

Der vom großen OpenAI-Modell angetriebene Roboter kommt spät in der Nacht!
Der Name ist Figur 01, sie kann zuhören, sprechen und sich flexibel bewegen.

Beschreiben Sie alles, was Sie vor sich sehen:
Ich sah einen roten Apfel auf dem Tisch, und auf dem Abtropfgestell standen mehrere Teller und eine Tasse; Sie standen mit Ihren Händen daneben Legen Sie es vorsichtig auf den Tisch.
 Bilder
Bilder
Wenn der Mensch sagt „Ich möchte essen“, gebe ich sofort den Apfel ab.
 Bilder
Bilder
Und ich habe eine klare Vorstellung davon, was ich tue. Ich habe den Apfel gegeben, weil er das einzige Essbare auf dem Tisch ist.
Es organisiert nebenbei auch Dinge und kann zwei Aufgaben gleichzeitig erledigen.
 Bilder
Bilder
Das Wichtigste ist, dass diese Demonstrationen nicht beschleunigt werden, die ursprünglichen Bewegungen des Roboters sind so schnell.
(Niemand sitzt am Steuer)

Jetzt konnten die Internetnutzer nicht still sitzen und sofort @Boston Dynamics:
Alte Leute, dieser Typ ist wirklich aufgeregt. Wir müssen zurück ins Labor und den alten Roboter (Boston Dynamics) noch ein bisschen tanzen lassen.
 Bilder
Bilder
Es gibt auch Internetnutzer, die zusahen, wie OpenAI das große Sprachmodell und Vincents Video herausbrachte, und dann den Roboter schnüffelten und mit Emotionen sagten:
Das ist ein harter Wettbewerb; durch die Zusammenarbeit mit OpenAI könnte Apple Tesla-Pull übertreffen.
Aber von der Hardware her sieht Optimus Prime schöner aus, Abbildung 01 bedarf noch einer „Schönheits-OP“. (Doge)
 Bilder
Bilder
Als nächstes schauen wir uns weiter die Details von Abbildung 01 an.
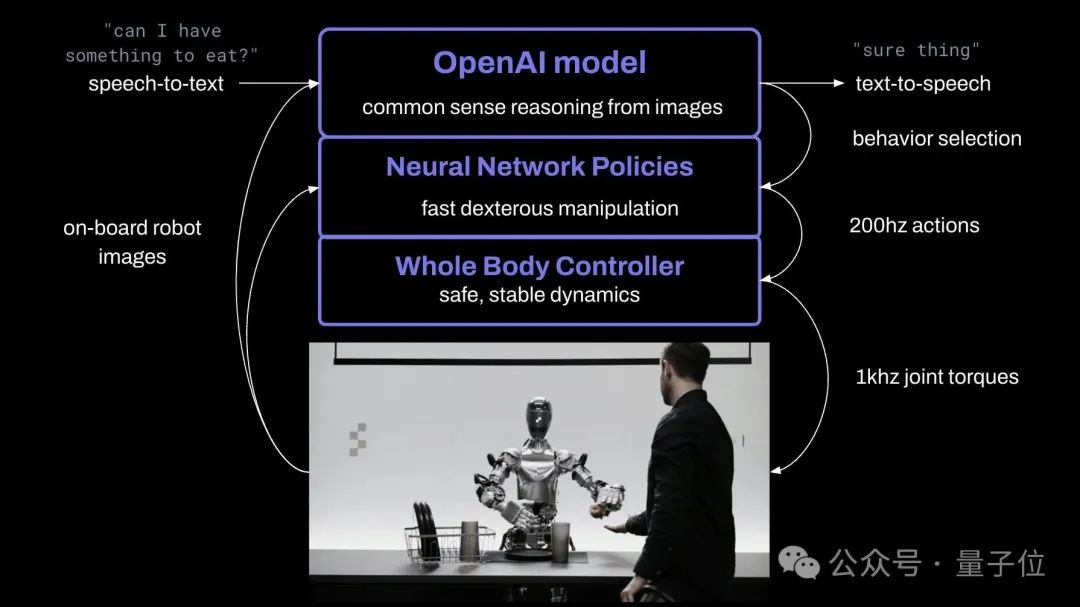
Laut der Einführung des Gründers kann Abbildung 01 über ein durchgängiges neuronales Netzwerk frei mit Menschen kommunizieren.
Basierend auf den von OpenAI bereitgestellten visuellen Verständnis- und Sprachverständnisfunktionen können schnelle, einfache und geschickte Aktionen ausgeführt werden.
Bei dem Modell soll es sich lediglich um ein großes visuelles Sprachmodell handeln. Es ist nicht bekannt, ob es sich um GPT-4V handelt.
 Bilder
Bilder
Es kann auch Aktionen planen, über ein Kurzzeitgedächtnis verfügen und seinen Denkprozess in Sprache erklären.
 Bilder
Bilder
Zum Beispiel im Dialog „Können Sie sie dort platzieren?“
Das Verständnis vager Ausdrücke wie „sie“ und „dort“ spiegelt die Kurzzeitgedächtnisfähigkeit des Roboters wider.
Es verwendet das von OpenAI trainierte visuelle Sprachmodell. Die Roboterkamera erfasst das Bild mit 10 Hz und das neuronale Netzwerk gibt dann Bewegungen mit 24 Freiheitsgraden (Handgelenk- und Fingergelenkwinkel) bei 200 Hz aus.
Auch hinsichtlich der konkreten Arbeitsteilung ist die Strategie des Roboters der des Menschen sehr ähnlich.
Komplexe Aktionen werden an das große KI-Modell übergeben. Das vorab trainierte Modell führt logische Überlegungen zu Bildern und Texten durch und gibt Aktionspläne vor.
Einfache Aktionen wie das Ergreifen einer Plastiktüte (Sie können sie überall greifen). Der Roboter basiert auf der erlernten Vision. Strategien zur Aktionsausführung ermöglichen es Ihnen, einige „unbewusste“ schnelle Reaktionsaktionen durchzuführen.
Gleichzeitig ist der Ganzkörpercontroller für die Aufrechterhaltung des Körpergleichgewichts und der stabilen Bewegung verantwortlich.
 Bilder
Bilder
Die Sprachfähigkeiten des Roboters sind auf der Grundlage eines großen Text-Sprach-Modells fein abgestimmt.
 Pictures
Pictures
Neben dem fortschrittlichsten KI-Modell erwähnte der Gründer und CEO von Figure, dem Unternehmen hinter Figure 01, in einem Tweet auch, dass Figure alle Schlüsselkomponenten des Roboters integriert.
Einschließlich Motoren, Middleware-Betriebssysteme, Sensoren, mechanische Strukturen usw., alle von Figure-Ingenieuren entworfen.
Es versteht sich, dass dieses Robotik-Startup seine Zusammenarbeit mit OpenAI erst vor zwei Wochen offiziell bekannt gegeben hat, ein so großes Ergebnis jedoch erst 13 Tage später brachte. Viele Menschen beginnen, sich auf die spätere Zusammenarbeit zu freuen.
 Bilder
Bilder
Damit ist ein weiterer neuer Star im Bereich der verkörperten Intelligenz ins Rampenlicht gerückt.
Apropos Figure: Dieses Unternehmen wurde 2022 gegründet. Wie oben erwähnt, erregte es erneut Aufmerksamkeit von außen –
Die offizielle Ankündigung erfolgte in einem In der neuen Finanzierungsrunde wurden 675 Millionen US-Dollar eingeworben, und die Bewertung erreichte 2,6 Milliarden US-Dollar. Investoren sammelten fast die Hälfte des Silicon Valley, darunter Microsoft, OpenAI, Nvidia, Amazon-Gründer Bezos usw.
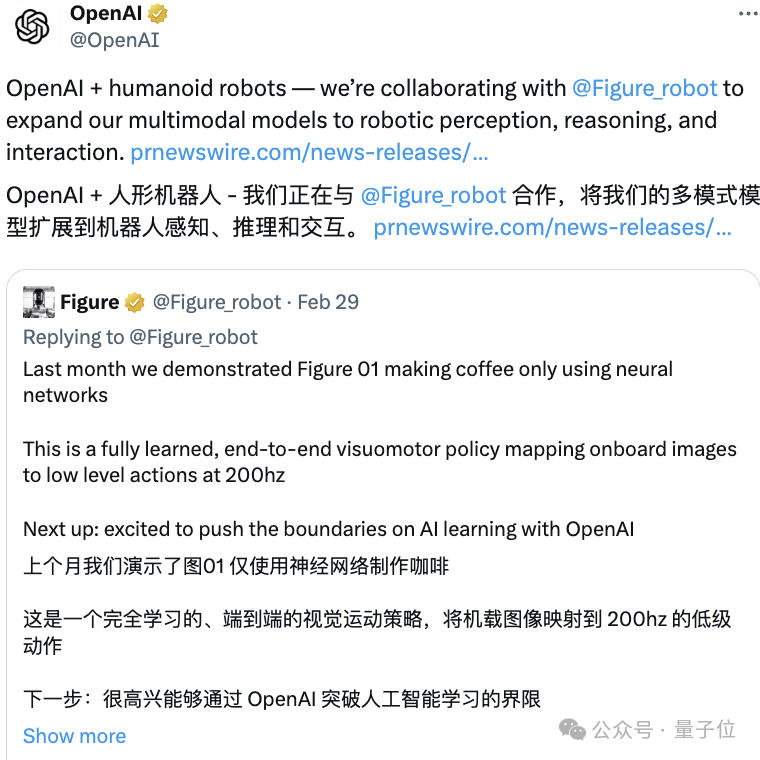
Noch wichtiger ist, dass OpenAI auch Pläne für eine weitere Zusammenarbeit mit Figure bekannt gab: die Erweiterung der Fähigkeiten multimodaler großer Modelle auf Roboterwahrnehmung, Argumentation und Interaktion, „Entwicklung humanoider Roboter, die Menschen bei körperlicher Arbeit ersetzen können“.
Um das derzeit angesagteste Technologievokabular nutzen zu können, müssen wir zusammenarbeiten, um verkörperte Intelligenz zu entwickeln.
 Bilder
Bilder
Zu dieser Zeit stammte der neueste Fortschritt von Abbildung 01 von Tante Jiang:
Durch das Ansehen menschlicher Demonstrationsvideos kann Abbildung 01 in nur 10 Stunden lernen, Kaffee mit einer Kapselkaffeemaschine zuzubereiten. Ausbildung bis zum Ende.
 Bilder
Bilder
Sobald die Zusammenarbeit zwischen Figure und OpenAI veröffentlicht wurde, waren die Internetnutzer bereits voller Erwartungen für zukünftige Durchbrüche.
 Bilder
Bilder
Schließlich schrieb Brett Adcock auf seiner persönlichen Homepage, dass „der einzige Fokus darin besteht, Figure aus einer 30-Jahres-Perspektive aufzubauen, um die Zukunft der Menschheit positiv zu beeinflussen.“
Aber vielleicht hätte sich niemand vorstellen können, dass in nur etwa zwei Wochen neue Fortschritte kommen würden.
So schnell, bisher. Und es kann weiterhin verallgemeinert und im Maßstab erweitert werden.
 Bilder
Bilder
Es ist erwähnenswert, dass Figures Rekrutierungsinformationen gleichzeitig mit der Demo des Bombenanschlagplatzes veröffentlicht wurden:
Wir erwecken humanoide Roboter zum Leben. begleiten Sie uns.
 Bilder
Bilder
Referenzlink:
[1]https://www.php.cn/link/59bbfbe0d3922ccd1d167661a26d8353
[2]https://www.php.cn/link/a3fc 34dce 15cda93287496c84af5203c
[3]https://www.php.cn/link/194585b5215aea447389c5fefca09c61
Das obige ist der detaillierte Inhalt vonOpenAI-Großmodell-Oberkörperroboter demonstriert die Explosion in voller Geschwindigkeit!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verwenden Sie die Zählfunktion
So verwenden Sie die Zählfunktion
 Was soll ich tun, wenn beim Einschalten des Computers englische Buchstaben angezeigt werden und der Computer nicht eingeschaltet werden kann?
Was soll ich tun, wenn beim Einschalten des Computers englische Buchstaben angezeigt werden und der Computer nicht eingeschaltet werden kann?
 Drei Hauptmerkmale von Java
Drei Hauptmerkmale von Java
 So legen Sie die Breite des Feldsatzes fest
So legen Sie die Breite des Feldsatzes fest
 So lösen Sie internalerror0x06
So lösen Sie internalerror0x06
 So verwenden Sie die Bauchmuskelfunktion
So verwenden Sie die Bauchmuskelfunktion
 So lösen Sie das Problem, dass CSS nicht geladen werden kann
So lösen Sie das Problem, dass CSS nicht geladen werden kann
 Du schirmst den Fahrer ab
Du schirmst den Fahrer ab








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



