
 Technologie-Peripheriegeräte
KI
Google veröffentlicht die neueste KI zum „Bildschirmlesen'! PaLM 2-S generiert automatisch Daten und mehrere Verständnisaufgaben aktualisieren SOTA
Technologie-Peripheriegeräte
KI
Google veröffentlicht die neueste KI zum „Bildschirmlesen'! PaLM 2-S generiert automatisch Daten und mehrere Verständnisaufgaben aktualisieren SOTA
Google veröffentlicht die neueste KI zum „Bildschirmlesen'! PaLM 2-S generiert automatisch Daten und mehrere Verständnisaufgaben aktualisieren SOTA

Das große Modell, das sich jeder wünscht, ist wirklich intelligent …
Nein, das Google-Team hat eine leistungsstarke KI zum „Bildschirmlesen“ entwickelt.
Die Forscher nennen es ScreenAI, ein neues visuelles Sprachmodell zum Verständnis von Benutzeroberflächen und Infografiken.

Papieradresse: https://arxiv.org/pdf/2402.04615.pdf Der Kern von ScreenAI ist eine neue Methode zur Darstellung von Screenshot-Texten, die den Typ und die Position von UI-Elementen identifizieren kann.
Die Forscher verwendeten das Google-Sprachmodell PaLM 2-S, um synthetische Trainingsdaten zu generieren, mit denen das Modell trainiert wurde, Fragen zu Bildschirminformationen, Bildschirmnavigation und Zusammenfassung des Bildschirminhalts zu beantworten. Erwähnenswert ist, dass diese Methode neue Ideen zur Verbesserung der Leistung des Modells bei der Bearbeitung bildschirmbezogener Aufgaben liefert.
Wenn Sie beispielsweise eine Musik-APP-Seite öffnen, können Sie fragen: „Wie viele Songs sind weniger als 30 Sekunden lang?“? 
ScreenAI gibt eine einfache Antwort: 1.
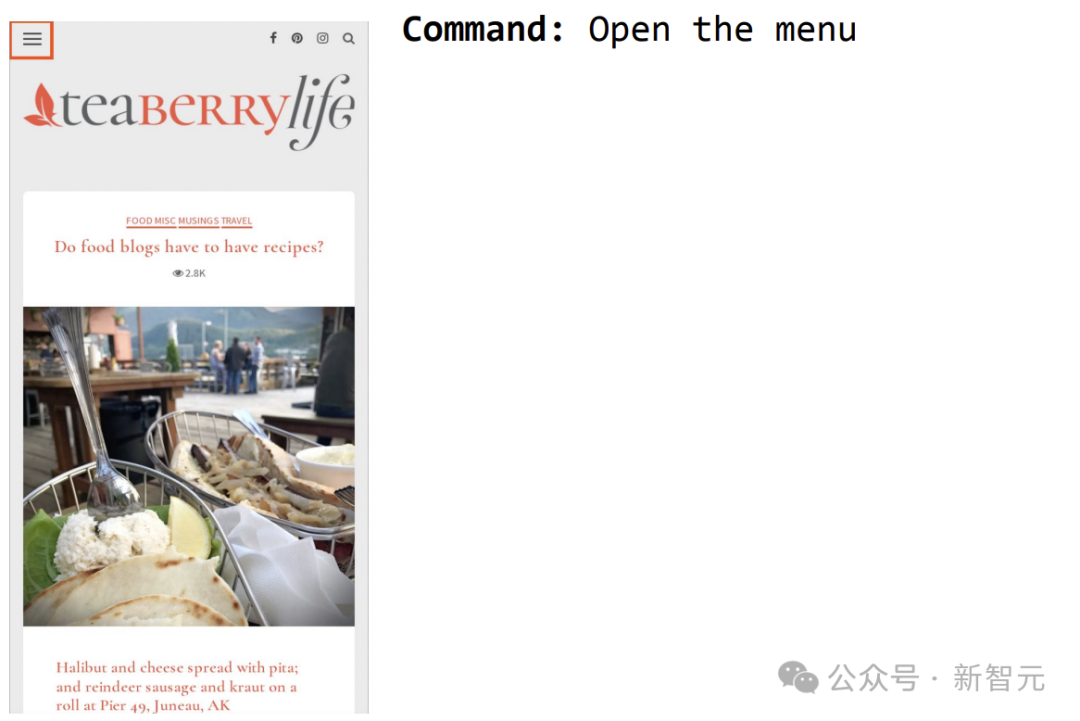
Ein weiteres Beispiel besteht darin, ScreenAI zu befehlen, das Menü zu öffnen und Sie können es auswählen. 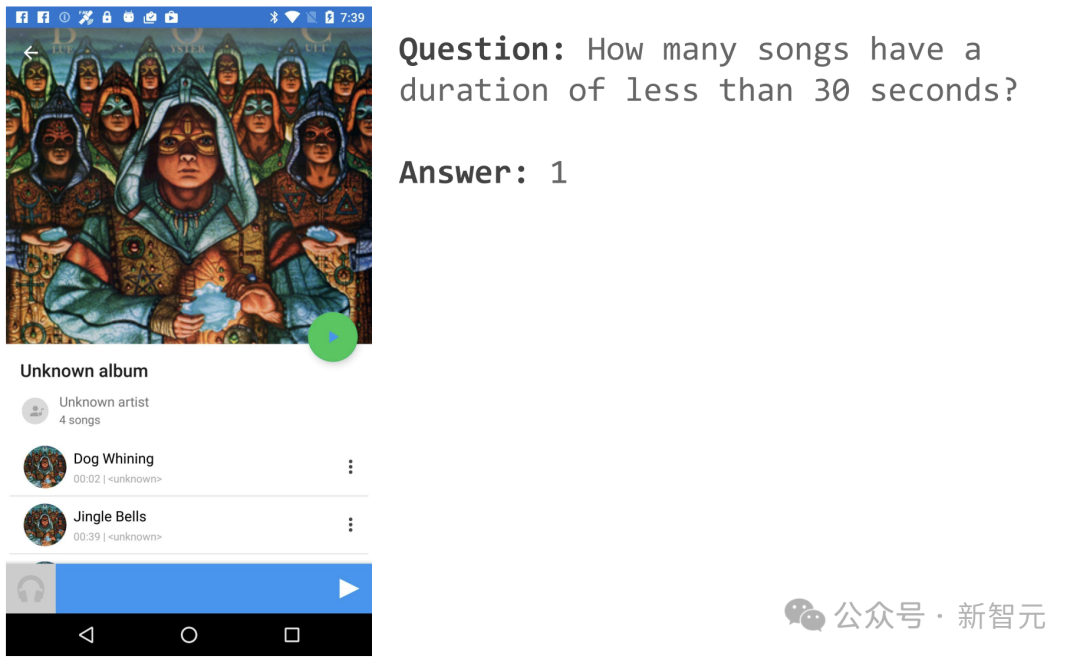
 Quelle der Architekturinspiration – PaLI
Quelle der Architekturinspiration – PaLI
Abbildung 1 zeigt die ScreenAI-Modellarchitektur. Inspiriert wurden die Forscher von der Architektur der PaLI-Modellfamilie, die aus einem multimodalen Encoderblock besteht.
Der Encoderblock enthält einen ViT-ähnlichen visuellen Encoder und einen mT5-Sprachencoder, der Bild- und Texteingaben verarbeitet, gefolgt von einem autoregressiven Decoder.
Das Eingabebild wird vom visuellen Encoder in eine Reihe von Einbettungen umgewandelt, die mit der Eingabetexteinbettung kombiniert und zusammen in den mT5-Sprachencoder eingespeist werden.
Die Ausgabe des Encoders wird an den Decoder weitergeleitet, der eine Textausgabe generiert.
Diese verallgemeinerte Formulierung kann dieselbe Modellarchitektur verwenden, um verschiedene visuelle und multimodale Aufgaben zu lösen. Diese Aufgaben können als Text+Bild-Probleme (Eingabe) in Text-Probleme (Ausgabe) umformuliert werden.
Im Vergleich zur Texteingabe machen Bildeinbettungen einen erheblichen Teil der Eingabelänge für multimodale Encoder aus.
Kurz gesagt: Dieses Modell verwendet einen Bild-Encoder und einen Sprach-Encoder, um Bild- und Textmerkmale zu extrahieren, die beiden zu verschmelzen und sie dann in den Decoder einzugeben, um Text zu generieren.
Diese Konstruktionsmethode kann in großem Umfang auf multimodale Aufgaben wie das Bildverständnis angewendet werden.
Darüber hinaus erweiterten die Forscher die Encoder-Decoder-Architektur von PaLI weiter, um verschiedene Bildblockierungsmodi zu akzeptieren. 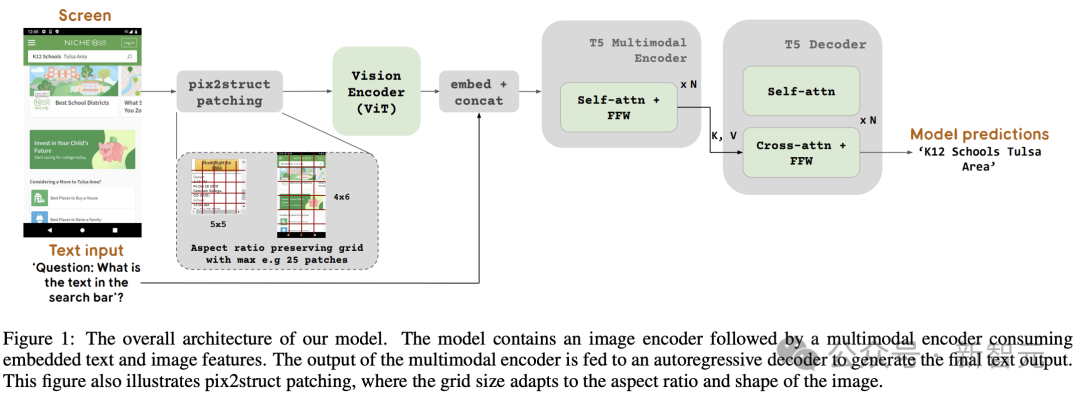
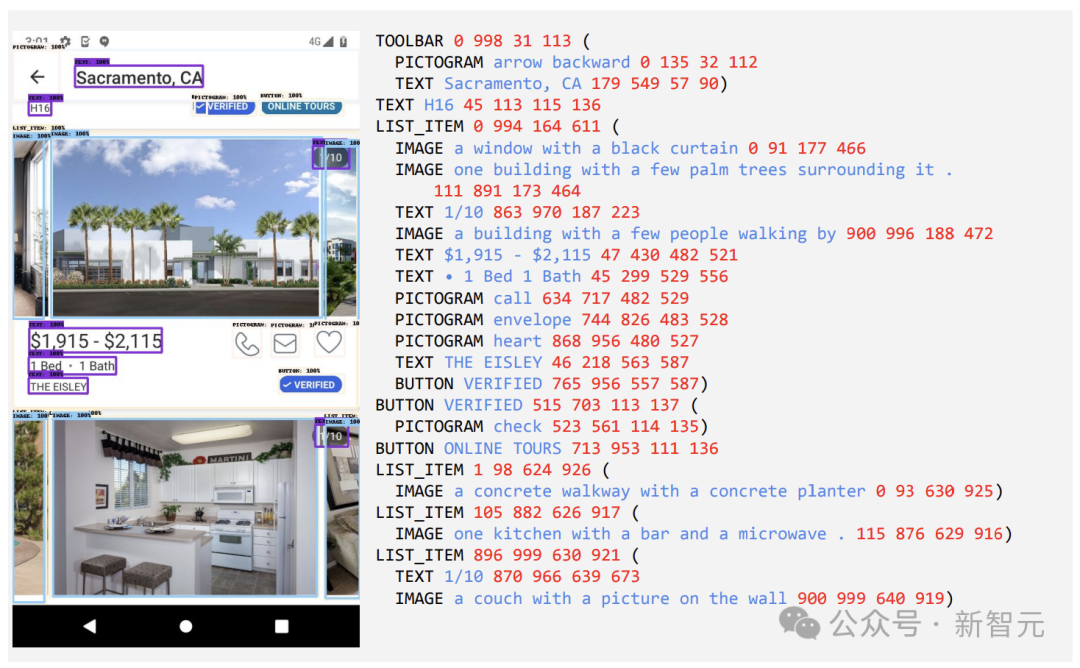
Die ursprüngliche PaLI-Architektur akzeptiert nur Bildfelder in einem festen Rastermuster, um Eingabebilder zu verarbeiten. Forscher im Bildschirmbereich stoßen jedoch auf Daten, die eine Vielzahl von Auflösungen und Seitenverhältnissen umfassen.
Damit sich ein einzelnes Modell an alle Bildschirmformen anpassen kann, muss eine Kachelstrategie verwendet werden, die für Bilder verschiedener Formen funktioniert.
Zu diesem Zweck hat sich das Google-Team eine in Pix2Struct eingeführte Technologie ausgeliehen, die die Generierung beliebiger gitterförmiger Bildblöcke basierend auf der Eingabebildform und einer vordefinierten maximalen Anzahl von Blöcken ermöglicht, wie in Abbildung 1 dargestellt.
Dies ist in der Lage, sich an eingegebene Bilder in verschiedenen Formaten und Seitenverhältnissen anzupassen, ohne dass das Bild aufgefüllt oder gestreckt werden muss, um seine Form zu fixieren. Dadurch wird das Modell vielseitiger und eignet sich sowohl für Mobilgeräte (d. h. Hochformat) als auch für Desktops (d. h. Querformat) Bildformat.
Modellkonfiguration
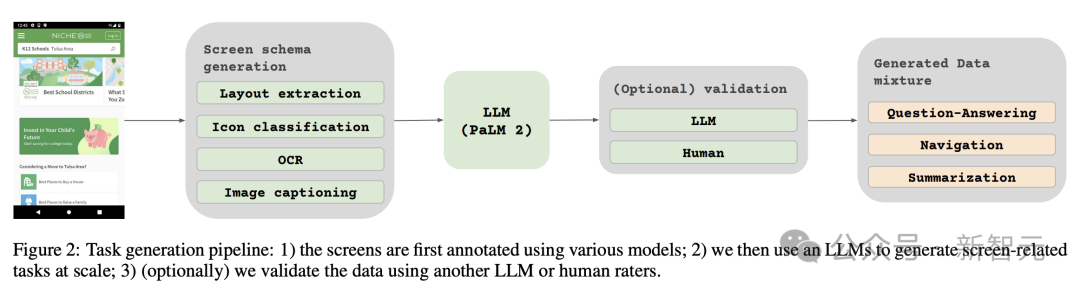
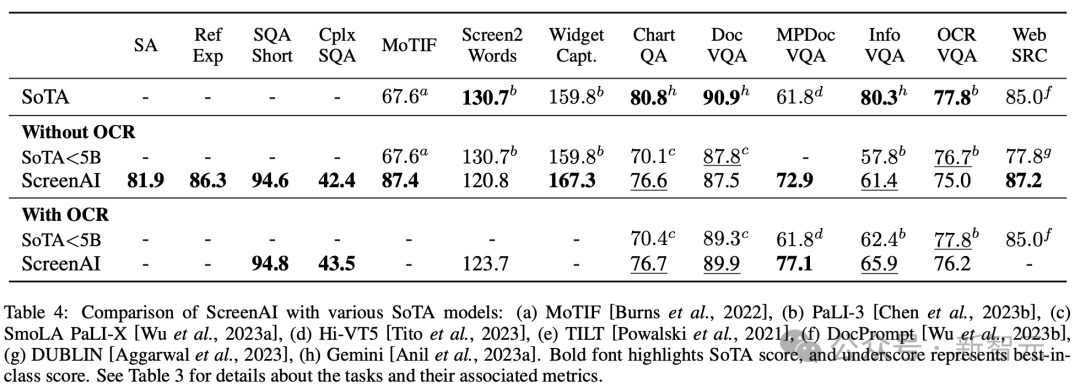
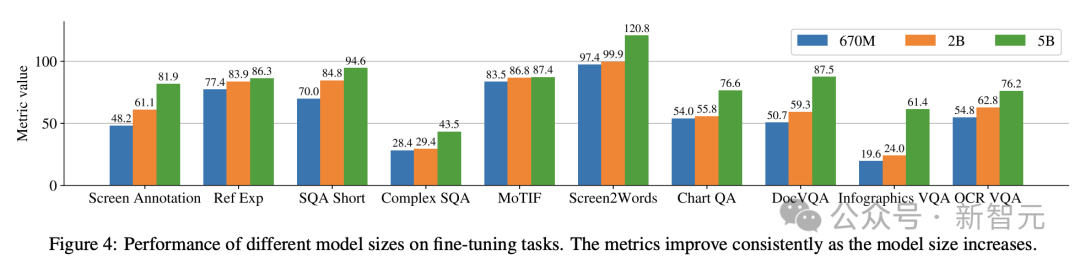
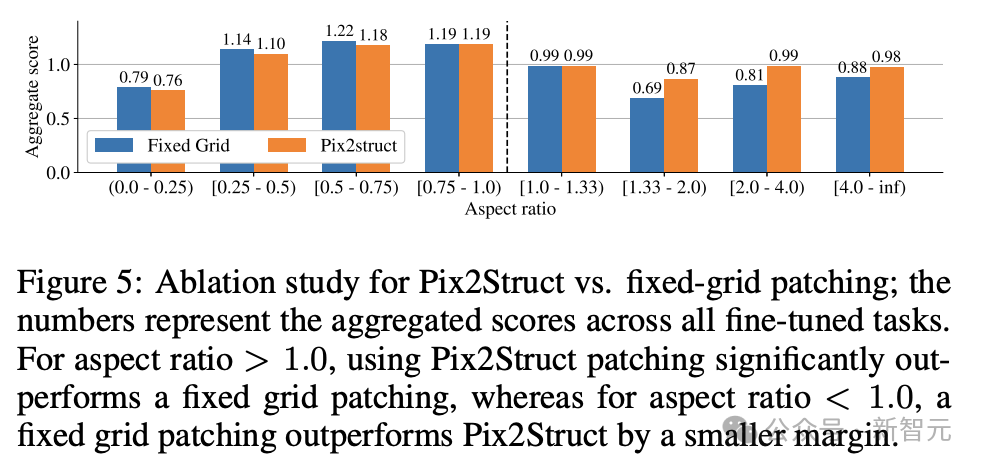
Die Forscher trainierten drei Modelle unterschiedlicher Größe mit den Parametern 670M, 2B und 5B. Für die 670M- und 2B-Parametermodelle begannen die Forscher mit vorab trainierten unimodalen Prüfpunkten eines visuellen Encoder- und Encoder-Decoder-Sprachmodells. Für das 5B-Parametermodell beginnen Sie am multimodalen Pre-Training-Checkpoint von PaLI-3, wo ViT mit einem UL2-basierten Encoder-Decoder-Sprachmodell trainiert wird. Die Parameterverteilung zwischen Seh- und Sprachmodellen ist in Tabelle 1 zu sehen. Automatische Datengenerierung Forscher sagen, dass die Vortrainingsphase der Modellentwicklung weitgehend vom Zugriff auf große und vielfältige Datensätze abhängt. Die manuelle Kennzeichnung umfangreicher Datensätze ist jedoch unpraktisch, daher lautet die Strategie des Google-Teams – automatische Datengenerierung. Dieser Ansatz nutzt spezialisierte kleine Modelle, von denen jedes gut darin ist, Daten effizient und mit hoher Genauigkeit zu generieren und zu kennzeichnen. Im Vergleich zur manuellen Annotation ist dieser automatisierte Ansatz nicht nur effizient und skalierbar, sondern gewährleistet auch ein gewisses Maß an Datenvielfalt und -komplexität. Der erste Schritt besteht darin, dem Modell ein umfassendes Verständnis der Textelemente, verschiedener Bildschirmkomponenten sowie ihrer Gesamtstruktur und Hierarchie zu vermitteln. Dieses grundlegende Verständnis ist entscheidend für die Fähigkeit des Modells, eine Vielzahl von Benutzeroberflächen genau zu interpretieren und mit ihnen zu interagieren. Hier sammelten Forscher durch das Crawlen von Anwendungen und Webseiten eine große Anzahl von Screenshots von verschiedenen Geräten, darunter Desktops, Mobilgeräte und Tablets. Diese Screenshots werden dann mit detaillierten Tags versehen, die die UI-Elemente, ihre räumlichen Beziehungen und andere beschreibende Informationen beschreiben. Um den Daten vor dem Training mehr Diversität zu verleihen, nutzten die Forscher außerdem die Leistungsfähigkeit von Sprachmodellen, insbesondere PaLM 2-S, um QA-Paare in zwei Stufen zu generieren. Erzeugen Sie zunächst das zuvor beschriebene Bildschirmmuster. Anschließend entwerfen die Autoren eine Eingabeaufforderung mit Bildschirmmustern, um das Sprachmodell bei der Generierung synthetischer Daten zu unterstützen. Nach einigen Iterationen kann ein Tipp identifiziert werden, der effektiv die erforderlichen Aufgaben generiert, wie in Anhang C dargestellt. Um die Qualität dieser generierten Antworten zu bewerten, führten die Forscher eine manuelle Überprüfung einer Teilmenge der Daten durch, um sicherzustellen, dass vorgegebene Qualitätsanforderungen erfüllt wurden. Diese Methode ist in Abbildung 2 beschrieben und verbessert die Tiefe und Breite des Datensatzes vor dem Training erheblich. Durch die Nutzung der natürlichen Sprachverarbeitungsfähigkeiten dieser Modelle in Kombination mit strukturierten Bildschirmmustern können verschiedene Benutzerinteraktionen und Szenarien simuliert werden. Als nächstes definierten die Forscher zwei verschiedene Aufgabensätze für das Modell: einen ersten Satz Vortrainingsaufgaben und einen Satz nachfolgender Feinabstimmungsaufgaben. Die beiden Gruppen unterscheiden sich hauptsächlich in zwei Aspekten: - Quelle realer Daten: Für Feinabstimmungsaufgaben werden die Etiketten von menschlichen Gutachtern bereitgestellt oder überprüft. Für Aufgaben vor dem Training werden Beschriftungen mithilfe selbstüberwachter Lernmethoden abgeleitet oder mithilfe anderer Modelle generiert. - Datensatzgröße: Normalerweise enthalten Vortrainingsaufgaben eine große Anzahl von Beispielen, daher werden diese Aufgaben verwendet, um das Modell durch eine längere Reihe von Schritten zu trainieren. Tabelle 2 zeigt eine Zusammenfassung aller Aufgaben vor dem Training. Bei gemischten Daten wird der Datensatz proportional zu seiner Größe gewichtet, wobei für jede Aufgabe die maximale Gewichtung zulässig ist. Durch die Einbindung multimodaler Quellen in das Multitasking-Training, von der Sprachverarbeitung über das visuelle Verständnis bis hin zur Analyse von Webinhalten, kann das Modell verschiedene Szenarien effektiv bewältigen und seine allgemeine Vielseitigkeit und Leistung verbessern. Forscher nutzen verschiedene Aufgaben und Benchmarks, um bei der Feinabstimmung die Qualität des Modells abzuschätzen. Tabelle 3 fasst diese Benchmarks zusammen, einschließlich bestehender Benchmarks für Primärbildschirme, Infografiken und Dokumentverständnis. Abbildung 4 zeigt die Leistung des ScreenAI-Modells und vergleicht sie mit den neuesten SOT-Ergebnissen bei verschiedenen Aufgaben im Zusammenhang mit Bildschirmen und Informationsgrafiken. Sie können die führende Leistung von ScreenAI bei verschiedenen Aufgaben sehen. In Tabelle 4 präsentieren die Forscher die Ergebnisse der Feinabstimmung einzelner Aufgaben mithilfe von OCR-Daten. Bei QA-Aufgaben kann das Hinzufügen von OCR die Leistung verbessern (z. B. bis zu 4,5 % bei Complex ScreenQA, MPDocVQA und InfoVQA). Durch die Verwendung von OCR erhöht sich jedoch die Eingabelänge geringfügig, was zu einem insgesamt langsameren Training führt. Außerdem ist es erforderlich, OCR-Ergebnisse zum Zeitpunkt der Inferenz zu erhalten. Darüber hinaus führten die Forscher Einzelaufgabenexperimente mit den folgenden Modellgrößen durch: 670 Millionen Parameter, 2 Milliarden Parameter und 5 Milliarden Parameter. Wie in Abbildung 4 zu sehen ist, verbessert eine Erhöhung der Modellgröße bei allen Aufgaben die Leistung, und die Verbesserung im größten Maßstab ist noch nicht ausgeschöpft. Bei Aufgaben, die komplexere visuelle Texte und arithmetisches Denken erfordern (wie InfoVQA, ChartQA und Complex ScreenQA), ist die Verbesserung zwischen dem 2-Milliarden-Parameter-Modell und dem 5-Milliarden-Parameter-Modell deutlich größer als beim 670-Millionen-Parameter-Modell und das 2-Milliarden-Parameter-Modell. Abschließend zeigt Abbildung 5, dass für Bilder mit einem Seitenverhältnis >1,0 (Bilder im Querformat) die pix2struct-Segmentierungsstrategie deutlich besser ist als die Segmentierung mit festem Raster. Bei Bildern im Porträtmodus ist der Trend umgekehrt, aber die feste Rastersegmentierung ist nur geringfügig besser. Da die Forscher wollten, dass das ScreenAI-Modell mit Bildern mit unterschiedlichen Seitenverhältnissen funktioniert, entschieden sie sich für die Segmentierungsstrategie pix2struct. Google-Forscher sagten, dass das ScreenAI-Modell auch bei einigen Aufgaben mehr Forschung benötigt, um die Lücke zu größeren Modellen wie GPT-4 und Gemini zu schließen. 
Zwei Sätze unterschiedlicher Aufgaben



Experimentelle Ergebnisse
Das obige ist der detaillierte Inhalt vonGoogle veröffentlicht die neueste KI zum „Bildschirmlesen'! PaLM 2-S generiert automatisch Daten und mehrere Verständnisaufgaben aktualisieren SOTA. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Bei der Konvertierung von Zeichenfolgen in Objekte in Vue.js wird JSON.Parse () für Standard -JSON -Zeichenfolgen bevorzugt. Bei nicht standardmäßigen JSON-Zeichenfolgen kann die Zeichenfolge durch Verwendung regelmäßiger Ausdrücke verarbeitet und Methoden gemäß dem Format oder dekodierten URL-kodiert reduziert werden. Wählen Sie die entsprechende Methode gemäß dem String -Format aus und achten Sie auf Sicherheits- und Codierungsprobleme, um Fehler zu vermeiden.
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Vue- und Element-UI-Kaskaden-Dropdown-Box V-Model-Bindung
Apr 07, 2025 pm 08:06 PM
Vue- und Element-UI-Kaskaden-Dropdown-Box V-Model-Bindung
Apr 07, 2025 pm 08:06 PM
Vue- und Element-UI-kaskadierte Dropdown-Boxen V-Model-Bindung gemeinsame Grubenpunkte: V-Model bindet ein Array, das die ausgewählten Werte auf jeder Ebene des kaskadierten Auswahlfelds darstellt, nicht auf einer Zeichenfolge; Der Anfangswert von ausgewählten Optionen muss ein leeres Array sein, nicht null oder undefiniert. Die dynamische Belastung von Daten erfordert die Verwendung asynchroner Programmierkenntnisse, um Datenaktualisierungen asynchron zu verarbeiten. Für riesige Datensätze sollten Leistungsoptimierungstechniken wie virtuelles Scrollen und fauler Laden in Betracht gezogen werden.
 VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
Zusammenfassung: Es gibt die folgenden Methoden zum Umwandeln von VUE.JS -String -Arrays in Objektarrays: Grundlegende Methode: Verwenden Sie die Kartenfunktion, um regelmäßige formatierte Daten zu entsprechen. Erweitertes Gameplay: Die Verwendung regulärer Ausdrücke kann komplexe Formate ausführen, müssen jedoch sorgfältig geschrieben und berücksichtigt werden. Leistungsoptimierung: In Betracht ziehen die große Datenmenge, asynchrone Operationen oder effiziente Datenverarbeitungsbibliotheken können verwendet werden. Best Practice: Clear Code -Stil, verwenden Sie sinnvolle variable Namen und Kommentare, um den Code präzise zu halten.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
