
 Technologie-Peripheriegeräte
KI
Stable Video 3D feiert ein schockierendes Debüt: Ein einzelnes Bild erzeugt 3D-Videos ohne tote Winkel, und Modellgewichte werden geöffnet
Technologie-Peripheriegeräte
KI
Stable Video 3D feiert ein schockierendes Debüt: Ein einzelnes Bild erzeugt 3D-Videos ohne tote Winkel, und Modellgewichte werden geöffnet
Stable Video 3D feiert ein schockierendes Debüt: Ein einzelnes Bild erzeugt 3D-Videos ohne tote Winkel, und Modellgewichte werden geöffnet

Stability AI hat ein neues Mitglied in seiner großen Modellfamilie.
Gestern, nach der Einführung von Stable Diffusion und Stable Video Diffusion, stellte Stability AI der Community ein großes 3D-Videogenerierungsmodell „Stable Video 3D“ (kurz SV3D) vor.
Dieses Modell basiert auf Stable Video Diffusion. Sein Hauptvorteil besteht darin, dass es die Qualität der 3D-Generierung und die Konsistenz mehrerer Ansichten erheblich verbessert. Im Vergleich zum vorherigen von Stability AI eingeführten Stable Zero123 und dem gemeinsamen Open-Source-Modell Zero123-XL ist die Wirkung dieses Modells noch besser.
Derzeit unterstützt Stable Video 3D sowohl die kommerzielle Nutzung, für die der Beitritt zur Stability AI-Mitgliedschaft (Mitgliedschaft) erforderlich ist, als auch die nichtkommerzielle Nutzung, bei der Benutzer die Modellgewichte auf Hugging Face herunterladen können.

Stabilitäts-KI bietet zwei Modellvarianten, nämlich SV3D_u und SV3D_p. SV3D_u generiert Orbitalvideos auf der Grundlage einer einzelnen Bildeingabe, ohne dass Kameraeinstellungen erforderlich sind, während SV3D_p die Generierungsfähigkeiten durch die Anpassung eines einzelnen Bildes und einer Orbitalperspektive weiter erweitert, sodass Benutzer 3D-Videos entlang eines bestimmten Kamerapfads erstellen können.
Derzeit wurde das Forschungspapier zu Stable Video 3D mit drei Hauptautoren veröffentlicht.

- Papieradresse: https://stability.ai/s/SV3D_report.pdf
- Blogadresse: https://stability.ai/news/introducing-stable-video- 3d
- Huggingface Adresse: https://huggingface.co/stabilityai/sv3d
Technischer Überblick
Stable Video 3D hat erhebliche Fortschritte im Bereich der 3D-Generierung erzielt, insbesondere bei der Synthese neuartiger Ansichtsgenerierungen , NVS) Aspekte.
Frühere Methoden neigten oft dazu, das Problem begrenzter Betrachtungswinkel und inkonsistenter Eingaben zu lösen, während Stable Video 3D in der Lage ist, aus jedem gegebenen Winkel eine kohärente Ansicht zu liefern und gut zu verallgemeinern. Dadurch verbessert das Modell nicht nur die Posenkontrollierbarkeit, sondern sorgt auch für ein konsistentes Erscheinungsbild des Objekts über mehrere Ansichten hinweg, wodurch wichtige Probleme bei der realistischen und genauen 3D-Generierung weiter verbessert werden.
Wie in der Abbildung unten gezeigt, ist Stable Video 3D im Vergleich zu Stable Zero123 und Zero-XL in der Lage, neuartige Mehrfachansichten mit stärkeren Details, mehr Treue zum Eingabebild und konsistenteren Mehrfachansichten zu generieren.

Darüber hinaus nutzt Stable Video 3D seine Multi-View-Konsistenz, um 3D Neural Radiance Fields (NeRF) zu optimieren und die Qualität von 3D-Netzen zu verbessern, die direkt aus neuen Ansichten generiert werden.
Zu diesem Zweck hat Stability AI eine Maske für den Stichprobenverlust durch fraktionierte Destillation entwickelt, die die 3D-Qualität unsichtbarer Regionen in der vorhergesagten Ansicht weiter verbessert. Um Probleme mit der Beleuchtung zu vermeiden, verwendet Stable Video 3D ein entkoppeltes Beleuchtungsmodell, das mit 3D-Formen und -Texturen optimiert ist.
Das Bild unten zeigt ein Beispiel für eine verbesserte 3D-Netzgenerierung durch 3D-Optimierung bei Verwendung des Stable Video 3D-Modells und seiner Ausgabe.

Das Bild unten zeigt den Vergleich der mit Stable Video 3D generierten 3D-Netzergebnisse mit denen von EscherNet und Stable Zero123.

Architekturdetails
Die Architektur des Stable Video 3D-Modells ist in Abbildung 2 unten dargestellt. Es basiert auf der Stable Video Diffusion-Architektur und enthält ein UNet mit mehreren Ebenen, wobei jede Schicht Es enthält auch eine Folge von Restblöcken mit einer Conv3D-Schicht und zwei Transformatorblöcken mit Aufmerksamkeitsschichten (räumlich und zeitlich).
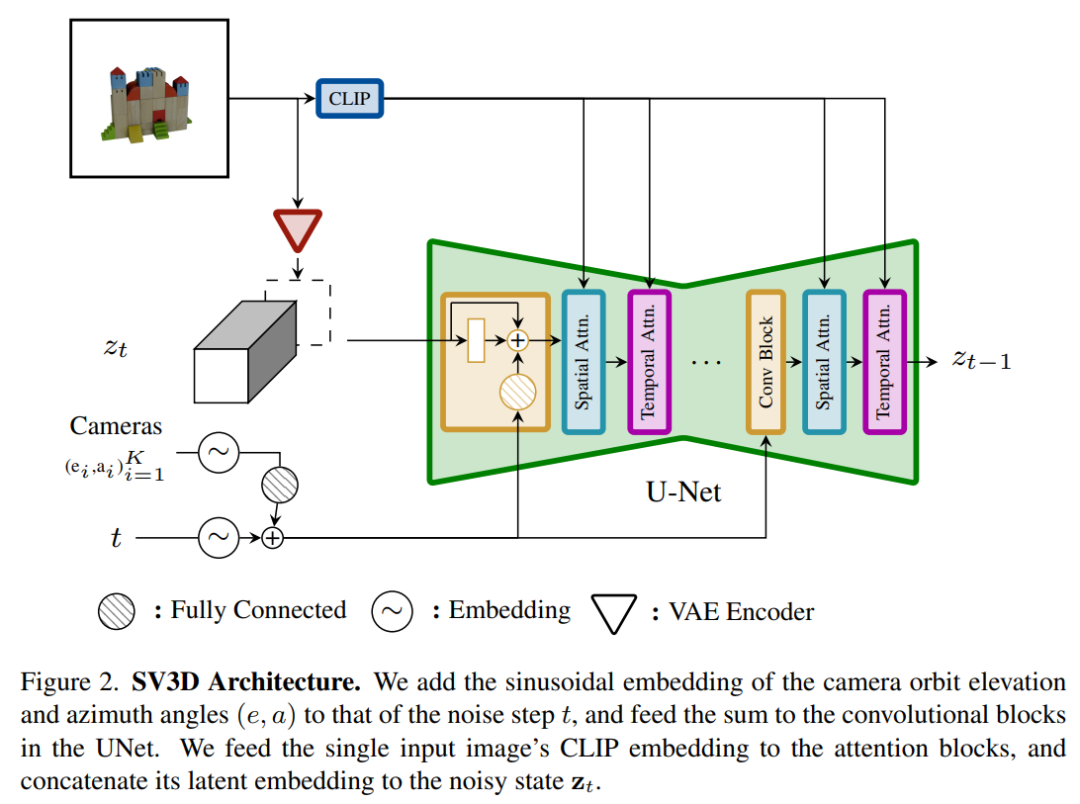
Der spezifische Prozess ist wie folgt:
(i) Löschen Sie die Vektorbedingungen „fps id“ und „motion Bucket id“, da sie nichts mit Stable Video 3D zu tun haben
(ii) Die Das bedingte Bild durchläuft den VAE-Encoder von Stable Video Diffusion, der in den latenten Raum eingebettet und dann im Rauschzeitschritt t mit dem Eingang zt für den latenten Rauschen verbunden wird, was zu UNet führt zu jedem Transformatorblock fungieren Queraufmerksamkeitsschichten als Schlüssel und Werte, und Abfragen werden zu Merkmalen der entsprechenden Schicht
(iv) Die Kamerabahn wird entlang des Diffusionsrauschen-Zeitschritts in den Restblock eingespeist. Die Kamerapositionswinkel ei und ai und der Rauschzeitschritt t werden zunächst in die sinusförmige Positionseinbettung eingebettet, dann werden die Kamerapositionseinbettungen zur linearen Transformation miteinander verkettet und zur Rauschzeitschritteinbettung hinzugefügt und schließlich in jeden Restblock eingespeist wird zu den Eingabemerkmalen des Blocks hinzugefügt.
Darüber hinaus hat Stability AI statische Umlaufbahnen und dynamische Umlaufbahnen entworfen, um die Auswirkungen von Kamerapositionsanpassungen zu untersuchen, wie in Abbildung 3 unten dargestellt.
Auf einer statischen Umlaufbahn dreht sich die Kamera im äquidistanten Azimut um das Objekt und verwendet dabei denselben Höhenwinkel wie das Zustandsbild. Der Nachteil dabei ist, dass Sie aufgrund des angepassten Höhenwinkels möglicherweise keine Informationen über die Ober- oder Unterseite des Objekts erhalten. In einer dynamischen Umlaufbahn können die Azimutwinkel ungleich sein und auch die Höhenwinkel jeder Ansicht können unterschiedlich sein. 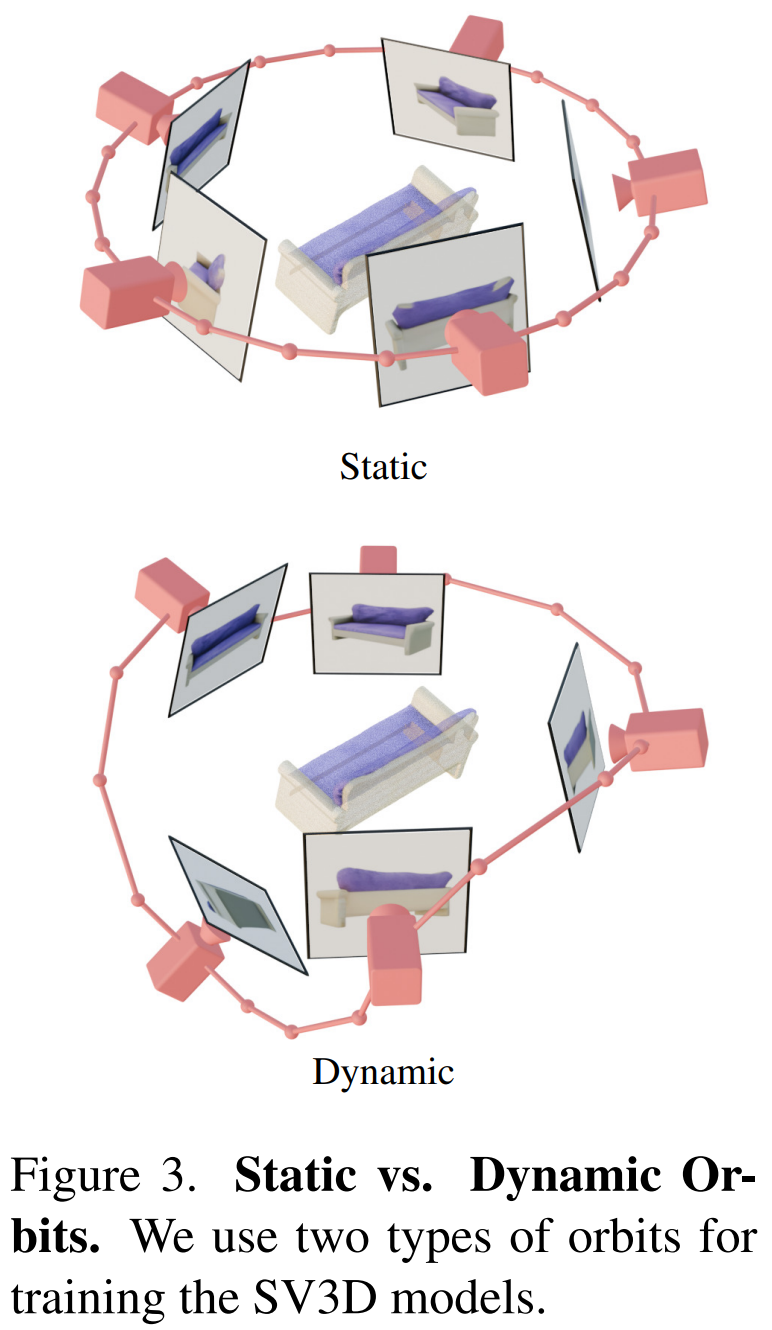
Um eine dynamische Umlaufbahn zu erstellen, tastet die Stabilitäts-KI eine statische Umlaufbahn ab, fügt ihrem Azimut ein kleines zufälliges Rauschen und ihrer Höhe eine zufällig gewichtete Kombination von Sinuskurven unterschiedlicher Frequenz hinzu. Dies sorgt für eine zeitliche Glätte und stellt sicher, dass die Kamerabahn entlang derselben Azimut- und Höhenschleife endet wie das Zustandsbild.
Experimentelle Ergebnisse
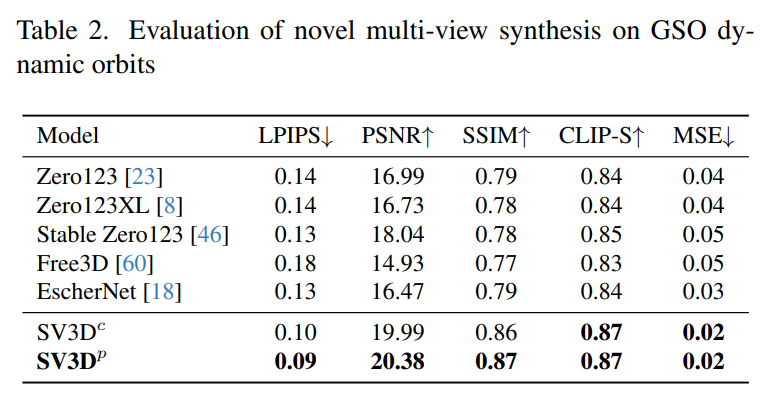
Stabilitäts-KI wertet Stable Video 3D-Composite-Mehrfachansichtseffekte auf statischen und dynamischen Umlaufbahnen in unsichtbaren GSO- und OmniObject3D-Datensätzen aus. Die in den Tabellen 1 bis 4 unten aufgeführten Ergebnisse zeigen, dass Stable Video 3D bei der neuartigen Multi-View-Synthese eine hochmoderne Leistung erzielt.
Tabelle 1 und Tabelle 3 zeigen die Ergebnisse von Stable Video 3D im Vergleich zu anderen Modellen auf statischen Umlaufbahnen und zeigen, dass sogar das Modell SV3D_u ohne Posenanpassung eine bessere Leistung erbringt als alle vorherigen Methoden.
Die Ergebnisse der Ablationsanalyse zeigen, dass SV3D_c und SV3D_p SV3D_u bei der Generierung statischer Trajektorien übertreffen, obwohl letzteres ausschließlich auf statischen Trajektorien trainiert wird.
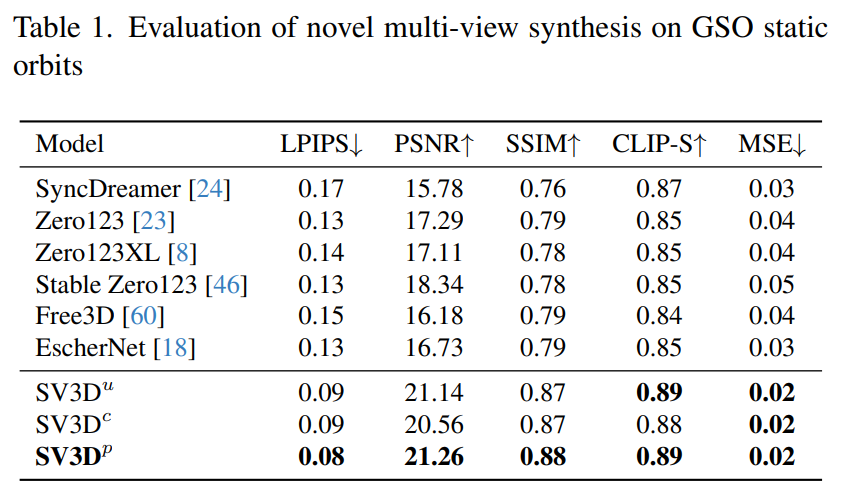
Tabelle 2 und Tabelle 4 unten zeigen die Generierungsergebnisse dynamischer Umlaufbahnen, einschließlich der Posenanpassungsmodelle SV3D_c und SV3D_p, wobei letzteres SOTA bei allen Metriken erreicht. 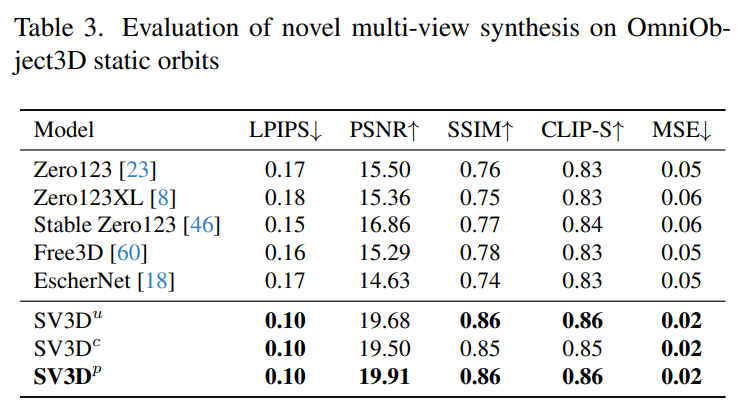
Die visuellen Vergleichsergebnisse in Abbildung 6 unten zeigen weiter, dass die von Stable Video 3D generierten Bilder im Vergleich zu früheren Arbeiten detaillierter, dem bedingten Bild treuer und über mehrere Perspektiven hinweg konsistenter sind . 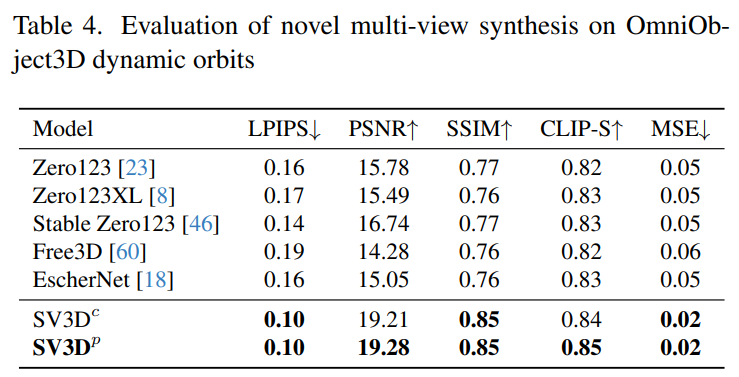
Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier. 
Das obige ist der detaillierte Inhalt vonStable Video 3D feiert ein schockierendes Debüt: Ein einzelnes Bild erzeugt 3D-Videos ohne tote Winkel, und Modellgewichte werden geöffnet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
Um eine Oracle -Datenbank zu erstellen, besteht die gemeinsame Methode darin, das dbca -grafische Tool zu verwenden. Die Schritte sind wie folgt: 1. Verwenden Sie das DBCA -Tool, um den DBNAME festzulegen, um den Datenbanknamen anzugeben. 2. Setzen Sie Syspassword und SystemPassword auf starke Passwörter. 3.. Setzen Sie Charaktere und NationalCharacterset auf AL32UTF8; 4. Setzen Sie MemorySize und tablespacesize, um sie entsprechend den tatsächlichen Bedürfnissen anzupassen. 5. Geben Sie den Logfile -Pfad an. Erweiterte Methoden werden manuell mit SQL -Befehlen erstellt, sind jedoch komplexer und anfällig für Fehler. Achten Sie auf die Kennwortstärke, die Auswahl der Zeichensatz, die Größe und den Speicher von Tabellenräumen
 Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Das Erstellen einer Oracle -Datenbank ist nicht einfach, Sie müssen den zugrunde liegenden Mechanismus verstehen. 1. Sie müssen die Konzepte von Datenbank und Oracle DBMS verstehen. 2. Beherrschen Sie die Kernkonzepte wie SID, CDB (Containerdatenbank), PDB (Pluggable -Datenbank); 3.. Verwenden Sie SQL*Plus, um CDB zu erstellen und dann PDB zu erstellen. Sie müssen Parameter wie Größe, Anzahl der Datendateien und Pfade angeben. 4. Erweiterte Anwendungen müssen den Zeichensatz, den Speicher und andere Parameter anpassen und die Leistungsstimmung durchführen. 5. Achten Sie auf Speicherplatz, Berechtigungen und Parametereinstellungen und überwachen und optimieren Sie die Datenbankleistung kontinuierlich. Nur indem Sie es geschickt beherrschen, müssen Sie die Erstellung und Verwaltung von Oracle -Datenbanken wirklich verstehen.
 So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
Der Kern von Oracle SQL -Anweisungen ist ausgewählt, einfügen, aktualisiert und löschen sowie die flexible Anwendung verschiedener Klauseln. Es ist wichtig, den Ausführungsmechanismus hinter der Aussage wie die Indexoptimierung zu verstehen. Zu den erweiterten Verwendungen gehören Unterabfragen, Verbindungsabfragen, Analysefunktionen und PL/SQL. Häufige Fehler sind Syntaxfehler, Leistungsprobleme und Datenkonsistenzprobleme. Best Practices für Leistungsoptimierung umfassen die Verwendung geeigneter Indizes, die Vermeidung von Auswahl *, optimieren Sie, wo Klauseln und gebundene Variablen verwenden. Das Beherrschen von Oracle SQL erfordert Übung, einschließlich des Schreibens von Code, Debuggen, Denken und Verständnis der zugrunde liegenden Mechanismen.
 Hinzufügen, Ändern und Löschen von MySQL Data Table Field Operation Operation Guide, addieren, ändern und löschen
Apr 11, 2025 pm 05:42 PM
Hinzufügen, Ändern und Löschen von MySQL Data Table Field Operation Operation Guide, addieren, ändern und löschen
Apr 11, 2025 pm 05:42 PM
Feldbetriebshandbuch in MySQL: Felder hinzufügen, ändern und löschen. Feld hinzufügen: Alter table table_name hinzufügen column_name data_type [nicht null] [Standard default_value] [Primärschlüssel] [auto_increment] Feld ändern: Alter table table_name Ändern Sie Column_Name Data_type [nicht null] [diffault default_value] [Primärschlüssel] [Primärschlüssel]
 Was sind die Integritätsbeschränkungen von Oracle -Datenbanktabellen?
Apr 11, 2025 pm 03:42 PM
Was sind die Integritätsbeschränkungen von Oracle -Datenbanktabellen?
Apr 11, 2025 pm 03:42 PM
Die Integritätsbeschränkungen von Oracle -Datenbanken können die Datengenauigkeit sicherstellen, einschließlich: nicht Null: Nullwerte sind verboten; Einzigartig: Einzigartigkeit garantieren und einen einzelnen Nullwert ermöglichen; Primärschlüssel: Primärschlüsselbeschränkung, Stärkung der einzigartigen und verboten Nullwerte; Fremdschlüssel: Verwalten Sie die Beziehungen zwischen Tabellen, Fremdschlüssel beziehen sich auf Primärtabellen -Primärschlüssel. Überprüfen Sie: Spaltenwerte nach Bedingungen begrenzen.
 Detaillierte Erläuterung verschachtelter Abfrageinstanzen in der MySQL -Datenbank
Apr 11, 2025 pm 05:48 PM
Detaillierte Erläuterung verschachtelter Abfrageinstanzen in der MySQL -Datenbank
Apr 11, 2025 pm 05:48 PM
Verschachtelte Anfragen sind eine Möglichkeit, eine andere Frage in eine Abfrage aufzunehmen. Sie werden hauptsächlich zum Abrufen von Daten verwendet, die komplexe Bedingungen erfüllen, mehrere Tabellen assoziieren und zusammenfassende Werte oder statistische Informationen berechnen. Beispiele hierfür sind zu findenen Mitarbeitern über den überdurchschnittlichen Löhnen, das Finden von Bestellungen für eine bestimmte Kategorie und die Berechnung des Gesamtbestellvolumens für jedes Produkt. Beim Schreiben verschachtelter Abfragen müssen Sie folgen: Unterabfragen schreiben, ihre Ergebnisse in äußere Abfragen schreiben (auf Alias oder als Klauseln bezogen) und optimieren Sie die Abfrageleistung (unter Verwendung von Indizes).
 Was macht Oracle?
Apr 11, 2025 pm 06:06 PM
Was macht Oracle?
Apr 11, 2025 pm 06:06 PM
Oracle ist das weltweit größte Softwareunternehmen für Datenbankverwaltungssystem (DBMS). Zu den Hauptprodukten gehören die folgenden Funktionen: Entwicklungstools für relationale Datenbankverwaltungssysteme (Oracle Database) (Oracle Apex, Oracle Visual Builder) Middleware (Oracle Weblogic Server, Oracle Soa Suite) Cloud -Dienst (Oracle Cloud Infrastructure) Analyse und Business Intelligence (Oracle Analytic
 So konfigurieren Sie das Debian Apache -Protokollformat
Apr 12, 2025 pm 11:30 PM
So konfigurieren Sie das Debian Apache -Protokollformat
Apr 12, 2025 pm 11:30 PM
In diesem Artikel wird beschrieben, wie das Protokollformat von Apache auf Debian -Systemen angepasst wird. Die folgenden Schritte führen Sie durch den Konfigurationsprozess: Schritt 1: Greifen Sie auf die Apache -Konfigurationsdatei zu. Die Haupt -Apache -Konfigurationsdatei des Debian -Systems befindet sich normalerweise in /etc/apache2/apache2.conf oder /etc/apache2/httpd.conf. Öffnen Sie die Konfigurationsdatei mit Root -Berechtigungen mit dem folgenden Befehl: Sudonano/etc/apache2/apache2.conf oder sudonano/etc/apache2/httpd.conf Schritt 2: Definieren Sie benutzerdefinierte Protokollformate, um zu finden oder zu finden oder
