
 Technologie-Peripheriegeräte
KI
Eine clevere Lösung für das Problem der „Datenknappheit'! Tsinghua Open Source GPD: Verwendung eines Diffusionsmodells zur Generierung neuronaler Netzwerkparameter
Technologie-Peripheriegeräte
KI
Eine clevere Lösung für das Problem der „Datenknappheit'! Tsinghua Open Source GPD: Verwendung eines Diffusionsmodells zur Generierung neuronaler Netzwerkparameter
Eine clevere Lösung für das Problem der „Datenknappheit'! Tsinghua Open Source GPD: Verwendung eines Diffusionsmodells zur Generierung neuronaler Netzwerkparameter

Herkömmliche räumlich-zeitliche Vorhersagemodelle erfordern normalerweise eine große Menge an Datenunterstützung, um gute Ergebnisse zu erzielen.
Allerdings sind raumzeitliche Daten (z. B. Verkehrs- und Massenstromdaten) in vielen Bereichen aufgrund unterschiedlicher Entwicklungsniveaus verschiedener Städte und inkonsistenter Datenerfassungsrichtlinien begrenzt. Daher wird die Übertragbarkeit von Modellen besonders wichtig, wenn Daten knapp sind.
Die aktuelle Forschung stützt sich hauptsächlich auf Daten aus Quellstädten, um Modelle zu trainieren und sie auf Daten aus Zielstädten anzuwenden. Dieser Ansatz erfordert jedoch häufig komplexe Matching-Designs. Wie ein breiterer Wissenstransfer zwischen Quell- und Zielstädten erreicht werden kann, bleibt eine Herausforderung.
In letzter Zeit haben vorab trainierte Modelle erhebliche Fortschritte in den Bereichen Verarbeitung natürlicher Sprache und Computer Vision gemacht. Die Einführung der Prompt-Technologie verringert die Lücke zwischen Feinabstimmung und Vortraining, sodass sich fortschrittliche vorab trainierte Modelle schneller an neue Aufgaben anpassen können. Der Vorteil dieser Methode besteht darin, dass sie die Abhängigkeit von mühsamer Feinabstimmung reduziert und die Effizienz und Flexibilität des Modells verbessert. Durch die schnelle Technologie können Modelle die Bedürfnisse der Benutzer besser verstehen und genauere Ergebnisse liefern, wodurch den Menschen bessere Erfahrungen und Dienste geboten werden. Dieser innovative Ansatz treibt die Entwicklung der Technologie der künstlichen Intelligenz voran und eröffnet verschiedenen Branchen mehr Möglichkeiten und Chancen.
 Bilder
Bilder
Papierlink: https://openreview.net/forum?id=QyFm3D3Tzi
Offener Quellcode und Daten: https://www.php.cn/link/6644cb08d30b2ca55c284344a9750c2e
La Testveröffentlichung unter ICLR2024 Das Ergebnis „Spatio-Temporal Few-Shot Learning via Diffusive Neural Network Generation“ des Urban Science and Computing Research Center des Department of Electronic Engineering der Tsinghua University führte das GPD-Modell (Generative Pre-Trained Diffusion) ein und realisierte erfolgreich räumliche zeitliches Lernen in spärlichen Datenszenarien.
Diese Methode nutzt die Parameter des generativen neuronalen Netzwerks, um räumlich-zeitliches Lernen mit spärlichen Daten in ein generatives Vortrainingsproblem des Diffusionsmodells umzuwandeln. Im Gegensatz zu herkömmlichen Methoden erfordert diese Methode nicht mehr das Extrahieren übertragbarer Merkmale oder das Entwerfen komplexer Mustervergleichsstrategien, noch muss eine gute Modellinitialisierung für Szenarien mit wenigen Schüssen erlernt werden.
Stattdessen erlernt diese Methode Wissen über die Parameteroptimierung neuronaler Netzwerke durch Vortraining auf Daten aus der Quellstadt und generiert dann basierend auf Eingabeaufforderungen ein für die Zielstadt geeignetes neuronales Netzwerkmodell.
Die Innovation dieser Methode besteht darin, dass sie auf der Grundlage von „Eingabeaufforderungen“ maßgeschneiderte neuronale Netze generieren, sich effektiv an die Unterschiede in der Datenverteilung und den Merkmalen zwischen verschiedenen Städten anpassen und einen ausgeklügelten räumlich-zeitlichen Wissenstransfer erreichen kann.
Diese Forschung liefert neue Ideen zur Lösung des Problems der Datenknappheit im Urban Computing. Die Daten und der Code des Papiers sind Open Source.
Von der Datenverteilung zur neuronalen Netzwerkparameterverteilung
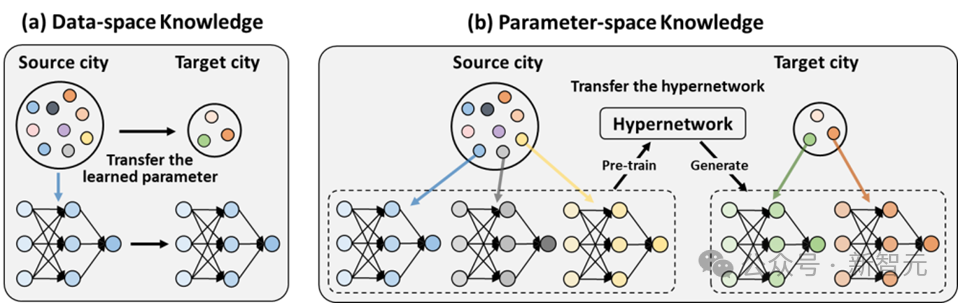 Abbildung 1: Wissenstransfer auf Datenmusterebene vs. Wissenstransfer auf neuronaler Netzwerkebene
Abbildung 1: Wissenstransfer auf Datenmusterebene vs. Wissenstransfer auf neuronaler Netzwerkebene
Wie in Abbildung 1(a) gezeigt, ist die traditionelle Wissenstransfermethode normalerweise am Quelle Trainieren Sie das Modell anhand von Stadtdaten und wenden Sie es dann auf die Zielstadt an. Es kann jedoch erhebliche Unterschiede in der Datenverteilung zwischen verschiedenen Städten geben, was zu einer direkten Migration des Quellstadtmodells führt, das möglicherweise nicht gut mit der Datenverteilung der Zielstadt übereinstimmt.
Deshalb müssen wir unsere Abhängigkeit von der unordentlichen Datenverteilung aufgeben und nach einer grundlegenderen und übertragbareren Möglichkeit des Wissensaustauschs suchen. Im Vergleich zur Datenverteilung weist die Verteilung neuronaler Netzwerkparameter mehr Merkmale „höherer Ordnung“ auf.
Abbildung 1 zeigt den Transformationsprozess von der Datenmusterebene zum Wissenstransfer auf neuronaler Netzwerkebene. Durch das Training eines neuronalen Netzwerks anhand von Daten aus einer Quellstadt und deren Umwandlung in einen Prozess zur Generierung neuronaler Netzwerkparameter, die an die Zielstadt angepasst sind, können die Datenverteilung und die Eigenschaften der Zielstadt besser angepasst werden.
Vortraining + schnelle Feinabstimmung: Erzielen des räumlich-zeitlichen Lernens mit wenigen Schüssen Entwickelt, um Daten aus Quellstädten direkt zu generieren und neue Modellparameter für die Zielstadt zu generieren:
1 Vorbereitungsphase des neuronalen Netzwerks: Zunächst trainiert die Studie a Separates räumlich-zeitliches Vorhersagemodell und Speichern seiner optimierten Netzwerkparameter. Die Modellparameter für jede Region werden unabhängig und ohne Parameterfreigabe optimiert, um sicherzustellen, dass sich das Modell optimal an die Merkmale der jeweiligen Region anpassen kann. 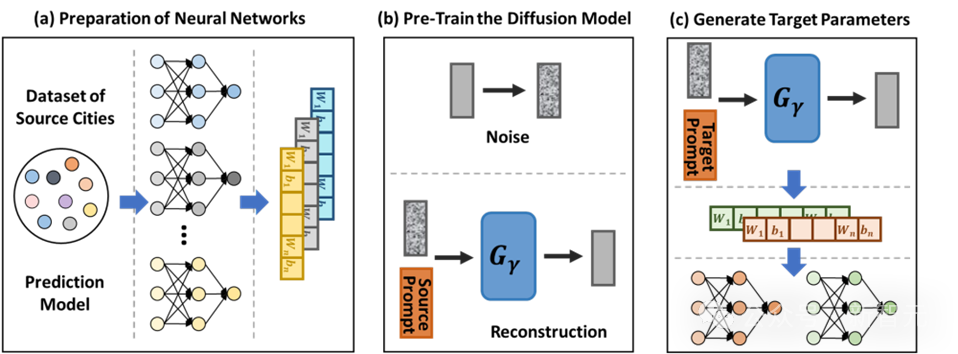
2. Vortraining des Diffusionsmodells: Dieses Framework verwendet die gesammelten vorab trainierten Modellparameter als Trainingsdaten, um das Diffusionsmodell zu trainieren und den Prozess der Modellparametergenerierung zu erlernen. Das Diffusionsmodell generiert Parameter durch schrittweises Entrauschen, ein Prozess, der dem Parameteroptimierungsprozess ab einer zufälligen Initialisierung ähnelt, und ist daher besser in der Lage, sich an die Datenverteilung der Zielstadt anzupassen.
3. Generierung neuronaler Netzwerkparameter: Nach dem Vortraining können Parameter mithilfe regionaler Hinweise der Zielstadt generiert werden. Dieser Ansatz nutzt Hinweise, um den Wissenstransfer und den präzisen Parameterabgleich zu erleichtern und dabei die Ähnlichkeiten zwischen Stadtregionen voll auszunutzen.
Es ist erwähnenswert, dass im Rahmen der Feinabstimmung der Cues vor dem Training die Auswahl der Cues sehr flexibel ist, solange sie die Merkmale einer bestimmten Region erfassen kann. Hierzu können beispielsweise verschiedene statische Merkmale wie Bevölkerung, regionale Fläche, Funktionen und Verteilung von Points of Interest (POIs) genutzt werden.
Diese Arbeit nutzt regionale Hinweise sowohl aus räumlichen als auch aus zeitlichen Aspekten: Räumliche Hinweise stammen aus Knotendarstellungen in städtischen Wissensgraphen [1,2], die nur Beziehungen wie regionale Nachbarschaft und funktionale Ähnlichkeit nutzen, die in allen Städten leicht vorkommen zugänglich; die zeitlichen Hinweise stammen vom Encoder des selbstüberwachten Lernmodells. Weitere Informationen zum Prompt-Design finden Sie im Originalartikel.
Darüber hinaus untersuchte diese Studie auch verschiedene Methoden zur Einführung von Hinweisen, und Experimente bestätigten, dass die Einführung von Hinweisen auf der Grundlage von Vorkenntnissen die optimale Leistung erbringt: Verwendung räumlicher Hinweise zur Steuerung der Generierung neuronaler Netzwerkparameter zur Modellierung räumlicher Korrelation und Verwendung zeitlicher Hinweise dazu Leitfaden für die Generierung von Netzwerkparametern im temporalen neuronalen Netzwerk.
Experimentelle Ergebnisse
Das Team beschrieb die experimentellen Einstellungen im Papier ausführlich, um anderen Forschern die Reproduktion ihrer Ergebnisse zu erleichtern. Sie stellten auch das Originalpapier und den Open-Source-Datencode zur Verfügung, auf deren experimentelle Ergebnisse wir uns hier konzentrieren.
Um die Wirksamkeit des vorgeschlagenen Rahmenwerks zu bewerten, wurden in dieser Studie Experimente zu zwei Arten klassischer räumlich-zeitlicher Vorhersageaufgaben durchgeführt: Vorhersage des Menschenstroms und Vorhersage der Verkehrsgeschwindigkeit, wobei mehrere Stadtdatensätze abgedeckt wurden.
 Bilder
Bilder
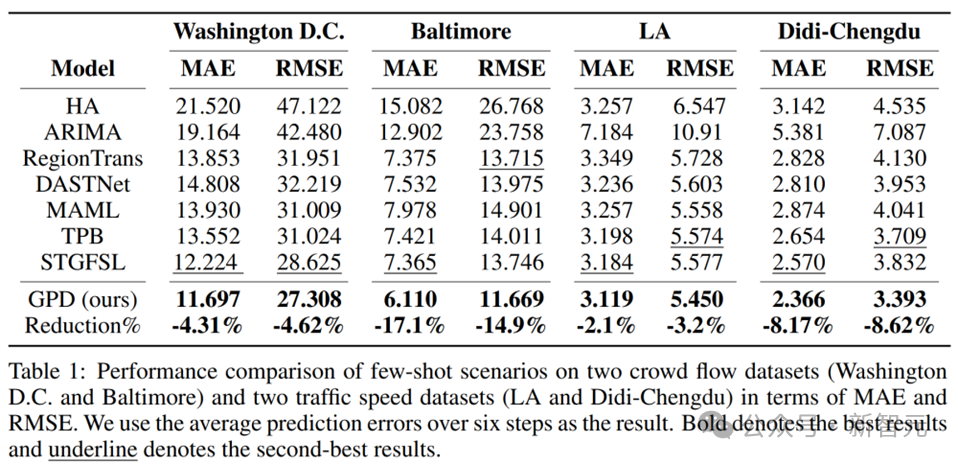
Tabelle 1 zeigt die Vergleichsergebnisse mit modernsten Basismethoden für vier Datensätze. Basierend auf diesen Ergebnissen können die folgenden Beobachtungen gemacht werden:
1) GPD weist erhebliche Leistungsvorteile gegenüber dem Basismodell auf und schneidet in verschiedenen Datenszenarien durchweg besser ab, was darauf hindeutet, dass GPD einen effektiven Wissenstransfer auf der Ebene der neuronalen Netzwerkparameter erreicht.
2) GPD schneidet in langfristigen Vorhersageszenarien gut ab. Dieser bedeutende Trend ist auf die Gewinnung wesentlicherer Kenntnisse durch das Framework zurückzuführen, was dazu beiträgt, langfristiges raumzeitliches Musterwissen auf Zielstädte zu übertragen.
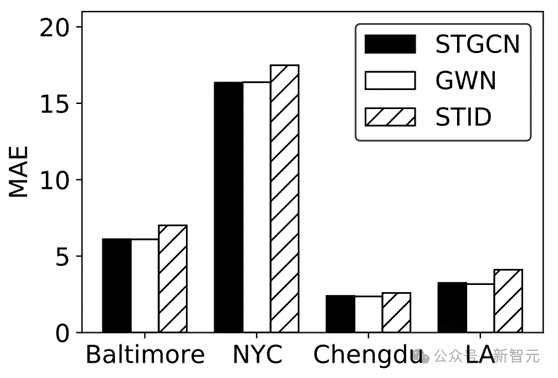 Abbildung 3 Leistungsvergleich verschiedener raumzeitlicher Vorhersagemodelle
Abbildung 3 Leistungsvergleich verschiedener raumzeitlicher Vorhersagemodelle
Darüber hinaus überprüfte diese Studie auch die Flexibilität des GPD-Frameworks für die Anpassung verschiedener raumzeitlicher Vorhersagemodelle. Zusätzlich zur klassischen raumzeitlichen Graphenmethode STGCN werden in dieser Studie auch GWN und STID als raumzeitliche Vorhersagemodelle eingeführt und ein Diffusionsmodell zur Generierung ihrer Netzwerkparameter verwendet.
Experimentelle Ergebnisse zeigen, dass die Überlegenheit des Frameworks durch die Modellauswahl nicht beeinträchtigt wird, sodass es an verschiedene fortgeschrittene Modelle angepasst werden kann.
Darüber hinaus führt die Studie eine Fallanalyse durch, indem sie die Musterähnlichkeit in zwei synthetischen Datensätzen manipuliert.
Abbildung 4 zeigt, dass die Regionen A und B sehr ähnliche Zeitreihenmuster aufweisen, während Region C deutlich unterschiedliche Muster aufweist. Abbildung 5 zeigt, dass die Knoten A und B symmetrische räumliche Positionen haben.
Daher können wir schließen, dass die Regionen A und B sehr ähnliche räumlich-zeitliche Muster aufweisen, während es deutliche Unterschiede zu C gibt. Die vom Modell generierten Ergebnisse der Parameterverteilung des neuronalen Netzwerks zeigen, dass die Parameterverteilungen von A und B ähnlich sind, sich jedoch erheblich von der Parameterverteilung von C unterscheiden. Dies bestätigt weiter die Fähigkeit des GPD-Frameworks, neuronale Netzwerkparameter mit unterschiedlichen räumlich-zeitlichen Mustern effektiv zu generieren.
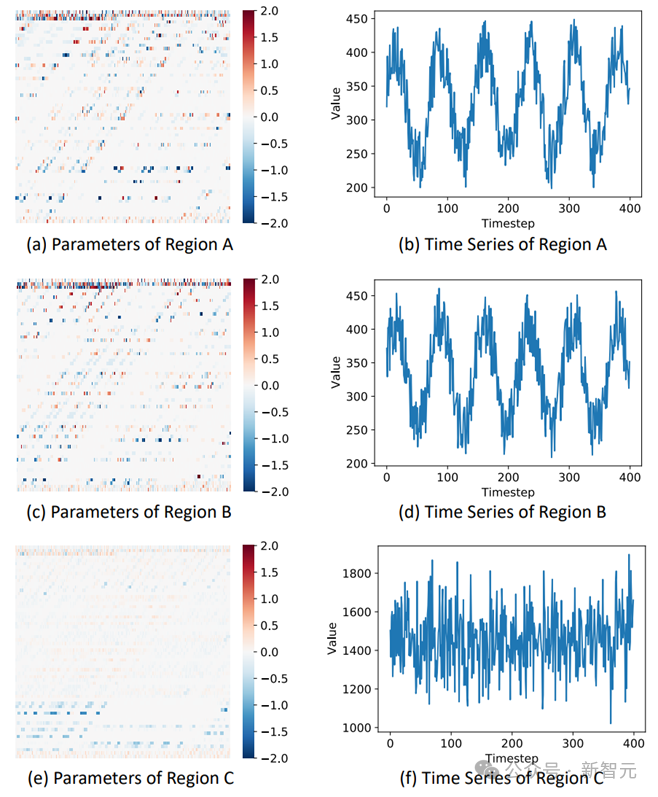
Abbildung 4 Visualisierung von Zeitreihen und neuronaler Netzwerkparameterverteilung in verschiedenen Regionen
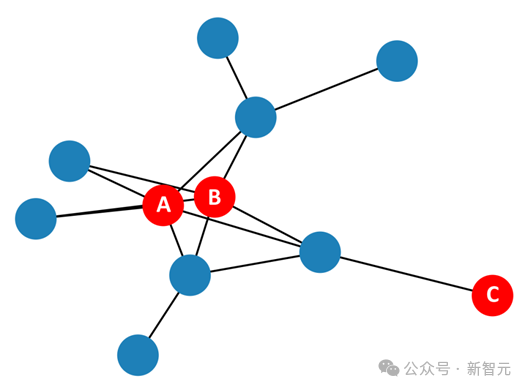
Abbildung 5 Regionale räumliche Verbindungsbeziehung des Simulationsdatensatzes
Referenz:
https://www.php.cn / link/6644cb08d30b2ca55c284344a9750c2e
[1] Liu, Yu, et al. „Urbankg: An urban Knowledge Graph System 14.4 (2023): 1-25.
[2] Zhou, Zhilun, et al. „Hierarchisches Wissensgraphenlernen ermöglichte die Vorhersage sozioökonomischer Indikatoren in standortbasierten sozialen Netzwerken.“
Das obige ist der detaillierte Inhalt vonEine clevere Lösung für das Problem der „Datenknappheit'! Tsinghua Open Source GPD: Verwendung eines Diffusionsmodells zur Generierung neuronaler Netzwerkparameter. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1677
1677
 14
1431
52
1334
25
1280
29
1257
24
14
1431
52
1334
25
1280
29
1257
24

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden können. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir auf metrische Relativwerte schließen
