


Papieradresse: https://arxiv.org/abs/2307.09283
Codeadresse: https://github.com/THU-MIG/RepViT
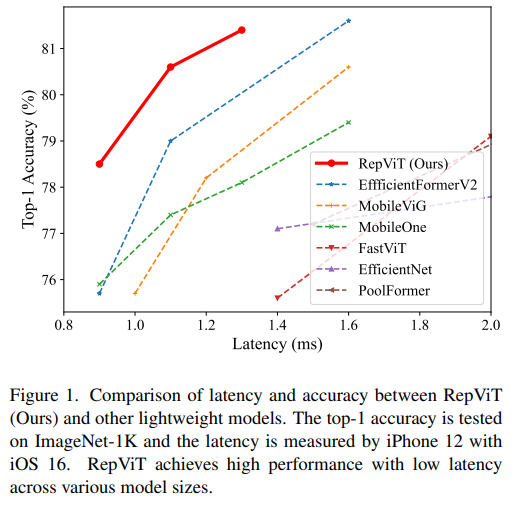
RepViT auf dem Handy Seite Hervorragende Leistung in der ViT-Architektur mit erheblichen Vorteilen. Als nächstes untersuchen wir die Beiträge dieser Studie.
MSHA Darstellung. Allerdings wurden die architektonischen Unterschiede zwischen Lightweight-ViTs und Lightweight-CNNs noch nicht vollständig untersucht. MSHA)可以让模型学习全局表示。然而,轻量级 ViTs 和轻量级 CNNs 之间的架构差异尚未得到充分研究。MobileNetV3 的移动友好性。这便衍生出一个新的纯轻量级 CNN 家族的诞生,即RepViT。值得注意的是,尽管 RepViT 具有 MetaFormer 结构,但它完全由卷积组成。RepViT 超越了现有的最先进的轻量级 ViTs,并在各种视觉任务上显示出优于现有最先进轻量级ViTs的性能和效率,包括 ImageNet 分类、COCO-2017 上的目标检测和实例分割,以及 ADE20k 上的语义分割。特别地,在ImageNet上,RepViT 在 iPhone 12 上达到了近乎 1ms 的延迟和超过 80% 的Top-1 准确率,这是轻量级模型的首次突破。好了,接下来大家应该关心的应该时“如何设计到如此低延迟但精度还很6的模型”出来呢?
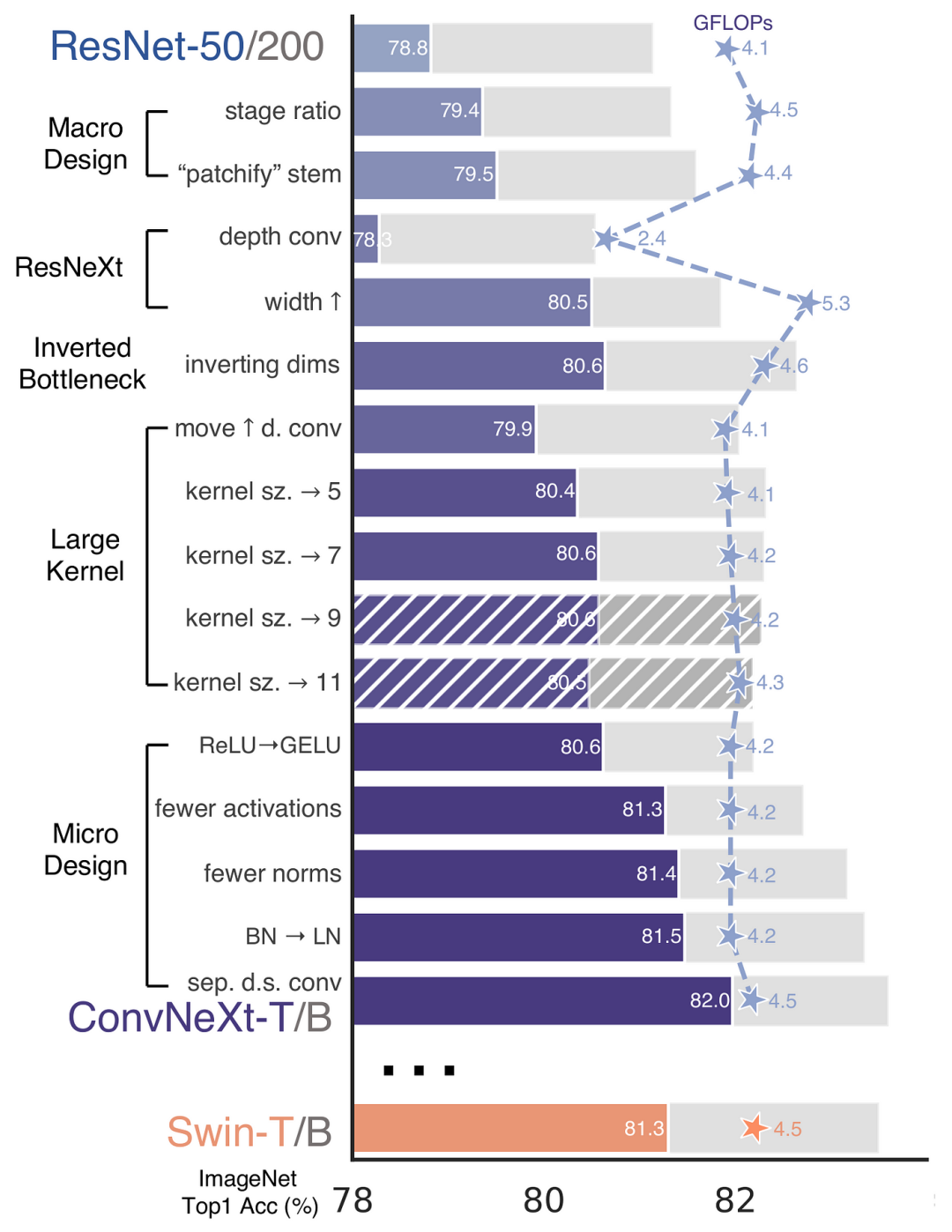
再 ConvNeXt 中,作者们是基于 ResNet50 架构的基础上通过严谨的理论和实验分析,最终设计出一个非常优异的足以媲美 Swin-Transformer 的纯卷积神经网络架构。同样地,RepViT也是主要通过将轻量级 ViTs 的架构设计逐步整合到标准轻量级 CNN,即MobileNetV3-LIn dieser Studie haben die Autoren das standardmäßige leichte CNN schrittweise verbessert (insbesondere MobileNetV3s Mobilfreundlichkeit. Daraus ergibt sich die Geburt einer neuen, reinen, leichten CNN-Familie, nämlich RepViT Es ist erwähnenswert, dass RepViT zwar eine MetaFormer-Struktur hat, aber vollständig aus Faltungen besteht.
RepViT Code> in <code style="background-color: rgb(231, 243, 237); padding: 1px 3px; border-radius: 4px; overflow-wrap: break-word; text-indent: 0px; display: inline- block;">iPhone 12 erreichte eine Latenz von fast 1 ms und über 80 % Top-1-Genauigkeit, was den ersten Durchbruch für leichte Modelle darstellt. 🎜Okay, als nächstes sollten sich alle Gedanken darüber machen: „Wie entwirft man ein Modell mit so geringer Latenz, aber hoher Genauigkeit?“ 🎜🎜🎜again ConvNeXt, die Autoren basieren auf ResNet50 Architektur durch strenge Theorie und Experiment Wir haben endlich ein sehr gutes Design entworfen, das vergleichbar ist mit Swin-Transformers reine Faltungs-Neuronale Netzwerkarchitektur. Ebenso RepViT erfolgt hauptsächlich durch die schrittweise Integration des Architekturdesigns von Lightweight-ViTs in das Standard-Lightweight-CNN, d. h. MobileNetV3-L um eine gezielte Transformation durchzuführen (magische Modifikation) In diesem Prozess betrachteten die Autoren Designelemente auf unterschiedlichen Granularitätsebenen und erreichten Optimierungsziele durch eine Reihe von Schritten. 🎜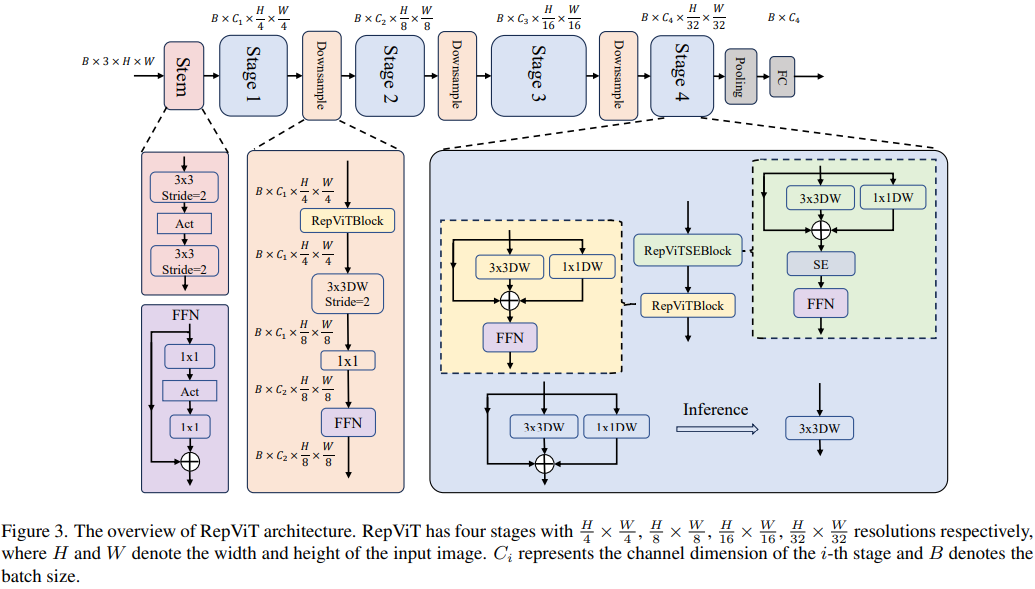
In dem Papier wird eine neue Metrik eingeführt, um die Latenz auf Mobilgeräten zu messen und sicherzustellen, dass die Trainingsstrategie mit derzeit beliebten Lightweight-ViTs übereinstimmt. Der Zweck dieser Initiative besteht darin, die Konsistenz des Modelltrainings sicherzustellen, das zwei Schlüsselkonzepte der Verzögerungsmessung und der Anpassung der Trainingsstrategie umfasst.
Latenzmetrik
Um die Leistung des Modells auf echten Mobilgeräten genauer zu messen, hat sich der Autor dafür entschieden, die tatsächliche Latenz des Modells auf dem Gerät als Basismetrik direkt zu messen. Diese Messmethode unterscheidet sich von früheren Studien, die hauptsächlich FLOPs oder Modellgröße optimieren die Inferenzgeschwindigkeit des Modells, und diese Metriken spiegeln die tatsächliche Latenz in mobilen Anwendungen nicht immer gut wider. FLOPs或模型大小等指标优化模型的推理速度,这些指标并不总能很好地反映在移动应用中的实际延迟。
训练策略的对齐
这里,将 MobileNetV3-L 的训练策略调整以与其他轻量级 ViTs 模型对齐。这包括使用 AdamW 优化器【ViTs 模型必备的优化器】,进行 5 个 epoch 的预热训练,以及使用余弦退火学习率调度进行 300 个 epoch 的训练。尽管这种调整导致了模型准确率的略微下降,但可以保证公平性。
接下来,基于一致的训练设置,作者们探索了最优的块设计。块设计是 CNN 架构中的一个重要组成部分,优化块设计有助于提高网络的性能。
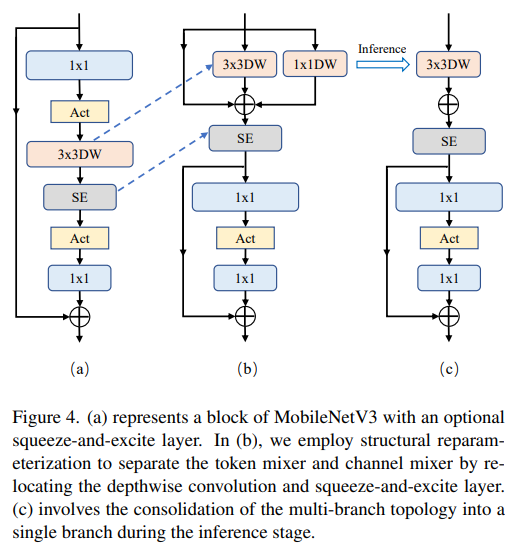
分离 Token 混合器和通道混合器
这块主要是对 MobileNetV3-LAusrichtung der Trainingsstrategie
Hier wird die Trainingsstrategie von MobileNetV3-L angepasst, um sie an andere leichte ViTs-Modelle anzupassen. Dazu gehört die Verwendung von AdamW-Optimierer [wesentlicher Optimierer für das ViTs-Modell], führt 5 Epochen des Aufwärmtrainings durch und verwendet die Cosinus-Annealing-Lernratenplanung für 300 Trainingsepochen. Obwohl diese Anpassung zu einer leichten Verringerung der Modellgenauigkeit führt, ist Fairness gewährleistet.
Separater Token-Mixer und Kanal-Mixer
Dieses Stück ist hauptsächlich für<img src="https://img.php.cn/upload/article/000/465/014/171013003966159.png" alt="1.3ms耗时!清华最新开源移动端神经网络架构 RepViT"><span>Reduzieren Sie das Erweiterungsverhältnis und erhöhen Sie die Breite</span>🎜Im Kanalmischer beträgt das ursprüngliche Erweiterungsverhältnis 4, was bedeutet, dass die verborgene Dimension des MLP-Blocks viermal so groß ist wie die Eingabedimension, was viele Rechenressourcen verbraucht und Auswirkungen auf die Inferenzzeit haben einen großen Einfluss. Um dieses Problem zu lindern, können wir das Dilatationsverhältnis auf 2 reduzieren, wodurch Parameterredundanz und Latenz reduziert werden und die Latenz von MobileNetV3-L auf 0,65 ms reduziert wird. Anschließend erhöhte sich die Top-1-Genauigkeit durch die Vergrößerung der Breite des Netzwerks, d. h. die Erhöhung der Anzahl der Kanäle auf jeder Stufe, auf 73,5 %, während die Latenz nur auf 0,89 ms anstieg! 🎜🎜Optimierung makroarchitektonischer Elemente🎜🎜In diesem Schritt optimiert dieser Artikel die Leistung von MobileNetV3-L auf Mobilgeräten weiter, hauptsächlich ausgehend von makroarchitektonischen Elementen, einschließlich Stamm, Downsampling-Schicht, Klassifikator und Gesamtstufenverhältnis. Durch die Optimierung dieser makroarchitektonischen Elemente kann die Leistung des Modells deutlich verbessert werden. 🎜🎜🎜Flaches Netzwerk mit Faltungsextraktor🎜🎜🎜🎜🎜Bild🎜🎜<p style="max-width:90%">ViTs verwenden normalerweise eine „Patchify“-Operation, die das Eingabebild als Stamm in nicht überlappende Patches aufteilt. Dieser Ansatz hat jedoch Probleme mit der Trainingsoptimierung und der Sensibilität gegenüber Trainingsrezepten. Daher haben die Autoren stattdessen die frühe Faltung gewählt, einen Ansatz, der von vielen leichtgewichtigen ViTs übernommen wurde. Im Gegensatz dazu verwendet MobileNetV3-L einen komplexeren Stamm für das 4-fache Downsampling. Obwohl die anfängliche Anzahl der Filter auf diese Weise auf 24 erhöht wird, wird die Gesamtlatenz auf 0,86 ms reduziert, während die Top-1-Genauigkeit auf 73,9 % steigt. </p>
<h5 style="text-align: justify;">Tiefere Downsampling-Schicht</h5>
<p style="text-align:center;"><img src="https://img.php.cn/upload/article/000/465/014/171013003976243.png" alt="1.3ms耗时!清华最新开源移动端神经网络架构 RepViT"></p>
<p style="text-align: justify;">In ViTs wird räumliches Downsampling normalerweise über eine separate Patch-Merging-Schicht implementiert. Hier können wir also eine separate und tiefere Downsampling-Schicht einsetzen, um die Netzwerktiefe zu erhöhen und den Informationsverlust aufgrund der Auflösungsreduzierung zu reduzieren. Insbesondere verwendeten die Autoren zunächst eine 1x1-Faltung, um die Kanaldimension anzupassen, und verbanden dann die Eingabe und Ausgabe zweier 1x1-Faltungen über das Residuum, um ein Feedforward-Netzwerk zu bilden. Darüber hinaus fügten sie vorab einen RepViT-Block hinzu, um die Downsampling-Ebene weiter zu vertiefen. Dieser Schritt verbesserte die Top-1-Genauigkeit auf 75,4 % bei einer Latenz von 0,96 ms. </p>
<p style="text-align: justify;"><strong>Einfacher Klassifikator</strong></p>
<p style="text-align:center;"><img src="https://img.php.cn/upload/article/000/465/014/171013003951910.png" alt="1.3ms耗时!清华最新开源移动端神经网络架构 RepViT"></p>
<p style="text-align: justify;">In leichten ViTs besteht der Klassifikator normalerweise aus einer globalen Durchschnitts-Pooling-Schicht, gefolgt von einer linearen Schicht. Im Gegensatz dazu verwendet MobileNetV3-L einen komplexeren Klassifikator. Da die letzte Stufe nun über mehr Kanäle verfügt, haben die Autoren sie durch einen einfachen Klassifikator, eine globale Durchschnitts-Pooling-Schicht und eine lineare Schicht ersetzt. Dieser Schritt reduzierte die Latenz auf 0,77 ms und erreichte gleichzeitig eine Top-1-Genauigkeit. </p>
<p style="text-align: justify;"><strong>Das Gesamtstufenverhältnis </strong></p>
<p style="text-align: justify;">Das Stufenverhältnis stellt das Verhältnis der Anzahl der Blöcke in verschiedenen Stufen dar und gibt somit die Verteilung der Berechnungen in jeder Stufe an. Das Papier wählt ein besseres Bühnenverhältnis von 1:1:7:1 und erhöht dann die Netzwerktiefe auf 2:2:14:2, wodurch ein tieferes Layout erreicht wird. Dieser Schritt erhöht die Top-1-Genauigkeit auf 76,9 % bei einer Latenz von 1,02 ms. </p>
<h4 style="text-align: justify;">Anpassung des Mikrodesigns</h4>
<p style="text-align: justify;">Als nächstes passt RepViT das leichte CNN durch schichtweises Mikrodesign an, einschließlich der Auswahl der geeigneten Faltungskerngröße und der Optimierung der Position der Squeeze-and-Excitation (SE)-Schicht. Beide Methoden verbessern die Modellleistung erheblich. </p>
<p style="text-align: justify;"><strong>Auswahl der Faltungskerngröße</strong></p>
<p style="text-align: justify;">Es ist bekannt, dass die Leistung und Latenz von CNNs normalerweise von der Größe des Faltungskerns beeinflusst werden. Um beispielsweise weitreichende Kontextabhängigkeiten wie MHSA zu modellieren, verwendet ConvNeXt große Faltungskerne, was zu erheblichen Leistungsverbesserungen führt. Allerdings sind große Faltungskerne aufgrund ihrer Rechenkomplexität und Speicherzugriffskosten nicht für Mobilgeräte geeignet. MobileNetV3-L verwendet hauptsächlich 3x3-Faltungen und in einigen Blöcken werden 5x5-Faltungen verwendet. Die Autoren ersetzten sie durch 3x3-Faltungen, was zu einer Reduzierung der Latenz auf 1,00 ms bei gleichzeitiger Beibehaltung einer Top-1-Genauigkeit von 76,9 % führte. </p>
<p style="text-align: justify;"><strong> Position der SE-Schicht </strong></p>
<p style="text-align: justify;">Ein Vorteil des Selbstaufmerksamkeitsmoduls gegenüber der Faltung ist die Möglichkeit, die Gewichte basierend auf der Eingabe anzupassen, was als datengesteuerte Eigenschaft bezeichnet wird. Als Kanalaufmerksamkeitsmodul kann die SE-Schicht die Einschränkungen der Faltung durch das Fehlen datengesteuerter Eigenschaften ausgleichen und so zu einer besseren Leistung führen. MobileNetV3-L fügt in einigen Blöcken SE-Ebenen hinzu, wobei der Schwerpunkt hauptsächlich auf den letzten beiden Phasen liegt. Allerdings erzielt die Stufe mit niedrigerer Auflösung durch den von SE bereitgestellten globalen Durchschnitts-Pooling-Vorgang geringere Genauigkeitsgewinne als die Stufe mit höherer Auflösung. Die Autoren entwickelten eine Strategie, um die SE-Schicht in allen Phasen blockübergreifend zu nutzen, um die Genauigkeitsverbesserung mit dem kleinsten Verzögerungsinkrement zu maximieren. Dieser Schritt verbesserte die Top-1-Genauigkeit auf 77,4 %, während die Verzögerung auf 0,87 ms reduziert wurde. [Tatsächlich hat Baidu bereits vor langer Zeit Experimente und Vergleiche zu diesem Punkt durchgeführt und ist zu diesem Schluss gekommen. Die SE-Schicht ist effektiver, wenn sie in der Nähe der tiefen Schicht platziert wird]</p>
<h4 style="text-align: justify;">Netzwerkarchitektur</h4>
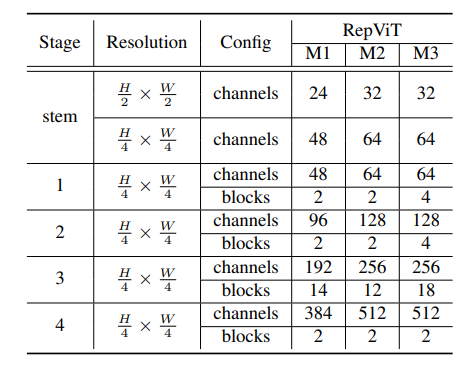
<p style="text-align: justify;">Durch die Integration der oben genannten Verbesserungsstrategien erhalten wir schließlich das Modell<code style="background-color: rgb(231, 243, 237); padding: 1px 3px; border-radius: 4px; overflow-wrap: break-word; text-indent: 0px; display: inline-block;">RepViT的整体架构,该模型有多个变种,例如RepViT-M1/M2/M3. Ebenso unterscheiden sich die verschiedenen Varianten hauptsächlich durch die Anzahl der Kanäle und Blöcke pro Stufe.
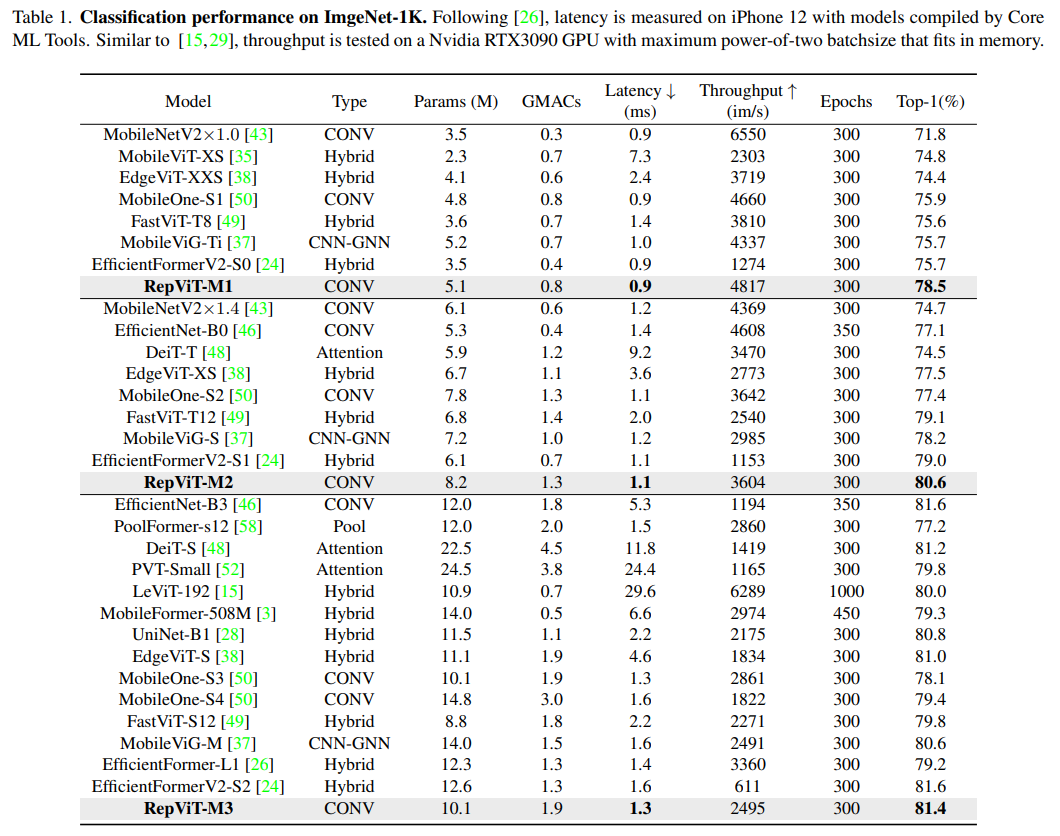
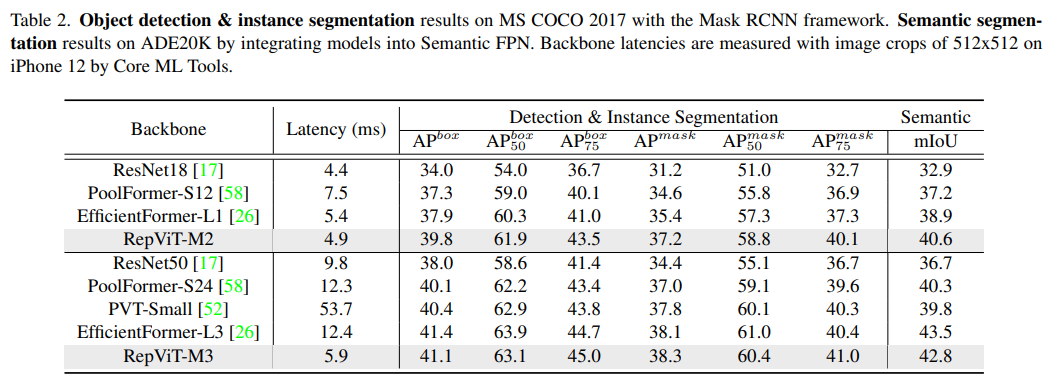
Dieses Papier befasst sich erneut mit dem effizienten Design von leichten CNNs, indem es die architektonische Wahl von leichtgewichtigem ViT vorstellt. Dies führte zur Entstehung von RepViT, einer neuen Familie leichter CNNs, die für ressourcenbeschränkte Mobilgeräte entwickelt wurden. RepViT übertrifft bestehende hochmoderne, leichtgewichtige ViTs und CNNs bei verschiedenen Sehaufgaben und weist eine überlegene Leistung und Latenz auf. Dies unterstreicht das Potenzial rein leichter CNNs für mobile Geräte.
Das obige ist der detaillierte Inhalt von1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



