
 Technologie-Peripheriegeräte
KI
Google veröffentlicht „Vlogger'-Modell: Ein einzelnes Bild erzeugt ein 10-Sekunden-Video
Technologie-Peripheriegeräte
KI
Google veröffentlicht „Vlogger'-Modell: Ein einzelnes Bild erzeugt ein 10-Sekunden-Video
Google veröffentlicht „Vlogger'-Modell: Ein einzelnes Bild erzeugt ein 10-Sekunden-Video

Google hat ein neues Video-Framework veröffentlicht:
Sie benötigen nur ein Bild von Ihnen und eine Aufzeichnung Ihrer Rede, und Sie können ein lebensechtes Video Ihrer Rede erhalten.
Die Videodauer ist variabel und beträgt im aktuellen Beispiel bis zu 10 Sekunden.
Sie können sehen, dass es sehr natürlich ist, egal ob Mundform oder Gesichtsausdruck.
Wenn das Eingabebild den gesamten Oberkörper abdeckt, kann es auch mit reichhaltigen Gesten verwendet werden:

Nachdem die Internetnutzer es gelesen hatten, sagten sie:
Damit müssen wir uns nicht mehr festhalten Online-Videokonferenzen in der Zukunft Machen Sie Ihre Frisur fertig und ziehen Sie sich an, bevor Sie gehen.
Nun, machen Sie einfach ein Porträt und nehmen Sie das Sprachaudio auf (manueller Hundekopf)
Verwenden Sie Ihre Stimme, um das Porträt zu steuern, um ein Video zu erstellen
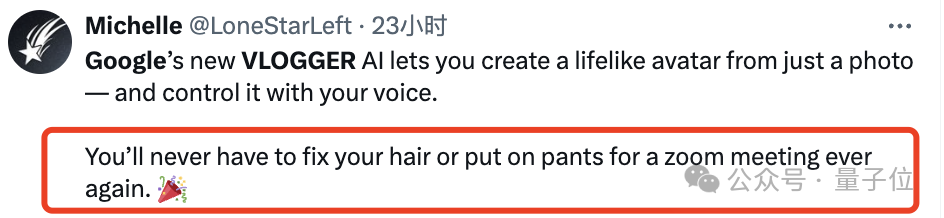
Dieses Framework heißt VLOGGER.
Es basiert hauptsächlich auf dem Diffusionsmodell und besteht aus zwei Teilen:
Einer ist das Diffusionsmodell „Zufällige Mensch-zu-3D-Bewegung“ (Mensch-zu-3D-Bewegung). Das andere ist eine neue Diffusionsarchitektur zur Verbesserung von Text-zu-Bild-Modellen.
 Unter ihnen ist ersterer dafür verantwortlich, die Audiowellenform als Eingabe zu verwenden, um die Körperkontrollaktionen des Charakters zu generieren, einschließlich Augen, Ausdrücke und Gesten, allgemeine Körperhaltung usw.
Unter ihnen ist ersterer dafür verantwortlich, die Audiowellenform als Eingabe zu verwenden, um die Körperkontrollaktionen des Charakters zu generieren, einschließlich Augen, Ausdrücke und Gesten, allgemeine Körperhaltung usw.
Letzteres ist ein Bild-zu-Bild-Modell mit zeitlicher Dimension, das verwendet wird, um das groß angelegte Bilddiffusionsmodell zu erweitern und die gerade vorhergesagten Aktionen zum Generieren entsprechender Frames zu verwenden.
Um die Ergebnisse an ein bestimmtes Charakterbild anzupassen, verwendet VLOGGER auch das Posendiagramm des Parameterbilds als Eingabe.
Das Training von VLOGGER wird an einem sehr großen Datensatz
(mit dem Namen MENTOR)abgeschlossen. Wie groß ist es?
Es ist 2200 Stunden lang und enthält 800.000 Charaktervideos. Unter anderem beträgt die Videodauer des Testsets ebenfalls 120 Stunden mit insgesamt 4.000 Zeichen.
Google stellte fest, dass die herausragendste Leistung von VLOGGER seine Vielfalt ist:
Wie im Bild unten gezeigt, sind die Aktionen umso reichhaltiger, je dunkler
(rot)der Teil des endgültigen Pixelbilds ist.
 Im Vergleich zu früheren ähnlichen Methoden in der Branche besteht der größte Vorteil von VLOGGER darin, dass nicht jeder geschult werden muss, nicht auf Gesichtserkennung und -zuschnitt angewiesen ist und das generierte Video sehr vollständig ist (einschließlich Gesichter und Lippen, einschließlich Körperbewegungen)
Im Vergleich zu früheren ähnlichen Methoden in der Branche besteht der größte Vorteil von VLOGGER darin, dass nicht jeder geschult werden muss, nicht auf Gesichtserkennung und -zuschnitt angewiesen ist und das generierte Video sehr vollständig ist (einschließlich Gesichter und Lippen, einschließlich Körperbewegungen)
Im Einzelnen, wie in der folgenden Tabelle gezeigt: 
Apropos Videobearbeitung: Wie im Bild unten gezeigt, ist eine der Anwendungen des VLOGGER-Modells folgende: Es kann dazu führen, dass der Charakter den Mund hält, die Augen schließt, nur das linke Auge schließt oder das ganze Auge öffnet mit einem Klick: 
Eine weitere Anwendung ist die Videoübersetzung: 
Ist das das Niveau von Google?

Der Name „VLOGGER“ tut mir ein bisschen leid.

——Verglichen mit Sora von OpenAI ist die Aussage des Internetnutzers tatsächlich nicht unvernünftig. .
Was meint ihr?
Weitere Effekte:https://enriccorona.github.io/vlogger/
Vollständiges Paper: https://enriccorona.github.io/vlogger/paper.pdf
Das obige ist der detaillierte Inhalt vonGoogle veröffentlicht „Vlogger'-Modell: Ein einzelnes Bild erzeugt ein 10-Sekunden-Video. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So nehmen Sie Bildschirmvideos mit einem OPPO-Telefon auf (einfache Bedienung)
May 07, 2024 pm 06:22 PM
So nehmen Sie Bildschirmvideos mit einem OPPO-Telefon auf (einfache Bedienung)
May 07, 2024 pm 06:22 PM
Spielfähigkeiten oder Lehrdemonstrationen: Im täglichen Leben müssen wir häufig Mobiltelefone verwenden, um Bildschirmvideos aufzunehmen, um einige Bedienschritte zu zeigen. Die Funktion zum Aufzeichnen von Bildschirmvideos ist ebenfalls sehr gut und das OPPO-Mobiltelefon ist ein leistungsstarkes Smartphone. Damit Sie die Aufnahmeaufgabe einfach und schnell erledigen können, wird in diesem Artikel detailliert beschrieben, wie Sie OPPO-Mobiltelefone zum Aufzeichnen von Bildschirmvideos verwenden. Vorbereitung – Aufnahmeziele festlegen Bevor Sie beginnen, müssen Sie Ihre Aufnahmeziele klären. Möchten Sie ein Schritt-für-Schritt-Demonstrationsvideo aufnehmen? Oder möchten Sie einen wundervollen Moment eines Spiels festhalten? Oder möchten Sie ein Lehrvideo aufnehmen? Nur durch eine bessere Organisation des Aufnahmeprozesses und klare Ziele. Öffnen Sie die Bildschirmaufzeichnungsfunktion des OPPO-Mobiltelefons und finden Sie sie im Verknüpfungsfeld. Die Bildschirmaufzeichnungsfunktion befindet sich im Verknüpfungsfeld.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 So wechseln Sie die Sprache in Adobe After Effects cs6 (Ae cs6) Detaillierte Schritte zum Wechseln zwischen Chinesisch und Englisch in Ae cs6 – ZOL-Download
May 09, 2024 pm 02:00 PM
So wechseln Sie die Sprache in Adobe After Effects cs6 (Ae cs6) Detaillierte Schritte zum Wechseln zwischen Chinesisch und Englisch in Ae cs6 – ZOL-Download
May 09, 2024 pm 02:00 PM
1. Suchen Sie zuerst den Ordner AMTLangagues. Wir haben einige Dokumentationen im AMTLangagues-Ordner gefunden. Wenn Sie vereinfachtes Chinesisch installieren, gibt es ein Textdokument zh_CN.txt (der Textinhalt ist: zh_CN). Wenn Sie es auf Englisch installiert haben, gibt es ein Textdokument en_US.txt (der Textinhalt ist: en_US). 3. Wenn wir also auf Chinesisch umsteigen möchten, müssen wir ein neues Textdokument von zh_CN.txt (der Textinhalt ist: zh_CN) unter dem Pfad AdobeAfterEffectsCCSupportFilesAMTLanguages erstellen. 4. Im Gegenteil, wenn wir auf Englisch umsteigen wollen,
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
 Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Um große Sprachmodelle (LLMs) an menschlichen Werten und Absichten auszurichten, ist es wichtig, menschliches Feedback zu lernen, um sicherzustellen, dass sie nützlich, ehrlich und harmlos sind. Im Hinblick auf die Ausrichtung von LLM ist Reinforcement Learning basierend auf menschlichem Feedback (RLHF) eine wirksame Methode. Obwohl die Ergebnisse der RLHF-Methode ausgezeichnet sind, gibt es einige Herausforderungen bei der Optimierung. Dazu gehört das Training eines Belohnungsmodells und die anschließende Optimierung eines Richtlinienmodells, um diese Belohnung zu maximieren. Kürzlich haben einige Forscher einfachere Offline-Algorithmen untersucht, darunter die direkte Präferenzoptimierung (Direct Preference Optimization, DPO). DPO lernt das Richtlinienmodell direkt auf der Grundlage von Präferenzdaten, indem es die Belohnungsfunktion in RLHF parametrisiert, wodurch die Notwendigkeit eines expliziten Belohnungsmodells entfällt. Diese Methode ist einfach und stabil
 Wie drehe ich Videos auf TikTok? Wie schalte ich das Mikrofon für Videoaufnahmen ein?
May 09, 2024 pm 02:40 PM
Wie drehe ich Videos auf TikTok? Wie schalte ich das Mikrofon für Videoaufnahmen ein?
May 09, 2024 pm 02:40 PM
Als eine der beliebtesten Kurzvideoplattformen von heute wirken sich Qualität und Wirkung der Videos von Douyin direkt auf das Seherlebnis des Benutzers aus. Wie dreht man also hochwertige Videos auf TikTok? 1. Wie drehe ich Videos auf Douyin? 1. Öffnen Sie die Douyin-App und klicken Sie unten in der Mitte auf die Schaltfläche „+“, um die Videoaufnahmeseite aufzurufen. 2. Douyin bietet eine Vielzahl von Aufnahmemodi, darunter normale Aufnahme, Zeitlupe, Kurzvideo usw. Wählen Sie den passenden Aufnahmemodus entsprechend Ihren Anforderungen. 3. Klicken Sie auf der Aufnahmeseite unten auf dem Bildschirm auf die Schaltfläche „Filter“, um verschiedene Filtereffekte auszuwählen und das Video individueller zu gestalten. 4. Wenn Sie Parameter wie Belichtung und Kontrast anpassen müssen, können Sie zum Einstellen auf die Schaltfläche „Parameter“ in der unteren linken Ecke des Bildschirms klicken. 5. Während der Aufnahme können Sie auf die linke Seite des Bildschirms klicken
