
 Computer-Tutorials
Computerwissen
Eine kurze Analyse der Architektur des Linux-Dateisystems (Dateisystem).
Computer-Tutorials
Computerwissen
Eine kurze Analyse der Architektur des Linux-Dateisystems (Dateisystem).
Eine kurze Analyse der Architektur des Linux-Dateisystems (Dateisystem).


In diesem Artikel geht es hauptsächlich um virtuelle Dateisysteme. Die Architektur des Linux-Dateisystems umfasst die Abstraktionsschicht zwischen bestimmten Dateisystemen (wie Ext2, Ext3, XFS usw.) und Anwendungen, nämlich das Virtual File System (VFS). VFS ermöglicht Anwendungen die Kommunikation mit verschiedenen Dateisystemtypen, ohne die Details des zugrunde liegenden Dateisystems zu kennen. Mit VFS können Dateisystemimplementierungen von Anwendungen isoliert und entkoppelt werden, wodurch die Flexibilität und Wartbarkeit des Systems verbessert wird. VFS ermöglicht dem Linux-Kernel außerdem die Unterstützung mehrerer Dateisystemtypen und bietet eine einheitliche Schnittstelle für Anwendungen, um auf das Dateisystem zuzugreifen. Im Rahmen von VFS können verschiedene Dateisysteme mit dem Kernel kommunizieren, indem Standard-Dateisystem-Betriebsschnittstellen implementiert werden
Bilder
Die obige Abbildung zeigt, dass das Zentrum dieser Architektur das virtuelle Dateisystem VFS ist. VFS stellt ein Dateisystem-Framework bereit und lokale Dateisysteme können basierend auf VFS implementiert werden. Es erledigt hauptsächlich folgende Aufgaben:
1) Als Abstraktionsschicht stellt VFS eine einheitliche Schnittstelle (Lesen, Schreiben, chmod usw.) für die Anwendungsschicht bereit.
2) Einige allgemeine Funktionen sind in VFS implementiert, z. B. Inode-Cache und Seiten-Cache.
3) Standardisiert die Schnittstellen, die bestimmte Dateisysteme implementieren sollten.
Basierend auf den oben genannten Einstellungen müssen andere spezifische Dateisysteme lediglich den Konventionen von VFS folgen, die entsprechenden Schnittstellen und die interne Logik implementieren und sie im System registrieren. Nachdem der Benutzer das Dateisystem formatiert und gemountet hat, kann er oder sie die Festplattenressourcen verwenden, um Vorgänge basierend auf dem Dateisystem auszuführen.
Im Linux-Betriebssystem müssen Sie nach dem Formatieren der Festplatte den Mount-Befehl verwenden, um sie in einem Verzeichnis in der Systemverzeichnisstruktur bereitzustellen. Dieses Verzeichnis wird als Mount-Punkt bezeichnet. Nachdem die Bereitstellung abgeschlossen ist, können wir den auf Basis dieses Dateisystems formatierten Festplattenspeicher nutzen. Im Linux-Betriebssystem kann der Mount-Punkt fast jedes Verzeichnis sein, zur Standardisierung ist der Mount-Punkt jedoch normalerweise ein Unterverzeichnis unter dem mnt-Verzeichnis.
Das Folgende zeigt eine relativ komplexe Verzeichnisstruktur. In dieser Verzeichnisstruktur befindet sich das Stammverzeichnis auf der SDA-Festplatte, und unter dem MNT-Verzeichnis gibt es drei Unterverzeichnisse, nämlich ext4, xfs und nfs, die jeweils das Ext4-Dateisystem (auf der SDB-Festplatte erstellt) bereitstellen XFS-Dateisystem (aufgebaut auf SDC-Festplatte) und NFS-Dateisystem (über Netzwerk bereitgestellt).
Bilder
Die Beziehung zwischen mehreren Dateisystemen im Verzeichnisbaum wird durch einige Datenstrukturen im Kernel dargestellt. Beim Mounten eines Dateisystems wird die Beziehung zwischen den Dateisystemen hergestellt und die API des spezifischen Dateisystems registriert. Wenn der Benutzermodus die API aufruft, um eine Datei zu öffnen, findet er die entsprechende Dateisystem-API und ordnet sie der dateibezogenen Struktur (z. B. Datei und Inode usw.) zu.
Die obige Beschreibung ist relativ schematisch und Sie sind möglicherweise immer noch etwas verwirrt. Aber keine Sorge, wir werden VFS und die Unterstützung mehrerer Dateisysteme anhand des Codes detaillierter vorstellen.
1. Von der Dateisystem-API über VFS bis hin zu einem bestimmten Dateisystem
VFS unter Linux gab es von Anfang an nicht. Die früheste veröffentlichte Version von Linux verfügte nicht über VFS. Darüber hinaus wurde VFS nicht unter Linux erfunden, sondern erstmals 1985 in SunOS2.0 entwickelt. Der Hauptzweck der Entwicklung von VFS besteht darin, das lokale Dateisystem und das NFS-Dateisystem anzupassen.
VFS implementiert die Abstraktion spezifischer Dateisysteme durch eine Reihe öffentlicher APIs und Datenstrukturen. Wenn der Benutzer die vom Betriebssystem bereitgestellte Dateisystem-API aufruft, wird die vom Kernel-VFS implementierte Funktion über einen Soft-Interrupt aufgerufen. Die folgende Tabelle zeigt die Entsprechung zwischen einigen Datei-APIs und Kernel-VFS-Funktionen.
|
Benutzermodus-API |
Kernel-Funktion |
Anleitung |
|
offen |
do_sys_open |
Datei öffnen |
|
schließen |
ksys_close |
Datei schließen |
|
lesen |
ksys_read/vfs_read |
Daten lesen |
|
schreiben |
ksys_write/vfs_write |
Daten schreiben |
|
montieren |
do_mount |
Dateisystem mounten |
Aus der obigen Tabelle ist ersichtlich, dass jede Benutzermodus-API über eine entsprechende Kernelmodus-Funktion verfügt. Wenn eine Anwendung die API des Dateisystems aufruft, wird die entsprechende Funktion im Kernel-Status ausgelöst. Was hier aufgeführt ist, ist nur eine relativ kleine Teilmenge der Dateisystem-API. Der Zweck besteht darin, die Beziehung zwischen der API und VFS zu veranschaulichen. Wenn Sie mehr über andere APIs erfahren möchten, lesen Sie bitte selbst den Kernel-Quellcode. Ich werde in diesem Artikel nicht auf Details eingehen.
Um jedem ein verständnisvolles Verständnis der Beziehung zwischen VFS und bestimmten Dateisystemen zu vermitteln, wird in diesem Abschnitt die Ext2-Schreib-API als Beispiel verwendet, um die Aufrufbeziehung von der API zu VFS-Funktionen und dann zu den Ext2-Dateisystemfunktionen zu zeigen. Wie in der folgenden Abbildung gezeigt, löst die API-Funktion write die Funktion ksys_write des Kernels über einen Soft-Interrupt aus. Nach mehreren Prozessen ruft diese Funktion schließlich die Funktion ext2_file_write_iter des Ext2-Dateisystems über den Funktionszeiger (file->f_op) auf ->wirte_iter).
Bilder
In der obigen Abbildung ist der Eingang zum Kernelprozess die Funktion ksys_write. Wie aus dem Implementierungscode ersichtlich ist, besteht der Hauptzweck hier darin, ein fd zu erhalten und dann vfs_write mit der Mitgliedsdatei im fd als Parameter aufzurufen . Unter diesen ist fd eine Struktur, deren Format wie in der folgenden Abbildung dargestellt ist. Das Dateimitglied ist eine relativ zentrale Datenstruktur. Wie aus der obigen Abbildung ersichtlich ist, werden die Funktionen des Ext2-Dateisystems über den Inhalt dieses Mitglieds übertragen.
Bilder
Es scheint sehr einfach zu sein: VFS muss nur den vom jeweiligen Dateisystem registrierten Funktionszeiger aufrufen. Aber hier gibt es ein ungelöstes Problem. Wann wurden die Funktionszeiger in VFS registriert?
Der Funktionszeiger von Ext2 wird beim Öffnen der Datei initialisiert (Einzelheiten finden Sie in Abschnitt 3.1.2.2 von „Insider der Dateisystemtechnologie“). Wie wir alle wissen, gibt ein Benutzermodusprogramm beim Öffnen einer Datei einen Dateideskriptor zurück, aber die Strukturdatei, die die Datei im Kernel darstellt, entspricht diesem. Zu den wichtigeren Mitgliedern dieser Struktur gehören f_inode, f_ops und f_mapping, wie in der folgenden Abbildung dargestellt.
Bilder
In der obigen Abbildung ist f_inode der Inode-Knoten, der der Datei entspricht. f_ops ist eine Sammlung von Funktionszeigern für Dateioperationen in einem bestimmten Dateisystem (z. B. Ext2). Sie wird beim Öffnen der Datei initialisiert. Über diese Sammlung von Funktionszeigern implementiert VFS den Zugriff auf bestimmte Dateisysteme.
Das Obige beinhaltet ein anderes Konzept von VFS, Inode. Unter Linux ist Inode die Abkürzung für Indexknoten, der ein bestimmtes Objekt (z. B. eine Datei oder ein Verzeichnis) im Dateisystem darstellt. In VFS gibt es eine Datenstruktur namens „Inode“, die eine Abstraktion des spezifischen Dateisystem-Inodes darstellt. Im Ext2-Dateisystem ist es beispielsweise speziell als ext2_inode_info definiert, in XFS wird es jedoch durch die Datenstruktur xfs_inode dargestellt. Darüber hinaus ist die Inode-Datenstruktur des jeweiligen Dateisystems eng mit dem Inode von VFS verbunden. Sie können den Code selbst lesen.
2.inode-Cache und Dentry-Cache
Im Architekturdiagramm sehen wir, dass es in VFS mehrere Cache-Implementierungen gibt, darunter Seiten-Cache, Inode-Cache, Dentry-Cache usw. Der Inode-Cache und der Dentry-Cache werden auf die gleiche Weise implementiert und sind relativ einfach. Daher werden in diesem Artikel zunächst diese beiden Caches vorgestellt.
Tatsächlich werden diese beiden Caches durch Hash-Tabellen implementiert. Jeder kennt das Konzept von Hash-Tabellen, daher werde ich in diesem Artikel nicht auf Details eingehen. Nehmen Sie als Beispiel den Inode-Cache. Anhand des Parameters ihash_entries können Sie erkennen, dass seine Größe dynamisch ist (seine Größe hängt vom Systemspeicher ab). lesen).
Bilder
Da beim Zugriff auf Dateien häufig auf Inode und Dentry zugegriffen wird, kann durch deren Zwischenspeicherung der Leistungsverlust vermieden werden, der durch das Lesen von Daten von der Festplatte verursacht wird.
3.Seiten-Cache
Der VFS-Seitencache (Cache) wird hauptsächlich zur Verbesserung der Leistung des Dateisystems verwendet. Unter Caching-Technologie versteht man eine Technologie, die einen Teil der Daten und Metadaten des Dateisystems im Speicher speichert, um die Leistung des Dateisystems zu verbessern. Da die Zugriffslatenz des Speichers ein Hunderttausendstel der Zugriffslatenz einer mechanischen Festplatte beträgt (wie in der folgenden Abbildung dargestellt, mit dem Register als Basiseinheit 1s), kann der Einsatz der Caching-Technologie die Leistung der Datei erheblich verbessern System.
Bilder
Cache verbessert die Leistung des Dateisystems durch drei Aspekte der IO-Optimierung, nämlich Hot Data, Vorlesen und IO-Zusammenführung. Viele Anwendungen verfügen über Hot Data. Wenn ein Autor beispielsweise ein Dokument bearbeitet, sind der aktuelle Datenblock und die Datenblöcke in der Nähe Hot Data. Oder wenn ein beliebter Artikel erscheint, handelt es sich bei dem Inhalt dieses Artikels um heiße Daten. Die Leistung der zugrunde liegenden Speichergeräte ist bei Lese- und Schreibvorgängen großer Blöcke oft besser. Beim Vorlesen werden große Datenblöcke im Voraus vom zugrunde liegenden Gerät gelesen und zwischengespeichert, sodass auf Anwendungsanfragen über den Cache reagiert werden kann. Die E/A-Zusammenführung erfolgt für Schreibanfragen. Die Schreibanfragen werden nicht sofort auf dem Back-End-Gerät gespeichert, sondern vor dem Schreiben zwischengespeichert und in große E/A-Blöcke aufgeteilt.
Da die Kapazität des Speichers viel kleiner ist als die Kapazität der Festplatte, kann der Seitencache nicht alle Daten der Festplatte zwischenspeichern. Auf diese Weise kann nur eine Teilmenge der Dateisystemdaten im Cache gespeichert werden. Wenn Benutzer weiterhin Daten schreiben, kommt es zu einer Situation, in der der Cache voll ist. Zu diesem Zeitpunkt stellt sich das Problem, wie die Cache-Daten auf die Festplatte geleert und dann neue Daten gespeichert werden.
Der Vorgang des Leerens des Caches auf die Festplatte und des Speicherns neuer Daten wird als Cache-Ersetzung bezeichnet. Es gibt viele Algorithmen zum Cache-Ersetzen, die jeweils zur Lösung unterschiedlicher Probleme eingesetzt werden. Als nächstes stellen wir mehrere gängige Cache-Ersetzungsalgorithmen vor.
LRU-Algorithmus, der vollständige Name von LRU ist Least Latest Used, was bedeutet, dass es am wenigsten kürzlich verwendet wurde. Dieser Algorithmus basiert auf dem Prinzip der zeitlichen Lokalität, d. h. wenn ein Datenelement kürzlich verwendet wurde, besteht eine hohe Wahrscheinlichkeit, dass es in Zukunft erneut verwendet wird. Daher gibt der Algorithmus Caches frei, die in letzter Zeit nicht verwendet wurden.
Der LRU-Algorithmus wird normalerweise mithilfe einer verknüpften Liste implementiert. Der gerade verwendete Cache wird in den Kopf der Tabelle eingefügt, während die nicht häufig verwendeten Daten langsam an das Ende der verknüpften Liste gequetscht werden. Um das Prinzip von LRU besser zu verstehen, veranschaulichen wir es anhand der folgenden Abbildung.
Bilder
In diesem Beispiel nehmen wir volle Treffer als Beispiel. Gehen Sie davon aus, dass sich im Cache 6 Datenblöcke befinden, wie in der ersten Zeile der Abbildung dargestellt. Die Zahl im Feld gibt die Nummer des Datenblocks an. Angenommen, der erste Zugriff (kann gelesen oder geschrieben werden) ist Datenblock Nr. 3. Da darauf zugegriffen wurde, wird er an den Kopf der verknüpften Liste verschoben.
Der zweite Zugriff erfolgt auf den Datenblock Nr. 4. Nach dem gleichen Prinzip wird dieser Datenblock auch an den Kopf der verknüpften Liste verschoben. Die Details sind in Zeile 2 der obigen Abbildung dargestellt.
Also analog dazu wurden nach 4 Zugriffsrunden die Daten, auf die zugegriffen wurde, nach vorne verschoben, während die Datenblöcke, auf die nicht zugegriffen wurde (z. B. 1 und 2), langsam an das Ende der verknüpften Liste gedrängt wurden. Dies deutet gewissermaßen darauf hin, dass die Wahrscheinlichkeit eines späteren Zugriffs auf diese beiden Datenblöcke relativ gering ist.
Bei einem Volltreffer erfolgt kein Cache-Ersatz. Die tatsächliche Situation ist, dass der Cache oft nicht ausreicht und die darin enthaltenen Daten freigegeben werden müssen (abhängig von der Situation, ob sie auf die Festplatte geleert werden müssen), um neue Daten zu speichern. Zu diesem Zeitpunkt ist der LRU-Algorithmus nützlich. Dieser Algorithmus verwendet den Enddatenblock, um neue Daten zu speichern, und platziert ihn dann an der Spitze der verknüpften Liste, wie in der folgenden Abbildung dargestellt. Wenn dieser Datenblock fehlerhafte Daten enthält, müssen diese auf die Festplatte geleert werden, andernfalls können sie direkt freigegeben werden.
Bilder
Das Prinzip und die Implementierung des LRU-Algorithmus sind relativ einfach, er bietet jedoch ein breites Einsatzspektrum. Der LRU-Algorithmus weist jedoch einen Nachteil auf: Wenn plötzlich eine große Menge kontinuierlicher Daten geschrieben wird, werden alle Cache-Blöcke ersetzt, wodurch alle vorherigen Cache-Nutzungsstatistiken ungültig werden. Dieses Phänomen wird als Cache-Verschmutzung bezeichnet. Um das Problem der Cache-Verschmutzung zu lösen, gibt es viele verbesserte LRU-Algorithmen, darunter LRU-K, 2Q und LIRS.
LFU-Algorithmus, der vollständige Name von LFU lautet „Least Frequently Used“, was bedeutet, dass er in letzter Zeit am seltensten verwendet wurde. Dieser Algorithmus entscheidet anhand der Häufigkeit des Datenzugriffs, welcher Cache-Block freigegeben werden soll. Der Cache-Block mit der niedrigsten Zugriffshäufigkeit wird zuerst freigegeben.
Wie unten gezeigt ist ein schematisches Diagramm des LFU-Algorithmus. Zeile 1 ist der Originalzustand und die Zahl im Feld gibt an, wie oft auf den Cache-Block zugegriffen wurde. Das Hinzufügen neuer Daten und das Entfernen von Cache-Blöcken erfolgen vom Ende aus. Angenommen, auf ein bestimmtes Datenelement (gepunktetes Feld) wurde viermal zugegriffen und die Anzahl der Zugriffe hat sich von 12 auf 16 geändert, sodass es an einen neuen Speicherort verschoben werden muss, wie Zeile 2 in der Abbildung aussieht .
Bilder
Dieses Buch verwendet eine verknüpfte Liste als Beispiel, um das Prinzip von LFU zu veranschaulichen und das Verständnis zu erleichtern. Es wird jedoch niemals während der Projektimplementierung mithilfe einer verknüpften Liste implementiert. Da ein neuer Speicherort gefunden werden muss, wenn sich die Anzahl der Zugriffe auf einen Datenblock ändert, ist die Suche nach verknüpften Listen sehr zeitaufwändig. Um eine schnelle Suche zu erreichen, wird im Allgemeinen ein Suchbaum verwendet.
LFU hat auch seine Nachteile: Wenn in einem bestimmten Zeitraum vor langer Zeit häufig auf einen Datenblock zugegriffen wurde und in Zukunft nicht mehr darauf zugegriffen wird, verbleiben die Daten im Cache. Da jedoch nicht mehr auf die Daten zugegriffen wird, verringert sich die effektive Kapazität des Caches. Mit anderen Worten: Der LFU-Algorithmus berücksichtigt nicht die aktuelle Situation.
In diesem Artikel werden hauptsächlich zwei sehr grundlegende Ersetzungsalgorithmen vorgestellt: LRU und LFU. Zusätzlich zu den oben genannten Algorithmen gibt es viele Ersatzalgorithmen, von denen die meisten auf der Theorie von LRU und LFU basieren, wie z. B. 2Q, MQ, LRFU, TinyLFU und ARC usw. Aus Platzgründen wird in diesem Buch nicht auf Einzelheiten eingegangen. Sie können die relevanten Artikel selbst lesen.
Das Vorlesen von Daten verfügt auch über einen bestimmten Algorithmus. Der Vorlesealgorithmus liest Daten im Voraus von der Festplatte in den Cache, indem er E/A-Muster identifiziert. Auf diese Weise kann die Anwendung beim Lesen von Daten die Daten direkt aus dem Cache lesen, wodurch die Leistung beim Lesen von Daten erheblich verbessert wird.
Das Wichtigste im Vorlesealgorithmus ist die Auslösebedingung, das heißt, unter welchen Umständen der Vorlesevorgang eingeleitet wird. Normalerweise gibt es zwei Situationen, die ein Vorauslesen auslösen: Zum einen, wenn aufeinanderfolgende Leseanforderungen von mehreren Adressen vorliegen, was einen Vorauslesevorgang auslöst, und zum anderen, wenn die Anwendung mit einer Vorauslesemarkierung auf einen Cache zugreift. Hierbei handelt es sich bei der Cache-Vorlesemarkierung um eine Markierung auf der Cache-Seite, wenn der Lesevorgang abgeschlossen ist. Wenn die Anwendung den Cache mit dieser Markierung liest, wird das nächste Vorauslesen ausgelöst, wodurch die Identifizierung weggelassen wird des IO-Modus.
Bilder
Um die Logik des Vorlesens klarer zu erklären, stellen wir den gesamten Prozess anhand des obigen Bildes vor. Wenn das Dateisystem erkennt, dass der IO-Modus ein Vorlesen erfordert, liest es einen zusätzlichen Teil des Inhalts aus (sogenanntes synchrones Vorlesen), wie in Zeit 1 (erste Zeile) gezeigt. Gleichzeitig markiert das Dateisystem für synchrone Read-Ahead-Daten einen der Blöcke. Der Zweck dieser Markierung besteht darin, den nächsten Preread so früh wie möglich vor dem Ende des Caches auszulösen.
Zum zweiten Zeitpunkt, wenn die Anwendung weiterhin Daten liest, wird gleichzeitig der nächste Vorlesevorgang ausgelöst, da der markierte Cache-Block gelesen wird. Zu diesem Zeitpunkt werden die Daten in einem Schritt von der Festplatte gelesen, und Sie können der Abbildung entnehmen, dass der Cache zunimmt.
Zum nächsten Zeitpunkt Punkt 3 und 4 kann die Anwendung Daten direkt aus dem Cache lesen. Da kein markierter Cache-Block gelesen wurde, wird der nächste Read-Ahead nicht ausgelöst. Zum Zeitpunkt 5 wird der Vorlesevorgang erneut ausgelöst, da eine Vorlesemarkierung vorhanden ist.
Aus der obigen Analyse ist ersichtlich, dass die Daten aufgrund der Vorlesefunktion im Voraus in den Cache eingelesen werden. Anwendungen können Daten direkt aus dem Cache lesen, ohne auf die Festplatte zuzugreifen, sodass die Gesamtzugriffsleistung erheblich verbessert wird.
Das obige ist der detaillierte Inhalt vonEine kurze Analyse der Architektur des Linux-Dateisystems (Dateisystem).. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

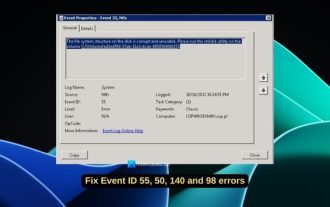 Beheben Sie den Festplattenfehler der Ereignis-ID 55, 50, 98, 140 in der Ereignisanzeige
Mar 19, 2024 am 09:43 AM
Beheben Sie den Festplattenfehler der Ereignis-ID 55, 50, 98, 140 in der Ereignisanzeige
Mar 19, 2024 am 09:43 AM
Wenn Sie in der Ereignisanzeige von Windows 11/10 die Ereignis-ID 55, 50, 140 oder 98 finden oder auf einen Fehler stoßen, dass die Dateisystemstruktur der Festplatte beschädigt ist und nicht verwendet werden kann, befolgen Sie bitte die nachstehende Anleitung, um das Problem zu beheben. Was bedeutet Ereignis 55, Dateisystemstruktur auf der Festplatte beschädigt und unbrauchbar? Bei Sitzung 55 ist die Dateisystemstruktur auf der Ntfs-Festplatte beschädigt und unbrauchbar. Bitte führen Sie das Dienstprogramm chkMSK auf dem Volume aus. Wenn NTFS keine Daten in das Transaktionsprotokoll schreiben kann, wird ein Fehler mit der Ereignis-ID 55 ausgelöst, der dazu führt, dass NTFS den Vorgang nicht abschließen kann und die Transaktionsdaten nicht schreiben kann. Dieser Fehler tritt normalerweise auf, wenn das Dateisystem beschädigt ist, möglicherweise aufgrund fehlerhafter Sektoren auf der Festplatte oder aufgrund der Unzulänglichkeit des Dateisystems im Festplattensubsystem.
 Vollständige Anleitung zur Deinstallation der Kali Linux-Software zur Lösung von Systemstabilitätsproblemen
Mar 23, 2024 am 10:50 AM
Vollständige Anleitung zur Deinstallation der Kali Linux-Software zur Lösung von Systemstabilitätsproblemen
Mar 23, 2024 am 10:50 AM
Diese Studie bietet eine umfassende und detaillierte Analyse von Software-Deinstallationsproblemen, die während des Penetrationstest- und Sicherheitsüberprüfungsprozesses von KaliLinux auftreten können, und liefert Lösungen zur Gewährleistung der Systemstabilität und -zuverlässigkeit. 1. Verstehen Sie die Softwareinstallationsmethode. Kalilinux deinstalliert zunächst den Installationspfad. Anschließend wird entsprechend dem gewählten Pfad die passende Offloading-Lösung ausgewählt. Zu den gängigen Installationsmethoden gehören apt-get, dpkg, Quellcode-Kompilierung und andere Formen. Jede Strategie hat ihre eigenen Merkmale und entsprechende Entlastungsmaßnahmen. 2. Verwenden Sie den Befehl apt-get, um Software zu deinstallieren. Im KaliLinux-System wird die Funktionskomponente apt-get häufig verwendet, um Softwarepakete effizient und bequem auszuführen.
 Eine vollständige Anleitung zur Installation des heimischen Betriebssystems Kirin Linux, abgeschlossen in 15 Minuten
Mar 21, 2024 pm 02:36 PM
Eine vollständige Anleitung zur Installation des heimischen Betriebssystems Kirin Linux, abgeschlossen in 15 Minuten
Mar 21, 2024 pm 02:36 PM
In letzter Zeit hat das inländische Betriebssystem Kirin Linux große Aufmerksamkeit auf sich gezogen. Als leitender Computeringenieur habe ich ein starkes Interesse an technologischen Innovationen, daher habe ich den Installationsprozess dieses Systems persönlich miterlebt, und jetzt werde ich meine Erfahrungen mit Ihnen teilen. Bevor ich den Installationsprozess durchführte, war ich umfassend auf die relevanten Schritte vorbereitet. Die erste Aufgabe besteht darin, das neueste Kirin-Linux-Betriebssystem-Image herunterzuladen und auf ein USB-Flash-Laufwerk zu kopieren. Zweitens muss bei 64-Bit-Linux sichergestellt werden, dass wichtige Daten auf persönlichen Geräten gesichert wurden, um mögliche Installationsprobleme zu beheben Fahren Sie den Computer herunter und stecken Sie den USB-Stick ein. Nachdem Sie die Installationsoberfläche aufgerufen und den Computer neu gestartet haben, drücken Sie sofort die Funktionstaste F12, rufen Sie das Systemstartmenü auf und wählen Sie die Option USB-Prioritätsstart. Vor Ihnen erscheint ein schöner und einfacher Startbildschirm
 Puppylinux-Installations-USB-Diskette
Mar 18, 2024 pm 06:31 PM
Puppylinux-Installations-USB-Diskette
Mar 18, 2024 pm 06:31 PM
Tatsächlich zeigt die Gesamtleistung nach längerer Nutzung eines Computers einen Abwärtstrend und die Anpassungsfähigkeit an das Windows-System nimmt weiter ab. Neben den Gründen für den Computer selbst wird das Windows-System immer weiter verbessert und erweitert, und auch die Anforderungen an die Hardware werden immer höher. Daher ist es nicht verwunderlich, dass es bei alten Computern nach der Installation des Windows-Systems zu Verzögerungen kommt. Zuvor fragten viele Freunde im Hintergrund wegen Systemverzögerungen, was tun mit alten Computern? Wenn Sie feststellen, dass die Installation des neuen Windows 10-Systems auf Ihrem alten Computer zu Verzögerungen und Betriebsproblemen führt, ist es möglicherweise eine gute Wahl, einen Wechsel zu Linux in Betracht zu ziehen. Dabaicai hat 5 Micro-Linux-Systeme zusammengestellt, die für alte Computer geeignet sind und die CPU-Auslastung effektiv reduzieren und Ihre Leistung verbessern können
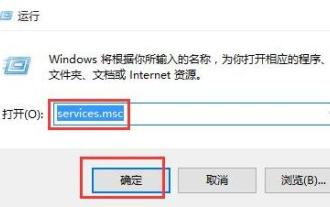 Umgang mit dem Dateisystemfehler 2147416359 in WIN10
Mar 27, 2024 am 11:31 AM
Umgang mit dem Dateisystemfehler 2147416359 in WIN10
Mar 27, 2024 am 11:31 AM
1. Drücken Sie win+r, um das Ausführungsfenster aufzurufen, geben Sie [services.msc] ein und drücken Sie die Eingabetaste. 2. Suchen Sie im Dienstfenster nach [Windows-Lizenzmanager-Dienst] und doppelklicken Sie, um ihn zu öffnen. 3. Ändern Sie in der Benutzeroberfläche den Starttyp auf [Automatisch] und klicken Sie dann auf [Übernehmen → OK]. 4. Nehmen Sie die oben genannten Einstellungen vor und starten Sie den Computer neu.
 Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA basiert auf der JPA-Architektur und interagiert mit der Datenbank über Mapping, ORM und Transaktionsmanagement. Sein Repository bietet CRUD-Operationen und abgeleitete Abfragen vereinfachen den Datenbankzugriff. Darüber hinaus nutzt es Lazy Loading, um Daten nur bei Bedarf abzurufen und so die Leistung zu verbessern.
 So lösen Sie das Problem verstümmelter Zeichen, die in der Linux-Befehlszeile angezeigt werden
Mar 21, 2024 am 08:30 AM
So lösen Sie das Problem verstümmelter Zeichen, die in der Linux-Befehlszeile angezeigt werden
Mar 21, 2024 am 08:30 AM
Methoden zur Lösung des Problems verstümmelter Zeichen, die in der Linux-Befehlszeile angezeigt werden. Im Linux-Betriebssystem werden manchmal verstümmelte Zeichen angezeigt, wenn wir die Befehlszeilenschnittstelle verwenden, was unsere normale Anzeige und unser Verständnis der Befehlsausgabeergebnisse oder -dateien beeinträchtigt Inhalt. Die Ursachen für verstümmelte Zeichen können in falschen Systemzeichensatzeinstellungen, Terminalsoftware, die die Anzeige bestimmter Zeichensätze nicht unterstützt, inkonsistenten Dateikodierungsformaten usw. liegen. In diesem Artikel werden einige Methoden zur Lösung des Problems verstümmelter Zeichen in der Linux-Befehlszeile vorgestellt und spezifische Codebeispiele bereitgestellt, um Lesern bei der Lösung ähnlicher Probleme zu helfen.
 Warum schlafen Prozesse unter Linux?
Mar 20, 2024 pm 02:09 PM
Warum schlafen Prozesse unter Linux?
Mar 20, 2024 pm 02:09 PM
Warum schlafen Prozesse unter Linux? Im Linux-Betriebssystem kann ein Prozess aus verschiedenen Gründen und Bedingungen in den Ruhezustand geraten. Wenn sich ein Prozess in einem Ruhezustand befindet, bedeutet dies, dass der Prozess vorübergehend angehalten ist und die Ausführung nicht fortsetzen kann, bis bestimmte Bedingungen erfüllt sind, bevor er zur Fortsetzung der Ausführung aktiviert werden kann. Als Nächstes werden wir einige häufige Situationen, in denen ein Prozess unter Linux in den Ruhezustand wechselt, im Detail vorstellen und sie anhand spezifischer Codebeispiele veranschaulichen. Warten auf den Abschluss der E/A: Wenn ein Prozess einen E/A-Vorgang initiiert (z. B. Lesen).
