
 Technologie-Peripheriegeräte
KI
Stability AI Open-Source-Neuveröffentlichung: 3D-Generierung führt Videodiffusionsmodell ein, Qualitätskonsistenz erhöht, 4090 spielbar
Technologie-Peripheriegeräte
KI
Stability AI Open-Source-Neuveröffentlichung: 3D-Generierung führt Videodiffusionsmodell ein, Qualitätskonsistenz erhöht, 4090 spielbar
Stability AI Open-Source-Neuveröffentlichung: 3D-Generierung führt Videodiffusionsmodell ein, Qualitätskonsistenz erhöht, 4090 spielbar

Stability AI, das Unternehmen hinter Stable Diffusion, hat etwas Neues auf den Markt gebracht.
Diese Zeit bringt neue Fortschritte in der 3D-Grafik:
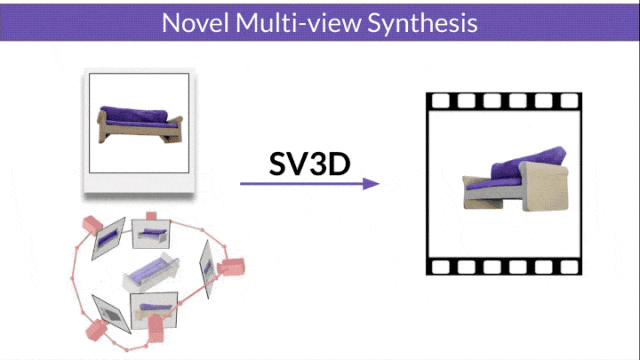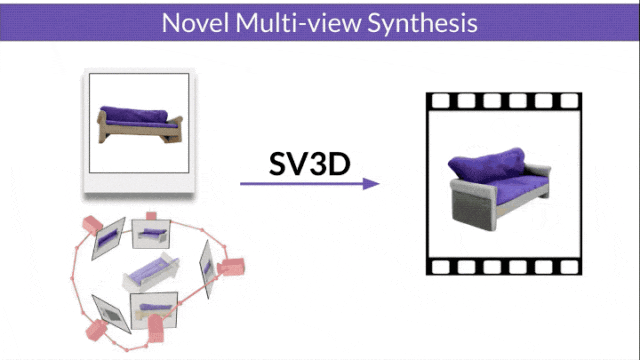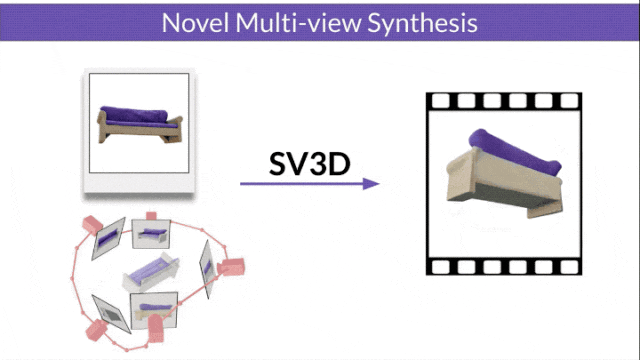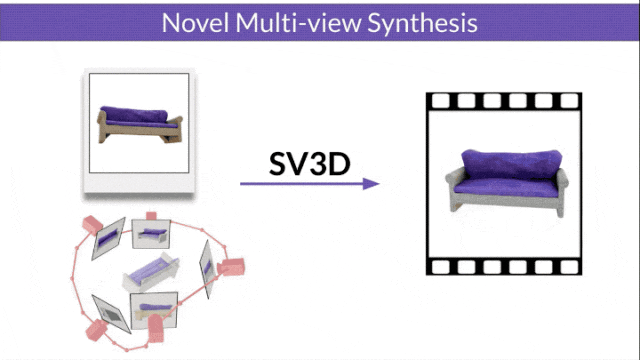
Stable Video 3D (SV3D) basierend auf Stable Video Diffusion kann mit nur einem Bild hochwertige 3D-Netze erzeugen.

Stable Video Diffusion (SVD) ist ein zuvor von Stability AI veröffentlichtes Modell zur Generierung hochauflösender Videos. Die Einführung von SV3D markiert das erste Mal, dass das Videodiffusionsmodell erfolgreich auf den Bereich der 3D-Generierung angewendet wurde.
Offiziell heißt es, dass SV3D auf dieser Grundlage die Qualität und Ansichtskonsistenz der 3D-Generierung erheblich verbessert hat.

Die Modellgewichte sind weiterhin Open Source, können aber nur für nichtkommerzielle Zwecke genutzt werden. Wenn Sie sie kommerziell nutzen möchten, müssen Sie eine Stability AI-Mitgliedschaft erwerben. ~
Nehmen wir es ohne weiteres Schauen Sie sich die Details des Papiers an.
Verwendung des Videodiffusionsmodells für die 3D-Generierung
Bei der Einführung des latenten Videodiffusionsmodells besteht der Hauptzweck von SV3D darin, die zeitliche Konsistenz des Videomodells zu nutzen, um die Konsistenz der 3D-Generierung zu verbessern.
Und auch die Videodaten selbst sind einfacher zu erhalten als 3D-Daten.
Stability AI bietet dieses Mal zwei Versionen von SV3D:
- SV3D_u: Orbitalvideo basierend auf einem einzelnen Bild generieren.
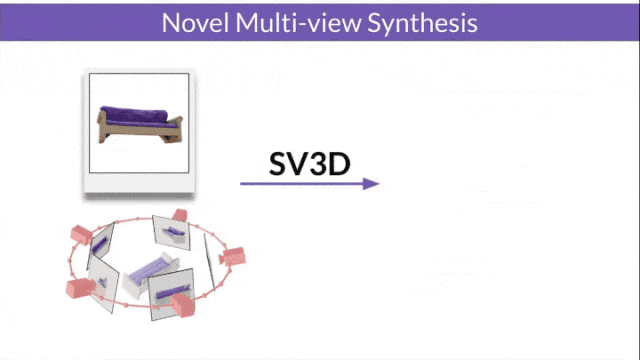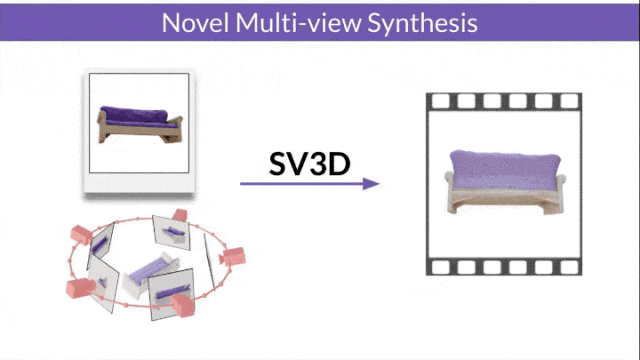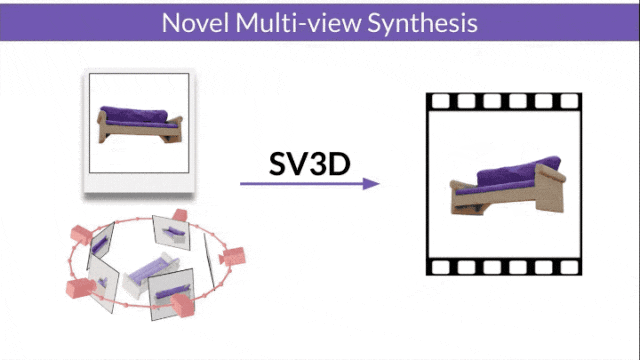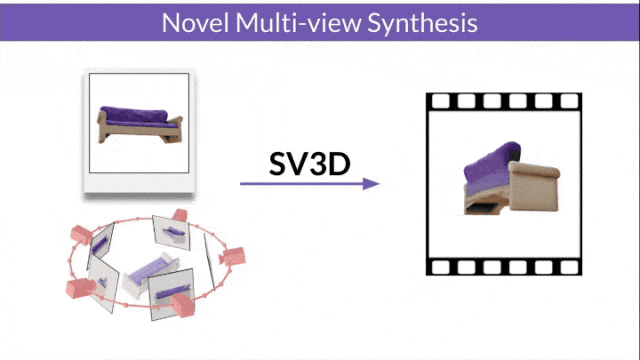
- SV3D_p: Erweitert die Funktionalität von SV3D_u, um 3D-Modellvideos basierend auf angegebenen Kamerapfaden zu erstellen.
Die Forscher verbesserten auch die 3D-Optimierungstechnologie: Mithilfe einer Grob-zu-Fein-Trainingsstrategie optimierten sie NeRF- und DMTet-Netze, um 3D-Objekte zu generieren.
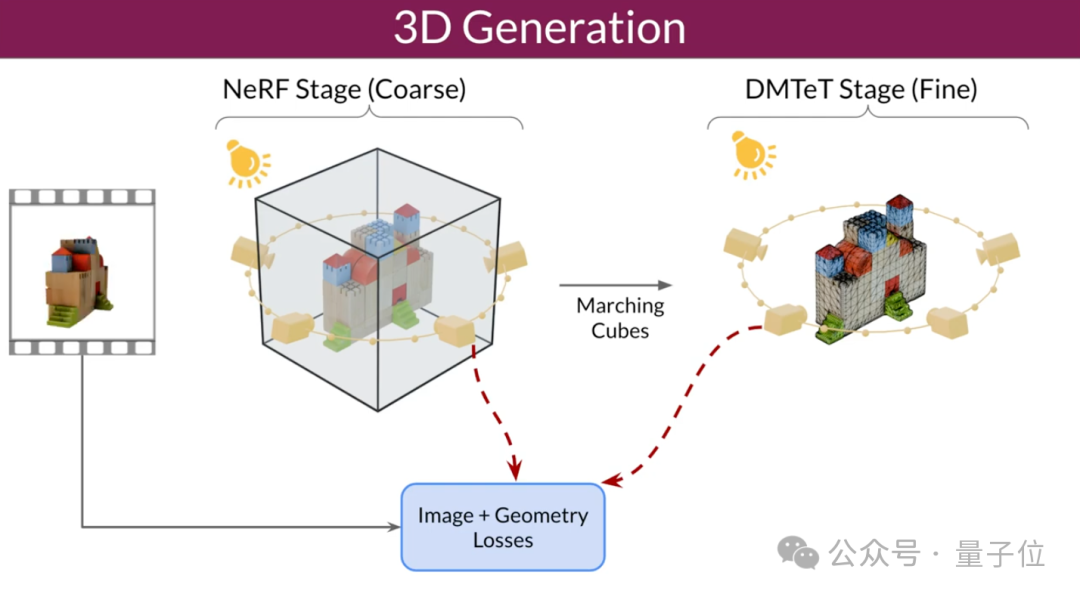
Sie haben außerdem eine spezielle Verlustfunktion namens Masked Score Distillation Sampling (SDS) entwickelt, um die Qualität und Konsistenz der generierten 3D-Modelle durch Optimierung von Bereichen zu verbessern, die in den Trainingsdaten nicht direkt sichtbar sind.
Gleichzeitig führt SV3D ein Beleuchtungsmodell ein, das auf sphärischem Gauß basiert, um Lichteffekte und Texturen zu trennen und so integrierte Beleuchtungsprobleme effektiv zu reduzieren und gleichzeitig die Klarheit der Texturen beizubehalten.
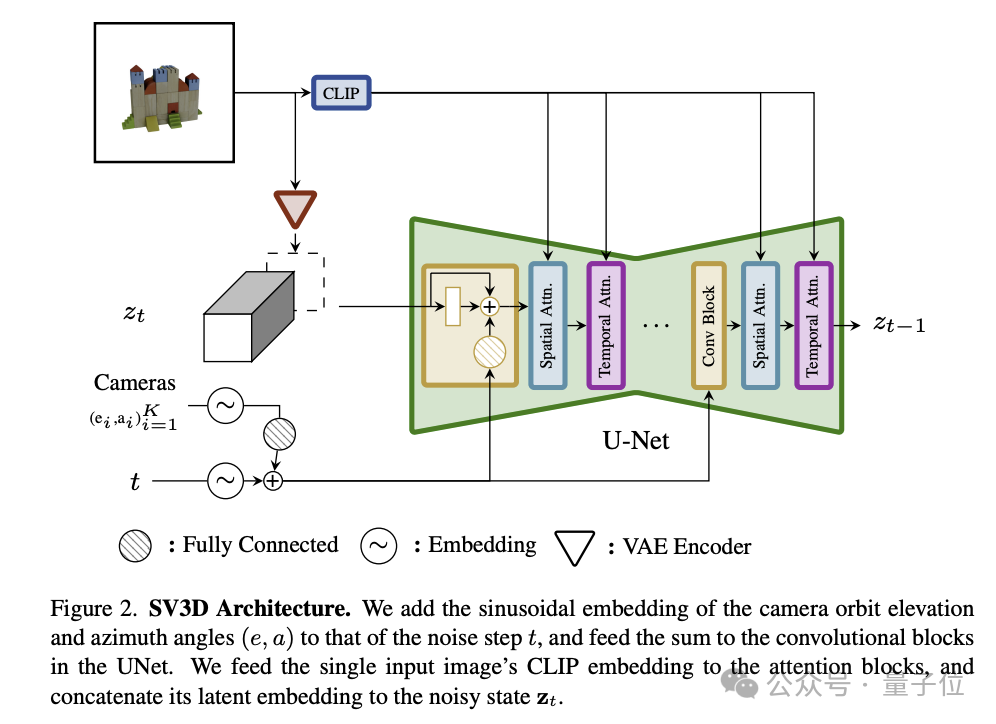
Insbesondere in Bezug auf die Architektur enthält SV3D die folgenden Schlüsselkomponenten:
- UNet: SV3D basiert auf SVD und enthält ein mehrschichtiges UNet, wobei jede Schicht eine Reihe von Restblöcken aufweist (einschließlich 3D-Faltungsschicht) und zwei Transformer-Module, die räumliche bzw. zeitliche Informationen verarbeiten.
- Bedingte Eingabe: Das Eingabebild wird über den VAE-Encoder in den latenten Raum eingebettet und mit dem latenten Rauschzustand zusammengeführt und zusammen in UNet eingegeben. Die CLIP-Einbettungsmatrix des Eingabebildes wird als Schlüssel für jeden Transformator verwendet Wertepaar der Queraufmerksamkeitsebene des Moduls.
- Kodierung der Kameratrajektorie: SV3D hat zwei Arten von Trajektorien entwickelt, statisch und dynamisch, um die Auswirkungen von Kameralagebedingungen zu untersuchen. In einer statischen Umlaufbahn umgibt die Kamera das Objekt in regelmäßigen Azimutwinkeln. In einer dynamischen Umlaufbahn ermöglicht die Kamera unregelmäßig verteilte Azimutwinkel und unterschiedliche Höhenwinkel.
Die Bewegungsbahninformationen der Kamera und die Zeitinformationen des Diffusionsrauschens werden zusammen in das Restmodul eingegeben und in eine sinusförmige Positionseinbettung umgewandelt. Anschließend werden diese Einbettungsinformationen integriert und linear transformiert und zur Rauschzeit addiert Stufeneinbettung.
Ein solches Design zielt darauf ab, die Fähigkeit des Modells zur Bildverarbeitung zu verbessern, indem Kamerabahnen und Rauscheinträge genau gesteuert werden.
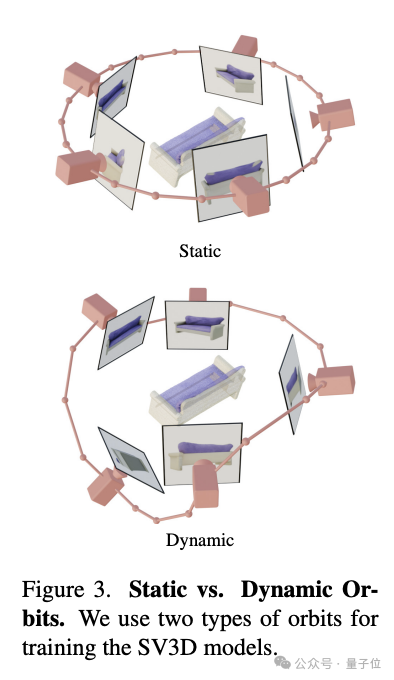
Darüber hinaus verwendet SV3D während des Generierungsprozesses CFG (klassifikatorfreie Führung), um die Schärfe der Generierung zu steuern, insbesondere bei der Generierung der letzten Frames der Spur wird die Dreieck-CFG-Skalierung verwendet, um eine Überschärfung zu vermeiden .
Die Forscher trainierten SV3D auf dem Objaverse-Datensatz mit einer Bildauflösung von 575×576 und einem Sichtfeld von 33,8 Grad. Aus dem Papier geht hervor, dass alle drei Modelle (SV3D_u, SV3D_c, SV3D_p) etwa 6 Tage lang auf 4 Knoten trainiert wurden, wobei jeder Knoten mit 8 80-GB-A100-GPUs ausgestattet war.
Experimentelle Ergebnisse
In Bezug auf neue Perspektivensynthese (NVS) und 3D-Rekonstruktion übertrifft SV3D andere bestehende Methoden und erreicht SOTA.
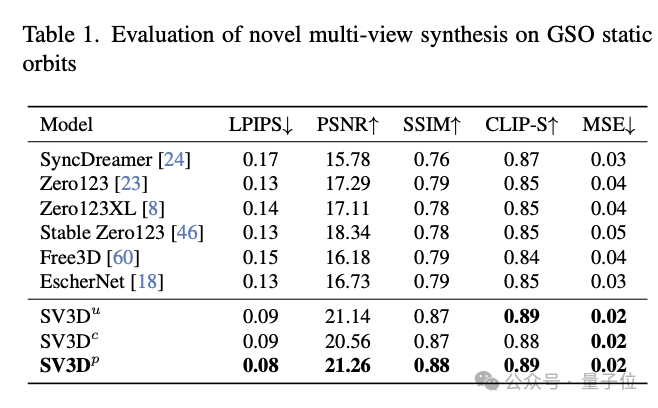
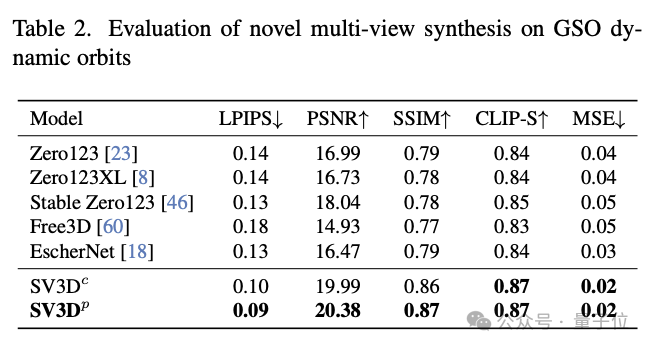
Den Ergebnissen des qualitativen Vergleichs nach zu urteilen, ist die von SV3D generierte Mehrfachansicht detaillierter und näher am ursprünglichen Eingabebild. Mit anderen Worten: SV3D kann Details genauer erfassen und bei Änderungen des Betrachtungswinkels die Konsistenz wahren, um die 3D-Struktur von Objekten zu verstehen und zu rekonstruieren.

Solche Ergebnisse haben die Emotionen vieler Internetnutzer geweckt:
Es ist denkbar, dass in den nächsten 6-12 Monaten die 3D-Generationstechnologie in Spielen und Videoprojekten eingesetzt wird.

Im Kommentarbereich gibt es immer ein paar mutige Ideen...
Und die erste Welle von Freunden hat es bereits gespielt und kann es auf 4090 ausführen.

Referenzlink:
[1]https://twitter.com/StabilityAI/status/1769817136799855098.
[2]https://stability.ai/news/introducing-stable-video-3d.
[3]https://sv3d.github.io/index.html.
Das obige ist der detaillierte Inhalt vonStability AI Open-Source-Neuveröffentlichung: 3D-Generierung führt Videodiffusionsmodell ein, Qualitätskonsistenz erhöht, 4090 spielbar. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1206
24
52
1206
24

 Wie ist die Methode, um Vue.js -Zeichenfolgen in Objekte umzuwandeln?
Apr 07, 2025 pm 09:18 PM
Wie ist die Methode, um Vue.js -Zeichenfolgen in Objekte umzuwandeln?
Apr 07, 2025 pm 09:18 PM
Die Verwendung von JSON.Parse () String to Object ist am sichersten und effizientesten: Stellen Sie sicher, dass die Zeichenfolgen den JSON -Spezifikationen entsprechen, und vermeiden Sie häufige Fehler. Verwenden Sie Try ... Fang, um Ausnahmen zu bewältigen, um die Code -Robustheit zu verbessern. Vermeiden Sie die Verwendung der Methode EVAL (), die Sicherheitsrisiken aufweist. Für riesige JSON -Saiten kann die Analyse oder eine asynchrone Parsen in Betracht gezogen werden, um die Leistung zu optimieren.
 Das Transformer-Autoren-Startup Sakana AI bringt AI Scientist auf den Markt, das erste vollautomatische KI-System für wissenschaftliche Entdeckungen
Aug 13, 2024 pm 04:43 PM
Das Transformer-Autoren-Startup Sakana AI bringt AI Scientist auf den Markt, das erste vollautomatische KI-System für wissenschaftliche Entdeckungen
Aug 13, 2024 pm 04:43 PM
Herausgeber | ScienceAI Vor einem Jahr verließ Llion Jones, der letzte Autor des Transformer-Artikels von Google, das Unternehmen, um ein Unternehmen zu gründen, und gründete zusammen mit dem ehemaligen Google-Forscher David Ha das Unternehmen für künstliche Intelligenz SakanaAI. SakanaAI behauptet, ein neues Basismodell zu schaffen, das auf von der Natur inspirierten Intelligenz basiert! Jetzt hat SakanaAI seinen Antwortbogen eingereicht. SakanaAI kündigt die Einführung von AIScientist an, dem weltweit ersten KI-System für automatisierte wissenschaftliche Forschung und offene Entdeckung! Von der Konzeption, dem Schreiben von Code, der Durchführung von Experimenten und der Zusammenfassung der Ergebnisse bis hin zum Verfassen ganzer Arbeiten und der Durchführung von Peer-Reviews ermöglicht AIScientist KI-gesteuerte wissenschaftliche Forschung und Beschleunigung
 HyperOS 2.0 debütiert mit Xiaomi 15, KI steht im Mittelpunkt
Sep 01, 2024 pm 03:39 PM
HyperOS 2.0 debütiert mit Xiaomi 15, KI steht im Mittelpunkt
Sep 01, 2024 pm 03:39 PM
Kürzlich wurde bekannt, dass Xiaomi im Oktober die mit Spannung erwartete HyperOS 2.0-Version herausbringen wird. 1.HyperOS2.0 wird voraussichtlich gleichzeitig mit dem Xiaomi 15-Smartphone veröffentlicht. HyperOS 2.0 wird die KI-Fähigkeiten insbesondere in der Foto- und Videobearbeitung deutlich verbessern. HyperOS2.0 wird eine modernere und verfeinerte Benutzeroberfläche (UI) mit sich bringen, die flüssigere, klarere und schönere visuelle Effekte bietet. Das HyperOS 2.0-Update enthält außerdem eine Reihe von Verbesserungen der Benutzeroberfläche, wie erweiterte Multitasking-Funktionen, verbesserte Benachrichtigungsverwaltung und mehr Optionen zur Anpassung des Startbildschirms. Die Veröffentlichung von HyperOS 2.0 ist nicht nur ein Beweis für Xiaomis technische Stärke, sondern auch für seine Vision für die Zukunft der Smartphone-Betriebssysteme.
 Der ehemalige Google-Chef Schmidt machte eine überraschende Aussage: KI-Unternehmertum könne zunächst „gestohlen' und später „verarbeitet' werden
Aug 15, 2024 am 11:53 AM
Der ehemalige Google-Chef Schmidt machte eine überraschende Aussage: KI-Unternehmertum könne zunächst „gestohlen' und später „verarbeitet' werden
Aug 15, 2024 am 11:53 AM
Laut Nachrichten dieser Website vom 15. August sorgte eine Rede des ehemaligen Google-CEO und -Vorsitzenden Eric Schmidt gestern an der Stanford University für große Kontroversen. Als er über die zukünftige Entwicklung der künstlichen Intelligenz sprach, sorgte er nicht nur für Kontroversen, als er sagte, Google-Mitarbeiter seien der Meinung, dass „von zu Hause aus zu arbeiten wichtiger sei als zu gewinnen“, und erklärte offen, dass KI-Startups zunächst durch KI-Tools geistiges Eigentum (IP) stehlen können und dann Rechtsanwälte beauftragen, die sich mit Rechtsstreitigkeiten befassen. Schmidt spricht über die Auswirkungen des TikTok-Verbots. Als Beispiel nennt Schmidt die Kurzvideoplattform TikTok und behauptet, dass bei einem Verbot von TikTok jeder KI nutzen könne, um eine ähnliche Anwendung zu generieren und alle Nutzer, sämtliche Musik und andere Inhalte direkt zu stehlen (MakemeacopyofTikTok , stehlen Sie alles
 Wie unterscheidet ich zwischen dem Schließen eines Browser -Registerkartens und dem Schließen des gesamten Browsers mit JavaScript?
Apr 04, 2025 pm 10:21 PM
Wie unterscheidet ich zwischen dem Schließen eines Browser -Registerkartens und dem Schließen des gesamten Browsers mit JavaScript?
Apr 04, 2025 pm 10:21 PM
Wie unterscheidet ich zwischen den Registerkarten und dem Schließen des gesamten Browsers mit JavaScript in Ihrem Browser? Während der täglichen Verwendung des Browsers können Benutzer ...
 Was sind die besten Praktiken für das Umwandeln von XML in Bilder?
Apr 02, 2025 pm 08:09 PM
Was sind die besten Praktiken für das Umwandeln von XML in Bilder?
Apr 02, 2025 pm 08:09 PM
Das Konvertieren von XML in Bilder kann in den folgenden Schritten erreicht werden: Analyse von XML -Daten und extrahieren visuelle Elementinformationen. Wählen Sie die entsprechende Grafikbibliothek (z. B. Kissen in Python, Jfreechart in Java), um das Bild zu rendern. Verstehen Sie die XML -Struktur und bestimmen Sie, wie die Daten verarbeitet werden. Wählen Sie die richtigen Werkzeuge und Methoden basierend auf der XML -Struktur und der Bildkomplexität. Erwägen Sie die Verwendung von Multithread- oder Asynchron -Programmierungen, um die Leistung zu optimieren und gleichzeitig die Lesbarkeit und Wartbarkeit der Code beizubehalten.
 C Sprachdatenstruktur: Die Schlüsselrolle von Datenstrukturen in der künstlichen Intelligenz
Apr 04, 2025 am 10:45 AM
C Sprachdatenstruktur: Die Schlüsselrolle von Datenstrukturen in der künstlichen Intelligenz
Apr 04, 2025 am 10:45 AM
C Sprachdatenstruktur: Überblick über die Schlüsselrolle der Datenstruktur in der künstlichen Intelligenz im Bereich der künstlichen Intelligenz sind Datenstrukturen für die Verarbeitung großer Datenmengen von entscheidender Bedeutung. Datenstrukturen bieten eine effektive Möglichkeit, Daten zu organisieren und zu verwalten, Algorithmen zu optimieren und die Programmeffizienz zu verbessern. Gemeinsame Datenstrukturen, die häufig verwendete Datenstrukturen in der C -Sprache sind: Arrays: Eine Reihe von nacheinander gespeicherten Datenelementen mit demselben Typ. Struktur: Ein Datentyp, der verschiedene Arten von Daten zusammen organisiert und ihnen einen Namen gibt. Linked List: Eine lineare Datenstruktur, in der Datenelemente durch Zeiger miteinander verbunden werden. Stack: Datenstruktur, die dem LEST-In-First-Out-Prinzip (LIFO) folgt. Warteschlange: Datenstruktur, die dem First-In-First-Out-Prinzip (FIFO) folgt. Praktischer Fall: Die benachbarte Tabelle in der Graphentheorie ist künstliche Intelligenz
 Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Bei der Konvertierung von Zeichenfolgen in Objekte in Vue.js wird JSON.Parse () für Standard -JSON -Zeichenfolgen bevorzugt. Bei nicht standardmäßigen JSON-Zeichenfolgen kann die Zeichenfolge durch Verwendung regelmäßiger Ausdrücke verarbeitet und Methoden gemäß dem Format oder dekodierten URL-kodiert reduziert werden. Wählen Sie die entsprechende Methode gemäß dem String -Format aus und achten Sie auf Sicherheits- und Codierungsprobleme, um Fehler zu vermeiden.
