
 Technologie-Peripheriegeräte
KI
Neue Arbeit von Tian Yuandong und anderen: Durchbrechen des Speicherengpasses und Ermöglichen eines 4090 vorab trainierten 7B-Großmodells
Technologie-Peripheriegeräte
KI
Neue Arbeit von Tian Yuandong und anderen: Durchbrechen des Speicherengpasses und Ermöglichen eines 4090 vorab trainierten 7B-Großmodells
Neue Arbeit von Tian Yuandong und anderen: Durchbrechen des Speicherengpasses und Ermöglichen eines 4090 vorab trainierten 7B-Großmodells

Meta FAIR Das Forschungsprojekt, an dem Tian Yuandong teilnahm, erhielt letzten Monat großes Lob. In ihrem Artikel „MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases“ begannen sie zu untersuchen, wie kleine Modelle mit weniger als 1 Milliarde Parametern optimiert werden können, um das Ziel zu erreichen, große Sprachmodelle auf mobilen Geräten auszuführen .
Am 6. März veröffentlichte das Team von Tian Yuandong die neuesten Forschungsergebnisse, diesmal mit Schwerpunkt auf der Verbesserung der Effizienz des LLM-Speichers. Zum Forschungsteam gehören neben Tian Yuandong selbst auch Forscher des California Institute of Technology, der University of Texas at Austin und der CMU. Ziel dieser Forschung ist es, die Leistung des LLM-Speichers weiter zu optimieren und Unterstützung und Anleitung für die zukünftige Technologieentwicklung bereitzustellen.
Sie schlugen gemeinsam eine Trainingsstrategie namens GaLore (Gradient Low-Rank Projection) vor, die ein vollständiges Parameterlernen ermöglicht. Im Vergleich zu herkömmlichen adaptiven Methoden mit niedrigem Rang wie LoRA weist GaLore eine höhere Gedächtniseffizienz auf.
Diese Studie zeigt zum ersten Mal, dass 7B-Modelle erfolgreich auf einer Consumer-GPU mit 24 GB Speicher (z. B. NVIDIA RTX 4090) vorab trainiert werden können, ohne Modellparallelität, Checkpointing oder Offloading-Strategien zu verwenden.

Papieradresse: https://arxiv.org/abs/2403.03507
Papiertitel: GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Lass uns als nächstes einen Blick darauf werfen Der Hauptinhalt des Artikels.
Derzeit haben große Sprachmodelle (LLM) in vielen Bereichen ein herausragendes Potenzial gezeigt, aber wir müssen uns auch einem echten Problem stellen, nämlich dass das Vortraining und die Feinabstimmung von LLM nicht nur eine große Menge an Rechenressourcen erfordern. erfordern aber auch viel Speicherunterstützung.
Der Speicherbedarf von LLM umfasst nicht nur Parameter in Milliardenhöhe, sondern auch Gradienten und Optimiererzustände (wie Gradientenimpuls und Varianz in Adam), die größer sein können als der Speicher selbst. Beispielsweise erfordert LLaMA 7B, das von Grund auf mit einer einzelnen Batch-Größe vorab trainiert wurde, mindestens 58 GB Speicher (14 GB für trainierbare Parameter, 42 GB für Adam Optimizer States und Gewichtsgradienten und 2 GB für Aktivierungen). Dadurch ist das Training von LLM auf Consumer-GPUs wie der NVIDIA RTX 4090 mit 24 GB Speicher nicht möglich.
Um die oben genannten Probleme zu lösen, entwickeln Forscher weiterhin verschiedene Optimierungstechniken, um die Speichernutzung während des Vortrainings und der Feinabstimmung zu reduzieren.
Diese Methode reduziert die Speichernutzung unter Optimierungszuständen um 65,5 %, während die Effizienz und Leistung des Vortrainings auf LLaMA 1B- und 7B-Architekturen unter Verwendung des C4-Datensatzes mit bis zu 19,7 B-Tokens und in GLUE-Feinabstimmung erhalten bleibt Effizienz und Leistung von RoBERTa bei der Aufgabe. Im Vergleich zur BF16-Basislinie reduziert 8-Bit-GaLore den Optimierungsspeicher um 82,5 % und den gesamten Trainingsspeicher um 63,3 %.
Nachdem sie diese Studie gesehen hatten, sagten Internetnutzer: „Es ist Zeit, die Cloud und HPC zu vergessen. Mit GaLore wird die gesamte AI4Science auf einer 2.000-Dollar-GPU für Endverbraucher durchgeführt.“
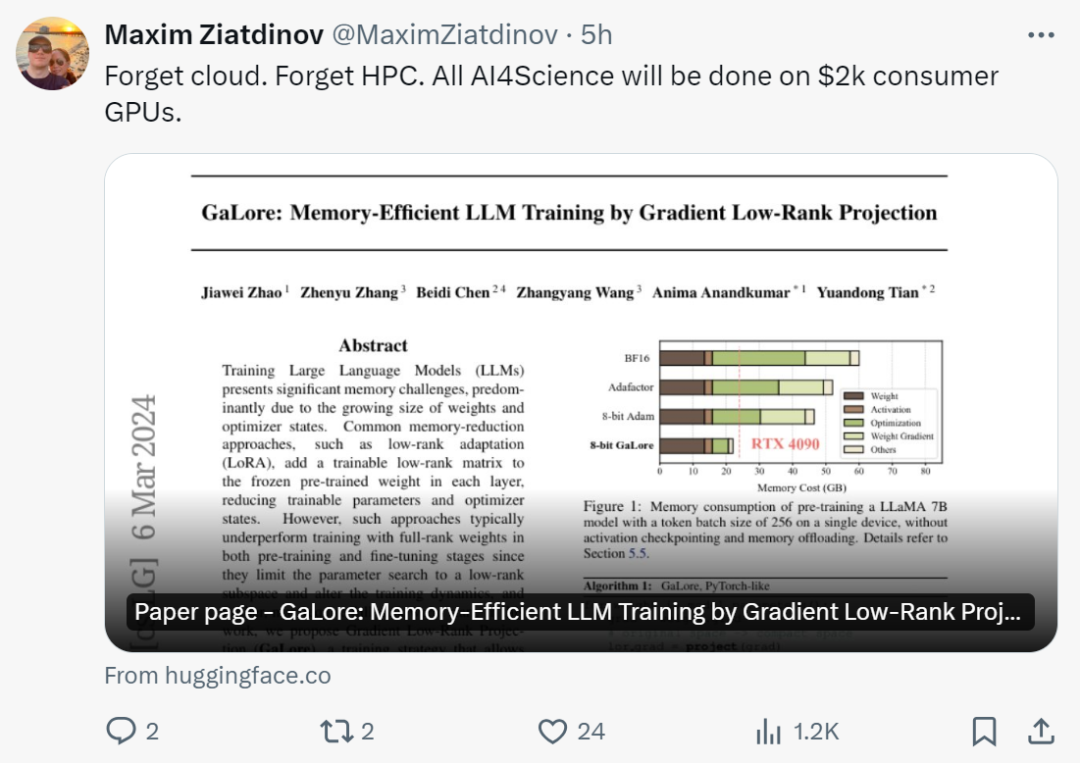
Tian Yuandong sagte: „Mit GaLore ist es jetzt möglich, das 7B-Modell in NVidia RTX 4090s mit 24G-Speicher vorab zu trainieren.
Wir sind nicht von einer Low-Rank-Gewichtsstruktur wie LoRA ausgegangen, sondern haben bewiesen, dass der Gewichtsgradient von Natur aus niedrig ist.“ Rang und kann somit in einen (variierenden) niedrigdimensionalen Raum projiziert werden. Daher speichern wir gleichzeitig Speicher für Gradienten, Adam-Impuls und Varianz
Daher verändert GaLore im Gegensatz zu LoRA nicht die Trainingsdynamik und kann dies auch tun Beginnen Sie mit dem Vortraining des 7B-Modells ohne speicherintensives Aufwärmen und erzielen Sie Ergebnisse, die mit denen von LoRA vergleichbar sind.
Methodeneinführung
Wie bereits erwähnt, ist GaLore eine Trainingsstrategie, die das Lernen vollständiger Parameter ermöglicht, aber speichereffizienter ist als gängige adaptive Methoden mit niedrigem Rang (wie LoRA). Die Schlüsselidee von GaLore besteht darin, die sich langsam ändernde Struktur mit niedrigem Rang des Gradienten 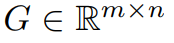 der Gewichtsmatrix W zu nutzen, anstatt zu versuchen, die Gewichtsmatrix direkt in eine Form mit niedrigem Rang zu approximieren.
der Gewichtsmatrix W zu nutzen, anstatt zu versuchen, die Gewichtsmatrix direkt in eine Form mit niedrigem Rang zu approximieren.
Dieser Artikel beweist zunächst theoretisch, dass die Gradientenmatrix G während des Trainingsprozesses einen niedrigen Rang erhält. Auf der Grundlage der Theorie verwendet dieser Artikel GaLore, um zwei Projektionsmatrizen zu berechnen 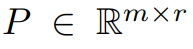 und
und 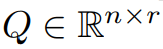 , um die Gradientenmatrix G zu projizieren Niedrigrangige Form P^⊤GQ. In diesem Fall können die Speicherkosten von Optimiererzuständen, die auf Komponentengradientenstatistiken basieren, erheblich reduziert werden. Wie in Tabelle 1 gezeigt, ist GaLore speichereffizienter als LoRA. Tatsächlich kann dies im Vergleich zu LoRA das Gedächtnis während des Vortrainings um bis zu 30 % reduzieren.
, um die Gradientenmatrix G zu projizieren Niedrigrangige Form P^⊤GQ. In diesem Fall können die Speicherkosten von Optimiererzuständen, die auf Komponentengradientenstatistiken basieren, erheblich reduziert werden. Wie in Tabelle 1 gezeigt, ist GaLore speichereffizienter als LoRA. Tatsächlich kann dies im Vergleich zu LoRA das Gedächtnis während des Vortrainings um bis zu 30 % reduzieren.

Dieser Artikel beweist, dass GaLore beim Vortraining und bei der Feinabstimmung gute Leistungen erbringt. Beim Vortraining von LLaMA 7B auf dem C4-Datensatz kombiniert 8-Bit-GaLore einen 8-Bit-Optimierer und eine Schicht-für-Schicht-Gewichtsaktualisierungstechnologie, um eine mit Full Rank vergleichbare Leistung zu erreichen, mit weniger als 10 % Speicherkosten für den Optimiererstatus.
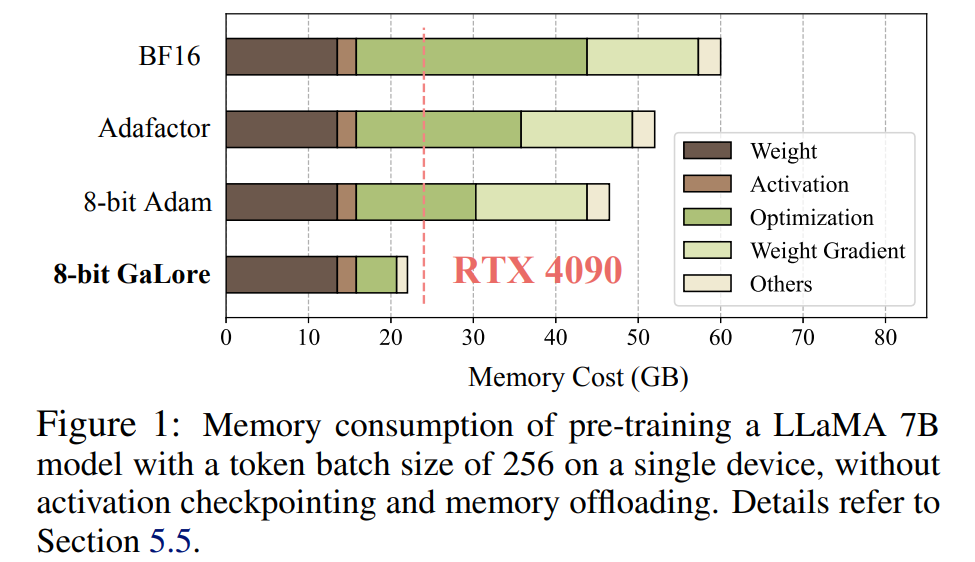
Es ist erwähnenswert, dass GaLore vor dem Training das Gedächtnis während des gesamten Trainingsprozesses niedrig hält, ohne dass ein umfassendes Training wie ReLoRA erforderlich ist. Dank der Speichereffizienz von GaLore kann LLaMA 7B erstmals von Grund auf auf einer einzelnen GPU mit 24 GB Speicher (z. B. auf einer NVIDIA RTX 4090) trainiert werden, ohne dass teure Techniken zur Speicherauslagerung erforderlich sind (Abbildung 1).
Als Gradientenprojektionsmethode ist GaLore unabhängig von der Wahl des Optimierers und kann einfach mit nur zwei Codezeilen in einen vorhandenen Optimierer eingebunden werden, wie in Algorithmus 1 gezeigt.

Die folgende Abbildung zeigt den Algorithmus zur Anwendung von GaLore auf Adam:

Experimente und Ergebnisse
Die Forscher bewerteten das Vortraining von GaLore und die Feinabstimmung von LLM. Alle Experimente wurden auf einer NVIDIA A100-GPU durchgeführt.
Um seine Leistung zu bewerten, verwendeten die Forscher GaLore, um ein großes Sprachmodell basierend auf LLaMA auf dem C4-Datensatz zu trainieren. Der C4-Datensatz ist eine riesige, bereinigte Version des Web-Crawling-Korpus Common Crawl, der hauptsächlich zum Vorabtrainieren von Sprachmodellen und Wortdarstellungen verwendet wird. Um das tatsächliche Szenario vor dem Training bestmöglich zu simulieren, trainierten die Forscher mit einer ausreichend großen Datenmenge, ohne die Daten zu duplizieren, wobei die Modellgrößen bis zu 7 Milliarden Parameter umfassten.
Dieses Papier folgt dem experimentellen Aufbau von Lialin et al. und verwendet eine LLaMA3-basierte Architektur mit RMSNorm- und SwiGLU-Aktivierung. Für jede Modellgröße verwendeten sie mit Ausnahme der Lernrate den gleichen Satz an Hyperparametern und führten alle Experimente im BF16-Format durch, um die Speichernutzung zu reduzieren und gleichzeitig die Lernrate für jede Methode mit demselben Rechenbudget anzupassen und eine optimale Leistung zu erzielen.
Darüber hinaus nutzten die Forscher die GLUE-Aufgabe als Benchmark für die speichereffiziente Feinabstimmung von GaLore und LoRA. GLUE ist ein Benchmark zur Bewertung der Leistung von NLP-Modellen bei einer Vielzahl von Aufgaben, einschließlich Stimmungsanalyse, Beantwortung von Fragen und Textkorrelation.
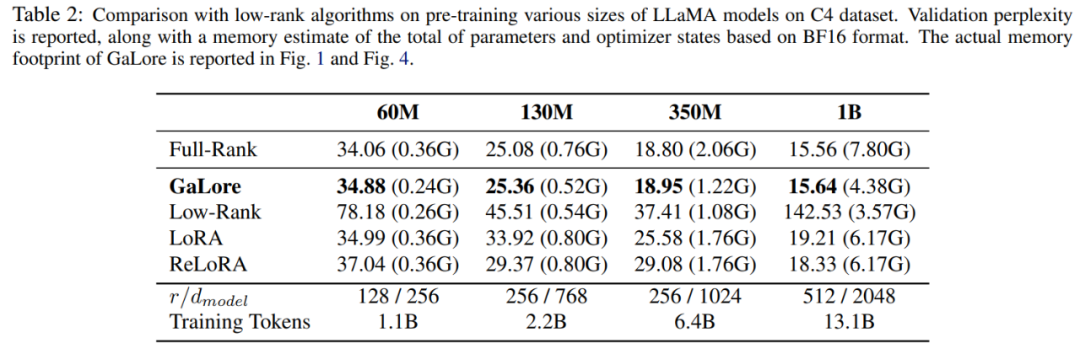
In diesem Artikel wird zunächst der Adam-Optimierer verwendet, um GaLore mit vorhandenen Low-Rank-Methoden zu vergleichen. Die Ergebnisse sind in Tabelle 2 aufgeführt.
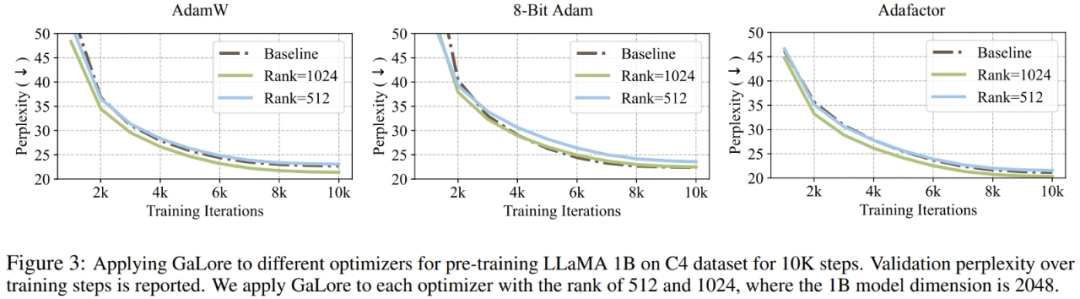
Forscher haben bewiesen, dass GaLore auf verschiedene Lernalgorithmen, insbesondere speichereffiziente Optimierer, angewendet werden kann, um die Speichernutzung weiter zu reduzieren. Die Forscher wendeten GaLore auf die Optimierer AdamW, 8-bit Adam und Adafactor an. Sie verwenden den statistischen Adafaktor erster Ordnung, um Leistungseinbußen zu vermeiden.
Experimentes bewertete sie auf der LLaMA 1B-Architektur mit 10.000 Trainingsschritten, optimierte die Lernrate für jede Einstellung und meldete die beste Leistung. Wie in Abbildung 3 dargestellt, zeigt die folgende Grafik, dass GaLore mit gängigen Optimierern wie AdamW, 8-Bit Adam und Adafactor funktioniert. Darüber hinaus hat die Einführung sehr weniger Hyperparameter keinen Einfluss auf die Leistung von GaLore.
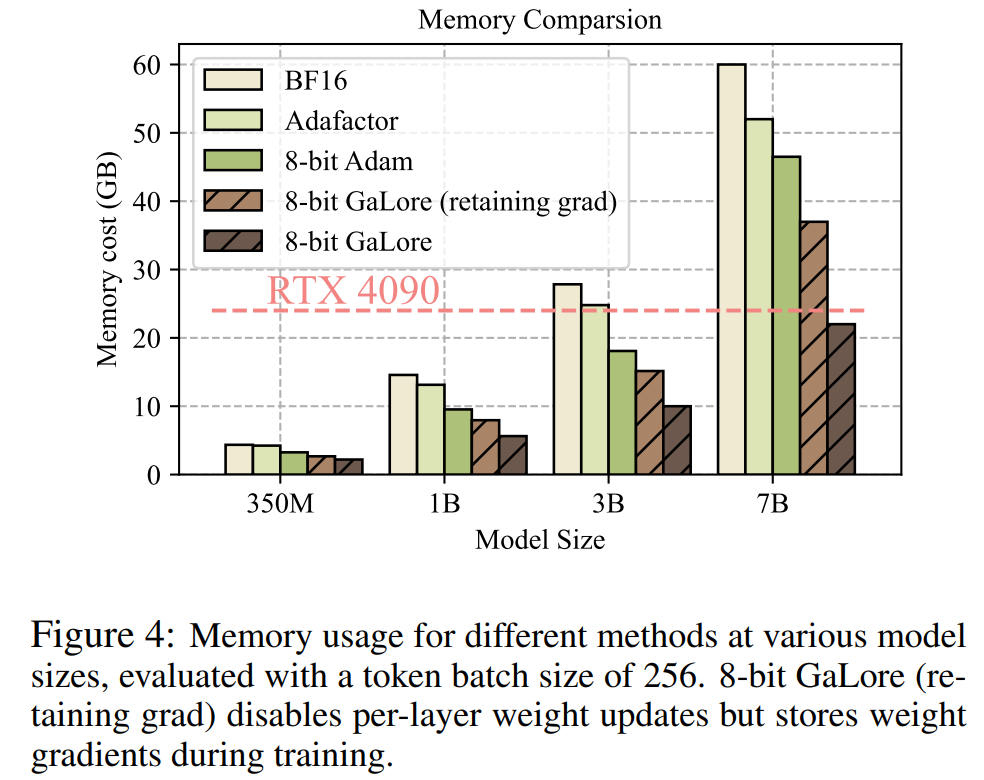
Wie in Tabelle 4 gezeigt, kann GaLore bei den meisten Aufgaben eine höhere Leistung als LoRA mit weniger Speicherverbrauch erzielen. Dies zeigt, dass GaLore als speichereffiziente Full-Stack-Trainingsstrategie für das LLM-Vortraining und die Feinabstimmung verwendet werden kann.
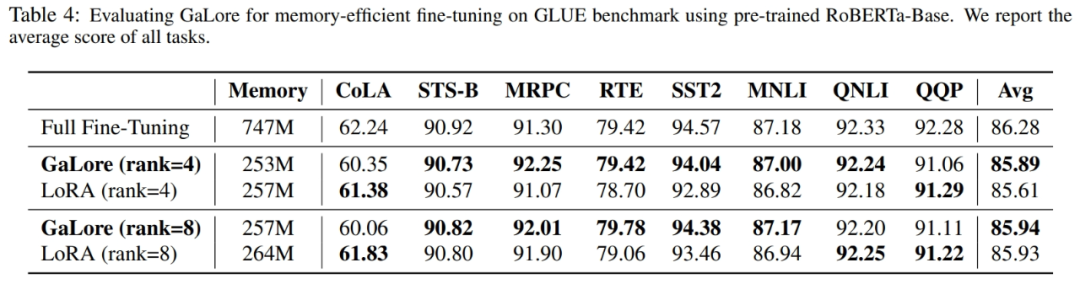
Wie in Abbildung 4 gezeigt, benötigt 8-Bit-GaLore im Vergleich zum BF16-Benchmark und 8-Bit-Adam viel weniger Speicher, beim Vortraining von LLaMA 7B werden nur 22,0 G Speicher und die Token-Batchgröße jeder GPU benötigt ist kleiner (bis zu 500 Token).
Für weitere technische Details lesen Sie bitte das Originalpapier.
Das obige ist der detaillierte Inhalt vonNeue Arbeit von Tian Yuandong und anderen: Durchbrechen des Speicherengpasses und Ermöglichen eines 4090 vorab trainierten 7B-Großmodells. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Die lokale Feinabstimmung von Deepseek-Klasse-Modellen steht vor der Herausforderung unzureichender Rechenressourcen und Fachkenntnisse. Um diese Herausforderungen zu bewältigen, können die folgenden Strategien angewendet werden: Modellquantisierung: Umwandlung von Modellparametern in Ganzzahlen mit niedriger Präzision und Reduzierung des Speicherboots. Verwenden Sie kleinere Modelle: Wählen Sie ein vorgezogenes Modell mit kleineren Parametern für eine einfachere lokale Feinabstimmung aus. Datenauswahl und Vorverarbeitung: Wählen Sie hochwertige Daten aus und führen Sie eine geeignete Vorverarbeitung durch, um eine schlechte Datenqualität zu vermeiden, die die Modelleffizienz beeinflusst. Batch -Training: Laden Sie für große Datensätze Daten in Stapel für das Training, um den Speicherüberlauf zu vermeiden. Beschleunigung mit GPU: Verwenden Sie unabhängige Grafikkarten, um den Schulungsprozess zu beschleunigen und die Trainingszeit zu verkürzen.
 Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
1. Rufen Sie zunächst den Edge-Browser auf und klicken Sie auf die drei Punkte in der oberen rechten Ecke. 2. Wählen Sie dann in der Taskleiste [Erweiterungen] aus. 3. Schließen oder deinstallieren Sie als Nächstes die Plug-Ins, die Sie nicht benötigen.
 Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Um große Sprachmodelle (LLMs) an menschlichen Werten und Absichten auszurichten, ist es wichtig, menschliches Feedback zu lernen, um sicherzustellen, dass sie nützlich, ehrlich und harmlos sind. Im Hinblick auf die Ausrichtung von LLM ist Reinforcement Learning basierend auf menschlichem Feedback (RLHF) eine wirksame Methode. Obwohl die Ergebnisse der RLHF-Methode ausgezeichnet sind, gibt es einige Herausforderungen bei der Optimierung. Dazu gehört das Training eines Belohnungsmodells und die anschließende Optimierung eines Richtlinienmodells, um diese Belohnung zu maximieren. Kürzlich haben einige Forscher einfachere Offline-Algorithmen untersucht, darunter die direkte Präferenzoptimierung (Direct Preference Optimization, DPO). DPO lernt das Richtlinienmodell direkt auf der Grundlage von Präferenzdaten, indem es die Belohnungsfunktion in RLHF parametrisiert, wodurch die Notwendigkeit eines expliziten Belohnungsmodells entfällt. Diese Methode ist einfach und stabil
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
 KI-Startups wechselten gemeinsam ihre Jobs zu OpenAI, und das Sicherheitsteam formierte sich neu, nachdem Ilya gegangen war!
Jun 08, 2024 pm 01:00 PM
KI-Startups wechselten gemeinsam ihre Jobs zu OpenAI, und das Sicherheitsteam formierte sich neu, nachdem Ilya gegangen war!
Jun 08, 2024 pm 01:00 PM
Letzte Woche wurde OpenAI inmitten der Welle interner Kündigungen und externer Kritik von internen und externen Problemen geplagt: - Der Verstoß gegen die Schwester der Witwe löste weltweit hitzige Diskussionen aus - Mitarbeiter, die „Overlord-Klauseln“ unterzeichneten, wurden einer nach dem anderen entlarvt – Internetnutzer listeten Ultramans „ Sieben Todsünden“ – Gerüchtebekämpfung: Laut durchgesickerten Informationen und Dokumenten, die Vox erhalten hat, war sich die leitende Führung von OpenAI, darunter Altman, dieser Eigenkapitalrückgewinnungsbestimmungen wohl bewusst und hat ihnen zugestimmt. Darüber hinaus steht OpenAI vor einem ernsten und dringenden Problem – der KI-Sicherheit. Die jüngsten Abgänge von fünf sicherheitsrelevanten Mitarbeitern, darunter zwei der prominentesten Mitarbeiter, und die Auflösung des „Super Alignment“-Teams haben die Sicherheitsprobleme von OpenAI erneut ins Rampenlicht gerückt. Das Fortune-Magazin berichtete, dass OpenA
 LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
May 09, 2024 pm 04:55 PM
LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
May 09, 2024 pm 04:55 PM
Oben geschrieben und persönliches Verständnis des Autors: Dieses Papier widmet sich der Lösung der wichtigsten Herausforderungen aktueller multimodaler großer Sprachmodelle (MLLMs) in autonomen Fahranwendungen, nämlich dem Problem der Erweiterung von MLLMs vom 2D-Verständnis auf den 3D-Raum. Diese Erweiterung ist besonders wichtig, da autonome Fahrzeuge (AVs) genaue Entscheidungen über 3D-Umgebungen treffen müssen. Das räumliche 3D-Verständnis ist für AVs von entscheidender Bedeutung, da es sich direkt auf die Fähigkeit des Fahrzeugs auswirkt, fundierte Entscheidungen zu treffen, zukünftige Zustände vorherzusagen und sicher mit der Umgebung zu interagieren. Aktuelle multimodale große Sprachmodelle (wie LLaVA-1.5) können häufig nur Bildeingaben mit niedrigerer Auflösung verarbeiten (z. B. aufgrund von Auflösungsbeschränkungen des visuellen Encoders und Einschränkungen der LLM-Sequenzlänge). Allerdings erfordern autonome Fahranwendungen
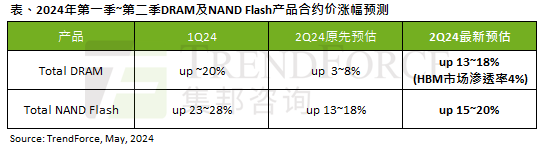 Die Auswirkungen der KI-Welle sind offensichtlich. TrendForce hat seine Prognose für Preiserhöhungen bei DRAM-Speicher und NAND-Flash-Speicher in diesem Quartal nach oben korrigiert.
May 07, 2024 pm 09:58 PM
Die Auswirkungen der KI-Welle sind offensichtlich. TrendForce hat seine Prognose für Preiserhöhungen bei DRAM-Speicher und NAND-Flash-Speicher in diesem Quartal nach oben korrigiert.
May 07, 2024 pm 09:58 PM
Laut einem TrendForce-Umfragebericht hat die KI-Welle erhebliche Auswirkungen auf die Märkte für DRAM-Speicher und NAND-Flash-Speicher. In den Nachrichten dieser Website vom 7. Mai sagte TrendForce heute in seinem neuesten Forschungsbericht, dass die Agentur die Vertragspreiserhöhungen für zwei Arten von Speicherprodukten in diesem Quartal erhöht habe. Konkret schätzte TrendForce ursprünglich, dass der DRAM-Speichervertragspreis im zweiten Quartal 2024 um 3 bis 8 % steigen wird, und schätzt ihn nun auf 13 bis 18 %, bezogen auf NAND-Flash-Speicher, die ursprüngliche Schätzung wird um 13 bis 18 % steigen 18 %, und die neue Schätzung liegt bei 15 %, nur eMMC/UFS weist einen geringeren Anstieg von 10 % auf. ▲Bildquelle TrendForce TrendForce gab an, dass die Agentur ursprünglich damit gerechnet hatte, dies auch weiterhin zu tun
