


Meta hat kürzlich zwei leistungsstarke GPU-Cluster auf den Markt gebracht, um das Training generativer KI-Modelle der nächsten Generation zu unterstützen, einschließlich des kommenden Llama 3.
Beide Rechenzentren sind Berichten zufolge mit bis zu 24.576 GPUs ausgestattet, die darauf ausgelegt sind, größere und komplexere generative KI-Modelle als zuvor veröffentlicht zu unterstützen.
Als beliebtes Open-Source-Algorithmusmodell ist Metas Llama mit OpenAIs GPT und Googles Gemini vergleichbar.
Laut Geek.com sind diese beiden GPU-Cluster mit der leistungsstärksten H100-GPU von NVIDIA ausgestattet, die viel größer ist als die zuvor von Meta eingeführten großen Cluster. Zuvor verfügte Metas Cluster über etwa 16.000 Nvidia A100-GPUs.
Es wird berichtet, dass Meta Tausende der neuesten GPUs von Nvidia gekauft hat. Das Marktforschungsunternehmen Omdia wies in seinem jüngsten Bericht darauf hin, dass Meta zu einem der wichtigsten Kunden von Nvidia geworden sei.
Meta-Ingenieure gaben bekannt, dass sie planen, neue GPU-Cluster zur Feinabstimmung bestehender KI-Systeme zu verwenden, um neuere und leistungsstärkere KI-Systeme, einschließlich Llama 3, zu trainieren.
Der Ingenieur wies darauf hin, dass die Entwicklung von Llama 3 derzeit „in Arbeit“ sei, gab jedoch nicht bekannt, wann es veröffentlicht wird.
Metas langfristiges Ziel ist die Entwicklung allgemeiner künstlicher Intelligenz (AGI)-Systeme, da AGI in puncto Kreativität näher am Menschen ist und sich deutlich von bestehenden generativen KI-Modellen unterscheidet.
Der neue GPU-Cluster wird Meta dabei helfen, diese Ziele zu erreichen. Darüber hinaus verbessert das Unternehmen das PyTorch-KI-Framework, um mehr GPUs zu unterstützen.
Es ist erwähnenswert, dass die beiden Cluster zwar genau die gleiche Anzahl an GPUs haben und sich mit Endpunkten mit 400 GB pro Sekunde verbinden können, aber unterschiedliche Architekturen verwenden.
Unter anderem kann ein GPU-Cluster über eine konvergente Ethernet-Netzwerkstruktur, die mit Arista 7800 von Arista Networks mit Wedge400 und Minipack2 OCP-Rack-Switches erstellt wurde, aus der Ferne auf Direktspeicher oder RDMA zugreifen. Ein weiterer GPU-Cluster basiert auf Nvidias Quantum2 InfiniBand-Netzwerk-Fabric-Technologie.
Beide Cluster nutzen Grand Teton, die offene GPU-Hardwareplattform von Meta, die für die Unterstützung umfangreicher KI-Workloads konzipiert ist. Grand Teton bietet die vierfache Host-zu-GPU-Bandbreite seines Vorgängers, der Zion-EX-Plattform, und die doppelte Rechenleistung, Bandbreite und Leistung von Zion-EX.
Meta sagte, dass diese beiden Cluster die neueste offene Rack-Stromversorgung und Rack-Infrastruktur nutzen, um eine größere Flexibilität beim Design von Rechenzentren zu bieten. Open Rack v3 ermöglicht die Montage von Power Racks an einer beliebigen Stelle im Rack, anstatt sie an Stromschienen zu befestigen, was flexiblere Konfigurationen ermöglicht.
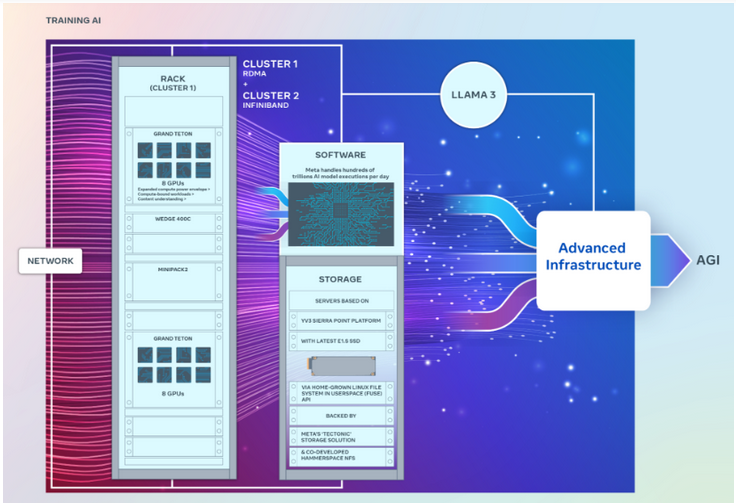
Darüber hinaus ist auch die Anzahl der Server pro Rack anpassbar, was eine effizientere Balance hinsichtlich der Durchsatzkapazität jedes Servers ermöglicht.
In Bezug auf den Speicher basieren diese beiden GPU-Cluster auf der YV3 Sierra Point-Serverplattform und verwenden die fortschrittlichsten E1.S-Solid-State-Laufwerke.
Meta-Ingenieure betonten in dem Artikel, dass sich das Unternehmen für offene Innovationen des KI-Hardware-Stacks einsetzt. „Wenn wir in die Zukunft blicken, erkennen wir, dass das, was zuvor oder jetzt funktioniert hat, möglicherweise nicht ausreicht, um zukünftige Anforderungen zu erfüllen. Deshalb evaluieren und verbessern wir ständig unsere Infrastruktur.
Meta ist Mitglied der kürzlich gegründeten AI Alliance . Ziel der Allianz ist es, ein offenes Ökosystem zu schaffen, das die Transparenz und das Vertrauen in die KI-Entwicklung erhöht und sicherstellt, dass alle von seinen Innovationen profitieren.
Meta gab außerdem bekannt, dass es weiterhin weitere Nvidia H100-GPUs kaufen wird und plant, bis Ende dieses Jahres über mehr als 350.000 GPUs zu verfügen. Diese GPUs werden für den weiteren Aufbau der KI-Infrastruktur verwendet, was bedeutet, dass in Zukunft immer leistungsfähigere GPU-Cluster verfügbar sein werden.
Das obige ist der detaillierte Inhalt vonMeta hat zwei neue 10.000-Karten-Cluster hinzugefügt und fast 50.000 Nvidia H100-GPUs investiert.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



