
 Technologie-Peripheriegeräte
KI
ICLR 2024 |. Um eine neue Perspektive für die Audio- und Videotrennung zu bieten, hat das Hu Xiaolin-Team der Tsinghua-Universität RTFS-Net ins Leben gerufen
Technologie-Peripheriegeräte
KI
ICLR 2024 |. Um eine neue Perspektive für die Audio- und Videotrennung zu bieten, hat das Hu Xiaolin-Team der Tsinghua-Universität RTFS-Net ins Leben gerufen
ICLR 2024 |. Um eine neue Perspektive für die Audio- und Videotrennung zu bieten, hat das Hu Xiaolin-Team der Tsinghua-Universität RTFS-Net ins Leben gerufen

Der Hauptzweck der AVSS-Technologie (Audiovisual Speech Separation) besteht darin, die Stimme des Zielsprechers im gemischten Signal zu identifizieren und zu trennen und dabei Gesichtsinformationen zu verwenden, um dieses Ziel zu erreichen. Diese Technologie findet vielfältige Anwendungsmöglichkeiten in zahlreichen Bereichen, darunter intelligente Assistenten, Fernkonferenzen und Augmented Reality. Durch die AVSS-Technologie kann die Qualität von Sprachsignalen in lauten Umgebungen erheblich verbessert und dadurch die Wirkung der Spracherkennung und Kommunikation verbessert werden. Die Entwicklung dieser Technologie hat das tägliche Leben und die Arbeit der Menschen komfortabler gemacht und es einfacher gemacht,
Herkömmliche audiovisuelle Sprachtrennungsmethoden erfordern normalerweise komplexe Modelle und eine große Menge an Rechenressourcen, insbesondere wenn es viele oder viele laute Hintergründe gibt In diesem Fall ist die Leistung leicht eingeschränkt. Um diese Probleme zu überwinden, begannen Forscher, Methoden zu erforschen, die auf Deep Learning basieren. Die bestehende Deep-Learning-Technologie weist jedoch die Herausforderungen einer hohen Rechenkomplexität und Schwierigkeiten bei der Anpassung an unbekannte Umgebungen auf.
Insbesondere weisen die aktuellen audiovisuellen Sprachtrennungsmethoden die folgenden Probleme auf:
Zeitbereichsmethode: Sie kann qualitativ hochwertige Audiotrennungseffekte liefern, aber aufgrund mehr Parameter ist die Berechnungskomplexität höher und die Verarbeitungsgeschwindigkeit höher ist langsamer.
Methoden im Zeit-Frequenz-Bereich: recheneffizienter, weisen jedoch in der Vergangenheit im Vergleich zu Methoden im Zeitbereich eine schlechte Leistung auf. Sie stehen vor drei Hauptherausforderungen:
1. Mangel an unabhängiger Modellierung von Zeit- und Frequenzdimensionen.
2. Visuelle Hinweise aus mehreren rezeptiven Feldern werden nicht vollständig zur Verbesserung der Modellleistung genutzt.
3. Eine unsachgemäße Verarbeitung komplexer Merkmale führt zum Verlust wichtiger Amplituden- und Phaseninformationen.
Um diese Herausforderungen zu bewältigen, schlugen Forscher des Teams von außerordentlichem Professor Hu Xiaolin von der Tsinghua-Universität ein neues audiovisuelles Sprachtrennungsmodell namens RTFS-Net vor. Das Modell verwendet eine Komprimierungs-Rekonstruktionsmethode, die die Rechenkomplexität und die Anzahl der Parameter des Modells erheblich reduziert und gleichzeitig die Trennleistung verbessert. RTFS-Net ist die erste audiovisuelle Sprachtrennungsmethode, die weniger als 1 Million Parameter verwendet, und es ist auch die erste Methode, die alle Zeitdomänenmodelle bei der multimodalen Trennung im Zeit-Frequenzbereich übertrifft.

Papieradresse: https://arxiv.org/abs/2309.17189
Papierhomepage: https://cslikai.cn/RTFS-Net/AV-Model-Demo.html
-
Codeadresse: https://github.com/spkgyk/RTFS-Net (bald verfügbar)
Einführung in die Methode
Die gesamte Netzwerkarchitektur von RTFS-Net ist in Abbildung 1 unten dargestellt:
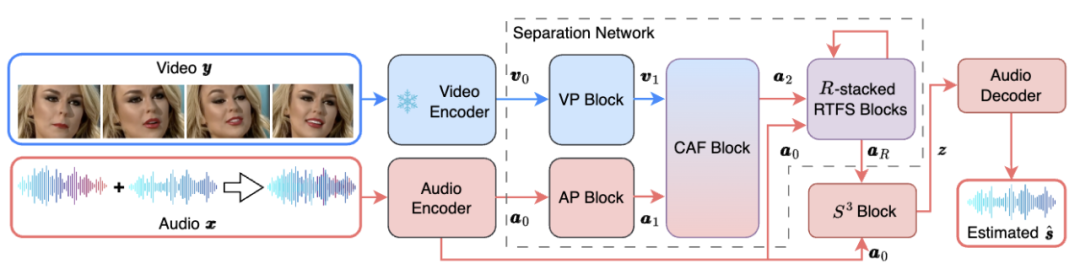
Abbildung 1. Netzwerk-Framework von RTFS-NET
Unter ihnen komprimiert der RTFS-Block (gezeigt in Abbildung 2) und modelliert unabhängig die akustischen Abmessungen (Zeit und Frequenz) und versucht, einen Unterraum mit niedriger Komplexität zu erstellen versuchen, den Informationsverlust zu reduzieren. Insbesondere verwendet der RTFS-Block eine Dual-Path-Architektur für die effiziente Verarbeitung von Audiosignalen sowohl in Zeit- als auch in Frequenzdimensionen. Mit diesem Ansatz können RTFS-Blöcke die Rechenkomplexität reduzieren und gleichzeitig eine hohe Empfindlichkeit und Genauigkeit für Audiosignale beibehalten. Das Folgende ist der spezifische Arbeitsablauf des RTFS-Blocks:
1 Zeit-Frequenz-Komprimierung: Der RTFS-Block komprimiert zunächst die Eingabeaudiofunktionen in den Zeit- und Frequenzdimensionen.
2. Unabhängige Dimensionsmodellierung: Nach Abschluss der Komprimierung modelliert der RTFS-Block unabhängig die Zeit- und Frequenzdimensionen.
3. Dimensionsfusion: Nach der unabhängigen Verarbeitung der Zeit- und Frequenzdimensionen führt der RTFS-Block die Informationen der beiden Dimensionen über ein Fusionsmodul zusammen.
4. Rekonstruktion und Ausgabe: Schließlich werden die fusionierten Merkmale durch eine Reihe von Entfaltungsschichten wieder in den ursprünglichen Zeit-Frequenz-Raum rekonstruiert.
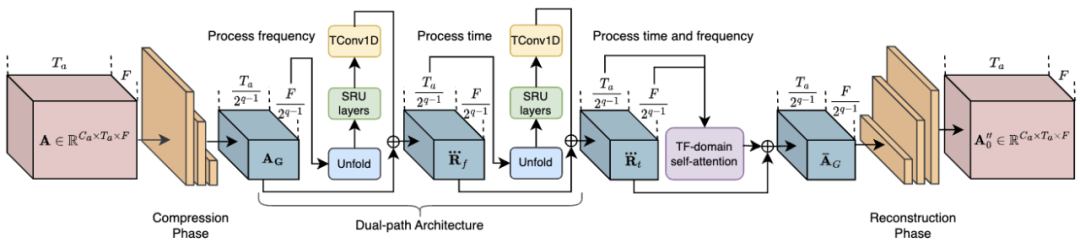
Abbildung 2. Netzwerkstruktur des RTFS-Blocks
Das Cross-Dimensional Attention Fusion (CAF)-Modul (dargestellt in Abbildung 3) führt effektiv Audio- und visuelle Informationen zusammen, verbessert den Sprachtrennungseffekt und reduziert die Rechenkomplexität Es beträgt nur 1,3 % der bisherigen SOTA-Methode. Insbesondere generiert das CAF-Modul zunächst Aufmerksamkeitsgewichte mithilfe von Tiefen- und gruppierten Faltungsoperationen. Diese Gewichtungen passen sich dynamisch an die Bedeutung der Eingabemerkmale an, sodass sich das Modell auf die relevantesten Informationen konzentrieren kann. Durch die Anwendung der generierten Aufmerksamkeitsgewichtungen auf visuelle und auditive Merkmale ist das CAF-Modul dann in der Lage, sich auf Schlüsselinformationen in mehreren Dimensionen zu konzentrieren. In diesem Schritt werden Features unterschiedlicher Dimension gewichtet und zusammengeführt, um eine umfassende Feature-Darstellung zu erstellen. Zusätzlich zum Aufmerksamkeitsmechanismus kann das CAF-Modul auch einen Gating-Mechanismus übernehmen, um den Grad der Fusion von Merkmalen aus verschiedenen Quellen weiter zu steuern. Dieser Ansatz kann die Flexibilität des Modells erhöhen und eine feinere Steuerung des Informationsflusses ermöglichen.
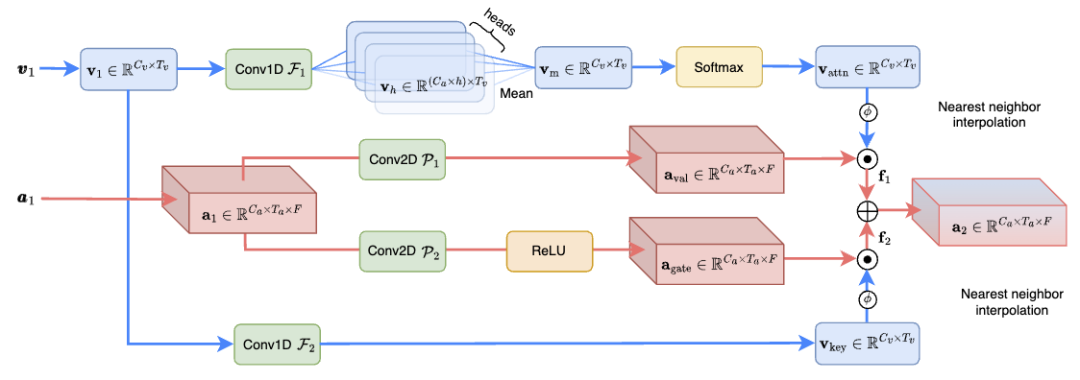
Abbildung 3. Schematisches Strukturdiagramm des CAF -Fusionsmoduls
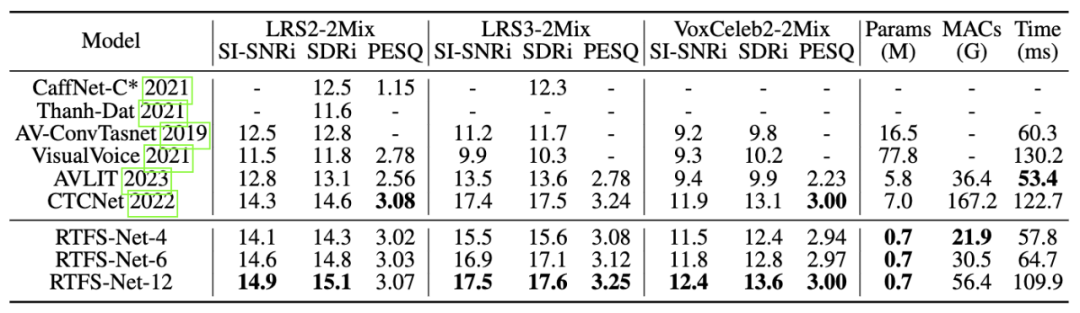
Das Entwurfskonzept der Spektrumquellenabteilung (S^3) besteht darin, die durch komplexen Zahlen dargestellten Spektralinformationen zu verwenden, um die Sprache effektiv zu extrahieren des Ziellautsprechers aus der Mixed-Audio-Funktion. Diese Methode nutzt die Phasen- und Amplitudeninformationen des Audiosignals vollständig aus und verbessert so die Genauigkeit und Effizienz der Quellentrennung. Und die Verwendung eines komplexen Netzwerks ermöglicht es dem S^3-Block, das Signal bei der Isolierung der Sprache des Zielsprechers genauer zu verarbeiten, insbesondere durch die Beibehaltung von Details und die Reduzierung von Artefakten, wie unten gezeigt. Ebenso ermöglicht das Design des S^3-Blocks eine einfache Integration in verschiedene Audioverarbeitungs-Frameworks, eignet sich für eine Vielzahl von Aufgaben zur Quellentrennung und verfügt über gute Generalisierungsfähigkeiten. Experimentelle Ergebnisse Komplexität, die sich dem aktuellen Stand der Technik annähert oder diese übertrifft. Der Kompromiss zwischen Effizienz und Leistung wird anhand von Varianten mit unterschiedlicher Anzahl von RTFS-Blöcken (4, 6, 12 Blöcke) demonstriert, wobei RTFS-Net-6 ein gutes Gleichgewicht zwischen Leistung und Effizienz bietet. RTFS-Net-12 schnitt bei allen getesteten Datensätzen am besten ab und bewies die Vorteile von Zeit-Frequenz-Domänenmethoden bei der Bewältigung komplexer Aufgaben zur Trennung von Audio- und Videosynchronisation.
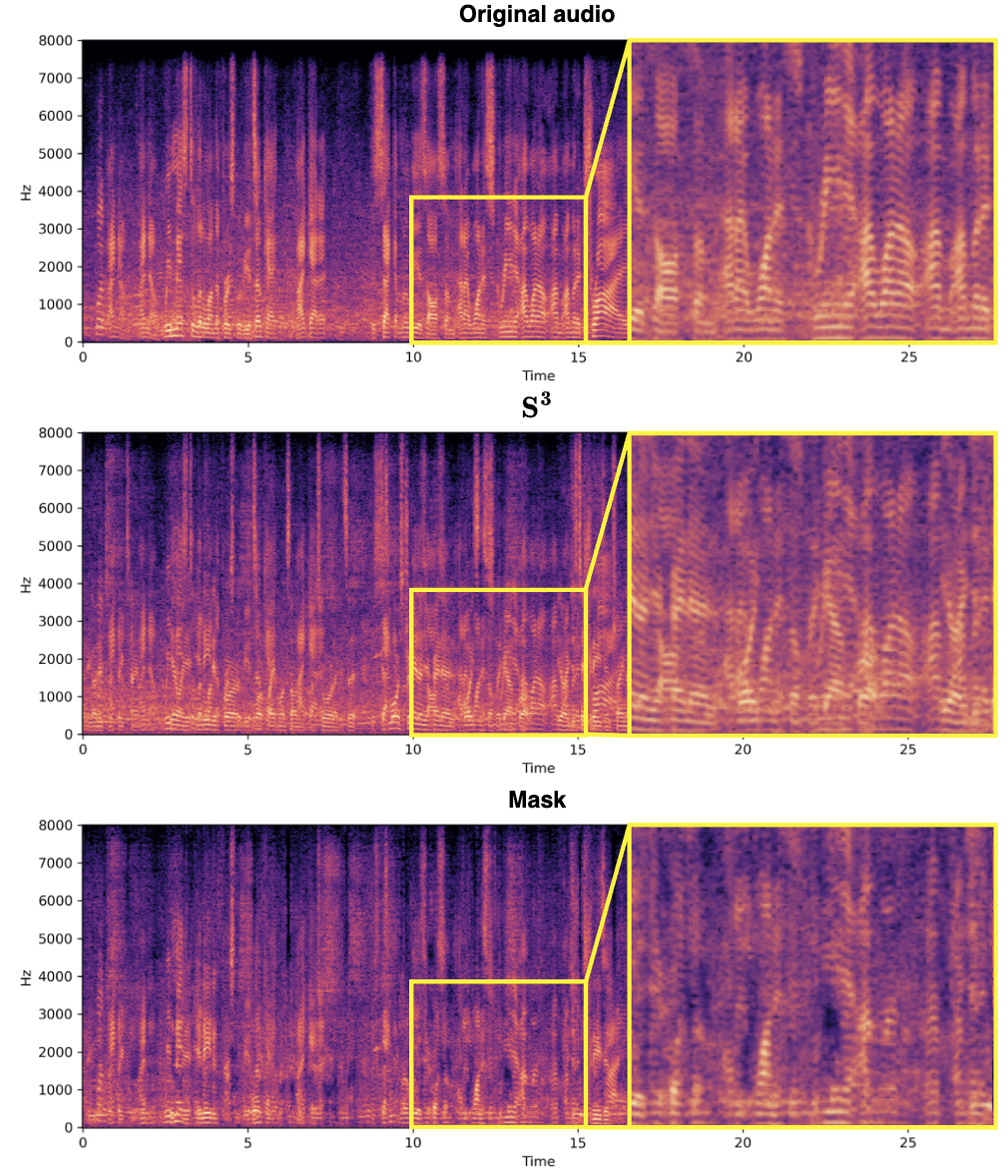
Echte Effekte
Gemischtes Video: Audio für weibliche Sprecher:
Audio für männliche Sprecher:
Zusammenfassung
Mit dem Kontinuierliche Weiterentwicklung der großen Modelltechnologieentwicklung, audiovisuelle Die Auch im Bereich der Sprachtrennung werden große Modelle zur Verbesserung der Trennqualität verfolgt. Für Endgeräte ist dies jedoch nicht realisierbar. RTFS-Net erzielt erhebliche Leistungsverbesserungen bei gleichzeitig deutlich reduzierter Rechenkomplexität und Anzahl der Parameter. Dies zeigt, dass eine Verbesserung der AVSS-Leistung nicht unbedingt größere Modelle erfordert, sondern vielmehr innovative, effiziente Architekturen, die das komplexe Zusammenspiel zwischen Audio- und visuellen Modalitäten besser erfassen.
Das obige ist der detaillierte Inhalt vonICLR 2024 |. Um eine neue Perspektive für die Audio- und Videotrennung zu bieten, hat das Hu Xiaolin-Team der Tsinghua-Universität RTFS-Net ins Leben gerufen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1206
24
52
1206
24

 Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Aber vielleicht kann er den alten Mann im Park nicht besiegen? Die Olympischen Spiele in Paris sind in vollem Gange und Tischtennis hat viel Aufmerksamkeit erregt. Gleichzeitig haben Roboter auch beim Tischtennisspielen neue Durchbrüche erzielt. Gerade hat DeepMind den ersten lernenden Roboteragenten vorgeschlagen, der das Niveau menschlicher Amateurspieler im Tischtennis-Wettkampf erreichen kann. Papieradresse: https://arxiv.org/pdf/2408.03906 Wie gut ist der DeepMind-Roboter beim Tischtennisspielen? Vermutlich auf Augenhöhe mit menschlichen Amateurspielern: Sowohl Vorhand als auch Rückhand: Der Gegner nutzt unterschiedliche Spielstile, und auch der Roboter hält aus: Aufschlagannahme mit unterschiedlichem Spin: Allerdings scheint die Intensität des Spiels nicht so intensiv zu sein wie Der alte Mann im Park. Für Roboter, Tischtennis
 Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Am 21. August fand in Peking die Weltroboterkonferenz 2024 im großen Stil statt. Die Heimrobotermarke „Yuanluobot SenseRobot“ von SenseTime hat ihre gesamte Produktfamilie vorgestellt und kürzlich den Yuanluobot AI-Schachspielroboter – Chess Professional Edition (im Folgenden als „Yuanluobot SenseRobot“ bezeichnet) herausgebracht und ist damit der weltweit erste A-Schachroboter für heim. Als drittes schachspielendes Roboterprodukt von Yuanluobo hat der neue Guoxiang-Roboter eine Vielzahl spezieller technischer Verbesserungen und Innovationen in den Bereichen KI und Maschinenbau erfahren und erstmals die Fähigkeit erkannt, dreidimensionale Schachfiguren aufzunehmen B. durch mechanische Klauen an einem Heimroboter, und führen Sie Mensch-Maschine-Funktionen aus, z. B. Schach spielen, jeder spielt Schach, Überprüfung der Notation usw.
 Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Der Schulstart steht vor der Tür und nicht nur die Schüler, die bald ins neue Semester starten, sollten auf sich selbst aufpassen, sondern auch die großen KI-Modelle. Vor einiger Zeit war Reddit voller Internetnutzer, die sich darüber beschwerten, dass Claude faul werde. „Sein Niveau ist stark gesunken, es kommt oft zu Pausen und sogar die Ausgabe wird sehr kurz. In der ersten Woche der Veröffentlichung konnte es ein komplettes 4-seitiges Dokument auf einmal übersetzen, aber jetzt kann es nicht einmal eine halbe Seite ausgeben.“ !
 Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der World Robot Conference in Peking ist die Präsentation humanoider Roboter zum absoluten Mittelpunkt der Szene geworden. Am Stand von Stardust Intelligent führte der KI-Roboterassistent S1 drei große Darbietungen mit Hackbrett, Kampfkunst und Kalligraphie auf Ein Ausstellungsbereich, der sowohl Literatur als auch Kampfkunst umfasst, zog eine große Anzahl von Fachpublikum und Medien an. Durch das elegante Spiel auf den elastischen Saiten demonstriert der S1 eine feine Bedienung und absolute Kontrolle mit Geschwindigkeit, Kraft und Präzision. CCTV News führte einen Sonderbericht über das Nachahmungslernen und die intelligente Steuerung hinter „Kalligraphie“ durch. Firmengründer Lai Jie erklärte, dass hinter den seidenweichen Bewegungen die Hardware-Seite die beste Kraftkontrolle und die menschenähnlichsten Körperindikatoren (Geschwindigkeit, Belastung) anstrebt. usw.), aber auf der KI-Seite werden die realen Bewegungsdaten von Menschen gesammelt, sodass der Roboter stärker werden kann, wenn er auf eine schwierige Situation stößt, und lernen kann, sich schnell weiterzuentwickeln. Und agil
 Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bei dieser ACL-Konferenz haben die Teilnehmer viel gewonnen. Die sechstägige ACL2024 findet in Bangkok, Thailand, statt. ACL ist die führende internationale Konferenz im Bereich Computerlinguistik und Verarbeitung natürlicher Sprache. Sie wird von der International Association for Computational Linguistics organisiert und findet jährlich statt. ACL steht seit jeher an erster Stelle, wenn es um akademischen Einfluss im Bereich NLP geht, und ist außerdem eine von der CCF-A empfohlene Konferenz. Die diesjährige ACL-Konferenz ist die 62. und hat mehr als 400 innovative Arbeiten im Bereich NLP eingereicht. Gestern Nachmittag gab die Konferenz den besten Vortrag und weitere Auszeichnungen bekannt. Diesmal gibt es 7 Best Paper Awards (zwei davon unveröffentlicht), 1 Best Theme Paper Award und 35 Outstanding Paper Awards. Die Konferenz verlieh außerdem drei Resource Paper Awards (ResourceAward) und einen Social Impact Award (
 Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Heute Nachmittag begrüßte Hongmeng Zhixing offiziell neue Marken und neue Autos. Am 6. August veranstaltete Huawei die Hongmeng Smart Xingxing S9 und die Huawei-Konferenz zur Einführung neuer Produkte mit umfassendem Szenario und brachte die Panorama-Smart-Flaggschiff-Limousine Xiangjie S9, das neue M7Pro und Huawei novaFlip, MatePad Pro 12,2 Zoll, das neue MatePad Air und Huawei Bisheng mit Mit vielen neuen Smart-Produkten für alle Szenarien, darunter die Laserdrucker der X1-Serie, FreeBuds6i, WATCHFIT3 und der Smart Screen S5Pro, von Smart Travel über Smart Office bis hin zu Smart Wear baut Huawei weiterhin ein Smart-Ökosystem für alle Szenarien auf, um Verbrauchern ein Smart-Erlebnis zu bieten Internet von allem. Hongmeng Zhixing: Huawei arbeitet mit chinesischen Partnern aus der Automobilindustrie zusammen, um die Modernisierung der Smart-Car-Industrie voranzutreiben
 Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, der Vater des Reinforcement Learning, wird teilnehmen! Yan Shuicheng, Sergey Levine und DeepMind-Wissenschaftler werden Grundsatzreden halten
Aug 22, 2024 pm 08:02 PM
Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, der Vater des Reinforcement Learning, wird teilnehmen! Yan Shuicheng, Sergey Levine und DeepMind-Wissenschaftler werden Grundsatzreden halten
Aug 22, 2024 pm 08:02 PM
Einleitung zur Konferenz Mit der rasanten Entwicklung von Wissenschaft und Technologie ist künstliche Intelligenz zu einer wichtigen Kraft bei der Förderung des sozialen Fortschritts geworden. In dieser Zeit haben wir das Glück, die Innovation und Anwendung der verteilten künstlichen Intelligenz (DAI) mitzuerleben und daran teilzuhaben. Verteilte Künstliche Intelligenz ist ein wichtiger Zweig des Gebiets der Künstlichen Intelligenz, der in den letzten Jahren immer mehr Aufmerksamkeit erregt hat. Durch die Kombination des leistungsstarken Sprachverständnisses und der Generierungsfähigkeiten großer Modelle sind plötzlich Agenten aufgetaucht, die auf natürlichen Sprachinteraktionen, Wissensbegründung, Aufgabenplanung usw. basieren. AIAgent übernimmt das große Sprachmodell und ist zu einem heißen Thema im aktuellen KI-Kreis geworden. Au
 Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Tiefe Integration von Vision und Roboterlernen. Wenn zwei Roboterhände reibungslos zusammenarbeiten, um Kleidung zu falten, Tee einzuschenken und Schuhe zu packen, gepaart mit dem humanoiden 1X-Roboter NEO, der in letzter Zeit für Schlagzeilen gesorgt hat, haben Sie vielleicht das Gefühl: Wir scheinen in das Zeitalter der Roboter einzutreten. Tatsächlich sind diese seidigen Bewegungen das Produkt fortschrittlicher Robotertechnologie + exquisitem Rahmendesign + multimodaler großer Modelle. Wir wissen, dass nützliche Roboter oft komplexe und exquisite Interaktionen mit der Umgebung erfordern und die Umgebung als Einschränkungen im räumlichen und zeitlichen Bereich dargestellt werden kann. Wenn Sie beispielsweise möchten, dass ein Roboter Tee einschenkt, muss der Roboter zunächst den Griff der Teekanne ergreifen und sie aufrecht halten, ohne den Tee zu verschütten, und ihn dann sanft bewegen, bis die Öffnung der Kanne mit der Öffnung der Tasse übereinstimmt , und neigen Sie dann die Teekanne in einem bestimmten Winkel. Das
