
 Technologie-Peripheriegeräte
KI
Das MovieLLM-Framework von Tencent nutzt KI-Kurzvideos, um das Verständnis langer Videos „zurückzumelden', und zielt auf die kontinuierliche Bildgenerierung auf Filmebene ab
Technologie-Peripheriegeräte
KI
Das MovieLLM-Framework von Tencent nutzt KI-Kurzvideos, um das Verständnis langer Videos „zurückzumelden', und zielt auf die kontinuierliche Bildgenerierung auf Filmebene ab
Das MovieLLM-Framework von Tencent nutzt KI-Kurzvideos, um das Verständnis langer Videos „zurückzumelden', und zielt auf die kontinuierliche Bildgenerierung auf Filmebene ab

Obwohl multimodale Modelle im Bereich des Videoverständnisses Durchbrüche bei der Analyse kurzer Videos erzielt und starke Verständnisfähigkeiten gezeigt haben, scheinen sie bei langen Videos auf Filmebene machtlos zu sein. Daher ist die Analyse und das Verständnis langer Videos, insbesondere das Verständnis stundenlanger Filminhalte, heutzutage zu einer großen Herausforderung geworden.
Die Schwierigkeit des Modells, lange Videos zu verstehen, ist hauptsächlich auf den Mangel an Datenressourcen für lange Videos zurückzuführen, die Mängel in Qualität und Vielfalt aufweisen. Darüber hinaus erfordert das Sammeln und Kennzeichnen dieser Daten einen hohen Arbeitsaufwand.
Angesichts eines solchen Problems schlug das Forschungsteam von Tencent und der Fudan-Universität MovieLLM vor, ein innovatives KI-Generierungs-Framework. MovieLLM verwendet eine innovative Methode, die nicht nur qualitativ hochwertige und vielfältige Videodaten generiert, sondern auch automatisch eine große Anzahl verwandter Frage- und Antwortdatensätze generiert, wodurch die Dimension und Tiefe der Daten erheblich bereichert wird und der gesamte automatisierte Prozess ebenfalls äußerst hoch ist Dadi reduziert menschliche Investitionen.

- Papieradresse: https://arxiv.org/abs/2403.01422
- Homepage-Adresse: https://deaddawn.github.io/MovieLLM/
Diese wichtige Entwicklung verbessert nicht nur das Verständnis des Modells für komplexe Videoerzählungen, sondern erweitert auch die analytischen Fähigkeiten des Modells bei der Verarbeitung stundenlanger Filminhalte. Gleichzeitig überwindet es die Einschränkungen der Knappheit und Verzerrung vorhandener Datensätze und bietet eine neue und effektive Möglichkeit, ultralange Videoinhalte zu verstehen.
MovieLLM nutzt geschickt die leistungsstarken Generierungsfähigkeiten von GPT-4 und Diffusionsmodellen und wendet eine „story-expandierende“ Strategie zur kontinuierlichen Generierung von Frame-Beschreibungen an. Die Methode der „Textinversion“ wird verwendet, um das Diffusionsmodell so zu steuern, dass Szenenbilder generiert werden, die mit der Textbeschreibung übereinstimmen, wodurch fortlaufende Bilder eines vollständigen Films erstellt werden.

Methodenübersicht
MovieLLM kombiniert GPT-4 und Diffusionsmodelle, um das Verständnis großer Modelle für lange Videos zu verbessern. Diese clevere Kombination erzeugt hochwertige, vielfältige lange Videodaten sowie QA-Fragen und -Antworten und trägt so dazu bei, die generativen Fähigkeiten des Modells zu verbessern.
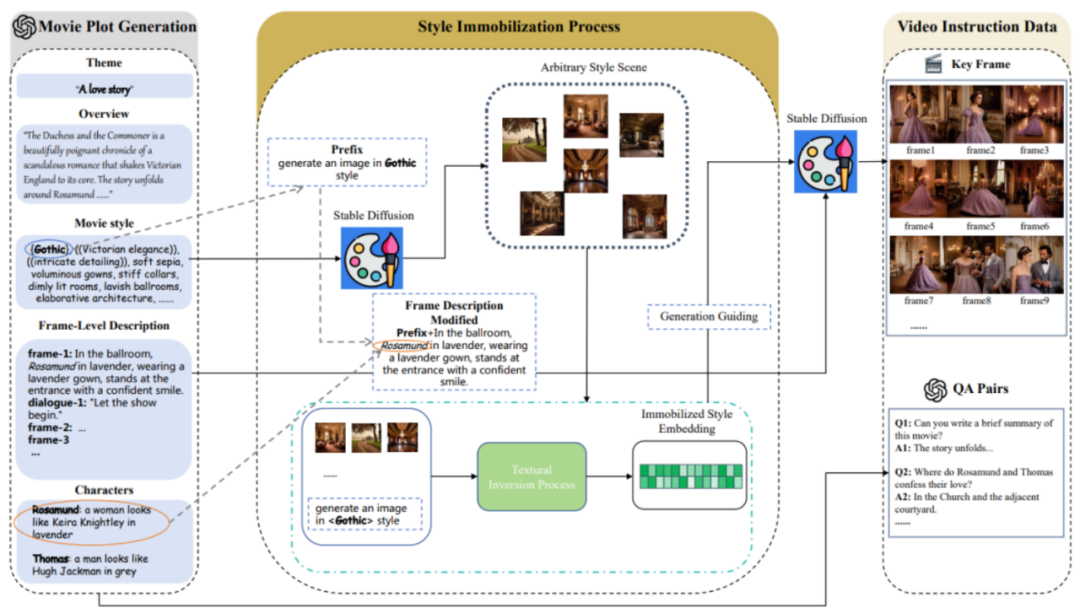
MovieLLM umfasst hauptsächlich drei Phasen:
1. Filmhandlungserstellung.
MovieLLM verlässt sich bei der Generierung von Plots nicht auf das Web oder vorhandene Datensätze, sondern nutzt die Leistungsfähigkeit von GPT-4 voll aus, um synthetische Daten zu erzeugen. Durch die Bereitstellung spezifischer Elemente wie Thema, Übersicht und Stil wird GPT-4 angeleitet, filmische Keyframe-Beschreibungen zu erstellen, die auf den nachfolgenden Generierungsprozess zugeschnitten sind.
2. Stilfixierungsprozess.
MovieLLM nutzt geschickt die Technologie der „Textinversion“, um die im Drehbuch generierte Stilbeschreibung im latenten Raum des Diffusionsmodells zu fixieren. Diese Methode führt das Modell dazu, Szenen mit einem festen Stil zu generieren und die Vielfalt bei gleichzeitiger Beibehaltung einer einheitlichen Ästhetik beizubehalten.
3. Generierung von Videobefehlsdaten.
Basierend auf den ersten beiden Schritten wurden eine feste Stileinbettung und eine Keyframe-Beschreibung erstellt. Auf dieser Grundlage nutzt MovieLLM die Einbettung von Stilen, um das Diffusionsmodell so zu steuern, dass es Schlüsselbilder generiert, die den Schlüsselbildbeschreibungen entsprechen, und generiert nach und nach verschiedene Frage- und Antwortpaare mit Anweisungen entsprechend der Filmhandlung.

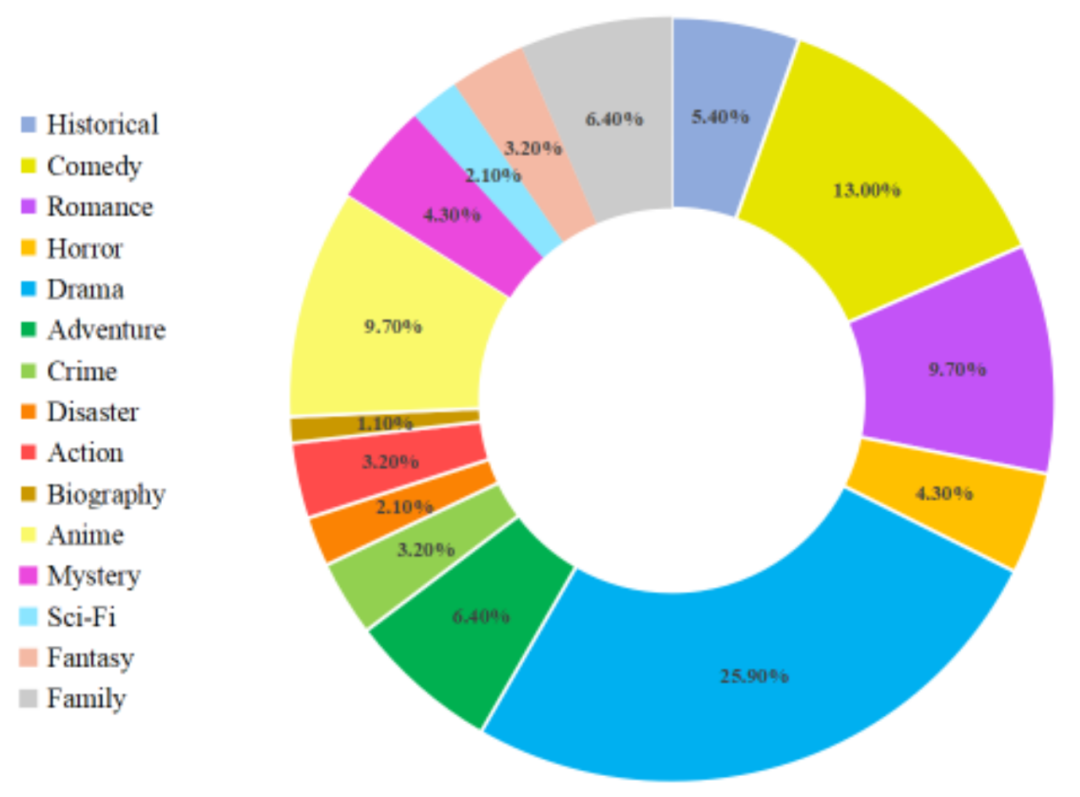
Nach den oben genannten Schritten hat MovieLLM hochwertige, vielfältige Stile, kohärente Filmbilder und entsprechende Frage-Antwort-Paardaten erstellt. Die detaillierte Verteilung der Filmdatentypen ist wie folgt:
Experimentelle Ergebnisse
Durch die Anwendung von auf MovieLLM erstellten Daten zur Feinabstimmung auf LLaMA-VID, einem großen Modell, das sich auf das Verständnis langer Videos konzentriert, verbessert dieser Artikel die Fähigkeit des Modells, Videoinhalte unterschiedlicher Länge zu verstehen, erheblich. Für das Verständnis langer Videos gibt es derzeit keine Arbeit, die einen Test-Benchmark vorschlägt. Daher wird in diesem Artikel auch ein Benchmark zum Testen der Fähigkeiten zum Verstehen langer Videos vorgeschlagen.
Obwohl MovieLLM keine speziellen Kurzvideodaten für das Training erstellt hat, wurden durch das Training dennoch Leistungsverbesserungen bei verschiedenen Kurzvideo-Benchmarks beobachtet:
In MSVD-QA und MSRVTT – im Vergleich zu Mit dem Basismodell hat sich die Qualitätssicherung bei diesen beiden Testdatensätzen deutlich verbessert.

Beim videogenerierungsbasierten Leistungsbenchmark wurden in allen fünf Bewertungsbereichen Leistungsverbesserungen erzielt.
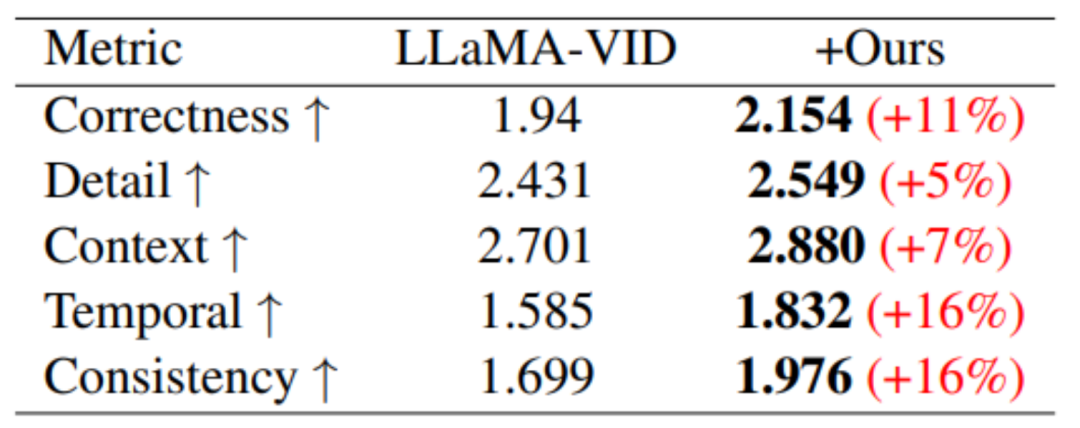
In Bezug auf das Verständnis langer Videos wurde durch das Training von MovieLLM das Verständnis des Modells für Zusammenfassung, Handlung und Timing erheblich verbessert.

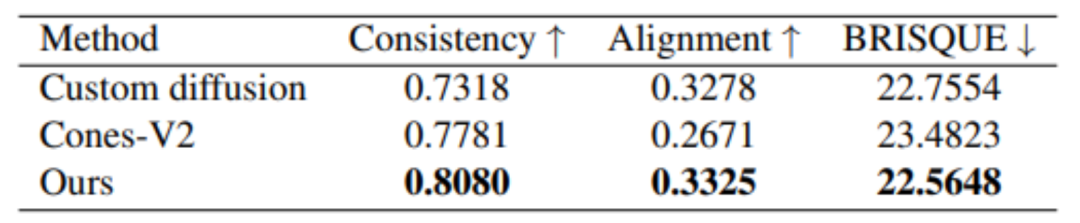
Darüber hinaus erzielt MovieLLM auch bessere Ergebnisse in Bezug auf die Generierungsqualität im Vergleich zu anderen ähnlichen Methoden zur Bildgenerierung mit festem Stil.
Kurz gesagt, der von MovieLLM vorgeschlagene Arbeitsablauf zur Datengenerierung reduziert die Herausforderung der Erstellung von Videodaten auf Filmebene für Modelle erheblich und verbessert die Kontrolle und Vielfalt der generierten Inhalte. Gleichzeitig verbessert MovieLLM die Fähigkeit des multimodalen Modells, lange Videos auf Filmebene zu verstehen, erheblich und bietet so eine wertvolle Referenz für andere Bereiche, um ähnliche Datengenerierungsmethoden zu übernehmen.
Leser, die sich für diese Forschung interessieren, können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren.
Das obige ist der detaillierte Inhalt vonDas MovieLLM-Framework von Tencent nutzt KI-Kurzvideos, um das Verständnis langer Videos „zurückzumelden', und zielt auf die kontinuierliche Bildgenerierung auf Filmebene ab. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Wie man Debian Hadoop Log Management macht
Apr 13, 2025 am 10:45 AM
Wie man Debian Hadoop Log Management macht
Apr 13, 2025 am 10:45 AM
Wenn Sie Hadoop-Protokolle auf Debian verwalten, können Sie die folgenden Schritte und Best Practices befolgen: Protokollaggregation Aktivieren Sie die Protokollaggregation: Set Garn.log-Aggregation-Enable in true in der Datei marn-site.xml, um die Protokollaggregation zu aktivieren. Konfigurieren von Protokoll-Retentionsrichtlinien: Setzen Sie Garn.log-Aggregation.Retain-Sekunden, um die Retentionszeit des Protokolls zu definieren, z. B. 172800 Sekunden (2 Tage). Log Speicherpfad angeben: über Garn.n
