Dieses Modell nutzt das DiT-Framework wie Sora.
Wie wir alle wissen, erfordert die Entwicklung von T2I-Modellen auf höchstem Niveau viele Ressourcen, sodass es für einzelne Forscher mit begrenzten Ressourcen grundsätzlich unmöglich ist, sich dies zu leisten. Dies ist auch zum AIGC (Artificial Intelligence Content) geworden Generationsgemeinschaft Ein großes Hindernis für Innovationen. Gleichzeitig wird die AIGC-Community im Laufe der Zeit in der Lage sein, kontinuierlich aktualisierte, qualitativ hochwertigere Datensätze und fortschrittlichere Algorithmen zu erhalten. Hier stellt sich also die entscheidende Frage: Wie können wir diese neuen Elemente effizient in das bestehende Modell integrieren und das Modell mit begrenzten Ressourcen leistungsfähiger machen? Um dieses Problem zu untersuchen, schlug ein Forschungsteam von Forschungseinrichtungen wie dem Noah’s Ark Laboratory von Huawei eine neue Trainingsmethode vor: Schwach-zu-Stark-Training. 
Papiertitel: PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image GenerationPapieradresse: https://arxiv.org/pdf/2403.04692.pdfProjekt Seite: https://pixart-alpha.github.io/PixArt-sigma-project/ Ihre Forschung basiert auf PixArt-α, einer effizienten lexikografischen Trainingsmethode, die sie letzten Oktober vorgeschlagen haben. Weitere Informationen finden Sie in diesem Website-Bericht „PixArt, ein Grafikmodell mit extrem niedrigen Schulungskosten, ist da, mit Ergebnissen, die mit MJ vergleichbar sind und nur 10 % SD-Trainingszeit erfordern“. PixArt-α ist ein früher Versuch des DiT-Frameworks (Diffusion Transformer). Jetzt, wo Sora auf der heißen Suche ist und Stable Diffusion in unzähligen Anwendungen auftaucht, wurde die Wirksamkeit der DiT-Architektur durch immer mehr Arbeiten in der Forschungsgemeinschaft bestätigt, wie z. B. PixArt, Dit-3D, GenTron usw. [1] . Das Team nutzte das vorab trainierte Basismodell von PixArt-α und integrierte erweiterte Elemente, um dessen kontinuierliche Verbesserung voranzutreiben, was letztendlich zu einem leistungsfähigeren Modell PixArt-Σ führte. Abbildung 1 zeigt einige Beispiele generierter Ergebnisse.
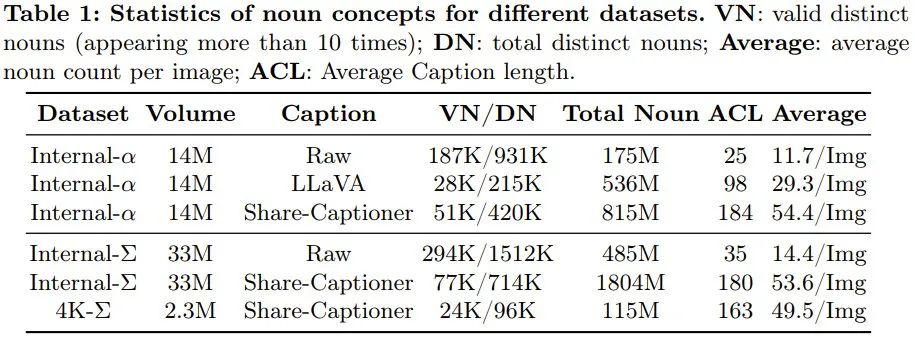
PixArt-Σ Wie macht man es? Konkret hat das Team die folgenden Verbesserungsmaßnahmen ergriffen, um ein schwaches bis starkes Training zu erreichen und PixArt-Σ zu schaffen. Trainingsdaten von höherer QualitätDas Team hat einen hochwertigen Datensatz Internal-Σ gesammelt, der sich hauptsächlich auf zwei Aspekte konzentriert: (1) Hochwertige Bilder: Der Datensatz enthält 33 Millionen hochauflösende Bilder aus dem Internet, alle über 1K-Auflösung, darunter 2,3 Millionen Bilder mit etwa 4K-Auflösung. Die Hauptmerkmale dieser Bilder sind ihre hohe Ästhetik und sie decken ein breites Spektrum künstlerischer Stile ab. (2) Dichte und genaue Beschreibung: Um eine präzisere und detailliertere Beschreibung für das obige Bild bereitzustellen, ersetzte das Team das in PixArt-α verwendete LLaVA durch einen leistungsfähigeren Bilddeskriptor, Share-Captioner. Um die Fähigkeit des Modells zur Ausrichtung von Textkonzepten und visuellen Konzepten zu verbessern, erweiterte das Team außerdem die Tokenlänge des Textencoders (d. h. Flan-T5) auf etwa 300 Wörter. Sie stellten fest, dass diese Verbesserungen die Halluzinationsneigung des Modells wirksam beseitigen und eine qualitativ hochwertigere Text-Bild-Ausrichtung ermöglichen. Tabelle 1 unten zeigt die Statistiken verschiedener Datensätze.
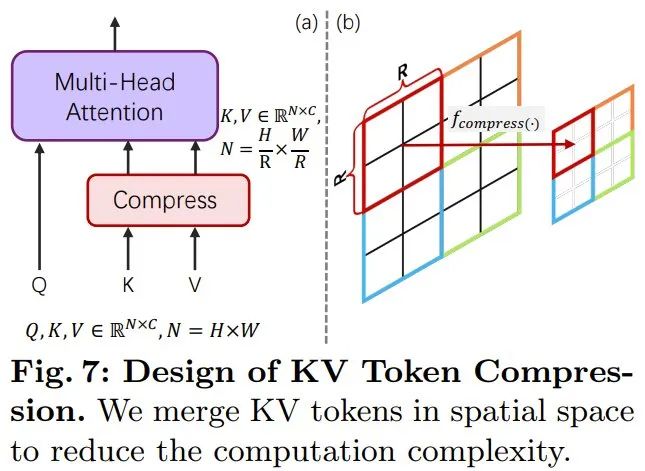
Effiziente Token-KomprimierungUm PixArt-α zu verbessern, erhöhte das Team die Generierungsauflösung von 1K auf 4K. Um Bilder mit ultrahoher Auflösung (z. B. 2K/4K) zu erzeugen, wird die Anzahl der Token erheblich zunehmen, was zu einem erheblichen Anstieg des Rechenbedarfs führen wird. Um dieses Problem zu lösen, führten sie ein speziell auf das DiT-Framework abgestimmtes Selbstaufmerksamkeitsmodul ein, das die Schlüssel- und Wert-Token-Komprimierung nutzt. Insbesondere verwendeten sie gruppierte Faltungen mit Schritt 2, um eine lokale Aggregation von Schlüsseln und Werten durchzuführen, wie in Abbildung 7 unten dargestellt.
Darüber hinaus hat das Team ein speziell entwickeltes Gewichtsinitialisierungsschema übernommen, das eine reibungslose Anpassung von vorab trainierten Modellen ohne Verwendung der KV-Komprimierung (Schlüsselwert) ermöglicht. Dieses Design reduziert die Trainings- und Inferenzzeit für die Erzeugung hochauflösender Bilder effektiv um etwa 34 %. Trainingsstrategie von schwach zu starkDas Team hat eine Vielzahl von Feinabstimmungstechniken vorgeschlagen, um schwache Modelle schnell und effizient an starke Modelle anzupassen. Dazu gehören: (1) Ersatz durch einen leistungsfähigeren Variational Autoencoder (VAE): Ersetzen des VAE von PixArt-α durch den VAE von SDXL. (2) Um von niedriger Auflösung auf hohe Auflösung zu erweitern und das Problem der Leistungseinbuße zu bewältigen, verwenden sie die Position Embedding (PE)-Interpolationsmethode. (3) Entwickelt sich von einem Modell, das keine KV-Komprimierung verwendet, zu einem Modell, das KV-Komprimierung verwendet. Die experimentellen Ergebnisse bestätigten die Machbarkeit und Wirksamkeit der schwach-starken Trainingsmethode. Durch die oben genannten Verbesserungen kann PixArt-Σ qualitativ hochwertige Bilder mit 4K-Auflösung mit möglichst geringem Schulungsaufwand und möglichst wenigen Modellparametern erzeugen. Insbesondere indem das Team mit einem bereits vorab trainierten Modell begann und es verfeinerte, war es in der Lage, ein Modell zu erstellen, das in der Lage ist, hochauflösende 1K-Bilder zu erzeugen, wobei nur 9 % der zusätzlich benötigten GPU-Zeit benötigt wurden PixArt-α. Diese Leistung ist bemerkenswert, da auch neue Trainingsdaten und eine leistungsfähigere VAE verwendet werden. Außerdem beträgt die Parametermenge von PixArt-Σ nur 0,6B. Im Vergleich dazu beträgt die Parametermenge von SDXL und SD Cascade 2,6B bzw. 5,1B. Die Schönheit der von PixArt-Σ generierten Bilder ist vergleichbar mit den aktuellen Top-Pixel-Art-Produkten wie DALL・E 3 und MJV6. Darüber hinaus zeigt PixArt-Σ auch hervorragende Fähigkeiten zur feinkörnigen Ausrichtung mit Textaufforderungen.
Abbildung 2 zeigt das Ergebnis der Erstellung eines hochauflösenden 4K-Bildes durch PixArt. Es ist ersichtlich, dass das generierte Ergebnis komplexen und informationsreichen Textanweisungen gut folgt. Experimente (d. h. Flan-T5-XXL). Das grundlegende Diffusionsmodell ist PixArt-α. Anders als bei der Praxis, in den meisten Studien feste 77 Text-Tokens zu extrahieren, wird die Länge der Text-Tokens von 120 in PixArt-α auf 300 erhöht, da die in Internal-Σ organisierten Beschreibungsinformationen dichter sind und sehr feinkörnige Details liefern können . . Darüber hinaus verwendet VAE eine vorab trainierte eingefrorene Version von VAE von SDXL. Andere Implementierungsdetails sind die gleichen wie bei PixArt-α.
Das Modell wird ausgehend vom 256-Pixel-Pre-Training-Checkpoint von PixArt-α feinabgestimmt und verwendet Positionseinbettungsinterpolationstechnologie.
Das endgültige Modell (einschließlich 1K-Auflösung) wurde auf 32 V100-GPUs trainiert. Außerdem nutzten sie weitere 16 A100-GPUs, um 2K- und 4K-Bilderzeugungsmodelle zu trainieren. Bewertungsmetriken: Um Ästhetik und semantische Fähigkeiten besser zu demonstrieren, sammelte das Team 30.000 hochwertige Text-Bild-Paare, um die leistungsstärksten Vincent-Grafikmodelle zu vergleichen. PixArt-Σ wird hier hauptsächlich anhand menschlicher und KI-Präferenzen bewertet, da die FID-Metrik die Generierungsqualität möglicherweise nicht angemessen widerspiegelt.
Bewertung der Bildqualität: Das Team verglich die Generierungsqualität von PixArt-Σ qualitativ mit Closed-Source-Text-to-Image-Produkten (T2I) und Open-Source-Modellen. Wie in Abbildung 3 dargestellt, sind die von PixArt-Σ generierten Porträts im Vergleich zum Open-Source-Modell SDXL und dem vorherigen PixArt-α des Teams realistischer und verfügen über bessere semantische Analysefunktionen. PixArt-Σ befolgt Benutzeranweisungen besser als SDXL.
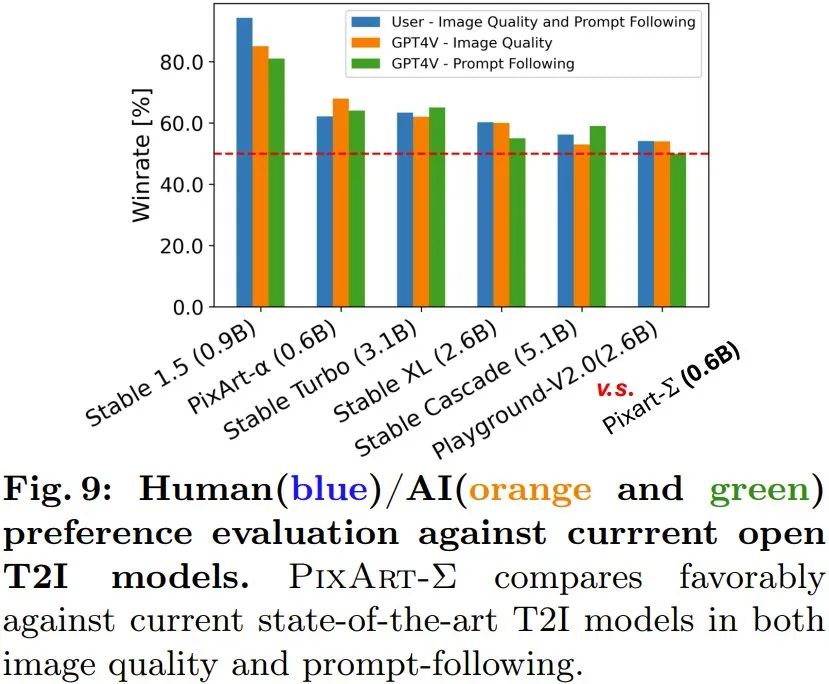
PixArt-Σ übertrifft nicht nur Open-Source-Modelle, sondern ist auch mit aktuellen Closed-Source-Produkten konkurrenzfähig, wie in Abbildung 4 dargestellt. Hochauflösende Bilder generieren: Mit der neuen Methode können Bilder mit 4K-Auflösung direkt und ohne Nachbearbeitung generiert werden. Darüber hinaus kann PixArt-Σ auch komplexe und detaillierte Langtexte, die von Benutzern bereitgestellt werden, genau befolgen. Daher müssen sich Benutzer nicht die Mühe machen, Eingabeaufforderungen zu entwerfen, um zufriedenstellende Ergebnisse zu erzielen. Präferenzstudie Mensch/KI (GPT-4V): Das Team untersuchte auch Präferenzen von Mensch und KI für generierte Ergebnisse. Sie sammelten die Generierungsergebnisse von 6 Open-Source-Modellen, darunter PixArt-α, PixArt-Σ, SD1.5, Stable Turbo, Stable XL, Stable Cascade und Playground-V2.0. Sie entwickelten eine Website, die Feedback zu menschlichen Vorlieben sammelt, indem sie Eingabeaufforderungen und entsprechende Bilder anzeigt. Menschliche Bewerter können Bilder anhand der Generierungsqualität und der Übereinstimmung mit der Eingabeaufforderung bewerten. Die Ergebnisse sind im blauen Balkendiagramm von Abbildung 9 dargestellt. Man erkennt, dass menschliche Bewerter PixArt-Σ den anderen 6 Generatoren vorziehen. Im Vergleich zu früheren Vincentian-Graph-Diffusionsmodellen wie SDXL (2,6 B Parameter) und SD Cascade (5,1 B Parameter) kann PixArt-Σ mit viel weniger Parametern (0,6 B) Bilder mit höherer Qualität und konsistenterer Benutzeranforderung erzeugen.
Darüber hinaus nutzte das Team das fortschrittliche multimodale Modell GPT-4 Vision, um KI-Präferenzstudien durchzuführen. Sie füttern GPT-4 Vision mit zwei Bildern und lassen es anhand der Bildqualität und der Bild-Text-Ausrichtung abstimmen. Die Ergebnisse sind in den orangefarbenen und grünen Balken in Abbildung 9 dargestellt und es ist ersichtlich, dass die Situation im Wesentlichen mit der menschlichen Bewertung übereinstimmt. Das Team führte außerdem Ablationsstudien durch, um die Wirksamkeit verschiedener Verbesserungsmaßnahmen zu überprüfen. Weitere Einzelheiten finden Sie im Originalpapier. Referenzartikel: 1. https://www.shoufachen.com/Awesome-Diffusion-Transformers/Das obige ist der detaillierte Inhalt vonDas Huawei Noah 0.6B Vincent Grafikmodell PixArt-Σ basiert auf DiT und unterstützt die 4K-Bilderzeugung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!





 Welche Börse ist EDX?
Welche Börse ist EDX?
 Verwendung der Geschwindigkeitsanmerkung
Verwendung der Geschwindigkeitsanmerkung
 So deaktivieren Sie das Windows-Sicherheitscenter
So deaktivieren Sie das Windows-Sicherheitscenter
 In welcher Sprache kann vscode geschrieben werden?
In welcher Sprache kann vscode geschrieben werden?
 So speichern Sie Bilder im Douyin-Kommentarbereich auf dem Mobiltelefon
So speichern Sie Bilder im Douyin-Kommentarbereich auf dem Mobiltelefon
 So laden Sie Ouyiokx auf
So laden Sie Ouyiokx auf
 So verwenden Sie die Shift-Hintertür
So verwenden Sie die Shift-Hintertür
 Tutorial zum Festlegen des Startkennworts für Windows 10
Tutorial zum Festlegen des Startkennworts für Windows 10
 Welche Zeichensoftware gibt es?
Welche Zeichensoftware gibt es?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



