
 Technologie-Peripheriegeräte
KI
Wie man LoRA-Code von Grund auf schreibt, finden Sie hier in einer Anleitung
Technologie-Peripheriegeräte
KI
Wie man LoRA-Code von Grund auf schreibt, finden Sie hier in einer Anleitung
Wie man LoRA-Code von Grund auf schreibt, finden Sie hier in einer Anleitung

LoRA (Low-Rank Adaptation) ist eine beliebte Technik zur Feinabstimmung großer Sprachmodelle (LLM). Diese Technologie wurde ursprünglich von Microsoft-Forschern vorgeschlagen und in das Papier „LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS“ aufgenommen. LoRA unterscheidet sich von anderen Techniken dadurch, dass es sich nicht auf die Anpassung aller Parameter des neuronalen Netzwerks, sondern auf die Aktualisierung einer kleinen Anzahl von Matrizen mit niedrigem Rang konzentriert, wodurch der zum Trainieren des Modells erforderliche Rechenaufwand erheblich reduziert wird.
Da die Feinabstimmungsqualität von LoRA mit der Feinabstimmung eines vollständigen Modells vergleichbar ist, bezeichnen viele Menschen diese Methode als Feinabstimmungsartefakt. Seit ihrer Veröffentlichung waren viele Menschen neugierig auf die Technologie und wollten Code schreiben, um die Forschung besser zu verstehen. In der Vergangenheit war der Mangel an ordnungsgemäßer Dokumentation ein Problem, aber jetzt haben wir Tutorials, die Ihnen helfen.
Der Autor dieses Tutorials ist Sebastian Raschka, ein bekannter Forscher für maschinelles Lernen und KI. Er sagte, dass LoRA unter den verschiedenen effektiven LLM-Feinabstimmungsmethoden immer noch seine erste Wahl sei. Zu diesem Zweck hat Sebastian einen Blog „Code LoRA From Scratch“ geschrieben, um LoRA von Grund auf zu erstellen. Seiner Meinung nach ist dies eine gute Lernmethode.
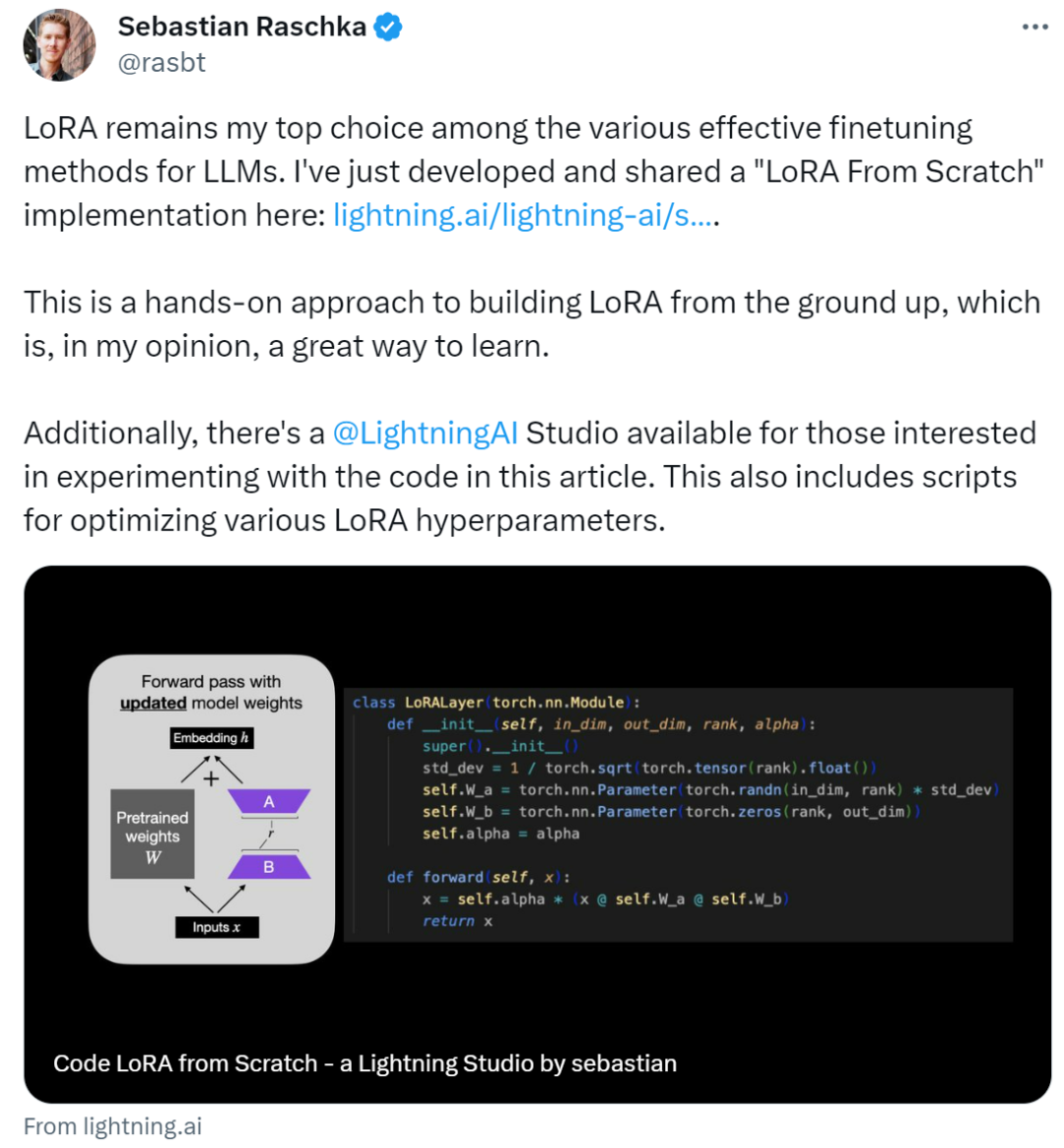
In diesem Artikel wird die Low-Rank-Adaption (LoRA) vorgestellt, indem Sebastian das DistilBERT-Modell im Experiment verfeinert und auf die Klassifizierungsaufgabe angewendet hat.
Die Vergleichsergebnisse zwischen der LoRA-Methode und der herkömmlichen Feinabstimmungsmethode zeigen, dass die LoRA-Methode eine Testgenauigkeit von 92,39 % erreicht, was der Feinabstimmung nur der letzten Schichten des Modells (86,22 % Testgenauigkeit) überlegen ist ) Leistung. Dies zeigt, dass die LoRA-Methode offensichtliche Vorteile bei der Optimierung der Modellleistung bietet und die Generalisierungsfähigkeit und Vorhersagegenauigkeit des Modells besser verbessern kann. Dieses Ergebnis unterstreicht die Bedeutung der Anwendung fortschrittlicher Techniken und Methoden beim Modelltraining und -tuning, um bessere Leistung und Ergebnisse zu erzielen. Werfen wir einen Blick darauf, indem wir vergleichen, wie
Sebastian es erreicht.
Schreiben Sie LoRA von Grund auf
Das Erklären einer LoRA-Ebene im Code sieht folgendermaßen aus:
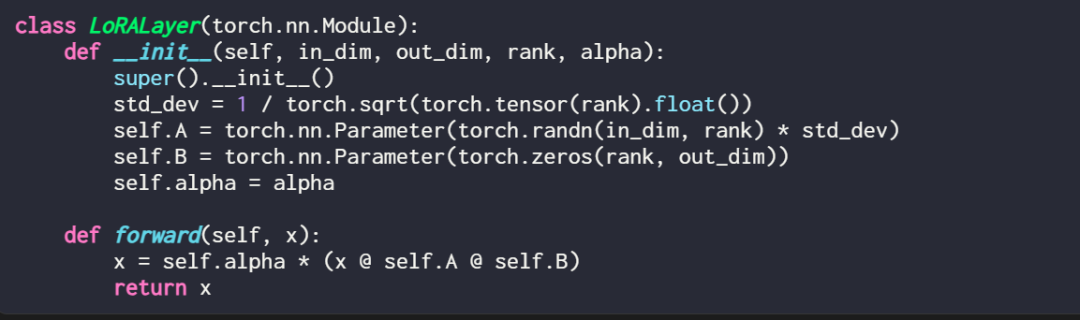
wobei in_dim die Eingabedimension der Ebene ist, die Sie mit LoRA ändern möchten, entsprechend out_dim die Ausgabedimension der Ebene. Dem Code wird außerdem ein Hyperparameter hinzugefügt, der Skalierungsfaktor Alpha. Höhere Alpha-Werte bedeuten größere Anpassungen des Modellverhaltens, niedrigere Werte bedeuten das Gegenteil. Darüber hinaus initialisiert dieser Artikel Matrix A mit kleineren Werten aus einer Zufallsverteilung und Matrix B mit Nullen.
Es ist erwähnenswert, dass LoRA normalerweise in der linearen (Feedforward-)Schicht eines neuronalen Netzwerks ins Spiel kommt. Beispielsweise kann für ein einfaches PyTorch-Modell oder -Modul mit zwei linearen Schichten (dies könnte beispielsweise ein Feedforward-Modul des Transformer-Blocks sein) die Vorwärtsmethode wie folgt ausgedrückt werden:

Bei Verwendung von LoRA ist es Es ist üblich, der Ausgabe dieser linearen Ebenen LoRA-Updates hinzuzufügen. Der resultierende Code lautet wie folgt:

Wenn Sie LoRA durch Ändern eines vorhandenen PyTorch-Modells implementieren möchten, besteht eine einfache Möglichkeit darin, jede lineare Ebene zu aktualisieren wird durch eine LinearWithLoRA-Schicht ersetzt:
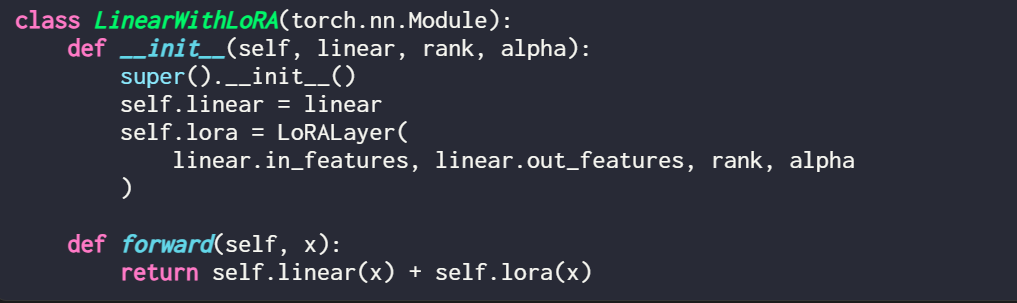
Diese Konzepte sind in der folgenden Abbildung zusammengefasst:
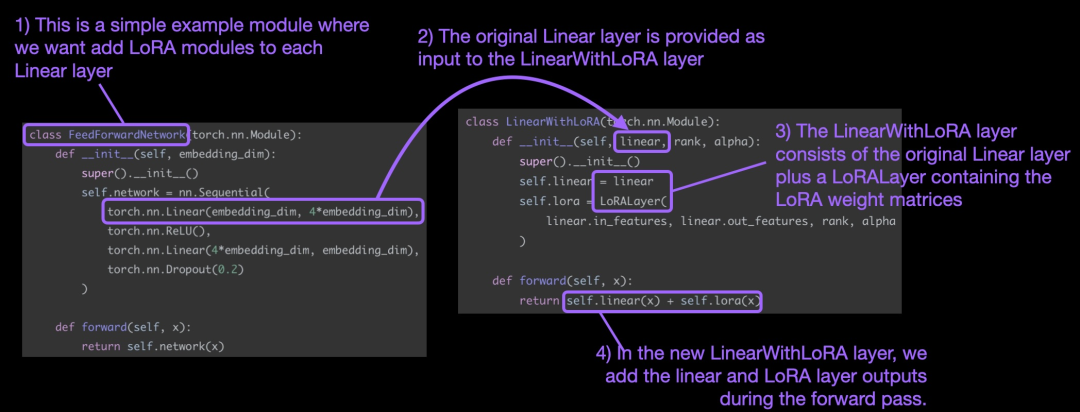
Um LoRA anzuwenden, ersetzt dieser Artikel die vorhandenen linearen Schichten im neuronalen Netzwerk durch eine kombinierte Die ursprüngliche lineare Ebene und die LinearWithLoRA-Ebene des LoRALayers.
So beginnen Sie mit der Verwendung von LoRA zur Feinabstimmung
LoRA kann für Modelle wie GPT oder Bildgenerierung verwendet werden. Zur einfachen Erklärung verwendet dieser Artikel ein kleines BERT-Modell (DistilBERT) zur Textklassifizierung.

Da dieser Artikel nur neue LoRA-Gewichte trainiert, müssen Sie „requires_grad“ aller trainierbaren Parameter auf „False“ setzen, um alle Modellparameter einzufrieren:

Als nächstes verwenden Sie print (model), um das Modell zu überprüfen Struktur von:

Aus der Ausgabe ist ersichtlich, dass das Modell aus 6 Transformatorschichten besteht, einschließlich linearer Schichten:

Darüber hinaus verfügt das Modell über zwei lineare Ausgabeschichten:

LoRA kann optional für diese linearen Schichten aktiviert werden, indem die folgende Zuweisungsfunktion und Schleife definiert wird:
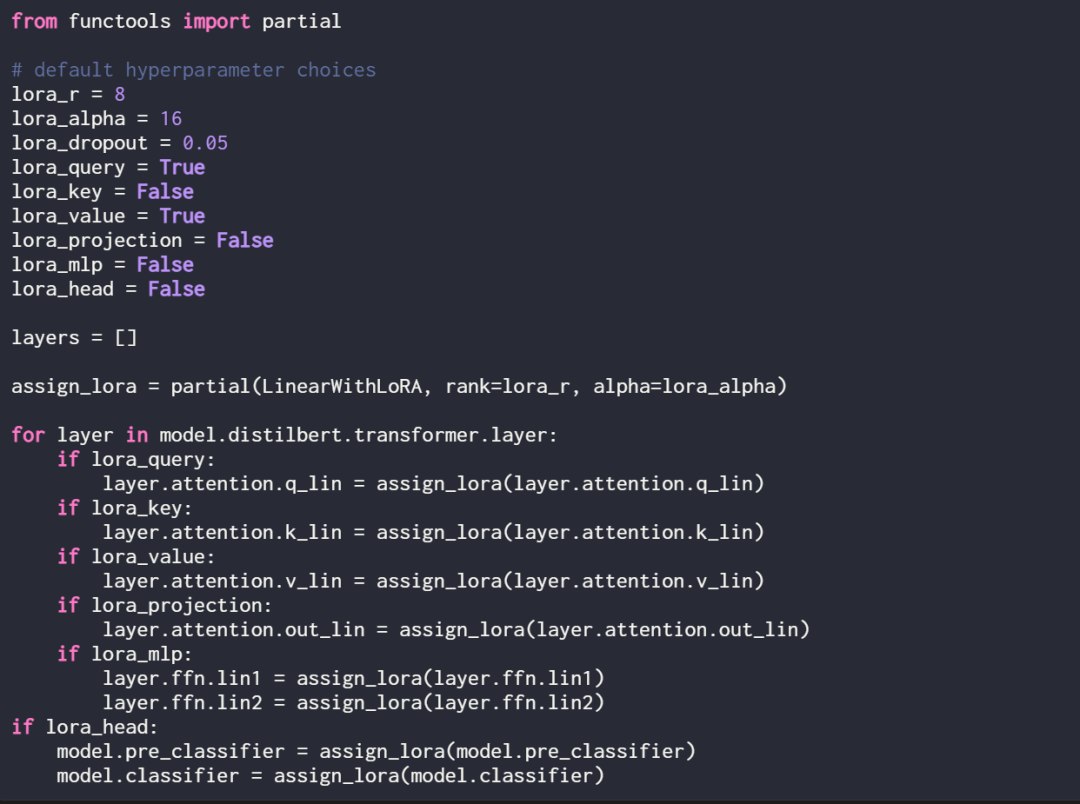
Überprüfen Sie das Modell erneut mit print (model), um seine aktualisierte Struktur zu überprüfen:
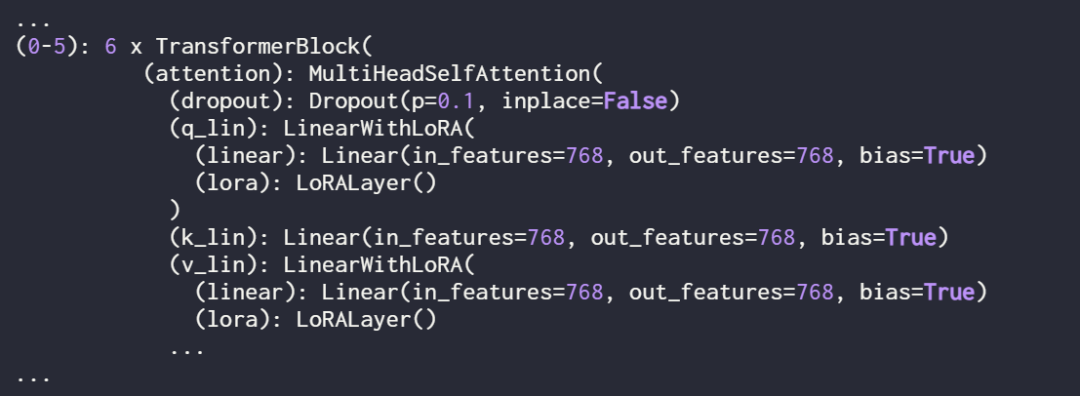
Wie Sie oben sehen können, wurde die Ebene „Linear“ erfolgreich durch die Ebene „LinearWithLoRA“ ersetzt.
Wenn Sie das Modell mit den oben gezeigten Standard-Hyperparametern trainieren, führt dies zu der folgenden Leistung im IMDb-Klassifizierungsdatensatz für Filmrezensionen:
- Trainingsgenauigkeit: 92,15 %
- Validierungsgenauigkeit: 89,98 %
- Testgenauigkeit: 89,44 %
Im nächsten Abschnitt vergleicht dieses Papier diese LoRA-Feinabstimmungsergebnisse mit traditionellen Feinabstimmungsergebnissen.
Vergleich mit herkömmlichen Feinabstimmungsmethoden
Im vorherigen Abschnitt erreichte LoRA unter Standardeinstellungen eine Testgenauigkeit von 89,44 %. Wie schneidet dies im Vergleich zu herkömmlichen Feinabstimmungsmethoden ab?
Zum Vergleich wurde in diesem Artikel ein weiteres Experiment durchgeführt, bei dem das Training des DistilBERT-Modells als Beispiel genommen wurde, aber während des Trainings nur die letzten beiden Schichten aktualisiert wurden. Dies erreichten die Forscher, indem sie alle Modellgewichte einfrierten und dann die beiden linearen Ausgabeschichten entsperrten:
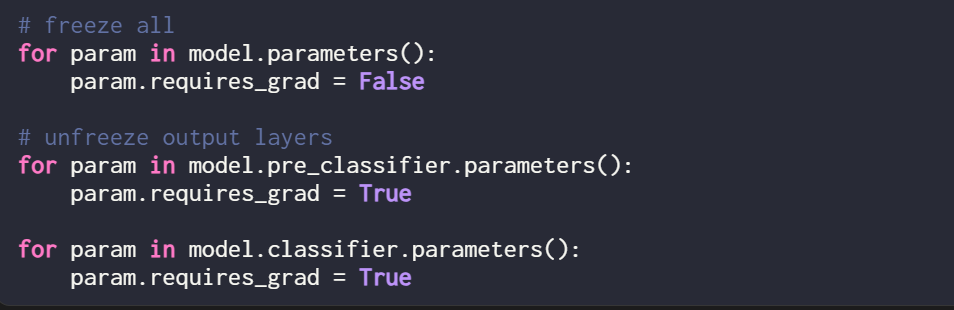
Die Klassifizierungsleistung, die durch das Training nur der letzten beiden Schichten erzielt wurde, ist wie folgt:
- Trainingsgenauigkeit: 86,68 %
- Validierungsgenauigkeit: 87,26 %
- Testgenauigkeit: 86,22 %
Die Ergebnisse zeigen, dass LoRA eine bessere Leistung erbringt als die herkömmliche Methode zur Feinabstimmung der letzten beiden Schichten, aber viermal weniger Parameter verwendet . Die Feinabstimmung aller Ebenen erforderte die Aktualisierung von 450-mal mehr Parametern als beim LoRA-Setup, verbesserte die Testgenauigkeit jedoch nur um 2 %.
LoRA-Konfiguration optimieren
Die oben genannten Ergebnisse werden alle von LoRA unter den Standardeinstellungen durchgeführt. Die Hyperparameter sind wie folgt:

Wenn der Benutzer verschiedene Hyperparameter-Konfigurationen ausprobieren möchte Verwenden Sie den folgenden Befehl:

Die optimale Hyperparameterkonfiguration lautet jedoch wie folgt:

Unter dieser Konfiguration lautet das Ergebnis:
- Validierungsgenauigkeit: 92,96 %
- Testgenauigkeit: 92,39 %
Es ist erwähnenswert, dass, obwohl es in der LoRA-Einstellung nur einen kleinen Satz trainierbarer Parameter gibt (500k VS 66M), die Genauigkeit ist immer noch etwas höher als die Genauigkeit, die mit vollständiger Feinabstimmung erreicht wird.
Originallink: https://lightning.ai/lightning-ai/studios/code-lora-from-scratch?cnotallow=f5fc72b1f6eeeaf74b648b2aa8aaf8b6
Das obige ist der detaillierte Inhalt vonWie man LoRA-Code von Grund auf schreibt, finden Sie hier in einer Anleitung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
 So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
In diesem Artikel wird beschrieben, wie Sie Firewall -Regeln mit Iptables oder UFW in Debian -Systemen konfigurieren und Syslog verwenden, um Firewall -Aktivitäten aufzuzeichnen. Methode 1: Verwenden Sie IptableSiptables ist ein leistungsstarkes Befehlszeilen -Firewall -Tool im Debian -System. Vorhandene Regeln anzeigen: Verwenden Sie den folgenden Befehl, um die aktuellen IPTables-Regeln anzuzeigen: Sudoiptables-L-N-V Ermöglicht spezifische IP-Zugriff: ZBELTE IP-Adresse 192.168.1.100 Zugriff auf Port 80: sudoiptables-ainput-ptcp--dort80-s192.16
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
