
 Technologie-Peripheriegeräte
KI
Die Tsinghua NLP Group hat InfLLM veröffentlicht: Keine zusätzliche Schulung erforderlich, „1024K ultralanger Kontext' 100 % Rückruf!
Technologie-Peripheriegeräte
KI
Die Tsinghua NLP Group hat InfLLM veröffentlicht: Keine zusätzliche Schulung erforderlich, „1024K ultralanger Kontext' 100 % Rückruf!
Die Tsinghua NLP Group hat InfLLM veröffentlicht: Keine zusätzliche Schulung erforderlich, „1024K ultralanger Kontext' 100 % Rückruf!

Große Modelle können sich nur einen begrenzten Kontext merken und verstehen, was zu einer großen Einschränkung ihrer praktischen Anwendungen geworden ist. Konversations-KI-Systeme können sich beispielsweise häufig nicht dauerhaft an die Gespräche des Vortages erinnern, was dazu führt, dass Agenten, die mit großen Modellen erstellt wurden, inkonsistentes Verhalten und Gedächtnis aufweisen.
Damit große Modelle längere Kontexte besser verarbeiten können, haben Forscher eine neue Methode namens InfLLM vorgeschlagen. Diese von Forschern der Tsinghua-Universität, des MIT und der Renmin-Universität gemeinsam vorgeschlagene Methode ermöglicht es großen Sprachmodellen (LLMs), extrem lange Texte ohne zusätzliche Schulung zu verarbeiten. InfLLM nutzt eine geringe Menge an Rechenressourcen und Grafikspeicher-Overhead, um eine effiziente Verarbeitung sehr langer Texte zu erreichen.

Papieradresse: https://arxiv.org/abs/2402.04617
Code-Repository: https://github.com/thunlp/InfLLM
Experimentelle Ergebnisse zeigen, dass InfLLM sein kann effektiv Es erweitert das Kontextverarbeitungsfenster von Mistral und LLaMA erheblich und erreicht 100 % Rückruf bei der Suche nach der Nadel im Heuhaufen mit 1024.000 Kontexten.
Forschungshintergrund
Groß angelegte vorab trainierte Sprachmodelle (LLMs) haben in den letzten Jahren bei vielen Aufgaben bahnbrechende Fortschritte gemacht und sind zum Basismodell für viele Anwendungen geworden.
Diese praktischen Anwendungen stellen auch größere Herausforderungen an die Fähigkeit von LLMs, lange Sequenzen zu verarbeiten. Beispielsweise muss ein LLM-gesteuerter Agent die von der externen Umgebung empfangenen Informationen kontinuierlich verarbeiten, was eine stärkere Speicherkapazität erfordert. Gleichzeitig muss sich die Konversations-KI den Inhalt von Gesprächen mit Benutzern besser merken, um personalisiertere Antworten zu generieren.
Aktuelle groß angelegte Modelle werden jedoch normalerweise nur auf Sequenzen mit Tausenden von Tokens vorab trainiert, was bei der Anwendung auf sehr lange Texte zu zwei großen Herausforderungen führt:
1 Länge: Die direkte Anwendung von LLMs auf Texte mit längerer Länge erfordert häufig, dass LLMs die Positionskodierung über den Trainingsbereich hinaus verarbeiten, was zu Out-of-Distribution-Problemen und einem Versagen bei der Verallgemeinerung führt.
Ein zu langer Kontext führt dazu, dass die Aufmerksamkeit des Modells übermäßig auf irrelevante Informationen abgelenkt wird, wodurch es unmöglich wird, langfristige semantische Abhängigkeiten im Kontext effektiv zu modellieren. Einführung in die Methode InfLLM zielt darauf ab, die intrinsische Fähigkeit von LLMs zu stimulieren, semantische Abhängigkeiten über große Entfernungen in extrem langen Kontexten mit begrenztem Rechenaufwand zu erfassen und so ein effizientes Verständnis langer Texte zu ermöglichen.
Gesamtrahmen: Angesichts der spärlichen Aufmerksamkeit für lange Texte erfordert die Verarbeitung jedes Tokens normalerweise nur einen kleinen Teil seines Kontexts.
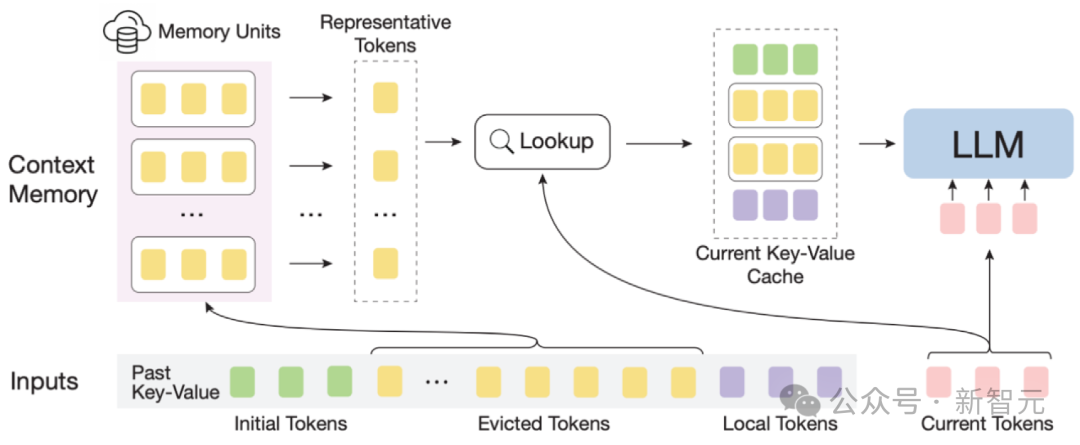
So können LLMs eine begrenzte Fenstergröße verwenden, um die gesamte lange Sequenz zu verstehen und die Einführung von Rauschen zu vermeiden.
Der massive Kontext in extrem langen Sequenzen bringt jedoch erhebliche Herausforderungen für die effektive Lokalisierung verwandter Informationen und die Effizienz der Speichersuche im Speichermodul mit sich.
Um diese Herausforderungen zu bewältigen, besteht jede Speichereinheit im kontextuellen Speichermodul aus einem semantischen Block, und ein semantischer Block besteht aus mehreren aufeinanderfolgenden Token.
Konkret: (1) Um relevante Speichereinheiten effektiv zu lokalisieren, kann die kohärente Semantik jedes semantischen Blocks die Anforderungen verwandter Informationsabfragen effektiver erfüllen als fragmentierte Token.
Darüber hinaus wählt der Autor aus jedem semantischen Block das semantisch wichtigste Token aus, also das Token, das den höchsten Aufmerksamkeitswert erhält, als Darstellung des semantischen Blocks. Diese Methode hilft, Ungenauigkeiten bei der Korrelationsberechnung zu vermeiden . Störung durch wichtige Token.
(2) Für eine effiziente Speichersuche vermeidet die Speichereinheit auf semantischer Blockebene Token-für-Token- und Aufmerksamkeit-für-Aufmerksamkeit-Korrelationsberechnungen, wodurch die Rechenkomplexität reduziert wird. Darüber hinaus sorgen semantische Speichereinheiten auf Blockebene für einen kontinuierlichen Speicherzugriff und reduzieren die Speicherladekosten. Dank dessen hat der Autor einen effizienten Offloading-Mechanismus (Offloading) für das Kontextspeichermodul entwickelt. Angesichts der Tatsache, dass die meisten Speichereinheiten selten verwendet werden, verlagert InfLLM alle Speichereinheiten in den CPU-Speicher und behält häufig verwendete Speichereinheiten dynamisch im GPU-Speicher bei, wodurch die Videospeichernutzung erheblich reduziert wird. InfLLM kann wie folgt zusammengefasst werden: 1. Fügen Sie basierend auf dem Schiebefenster ein Kontextspeichermodul mit großer Reichweite hinzu. 2. Teilen Sie den historischen Kontext in semantische Blöcke auf, um Speichereinheiten im Kontextspeichermodul zu bilden. Jede Speichereinheit bestimmt anhand ihrer Aufmerksamkeitsbewertung in der vorherigen Aufmerksamkeitsberechnung ein repräsentatives Token als Darstellung der Speichereinheit. Dadurch werden Rauschstörungen im Kontext vermieden und die Komplexität der Speicherabfrage reduziert , verwendet lokale Fenstergrößen von 4K bzw. 2K. Im Vergleich zum Originalmodell, der Positionskodierungsinterpolation, Infinite-LM und StreamingLLM wurden bei Langtextdaten Infinite-Bench und Longbench erhebliche Leistungsverbesserungen erzielt.
Experimentieren Sie mit sehr langen Texten Experimentelle Ergebnisse der Suche nach einer Nadel im Heuhaufen Zusammenfassung InfLLM fügt ein Speichermodul hinzu, das Kontextinformationen über große Entfernungen basierend auf dem Schiebefenster enthält, und verwendet den Cache- und Offload-Mechanismus, um Streaming-Langtext-Argumentation mit geringem Rechenaufwand und geringem Speicherverbrauch zu implementieren. 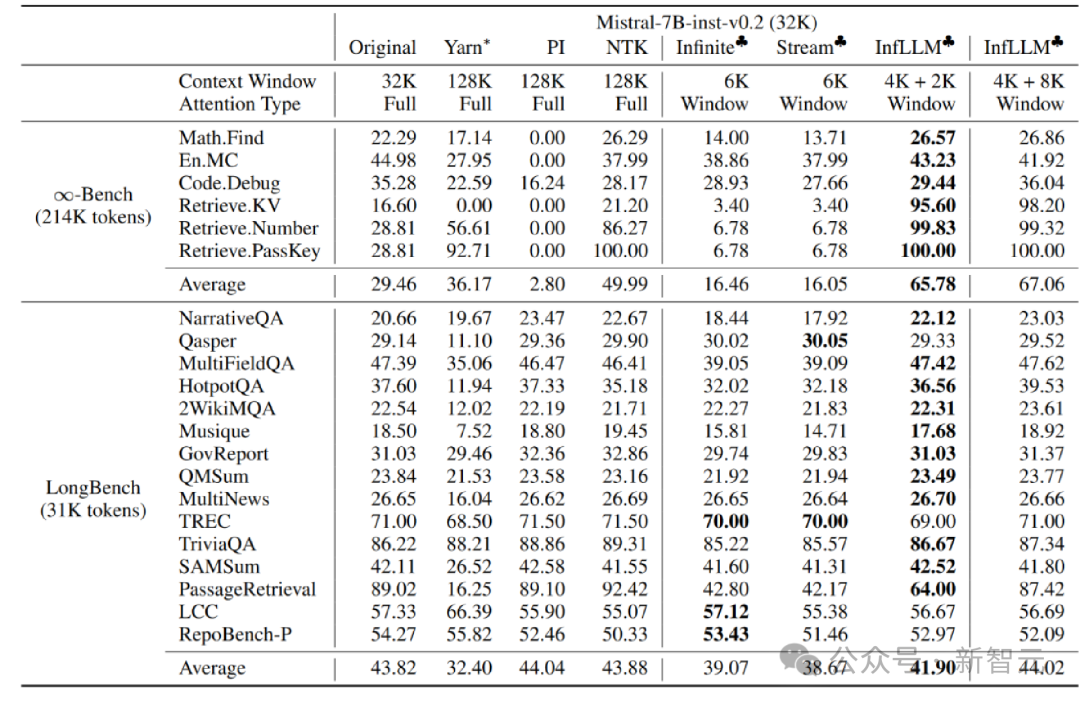
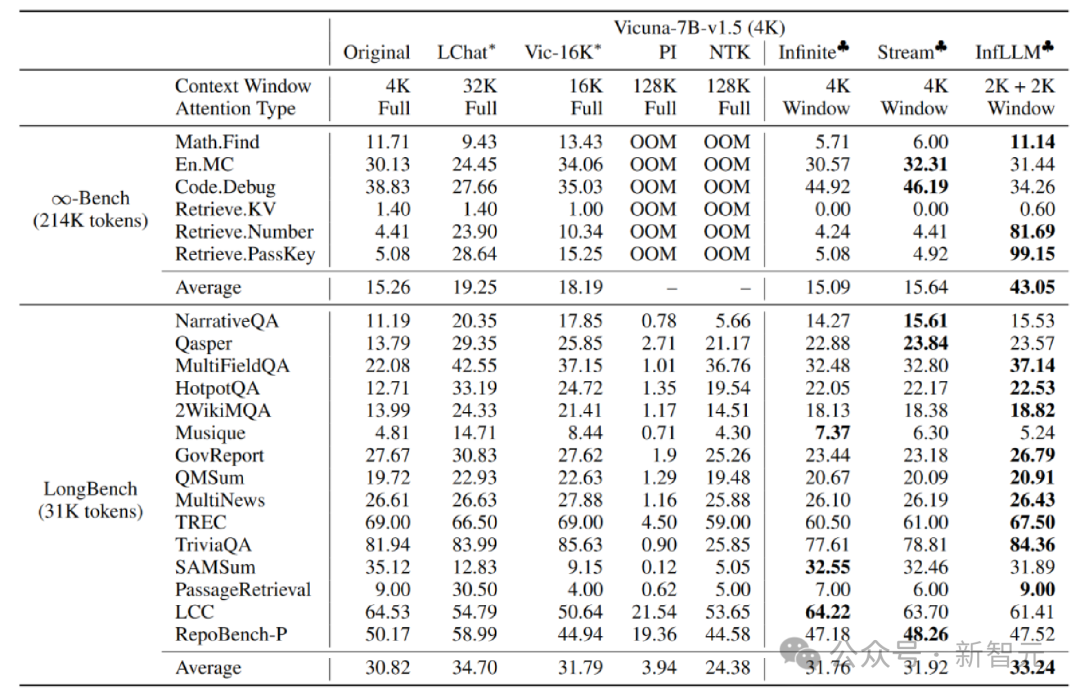 Darüber hinaus erforschte der Autor weiterhin die Generalisierungsfähigkeit von InfLLM bei längeren Texten, und es kann immer noch in der „Nadel im Heuhaufen“ funktionieren " Aufgabe mit einer Länge von 1024 KB. Behalten Sie eine Rückrufrate von 100 % bei.
Darüber hinaus erforschte der Autor weiterhin die Generalisierungsfähigkeit von InfLLM bei längeren Texten, und es kann immer noch in der „Nadel im Heuhaufen“ funktionieren " Aufgabe mit einer Länge von 1024 KB. Behalten Sie eine Rückrufrate von 100 % bei. 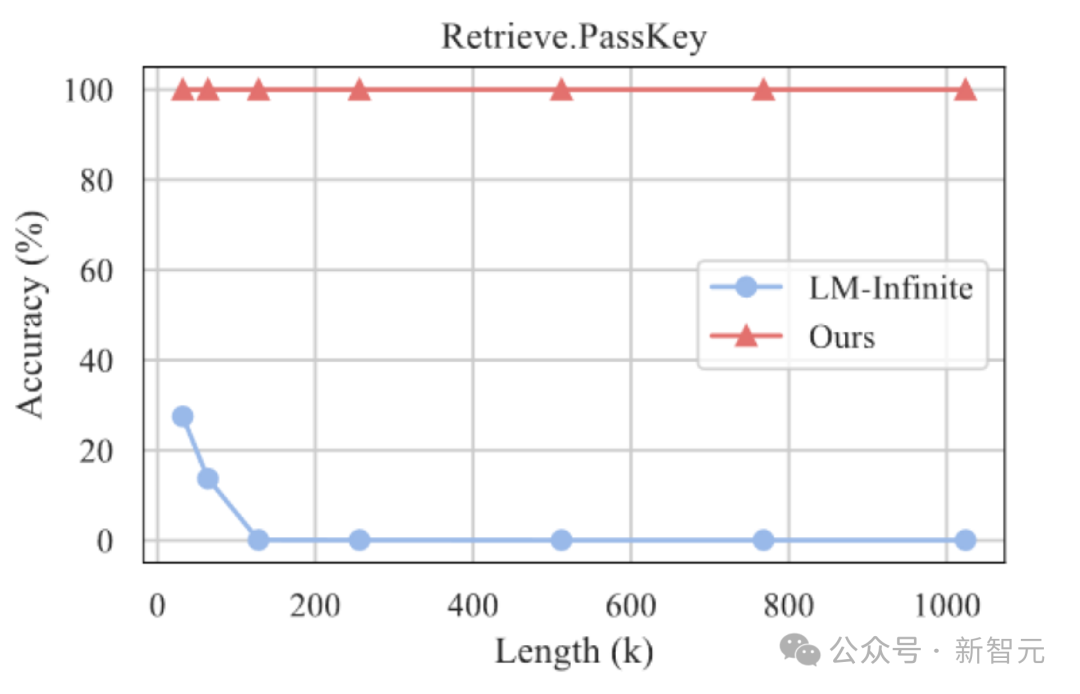 In diesem Artikel schlug das Team InfLLM vor, das die ultralange Textverarbeitung von LLM ohne Schulung erweitern und Langstreckensemantik erfassen kann Information .
In diesem Artikel schlug das Team InfLLM vor, das die ultralange Textverarbeitung von LLM ohne Schulung erweitern und Langstreckensemantik erfassen kann Information .
Das obige ist der detaillierte Inhalt vonDie Tsinghua NLP Group hat InfLLM veröffentlicht: Keine zusätzliche Schulung erforderlich, „1024K ultralanger Kontext' 100 % Rückruf!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
Der Befehl zum Neustart des SSH -Dienstes lautet: SystemCTL Neustart SSHD. Detaillierte Schritte: 1. Zugriff auf das Terminal und eine Verbindung zum Server; 2. Geben Sie den Befehl ein: SystemCTL Neustart SSHD; 1. Überprüfen Sie den Dienststatus: SystemCTL -Status SSHD.
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
