
 Technologie-Peripheriegeräte
KI
Zum ersten Mal die drei Hauptprobleme des „graphbasierten Modells' überwunden! HKU Open Source OpenGraph: Zero-Sample-Lernen passt sich einer Vielzahl nachgelagerter Aufgaben an
Technologie-Peripheriegeräte
KI
Zum ersten Mal die drei Hauptprobleme des „graphbasierten Modells' überwunden! HKU Open Source OpenGraph: Zero-Sample-Lernen passt sich einer Vielzahl nachgelagerter Aufgaben an
Zum ersten Mal die drei Hauptprobleme des „graphbasierten Modells' überwunden! HKU Open Source OpenGraph: Zero-Sample-Lernen passt sich einer Vielzahl nachgelagerter Aufgaben an

Graph-Learning-Technologie wird in verschiedenen Bereichen häufig eingesetzt, darunter Empfehlungssysteme, Analyse sozialer Netzwerke, Zitiernetzwerke und Transportnetzwerke. Diese Technologie kann komplexe relationale Daten effizient abbauen und erlernen und stellt ein leistungsstarkes Werkzeug für Datenwissenschaftler und Ingenieure dar. Durch Graph-Learning-Algorithmen können wir die Zusammenhänge und Verbindungen zwischen Daten besser verstehen und so die Gesetze und Muster entdecken, die sich hinter den Daten verbergen. In praktischen Anwendungen kann die Graph-Learning-Technologie uns dabei helfen, genauere und
Graph Neural Networks (GNNs) mithilfe iterativer Message-Passing-Mechanismen zu erstellen, um komplexe Beziehungen höherer Ordnung in graphstrukturierten Daten zu erfassen. In verschiedenen Bereichen wurden bemerkenswerte Erfolge erzielt Anwendungen zum Lernen von Graphen.
Normalerweise erfordert diese Art von End-to-End-Graph-Neuronalen Netzwerken eine große Menge hochwertiger annotierter Daten, um bessere Trainingsergebnisse zu erzielen.
In den letzten Jahren wurde in einigen Arbeiten der Vortrainings- und Feinabstimmungsmodus (Vortraining und Feinabstimmung) von Diagrammmodellen vorgeschlagen, der verschiedene selbstüberwachte Lernaufgaben verwendet, um zunächst ein unbeschriftetes Diagramm vorab zu trainieren Daten und verwenden Sie dann eine kleine Menge Feinabstimmung, um das Problem unzureichender Überwachungssignale zu bekämpfen. Zu den selbstüberwachten Lernaufgaben zählen dabei Methoden wie kontrastives Lernen, Maskenrekonstruktion sowie lokale und globale gegenseitige Informationsmaximierung.
Obwohl solche Pre-Training-Methoden bis zu einem gewissen Grad erfolgreich sind, weisen sie bestimmte Einschränkungen bei den Generalisierungsfähigkeiten auf, insbesondere wenn es zu Verteilungsverschiebungen zwischen Pre-Training- und Downstream-Aufgaben kommt.
In Empfehlungssystemen werden vorab trainierte Modelle auf der Grundlage früher Daten trainiert, aber Benutzerpräferenzen und Produktpopularität ändern sich häufig, was eine kontinuierliche Aktualisierung des Modells erfordert, um sich an neue Informationen anzupassen.
Um dieser Herausforderung zu begegnen, wurden in neueren Untersuchungen Methoden zur Feinabstimmung von Hinweisen für Diagrammmodelle vorgeschlagen, damit sich vorab trainierte Modelle effektiver an verschiedene nachgelagerte Aufgaben und Daten anpassen können.
Obwohl die obige Forschung die Verallgemeinerungsleistung von graphischen neuronalen Netzwerkmodellen gefördert hat, basieren diese Modelle auf einer Annahme: Trainingsdaten und Testdaten haben denselben Knotensatz und denselben Merkmalsraum.
Dies schränkt den Anwendungsbereich vorab trainierter Diagrammmodelle erheblich ein. Daher untersucht dieser Artikel Methoden zur weiteren Verbesserung der Generalisierungsfähigkeit grafischer Modelle.
Wir erwarten, dass OpenGraph gängige topologische Strukturmuster erfasst und Zero-Shot-Vorhersagen für Testdaten erzielt. Dies bedeutet, dass durch den Vorwärtsausbreitungsprozess Merkmale effizient extrahiert und Testdiagrammdaten genau vorhergesagt werden können.
Der Trainingsprozess des Modells wird an völlig unterschiedlichen Diagrammdaten durchgeführt. Während der Trainingsphase werden keine Elemente des Testdiagramms berührt, einschließlich Knoten, Kanten und Merkmalsvektoren. Um dieses Ziel zu erreichen, müssen in diesem Artikel die folgenden drei Herausforderungen gelöst werden: Die Aufgabe besteht darin, dass unterschiedliche Diagrammdaten normalerweise völlig unterschiedliche Sätze von Diagrammtokens haben. Insbesondere überlappen Knotensätze aus verschiedenen Diagrammen häufig nicht und verschiedene Diagrammdatensätze verwenden häufig völlig unterschiedliche Knotenmerkmale. Dadurch wird verhindert, dass das Modell datensatzübergreifende Vorhersageaufgaben durchführt, indem es Parameter lernt, die an die Diagramm-Tokens eines bestimmten Datensatzes gebunden sind.
 C2. Effiziente Beziehungsmodellierung zwischen Knoten
C2. Effiziente Beziehungsmodellierung zwischen Knoten
Im Bereich des Graphenlernens gibt es häufig komplexe Abhängigkeiten zwischen Knoten, und das Modell muss die lokalen und globalen Nachbarschaftsbeziehungen von Knoten umfassend berücksichtigen. Beim Erstellen eines allgemeinen Diagrammmodells besteht eine wichtige Aufgabe darin, die Beziehungen zwischen Knoten effizient modellieren zu können, was den Modelleffekt und die Skalierbarkeit bei der Verarbeitung großer Mengen an Diagrammdaten verbessern kann.
C3. Knappheit an Trainingsdaten
Aufgrund des Datenschutzes, der Datenerfassungskosten und anderer Gründe sind Datenknappheitsprobleme in vielen nachgelagerten Bereichen des Graphenlernens weit verbreitet, was das Training allgemeiner Graphenmodelle anfällig für Mängel macht Unterstützung für bestimmte Suboptimale Trainingsergebnisse aufgrund mangelnden Verständnisses nachgelagerter Domänen.
Um die oben genannten Herausforderungen anzugehen, schlugen Forscher der Universität Hongkong OpenGraph vor, ein Modell, das sich gut für Zero-Shot-Lernen eignet und übertragbare topologische Strukturmuster zwischen verschiedenen nachgelagerten Domänen identifizieren kann.
?? Projektion Der vorgeschlagene Graph-Tokenizer löst die Herausforderung C1 und generiert dadurch einheitliche Graph-Tokens.

Um Herausforderung C2 zu bewältigen, wurde ein skalierbarer Graph-Transformer entwickelt, der mit einem effizienten Selbstaufmerksamkeitsmechanismus basierend auf Anker-Sampling ausgestattet ist und Token-Sequenz-Sampling beinhaltet, um ein effizienteres Training zu erreichen.
Um Herausforderung C3 zu bewältigen, nutzen wir große Sprachmodelle zur Datenerweiterung, um unser Pre-Training zu bereichern, indem wir Hint-Tree-Algorithmen und Gibbs-Sampling verwenden, um reale, graphstrukturierte relationale Daten zu simulieren. Unsere umfangreichen Tests an mehreren Diagrammdatensätzen zeigen die überlegenen Generalisierungsfähigkeiten von OpenGraph in einer Vielzahl von Umgebungen. Modelleinführung .
Unified Graph Tokenizer
Um mit den großen Unterschieden in Knoten, Kanten und Merkmalen verschiedener Datensätze fertig zu werden, besteht unsere erste Aufgabe darin, einen einheitlichen Graphen zu erstellen tokenizer, der verschiedene Diagrammdaten effektiv in eine einheitliche Token-Sequenz abbilden kann. In unserem Tokenizer verfügt jeder Token über einen semantischen Vektor, der die Informationen des entsprechenden Knotens beschreibt.
Durch die Einführung eines einheitlichen Knotendarstellungsraums und einer flexiblen Sequenzdatenstruktur hoffen wir, eine standardisierte und effiziente Tokenisierung für verschiedene Diagrammdaten durchzuführen.

Glatte Adjazenzmatrix hoher Ordnung
Beim Graph-Tokenisierungsprozess wird die Potenz hoher Ordnung der Adjazenzmatrix als eine der Eingaben verwendet. Diese Methode kann nicht nur die hohe Ordnung erhalten. Ordnen Sie die Verbindungsbeziehung der Diagrammstruktur an, sondern lösen Sie auch das Problem der Verbindungssparsität in der ursprünglichen Adjazenzmatrize.
Während des Berechnungsprozesses wird eine Laplace-Normalisierung durchgeführt und alle Potenzen der Adjazenzmatrix unterschiedlicher Ordnung berücksichtigt. Die spezifische Berechnungsmethode ist wie folgt.
Topologiebewusste Abbildung beliebiger Graphen
Die Adjazenzmatrizen verschiedener Datensätze weisen große Dimensionsunterschiede auf, was uns daran hindert, die Adjazenzmatrix direkt als Eingabe zu nehmen und dann eine feste Eingabe zu verwenden Dimensionale neuronale Netzwerkverarbeitung.
Unsere Lösung besteht darin, zunächst die Adjazenzmatrix in die Form einer Knotendarstellungssequenz zu projizieren und dann zur Verarbeitung ein Sequenzmodell variabler Länge zu verwenden. Um den Informationsverlust im Mapping-Prozess zu reduzieren, schlagen wir eine topologiebewusste Mapping-Methode vor.
Zunächst ist der Wertebereich unserer topologiebewussten Abbildung ein höherdimensionaler latenter Darstellungsraum. Einige frühere Arbeiten haben darauf hingewiesen, dass selbst zufällige Zuordnungen oft zu zufriedenstellenden Darstellungen führen können, wenn größere latente Raumdimensionen übernommen werden.
Um die Strukturinformationen des Graphen weiter zu bewahren und den Einfluss von Zufälligkeiten zu reduzieren, verwenden wir die schnelle Eigenwertzerlegung (SVD), um unsere Abbildungsfunktion zu erstellen. In tatsächlichen Experimenten können zwei Runden schneller Eigenwertzerlegung topologische Informationen effektiv beibehalten, und der resultierende Rechenaufwand ist im Vergleich zu anderen Modulen vernachlässigbar. 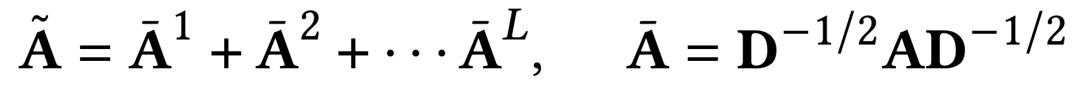
Skalierbarer Graph Transformer
Nach einem Parameter-freien Graph-Tokenisierungsprozess weist OpenGraph Diagrammdaten mit unterschiedlichen Eigenschaften eine einheitliche topologiebewusste Graph-Token-Darstellung zu. Die nächste Aufgabe besteht darin, die komplexen Abhängigkeiten zwischen Knoten mithilfe trainierbarer neuronaler Netze zu modellieren.
OpenGraph übernimmt die Transformer-Architektur, um deren leistungsstarke Fähigkeiten bei der Modellierung komplexer Beziehungen zu nutzen. Um die Effizienz und Leistung des Modells sicherzustellen, führen wir die folgenden zwei Stichprobentechniken ein.
Token-Sequenz-Sampling
Da unsere Diagramm-Token-Sequenzdaten im Allgemeinen eine große Anzahl von Token und versteckten Darstellungsdimensionen aufweisen, tastet der von OpenGraph verwendete Diagrammtransformator die Eingabe-Token-Sequenz ab und lernt nur den aktuellen Trainingsstapel Paarweise Beziehungen zwischen Token innerhalb einer Zeit reduzieren die Anzahl der Beziehungspaare, die modelliert werden müssen, vom Quadrat der Anzahl der Knoten zum Quadrat der Trainingsstapelgröße, wodurch der Zeit- und Platzaufwand des Graphtransformators im Training erheblich reduziert wird Phase. Darüber hinaus ermöglicht diese Stichprobenmethode dem Modell, beim Training mehr Aufmerksamkeit auf den aktuellen Trainingsstapel zu richten.
Obwohl die Eingabedaten abgetastet werden, kann die abgetastete Token-Sequenz dennoch bis zu einem gewissen Grad die Informationen aller Knoten im gesamten Diagramm widerspiegeln, da unsere anfängliche Diagramm-Token-Darstellung die topologische Beziehung zwischen Knoten enthält.
Anker-Sampling-Methode in der Selbstaufmerksamkeit
Obwohl das Token-Sequenz-Sampling die Komplexität vom Quadrat der Anzahl der Knoten auf das Quadrat der Stapelgröße reduziert, hat die Komplexität auf Quadratebene einen größeren Einfluss auf die Batchgröße: Die Beschränkung macht es unmöglich, größere Batches für das Modelltraining zu verwenden, was sich auf die Gesamttrainingszeit und die Trainingsstabilität auswirkt.
Um dieses Problem zu lindern, gibt der Transformatorteil von OpenGraph die Modellierung der paarweisen Beziehung zwischen allen Token auf und teilt stattdessen das Beziehungslernen zwischen allen Knoten auf.
Wissensdestillation für große Sprachmodelle
Aus Datenschutz- und anderen Gründen ist es sehr schwierig, Daten aus verschiedenen Bereichen zu erhalten, um ein allgemeines Diagrammmodell zu trainieren. Da wir das erstaunliche Wissen und die Verständnisfähigkeiten großer Sprachmodelle (LLM) spüren, nutzen wir ihre Leistungsfähigkeit, um verschiedene graphstrukturierte Daten für das Training allgemeiner Graphmodelle zu generieren.
Der von uns entwickelte Datenerweiterungsmechanismus ermöglicht es LLM-erweiterten Diagrammdaten, die Eigenschaften realer Diagramme besser anzunähern, wodurch die Relevanz und Nützlichkeit der erweiterten Daten verbessert wird.
LLM-basierte Knotengenerierung
Bei der Generierung eines Diagramms besteht unser erster Schritt darin, einen Knotensatz zu erstellen, der für ein bestimmtes Anwendungsszenario geeignet ist. Jeder Knoten verfügt über eine textbasierte Funktionsbeschreibung, die den nachfolgenden Kantengenerierungsprozess erleichtert.
Bei der Bearbeitung realer Szenarien kann diese Aufgabe jedoch aufgrund der großen Größe des Knotensatzes eine besondere Herausforderung darstellen. Auf einer E-Commerce-Plattform können Diagrammdaten beispielsweise Milliarden von Produkten enthalten. Daher wird es zu einer großen Herausforderung, LLM effizient in die Lage zu versetzen, eine große Anzahl von Knoten zu generieren.
Um die oben genannten Herausforderungen zu bewältigen, verfolgen wir eine Strategie, bei der allgemeine Knoten kontinuierlich in detailliertere Unterkategorien unterteilt werden.
Beim Generieren von Produktknoten in einem E-Commerce-Szenario verwenden Sie beispielsweise zunächst ein Abfrageaufforderungs-LLM ähnlich wie „Listen Sie die Unterkategorien aller Produkte auf E-Commerce-Plattformen wie Taobao auf“. LLM antwortete mit einer Liste von Unterkategorien wie „Kleidung“, „Heimküchengeräte“ und „Elektronik“.
Dann bitten wir LLM, jede Unterkategorie weiter zu verfeinern, um diesen iterativen Aufteilungsprozess fortzusetzen. Dieser Vorgang wird wiederholt, bis wir Knoten haben, die realen Instanzen ähneln, z. B. einen Knoten mit den Bezeichnungen „Kleidung“, „Damenbekleidung“, „Pullover“, „Pullover mit Taschen“ und „Pullover mit weißen Taschen“.
Prompt-Baum-Algorithmus
Der Prozess der Aufteilung von Knoten in Unterkategorien und der Generierung feinkörniger Entitäten folgt einer baumähnlichen Struktur. Die anfänglichen allgemeinen Knoten (z. B. „Produkt“, „Deep-Learning-Papier“) dienen als Wurzeln und feinkörnige Einheiten dienen als Blattknoten. Wir wenden eine Baumhinweisstrategie an, um diese Knoten zu durchlaufen und zu generieren.

Kantengenerierung basierend auf LLM und Gibbs-Sampling
Um Kanten zu generieren, verwenden wir den Gibbs-Sampling-Algorithmus mit dem oben generierten Knotensatz. Der Algorithmus beginnt mit einer Zufallsstichprobe und iteriert jedes Mal, basierend auf der aktuellen Stichprobe, eine Stichprobe, die durch Ändern einer der Datendimensionen erhalten wird.
Der Schlüssel zu diesem Algorithmus besteht darin, die bedingte Wahrscheinlichkeit abzuschätzen, dass sich eine bestimmte Datendimension unter den Bedingungen der aktuellen Stichprobe ändert. Wir schlagen vor, eine Wahrscheinlichkeitsschätzung durch LLM basierend auf den Textmerkmalen durchzuführen, die bei der Knotengenerierung erhalten werden.
Da der Mengenraum der Kanten groß ist, verwenden wir zunächst LLM zur Charakterisierung der Knotenmenge und verwenden dann einen einfachen Ähnlichkeitsoperator, um die darauf basierenden Knoten zu charakterisieren, um den enormen Aufwand zu vermeiden, der durch die Erkundung durch LLM entsteht Berechnen Sie die Beziehung zwischen ihnen. Innerhalb des oben genannten Kantengenerierungsrahmens übernehmen wir auch die folgenden drei wichtigen Techniken zur Anpassung.
Dynamische Wahrscheinlichkeitsnormalisierung
Da die Ähnlichkeit der LLM-Darstellung erheblich vom Bereich [0, 1] abweichen kann, verwenden wir eine dynamische Wahrscheinlichkeitsnormalisierung, um einen für die Stichprobe besser geeigneten Wahrscheinlichkeitswert zu erhalten Methoden.
Diese Methode verwaltet dynamisch die aktuellsten T'-Ähnlichkeitsschätzwerte während des Stichprobenvorgangs, berechnet deren Mittelwert und Standardabweichung und ordnet schließlich die aktuelle Ähnlichkeitsschätzung dem Verteilungsbereich von zwei Standardabweichungen oberhalb und unterhalb des Mittelwerts zu . Dies führt zu einer Wahrscheinlichkeitsschätzung von ungefähr [0, 1].
Einführung in die Knotenlokalität
Die auf LLM basierende Kantengenerierungsmethode kann ihre potenziellen Verbindungsbeziehungen basierend auf der semantischen Ähnlichkeit von Knoten effektiv bestimmen.
Allerdings entstehen tendenziell zu viele Verbindungen zwischen allen semantisch verwandten Knoten, wodurch das wichtige Konzept der Lokalität in Diagrammen der realen Welt ignoriert wird.
In der realen Welt ist es wahrscheinlicher, dass Knoten mit einer Teilmenge verwandter Knoten verbunden sind, da sie normalerweise nur eine begrenzte Interaktion mit einer Teilmenge von Knoten haben. Um diese wichtige Eigenschaft zu modellieren, wird eine Methode eingeführt, die die Lokalität bei der Kantengenerierung berücksichtigt.
Jedem Knoten wird zufällig ein Lokalitätsindex zugewiesen. Die Interaktionswahrscheinlichkeit zwischen zwei Knoten wird durch die Abschwächung der absoluten Differenz des Lokalitätsindex beeinflusst. Je größer der Unterschied im Lokalitätsindex der Knoten ist, desto schwerwiegender ist die Abschwächung wird sein.
Diagrammtopologiemuster einfügen
Um die generierten Diagrammdaten konsistenter mit dem Muster der topologischen Struktur zu machen, generieren wir während des ersten Diagrammgenerierungsprozesses erneut modifizierte Knotendarstellungen.
Diese Knotendarstellung wird auf dem anfänglich generierten Diagramm mithilfe eines einfachen Diagrammfaltungsnetzwerks erhalten. Sie kann den Verteilungseigenschaften von Diagrammstrukturdaten besser entsprechen und Verteilungsverschiebungen zwischen Diagramm und Textraum vermeiden. Abschließend führen wir basierend auf der überarbeiteten Knotendarstellung erneut eine Diagrammstichprobe durch, um die endgültigen Diagrammstrukturdaten zu erhalten.
Experimentelle Verifizierung
Im Experiment haben wir nur den generierten Datensatz basierend auf LLM für das OpenGraph-Modelltraining verwendet. Die Testdatensätze sind reale Datensätze in verschiedenen Anwendungsszenarien und umfassen Knotenklassifizierung und -kette Es gibt zwei Arten von Straßenvorhersageaufgaben. Die spezifischen Einstellungen des Experiments sind wie folgt: 0-Schuss-Einstellung Verwendet einen völlig anderen realen Testdatensatz. Führen Sie Effekttests durch. Es gibt keine Überlappung zwischen dem Trainingsdatensatz und dem Testdatensatz in Bezug auf Knoten, Kanten, Features und Beschriftungen.
Einstellung für wenige Schüsse
Da die meisten vorhandenen Methoden keine effektive Null-Schuss-Vorhersage durchführen können, verwenden wir die Wenig-Schuss-Vorhersage, um sie zu testen. Basismethoden können anhand von Vortrainingsdaten vorab trainiert und dann mithilfe von K-Shot-Proben trainiert, verfeinert oder angedeutet werden.
Gesamtwirkungsvergleich
Die Testergebnisse zu 2 Aufgaben und insgesamt 8 Testdatensätzen sind wie folgt.
Es kann beobachtet werden:
1) Bei datensatzübergreifenden Datensätzen hat der Zero-Sample-Vorhersageeffekt von OpenGraph einen größeren Vorteil als bestehende Methoden.
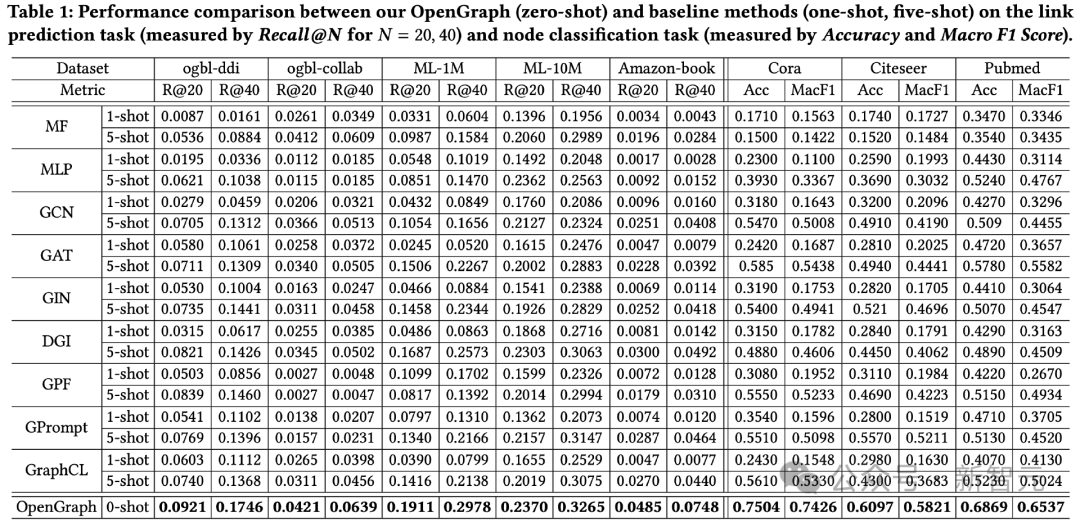 2) Bei der datensatzübergreifenden Migration sind bestehende Vortrainingsmethoden manchmal sogar schlechter als ihre Basismodelle, die nur an wenigen Stichproben von Grund auf trainiert werden, was die Fähigkeit von Diagrammmodellen widerspiegelt, übergreifende Ergebnisse zu erzielen. Schwierigkeiten bei der Verallgemeinerung von Datensätzen.
2) Bei der datensatzübergreifenden Migration sind bestehende Vortrainingsmethoden manchmal sogar schlechter als ihre Basismodelle, die nur an wenigen Stichproben von Grund auf trainiert werden, was die Fähigkeit von Diagrammmodellen widerspiegelt, übergreifende Ergebnisse zu erzielen. Schwierigkeiten bei der Verallgemeinerung von Datensätzen.
Graph Tokenizer Research
Als nächstes untersuchen wir den Einfluss des Bild-Tokenizer-Designs auf die Wirkung. Zuerst haben wir das Glättungsende der Adjazenzmatrix angepasst und seine Auswirkung auf den Effekt getestet. Der Effekt wird bei der Ordnung 0 stark abgeschwächt, was darauf hinweist, wie wichtig die Verwendung einer Glättung höherer Ordnung ist.
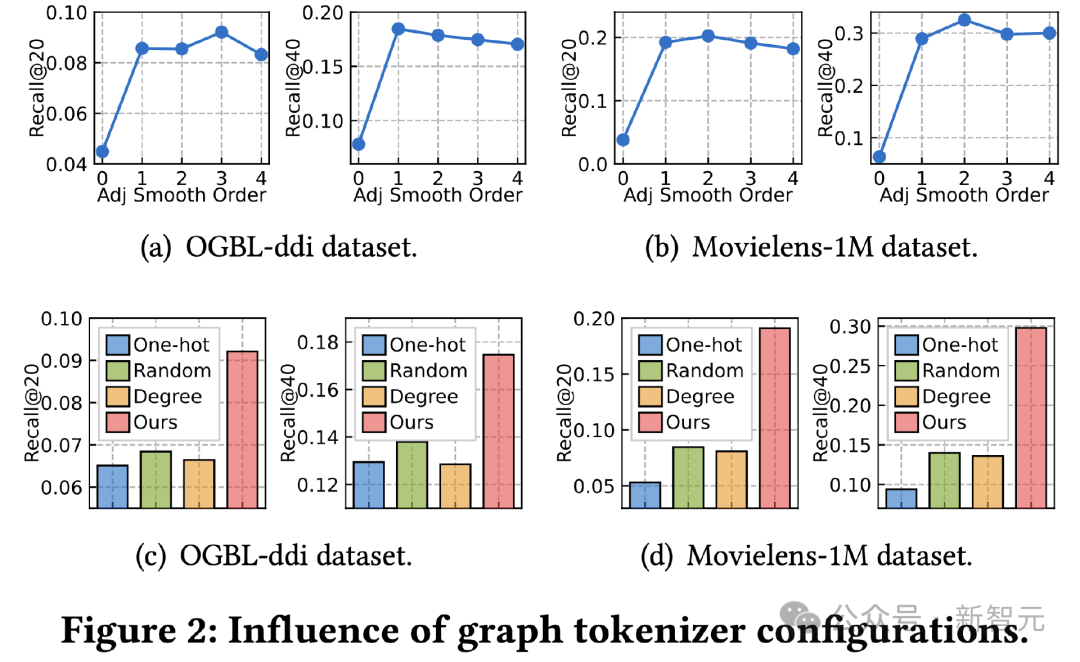
Zweitens ersetzen wir die topologiebewusste Zuordnungsfunktion durch andere einfache Methoden, einschließlich lernbarer One-Hot-ID-Darstellung über Datensätze hinweg, Zufallszuordnung und lernbarer Darstellung basierend auf dem Knotengrad.
Die Ergebnisse zeigen, dass alle drei Alternativen weniger effektiv sind. Unter ihnen hat das Erlernen der ID-Darstellung über mehrere Datensätze hinweg den schlechtesten Effekt Alle alternativen Methoden erzielen die beste Leistung, bleiben aber immer noch weit hinter unserer topologiebewussten Zuordnung zurück. ? auf die Wirkung.
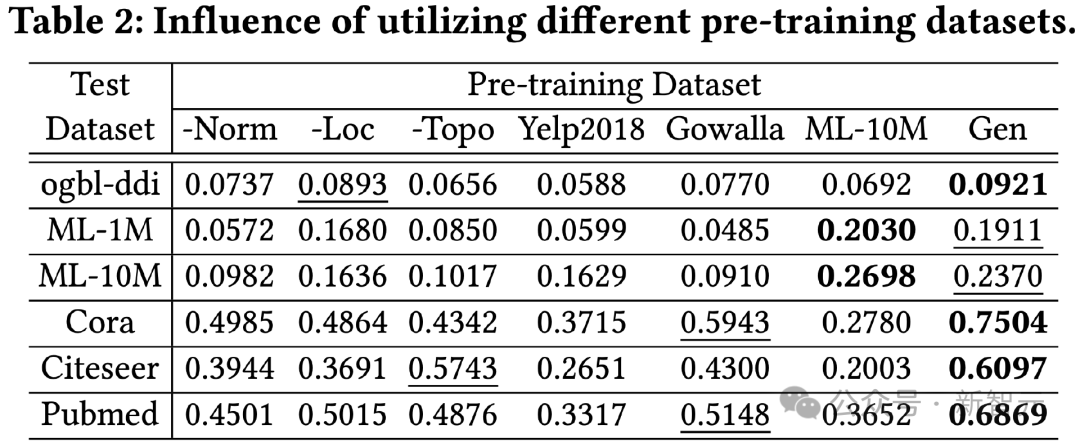
Die in diesem Experiment verglichenen Datensätze vor dem Training umfassen eine Version, die einen bestimmten Trick allein in unserer Generierungsmethode entfernt, sowie zwei echte Datensätze Yelp2018 und Gowalla, die nicht mit dem Testdatensatz und ML-bezogen zusammenhängen Der Testdatensatz. 10M Datensatz, aus den Ergebnissen ist ersichtlich:
1) Insgesamt kann unser generierter Datensatz bei allen Testdaten bessere Ergebnisse liefern.
2) Die drei getesteten Generationentechniken haben alle einen deutlichen Verbesserungseffekt.
3) Die Verwendung realer Datensätze (Yelp, Gowalla) für das Training kann negative Auswirkungen haben, die möglicherweise auf Verteilungsunterschiede zwischen verschiedenen realen Datensätzen zurückzuführen sind.
4) ML-10M erzielte sowohl auf ML-1M als auch auf ML-10M die besten Ergebnisse, was zeigt, dass die Verwendung ähnlicher Trainingsdatensätze zu besseren Ergebnissen führen kann.
Forschung zu Sampling-Techniken in Transformer
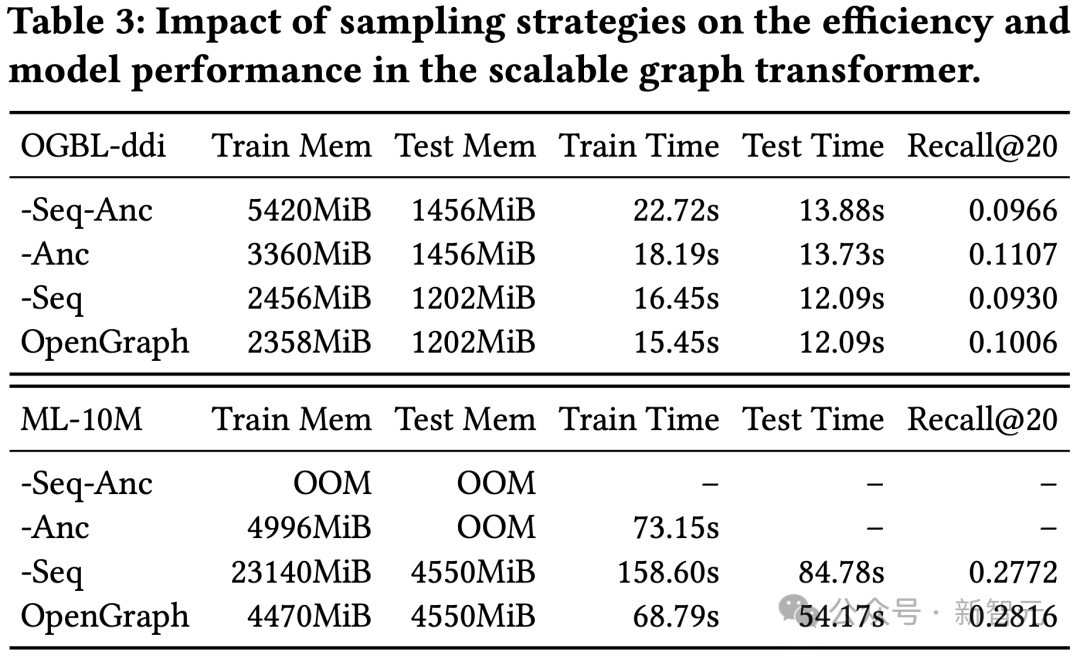
Dieses Experiment führte einen Ablationstest zum Token-Sequenz-Sampling (Seq) und Anker-Sampling (Anc) in unserem Graph-Transformer-Modul durch.
Die Ergebnisse zeigen, dass die beiden Stichprobenmethoden den Platz- und Zeitaufwand des Modells während des Trainings- und Testprozesses optimieren können. In Bezug auf die Wirkung wirkt sich das Token-Sequenz-Sampling positiv auf den Modelleffekt aus, während die Ergebnisse des DDI-Datensatzes zeigen, dass das Ankerschalen-Sampling einen negativen Einfluss auf den Modelleffekt hat.
Fazit
 Der Hauptschwerpunkt dieser Forschung liegt auf der Entwicklung eines hochgradig anpassungsfähigen Frameworks, das in der Lage ist, komplexe topologische Muster in verschiedenen Graphstrukturen genau zu erfassen und zu verstehen.
Der Hauptschwerpunkt dieser Forschung liegt auf der Entwicklung eines hochgradig anpassungsfähigen Frameworks, das in der Lage ist, komplexe topologische Muster in verschiedenen Graphstrukturen genau zu erfassen und zu verstehen.
Durch die Nutzung des Potenzials des vorgeschlagenen Modells wollen wir die Generalisierungsfähigkeit des Modells deutlich verbessern, um bei Zero-Shot-Graph-Lernaufgaben, einschließlich verschiedener nachgelagerter Anwendungen, eine gute Leistung zu erbringen.
Um die Effizienz und Robustheit von OpenGraph weiter zu verbessern, haben wir unser Modell auf der Grundlage einer skalierbaren Graphtransformator-Architektur und eines LLM-basierten Datenerweiterungsmechanismus aufgebaut.
Durch umfangreiche Experimente mit mehreren Benchmark-Datensätzen haben wir die herausragenden Generalisierungsfähigkeiten des Modells überprüft. Diese Studie unternimmt einen ersten Erkundungsversuch in Richtung des Graphenbasismodells.
In zukünftigen Arbeiten planen wir, unser Framework in die Lage zu versetzen, verrauschte Verbindungen und Strukturen mit kontrafaktischem Lerneinfluss automatisch zu entdecken und gleichzeitig allgemeine und übertragbare Strukturmuster für verschiedene Diagramme zu lernen.
Das obige ist der detaillierte Inhalt vonZum ersten Mal die drei Hauptprobleme des „graphbasierten Modells' überwunden! HKU Open Source OpenGraph: Zero-Sample-Lernen passt sich einer Vielzahl nachgelagerter Aufgaben an. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
 Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Um große Sprachmodelle (LLMs) an menschlichen Werten und Absichten auszurichten, ist es wichtig, menschliches Feedback zu lernen, um sicherzustellen, dass sie nützlich, ehrlich und harmlos sind. Im Hinblick auf die Ausrichtung von LLM ist Reinforcement Learning basierend auf menschlichem Feedback (RLHF) eine wirksame Methode. Obwohl die Ergebnisse der RLHF-Methode ausgezeichnet sind, gibt es einige Herausforderungen bei der Optimierung. Dazu gehört das Training eines Belohnungsmodells und die anschließende Optimierung eines Richtlinienmodells, um diese Belohnung zu maximieren. Kürzlich haben einige Forscher einfachere Offline-Algorithmen untersucht, darunter die direkte Präferenzoptimierung (Direct Preference Optimization, DPO). DPO lernt das Richtlinienmodell direkt auf der Grundlage von Präferenzdaten, indem es die Belohnungsfunktion in RLHF parametrisiert, wodurch die Notwendigkeit eines expliziten Belohnungsmodells entfällt. Diese Methode ist einfach und stabil
 Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
1. Einleitung In den letzten Jahren haben sich YOLOs aufgrund ihres effektiven Gleichgewichts zwischen Rechenkosten und Erkennungsleistung zum vorherrschenden Paradigma im Bereich der Echtzeit-Objekterkennung entwickelt. Forscher haben das Architekturdesign, die Optimierungsziele, Datenerweiterungsstrategien usw. von YOLO untersucht und erhebliche Fortschritte erzielt. Gleichzeitig behindert die Verwendung von Non-Maximum Suppression (NMS) bei der Nachbearbeitung die End-to-End-Bereitstellung von YOLO und wirkt sich negativ auf die Inferenzlatenz aus. In YOLOs fehlt dem Design verschiedener Komponenten eine umfassende und gründliche Prüfung, was zu erheblicher Rechenredundanz führt und die Fähigkeiten des Modells einschränkt. Es bietet eine suboptimale Effizienz und ein relativ großes Potenzial zur Leistungsverbesserung. Ziel dieser Arbeit ist es, die Leistungseffizienzgrenze von YOLO sowohl in der Nachbearbeitung als auch in der Modellarchitektur weiter zu verbessern. zu diesem Zweck
