
 Technologie-Peripheriegeräte
KI
Machen Sie große Modelle um 90 % „schlank'! Die Tsinghua-Universität und das Harbin Institute of Technology schlugen eine extreme Komprimierungslösung vor: 1-Bit-Quantisierung unter Beibehaltung von 83 % der Kapazität.
Technologie-Peripheriegeräte
KI
Machen Sie große Modelle um 90 % „schlank'! Die Tsinghua-Universität und das Harbin Institute of Technology schlugen eine extreme Komprimierungslösung vor: 1-Bit-Quantisierung unter Beibehaltung von 83 % der Kapazität.
Machen Sie große Modelle um 90 % „schlank'! Die Tsinghua-Universität und das Harbin Institute of Technology schlugen eine extreme Komprimierungslösung vor: 1-Bit-Quantisierung unter Beibehaltung von 83 % der Kapazität.

Quantifizierung, Bereinigung und andere KomprimierungVorgänge an großen Modellen sind der häufigste Teil der Bereitstellung.
Aber wie hoch ist dieses Limit?
Eine gemeinsame Studie der Tsinghua University und des Harbin Institute of Technology ergab die Antwort:
90 %.
Sie schlugen ein 1-Bit-Extremkomprimierungs-Framework für große Modelle vor, OneBit, das zum ersten Mal eine Gewichtskomprimierung für große Modelle von über 90 % erreichte und die meisten (83 %) Fähigkeiten beibehielt.
Man kann sagen, dass es beim Spielen um „Wollen und Wollen“ geht~

Lassen Sie uns einen Blick darauf werfen.
Die 1-Bit-Quantisierungsmethode für große Modelle ist da
Von der Beschneidung und Quantisierung bis hin zur Wissensdestillation und der Zerlegung niedriger Gewichte können große Modelle bereits ein Viertel des Gewichts fast ohne Verlust komprimieren.
Gewichtungsquantisierung wandelt typischerweise die Parameter eines großen Modells in eine Darstellung mit geringer Bitbreite um. Dies kann durch die Transformation eines vollständig trainierten Modells (PTQ) oder die Einführung eines Quantisierungsschritts während des Trainings (QAT) erreicht werden. Dieser Ansatz trägt dazu bei, den Rechen- und Speicherbedarf des Modells zu reduzieren und dadurch die Effizienz und Leistung des Modells zu verbessern. Durch die Quantisierung der Gewichte kann die Größe des Modells erheblich reduziert werden, wodurch es sich besser für den Einsatz in ressourcenbeschränkten Umgebungen eignet, während
Allerdings sind bestehende Quantisierungsmethoden mit erheblichen Leistungseinbußen unter 3 Bit konfrontiert, hauptsächlich aufgrund von:
- Die vorhandene Methode zur Darstellung niedriger Bitbreiten mit Parametern weist bei 1 Bit einen erheblichen Genauigkeitsverlust auf. Wenn die auf der Round-To-Nearest-Methode basierenden Parameter in 1 Bit ausgedrückt werden, verlieren der konvertierte Skalierungskoeffizient s und der Nullpunkt z ihre praktische Bedeutung.
- Die bestehende 1-Bit-Modellstruktur berücksichtigt die Bedeutung der Gleitkommagenauigkeit nicht vollständig. Das Fehlen von Gleitkommaparametern kann die Stabilität des Modellberechnungsprozesses beeinträchtigen und die eigene Lernfähigkeit erheblich beeinträchtigen.
Um die Hindernisse der 1-Bit-Quantisierung mit ultraniedriger Bitbreite zu überwinden, schlägt der Autor ein neues 1-Bit-Modell-Framework vor: OneBit, das eine neue 1-Bit-lineare Schichtstruktur und eine SVID-basierte Parameterinitialisierungsmethode enthält und tiefes Transferlernen basierend auf quantisierungsbewusster Wissensdestillation.
Diese neue 1-Bit-Modellquantisierungsmethode kann die meisten Fähigkeiten des Originalmodells beibehalten, mit einem riesigen Komprimierungsbereich, extrem geringem Platzbedarf und begrenzten Rechenkosten. Dies ist für den Einsatz großer Modelle auf PCs und sogar Smartphones von großer Bedeutung.
Gesamtrahmen
Das OneBit-Rahmenwerk kann im Allgemeinen Folgendes umfassen: eine neu gestaltete 1-Bit-Modellstruktur, eine Methode zur Initialisierung quantifizierter Modellparameter basierend auf dem Originalmodell und eine umfassende Fähigkeitsmigration basierend auf Wissensdestillation.
Diese neu gestaltete 1-Bit-Modellstruktur kann das schwerwiegende Problem des Genauigkeitsverlusts bei der 1-Bit-Quantisierung in früheren Quantisierungsarbeiten wirksam überwinden und zeigt eine hervorragende Stabilität während des Trainings und der Migration.
Die Initialisierungsmethode des quantitativen Modells kann einen besseren Ausgangspunkt für die Wissensdestillation festlegen, die Konvergenz beschleunigen und bessere Fähigkeitsübertragungseffekte erzielen.
1. 1-Bit-Modellstruktur
1bit erfordert, dass jeder Gewichtswert nur durch 1 Bit dargestellt werden kann, sodass es höchstens zwei mögliche Zustände gibt.
Der Autor wählt ±1 als diese beiden Zustände. Der Vorteil besteht darin, dass es zwei Symbole im digitalen System darstellt, vollständigere Funktionen hat und leicht über die Funktion Sign(·) erhalten werden kann.
Die 1-Bit-Modellstruktur des Autors wird erreicht, indem alle linearen Schichten des FP16-Modells (außer der Einbettungsschicht und lm_head) durch lineare 1-Bit-Schichten ersetzt werden.
Zusätzlich zu der 1-Bit-Gewichtung, die durch die Funktion Sign(·) erhalten wird, enthält die lineare 1-Bit-Schicht hier auch zwei weitere Schlüsselkomponenten – den Wertevektor mit FP16-Präzision.
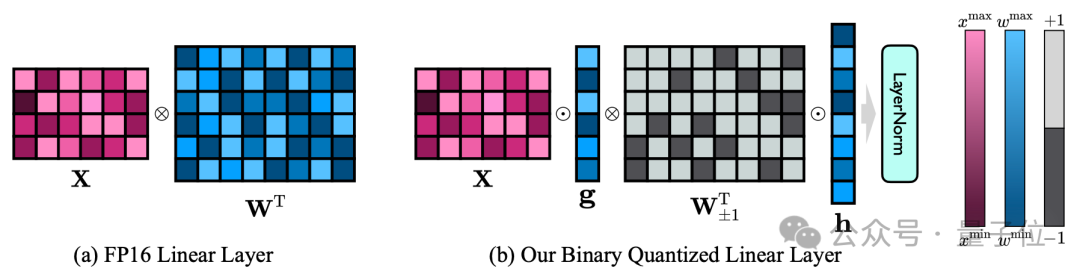
△Vergleich der linearen FP16-Schicht und der linearen OneBit-Schicht
Dieses Design behält nicht nur den hohen Rang der ursprünglichen Gewichtsmatrix bei, sondern bietet auch die erforderliche Gleitkommagenauigkeit durch den Wertevektor, was für die Gewährleistung der Stabilität von entscheidender Bedeutung ist und qualitativ hochwertiges Lernen Der Prozess ist sehr sinnvoll.
Wie aus der obigen Abbildung ersichtlich ist, verbleiben nur die Wertevektoren g und h im FP16-Format, während die Gewichtsmatrix vollständig aus ±1 besteht.
Der Autor kann anhand eines Beispiels einen Blick auf die Komprimierungsfunktionen von OneBit werfen.
Angenommen, um eine lineare 40964096 FP16-Schicht zu komprimieren, benötigt OneBit eine 40964096 1-Bit-Matrix und zwei 4096*1 FP16-Wertvektoren.
Die Gesamtzahl der Bits beträgt 16.908.288, die Gesamtzahl der Parameter beträgt 16.785.408 und jeder Parameter belegt im Durchschnitt nur etwa 1,0073 Bits.
Ein solcher Komprimierungsbereich ist beispiellos und kann als echtes 1-Bit-LLM bezeichnet werden.
2. Parameterinitialisierung und Transferlernen
Um das vollständig trainierte Originalmodell zur besseren Initialisierung des quantisierten Modells zu verwenden, schlägt der Autor eine neue Parametermatrix-Zerlegungsmethode namens „Value-Sign-Independent-Matrix“-Zerlegung (SVID) vor. ".
Diese Matrixzerlegungsmethode trennt Symbole und absolute Werte und führt eine Rang-1-Approximation für absolute Werte durch. Ihre Methode zur Approximation der ursprünglichen Matrixparameter kann wie folgt ausgedrückt werden:
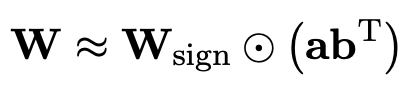
Rang-1-Näherung kann durch gängige Matrixfaktorisierungsmethoden wie Singular Value Decomposition (SVD) und nichtnegative Matrixfaktorisierung (NMF) erreicht werden.
Der Autor zeigt mathematisch, dass diese SVID-Methode dem 1-Bit-Modellrahmen entsprechen kann, indem die Reihenfolge der Operationen ausgetauscht wird, wodurch eine Parameterinitialisierung erreicht wird.
Darüber hinaus wurde auch der Beitrag der symbolischen Matrix zur Annäherung an die ursprüngliche Matrix während des Zerlegungsprozesses nachgewiesen. Weitere Informationen finden Sie im Artikel.
Der Autor glaubt, dass ein wirksamer Weg zur Lösung der Quantisierung großer Modelle mit extrem niedriger Bitbreite das quantisierungsbewusste Training von QAT sein könnte.
Nachdem SVID den Parameterstartpunkt des quantitativen Modells angegeben hat, verwendet der Autor das Originalmodell als Lehrermodell und lernt daraus durch Wissensdestillation.
Konkret erhält das Schülermodell hauptsächlich Anleitungen aus den Protokollen und dem verborgenen Zustand des Lehrermodells.
Während des Trainings werden die Werte des Wertevektors und der Parametermatrix aktualisiert, und während der Bereitstellung kann die quantisierte 1-Bit-Parametermatrix direkt zur Berechnung verwendet werden.
Je größer das Modell, desto besser der Effekt
Die vom Autor ausgewählten Basislinien sind FP16 Transformer, GPTQ, LLM-QAT und OmniQuant.
Die letzten drei sind alle klassische starke Basislinien im Bereich der Quantifizierung, insbesondere OmniQuant, die stärkste 2-Bit-Quantisierungsmethode seit dem Autor.
Da es derzeit keine Forschung zur 1-Bit-Gewichtsquantisierung gibt, verwendet der Autor nur die 1-Bit-Gewichtsquantisierung für das OneBit-Framework und übernimmt 2-Bit-Quantisierungseinstellungen für andere Methoden.
Für destillierte Daten folgte der Autor LLM-QAT und nutzte die Selbststichprobe des Lehrermodells, um Daten zu generieren.
Der Autor verwendet Modelle unterschiedlicher Größe von 1,3B bis 13B, OPT und LLaMA-1/2 in verschiedenen Serien, um die Wirksamkeit von OneBit zu beweisen. Als Bewertungsindikatoren werden die Verwirrung des Verifizierungssatzes und die Null-Schuss-Genauigkeit des gesunden Menschenverstandes verwendet. Einzelheiten finden Sie im Papier.
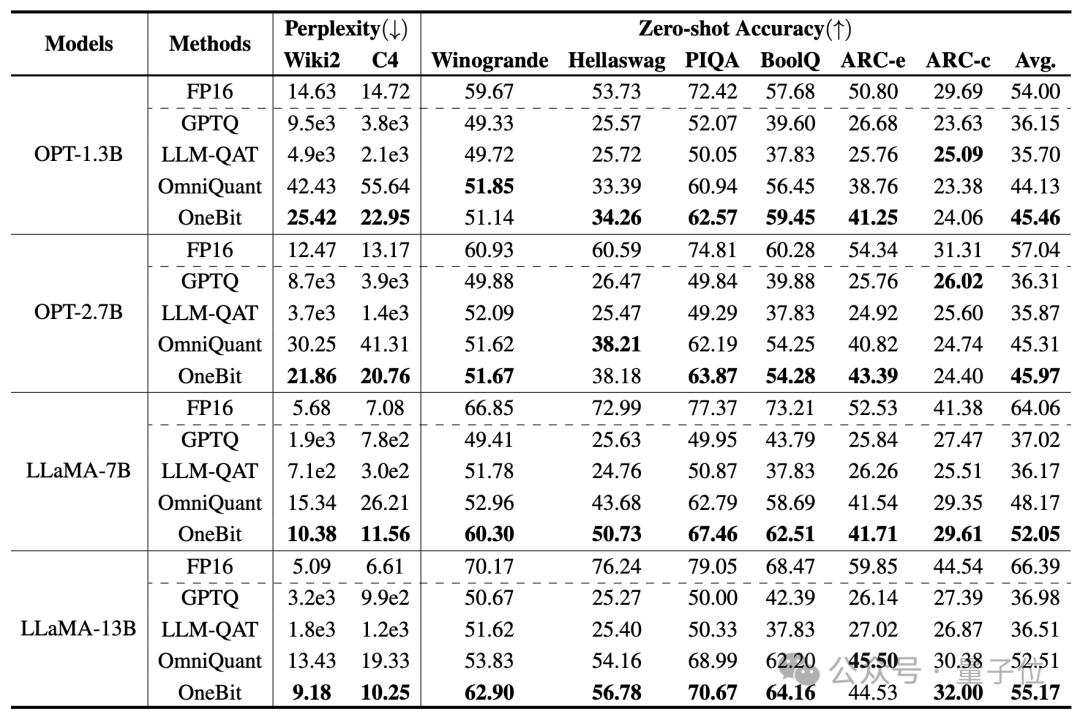
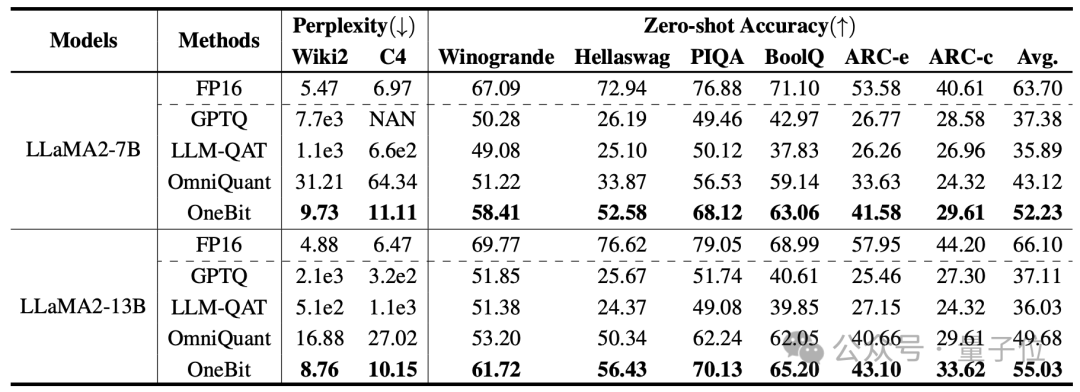
Die obige Tabelle zeigt die Vorteile von OneBit im Vergleich zu anderen Methoden bei der 1-Bit-Quantisierung. Es ist erwähnenswert, dass der OneBit-Effekt tendenziell besser ist, wenn das Modell größer ist.
Mit zunehmender Modellgröße verringert das quantifizierte OneBit-Modell die Verwirrung stärker als das FP16-Modell.
Das Folgende ist die vernünftige Argumentation, das Weltwissen und die Raumbelegung mehrerer verschiedener kleiner Modelle:
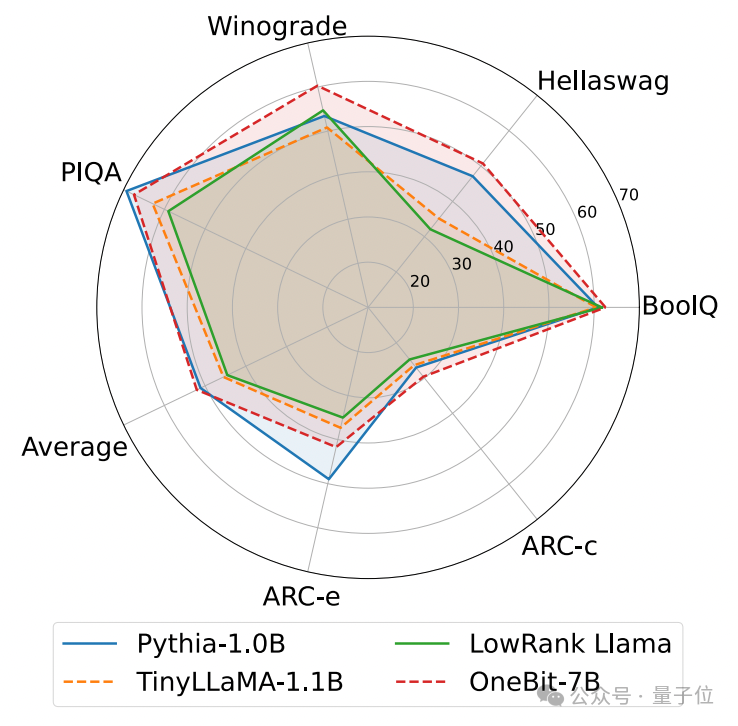
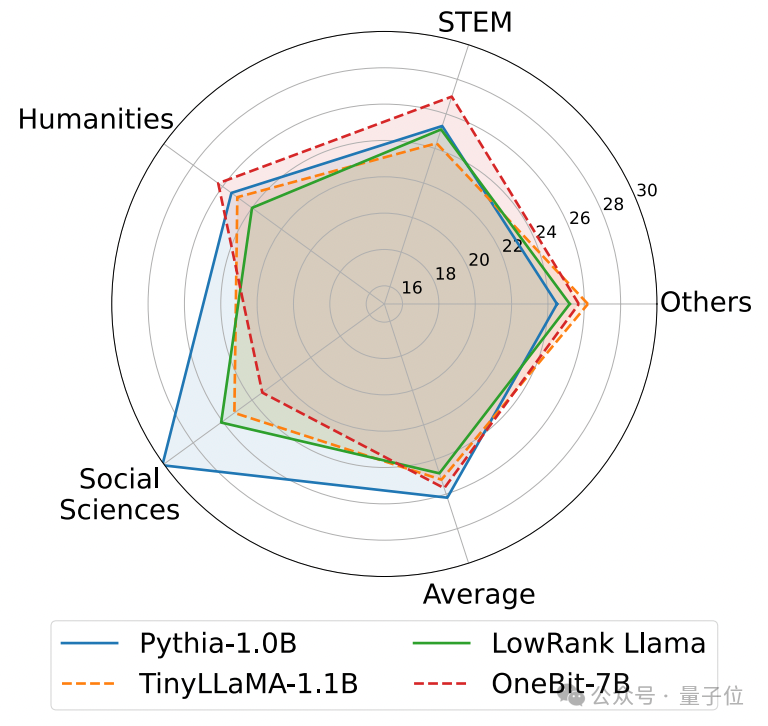
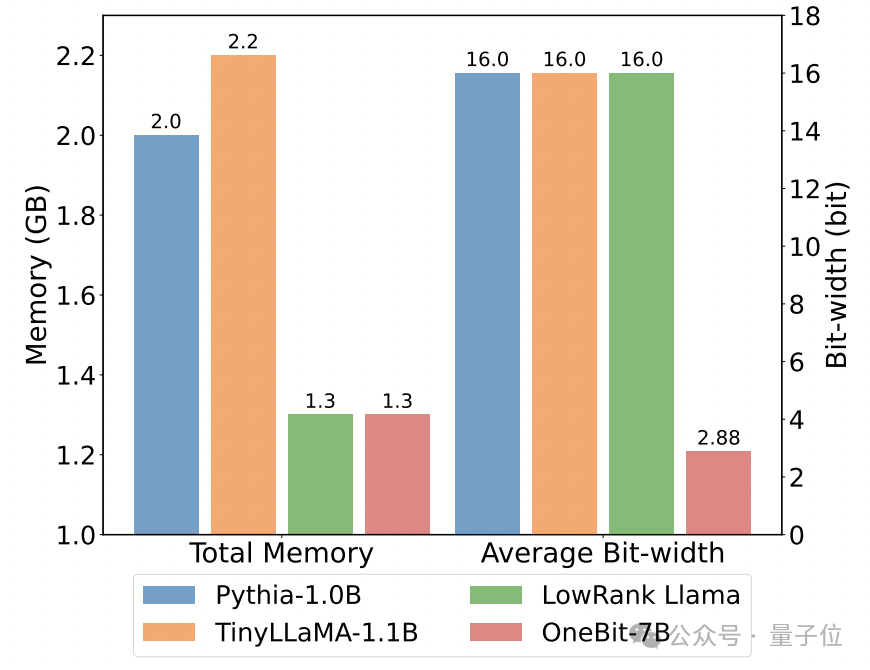
Der Autor verglich auch die Größe und tatsächlichen Fähigkeiten mehrerer verschiedener Arten kleiner Modelle.
Der Autor stellte fest, dass OneBit-7B zwar die kleinste durchschnittliche Bitbreite aufweist, den kleinsten Platz einnimmt und relativ wenige Trainingsschritte erfordert, anderen Modellen jedoch in Bezug auf die Fähigkeit zum gesunden Menschenverstand in nichts nachsteht.
Gleichzeitig stellte der Autor auch fest, dass das OneBit-7B-Modell ein ernsthaftes Wissensvergessen im Bereich der Sozialwissenschaften aufweist.

△Vergleich der linearen FP16-Ebene und der linearen OneBit-Ebene Ein Beispiel für die Textgenerierung nach der Feinabstimmung der OneBit-7B-Anweisung
Die obige Abbildung zeigt auch ein Beispiel für die Textgenerierung nach der Feinabstimmung der OneBit-7B-Anweisung. 7B-Anweisung. Es ist ersichtlich, dass OneBit-7B effektiv die Fähigkeiten der SFT-Stufe erlangt hat und Text relativ reibungslos generieren kann, obwohl die Gesamtparameter nur 1,3 GB betragen (vergleichbar mit dem 0,6B-Modell von FP16). Insgesamt zeigt OneBit-7B seinen praktischen Einsatzwert.
Analyse und Diskussion
Der Autor zeigt das Komprimierungsverhältnis von OneBit für LLaMA-Modelle unterschiedlicher Größe. Es ist ersichtlich, dass das Komprimierungsverhältnis von OneBit für das Modell erstaunliche 90 % übersteigt.
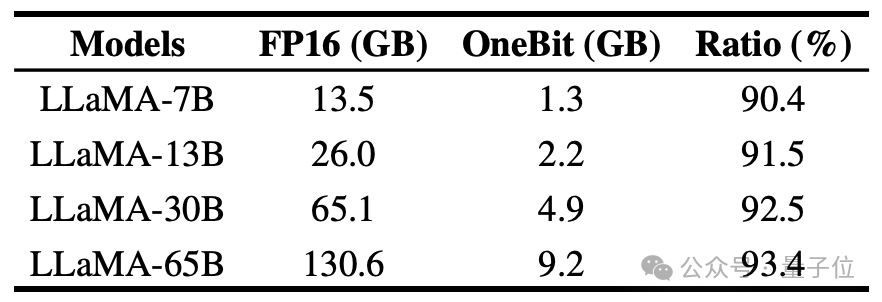
Insbesondere mit zunehmendem Modell wird das Komprimierungsverhältnis von OneBit höher.
Dies zeigt den Vorteil der Methode des Autors bei größeren Modellen: größerer Grenzgewinn (Perplexität) bei höheren Komprimierungsverhältnissen. Darüber hinaus erreicht der Ansatz der Autoren einen guten Kompromiss zwischen Größe und Leistung. 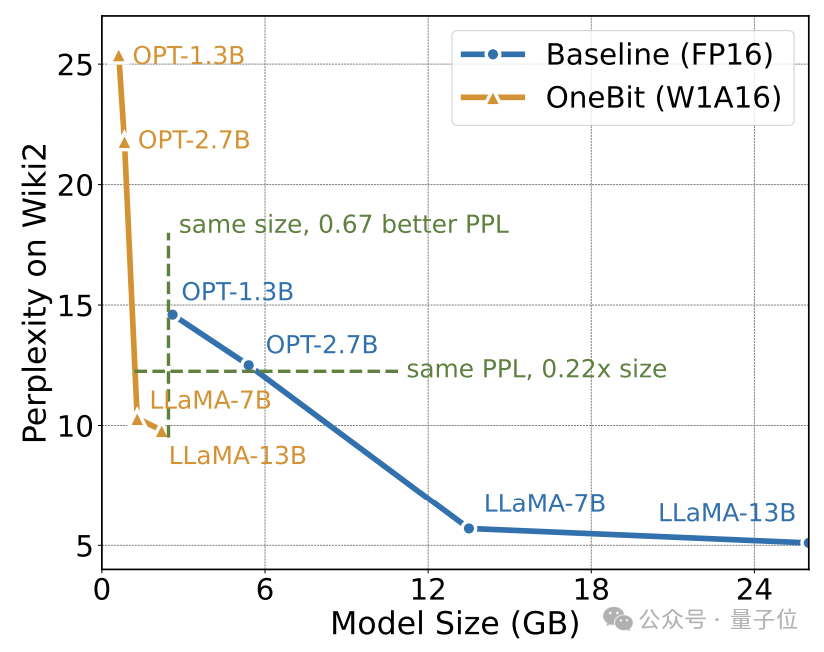
Das quantitative 1-Bit-Modell hat Rechenvorteile und ist von großer Bedeutung. Die rein binäre Darstellung von Parametern kann nicht nur viel Platz sparen, sondern auch die Hardwareanforderungen der Matrixmultiplikation reduzieren.
Die Elementmultiplikation der Matrixmultiplikation in hochpräzisen Modellen kann in effiziente Bitoperationen umgewandelt werden. Das Matrixprodukt kann nur durch Bitzuweisung und -addition vervollständigt werden, was große Anwendungsaussichten bietet.
Darüber hinaus sorgt die Methode des Autors für hervorragende stabile Lernfähigkeiten während des Trainingsprozesses.
Tatsächlich haben die Instabilitätsprobleme, die Empfindlichkeit gegenüber Hyperparametern und die Konvergenzschwierigkeiten des binären Netzwerktrainings die Forscher schon immer beschäftigt.
Der Autor analysiert die Bedeutung hochpräziser Wertevektoren für die Förderung einer stabilen Konvergenz des Modells.
Frühere Arbeiten haben eine 1-Bit-Modellarchitektur vorgeschlagen und diese verwendet, um Modelle von Grund auf zu trainieren (wie BitNet [1]), aber sie reagiert empfindlich auf Hyperparameter und es ist schwierig, das Lernen von vollständig trainierten hochpräzisen Modellen zu übertragen. Der Autor testete auch die Leistung von BitNet bei der Wissensdestillation und stellte fest, dass das Training nicht stabil genug war.
Zusammenfassung
Der Autor schlug eine Modellstruktur und eine entsprechende Parameterinitialisierungsmethode für die 1-Bit-Gewichtsquantisierung vor.
Umfangreiche Experimente an Modellen verschiedener Größen und Serien zeigen, dass OneBit auf repräsentativ starken Basislinien klare Vorteile hat und einen guten Kompromiss zwischen Modellgröße und Leistung erreicht.
Darüber hinaus analysiert der Autor die Fähigkeiten und Aussichten dieses extrem Low-Bit-Quantisierungsmodells weiter und gibt Hinweise für zukünftige Forschungen.
Papieradresse: https://arxiv.org/pdf/2402.11295.pdf
Das obige ist der detaillierte Inhalt vonMachen Sie große Modelle um 90 % „schlank'! Die Tsinghua-Universität und das Harbin Institute of Technology schlugen eine extreme Komprimierungslösung vor: 1-Bit-Quantisierung unter Beibehaltung von 83 % der Kapazität.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
