zu verarbeiten. Wie bei früheren Versionen von Stable Diffusion verwenden die Autoren vorab trainierte Modelle, um geeignete Text- und Bilddarstellungen abzuleiten. Konkret verwendeten sie drei verschiedene Texteinbettungsmodelle – zwei CLIP-Modelle und T5 – zum Kodieren von Textdarstellungen und ein verbessertes Autokodierungsmodell zum Kodieren von Bildtokens.
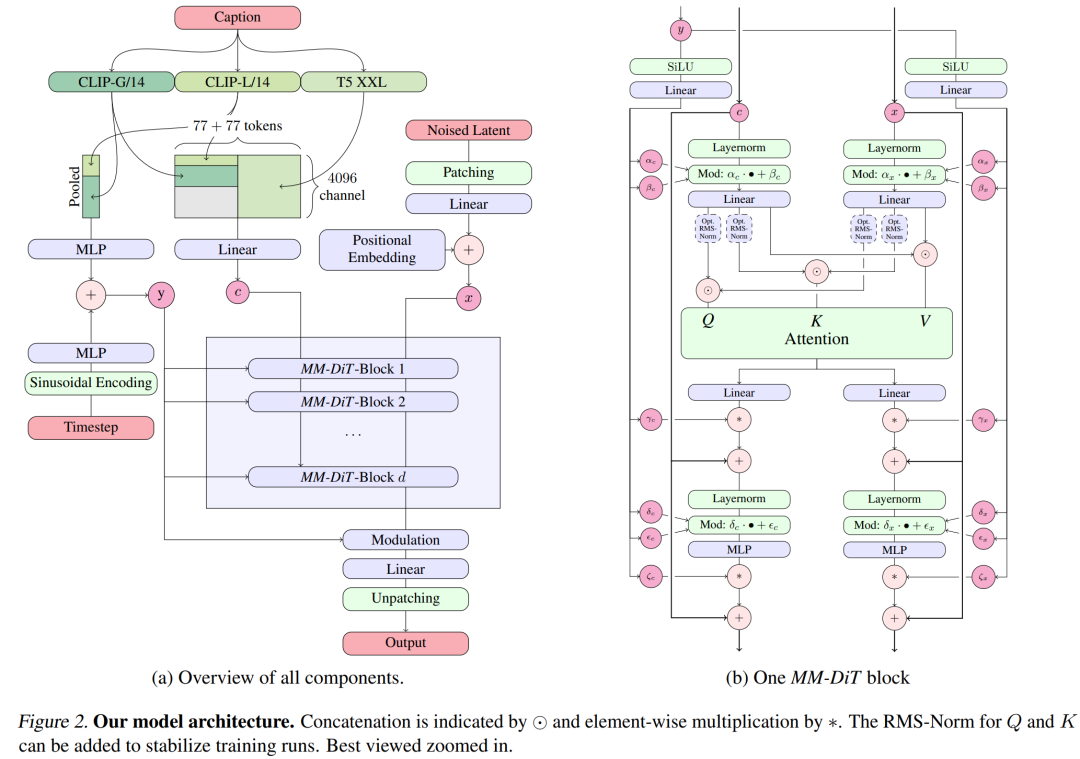
Stabile Diffusion 3-Modellarchitektur.
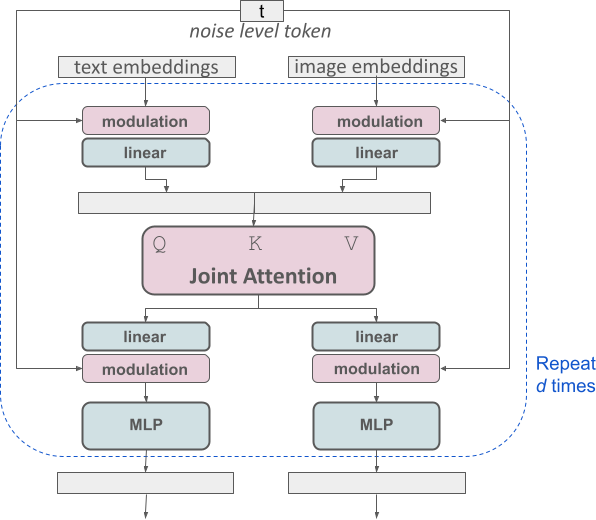
Verbesserter multimodaler Diffusionstransformator: MMDiT-Block.
Die SD3-Architektur basiert auf DiT, das von William Peebles, einem zentralen Forschungs- und Entwicklungsmitglied von Sora, und Xie Saining, Assistenzprofessor für Informatik an der New York University, vorgeschlagen wurde. Da Texteinbettung und Bildeinbettung konzeptionell sehr unterschiedlich sind, verwenden die Autoren von SD3 zwei unterschiedliche Gewichtungssätze für die beiden Modalitäten. Wie in der Abbildung oben gezeigt, entspricht dies der Einrichtung zweier unabhängiger Transformatoren für jede Modalität, wobei jedoch die Sequenzen der beiden Modalitäten für Aufmerksamkeitsoperationen kombiniert werden, sodass beide Darstellungen in ihrem eigenen Raum arbeiten können. Eine andere Darstellung wird ebenfalls berücksichtigt .
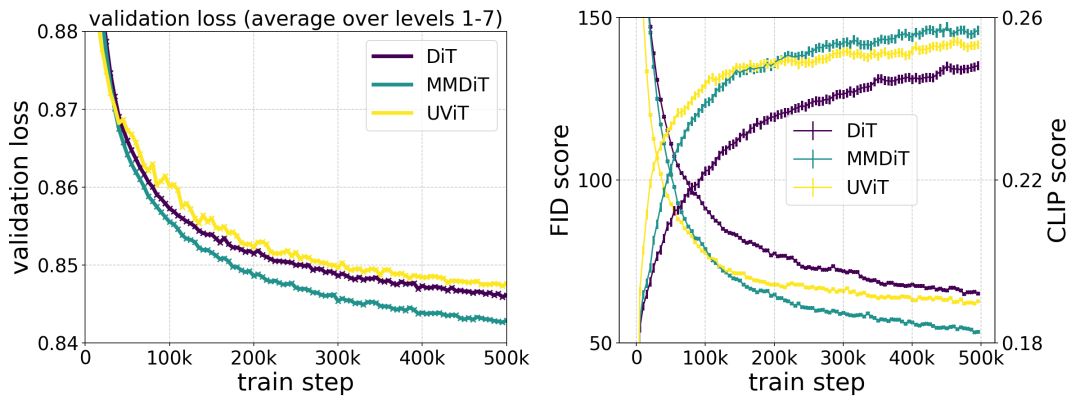
Die von den Autoren vorgeschlagene MMDiT-Architektur übertrifft etablierte Text-zu-Bild-Backbones wie UViT und DiT bei der Messung der visuellen Wiedergabetreue und der Textausrichtung während des Trainings.
Mit diesem Ansatz können Informationen zwischen Bildern und Text-Tokens fließen, wodurch das Gesamtverständnis des Modells verbessert und die Typografie der generierten Ausgabe verbessert wird. Wie im Artikel erläutert, lässt sich diese Architektur auch problemlos auf mehrere Modalitäten wie Video erweitern.

Dank der verbesserten Prompt-Following-Fähigkeiten von Stable Diffusion 3 ist das neue Modell in der Lage, Bilder zu produzieren, die sich auf eine Vielzahl unterschiedlicher Themen und Qualitäten konzentrieren, und ist gleichzeitig äußerst flexibel im Stil des Bildes selbst.

Stabile Diffusion 3 übernimmt die Gleichrichterflussformel (RF) Während des Trainingsprozesses werden die Daten und das Rauschen in einer linearen Flugbahn verbunden. Dadurch wird der Inferenzpfad gerader und die Abtastschritte werden reduziert. Darüber hinaus führen die Autoren während des Trainingsprozesses ein neues Trajektorien-Stichprobenschema ein. Sie stellten die Hypothese auf, dass der mittlere Teil der Flugbahn eine anspruchsvollere Vorhersageaufgabe darstellen würde, weshalb das Schema dem mittleren Teil der Flugbahn mehr Gewicht gab. Sie verglichen mehrere Datensätze, Metriken und Sampler-Einstellungen und testeten ihre vorgeschlagene Methode anhand von 60 anderen Diffusionsverläufen wie LDM, EDM und ADM. Die Ergebnisse zeigen, dass sich die Leistung früherer RF-Formulierungen zwar mit wenigen Probenahmeschritten verbessert, ihre relative Leistung jedoch mit zunehmender Anzahl von Schritten abnimmt. Im Gegensatz dazu verbessert die von den Autoren vorgeschlagene neugewichtete RF-Variante die Leistung kontinuierlich.
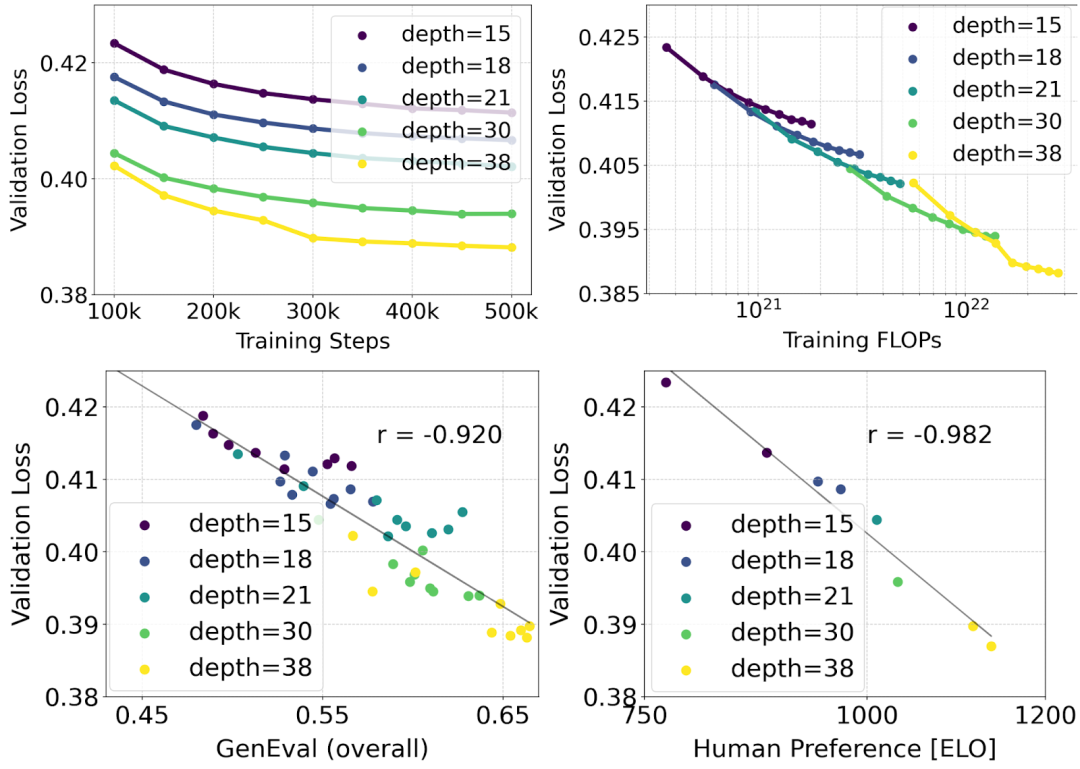
Der Autor führte eine Skalierungsforschung zur Text-zu-Bild-Synthese unter Verwendung der neu gewichteten Rectified Flow-Formel und des MMDiT-Grundgerüsts durch. Sie trainierten Modelle von 15 Blöcken mit 450 Millionen Parametern bis zu 38 Blöcken mit 8B Parametern und beobachteten, dass der Validierungsverlust mit zunehmender Modellgröße und Trainingsschritten gleichmäßig abnahm (erster Teil der Abbildung oben OK). Um zu untersuchen, ob dies zu sinnvollen Verbesserungen der Modellausgabe führte, bewerteten die Autoren auch die automatische Bildausrichtungsmetrik (GenEval) und den Human Preference Score (ELO) (zweite Zeile oben). Die Ergebnisse zeigen eine starke Korrelation zwischen diesen Metriken und dem Validierungsverlust, was darauf hindeutet, dass letzterer ein guter Prädiktor für die Gesamtleistung des Modells ist. Darüber hinaus zeigt der Skalierungstrend keine Anzeichen einer Sättigung, was die Autoren optimistisch stimmt, die Modellleistung in Zukunft weiter zu verbessern.
Durch Entfernen des speicherintensiven 4,7-B-Parameter-T5-Text-Encoders, der für die Inferenz verwendet wird, kann der Speicherbedarf von SD3 bei minimalem Leistungsverlust erheblich reduziert werden. Wie gezeigt, hat das Entfernen dieses Text-Encoders keine Auswirkungen auf die visuelle Ästhetik (50 % Gewinnrate ohne T5) und verringert die Textkonsistenz nur geringfügig (46 % Gewinnrate). Der Autor empfiehlt jedoch, T5 bei der Generierung von geschriebenem Text hinzuzufügen, um die Leistung von SD3 voll auszunutzen, da er beobachtet hat, dass ohne die Hinzufügung von T5 die Leistung beim Generieren von Schriftsätzen noch stärker abnahm (Gewinnrate 38 %), wie in der folgenden Abbildung dargestellt:

Nur bei der Präsentation sehr komplexer Eingabeaufforderungen mit vielen Details oder großen Textmengen führt die Entfernung von T5 zur Schlussfolgerung zu einer erheblichen Leistungseinbuße. Das Bild oben zeigt drei Zufallsstichproben jedes Beispiels.
Der Autor vergleicht die Ausgabebilder von Stable Diffusion 3 mit verschiedenen anderen Open-Source-Modellen (einschließlich SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 und Pixart-α) sowie Closed Source Modelle wie DALL-E 3, Midjourney v6 und Ideogram v1) wurden verglichen, um die Leistung basierend auf menschlichem Feedback zu bewerten. Bei diesen Tests erhalten menschliche Bewerter Beispiele für die Ausgabe jedes Modells und werden danach beurteilt, wie gut die Modellausgabe dem Kontext der gegebenen Eingabeaufforderung folgt (Eingabeaufforderung), wie gut der Text entsprechend der Eingabeaufforderung wiedergegeben wird (Typografie) und welche Bild Bilder mit höherer visueller Ästhetik werden ausgewählt, um die besten Ergebnisse zu erzielen.
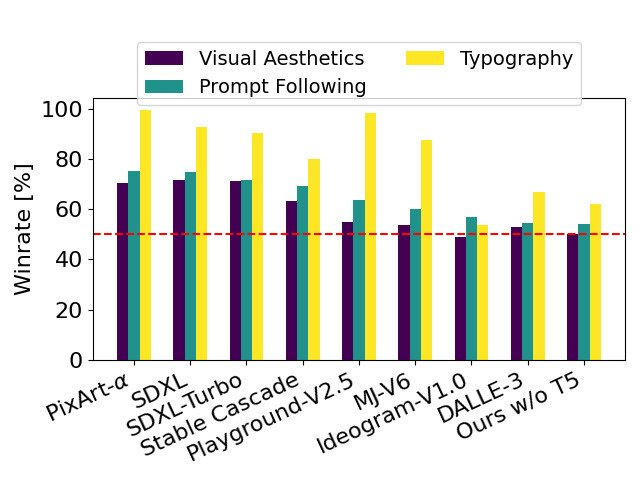
Dieses Diagramm wurde mit SD3 verglichen und zeigt die Erfolgsrate basierend auf der menschlichen Bewertung der visuellen Ästhetik, der Aufforderung zum Befolgen und des Textlayouts.
Anhand der Testergebnisse stellte der Autor fest, dass Stable Diffusion 3 in allen oben genannten Aspekten dem aktuellen, hochmodernen Text-zu-Bild-Generierungssystem gleichwertig oder sogar besser ist.
Bei frühen, nicht optimierten Inferenztests auf Consumer-Hardware passte das SD3-Modell mit dem größten 8B-Parameter in den 24-GB-VRAM der RTX 4090 und benötigte 34 Sekunden, um ein Bild mit einer Auflösung von 1024 x 1024 und 50 Abtastschritten zu erzeugen.

Darüber hinaus wird Stable Diffusion 3 bei der ersten Veröffentlichung in mehreren Varianten verfügbar sein, die von 800 m bis hin zu parametrischen 8B-Modellen reichen, um Hardware-Barrieren weiter zu beseitigen.


Weitere Einzelheiten finden Sie im Originalpapier.
Referenzlink: https://stability.ai/news/stable-diffusion-3-research-paper
Das obige ist der detaillierte Inhalt vonDas Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
 So stellen Sie dauerhaft gelöschte Dateien auf dem Computer wieder her
So stellen Sie dauerhaft gelöschte Dateien auf dem Computer wieder her
 So überprüfen Sie den Videospeicher von Win11
So überprüfen Sie den Videospeicher von Win11
 So starten Sie regelmäßig neu
So starten Sie regelmäßig neu
 Verwendung der Instr-Funktion
Verwendung der Instr-Funktion
 Der Unterschied zwischen MS-Karte und SD-Karte
Der Unterschied zwischen MS-Karte und SD-Karte
 Browser-Kompatibilität
Browser-Kompatibilität
 Verwendung der Sortierfunktion c++sort
Verwendung der Sortierfunktion c++sort








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



