
 Technologie-Peripheriegeräte
KI
Warten Sie nicht auf OpenAI, sondern darauf, dass Open-Sora vollständig Open Source ist
Technologie-Peripheriegeräte
KI
Warten Sie nicht auf OpenAI, sondern darauf, dass Open-Sora vollständig Open Source ist
Warten Sie nicht auf OpenAI, sondern darauf, dass Open-Sora vollständig Open Source ist

Vor nicht allzu langer Zeit wurde OpenAI Sora mit seinen erstaunlichen Videogenerierungseffekten schnell populär. Es stach aus der Masse der Wensheng-Videomodelle hervor und rückte in den Mittelpunkt der weltweiten Aufmerksamkeit. Nach der Einführung des Sora-Trainingsinferenzreproduktionsprozesses mit einer Kostenreduzierung von 46 % vor zwei Wochen hat das Colossal-AI-Team das weltweit erste Sora-ähnliche Architektur-Videogenerierungsmodell „Open-Sora 1.0“ vollständig als Open-Source-Lösung bereitgestellt, das den gesamten Trainingsprozess abdeckt , einschließlich Datenverarbeitung, aller Trainingsdetails und Modellgewichte, und schließen Sie sich mit globalen KI-Enthusiasten zusammen, um eine neue Ära der Videoerstellung voranzutreiben.
Für einen kleinen Vorgeschmack schauen wir uns zunächst ein Video einer geschäftigen Stadt an, das mit dem vom Colossal-AI-Team veröffentlichten Modell „Open-Sora 1.0“ erstellt wurde.

Ein Schnappschuss der geschäftigen Stadt, die von Open-Sora 1.0 generiert wurde
Dies ist nur die Spitze des Eisbergs der Reproduktionstechnologie von Sora, der Modellarchitektur des obigen Wensheng-Videos, der trainierten Modellgewichte und Alle Trainingsdetails der Reproduktion, das Colossal-AI-Team hat den Datenvorverarbeitungsprozess, die Demo-Anzeige und detaillierte Einführungs-Tutorials kostenlos und Open Source auf GitHub gemacht. Gleichzeitig kontaktierte der Autor das Team sofort und erfuhr, dass dies der Fall sein wird Aktualisieren Sie weiterhin Open-Sora-bezogene Lösungen und neueste Entwicklungen. Interessierte Freunde können weiterhin auf die Open-Source-Community von Open-Sora achten .
Open-Sora-Open-Source-Adresse: https://github.com/hpcaitech/Open-Sora
Umfassende Interpretation der Sora-Replikationslösung
Als nächstes werden wir uns mit verschiedenen Aspekten von Sora befassen Replikationslösung Zu den Schlüsselaspekten gehören Modellarchitekturdesign, Trainingsmethoden, Datenvorverarbeitung, Modelleffektanzeige und Optimierungstrainingsstrategien.
Modellarchitekturdesign
Das Modell übernimmt die derzeit beliebte Diffusion Transformer (DiT) [1]-Architektur. Das Autorenteam nutzt das hochwertige Open-Source-Vincent-Graphmodell PixArt-α [2], das ebenfalls die DiT-Architektur als Basis nutzt, führt auf dieser Basis eine zeitliche Aufmerksamkeitsschicht ein und erweitert diese auf Videodaten. Konkret umfasst die gesamte Architektur ein vorab trainiertes VAE, einen Textencoder und ein STDiT-Modell (Spatial Temporal Diffusion Transformer), das den räumlich-zeitlichen Aufmerksamkeitsmechanismus nutzt. Darunter ist die Struktur jeder Schicht von STDiT in der folgenden Abbildung dargestellt. Es verwendet eine serielle Methode, um ein eindimensionales zeitliches Aufmerksamkeitsmodul mit einem zweidimensionalen räumlichen Aufmerksamkeitsmodul zu überlagern und so zeitliche Beziehungen zu modellieren. Nach dem zeitlichen Aufmerksamkeitsmodul wird das Kreuzaufmerksamkeitsmodul verwendet, um die Semantik des Textes auszurichten. Im Vergleich zum Vollaufmerksamkeitsmechanismus reduziert eine solche Struktur den Trainings- und Inferenzaufwand erheblich. Im Vergleich zum Latte-Modell [3], das ebenfalls einen räumlich-zeitlichen Aufmerksamkeitsmechanismus verwendet, kann STDiT die Gewichte vorab trainierter Bild-DiT besser nutzen, um das Training an Videodaten fortzusetzen.
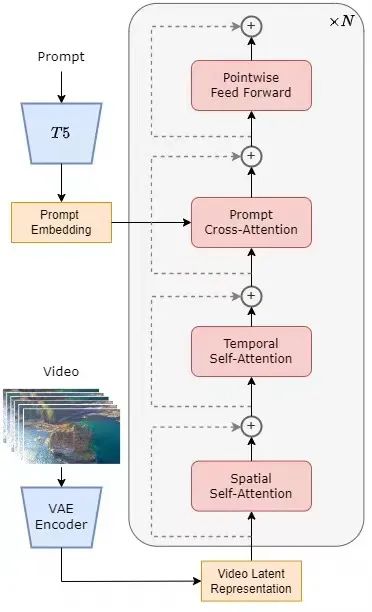
STDiT-Strukturdiagramm
Der Trainings- und Inferenzprozess des gesamten Modells ist wie folgt. Es versteht sich, dass in der Trainingsphase zunächst der vorab trainierte Variational Autoencoder (VAE)-Encoder zum Komprimieren der Videodaten verwendet wird und dann das STDiT-Diffusionsmodell zusammen mit der Texteinbettung im komprimierten latenten Raum trainiert wird. In der Inferenzphase wird ein Gaußsches Rauschen zufällig aus dem latenten Raum von VAE abgetastet und zusammen mit einer sofortigen Einbettung in STDiT eingegeben, um die entrauschten Merkmale zu erhalten. Schließlich wird es in den Decoder von VAE eingegeben und dekodiert, um das Video zu erhalten.

Modelltrainingsprozess
Trainingsreplikationsplan
Wir haben vom Team erfahren, dass sich das Replikationsschema von Open-Sora auf die Arbeit Stable Video Diffusion (SVD)[3] bezieht. Es besteht aus drei Stufen, nämlich:
- Großflächiges Bildvortraining.
- Groß angelegtes Video-Vortraining.
- Hochwertige Feinabstimmung der Videodaten.
In jeder Stufe wird das Training basierend auf den Gewichten der vorherigen Stufe fortgesetzt. Im Vergleich zum einstufigen Training von Grund auf erreicht das mehrstufige Training das Ziel einer qualitativ hochwertigen Videogenerierung effizienter, indem die Daten schrittweise erweitert werden.

Dreistufiger Trainingsplan
Die erste Stufe: groß angelegtes Bild-Vortraining
Die erste Stufe verwendet ein groß angelegtes Bild-Vortraining und nutzt das ausgereifte Vincentian-Grafikmodell, um die Kosten für das Video-Vortraining effektiv zu senken.
Das Autorenteam hat uns gezeigt, dass wir durch die umfangreichen, großformatigen Bilddaten im Internet und die fortschrittliche Vincent-Graph-Technologie ein hochwertiges Vincent-Graph-Modell trainieren können, das als Initialisierungsgewicht für die nächste Stufe dient des Video-Vortrainings. Da es derzeit keine qualitativ hochwertige räumlich-zeitliche VAE gibt, verwendeten sie gleichzeitig die durch das Stable Diffusion-Modell [5] vorab trainierte Bild-VAE. Diese Strategie stellt nicht nur die überlegene Leistung des ursprünglichen Modells sicher, sondern reduziert auch die Gesamtkosten für das Video-Vortraining erheblich.
Die zweite Stufe: groß angelegtes Video-Vortraining
Die zweite Stufe führt ein groß angelegtes Video-Vortraining durch, um die Fähigkeit zur Modellverallgemeinerung zu verbessern und die Zeitreihenkorrelation von Videos effektiv zu erfassen.
Wir verstehen, dass diese Phase eine große Menge an Videodatentraining erfordert, um die Vielfalt der Videothemen sicherzustellen und dadurch die Generalisierungsfähigkeit des Modells zu erhöhen. Das Modell der zweiten Stufe fügt dem vinzentinischen Graphenmodell der ersten Stufe ein zeitliches Aufmerksamkeitsmodul hinzu, um zeitliche Beziehungen in Videos zu lernen. Die verbleibenden Module bleiben mit der ersten Stufe konsistent und laden die Gewichte der ersten Stufe als Initialisierung, während die Ausgabe des zeitlichen Aufmerksamkeitsmoduls auf Null initialisiert wird, um eine effizientere und schnellere Konvergenz zu erreichen. Das Colossal-AI-Team verwendete Open-Source-Gewichte von PixArt-alpha [2] als Initialisierung für das STDiT-Modell der zweiten Stufe und das T5-Modell [6] als Text-Encoder. Gleichzeitig verwendeten sie für das Vortraining eine kleine Auflösung von 256 x 256, was die Konvergenzgeschwindigkeit weiter erhöhte und die Trainingskosten senkte.
Die dritte Stufe: Feinabstimmung hochwertiger Videodaten
Die dritte Stufe optimiert hochwertige Videodaten, um die Qualität der Videogenerierung deutlich zu verbessern.
Das Autorenteam erwähnte, dass die Größe der in der dritten Stufe verwendeten Videodaten eine Größenordnung geringer ist als die in der zweiten Stufe, aber die Länge, Auflösung und Qualität des Videos sind höher. Durch diese Feinabstimmung erreichten sie eine effiziente Skalierung der Videoerzeugung von kurz auf lang, von niedriger auf hohe Auflösung und von niedriger auf hohe Wiedergabetreue.
Das Autorenteam gab an, dass sie im Open-Sora-Reproduktionsprozess 64 H800-Blöcke für das Training verwendet haben. Das Gesamttrainingsvolumen der zweiten Stufe beträgt 2808 GPU-Stunden, was etwa 7000 US-Dollar entspricht, und das Trainingsvolumen der dritten Stufe beträgt 1920 GPU-Stunden, was etwa 4500 US-Dollar entspricht. Nach vorläufigen Schätzungen kontrollierte das gesamte Trainingsprogramm den Open-Sora-Reproduktionsprozess erfolgreich auf etwa 10.000 US-Dollar.
Datenvorverarbeitung
Um den Schwellenwert und die Komplexität der Sora-Reproduktion weiter zu reduzieren, stellt das Colossal-AI-Team außerdem ein praktisches Videodaten-Vorverarbeitungsskript im Code Warehouse bereit, sodass jeder problemlos mit der Sora-Reproduktion Pre beginnen kann -Das Training umfasst das Herunterladen öffentlicher Videodatensätze, das Segmentieren langer Videos in kurze Videoclips basierend auf der Aufnahmekontinuität und die Verwendung des Open-Source-Großsprachenmodells LLaVA [7] zur Generierung präziser Aufforderungswörter. Das Autorenteam erwähnte, dass der von ihm bereitgestellte Code zur Batch-Videotitelgenerierung ein Video mit zwei Karten und 3 Sekunden mit Anmerkungen versehen kann und die Qualität nahe an GPT-4V liegt. Die resultierenden Video-/Textpaare können direkt für das Training verwendet werden. Mit dem Open-Source-Code, den sie auf GitHub bereitstellen, können wir einfach und schnell die für das Training erforderlichen Video-/Textpaare auf unserem eigenen Datensatz generieren und so den technischen Schwellenwert und die vorbereitende Vorbereitung für den Start eines Sora-Replikationsprojekts erheblich reduzieren.

Video-/Textpaar wird automatisch basierend auf einem Datenvorverarbeitungsskript generiert
Anzeige des Modellgenerierungseffekts
Werfen wir einen Blick auf den tatsächlichen Videogenerierungseffekt von Open-Sora. Lassen Sie Open-Sora beispielsweise Luftaufnahmen von Meerwasser erstellen, das an Felsen an einer Klippenküste plätschert.

Lassen Sie Open-Sora die majestätische Luftaufnahme von Bergen und Wasserfällen einfangen, die von den Klippen herabstürzen und schließlich in den See fließen.

Sie können nicht nur in den Himmel fliegen, sondern auch ins Meer gehen und Open-Sora eine Aufnahme der Unterwasserwelt erstellen lassen die Korallenriffe.

Open-Sora kann uns durch Zeitrafferfotografie auch die Milchstraße mit funkelnden Sternen zeigen.

Wenn Sie weitere interessante Ideen für die Videogenerierung haben, können Sie die Open-Source-Community Open-Sora besuchen, um die Modellgewichte für ein kostenloses Erlebnis zu erhalten. Link: https://github.com/hpcaitech/Open-Sora
Es ist erwähnenswert, dass das Autorenteam auf Github erwähnt hat, dass die aktuelle Version nur 400.000 Trainingsdaten verwendet, die Generierungsqualität des Modells und die Fähigkeit, Text zu folgen Alles muss verbessert werden. Im obigen Schildkrötenvideo hat die resultierende Schildkröte beispielsweise ein zusätzliches Bein. Open-Sora 1.0 ist auch nicht gut darin, Porträts und komplexe Bilder zu erstellen. Das Autorenteam listete eine Reihe von Plänen auf, die auf Github umgesetzt werden sollen und die darauf abzielen, bestehende Mängel kontinuierlich zu beheben und die Qualität der Produktion zu verbessern.
Effiziente Trainingsunterstützung
Neben der deutlichen Reduzierung der technischen Schwelle für die Sora-Wiedergabe und der Verbesserung der Qualität der Videogenerierung in mehreren Dimensionen wie Dauer, Auflösung und Inhalt sorgt das Autorenteam auch für die Colossal-AI-Beschleunigung System zur Sora-Reproduktion. Durch effiziente Trainingsstrategien wie Bedieneroptimierung und Hybridparallelität wurde beim Training der Verarbeitung von Videos mit 64 Bildern und einer Auflösung von 512 x 512 ein 1,55-facher Beschleunigungseffekt erzielt. Gleichzeitig kann dank des heterogenen Speicherverwaltungssystems von Colossal-AI eine einminütige 1080p-HD-Video-Trainingsaufgabe ungehindert auf einem einzigen Server (8*H800) durchgeführt werden.
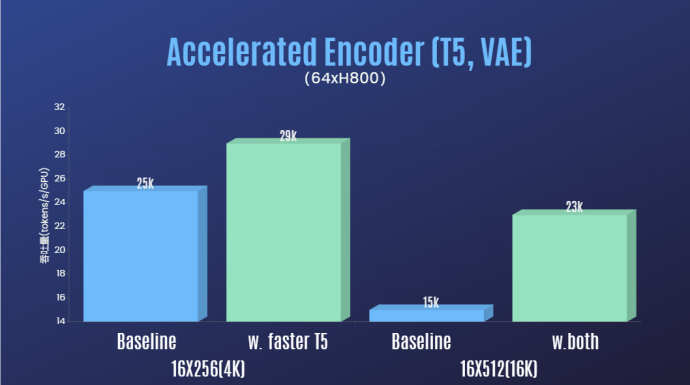
Darüber hinaus haben wir im Bericht des Autorenteams auch festgestellt, dass die STDiT-Modellarchitektur auch beim Training eine hervorragende Effizienz zeigte. Im Vergleich zu DiT, das einen vollständigen Aufmerksamkeitsmechanismus verwendet, erreicht STDiT eine bis zu fünffache Beschleunigung mit zunehmender Anzahl von Bildern, was besonders bei realen Aufgaben wie der Verarbeitung langer Videosequenzen von entscheidender Bedeutung ist.
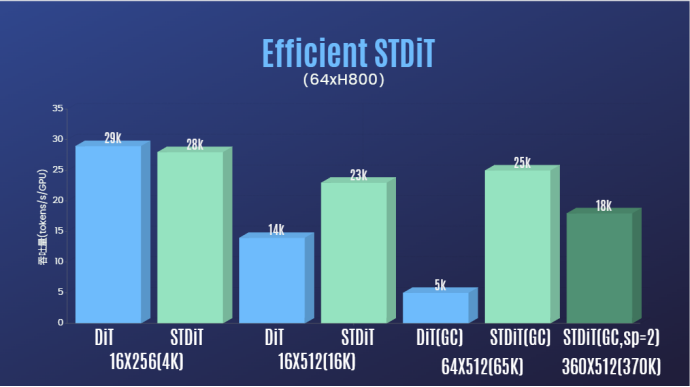
Willkommen, weiterhin auf das Open-Source-Projekt Open-Sora zu achten: https://github.com/hpcaitech/Open-Sora
Das Autorenteam gab an, dass es weiterhin pflegen und optimieren wird Das Open-Sora-Projekt wird voraussichtlich mehr Videotrainingsdaten verwenden, um qualitativ hochwertigere, längere Videoinhalte zu generieren und Funktionen mit mehreren Auflösungen zu unterstützen, um die Implementierung der KI-Technologie in Filmen, Spielen, Werbung und anderen Bereichen effektiv zu fördern.
Referenzlink:
[1] https://arxiv.org/abs/2212.09748 Skalierbare Diffusionsmodelle mit Transformatoren.
[2] https://arxiv.org/abs/2310.00426 PixArt-α: Schnelles Training des Diffusionstransformators für die fotorealistische Text-zu-Bild-Synthese.
[3] https://arxiv.org/abs/2311.15127 Stabile Videodiffusion: Skalierung latenter Videodiffusionsmodelle auf große Datensätze.
[4] https://arxiv.org/abs/2401.03048 Latte: Latent Diffusion Transformer für die Videoerzeugung.
[5] https://huggingface.co/stabilityai/sd-vae-ft-mse-original.
[6] https://github.com/google-research/text-to-text-transfer-transformer.
[7] https://github.com/haotian-liu/LLaVA.
[8] https://hpc-ai.com/blog/open-sora-v1.0.
Das obige ist der detaillierte Inhalt vonWarten Sie nicht auf OpenAI, sondern darauf, dass Open-Sora vollständig Open Source ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
 SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
Laut Nachrichten dieser Website vom 1. August hat SK Hynix heute (1. August) einen Blogbeitrag veröffentlicht, in dem es ankündigt, dass es am Global Semiconductor Memory Summit FMS2024 teilnehmen wird, der vom 6. bis 8. August in Santa Clara, Kalifornien, USA, stattfindet viele neue Technologien Generation Produkt. Einführung des Future Memory and Storage Summit (FutureMemoryandStorage), früher Flash Memory Summit (FlashMemorySummit), hauptsächlich für NAND-Anbieter, im Zusammenhang mit der zunehmenden Aufmerksamkeit für die Technologie der künstlichen Intelligenz wurde dieses Jahr in Future Memory and Storage Summit (FutureMemoryandStorage) umbenannt Laden Sie DRAM- und Speicheranbieter und viele weitere Akteure ein. Neues Produkt SK Hynix wurde letztes Jahr auf den Markt gebracht
