
 Technologie-Peripheriegeräte
KI
ViT, Meituan, die Zhejiang-Universität usw. weit übertreffend, schlug VisionLLAMA vor, eine einheitliche Architektur für visuelle Aufgaben
Technologie-Peripheriegeräte
KI
ViT, Meituan, die Zhejiang-Universität usw. weit übertreffend, schlug VisionLLAMA vor, eine einheitliche Architektur für visuelle Aufgaben
ViT, Meituan, die Zhejiang-Universität usw. weit übertreffend, schlug VisionLLAMA vor, eine einheitliche Architektur für visuelle Aufgaben

Seit mehr als einem halben Jahr hat Metas Open-Source-LLaMA-Architektur den Test im LLM bestanden und große Erfolge erzielt (stabiles Training und einfache Skalierung).
Können wir den Forschungsideen von ViT folgend mit Hilfe der innovativen LLaMA-Architektur wirklich die architektonische Vereinheitlichung von Sprache und Bildern erreichen?
Bei diesem Vorschlag hat eine aktuelle Studie von VisionLLaMA Fortschritte gemacht. VisionLLaMA hat sich im Vergleich zur ursprünglichen ViT-Klassenmethode bei vielen Mainstream-Aufgaben wie der Bilderzeugung (einschließlich des zugrunde liegenden DIT, auf das sich Sora verlässt) und dem Verständnis (Klassifizierung, Segmentierung, Erkennung, Selbstüberwachung) erheblich verbessert.

- Papiertitel: VisionLLaMA: A Unified LLaMA Interface for Vision Tasks
- Papieradresse: https://arxiv.org/abs/2403.00522
- Codeadresse : https://github.com/Meituan-AutoML/VisionLLaMA
Diese Forschung versucht, Bild- und Spracharchitektur zu vereinheitlichen und kann die Trainingsergebnisse der LLM-Community zu LLaMA nutzen, einschließlich stabiler und effektiver Erweiterung und Bereitstellung.
Forschungshintergrund
Das große Sprachmodell ist eines der einflussreichsten und repräsentativsten Werke, die auf dieser Architektur basieren der eingesetzten Lösungen basieren auf den Open-Source-Modellen dieser Serie. Bei der Weiterentwicklung multimodaler Modelle stützen sich viele dieser Methoden auf LLaMA für die Textverarbeitung und visuelle Transformatoren wie CLIP für die visuelle Wahrnehmung. Gleichzeitig werden viele Anstrengungen unternommen, um die Inferenzgeschwindigkeit von LLaMA zu beschleunigen und die Speicherkosten von LLaMA zu senken. Alles in allem ist LLaMA mittlerweile die de facto vielseitigste und wichtigste Modellarchitektur für große Sprachen.

Der Erfolg der LLaMA-Architektur veranlasste den Autor dieses Artikels, eine einfache und interessante Idee vorzuschlagen: Kann diese Architektur in visuellen Modalitäten gleichermaßen erfolgreich sein? Wenn die Antwort „Ja“ lautet, können sowohl visuelle als auch sprachliche Modelle dieselbe einheitliche Architektur verwenden und von den verschiedenen dynamischen Bereitstellungstechniken profitieren, die für LLaMA entwickelt wurden. Dies ist jedoch ein komplexes Thema, da es einige offensichtliche Unterschiede zwischen den beiden Modalitäten gibt.
Es gibt erhebliche Unterschiede in der Datenverarbeitung zwischen Textsequenzen und visuellen Aufgaben. Einerseits handelt es sich bei Textsequenzen um eindimensionale Daten, während bei Sehaufgaben die Verarbeitung komplexerer zwei- oder mehrdimensionaler Daten erforderlich ist. Andererseits ist es für visuelle Aufgaben normalerweise erforderlich, ein Pyramidenstruktur-Backbone-Netzwerk zu verwenden, um die Leistung zu verbessern, während der LLaMA-Encoder eine relativ einfache Struktur aufweist. Darüber hinaus ist die effiziente Verarbeitung von Bild- und Videoeingaben unterschiedlicher Auflösung eine Herausforderung. Diese Unterschiede müssen bei der übergreifenden Forschung zwischen Text- und visuellen Bereichen vollständig berücksichtigt werden, um effektivere Lösungen zu finden.
Der Zweck dieses Papiers besteht darin, diese Herausforderungen anzugehen und die architektonische Lücke zwischen verschiedenen Modalitäten zu schließen, indem eine an Sehaufgaben angepasste LLaMA-Architektur vorgeschlagen wird. Mit dieser Architektur können Probleme im Zusammenhang mit modalen Unterschieden gelöst und visuelle und sprachliche Daten einheitlich verarbeitet werden, was zu besseren Ergebnissen führt.
Die Hauptbeiträge dieses Artikels sind wie folgt:
1 Dieser Artikel schlägt VisionLLaMA vor, eine visuelle Transformationsarchitektur ähnlich LLaMA, um den architektonischen Unterschied zwischen Sprache und Vision zu verringern.
2. In diesem Artikel werden Möglichkeiten untersucht, VisionLLaMA an gängige Sehaufgaben anzupassen, einschließlich Bildverständnis und -erstellung (Abbildung 1). In diesem Artikel werden zwei bekannte Vision-Architekturschemata (reguläre Struktur und Pyramidenstruktur) untersucht und ihre Leistung in überwachten und selbstüberwachten Lernszenarien bewertet. Darüber hinaus wird in diesem Artikel AS2DRoPE (d. h. Autoscaling 2D RoPE) vorgeschlagen, das die Rotationspositionskodierung von 1D auf 2D erweitert und Interpolationsskalierung nutzt, um beliebige Auflösungen zu berücksichtigen.
3. Bei genauer Auswertung übertrifft VisionLLaMA aktuelle gängige und präzise abgestimmte Vision-Transformatoren bei vielen repräsentativen Aufgaben wie Bildgenerierung, Klassifizierung, semantische Segmentierung und Objekterkennung deutlich. Umfangreiche Experimente zeigen, dass VisionLLaMA eine schnellere Konvergenzgeschwindigkeit und eine bessere Leistung aufweist als bestehende Vision-Transformatoren.
VisionLLaMA Gesamtarchitekturdesign
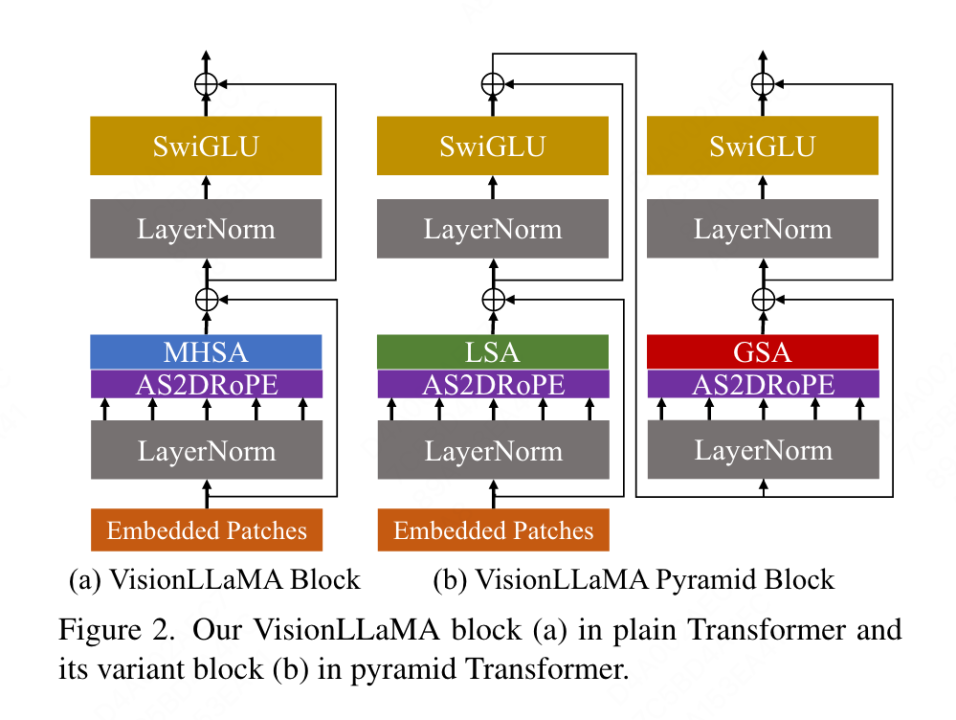
Konventioneller Transformator
Der in diesem Artikel vorgeschlagene konventionelle VisionLLaMA folgt dem Prozess von ViT und behält das architektonische Design von LLaMA so weit wie möglich bei. Für ein Bild wird es zunächst in eine Sequenz umgewandelt und reduziert, dann wird am Anfang der Sequenz ein Kategorie-Token hinzugefügt und die gesamte Sequenz wird durch L VisionLLaMA-Blöcke verarbeitet. Im Gegensatz zu ViT fügt VisionLLaMA der Eingabesequenz keine Positionskodierung hinzu, da die Blöcke von VisionLLaMA eine Positionskodierung enthalten. Insbesondere unterscheidet sich dieser Block vom Standard-ViT-Block in zweierlei Hinsicht: Selbstaufmerksamkeit mit Positionskodierung (RoPE) und SwiGLU-Aktivierung. In diesem Artikel wird immer noch LayerNorm anstelle von RMSNorm verwendet, da in diesem Artikel experimentell festgestellt wurde, dass ersteres eine bessere Leistung erbringt (siehe Tabelle 11g). Die Struktur des Blocks ist in Abbildung 2(a) dargestellt. In diesem Artikel wird festgestellt, dass die direkte Anwendung von 1D-RoPE in Bildverarbeitungsaufgaben nicht gut auf verschiedene Auflösungen verallgemeinert werden kann. Daher wird es auf eine 2D-Form erweitert:

Pyramid Structure Transformer
VisionLLaMA ist sehr einfach um auf fensterbasierte Transformatoren wie Swin anzuwenden, daher untersucht dieser Artikel, wie man einen leistungsstarken Pyramidenstrukturtransformator auf den stärkeren Basislinien-Twins aufbaut. Die ursprüngliche Architektur von Twins nutzt bedingte Positionscodierung und einen verschachtelten lokal-globalen Informationsaustausch in Form von lokal-globaler Aufmerksamkeit. Diese Komponenten sind bei allen Transformatoren gleich, was bedeutet, dass es nicht schwierig ist, VisionLLaMA auf verschiedene Transformatorvarianten anzuwenden.
Das Ziel dieses Artikels ist nicht, einen neuen Pyramidenstruktur-Vision-Transformator zu erfinden, sondern wie man das grundlegende Design von VisionLLaMA basierend auf dem bestehenden Design anpasst. Daher folgt dieser Artikel dem Prinzip minimaler Änderungen an der Architektur und Hyperparameter. Nach der Benennungsmethode von ViT können zwei aufeinanderfolgende Blöcke wie folgt geschrieben werden:

wobei LSA die lokale Selbstaufmerksamkeitsoperation innerhalb der Gruppe ist und GSA durch Interaktion mit den repräsentativen Schlüsselwerten in jedem durchgeführt wird Unterfenster Globale Unterabtastung der Aufmerksamkeit. In diesem Artikel wird die bedingte Positionskodierung in der Pyramidenstruktur VisionLLaMA entfernt, da die Positionsinformationen bereits in AS2DRoPE enthalten sind. Darüber hinaus wird das Kategorie-Token entfernt und GAP (Global Average Pooling) vor dem Klassifizierungskopf verwendet. Die Blockstruktur unter dieser Einstellung ist in Abbildung 2 (b) dargestellt.
Training oder Inferenz über Sequenzlängenbeschränkungen hinaus
Erweitern von eindimensionalem RoPE auf zweidimensional: Die Verarbeitung unterschiedlicher Eingabeauflösungen ist eine häufige Anforderung bei Bildverarbeitungsaufgaben. Faltungs-Neuronale Netze verwenden einen Schiebefenstermechanismus, um variable Längen zu verarbeiten. Im Gegensatz dazu wenden die meisten visuellen Transformatoren lokale Fensteroperationen oder Interpolation an, z. B. verwendet DeiT bikubische Interpolation, wenn CPVT auf faltungsbasierter Positionskodierung trainiert wird. In diesem Artikel wird die Leistung von 1D RoPE bewertet und festgestellt, dass es die höchste Genauigkeit bei einer Auflösung von 224 x 224 aufweist. Wenn die Auflösung jedoch auf 448 x 448 erhöht wird, sinkt die Genauigkeit stark und erreicht sogar 0. Daher erweitert dieser Artikel das eindimensionale RoPE auf zwei Dimensionen. Für den Mehrkopf-Selbstaufmerksamkeitsmechanismus wird das 2D-RoPE von verschiedenen Köpfen gemeinsam genutzt.
Positionsinterpolation trägt dazu bei, dass 2D-RoPE besser verallgemeinert werden kann: Inspiriert durch einige Arbeiten, bei denen Interpolation zur Erweiterung des Kontextfensters von LLaMA verwendet wurde, übernimmt VisionLLaMA eine ähnliche Methode zur Erweiterung des 2D-Kontextfensters unter Beteiligung höherer Auflösungen. Im Gegensatz zu Sprachaufgaben mit erweiterten festen Kontextlängen verarbeiten visuelle Aufgaben wie die Objekterkennung häufig unterschiedliche Stichprobenauflösungen in unterschiedlichen Iterationen. Dieser Artikel verwendet eine Eingabeauflösung von 224 x 224, um ein kleines Modell zu trainieren, und bewertet die Leistung einer größeren Auflösung ohne erneutes Training. Dieser Artikel leitet diesen Artikel an, die Interpolations- oder Heterodyn-Strategie besser anzuwenden. Nach Experimenten entschied sich dieser Artikel für die Anwendung der automatischen Skalierungsinterpolation (AS2DRoPE) basierend auf der „Ankerauflösung“. Die Berechnungsmethode für die Verarbeitung eines quadratischen Bildes von H × H und einer Ankerpunktauflösung von B × B lautet wie folgt:
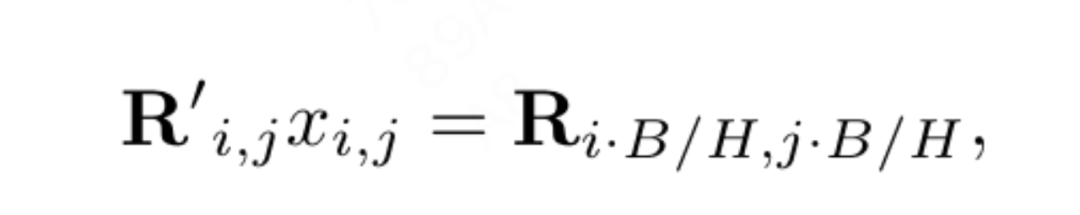
Diese Berechnungsmethode ist effizient und verursacht keine zusätzlichen Kosten. Bleibt die Trainingsauflösung unverändert, degeneriert AS2DRoPE zu 2D RoPE.

Aufgrund der Notwendigkeit, Standortinformationen zu den zusammengefassten Schlüsselwerten hinzuzufügen, führt dieser Artikel eine spezielle Verarbeitung für GSA unter der Pyramidenstruktureinstellung durch. Diese unterabgetasteten Schlüssel werden durch Abstraktion auf der Feature-Map generiert. In diesem Artikel wird die Faltung mit der Kernelgröße k×k und der Schrittweite k verwendet. Wie in Abbildung 3 dargestellt, können die Koordinaten der generierten Schlüsselwerte als Durchschnitt der abgetasteten Merkmale ausgedrückt werden.
Experimentelle Ergebnisse
Dieses Papier bewertet umfassend die Wirksamkeit von VisionLLaMA bei Aufgaben wie Bilderzeugung, Klassifizierung, Segmentierung und Erkennung. Standardmäßig werden alle Modelle in diesem Artikel auf 8 NVIDIA Tesla A100-GPUs trainiert.
Bildgenerierung
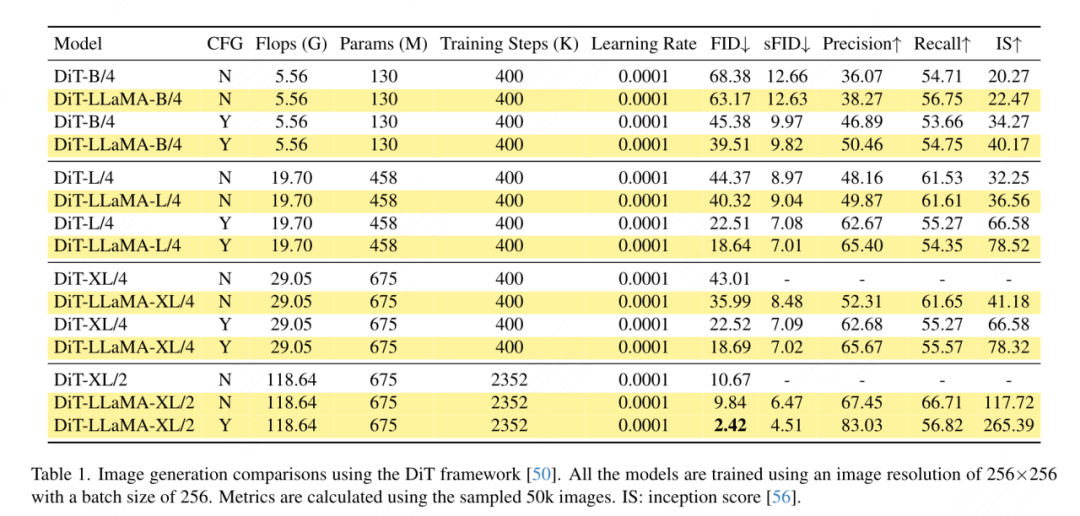
Bildgenerierung basierend auf dem DiT-Framework: In diesem Artikel wird die Anwendung von VisionLLaMA unter dem DiT-Framework ausgewählt, da DiT eine repräsentative Arbeit ist, die Visual Transformer und DDPM zur Bildgenerierung verwendet. Dieser Artikel ersetzt den ursprünglichen Vision-Transformer von DiT durch VisionLLaMA, während andere Komponenten und Hyperparameter unverändert bleiben. Dieses Experiment demonstriert die Vielseitigkeit von VisionLLaMA bei Bilderzeugungsaufgaben. Wie bei DiT werden in diesem Artikel die Beispielschritte von DDPM auf 250 festgelegt. Die experimentellen Ergebnisse sind in Tabelle 1 aufgeführt. In Übereinstimmung mit den meisten Methoden gilt FID als primäre Metrik und wird anhand anderer sekundärer Metriken wie sFID, Precision/Recall und Inception Score bewertet. Die Ergebnisse zeigen, dass VisionLLaMA DiT in verschiedenen Modellgrößen deutlich übertrifft. In diesem Artikel wird außerdem die Anzahl der Trainingsschritte des XL-Modells auf 2352.000 erweitert, um zu bewerten, ob unser Modell den Vorteil einer schnelleren Konvergenz bietet oder bei längeren Trainingsperioden immer noch eine bessere Leistung erbringt. Der FID von DiT-LLaMA-XL/2 ist um 0,83 niedriger als der von DiT-XL/2, was darauf hindeutet, dass VisionLLaMA nicht nur eine bessere Recheneffizienz, sondern auch eine höhere Leistung als DiT aufweist. Einige mit XL-Modellen generierte Beispiele sind in Abbildung 1 dargestellt.
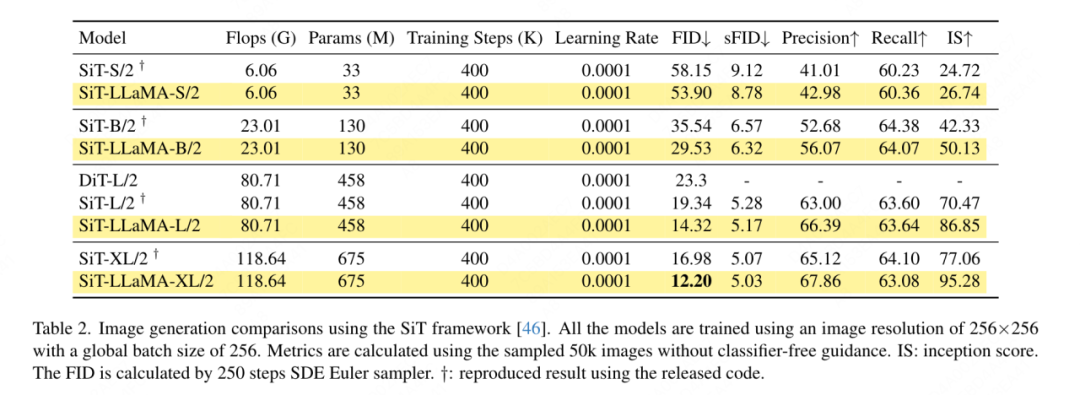
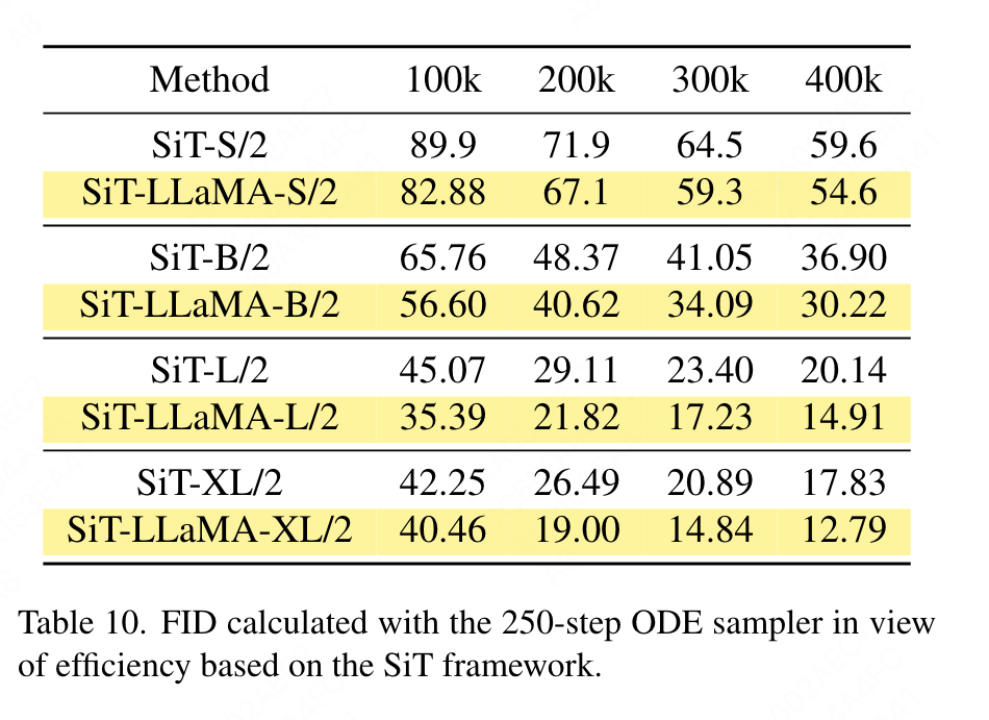
Bildgenerierung basierend auf dem SiT-Framework: Das SiT-Framework verbessert die Leistung der Bildgenerierung mithilfe visueller Transformatoren erheblich. In diesem Artikel wird der Vision-Transformer in SiT durch VisionLLaMA ersetzt, um die Vorteile einer besseren Modellarchitektur zu bewerten, die in diesem Artikel als SiT-LLaMA bezeichnet wird. Bei den Experimenten wurden alle verbleibenden Einstellungen und Hyperparameter in SiT beibehalten, alle Modelle wurden mit der gleichen Anzahl von Schritten trainiert und in allen Experimenten wurden lineare Interpolations- und Geschwindigkeitsmodelle verwendet. Für einen fairen Vergleich haben wir außerdem den veröffentlichten Code erneut ausgeführt und 50.000 256×256-Bilder mit einem SDE-Sampler (Euler) mit 250 Schritten abgetastet. Die Ergebnisse sind in Tabelle 2 aufgeführt. SiT-LLaMA übertrifft SiT modellübergreifend auf verschiedenen Kapazitätsniveaus. Im Vergleich zu SiT-L/2 verringert sich SiT-LLaMA-L/2 um 5,0 FID, was größer ist als die Verbesserung, die das neue Framework mit sich bringt (4,0 FID). Dieses Papier zeigt in Tabelle 13 auch einen effizienteren ODE-Sampler (dopri5), und der Leistungsunterschied zu unserer Methode besteht immer noch. Es lassen sich ähnliche Schlussfolgerungen wie im SiT-Papier ziehen: SDEs weisen eine bessere Leistung auf als ihre ODE-Pendants. ?? andere Datensätze Or Aufgrund des Einflusses der Destillationsfähigkeiten wurden alle Modelle mit dem ImageNet-1K-Trainingssatz trainiert. Die Genauigkeitsergebnisse des Validierungssatzes sind in Tabelle 3 aufgeführt.
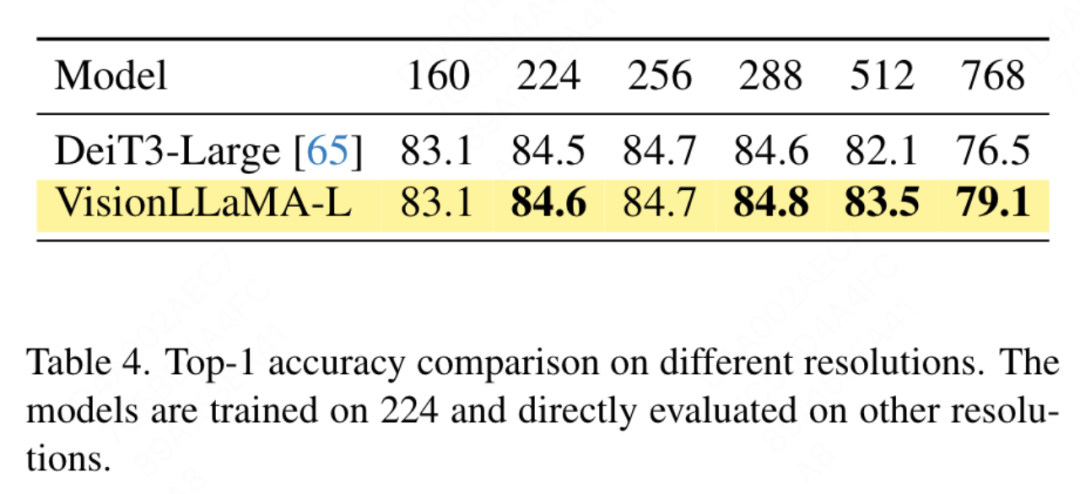
Vergleich konventioneller Vision-Transformatoren: DeiT3 ist der aktuelle, hochmoderne konventionelle Vision-Transformer, der eine spezielle Datenerweiterung vorschlägt und eine umfangreiche Hyperparametersuche durchführt, um die Leistung zu verbessern. DeiT3 reagiert empfindlich auf Hyperparameter und neigt zur Überanpassung. Das Ersetzen von Kategorie-Tokens durch GAP (Global Average Pooling) führt dazu, dass die Genauigkeit des DeiT3-Large-Modells nach 800 Trainingsepochen um 0,7 % sinkt. Daher verwendet dieser Artikel Kategorie-Tokens anstelle von GAP in regulären Transformern. Die Ergebnisse sind in Tabelle 3 aufgeführt, wobei VisionLLaMA eine mit DeiT3 vergleichbare Top-1-Genauigkeit erreicht. Die Genauigkeit bei einer einzelnen Auflösung bietet keinen umfassenden Vergleich. In diesem Artikel wird auch die Leistung bei verschiedenen Bildauflösungen bewertet. Die Ergebnisse sind in Tabelle 4 aufgeführt. Für DeiT3 verwenden wir bikubische Interpolation zur lernbaren Positionskodierung. Obwohl die beiden Modelle bei einer Auflösung von 224 x 224 eine vergleichbare Leistung aufweisen, wird der Abstand mit zunehmender Auflösung größer, was bedeutet, dass unsere Methode bei unterschiedlichen Auflösungen eine bessere Generalisierungsfähigkeit aufweist, was für die Zielerkennung und viele andere nachgelagerte Aufgaben besser ist.
Vergleich der Pyramidenstruktur mit visuellen Transformatoren: Dieser Artikel verwendet dieselbe Architektur wie Twins-SVT und die detaillierte Konfiguration ist in Tabelle 17 aufgeführt. In diesem Artikel wird die bedingte Positionskodierung entfernt, da VisionLLaMA bereits eine Rotationspositionskodierung enthält. Daher ist VisionLLaMA eine faltungsfreie Architektur. In diesem Artikel werden alle Einstellungen einschließlich Hyperparametern in Twins-SVT behandelt, was mit Twins-SVT übereinstimmt. In diesem Artikel werden keine Kategorietoken verwendet, sondern GAP angewendet. Die Ergebnisse sind in Tabelle 3 aufgeführt. Unsere Methode erreicht auf allen Modellebenen eine mit Twins vergleichbare Leistung und ist immer besser als Swin.
- Selbstüberwachtes Training
Dieser Artikel verwendet den ImageNet-Datensatz, um zwei gängige Methoden selbstüberwachter visueller Transformatoren zu bewerten, während die Trainingsdaten auf ImageNet-1K beschränkt werden und jegliche Verwendung von CLIP, DALLE oder entfernt wird Destillation usw. Komponenten, die die Leistung verbessern können. Die Implementierung dieses Artikels basiert auf dem MMPretrain-Framework, nutzt das MAE-Framework und verwendet VisionLLaMA, um den Encoder zu ersetzen, während andere Komponenten unverändert bleiben. Dieses Kontrollexperiment kann die Wirksamkeit dieser Methode bewerten. Darüber hinaus verwenden wir die gleichen Hyperparametereinstellungen wie die verglichenen Methoden, unter denen wir im Vergleich zu leistungsstarken Baselines immer noch deutliche Leistungsverbesserungen erzielen.
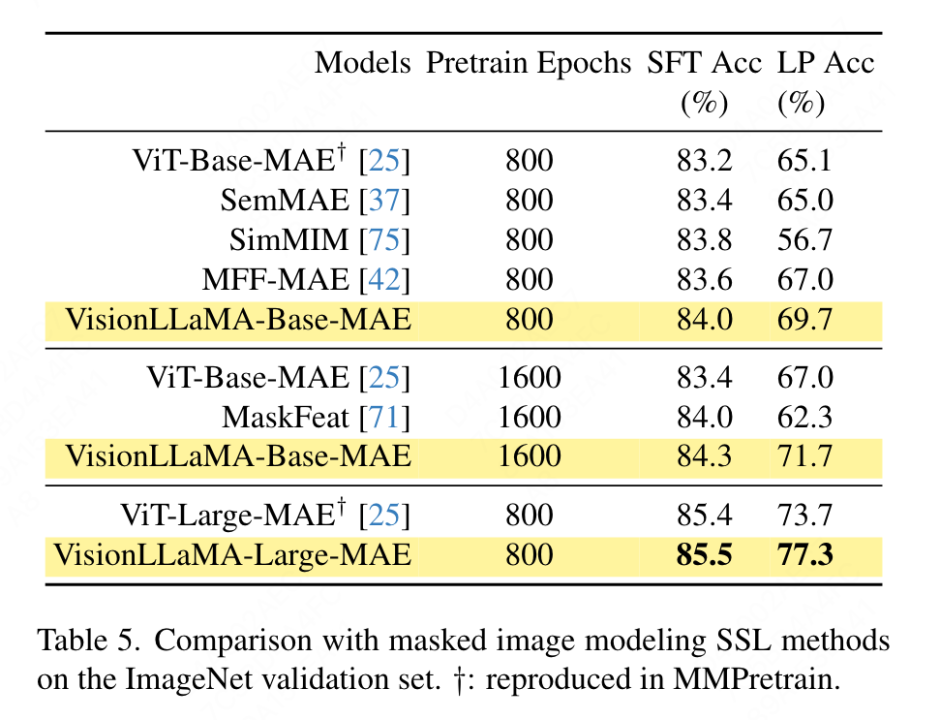
Vollständiges Fine-Tuning-Setup: Im aktuellen Setup wird das Modell zunächst mit vortrainierten Gewichten initialisiert und anschließend zusätzlich mit vollständig trainierbaren Parametern trainiert. VisionLLaMA-Base wurde auf ImageNet für 800 Epochen trainiert und erreichte eine Top-1-Genauigkeit von 84,0 %, was 0,8 % höher ist als ViT-Base. Die Methode in diesem Artikel trainiert etwa dreimal schneller als SimMIM. In diesem Dokument wird auch die Schulungsdauer auf 1600 erhöht, um zu überprüfen, ob VisionLLaMA seinen Vorteil mit ausreichenden Schulungsressourcen aufrechterhalten kann. VisionLLaMA-Base erzielt neue SOTA-Ergebnisse unter den MAE-Varianten mit einer Top-1-Genauigkeit von 84,3 %, was einer Verbesserung von 0,9 % gegenüber ViT-Base entspricht. Wenn man bedenkt, dass eine vollständige Feinabstimmung das Risiko einer Leistungssättigung birgt, ist die Verbesserung dieser Methode sehr bedeutend.
Lineares Sondieren: Eine aktuelle Arbeit betrachtet die lineare Sondierungsmetrik als zuverlässigere Bewertung des repräsentativen Lernens. Im aktuellen Setup wird das Modell mit vorab trainierten Gewichten aus der SSL-Phase initialisiert. Während des Trainings wird dann das gesamte Backbone-Netzwerk bis auf den Klassifikatorkopf eingefroren. Die Ergebnisse sind in Tabelle 5 dargestellt: Bei einem Trainingsaufwand von 800 Epochen übertrifft VisionLLaMA-Base ViTBase-MAE um 4,6 %. Es übertrifft auch ViT-Base-MAE, das für 1600 Epochen trainiert wurde. Wenn VisionLLaMA für 1600 Epochen trainiert wird, erreicht VisionLLaMA-Base eine Top1-Genauigkeit von 71,7 %. Diese Methode wird auch auf VisionLLaMA-Large erweitert, das im Vergleich zu ViT-Large eine Verbesserung um 3,6 % erzielt.
Semantische Segmentierung im ADE20K-Datensatz
- Vollständig überwachtes Training
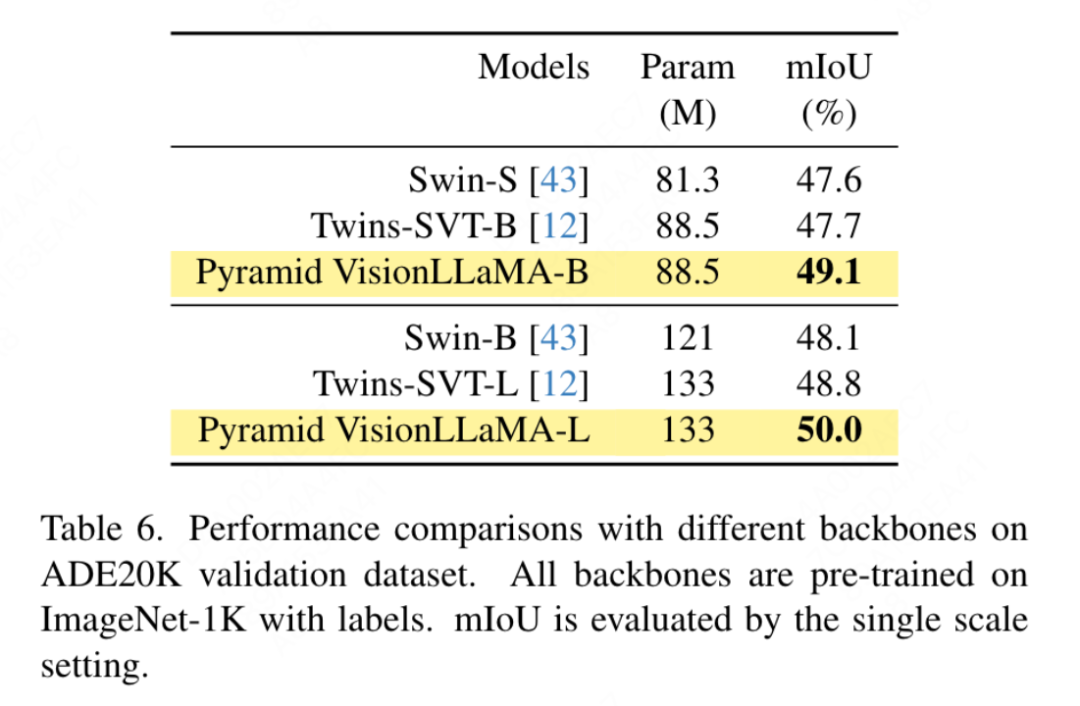
Gemäß den Einstellungen von Swin verwendet dieser Artikel. seman Tic-Segmentierung des ADE20K-Datensatzes zur Bewertung dieser Methode der Wirksamkeit. Für einen fairen Vergleich beschränkt dieses Dokument das Basismodell darauf, ImageNet-1K nur für das Vortraining zu verwenden. Dieser Artikel verwendet das UpperNet-Framework und ersetzt das Backbone-Netzwerk durch die Pyramidenstruktur VisionLLaMA. Die Implementierung dieses Artikels basiert auf dem MMSegmentation-Framework. Die Anzahl der Modelltrainingsschritte ist auf 160.000 festgelegt und die globale Stapelgröße beträgt 16. Die Ergebnisse sind in Tabelle 6 aufgeführt. Bei ähnlichen FLOPs übertrifft unsere Methode Swin und Twins um mehr als 1,2 % mIoU.
- Selbstüberwachtes Training
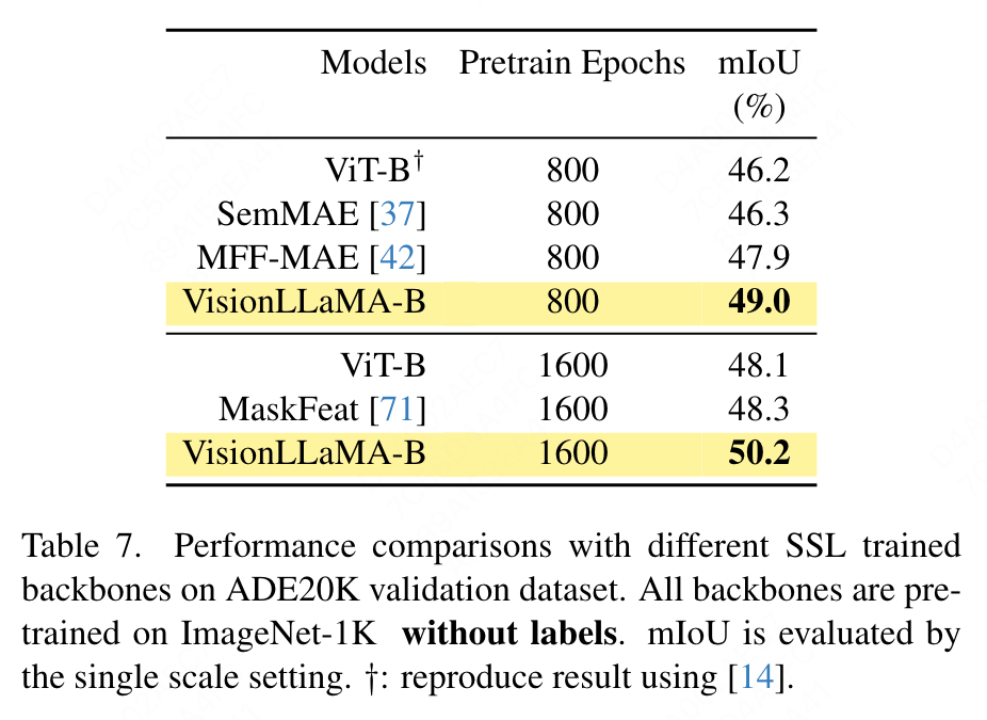
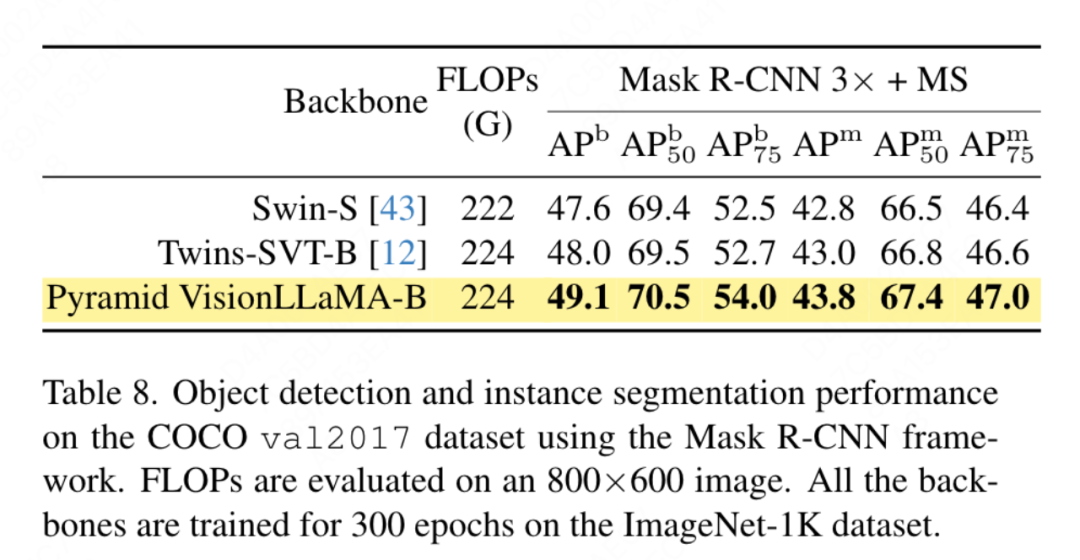
Dieses Papier verwendet das UpperNet-Framework für die semantische Segmentierung des ADE20K-Datensatzes und ersetzt das ViT-Backbone durch VisionLLaMA, während andere Komponenten und Hyperparameter unverändert bleiben. Die Implementierung dieses Artikels basiert auf MMSegmentierung und die Ergebnisse sind in Tabelle 7 dargestellt. Für den Vortrainingssatz von 800 Epochen verbesserte VisionLLaMA-B ViT-Base deutlich um 2,8 % mIoU. Unsere Methode ist auch deutlich besser als andere Verbesserungen, wie z. B. die Einführung zusätzlicher Trainingsziele oder -funktionen, die zusätzlichen Overhead für den Trainingsprozess mit sich bringen und die Trainingsgeschwindigkeit verringern würden. Im Gegensatz dazu erfordert VisionLLaMA nur den Austausch des Basismodells und verfügt über eine hohe Trainingsgeschwindigkeit. In diesem Artikel wird die Leistung von 1600 längeren Pre-Training-Epochen weiter bewertet. VisionLLaMA-B erreicht 50,2 % mIoU auf dem ADE20K-Validierungssatz, was die Leistung von ViT-B um 2,1 % mIoU verbessert. ?? der COCO-Datensatz . Dieses Papier verwendet das Mask RCNN-Framework und ersetzt das Backbone-Netzwerk durch ein visionLLaMA mit Pyramidenstruktur, das auf dem ImageNet-1K-Datensatz für 300 Epochen vorab trainiert wurde, ähnlich dem Aufbau von Swin. Daher verfügt unser Modell über die gleiche Anzahl an Parametern und FLOPs wie Twins. Dieses Experiment kann verwendet werden, um die Wirksamkeit dieser Methode bei Zielerkennungsaufgaben zu überprüfen. Die Implementierung dieses Artikels basiert auf dem MMDetection-Framework. Tabelle 8 zeigt die Ergebnisse des Standard-36-Epochen-Trainingszyklus (3×). Das Modell dieses Artikels ist besser als Swin und Twins. Insbesondere übertrifft VisionLLaMA-B Swin-S um 1,5 % Box-MAP und 1,0 % Masken-MAP. Im Vergleich zu den stärkeren Twins-B-Basislinien hat unsere Methode den Vorteil eines um 1,1 % höheren Box-mAP und eines um 0,8 % höheren Mask-mAP.
Selbstüberwachtes Training
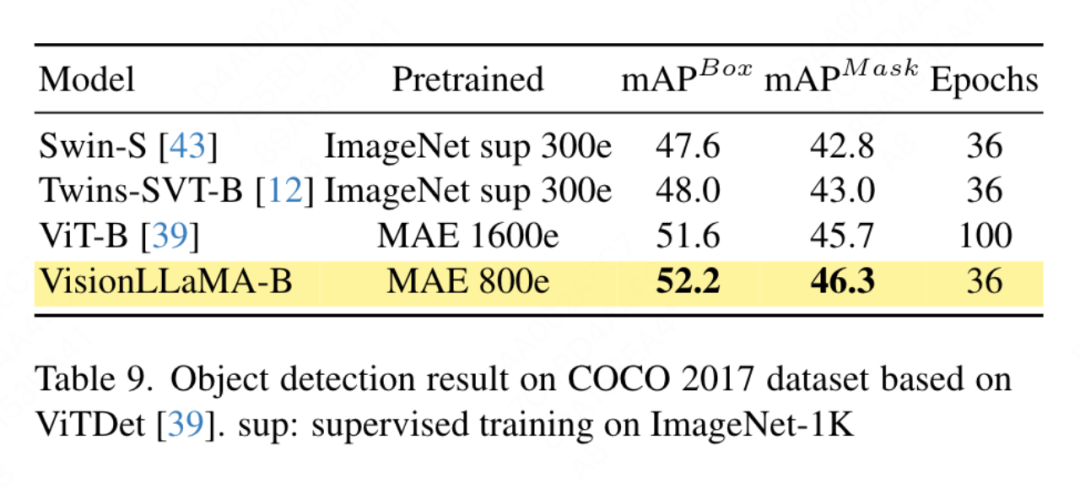
Dieses Dokument wendet VisionLLaMA auf der Grundlage des ViTDet-Frameworks an, das herkömmliche Vision-Transformatoren verwendet, um eine Leistung zu erzielen, die mit der des entsprechenden Vision-Transformators mit Pyramidenstruktur vergleichbar ist. In diesem Artikel wird der Mask RCNN-Detektor verwendet und das vit-Base-Backbone-Netzwerk durch das VisionLLaMA-Base-Modell ersetzt, das mit MAE für 800 Epochen vorab trainiert wurde. Das ursprüngliche ViTDet konvergiert langsam und erfordert spezielle Trainingsstrategien wie längere Trainingsperioden, um eine optimale Leistung zu erzielen. Während des Trainingsprozesses stellte dieser Artikel fest, dass VisionLLaMA nach 30 Epochen eine ähnliche Leistung erzielte. Daher wurde in diesem Artikel direkt die Standard-3x-Trainingsstrategie angewendet. Die Schulungskosten unserer Methode betragen nur 36 % des Basiswerts. Im Gegensatz zu den verglichenen Methoden führt unsere Methode keine optimale Hyperparametersuche durch. Die Ergebnisse sind in Tabelle 9 aufgeführt. VisionLLaMA übertrifft ViT-B um 0,6 % auf Box-MAP und 0,8 % auf Masken-MAP.Ablationsexperiment und Diskussion
 Ablationsexperiment
Ablationsexperiment
Ablation der Normalisierungsstrategie: In diesem Artikel werden zwei weit verbreitete Normalisierungsmethoden in Transformatoren, RMSNorm und LayerNorm, verglichen. Die Ergebnisse sind in Tabelle 11g aufgeführt. Letzteres weist eine bessere Endleistung auf, was darauf hindeutet, dass die Neuzentrierung der Invarianz auch bei Sehaufgaben wichtig ist. In diesem Artikel wird auch die durchschnittliche Zeit berechnet, die pro Iteration zum Messen der Trainingsgeschwindigkeit aufgewendet wird, wobei LayerNorm nur 2 % langsamer als RMSNorm ist. Daher wird in diesem Artikel LayerNorm anstelle von RMSNorm ausgewählt, um eine ausgewogenere Leistung zu erzielen.
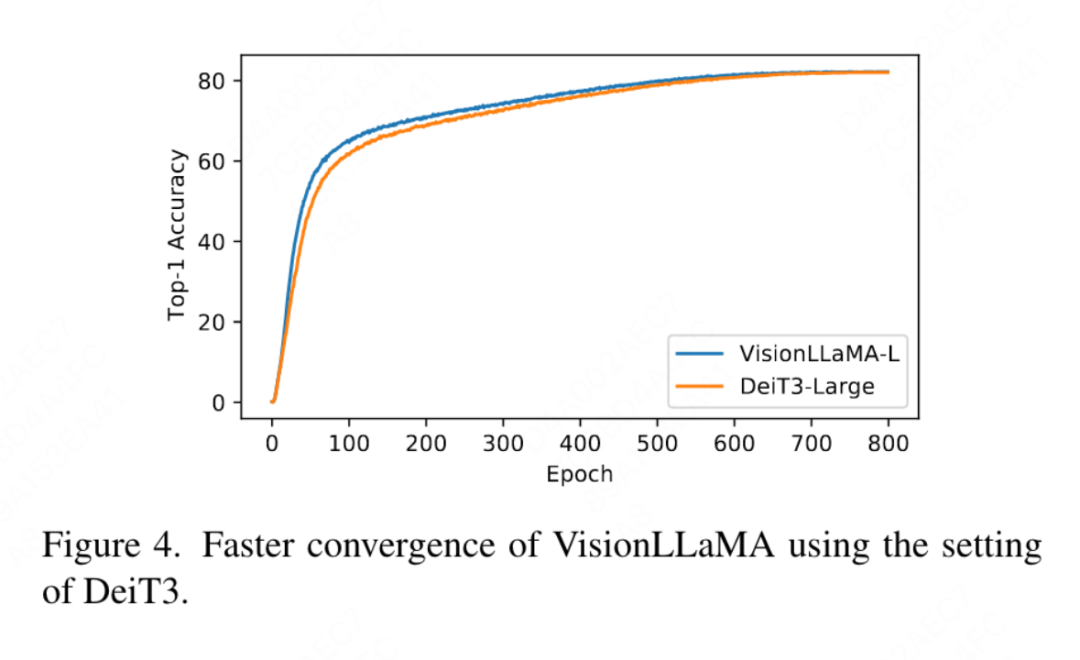
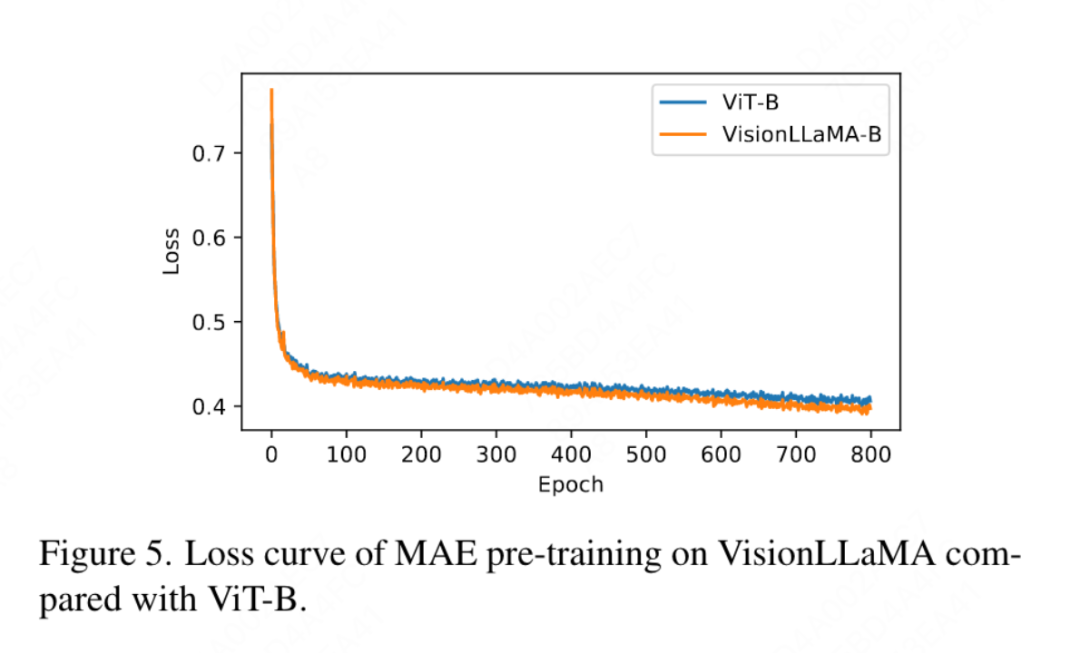
Partielle Positionskodierung: In diesem Artikel wird RoPE verwendet, um das Verhältnis aller Kanäle anzupassen. Die Ergebnisse sind in Tabelle 11b dargestellt. Die Ergebnisse zeigen, dass durch Einstellen des Verhältnisses auf einen kleinen Schwellenwert eine gute Leistung erzielt werden kann und keine signifikanten Unterschiede zwischen den verschiedenen Kanälen beobachtet werden Einstellungen. Leistungsunterschied. Daher behält dieser Artikel die Standardeinstellungen in LLaMA bei. Grundfrequenz: In diesem Artikel wird die Grundfrequenz geändert und verglichen. Die Ergebnisse sind in Tabelle 11c aufgeführt. Die Ergebnisse zeigen, dass die Leistung für einen weiten Frequenzbereich robust ist. Daher behält dieser Artikel die Standardwerte in LLaMA bei, um zusätzliche Sonderbehandlungen zum Zeitpunkt der Bereitstellung zu vermeiden. Gemeinsame Positionscodierung zwischen den einzelnen Aufmerksamkeitsköpfen: In diesem Artikel wird festgestellt, dass die gemeinsame Nutzung des gleichen PE zwischen verschiedenen Köpfen (die Häufigkeit in jedem Kopf variiert zwischen 1 und 10.000) besser ist als die unabhängige PE (die Häufigkeit in allen Kanälen variiert zwischen 1 und 10.000). ), die Ergebnisse sind in Tabelle 11d dargestellt. Feature-Abstraktionsstrategie: In diesem Artikel werden zwei gängige Feature-Extraktionsstrategien für ein Modell mit großer Parameterskala (-L) verglichen. Die Ergebnisse sind in Tabelle 11e dargestellt unterscheidet sich von der Schlussfolgerung aus PEG [13]. Allerdings sind die Trainingseinstellungen für die beiden Methoden recht unterschiedlich. Dieser Artikel führte auch zusätzliche Experimente mit DeiT3-L durch und kam zu ähnlichen Schlussfolgerungen. In diesem Artikel wird die Leistung der „kleinen“ (-S) und „Basis“-Modelle (-B) weiter bewertet. Interessanterweise wurde bei kleinen Modellen die gegenteilige Schlussfolgerung beobachtet, und es besteht Grund zu der Annahme, dass die in DeiT3 verwendete höhere Drop-Path-Rate es schwierig macht, den gewünschten Effekt mit parameterfreien Abstraktionsmethoden wie GAP zu erzielen. Positionskodierungsstrategie: In diesem Artikel werden auch andere absolute Positionskodierungsstrategien, wie z. B. lernbare Positionskodierung und PEG, anhand der Pyramidenstruktur VisionLLaMA-S bewertet. Da es eine starke Basislinie gibt, verwendet dieser Artikel das „kleine“ Modell, und die Ergebnisse sind in Tabelle 11f dargestellt: Erlernbares PE verbessert die Leistung nicht, PEG verbessert die Basislinie geringfügig von 81,6 % auf 81,8 %. In diesem Artikel wird PEG aus drei Gründen nicht als wesentlicher Bestandteil aufgeführt. Zunächst wird in diesem Artikel versucht, minimale Änderungen an LLaMA vorzunehmen. Zweitens besteht das Ziel dieses Papiers darin, einen allgemeinen Ansatz für verschiedene Aufgaben wie ViT vorzuschlagen. Bei maskierten Bildframeworks wie MAE erhöht PEG die Schulungskosten und kann die Leistung bei nachgelagerten Aufgaben beeinträchtigen. Im Prinzip kann spärliches PEG im MAE-Framework angewendet werden, es werden jedoch einsatzunfreundliche Operatoren eingeführt. Ob spärliche Faltungen genauso viele Positionsinformationen enthalten wie ihre dichten Versionen, bleibt eine offene Frage. Drittens ebnet das modalitätsfreie Design den Weg für weitere Forschung, die andere Modalitäten über Text und Bild hinaus abdeckt. Empfindlichkeit gegenüber der Eingabegröße: Ohne Training vergleicht dieser Artikel die Leistung einer erhöhten Auflösung und einer herkömmlichen Auflösung weiter. Die Ergebnisse sind in Tabelle 12 aufgeführt. Der Pyramidenstrukturtransformator wird hier verwendet, da er für nachgelagerte Aufgaben beliebter ist als die entsprechende nicht-hierarchische Version. Es ist nicht verwunderlich, dass die Leistung von 1D-RoPE durch Auflösungsänderungen stark beeinträchtigt wird. NTK-Aware-Interpolation mit α = 2 erreicht eine ähnliche Leistung wie 2D-RoPE, das eigentlich NTKAware ist (α = 1). AS2DRoPE zeigt die beste Leistung bei größeren Auflösungen. Konvergenzgeschwindigkeit: Für die Bilderzeugung untersucht dieser Artikel die Leistung unter verschiedenen Trainingsschritten und speichert Gewichte, um den Wiedergabetreueindex bei 100.000, 200.000, 300.000 und 400.000 Iterationen zu berechnen. Da SDE deutlich langsamer als ODE ist, haben wir uns in diesem Artikel für die Verwendung des ODE-Samplers entschieden. Die Ergebnisse in Tabelle 10 zeigen, dass VisionLLaMA auf allen Modellen viel schneller konvergiert als ViT. SiT-LLaMA übertrifft mit 300.000 Trainingsiterationen sogar das Basismodell mit 400.000 Trainingsiterationen. Dieses Papier vergleicht auch mit der Top-1-Genauigkeit von 800 Epochen vollständig überwachten Trainings auf ImageNet mit DeiT3-Large in Abbildung 4 und zeigt, dass VisionLLaMA schneller konvergiert als DeiT3-L. Dieser Artikel vergleicht außerdem den Trainingsverlust von 800 Epochen des ViT-Base-Modells unter dem MAE-Framework und ist in Abbildung 5 dargestellt. VisionLLaMA weist zu Beginn einen geringeren Trainingsverlust auf und behält diesen Trend bis zum Ende bei. 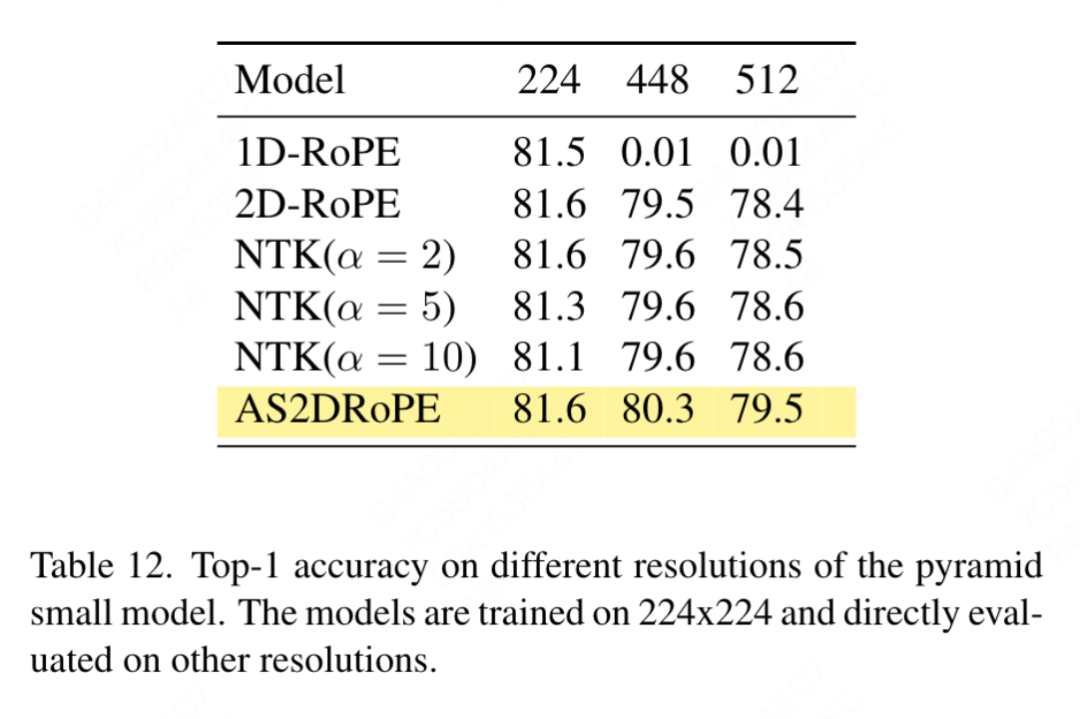
Diskussion
Das obige ist der detaillierte Inhalt vonViT, Meituan, die Zhejiang-Universität usw. weit übertreffend, schlug VisionLLAMA vor, eine einheitliche Architektur für visuelle Aufgaben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
