
 Technologie-Peripheriegeräte
KI
Was tun, wenn keine End-to-End-Daten vorhanden sind? ActiveAD: Durchgängiges autonomes Fahren, aktives Lernen für die Planung!
Technologie-Peripheriegeräte
KI
Was tun, wenn keine End-to-End-Daten vorhanden sind? ActiveAD: Durchgängiges autonomes Fahren, aktives Lernen für die Planung!
Was tun, wenn keine End-to-End-Daten vorhanden sind? ActiveAD: Durchgängiges autonomes Fahren, aktives Lernen für die Planung!


End-to-End-differenzierbares Lernen für autonomes Fahren ist in letzter Zeit zu einem prominenten Paradigma geworden. Ein großer Engpass liegt in der enormen Nachfrage nach qualitativ hochwertigen beschrifteten Daten wie 3D-Boxen und semantischer Segmentierung, deren manuelle Annotation notorisch teuer ist. Diese Schwierigkeit wird durch die herausragende Tatsache verschärft, dass das Verhalten innerhalb der Stichprobe bei AD häufig Long-Tail-Verteilungen aufweist. Mit anderen Worten: Die meisten der gesammelten Daten können trivial sein (z. B. beim Vorwärtsfahren auf einer geraden Straße), und nur wenige Situationen sind sicherheitskritisch. In diesem Artikel untersuchen wir ein praktisch wichtiges, aber wenig erforschtes Thema, nämlich die Frage, wie bei der End-to-End-AD eine Proben- und Etiketteneffizienz erreicht werden kann.
Konkret entwirft das Papier eine planungsorientierte aktive Lernmethode, die Teile der gesammelten Rohdaten nach und nach entsprechend den Diversitäts- und Nützlichkeitskriterien der vorgeschlagenen Planungsrouten annotiert. Empirisch kann der vorgeschlagene planorientierte Ansatz allgemeine aktive Lernansätze weit übertreffen. Bemerkenswert ist, dass unsere Methode mit nur 30 % der nuScenes-Daten eine vergleichbare Leistung wie hochmoderne End-to-End-AD-Methoden erreicht. Wir hoffen, dass unsere Arbeit neben methodischen Bemühungen auch künftige Arbeiten aus einer datenzentrierten Perspektive inspirieren wird.
Link zum Papier: https://arxiv.org/pdf/2403.02877.pdf
Hauptbeitrag dieses Artikels:
- Die erste Person, die sich eingehend mit den Datenproblemen von E2E-AD befasst. Bietet außerdem eine einfache, aber effektive Lösung, um wertvolle Daten für die Planung innerhalb eines begrenzten Budgets zu identifizieren und zu kommentieren.
- Basierend auf der planungsorientierten Philosophie des End-to-End-Ansatzes werden neue aufgabenspezifische Diversitäts- und Unsicherheitsmaße für die Routenplanung konzipiert.
- Umfangreiche Experimente und Ablationsstudien haben die Wirksamkeit der Methode nachgewiesen. ActiveAD übertrifft generische Peer-to-Peer-Methoden bei weitem und erreicht eine mit SOTA-Methoden vergleichbare Leistung mit vollständigen Bezeichnungen, die nur 30 % der nuScenes-Daten verwenden.
Einführung in die Methode
ActiveAD wird im End-to-End-AD-Framework ausführlich beschrieben, und Diversitäts- und Unsicherheitsindikatoren werden basierend auf den Datenmerkmalen von AD entworfen.
1) Erstprobenauswahl von Etiketten
Beim aktiven Lernen in Computer Vision basiert die Erstprobenauswahl normalerweise nur auf dem Originalbild ohne zusätzliche Informationen oder erlernte Funktionen, was zur gängigen Praxis der zufälligen Initialisierung führt. Im Fall von AD stehen zusätzliche Vorabinformationen zur Verfügung. Konkret können bei der Erfassung von Daten von Sensoren herkömmliche Informationen wie Geschwindigkeit und Flugbahn des eigenen Fahrzeugs gleichzeitig erfasst werden. Darüber hinaus sind Wetter- und Lichtverhältnisse häufig kontinuierlich und lassen sich auf Fragmentebene leicht annotieren. Diese Informationen erleichtern das Treffen fundierter Entscheidungen für die Erstauswahl des Sets. Aus diesem Grund haben wir ein Selbstdiversitätsmaß für die Erstauswahl entwickelt.
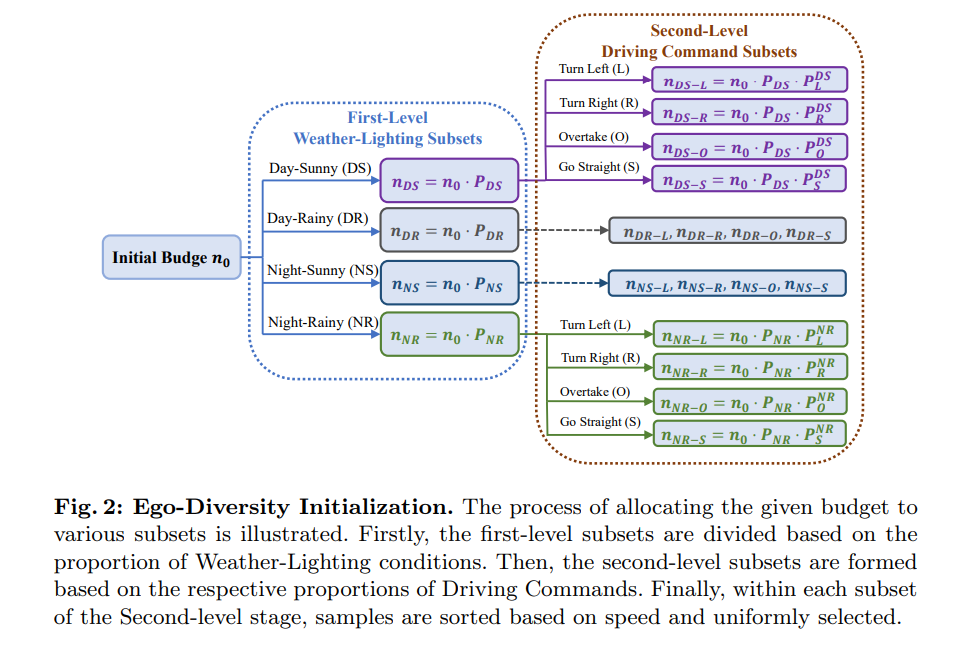
Ego Diversity: Besteht aus drei Teilen: 1) Wetterbeleuchtung 2) Fahranweisungen 3) Durchschnittsgeschwindigkeit. Verwenden Sie zunächst die Beschreibung in nuScenes, um den gesamten Datensatz in vier sich gegenseitig ausschließende Teilmengen zu unterteilen: Day Sunny (DS), Day Rainy (DR), Night Sunny (NS), NightRainy (NR). Zweitens ist jede Teilmenge in vier Kategorien unterteilt, basierend auf der Anzahl der Links-, Rechts- und Geradeausfahrbefehle in einem vollständigen Segment: Linkskurve (L), Rechtskurve (R), Überholen (O) und Geradeaus fahren (S). Das Papier entwirft einen Schwellenwert τc. Wenn die Anzahl der linken und rechten Befehle in einem Clip größer oder gleich dem Schwellenwert τc ist, betrachten wir dies als transzendentes Verhalten im Clip. Wenn nur die Anzahl der Linksbefehle größer als der Schwellenwert τc ist, deutet dies auf eine Linkskurve hin. Wenn nur die Anzahl der Rechtsbefehle größer als der Schwellenwert τc ist, deutet dies auf eine Rechtskurve hin. Alle anderen Fälle gelten als direkt. Drittens berechnen Sie die Durchschnittsgeschwindigkeit in jeder Szene und sortieren sie in aufsteigender Reihenfolge innerhalb der relevanten Teilmenge.
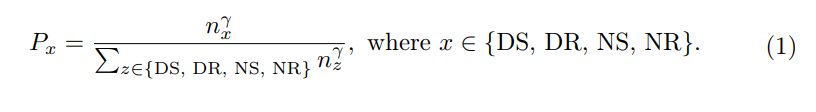
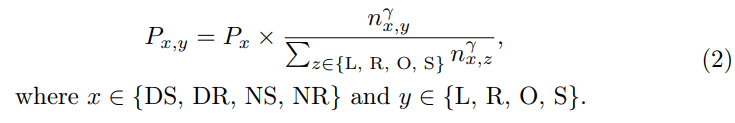
Abbildung 2 zeigt den detaillierten intuitiven Prozess des anfänglichen Auswahlprozesses basierend auf Mehrwegbäumen.
2) Kriteriendesign für die inkrementelle Auswahl
In diesem Abschnitt stellen wir vor, wie neue Teile eines Fragments basierend auf einem Modell, das mit bereits annotierten Fragmenten trainiert wurde, inkrementell annotiert werden. Wir werden das Zwischenmodell verwenden, um Rückschlüsse auf unbeschriftete Segmente zu ziehen, und nachfolgende Auswahlen basieren auf diesen Ausgaben. Dennoch wird eine planungsorientierte Perspektive eingenommen und drei Kriterien für die anschließende Datenauswahl eingeführt: Verschiebungsfehler, weiche Kollisionen und Proxy-Unsicherheiten.
Standard 1: Verschiebungsfehler (DE). wird als Abstand zwischen der vom Modell vorhergesagten geplanten Route τ und den im Datensatz aufgezeichneten menschlichen Flugbahnen τ* ausgedrückt.
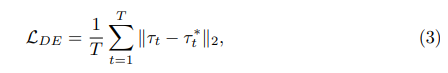
wobei T den Frame in der Szene darstellt. Da der Verschiebungsfehler selbst eine Leistungsmetrik ist (keine Anmerkung erforderlich), wird er natürlich zum ersten und kritischsten Kriterium bei der aktiven Auswahl.
Standard 2: Soft Collision (SC). LSC ist definiert als der Abstand zwischen der vorhergesagten Flugbahn des eigenen Fahrzeugs und der vorhergesagten Flugbahn des Agenten. Vorhersagen von Agenten mit geringem Vertrauen werden durch den Schwellenwert ε herausgefiltert. In jedem Szenario wird die kürzeste Entfernung als Maß für den Gefährdungskoeffizienten gewählt. Gleichzeitig bleibt eine positive Korrelation zwischen Begriff und kürzestem Abstand erhalten:
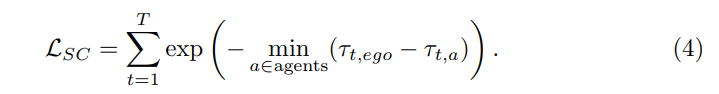
Verwenden Sie „weiche Kollision“ als Kriterium, weil: Einerseits ist die Berechnung des „Kollisionsverhältnisses“ im Gegensatz zum „Verschiebungsfehler“ davon abhängig auf der 3D des Ziels. Anmerkungen für Boxen, die in unbeschrifteten Daten nicht verfügbar sind. Daher sollte es möglich sein, das Kriterium ausschließlich auf der Grundlage der Inferenzergebnisse des Modells zu berechnen. Betrachten Sie andererseits ein hartes Kollisionskriterium: Wenn die vorhergesagte Flugbahn des eigenen Fahrzeugs mit den Flugbahnen anderer vorhergesagter Agenten kollidieren wird, weisen Sie ihr 1 zu, andernfalls weisen Sie ihr 0 zu. Dies kann jedoch zu zu wenigen Stichproben mit Label 1 führen, da die Kollisionsrate moderner Modelle in AD normalerweise gering ist (weniger als 1 %). Daher wurde beschlossen, anstelle der Metrik „Kollisionsrate“ die kürzeste Entfernung zu anderen Zielpaaren zu verwenden. Das Risiko wird als deutlich höher eingeschätzt, wenn der Abstand zu anderen Fahrzeugen oder Fußgängern zu gering ist. Kurz gesagt sind „weiche Kollisionen“ ein wirksames Maß für die Kollisionswahrscheinlichkeit und können eine intensive Überwachung ermöglichen.
Kriterium III: Agentenunsicherheit (AU). Vorhersagen über die zukünftigen Flugbahnen umgebender Agenten sind naturgemäß unsicher, daher generieren Bewegungsvorhersagemodule typischerweise mehrere Modalitäten und entsprechende Konfidenzwerte. Unser Ziel ist es, Daten auszuwählen, bei denen in der Nähe befindliche Agenten eine hohe Unsicherheit haben. Konkret werden entfernte Objekte durch einen Entfernungsschwellenwert δ herausgefiltert und die gewichtete Entropie der vorhergesagten Wahrscheinlichkeiten mehrerer Modi für die verbleibenden Objekte berechnet. Nehmen Sie an, dass die Anzahl der Modalitäten beträgt und der Konfidenzwert des Agenten in verschiedenen Modalitäten Pi(a) ist, wobei i∈{1,…,Nm}. Dann kann die Agentenunsicherheit definiert werden als:
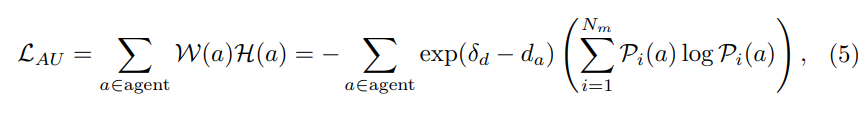
Gesamtverlust:
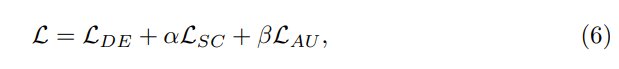
3) Gesamtes aktives Lernparadigma
Alg1 führt den gesamten Arbeitsablauf der Methode ein. Gegeben sei ein verfügbares Budget B, eine anfängliche Auswahlgröße n0, die Anzahl der in jedem Schritt getroffenen Aktivitätsauswahlen ni und insgesamt M Auswahlstufen. Die Auswahl wird zunächst mithilfe der oben beschriebenen Randomisierungs- oder Selbstdiversitätsmethoden initialisiert. Anschließend werden die aktuell annotierten Daten zum Trainieren des Netzwerks verwendet. Basierend auf dem trainierten Netzwerk treffen wir Vorhersagen zu den nicht gekennzeichneten Netzwerken und berechnen den Gesamtverlust. Abschließend werden die Samples nach dem Gesamtverlust sortiert und die Top-Ni-Samples ausgewählt, die in der aktuellen Iteration mit Anmerkungen versehen werden sollen. Dieser Vorgang wird wiederholt, bis die Iteration die Obergrenze M erreicht und die Anzahl der ausgewählten Stichproben die Obergrenze B erreicht.

Experimentelle Ergebnisse
Experimente wurden mit dem weit verbreiteten nuScenes-Datensatz durchgeführt. Alle Experimente werden mit PyTorch implementiert und auf RTX 3090- und A100-GPUs ausgeführt.
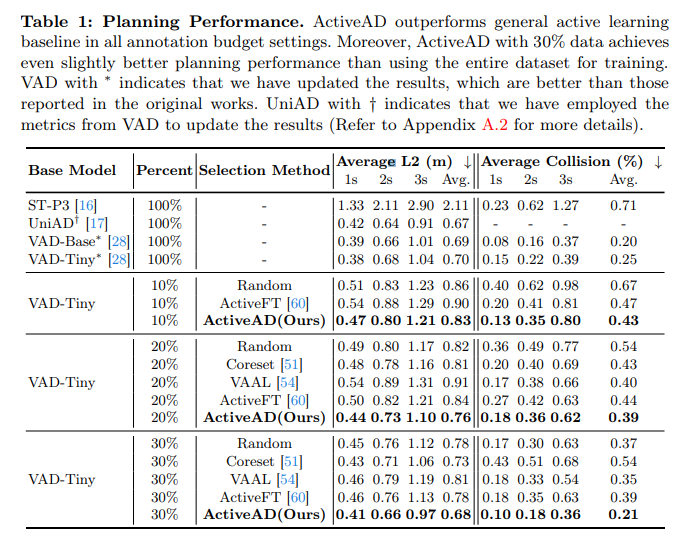
Tabelle 1: Planungsleistung. ActiveAD übertrifft die allgemeinen Basiswerte für aktives Lernen in allen Annotationsbudgeteinstellungen. Darüber hinaus erzielte ActiveAD mit 30 % der Daten eine etwas bessere Planungsleistung im Vergleich zum Training mit dem gesamten Datensatz. VADs mit * kennzeichnen aktualisierte Ergebnisse, die besser sind als die in der Originalarbeit berichteten. UniAD mit † zeigt an, dass die VAD-Indikatoren zur Aktualisierung der Ergebnisse verwendet wurden.
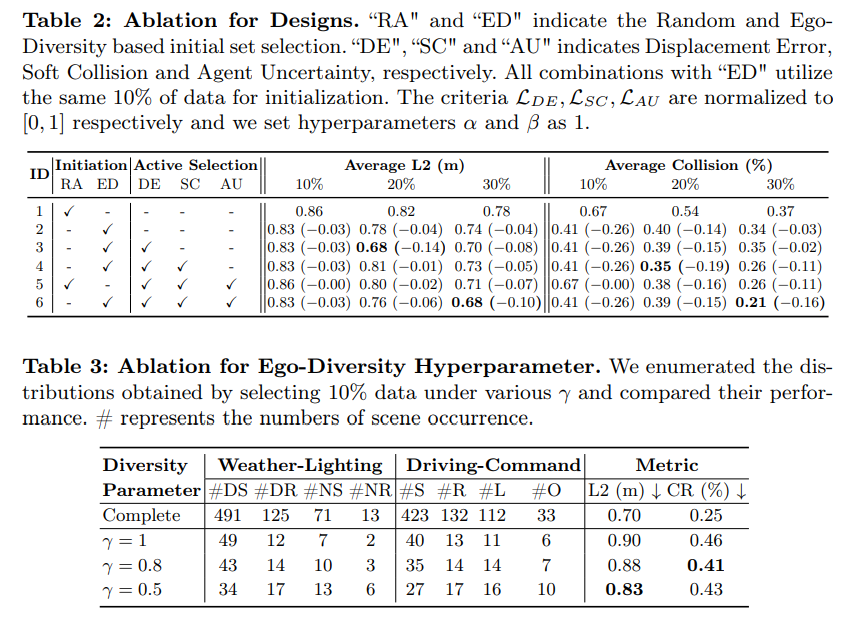
Tabelle 2: Konzipiertes Ablationsexperiment. „RA“ und „ED“ stellen die Auswahl des anfänglichen Satzes basierend auf Zufälligkeit und Selbstvielfalt dar. „DE“, „SC“ und „AU“ stellen Verschiebungsfehler dar, bei denen es sich um weiche Kollisionen bzw. Agentenunsicherheiten handelt. Alle Kombinationen mit „ED“ werden mit den gleichen 10 %-Daten initialisiert. LDE, LSC und LAU werden jeweils auf [0, 1] normalisiert und die Hyperparameter α und β werden auf 1 gesetzt.
Abbildung 3: Visualisierung ausgewählter Szenen. Verschiebungsfehler (Spalte 1), weiche Kollision (Spalte 2), Agentenunsicherheit (Spalte 3) und Hybridkriterien (Spalte 4) basierend auf ausgewählten Frontkamerabildern basierend auf einem Modell, das auf 10 % der Daten trainiert wurde. Mixed stellt unsere endgültige Auswahlstrategie, ActiveAD, dar und berücksichtigt die ersten drei Szenarien!

Tabelle 4, Leistung in verschiedenen Szenarien. Je kleiner die durchschnittliche L2(m)/durchschnittliche Kollisionsrate (%) des aktiven Modells ist, das 30 % der Daten verwendet, desto besser ist die Leistung unter verschiedenen Wetter-/Licht- und Fahrbefehlsbedingungen.
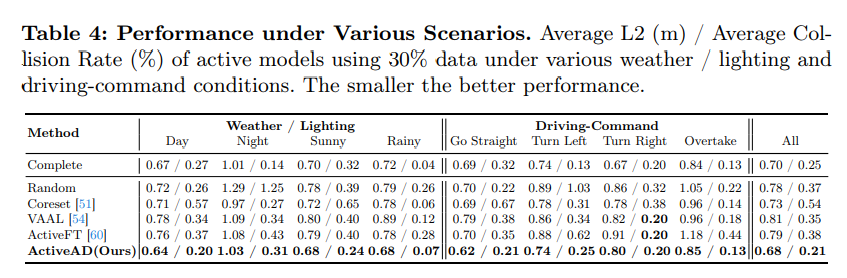
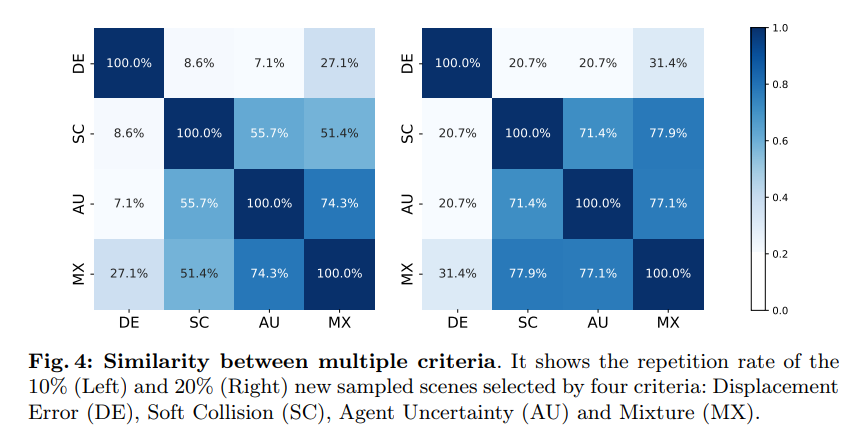
Abbildung 4: Ähnlichkeit zwischen mehreren Kriterien. Es zeigt das neue Stichprobenszenario mit 10 % (links) und 20 % (rechts), ausgewählt nach vier Kriterien: Verschiebungsfehler (DE), weiche Kollision (SC), Agentenunsicherheit (AU) und Mischung (MX)
Einige Schlussfolgerungen dieser Arbeit
Um die hohen Kosten und Langzeitprobleme der End-to-End-Annotation von autonomen Fahrdaten zu lösen, haben wir die Führung bei der Entwicklung einer maßgeschneiderten Lösung für aktives Lernen übernommen, ActiveAD. ActiveAD führt neue aufgabenspezifische Diversitäts- und Unsicherheitsmaße ein, die auf einer planungsorientierten Philosophie basieren. Eine Vielzahl von Experimenten belegt die Wirksamkeit der Methode. Mit nur 30 % der Daten übertrifft sie die allgemeinen bisherigen Methoden deutlich und erreicht eine mit den modernen Modellen vergleichbare Leistung. Dies stellt eine sinnvolle Untersuchung des durchgängigen autonomen Fahrens aus einer datenzentrierten Perspektive dar und wir hoffen, dass unsere Arbeit zukünftige Forschung und Entdeckungen inspirieren kann.
Das obige ist der detaillierte Inhalt vonWas tun, wenn keine End-to-End-Daten vorhanden sind? ActiveAD: Durchgängiges autonomes Fahren, aktives Lernen für die Planung!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Der erste Pilot- und Schlüsselartikel stellt hauptsächlich mehrere häufig verwendete Koordinatensysteme in der autonomen Fahrtechnologie vor und erläutert, wie die Korrelation und Konvertierung zwischen ihnen abgeschlossen und schließlich ein einheitliches Umgebungsmodell erstellt werden kann. Der Schwerpunkt liegt hier auf dem Verständnis der Umrechnung vom Fahrzeug in den starren Kamerakörper (externe Parameter), der Kamera-in-Bild-Konvertierung (interne Parameter) und der Bild-in-Pixel-Einheitenkonvertierung. Die Konvertierung von 3D in 2D führt zu entsprechenden Verzerrungen, Verschiebungen usw. Wichtige Punkte: Das Fahrzeugkoordinatensystem und das Kamerakörperkoordinatensystem müssen neu geschrieben werden: Das Ebenenkoordinatensystem und das Pixelkoordinatensystem. Schwierigkeit: Sowohl die Entzerrung als auch die Verzerrungsaddition müssen auf der Bildebene kompensiert werden. 2. Einführung Insgesamt gibt es vier visuelle Systeme Koordinatensystem: Pixelebenenkoordinatensystem (u, v), Bildkoordinatensystem (x, y), Kamerakoordinatensystem () und Weltkoordinatensystem (). Es gibt eine Beziehung zwischen jedem Koordinatensystem,
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
