
 Technologie-Peripheriegeräte
KI
Neues Werk von Yan Shuicheng/Cheng Mingming! DiT-Training, die Kernkomponente von Sora, wird um das Zehnfache beschleunigt und Masked Diffusion Transformer V2 ist Open Source
Technologie-Peripheriegeräte
KI
Neues Werk von Yan Shuicheng/Cheng Mingming! DiT-Training, die Kernkomponente von Sora, wird um das Zehnfache beschleunigt und Masked Diffusion Transformer V2 ist Open Source
Neues Werk von Yan Shuicheng/Cheng Mingming! DiT-Training, die Kernkomponente von Sora, wird um das Zehnfache beschleunigt und Masked Diffusion Transformer V2 ist Open Source

Als eine der überzeugenden Kerntechnologien von Sora nutzt DiT Diffusion Transformer, um das generative Modell auf einen größeren Maßstab zu skalieren und so herausragende Bilderzeugungseffekte zu erzielen.
Größere Modellgrößen führen jedoch dazu, dass die Schulungskosten in die Höhe schnellen.
Das Forschungsteam von Yan Shuicheng und Cheng Mingming vom Sea AI Lab der Nankai University und dem Kunlun Wanwei 2050 Research Institute schlug auf der ICCV 2023-Konferenz ein neues Modell namens Masked Diffusion Transformer vor. Dieses Modell verwendet die Maskenmodellierungstechnologie, um das Training des Diffusion Transformers durch das Erlernen semantischer Darstellungsinformationen zu beschleunigen und SoTA-Ergebnisse im Bereich der Bilderzeugung zu erzielen. Diese Innovation bringt neue Durchbrüche bei der Entwicklung von Bilderzeugungsmodellen und bietet Forschern eine effizientere Trainingsmethode. Durch die Kombination von Fachwissen und Technologie aus verschiedenen Bereichen schlug das Forschungsteam erfolgreich eine Lösung vor, die die Trainingsgeschwindigkeit erhöht und die Generierungsergebnisse verbessert. Ihre Arbeit hat wichtige innovative Ideen zur Entwicklung des Bereichs der künstlichen Intelligenz beigetragen und nützliche Inspiration für zukünftige Forschung und Praxis geliefert , Masked Diffusion Transformer V2 hat SoTA erneut aktualisiert, die Trainingsgeschwindigkeit im Vergleich zu DiT um mehr als das Zehnfache erhöht und den ImageNet-Benchmark-Score von 1,58 erreicht.
Die neueste Version des Papiers und des Codes sind Open Source. 
Zum Beispiel hat DiT, wie im Bild oben gezeigt, gelernt, beim 50. k-ten Trainingsschritt die Haartextur eines Hundes zu erzeugen, und dann beim 200. k-ten Trainingsschritt gelernt, eines der Augen des Hundes zu erzeugen Trainingsschritt und Mund, aber ein weiteres Auge fehlte.
Selbst beim 300-km-Trainingsschritt ist die durch DiT erzeugte relative Position der beiden Ohren des Hundes nicht sehr genau.
Dieser Trainings- und Lernprozess zeigt, dass das Diffusionsmodell die semantische Beziehung zwischen verschiedenen Teilen des Objekts im Bild nicht effizient lernen kann, sondern nur die semantischen Informationen jedes Objekts unabhängig lernt. 
Wie in der Abbildung oben gezeigt, führt MDT eine Lernstrategie für die Maskenmodellierung ein und behält gleichzeitig den Diffusionstrainingsprozess bei. Durch die Maskierung des verrauschten Bildtokens verwendet MDT eine asymmetrische Diffusionstransformator-Architektur (Asymmetric Diffusion Transformer), um das maskierte Bildtoken aus dem nicht maskierten verrauschten Bildtoken vorherzusagen und so gleichzeitig die Prozesse der Maskenmodellierung und des Diffusionstrainings zu erreichen.
Während des Inferenzprozesses behält MDT weiterhin den Standardprozess der Diffusionsgenerierung bei. Das Design von MDT hilft Diffusion Transformer dabei, sowohl die Fähigkeit zum Ausdruck semantischer Informationen zu nutzen, die durch das Lernen der Maskenmodellierungsdarstellung entsteht, als auch die Fähigkeit des Diffusionsmodells, Bilddetails zu generieren.
Konkret ordnet MDT Bilder über den VAE-Encoder dem latenten Raum zu und verarbeitet sie im latenten Raum, um Rechenkosten zu sparen.
Während des Trainingsprozesses maskiert MDT zunächst einen Teil der Bild-Tokens, nachdem Rauschen hinzugefügt wurde, und sendet die verbleibenden Tokens an den Asymmetric Diffusion Transformer, um nach dem Entrauschen alle Bild-Tokens vorherzusagen.
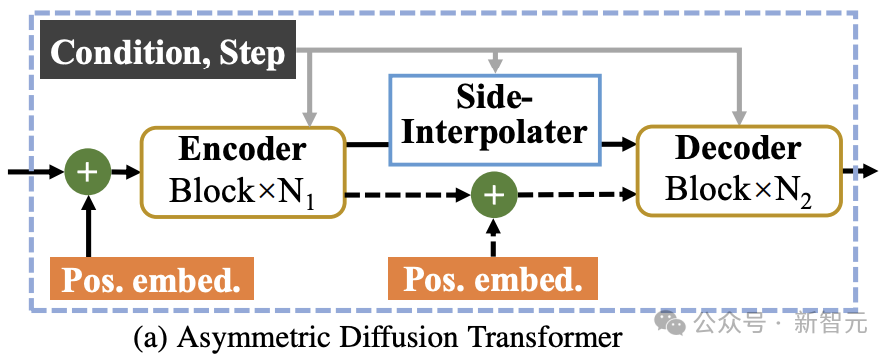
Asymmetric Diffusion Transformer-Architektur
 Bild
Bild
Wie in der Abbildung oben gezeigt, umfasst die Asymmetric Diffusion Transformer-Architektur einen Encoder, einen Seiteninterpolator (Hilfsinterpolator) und einen Decoder.
 Bilder
Bilder
Während des Trainingsprozesses verarbeitet der Encoder nur Token, die nicht maskiert sind; während des Inferenzprozesses verarbeitet er alle Token, da es keinen Maskierungsschritt gibt.
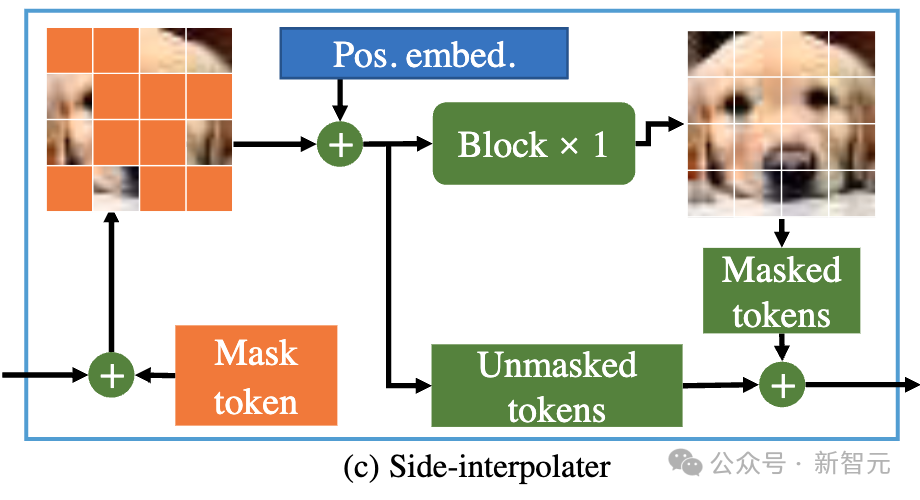
Um sicherzustellen, dass der Decoder während der Trainings- oder Inferenzphase immer alle Token verarbeiten kann, schlugen die Forscher daher eine Lösung vor: während des Trainingsprozesses durch einen Hilfsinterpolator, der aus DiT-Blöcken besteht (wie in der Abbildung dargestellt). oben), interpolieren und prognostizieren das maskierte Token aus der Ausgabe des Encoders und entfernen es während der Inferenzphase, ohne einen Inferenz-Overhead hinzuzufügen.
MDTs Encoder und Decoder fügen globale und lokale Positionscodierungsinformationen in den Standard-DiT-Block ein, um die Vorhersage des Tokens im Maskenteil zu erleichtern. Asymmetric Diffusion Transformer V2 Prozess der Modellierung.
Dazu gehört die Integration einer langen Verknüpfung im U-Net-Stil in den Encoder und einer dichten Eingabeverknüpfung in den Decoder.
Unter diesen sendet die dichte Eingabeverknüpfung das maskierte Token, nachdem Rauschen an den Decoder hinzugefügt wurde, wobei die dem maskierten Token entsprechenden Rauschinformationen beibehalten werden, wodurch das Training des Diffusionsprozesses erleichtert wird. 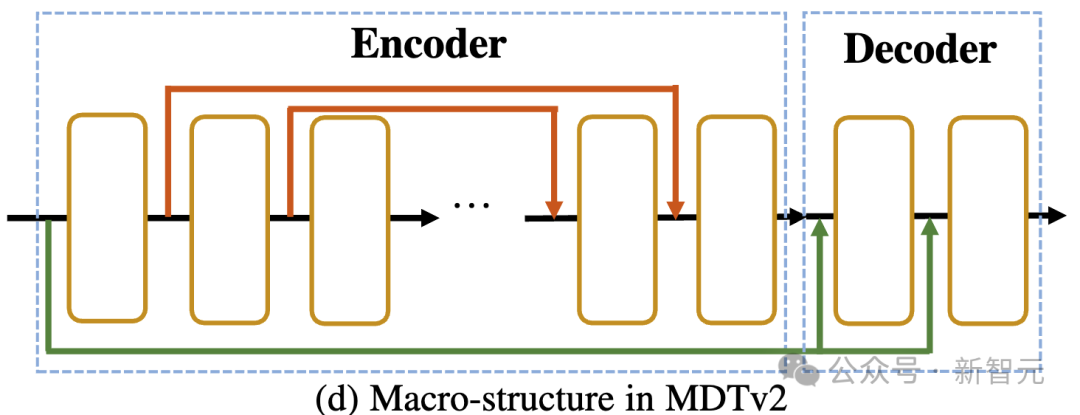
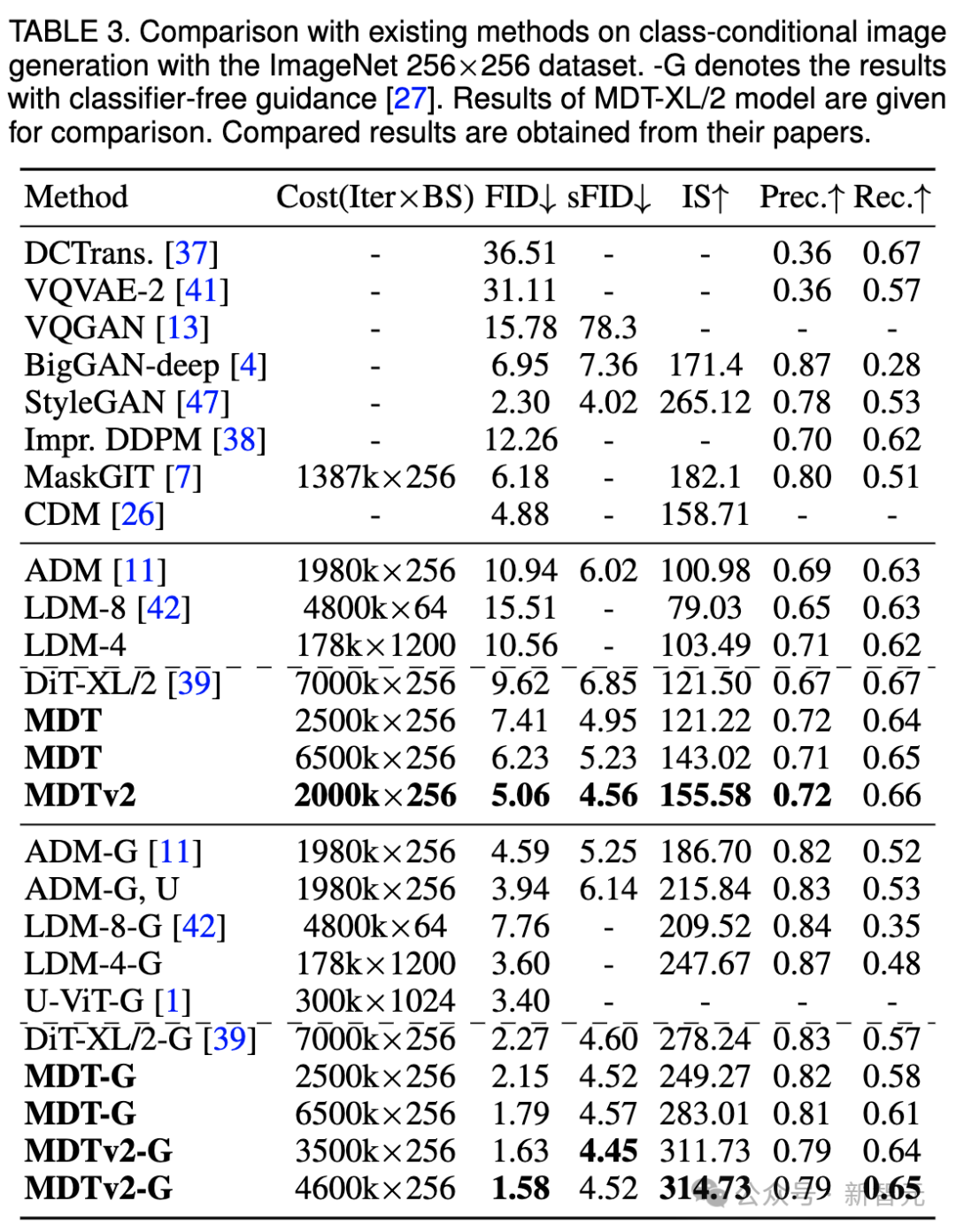
Die obige Tabelle vergleicht die Leistung von MDT und DiT unter dem ImageNet 256-Benchmark bei verschiedenen Modellgrößen.
Es ist offensichtlich, dass MDT bei allen Modellgrößen höhere FID-Werte mit weniger Schulungskosten erzielt.
Die Parameter und Inferenzkosten von MDT sind grundsätzlich die gleichen wie bei DiT, da, wie oben erwähnt, der mit DiT konsistente Standarddiffusionsprozess im MDT-Inferenzprozess weiterhin beibehalten wird. 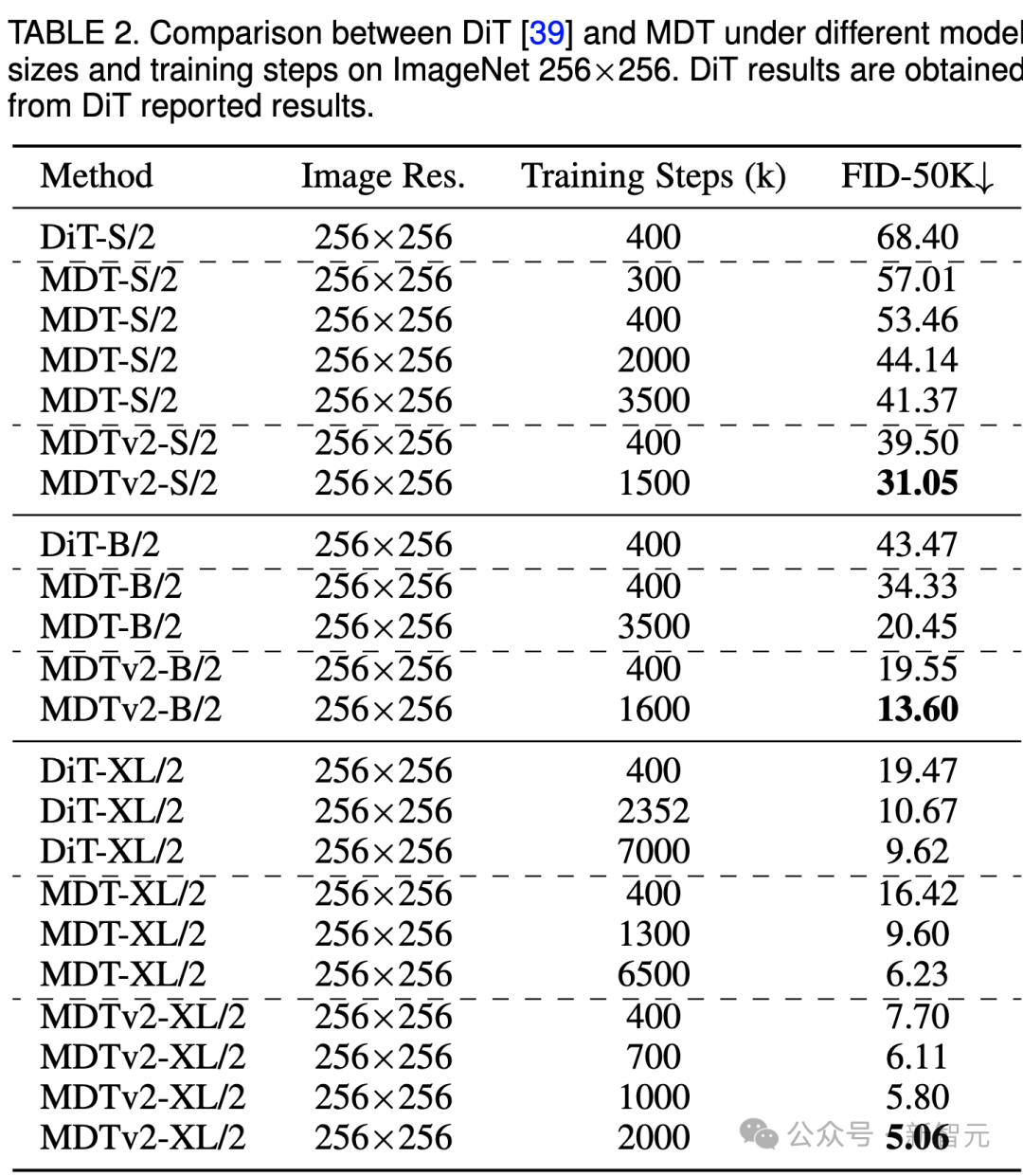
Bei kleinen Modellen erreicht MDTv2-S/2 immer noch eine deutlich bessere Leistung als DiT-S/2 mit deutlich weniger Trainingsschritten. Beispielsweise hat MDTv2 bei gleichem Training mit 400.000 Schritten einen FID-Index von 39,50, was deutlich über dem FID-Index von DiT von 68,40 liegt.
Noch wichtiger ist, dass dieses Ergebnis auch die Leistung des größeren Modells DiT-B/2 bei 400.000 Trainingsschritten übertrifft (39,50 vs. 43,47).
ImageNet 256 Benchmark-CFG-Generierungsqualitätsvergleich
 Bilder
Bilder
In der obigen Tabelle haben wir auch die Bildgenerierungsleistung von MDT mit vorhandenen Methoden unter klassifikatorfreier Anleitung verglichen.
MDT übertrifft frühere SOTA DiT und andere Methoden mit einem FID-Score von 1,79. MDTv2 verbessert die Leistung weiter und treibt den SOTA-FID-Score für die Bilderzeugung mit weniger Trainingsschritten auf einen neuen Tiefstwert von 1,58.
Ähnlich wie bei DiT beobachteten wir während des Trainings keine Sättigung des FID-Scores des Modells, während wir mit dem Training fortfuhren.
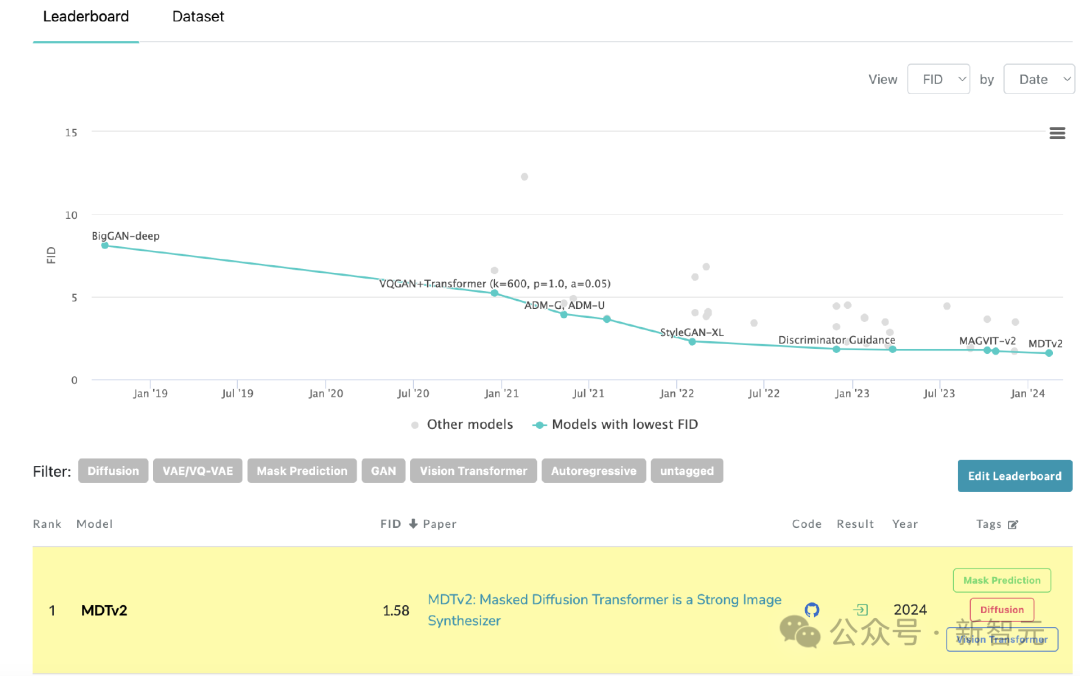 MDT aktualisiert SoTA auf der Rangliste von PaperWithCode
MDT aktualisiert SoTA auf der Rangliste von PaperWithCode
Konvergenzgeschwindigkeitsvergleich
 Bild
Bild
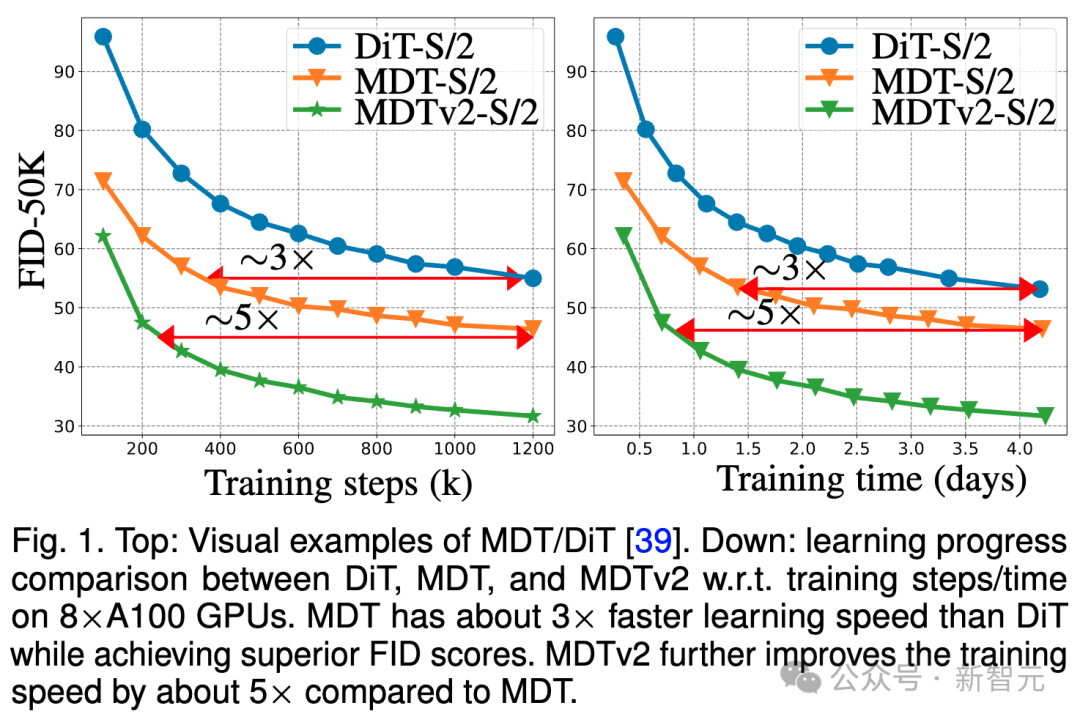
Das obige Bild vergleicht 8×A100 unter dem ImageNet 6 Benchmark DiT-S/ auf GPU 2 FID Leistung von Baseline, MDT-S/2 und MDTv2-S/2 unter verschiedenen Trainingsschritten/Trainingszeiten.
Dank besserer kontextbezogener Lernfähigkeiten übertrifft MDT DiT sowohl in der Leistung als auch in der Generierungsgeschwindigkeit. Die Trainingskonvergenzgeschwindigkeit von MDTv2 ist mehr als zehnmal höher als die von DiT.
MDT ist in Bezug auf Trainingsschritte und Trainingszeit etwa dreimal schneller als DiT. MDTv2 verbessert die Trainingsgeschwindigkeit im Vergleich zu MDT um etwa das Fünffache.
Zum Beispiel zeigt MDTv2-S/2 in nur 13 Stunden (15.000 Schritte) eine bessere Leistung als DiT-S/2, dessen Training etwa 100 Stunden (1.500.000 Schritte) dauert, was zeigt, dass das Lernen der kontextuellen Darstellung wichtig ist Ein schnelleres generatives Lernen von Diffusionsmodellen ist von entscheidender Bedeutung.
Zusammenfassung und Diskussion
MDT führt im Diffusionstrainingsprozess ein MAE-ähnliches Lernschema für die Maskenmodellierungsdarstellung ein, das die Kontextinformationen von Bildobjekten verwenden kann, um die vollständigen Informationen des unvollständigen Eingabebilds zu rekonstruieren und so zu lernen Die Semantik im Bild Die Korrelation zwischen Teilen, wodurch die Qualität der Bilderzeugung und die Lerngeschwindigkeit verbessert werden.
Forscher glauben, dass die Verbesserung des semantischen Verständnisses der physischen Welt durch das Lernen visueller Repräsentationen den Simulationseffekt des generativen Modells auf die physische Welt verbessern kann. Dies deckt sich mit Soras Vision, durch generative Modelle einen physischen Weltsimulator zu bauen. Hoffentlich wird diese Arbeit weitere Arbeiten zur Vereinheitlichung von Repräsentationslernen und generativem Lernen inspirieren.
Referenz:
https://arxiv.org/abs/2303.14389
Das obige ist der detaillierte Inhalt vonNeues Werk von Yan Shuicheng/Cheng Mingming! DiT-Training, die Kernkomponente von Sora, wird um das Zehnfache beschleunigt und Masked Diffusion Transformer V2 ist Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Einführung in die Verwendung des Joiplay-Simulators
May 04, 2024 pm 06:40 PM
Einführung in die Verwendung des Joiplay-Simulators
May 04, 2024 pm 06:40 PM
Der Jojplay-Simulator ist ein sehr einfach zu bedienender Mobiltelefonsimulator. Er unterstützt Computerspiele und kann auf Mobiltelefonen ausgeführt werden. Einige Spieler wissen nicht, wie man ihn verwendet wie man es benutzt. So verwenden Sie den Joiplay-Simulator 1. Zuerst müssen Sie den Joiplay-Body und das RPGM-Plug-in herunterladen. Am besten installieren Sie sie in der Reihenfolge Body – Plug-in. Das APK-Paket erhalten Sie in der Joiplay-Leiste. Klicken Sie hier, um >>> zu erhalten. 2. Nachdem Android fertig ist, können Sie in der unteren linken Ecke Spiele hinzufügen. 3. Geben Sie den Namen nach und nach ein und drücken Sie bei der ausführbaren Datei auf „Auswählen“, um die Datei „game.exe“ des Spiels auszuwählen. 4. Das Symbol kann leer bleiben oder Sie können Ihr Lieblingsbild auswählen.
 So aktivieren Sie VT auf dem MSI-Motherboard
May 01, 2024 am 09:28 AM
So aktivieren Sie VT auf dem MSI-Motherboard
May 01, 2024 am 09:28 AM
Wie aktiviere ich VT auf einem MSI-Motherboard? Welche Methoden gibt es? Diese Seite hat die MSI-Motherboard-VT-Aktivierungsmethoden für die Mehrheit der Benutzer sorgfältig zusammengestellt. Willkommen zum Lesen und Teilen! Der erste Schritt besteht darin, den Computer neu zu starten und das BIOS aufzurufen. Was soll ich tun, wenn die Startgeschwindigkeit zu hoch ist und ich das BIOS nicht aufrufen kann? Nachdem der Bildschirm aufleuchtet, drücken Sie weiter „Entf“, um die BIOS-Seite aufzurufen. Der zweite Schritt besteht darin, die VT-Option im Menü zu finden und zu aktivieren. Verschiedene Computermodelle haben unterschiedliche BIOS-Schnittstellen und unterschiedliche Namen für VT : 1. Geben Sie ein. Nachdem Sie die BIOS-Seite aufgerufen haben, suchen Sie die Option „OC (oder Übertaktung)“ – „CPU-Funktionen“ – „SVMMode (oder Intel Virtualization Technology)“ und ändern Sie die Option „Deaktiviert“.
 So aktivieren Sie VT auf dem ASRock-Motherboard
May 01, 2024 am 08:49 AM
So aktivieren Sie VT auf dem ASRock-Motherboard
May 01, 2024 am 08:49 AM
Wie aktiviert man VT auf dem ASRock-Motherboard, welche Methoden gibt es und wie wird es bedient? Diese Website hat die ASRock-Motherboard-VT-Aktivierungsmethode zusammengestellt, damit Benutzer sie lesen und teilen können! Der erste Schritt besteht darin, den Computer neu zu starten. Drücken Sie weiterhin die Taste „F2“, um die BIOS-Seite aufzurufen. Was soll ich tun, wenn die Startgeschwindigkeit zu hoch ist und ich das BIOS nicht aufrufen kann? Der zweite Schritt besteht darin, die VT-Option im Menü zu finden und zu aktivieren. Verschiedene Motherboard-Modelle haben unterschiedliche BIOS-Schnittstellen und unterschiedliche Namen für VT 1. Suchen Sie nach dem Aufrufen der BIOS-Seite nach „Erweitert“ – „CPU-Konfiguration“. (CPU-Konfiguration)“ – Option „SVMMOD (Virtualisierungstechnologie)“, ändern Sie „Deaktiviert“ in „Aktiviert“.
 Empfohlener Android-Emulator, der flüssiger ist (wählen Sie den Android-Emulator, den Sie verwenden möchten)
Apr 21, 2024 pm 06:01 PM
Empfohlener Android-Emulator, der flüssiger ist (wählen Sie den Android-Emulator, den Sie verwenden möchten)
Apr 21, 2024 pm 06:01 PM
Es kann Benutzern ein besseres Spiel- und Nutzungserlebnis bieten. Ein Android-Emulator ist eine Software, die die Ausführung des Android-Systems auf einem Computer simulieren kann. Es gibt viele Arten von Android-Emulatoren auf dem Markt, deren Qualität jedoch unterschiedlich ist. Um den Lesern bei der Auswahl des für sie am besten geeigneten Emulators zu helfen, konzentriert sich dieser Artikel auf einige reibungslose und benutzerfreundliche Android-Emulatoren. 1. BlueStacks: Hohe Laufgeschwindigkeit und ein reibungsloses Benutzererlebnis. BlueStacks ist ein beliebter Android-Emulator. Es ermöglicht Benutzern das Spielen einer Vielzahl mobiler Spiele und Anwendungen und kann Android-Systeme auf Computern mit extrem hoher Leistung simulieren. 2. NoxPlayer: Unterstützt mehrere Eröffnungen und macht das Spielen angenehmer. Sie können verschiedene Spiele in mehreren Emulatoren gleichzeitig ausführen
 So installieren Sie das Windows-System auf einem Tablet-Computer
May 03, 2024 pm 01:04 PM
So installieren Sie das Windows-System auf einem Tablet-Computer
May 03, 2024 pm 01:04 PM
Wie flasht man das Windows-System auf einem BBK-Tablet? Die erste Möglichkeit besteht darin, das System auf der Festplatte zu installieren. Solange das Computersystem nicht abstürzt, können Sie das System betreten und Dinge herunterladen. Sie können die Festplatte des Computers verwenden, um das System zu installieren. Die Methode ist wie folgt: Abhängig von Ihrer Computerkonfiguration können Sie das Betriebssystem WIN7 installieren. Wir haben uns entschieden, das Ein-Klick-Neuinstallationssystem von Xiaobai in vivopad herunterzuladen, um es zu installieren. Wählen Sie zunächst die für Ihren Computer geeignete Systemversion aus und klicken Sie auf „Dieses System installieren“, um zum nächsten Schritt zu gelangen. Dann warten wir geduldig darauf, dass die Installationsressourcen heruntergeladen werden, und warten dann darauf, dass die Umgebung bereitgestellt und neu gestartet wird. Die Schritte zum Installieren von Win11 auf dem Vivopad sind: Überprüfen Sie zunächst mithilfe der Software, ob Win11 installiert werden kann. Geben Sie nach bestandener Systemerkennung die Systemeinstellungen ein. Wählen Sie dort die Option Update & Sicherheit. Klicken
 Leitfaden für den Lebensneustart-Simulator
May 07, 2024 pm 05:28 PM
Leitfaden für den Lebensneustart-Simulator
May 07, 2024 pm 05:28 PM
Life Restart Simulator ist ein sehr interessantes Simulationsspiel. Es gibt viele Möglichkeiten, das Spiel zu spielen. Schauen Sie sich das Spiel an Strategien gibt es? Life Restart Simulator-Anleitung Anleitung Funktionen von Life Restart Simulator Dies ist ein sehr kreatives Spiel, in dem Spieler nach ihren eigenen Vorstellungen spielen können. Es gibt jeden Tag viele Aufgaben zu erledigen und Sie können ein neues Leben in dieser virtuellen Welt genießen. Es gibt viele Lieder im Spiel und alle möglichen Leben warten darauf, von Ihnen erlebt zu werden. Spielinhalt des Life Restart Simulators Talent-Zeichnungskarten: Talent: Sie müssen die geheimnisvolle kleine Kiste auswählen, um ein Unsterblicher zu werden. Um ein Absterben auf halbem Weg zu vermeiden, sind verschiedene kleine Kapseln erhältlich. Cthulhu kann wählen
 So packen Sie Pycharm in APK
Apr 18, 2024 am 05:57 AM
So packen Sie Pycharm in APK
Apr 18, 2024 am 05:57 AM
Wie packe ich eine Android-App mit PyCharm als APK? Stellen Sie sicher, dass das Projekt mit einem Android-Gerät oder Emulator verbunden ist. Build-Typ konfigurieren: Fügen Sie einen Build-Typ hinzu und aktivieren Sie „Signierte APK generieren“. Klicken Sie in der Build-Symbolleiste auf „APK erstellen“, wählen Sie Ihren Build-Typ aus und beginnen Sie mit dem Erstellen.
 Einführung in die Schriftarteinstellungsmethode des Joiplay-Simulators
May 09, 2024 am 08:31 AM
Einführung in die Schriftarteinstellungsmethode des Joiplay-Simulators
May 09, 2024 am 08:31 AM
Der Jojplay-Simulator kann die Schriftarten des Spiels tatsächlich anpassen und das Problem fehlender Zeichen und umrahmter Zeichen im Text lösen. Ich vermute, dass viele Spieler immer noch nicht wissen, wie man ihn bedient Schriftart des Jojplay-Simulators vorstellen. So legen Sie die Schriftart des Joiplay-Simulators fest: 1. Öffnen Sie zunächst den Joiplay-Simulator, klicken Sie auf die Einstellungen (drei Punkte) in der oberen rechten Ecke und suchen Sie ihn. 2. Klicken Sie in der Spalte „RPGMSettings“ auf die benutzerdefinierte Schriftart „CustomFont“ in der dritten Zeile, um sie auszuwählen. 3. Wählen Sie die Schriftartdatei aus und klicken Sie auf „OK“. Klicken Sie nicht auf das Symbol „Speichern“ in der unteren rechten Ecke, da sonst die Standardeinstellungen wiederhergestellt werden. 4. Empfehlen Sie Founder und Quasi-Yuan Simplified Chinese (bereits in den Ordnern der Spiele Fuxing und Rebirth). joi
