
 Technologie-Peripheriegeräte
KI
Weitere Beschleunigung der Umsetzung: Komprimierung des End-to-End-Bewegungsplanungsmodells des autonomen Fahrens
Technologie-Peripheriegeräte
KI
Weitere Beschleunigung der Umsetzung: Komprimierung des End-to-End-Bewegungsplanungsmodells des autonomen Fahrens
Weitere Beschleunigung der Umsetzung: Komprimierung des End-to-End-Bewegungsplanungsmodells des autonomen Fahrens

Originaltitel: On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving
Papierlink: https://arxiv.org/pdf/2403.01238.pdf
Codelink: https://github .com/tulerfeng/PlanKD
Autorenzugehörigkeit: Beijing Institute of Technology ALLRIDE.AI Hebei Provincial Key Laboratory of Big Data Science and Intelligent Technology

Thesis-Idee
Ein End-to-End-Bewegungsplanungsmodell ausgestattet mit einem tiefen neuronalen Netzwerk, das großes Potenzial für die Verwirklichung vollständig autonomen Fahrens zeigt. Zu große neuronale Netze machen sie jedoch für den Einsatz auf ressourcenbeschränkten Systemen ungeeignet, die zweifellos mehr Rechenzeit und Ressourcen erfordern. Um dieses Problem anzugehen, bietet die Wissensdestillation einen vielversprechenden Ansatz, indem Modelle komprimiert werden, indem ein kleineres Schülermodell von einem größeren Lehrermodell lernt. Dennoch ist bisher unerforscht, wie die Wissensdestillation zur Komprimierung von Bewegungsplanern eingesetzt werden kann. In diesem Artikel wird PlanKD vorgeschlagen, das erste Wissensdestillations-Framework, das auf komprimierende End-to-End-Bewegungsplaner zugeschnitten ist. Erstens: Da Fahrszenarien von Natur aus komplex sind und häufig Informationen enthalten, die für die Planung irrelevant oder sogar verrauscht sind, wäre die Übertragung dieser Informationen für den studentischen Planer nicht von Vorteil. Daher entwirft dieses Papier eine Strategie, die auf Informationsengpässen basiert und nur planungsbezogene Informationen destilliert, anstatt alle Informationen wahllos zu migrieren. Zweitens können unterschiedliche Wegpunkte in der ausgegebenen geplanten Flugbahn unterschiedlich wichtig für die Bewegungsplanung sein, und geringfügige Abweichungen bei einigen kritischen Wegpunkten können zu Kollisionen führen. Daher entwirft dieser Artikel ein sicherheitsbewusstes Wegpunkt-aufmerksames Destillationsmodul, um verschiedenen Wegpunkten basierend auf ihrer Wichtigkeit adaptive Gewichtungen zuzuweisen, um Schülermodelle zu ermutigen, kritischere Wegpunkte genauer zu imitieren und so die Gesamtsicherheit zu verbessern. Experimente zeigen, dass unser PlanKD die Leistung kleiner Planer deutlich verbessern und ihre Referenzzeit deutlich verkürzen kann.
Hauptbeiträge:
- Dieses Papier stellt den ersten Versuch dar, dedizierte Wissensdestillationsmethoden zu erforschen, um End-to-End-Bewegungsplaner beim autonomen Fahren zu komprimieren.
- Dieses Papier schlägt ein allgemeines und innovatives Framework PlanKD vor, das es studentischen Planern ermöglicht, planungsbezogenes Wissen in der mittleren Ebene zu erben und eine genaue Zuordnung wichtiger Wegpunkte zur Verbesserung der Sicherheit zu ermöglichen.
- Experimente zeigen, dass PlanKD in diesem Artikel die Leistung kleiner Planer erheblich verbessern kann und dadurch eine tragbarere und effizientere Lösung für die Bereitstellung mit begrenzten Ressourcen bietet.
Netzwerkdesign:
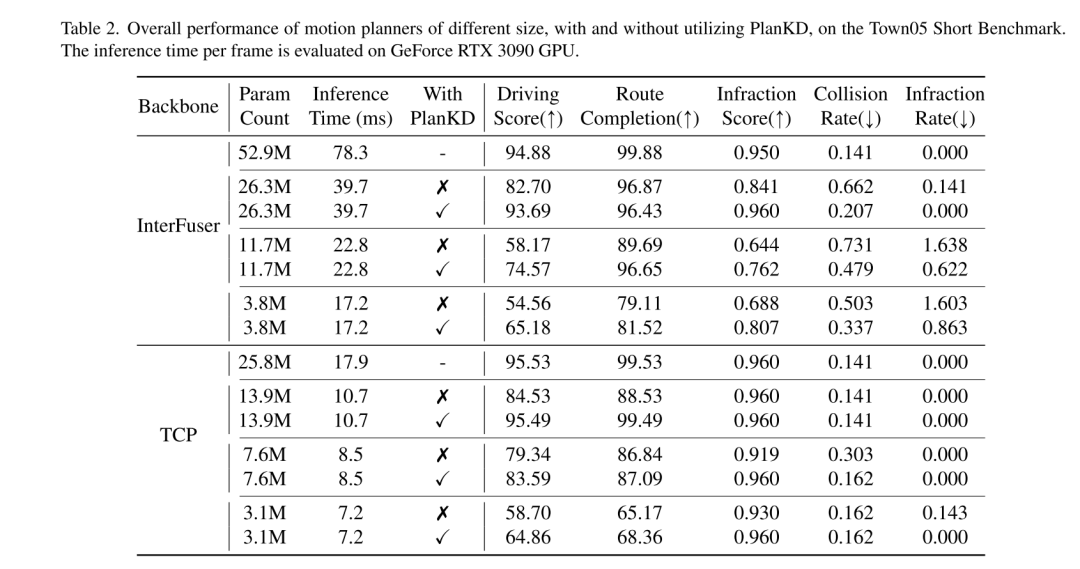
End-to-End-Bewegungsplanung hat sich in letzter Zeit als vielversprechende Richtung im autonomen Fahren herausgestellt [3, 10, 30, 31, 40, 47, 48], die rohe Sensordaten direkt abbildet geplante Aktionen. Dieses lernbasierte Paradigma weist die Vorteile auf, dass die starke Abhängigkeit von handgefertigten Regeln verringert und die Fehleranhäufung innerhalb komplexer Kaskadenmodule (normalerweise Erkennung, Verfolgung, Vorhersage und Planung) verringert wird (40, 48). Trotz ihres Erfolgs stellt die umfangreiche Architektur tiefer neuronaler Netze in Bewegungsplanern Herausforderungen für den Einsatz in ressourcenbeschränkten Umgebungen dar, beispielsweise bei autonomen Lieferrobotern, die auf die Rechenleistung von Edge-Geräten angewiesen sind. Darüber hinaus sind selbst in konventionellen Fahrzeugen die Rechenressourcen der Bordgeräte oft begrenzt [34]. Daher erfordert der direkte Einsatz von Deep- und Large-Planern zwangsläufig mehr Rechenzeit und Ressourcen, was es schwierig macht, schnell auf potenzielle Gefahren zu reagieren. Um dieses Problem zu lindern, besteht ein einfacher Ansatz darin, die Anzahl der Netzwerkparameter durch die Verwendung eines kleineren Backbone-Netzwerks zu reduzieren. In diesem Artikel wird jedoch festgestellt, dass die Leistung des End-to-End-Planungsmodells stark abnimmt, wie in Abbildung 1 dargestellt. Obwohl beispielsweise die Inferenzzeit von InterFuser [33], einem typischen End-to-End-Bewegungsplaner, von 52,9 Mio. auf 26,3 Mio. reduziert wurde, sank auch sein Fahrwert von 53,44 auf 36,55. Daher ist es notwendig, eine Modellkomprimierungsmethode zu entwickeln, die für eine durchgängige Bewegungsplanung geeignet ist.
Um einen tragbaren Bewegungsplaner zu erhalten, verwendet dieser Artikel die Wissensdestillation [19], um das End-to-End-Bewegungsplanungsmodell zu komprimieren. Die Wissensdestillation (KD) wurde umfassend zur Modellkomprimierung bei verschiedenen Aufgaben untersucht, beispielsweise bei der Objekterkennung [6, 24], der semantischen Segmentierung [18, 28] usw. Die Grundidee dieser Arbeiten besteht darin, ein vereinfachtes Schülermodell zu trainieren, indem Wissen von einem größeren Lehrermodell geerbt wird, und das Schülermodell während der Bereitstellung als Ersatz für das Lehrermodell zu verwenden. Obwohl diese Studien erhebliche Erfolge erzielt haben, führt ihre direkte Anwendung auf die durchgängige Bewegungsplanung zu suboptimalen Ergebnissen. Dies ist auf zwei neue Herausforderungen zurückzuführen, die mit Bewegungsplanungsaufgaben einhergehen: (i) Fahrszenarien sind von Natur aus komplex [46] und umfassen mehrere dynamische und statische Objekte, komplexe Hintergrundszenen sowie vielfältige Straßen- und Verkehrsinformationen, einschließlich Informationen. Allerdings sind nicht alle dieser Informationen für die Planung nützlich. Beispielsweise sind Hintergrundgebäude und entfernte Fahrzeuge für die Planung irrelevant oder sogar störend [41], während in der Nähe befindliche Fahrzeuge und Ampeln einen deterministischen Einfluss haben. Daher ist es wichtig, automatisch nur planungsrelevante Informationen aus dem Lehrermodell zu extrahieren, was mit bisherigen KD-Methoden nicht möglich ist. (ii) Unterschiedliche Wegpunkte in der Ausgabeplanungstrajektorie haben normalerweise unterschiedliche Bedeutung für die Bewegungsplanung. Wenn Sie beispielsweise an einer Kreuzung navigieren, können Wegpunkte in einer Flugbahn, die sich in der Nähe anderer Fahrzeuge befinden, eine höhere Bedeutung haben als andere Wegpunkte. Denn an diesen Punkten muss das eigene Fahrzeug aktiv mit anderen Fahrzeugen interagieren und schon kleine Abweichungen können zu Kollisionen führen. Eine weitere große Herausforderung bisheriger KD-Methoden ist jedoch die adaptive Bestimmung und genaue Nachahmung wichtiger Wegpunkte.
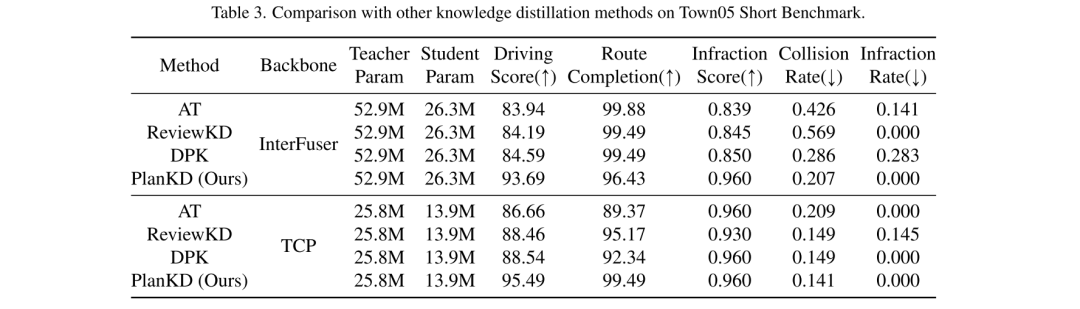
Um die beiden oben genannten Herausforderungen anzugehen, schlägt dieses Papier die erste Methode zur Wissensdestillation vor, die auf End-to-End-Bewegungsplaner im komprimierten autonomen Fahren zugeschnitten ist: PlanKD. Zunächst wird in diesem Artikel eine Strategie vorgeschlagen, die auf dem Informationsengpassprinzip [2] basiert und deren Ziel darin besteht, planungsbezogene Merkmale zu extrahieren, die minimale und ausreichende Planungsinformationen enthalten. Insbesondere maximiert dieses Dokument die gegenseitige Information zwischen den extrahierten planungsbezogenen Merkmalen und den wahren Wert des in diesem Dokument definierten Planungszustands und minimiert gleichzeitig die gegenseitige Information zwischen den extrahierten Merkmalen und Zwischenmerkmalskarten. Diese Strategie ermöglicht es dieser Arbeit, wichtige planungsrelevante Informationen nur auf der mittleren Ebene zu extrahieren und so die Wirksamkeit des Studentenmodells zu erhöhen. Zweitens verwendet dieser Artikel einen Aufmerksamkeitsmechanismus [38], um jeden Wegpunkt und sein Aufmerksamkeitsgewicht zwischen ihm und dem zugehörigen Kontext in der Vogelperspektive (BEV) zu berechnen, um wichtige Wegpunkte dynamisch zu identifizieren und originalgetreu nachzuahmen. Um die genaue Nachahmung sicherheitskritischer Wegpunkte während der Destillation zu fördern, entwerfen wir einen sicherheitsbewussten Ranking-Verlust, der dazu anregt, Wegpunkten in der Nähe von sich bewegenden Hindernissen ein höheres Aufmerksamkeitsgewicht zu geben. Dadurch kann die Sicherheit der Studienplaner deutlich erhöht werden. Die in Abbildung 1 gezeigten Beweise zeigen, dass die Fahrbewertung von Schülerplanern durch unser PlanKD erheblich verbessert werden kann. Darüber hinaus kann unsere Methode die Referenzzeit um etwa 50 % reduzieren und gleichzeitig eine vergleichbare Leistung wie der Lehrerplaner beim Town05 Long Benchmark beibehalten.
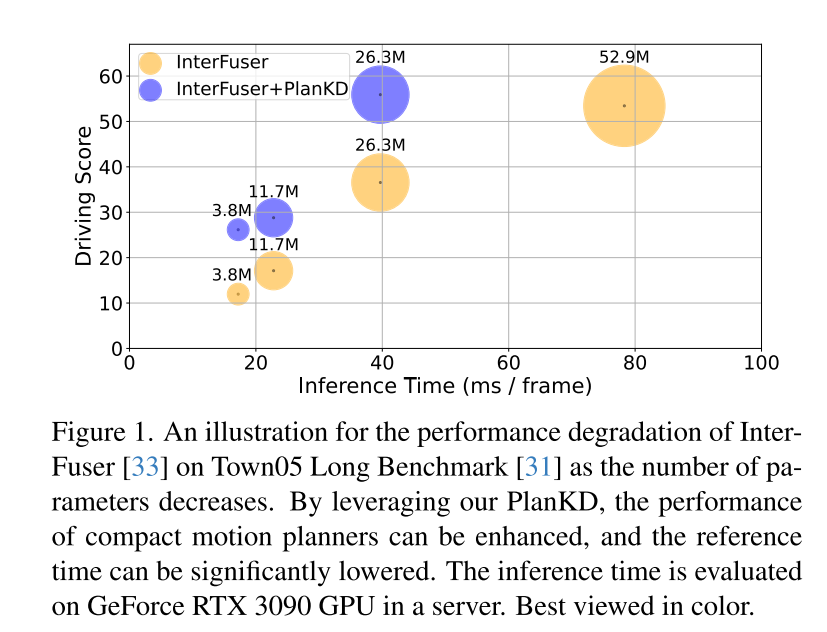
Abbildung 1. Schematische Darstellung der Leistungsverschlechterung von InterFuser[33], wenn die Anzahl der Parameter beim Town05 Long Benchmark abnimmt [31]. Durch den Einsatz unseres PlanKD können wir die Leistung kompakter Bewegungsplaner verbessern und Referenzzeiten erheblich verkürzen. Die Inferenzzeiten werden auf einer GeForce RTX 3090 GPU auf dem Server ausgewertet.
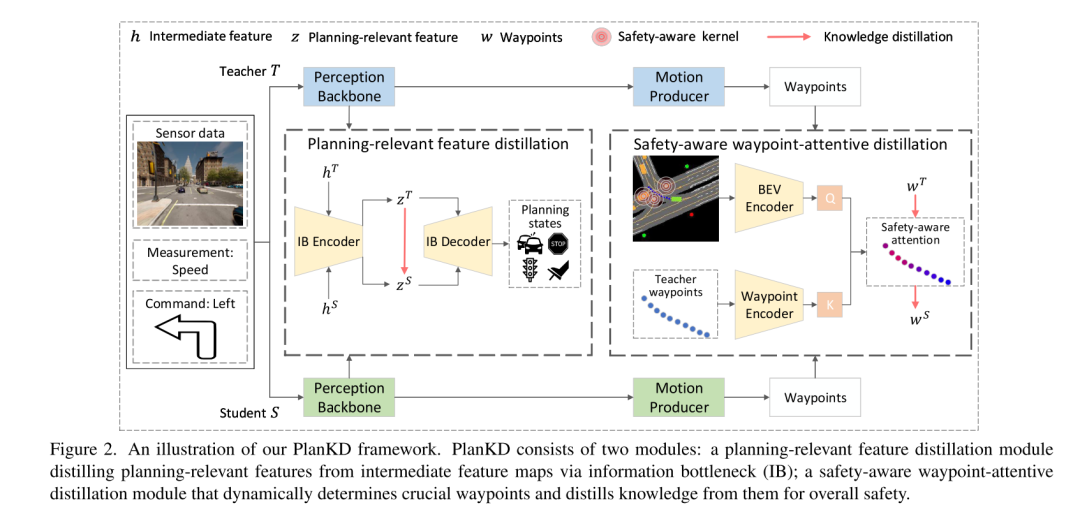
Abbildung 2. Schematische Darstellung des PlanKD-Frameworks dieses Artikels. PlanKD besteht aus zwei Modulen: einem planungsbezogenen Feature-Destillationsmodul, das planungsbezogene Features aus Zwischen-Feature-Karten durch Informationsengpässe (IB) extrahiert; ein sicherheitsbewusstes Wegpunkt-aufmerksames Destillationsmodul, das wichtige Wegpunkte dynamisch bestimmt und daraus Wissen extrahiert die allgemeine Sicherheit verbessern.
Experimentelle Ergebnisse:
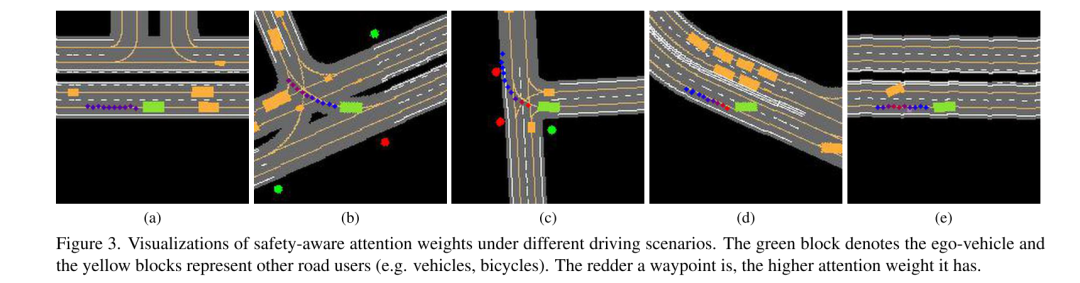
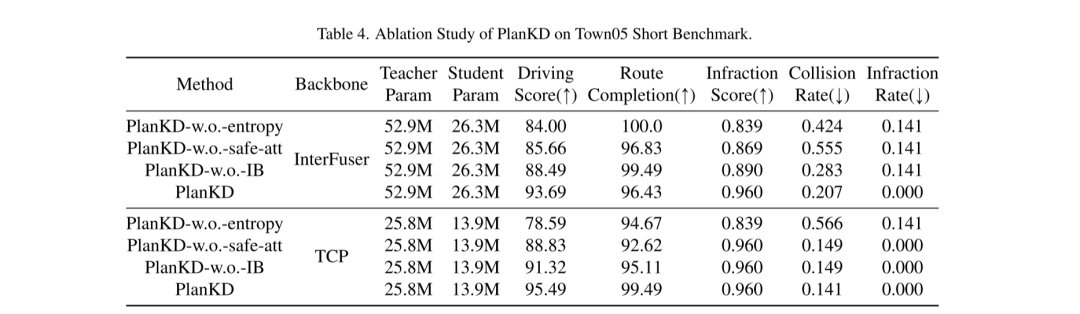
Abbildung 3. Visualisierung sicherheitsbewusster Aufmerksamkeitsgewichte in verschiedenen Fahrszenarien. Die grünen Blöcke repräsentieren das Ego-Fahrzeug und die gelben Blöcke repräsentieren andere Verkehrsteilnehmer (z. B. Autos, Fahrräder). Je rötlicher ein Wegpunkt ist, desto höher ist sein Aufmerksamkeitsgewicht.
Zusammenfassung:
Dieses Papier schlägt PlanKD vor, eine Wissensdestillationsmethode, die auf komprimierende End-to-End-Bewegungsplaner zugeschnitten ist. Die vorgeschlagene Methode kann planungsbezogene Merkmale durch Informationsengpässe erlernen, um eine effektive Merkmalsdestillation zu erreichen. Darüber hinaus entwirft dieses Papier einen sicherheitsbewussten Wegpunkt-aufmerksamen Destillationsmechanismus, um adaptiv über die Bedeutung jedes Wegpunkts für die Wegpunktdestillation zu entscheiden. Umfangreiche Experimente bestätigen die Wirksamkeit unseres Ansatzes und zeigen, dass PlanKD als tragbare und sichere Lösung für ressourcenbeschränkte Bereitstellungen dienen kann.
Zitat:
Feng K, Li C, Ren D, et al. On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving[J].
Das obige ist der detaillierte Inhalt vonWeitere Beschleunigung der Umsetzung: Komprimierung des End-to-End-Bewegungsplanungsmodells des autonomen Fahrens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
