
 Technologie-Peripheriegeräte
KI
ADMap: Eine neue Idee für störungsfreie Online-Hochpräzisionskarten
Technologie-Peripheriegeräte
KI
ADMap: Eine neue Idee für störungsfreie Online-Hochpräzisionskarten
ADMap: Eine neue Idee für störungsfreie Online-Hochpräzisionskarten

Vorab geschrieben und persönliches Verständnis des Autors
Ich freue mich sehr über die Einladung zur Teilnahme an der Veranstaltung „Heart of Autonomous Driving“. Wir werden die Anti-Störungs-Methode ADMap zur Online-Rekonstruktion vektorisierter hochpräziser Karten vorstellen. Sie finden unseren Code unter https://github.com/hht1996ok/ADMap. Vielen Dank an alle für Ihre Aufmerksamkeit und Unterstützung.
Im Bereich des autonomen Fahrens ist die hochauflösende Online-Kartenrekonstruktion für Planungs- und Vorhersageaufgaben von großer Bedeutung. In jüngster Zeit wurden viele leistungsstarke hochauflösende Kartenrekonstruktionsmodelle erstellt, um diesen Bedarf zu decken. Allerdings kann die Punktreihenfolge innerhalb der vektorisierten Instanz aufgrund von Vorhersageabweichungen schwanken oder unregelmäßig sein, was sich auf nachfolgende Aufgaben auswirkt. Daher schlagen wir das Anti-Disturbance Map Rekonstruktions-Framework (ADMap) vor. Ziel dieses Artikels ist es, die Modellgeschwindigkeit und Gesamtgenauigkeit zu berücksichtigen und Ingenieure bei der Bereitstellung nicht zu belästigen. Daher werden drei effiziente und effektive Module vorgeschlagen: Multi-Scale Perception Neck (MPN), Instance Interactive Attention (IIA) und Vector Direction Difference Loss (VDDL). Durch die Kaskadierung zur Untersuchung der Punktreihenfolgebeziehungen zwischen und innerhalb von Instanzen überwacht unser Modell den Punktreihenfolgevorhersageprozess besser.
Wir haben die Wirksamkeit von ADMap in nuScenes- und Argoverse2-Datensätzen überprüft. Experimentelle Ergebnisse zeigen, dass ADMap in verschiedenen Benchmark-Tests die beste Leistung zeigt. Im nuScenes-Benchmark verbessert ADMap den mAP um 4,2 % bzw. 5,5 % im Vergleich zur Basislinie, wobei nur Kameradaten bzw. multimodale Daten verwendet werden. ADMapv2 reduziert nicht nur die Inferenzlatenz, sondern verbessert auch die Basisleistung erheblich, wobei der höchste mAP 82,8 % erreicht. Im Argoverse-Datensatz stieg der mAP von ADMapv2 auf 62,9 %, während die Bildrate bei 14,8 FPS blieb.
Zusammenfassend hat die von uns vorgeschlagene ADMap die folgenden Hauptbeiträge:
- Schlug eine End-to-End-ADMap vor und rekonstruierte eine stabilere vektorisierte Karte mit hoher Präzision.
- MPN erfasst Multiskaleninformationen besser, ohne die Argumentationsressourcen zu erhöhen, wodurch die Punktsequenz-Rekonstruktionsprozesse durch VDDL genauer eingeschränkt werden .
- ADMap ermöglicht die Echtzeit-Rekonstruktion vektorisierter hochpräziser Karten und erreicht die höchste Genauigkeit im nuScenes-Benchmark und Argoverse2. Die
-Methode wird vorgeschlagen
Wie in Abbildung 1 gezeigt, kommt es häufig zu Jitter oder Verschiebungen der Vorhersagepunkte, die dazu führen, dass der rekonstruierte Instanzvektor ungleichmäßig oder gezackt wird Hochpräzise Online-Karten. Wir glauben, dass der Grund darin liegt, dass bestehende Modelle die Interaktion zwischen Instanzen und innerhalb von Instanzen nicht vollständig berücksichtigen. Eine unvollständige Interaktion zwischen Instanzpunkten und Kartentopologieinformationen wird zu ungenauen vorhergesagten Positionen führen. Darüber hinaus können nur Überwachungen wie L1-Verlust und Kosinus-Einbettungsverlust geometrische Beziehungen nicht effektiv nutzen, um den Vorhersageprozess von Instanzpunkten einzuschränken. Das Netzwerk muss Vektorliniensegmente zwischen Punkten verwenden, um die Richtungsinformationen der Punktsequenz genauer zu erfassen Beschränken Sie jeden Punkt.
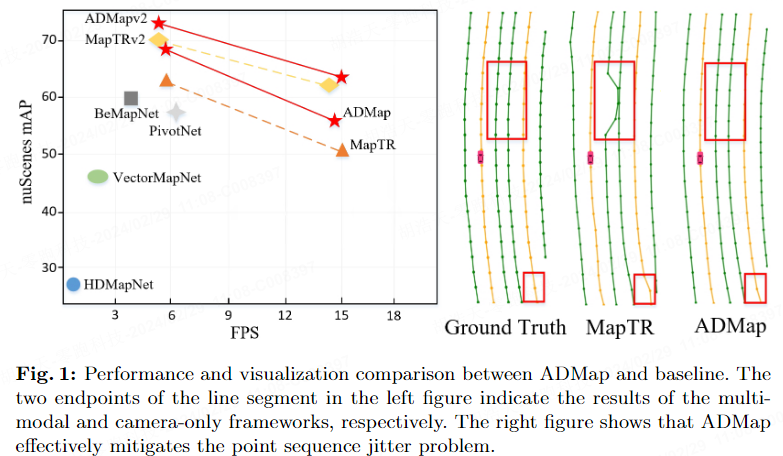
Um die oben genannten Probleme zu lindern, haben wir innovativ das Anti-Disturbance Map Rekonstruktions-Framework (ADMap) vorgeschlagen, um eine stabile Echtzeitrekonstruktion vektorisierter hochpräziser Karten zu erreichen.
Methodendesign
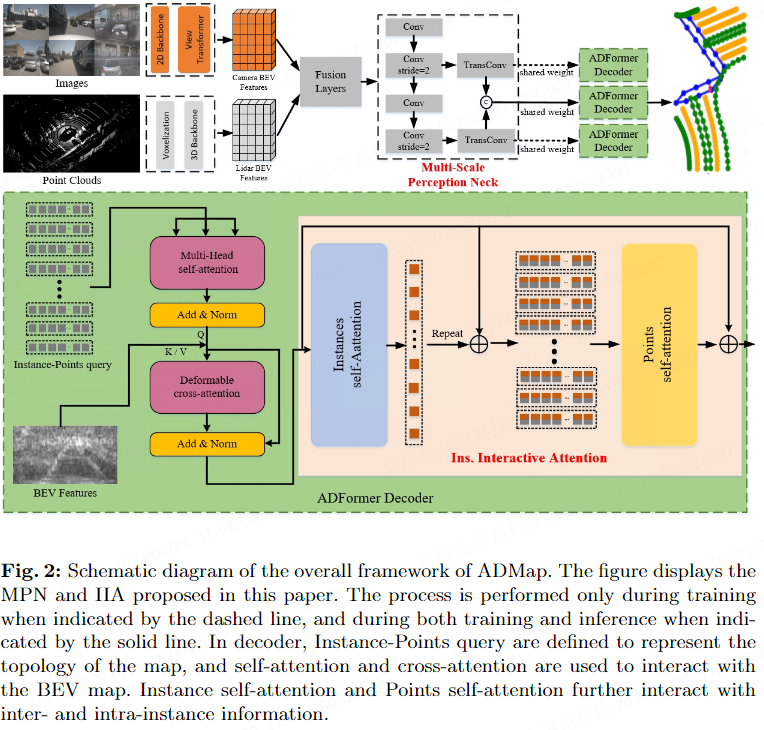
Wie in Abbildung 2 dargestellt, verwendet ADMap Multi-Scale Perception Neck (MPN), Instance Interactive Attention (IIA) und Vector Direction Difference Loss (VDDL), um die Punktreihenfolge vorherzusagen Topologie genauer. MPN, IIA und VDDL werden im Folgenden jeweils vorgestellt.
Multi-Scale Perception Neck
Um detailliertere BEV-Funktionen zu erhalten, führen wir Multi-Scale Perception Neck (MPN) ein. MPN erhält die fusionierten BEV-Merkmale als Eingabe. Durch Downsampling werden die BEV-Features jeder Ebene mit einem Upsampling-Layer verbunden, um die Feature-Map in Originalgröße wiederherzustellen. Schließlich werden die Feature-Maps auf jeder Ebene zu BEV-Features mit mehreren Maßstäben zusammengeführt.
Wie in Abbildung 2 dargestellt, stellt die gepunktete Linie dar, dass dieser Schritt nur während des Trainings implementiert wird, und die durchgezogene Linie stellt dar, dass dieser Schritt sowohl während des Trainings als auch während des Inferenzprozesses implementiert wird. Während des Trainingsprozesses werden BEV-Feature-Maps mit mehreren Maßstäben und BEV-Feature-Maps auf jeder Ebene an den Transformer Decoder gesendet, wodurch das Netzwerk Instanzinformationen der Szene in verschiedenen Maßstäben vorhersagen kann, um verfeinerte Features mit mehreren Maßstäben zu erfassen. Während des Inferenzprozesses behält MPN nur BEV-Features mit mehreren Maßstäben bei und gibt keine Feature-Maps auf jeder Ebene aus. Dadurch wird sichergestellt, dass die Ressourcennutzung des Halses während der Inferenz unverändert bleibt.
Transformer Decoder
Transformer Decoder definiert eine Reihe von Abfragen auf Instanzebene und eine Reihe von Abfragen auf Punktebene. Diese hierarchischen Abfragen werden wie folgt definiert:
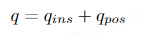
Der Decoder besteht aus mehreren kaskadierten Decodierungsschichten, die die hierarchische Abfrage iterativ aktualisieren. In jeder Decodierungsschicht werden hierarchische Abfragen in den Selbstaufmerksamkeitsmechanismus eingegeben, der den Austausch von Informationen zwischen hierarchischen Abfragen ermöglicht. Zur Interaktion mit hierarchischen Abfragen und mehrskaligen BEV-Funktionen wird verwendet.
Instance Interactive Attention
Um die Funktionen jeder Instanz in der Dekodierungsphase besser zu erhalten, haben wir Instance Interactive Attention (IIA) vorgeschlagen, das aus Instanz-Selbstaufmerksamkeit und Punkte-Selbstaufmerksamkeit besteht. Im Gegensatz zu MapTRv2, das Einbettungen auf Instanz- und Punktebene parallel extrahiert, extrahiert IIA Abfrageeinbettungen kaskadiert. Funktionsinteraktionen zwischen Instanzeinbettungen helfen dem Netzwerk außerdem dabei, Beziehungen zwischen Einbettungen auf Punktebene zu lernen.
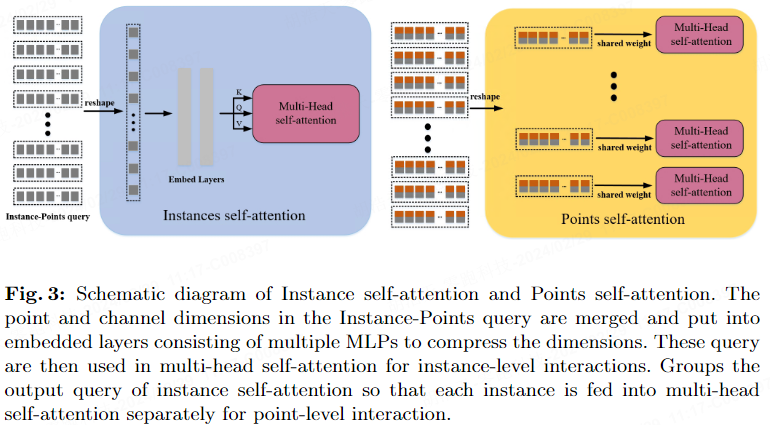
Wie in Abbildung 3 dargestellt, werden die von der verformbaren Kreuzaufmerksamkeit ausgegebenen hierarchischen Einbettungen in die Selbstaufmerksamkeit der Instanzen eingegeben. Nach dem Zusammenführen der Punktdimension und der Kanaldimension erfolgt die Dimensionstransformation. Anschließend wird die hierarchische Einbettung mit der aus mehreren MLPs bestehenden Einbettungsschicht verbunden, um die Instanzabfrage zu erhalten. Die Abfrage wird in die Multi-Head-Selbstaufmerksamkeit gestellt, um die topologische Beziehung zwischen Instanzen zu erfassen und die Instanzeinbettung zu erhalten. Um Informationen auf Instanzebene in Einbettungen auf Punktebene zu integrieren, summieren wir Instanzeinbettungen und hierarchische Einbettungen. Die hinzugefügten Features werden in die Point-Selbstaufmerksamkeit eingegeben, die mit den Punkt-Features innerhalb jeder Instanz interagiert, um die topologischen Beziehungen zwischen Punktsequenzen weiter fein zu korrelieren.
Vector Direction Difference Loss
Die hochpräzise Karte enthält vektorisierte statische Kartenelemente, einschließlich Fahrspurlinien, Bordsteine und Zebrastreifen. ADMap schlägt Vektorrichtungsdifferenzverlust für diese offenen Formen (Fahrspurlinien, Bordsteine) und geschlossene Formen (Fußgängerüberwege) vor. Wir modellieren die Richtung des Punktsequenzvektors innerhalb der Instanz, und die Richtung des Punkts kann anhand der Differenz zwischen der vorhergesagten Vektorrichtung und der wahren Vektorrichtung detaillierter überwacht werden. Darüber hinaus wird davon ausgegangen, dass Punkte mit großen Unterschieden in den realen Vektorrichtungen drastische Änderungen in der Topologie einiger Szenen darstellen (schwieriger vorherzusagen) und mehr Aufmerksamkeit vom Modell erfordern. Daher erhalten Punkte mit größeren wahren Vektorrichtungsunterschieden ein höheres Gewicht, um sicherzustellen, dass das Netzwerk diesen drastischen Änderungspunkt genau vorhersagen kann.

Abbildung 4 zeigt die anfängliche Modellierung der vorhergesagten Vektorlinie { und der wahren Vektorlinie { in der vorhergesagten Punktfolge { und der wahren Punktfolge { ). Um sicherzustellen, dass entgegengesetzte Winkel nicht den gleichen Verlust erleiden, berechnen wir den Kosinus der Winkeldifferenz der Vektorlinie θ':
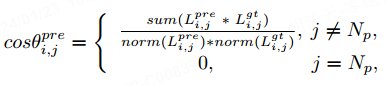
wobei die Funktion die Koordinatenposition der Vektorlinie akkumuliert, was den Normalisierungsvorgang darstellt . Wir verwenden die Vektorwinkeldifferenz jedes Punktes in der realen Instanz, um ihnen unterschiedlich große Gewichte zuzuweisen. Das Gewicht ist wie folgt definiert:
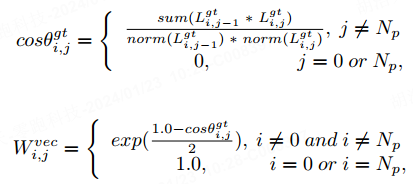
, was die Anzahl der Punkte in der Instanz darstellt, und die Funktion stellt die Exponentialfunktion mit der Basis e dar. Da die Vektorwinkeldifferenz zwischen dem ersten und dem letzten Punkt nicht berechnet werden kann, setzen wir die Gewichtung des ersten und des letzten Punkts auf 1. Wenn die Vektorwinkeldifferenz in der Grundwahrheit größer wird, geben wir diesem Punkt ein größeres Gewicht, wodurch das Netzwerk deutlich veränderten Kartentopologien mehr Aufmerksamkeit schenkt. Der Winkeldifferenzverlust jedes Punktes in der Punktfolge ist definiert als:
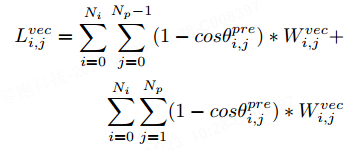
Wir verwenden θ, um das Intervall des Verlustwerts auf [0,0, 2,0] anzupassen. Durch Addition der Kosinuswerte der Winkeldifferenzen zwischen benachbarten Vektorlinien an jedem Punkt deckt dieser Verlust die geometrischen Topologieinformationen jedes Punkts umfassender ab. Da es zwischen dem ersten und dem letzten Punkt nur eine benachbarte Vektorlinie gibt, entspricht der Verlust am ersten und letzten Punkt dem Kosinus der einzelnen Vektorwinkeldifferenz.
Experiment
Zur fairen Bewertung unterteilen wir die Kartenelemente in drei Typen: Fahrspurlinien, Straßenbegrenzungen und Zebrastreifen. Die durchschnittliche Genauigkeit (AP) wird verwendet, um die Qualität der Kartenkonstruktion zu bewerten, und die Summe der Fasenabstände zwischen der vorhergesagten Punktreihenfolge und der wahren Punktreihenfolge wird verwendet, um zu bestimmen, ob die beiden übereinstimmen. Der Schwellenwert für den Fasenabstand ist auf [0,5, 1,0, 1,5] eingestellt. Wir berechnen AP jeweils unter diesen drei Schwellenwerten und verwenden den Durchschnitt als endgültigen Indikator.
Vergleichsexperiment
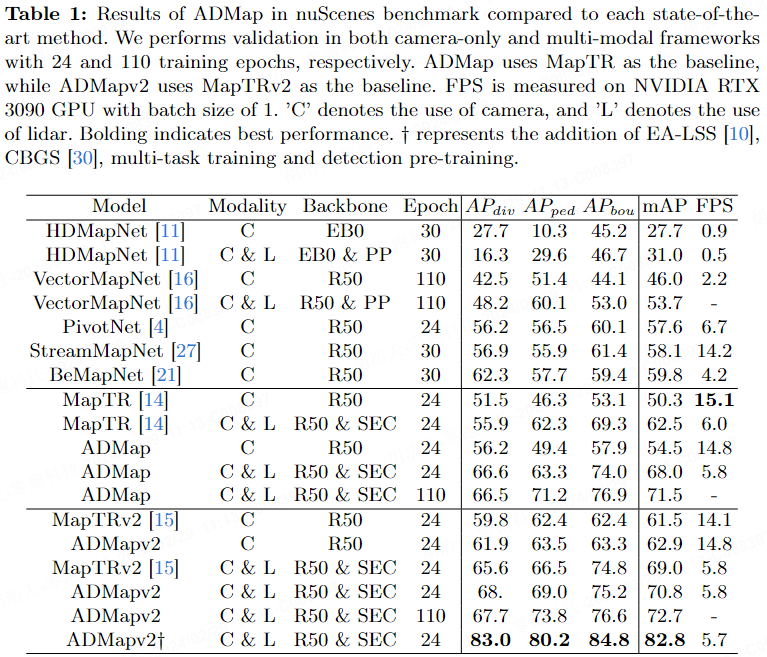
Tabelle 1 zeigt die Metriken von ADMap und modernste Methoden für den nuScenes-Datensatz. Unter dem Nur-Kamera-Framework stieg der mAP von ADMap um 5,5 % im Vergleich zum Ausgangswert (MapTR) und ADMapv2 stieg um 1,4 % im Vergleich zum Ausgangswert (MapTRv2). ADMapv2 hat einen maximalen mAP von 82,8 % und erreicht damit die beste Leistung unter den aktuellen Benchmarks. Einige Details werden in nachfolgenden arxiv-Versionen bekannt gegeben. In Bezug auf die Geschwindigkeit verbessert ADMap die Modellleistung im Vergleich zum Basismodell bei etwas niedrigeren FPS deutlich. Es ist erwähnenswert, dass ADMapv2 nicht nur die Leistung verbessert, sondern auch die Geschwindigkeit der Modellinferenz verbessert.
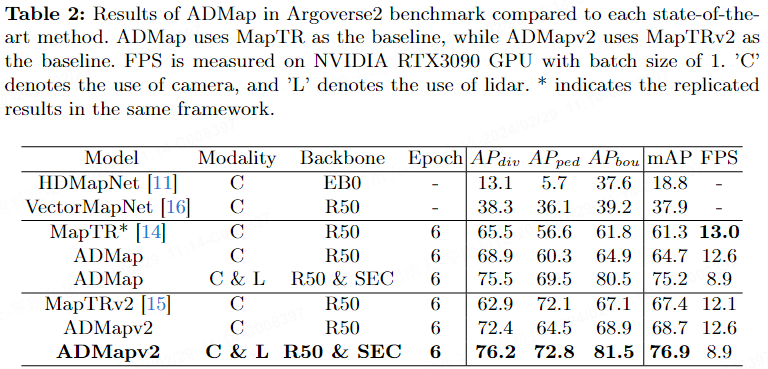
Tabelle 2 zeigt die Metriken von ADMap und modernste Methoden in Argoverse2. Unter dem Nur-Kamera-Framework verbesserten sich ADMap und ADMapv2 im Vergleich zum Ausgangswert um 3,4 % bzw. 1,3 %. Unter dem multimodalen Framework erzielten ADMap und ADMapv2 mit mAP von 75,2 % bzw. 76,9 % die beste Leistung. Was die Geschwindigkeit angeht. ADMapv2 verbesserte sich im Vergleich zu MapTRv2 um 11,4 ms.
Ablationsexperimente
In Tabelle 3 stellen wir Ablationsexperimente für jedes Modul von ADMap auf dem nuScenes-Benchmark bereit.
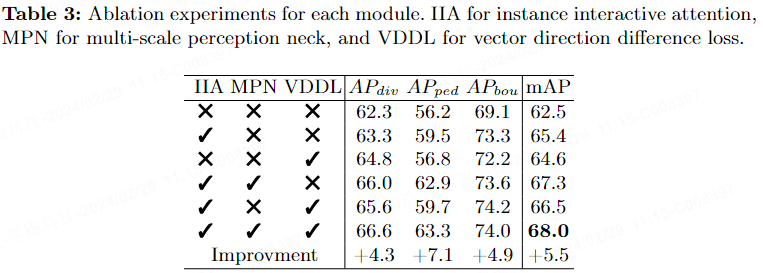
Tabelle 4 zeigt die Auswirkungen des Einfügens verschiedener Aufmerksamkeitsmechanismen auf die endgültige Leistung. DSA steht für entkoppelte Selbstaufmerksamkeit und IIA beispielsweise für interaktive Aufmerksamkeit. Die Ergebnisse zeigen, dass IIA den mAP im Vergleich zu DSA um 1,3 % verbessert.
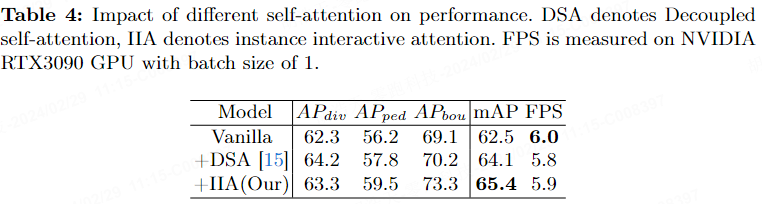
Tabelle 5 zeigt die Auswirkungen des Hinzufügens von Rückgrat- und Halsschichten auf mAP nach dem Zusammenführen von Features. Nach dem Hinzufügen der Rückgrat- und Halsschichten basierend auf SECOND erhöhte sich der mAP um 1,2 %. Nach dem Hinzufügen von MPN erhöhte sich der mAP des Modells um 2,0 %, ohne dass sich die Inferenzzeit erhöhte.
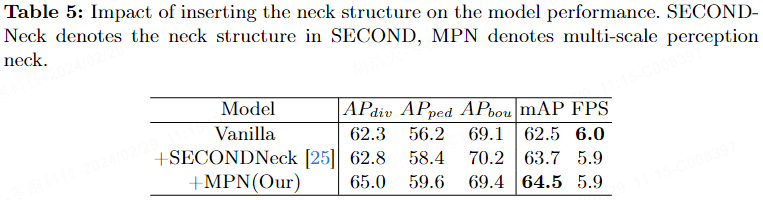
Tabelle 6 zeigt die Leistungsauswirkungen des Hinzufügens von VDDL im nuScenes-Benchmark. Es ist ersichtlich, dass bei einer Gewichtung von 1,0 der mAP am höchsten ist und 53,3 % erreicht.
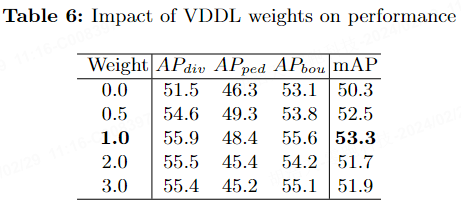
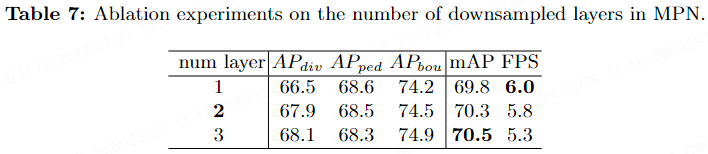
Tabelle 7 zeigt die Auswirkungen der Anzahl der MPN-Downsampling-Ebenen auf die endgültige Leistung im nuScenes-Benchmark. Je mehr Downsampling-Ebenen vorhanden sind, desto langsamer ist die Modellinferenzgeschwindigkeit. Um Geschwindigkeit und Leistung in Einklang zu bringen, legen wir daher die Anzahl der Downsampling-Ebenen auf 2 fest.
Um zu überprüfen, ob ADMap das Problem der Punktordnungsstörung effektiv lindert, haben wir den durchschnittlichen Fasenabstand (ACE) vorgeschlagen. Wir haben vorhergesagte Instanzen ausgewählt, deren Summe der Fasenabstände weniger als 1,5 beträgt, und ihren durchschnittlichen Fasenabstand (ACE) berechnet. Je kleiner der ACE ist, desto genauer ist die Vorhersage der Instanzpunktreihenfolge. Tabelle 8 beweist, dass ADMap das Problem der Punktwolkenstörung wirksam lindern kann.

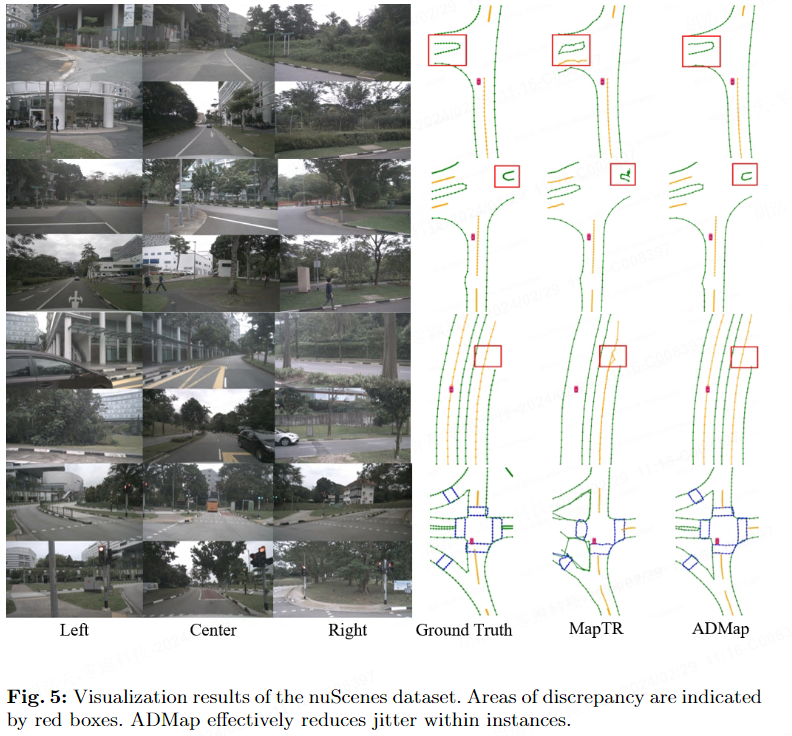
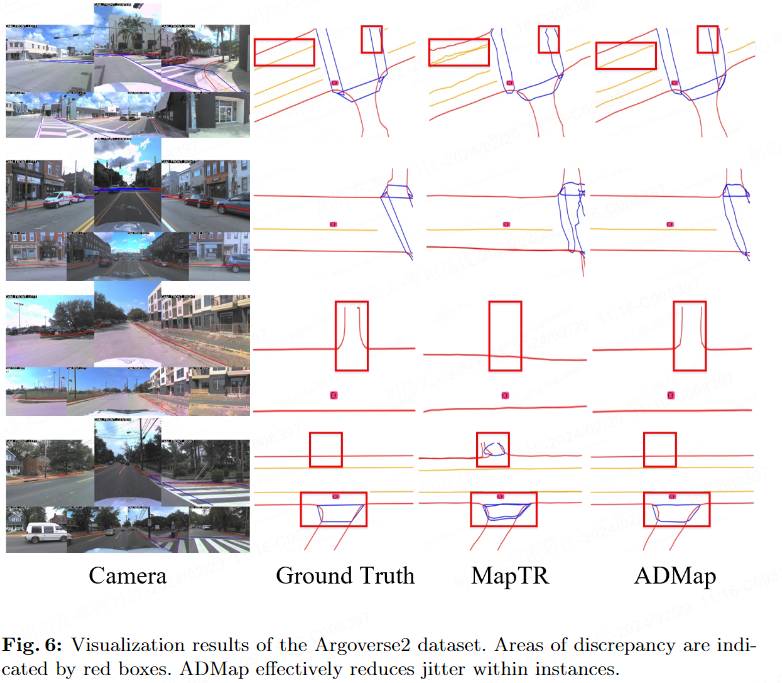
Visualisierungsergebnisse
Die folgenden beiden Bilder zeigen die Visualisierungsergebnisse des nuScenes-Datensatzes und des Argoverse2-Datensatzes.
Zusammenfassung
ADMap ist ein effizientes und effektives vektorisiertes, hochpräzises Kartenrekonstruktions-Framework, das den Jitter oder das gezackte Phänomen, das aufgrund von Vorhersageverzerrungen in der Punktreihenfolge von Instanzvektoren auftreten kann, effektiv lindert. Umfangreiche Experimente zeigen, dass unsere vorgeschlagene Methode sowohl bei nuScenes- als auch bei Argoverse2-Benchmarks die beste Leistung erzielt. Wir glauben, dass ADMap dazu beitragen wird, die Forschung zu hochpräzisen Vektorkartenrekonstruktionsaufgaben voranzutreiben und dadurch die Entwicklung des autonomen Fahrens und anderer Bereiche besser voranzutreiben.
Das obige ist der detaillierte Inhalt vonADMap: Eine neue Idee für störungsfreie Online-Hochpräzisionskarten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
In diesem Artikel wird das Problem der genauen Erkennung von Objekten aus verschiedenen Blickwinkeln (z. B. Perspektive und Vogelperspektive) beim autonomen Fahren untersucht, insbesondere wie die Transformation von Merkmalen aus der Perspektive (PV) in den Raum aus der Vogelperspektive (BEV) effektiv ist implementiert über das Modul Visual Transformation (VT). Bestehende Methoden lassen sich grob in zwei Strategien unterteilen: 2D-zu-3D- und 3D-zu-2D-Konvertierung. 2D-zu-3D-Methoden verbessern dichte 2D-Merkmale durch die Vorhersage von Tiefenwahrscheinlichkeiten, aber die inhärente Unsicherheit von Tiefenvorhersagen, insbesondere in entfernten Regionen, kann zu Ungenauigkeiten führen. Während 3D-zu-2D-Methoden normalerweise 3D-Abfragen verwenden, um 2D-Features abzutasten und die Aufmerksamkeitsgewichte der Korrespondenz zwischen 3D- und 2D-Features über einen Transformer zu lernen, erhöht sich die Rechen- und Bereitstellungszeit.
