
 Technologie-Peripheriegeräte
KI
Ein Artikel zum Verständnis der technischen Herausforderungen und Optimierungsstrategien für die Feinabstimmung großer Sprachmodelle
Technologie-Peripheriegeräte
KI
Ein Artikel zum Verständnis der technischen Herausforderungen und Optimierungsstrategien für die Feinabstimmung großer Sprachmodelle
Ein Artikel zum Verständnis der technischen Herausforderungen und Optimierungsstrategien für die Feinabstimmung großer Sprachmodelle

Hallo zusammen, mein Name ist Luga. Heute werden wir weiterhin Technologien im Ökosystem der künstlichen Intelligenz erforschen, insbesondere LLM Fine-Tuning. In diesem Artikel wird die LLM-Feinabstimmungstechnologie weiterhin eingehend analysiert, um allen zu helfen, ihren Implementierungsmechanismus besser zu verstehen, damit sie besser auf die Marktentwicklung und andere Bereiche angewendet werden kann.

LLMs (Large Language Models) sind führend in der neuen Welle der Technologie der künstlichen Intelligenz. Diese fortschrittliche KI simuliert die kognitiven und sprachlichen Fähigkeiten des Menschen, indem sie riesige Datenmengen mithilfe statistischer Modelle analysiert, um komplexe Muster zwischen Wörtern und Phrasen zu lernen. Die leistungsstarken Funktionen von LLMs haben großes Interesse bei vielen führenden Unternehmen und Technologiebegeisterten geweckt, die sich beeilen, diese innovativen, auf künstlicher Intelligenz basierenden Lösungen einzuführen, mit dem Ziel, die betriebliche Effizienz zu verbessern, die Arbeitsbelastung zu verringern, die Kostenaufwendungen zu senken und letztendlich zu inspirieren innovativere Ideen, die Geschäftswert schaffen.
Um jedoch das Potenzial von LLMs wirklich auszuschöpfen, liegt der Schlüssel in der „Anpassung“. Das heißt, wie Unternehmen durch spezifische Optimierungsstrategien allgemeine vorab trainierte Modelle in exklusive Modelle umwandeln können, die ihren eigenen individuellen Geschäftsanforderungen und Anwendungsszenarien entsprechen. Angesichts der Unterschiede zwischen verschiedenen Unternehmen und Anwendungsszenarien ist die Wahl einer geeigneten LLM-Integrationsmethode besonders wichtig. Daher wird die genaue Bewertung spezifischer Anwendungsfallanforderungen und das Verständnis der subtilen Unterschiede und Kompromisse zwischen verschiedenen Integrationsoptionen Unternehmen dabei helfen, fundierte Entscheidungen zu treffen.
Was ist Feinabstimmung?
Im heutigen Zeitalter der Popularisierung von Wissen war es noch nie einfacher, Informationen und Meinungen über KI und LLM einzuholen. Allerdings bleibt es eine Herausforderung, praktische, kontextspezifische professionelle Antworten zu finden. In unserem täglichen Leben stoßen wir oft auf ein so weit verbreitetes Missverständnis: Es wird allgemein angenommen, dass Fine-Tuning-Modelle (Feinabstimmungsmodelle) die einzige (oder vielleicht die beste) Möglichkeit für LLM sind, neues Wissen zu erwerben. Unabhängig davon, ob Sie Ihren Produkten intelligente kollaborative Assistenten hinzufügen oder LLM zur Analyse großer Mengen unstrukturierter Daten in der Cloud verwenden, sind Ihre tatsächlichen Daten und Ihre Geschäftsumgebung Schlüsselfaktoren bei der Wahl des richtigen LLM-Ansatzes.
In vielen Fällen ist es oft effektiver, alternative Strategien anzuwenden, die weniger komplex in der Handhabung sind, robuster gegenüber sich häufig ändernden Datensätzen sind und zuverlässigere und genauere Ergebnisse liefern als herkömmliche Feinabstimmungsmethoden. Obwohl die Feinabstimmung eine gängige LLM-Anpassungstechnik ist, die zusätzliches Training an einem vorab trainierten Modell für einen bestimmten Datensatz durchführt, um es besser an eine bestimmte Aufgabe oder Domäne anzupassen, weist sie auch einige wichtige Kompromisse und Einschränkungen auf.
Was ist also Feinabstimmung?
LLM-Feinabstimmung (Large Language Model) ist eine der Technologien, die in den letzten Jahren im Bereich NLP (Natural Language Processing) viel Aufmerksamkeit erregt hat. Dadurch kann sich das Modell besser an eine bestimmte Domäne oder Aufgabe anpassen, indem zusätzliches Training an einem bereits trainierten Modell durchgeführt wird. Diese Methode ermöglicht es dem Modell, mehr Wissen in Bezug auf eine bestimmte Domäne zu erlernen und dadurch eine bessere Leistung in dieser Domäne oder Aufgabe zu erzielen. Der Vorteil der LLM-Feinabstimmung besteht darin, dass sie sich das allgemeine Wissen zunutze macht, das das vorab trainierte Modell gelernt hat, und es dann in einem bestimmten Bereich weiter verfeinert, um eine höhere Genauigkeit und Leistung bei bestimmten Aufgaben zu erreichen. Diese Methode wird häufig bei verschiedenen NLP-Aufgaben eingesetzt und hat bedeutende Ergebnisse erzielt. Das Hauptkonzept der LLM-Feinabstimmung besteht darin, die Parameter des vorab trainierten Modells als Grundlage für neue Aufgaben zu verwenden und das Modell durch eine Feinabstimmung zu optimieren eine kleine Menge spezifischer Domänen- oder Aufgabendaten. Fähigkeit zur schnellen Anpassung an neue Aufgaben oder Datensätze. Diese Methode kann viel Trainingszeit und -ressourcen sparen und gleichzeitig die Leistung des Modells bei neuen Aufgaben verbessern. Die Flexibilität und Effizienz der LLM-Feinabstimmung machen sie zu einer der bevorzugten Methoden bei vielen Aufgaben der Verarbeitung natürlicher Sprache. Durch die Feinabstimmung auf Basis eines vorab trainierten Modells kann das Modell Funktionen und Muster für neue Aufgaben schneller erlernen und so die Gesamtleistung verbessern. Dies
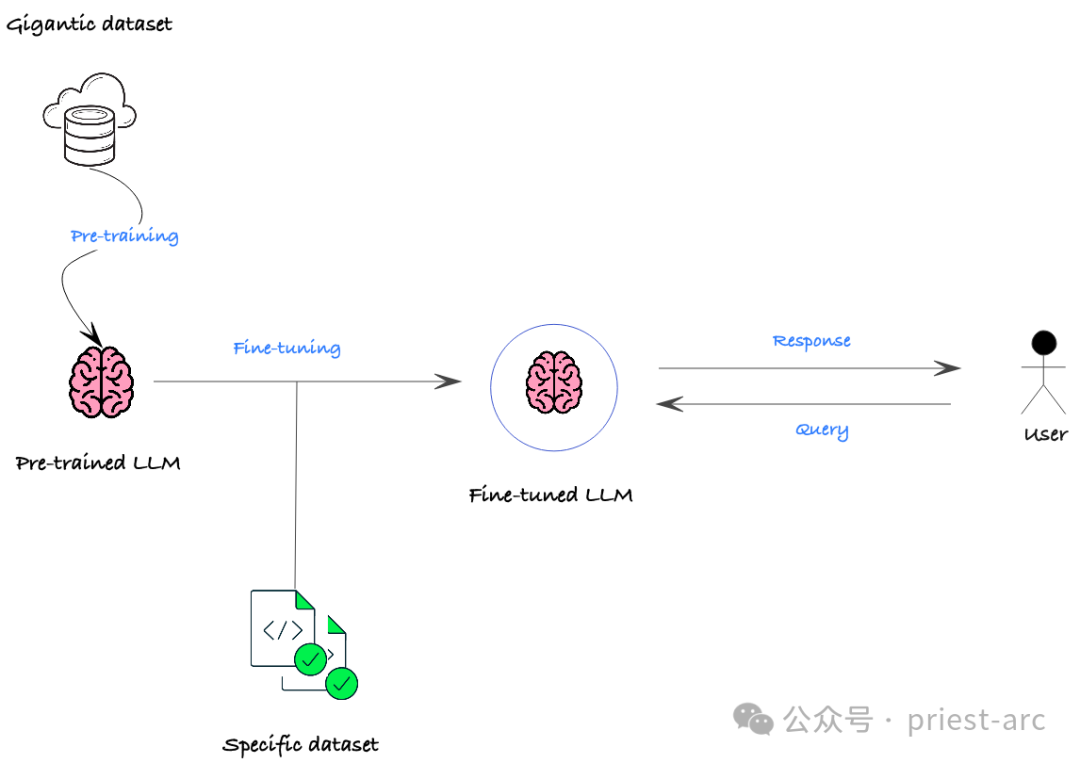 In tatsächlichen Geschäftsszenarien umfassen die Hauptzwecke der Feinabstimmung normalerweise die folgenden Punkte:
In tatsächlichen Geschäftsszenarien umfassen die Hauptzwecke der Feinabstimmung normalerweise die folgenden Punkte:
(1) Domänenanpassung
LLM wird normalerweise auf domänenübergreifenden allgemeinen Daten trainiert, jedoch auf bestimmte In-Felder angewendet B. in finanziellen, medizinischen, rechtlichen und anderen Situationen, kann die Leistung erheblich beeinträchtigt werden. Durch Feinabstimmung kann das vorab trainierte Modell an die Zieldomäne angepasst und angepasst werden, sodass es die Sprachmerkmale und semantischen Beziehungen einer bestimmten Domäne besser erfassen und dadurch die Leistung in dieser Domäne verbessern kann.
(2) Aufgabenanpassung
Selbst im gleichen Bereich können unterschiedliche spezifische Aufgaben unterschiedliche Anforderungen haben. Beispielsweise stellen NLP-Aufgaben wie Textklassifizierung, Beantwortung von Fragen, Erkennung benannter Entitäten usw. unterschiedliche Anforderungen an das Sprachverständnis und die Generierungsfähigkeiten. Durch Feinabstimmung können die Leistungsindikatoren des Modells für bestimmte Aufgaben, wie Genauigkeit, Rückruf, F1-Wert usw., entsprechend den spezifischen Anforderungen nachgelagerter Aufgaben optimiert werden.
(3) Leistungsverbesserung
Selbst bei einer bestimmten Aufgabe kann das vorab trainierte Modell Engpässe in Bezug auf Genauigkeit, Geschwindigkeit usw. aufweisen. Durch Feinabstimmung können wir die Leistung des Modells bei dieser Aufgabe weiter verbessern. Beispielsweise kann das Modell für Echtzeit-Anwendungsszenarien, die eine hohe Inferenzgeschwindigkeit erfordern, komprimiert und für Schlüsselaufgaben optimiert werden, die eine höhere Genauigkeit erfordern. Außerdem kann die Beurteilungsfähigkeit des Modells durch Feinabstimmung weiter verbessert werden.
Welche Vorteile und Schwierigkeiten bietet die Feinabstimmung (Feinabstimmung)?
Im Allgemeinen besteht der Hauptvorteil der Feinabstimmung (Feinabstimmung) darin, dass die Leistung vorhandener vorab trainierter Modelle effektiv verbessert werden kann in spezifischen Anwendungsszenarien. Durch kontinuierliches Training und Parameteranpassung des Basismodells im Zielbereich oder in der Zielaufgabe können die semantischen Merkmale und Muster in bestimmten Szenarien besser erfasst werden, wodurch die Schlüsselindikatoren des Modells in diesem Bereich oder in dieser Aufgabe erheblich verbessert werden. Durch die Feinabstimmung des Llama-2-Modells kann beispielsweise die Leistung einiger Funktionen besser sein als bei der ursprünglichen Sprachmodellimplementierung von Meta.
Obwohl die Feinabstimmung dem LLM erhebliche Vorteile bringt, sind auch einige Nachteile zu berücksichtigen. Vor welchen Problemen steht die Feinabstimmung (Feinabstimmung)? während des Vortrainings. Dies kann passieren, wenn die Nudge-Daten zu spezifisch sind oder sich hauptsächlich auf einen engen Bereich konzentrieren.
Datenanforderungen: Obwohl für die Feinabstimmung weniger Daten erforderlich sind als für das Training von Grund auf, sind für die spezifische Aufgabe dennoch hochwertige und relevante Daten erforderlich. Unzureichende oder falsch gekennzeichnete Daten können zu einer schlechten Leistung führen.
- Rechenressourcen: Der Feinabstimmungsprozess bleibt rechenintensiv, insbesondere bei komplexen Modellen und großen Datensätzen. Für kleinere Organisationen oder solche mit begrenzten Ressourcen kann dies ein Hindernis darstellen.
- Expertise erforderlich: Für die Feinabstimmung sind häufig Fachkenntnisse in Bereichen wie maschinellem Lernen, NLP und der spezifischen Aufgabe erforderlich. Die Auswahl des richtigen vorab trainierten Modells, die Konfiguration von Hyperparametern und die Auswertung der Ergebnisse können für diejenigen, die nicht über die erforderlichen Kenntnisse verfügen, kompliziert sein.
- Potenzielle Probleme:
- Bias-Verstärkung: Vorab trainierte Modelle können Bias aus ihren Trainingsdaten erben. Wenn die verschobenen Daten ähnliche Verzerrungen widerspiegeln, kann der Nudge diese Verzerrungen unbeabsichtigt verstärken. Dies kann zu unfairen oder diskriminierenden Ergebnissen führen.
Interpretierbarkeitsherausforderung: Fein abgestimmte Modelle sind schwieriger zu interpretieren als vorab trainierte Modelle. Es kann schwierig sein zu verstehen, wie ein Modell seine Ergebnisse erzielt, was das Debuggen und das Vertrauen in die Modellausgabe behindern kann.
- Sicherheitsrisiko: Fein abgestimmte Modelle können anfällig für gegnerische Angriffe sein, bei denen böswillige Akteure Eingabedaten manipulieren und dazu führen, dass das Modell falsche Ausgaben erzeugt.
- Wie schneidet Fine-Tuning im Vergleich zu anderen Anpassungsmethoden ab?
- Im Allgemeinen ist Fine-Tuning nicht die einzige Möglichkeit, die Modellausgabe anzupassen oder benutzerdefinierte Daten zu integrieren. Tatsächlich ist es möglicherweise nicht für unsere spezifischen Anforderungen und Anwendungsfälle geeignet. Es gibt einige andere Alternativen, die es wert sind, erkundet und in Betracht gezogen zu werden:
Diese Strategie ist relativ einfach, dennoch sollte ein datengesteuerter Ansatz verwendet werden, um die Genauigkeit verschiedener Tipps quantitativ zu bewerten, um die gewünschte Leistung sicherzustellen. Auf diese Weise können wir die Hinweise systematisch verfeinern, um den effizientesten Weg zu finden, das Modell so zu steuern, dass es die gewünschte Ausgabe liefert.
Prompt Engineering ist jedoch nicht ohne Mängel. Erstens können große Datensätze nicht direkt integriert werden, da Eingabeaufforderungen normalerweise manuell geändert und bereitgestellt werden. Dies bedeutet, dass Prompt Engineering bei der Verarbeitung großer Datenmengen möglicherweise weniger effizient erscheint. 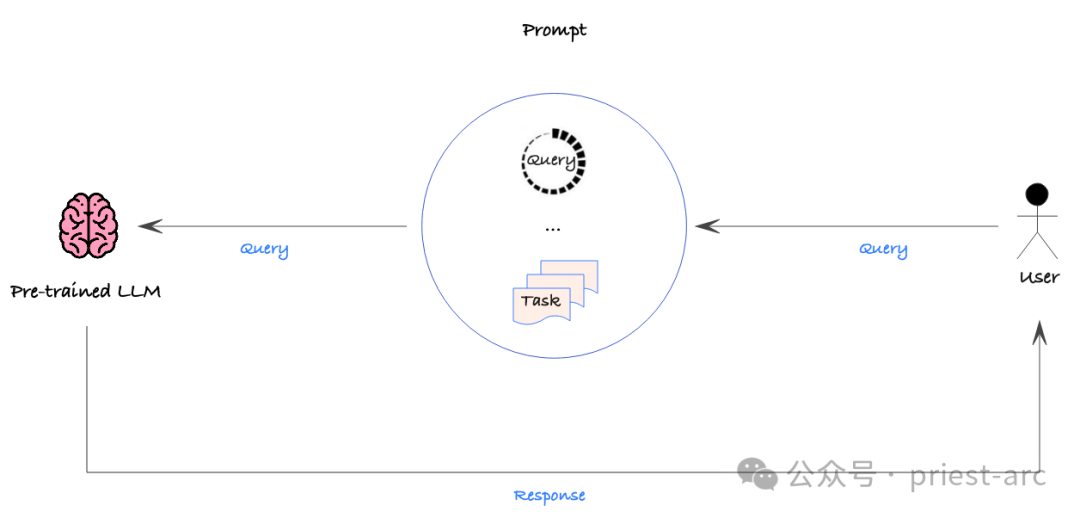
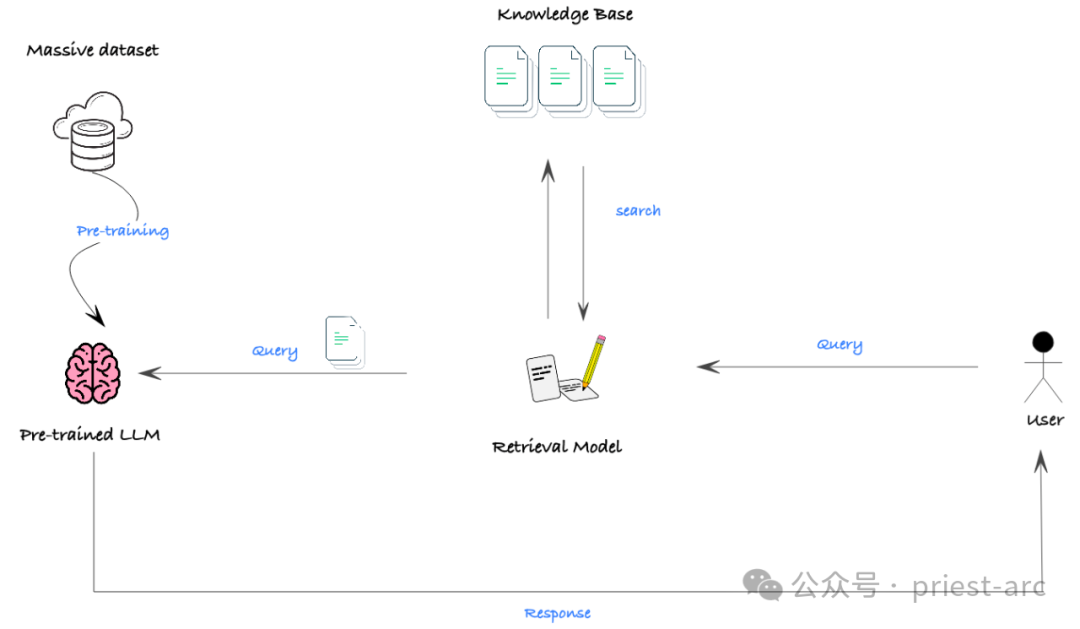
In tatsächlichen Szenarien besteht das größte Hindernis für die Wirksamkeit von RAG darin, dass viele Modelle ein begrenztes Kontextfenster haben, d. h. die maximale Textlänge, die das Modell gleichzeitig verarbeiten kann, ist begrenzt. In einigen Situationen, in denen umfangreiches Hintergrundwissen erforderlich ist, kann es sein, dass das Modell nicht genügend Informationen erhält, um eine gute Leistung zu erzielen.
Mit der rasanten Entwicklung der Technologie erweitert sich jedoch das Kontextfenster des Modells rasch. Sogar einige Open-Source-Modelle konnten Langtexteingaben von bis zu 32.000 Token verarbeiten. Damit hat RAG künftig breitere Einsatzmöglichkeiten und kann komplexere Aufgabenstellungen tatkräftig unterstützen.
Lassen Sie uns als Nächstes die spezifische Leistung dieser drei Technologien in Bezug auf den Datenschutz verstehen und vergleichen. Einzelheiten finden Sie im Folgenden:
(1) Feinabstimmung (Feinabstimmung)
Feinabstimmung ( Feinabstimmung) besteht darin, dass die beim Training des Modells verwendeten Informationen in die Parameter des Modells codiert werden. Dies bedeutet, dass die zugrunde liegenden Trainingsdaten möglicherweise trotzdem durchgesickert sind, selbst wenn die Ausgabe des Modells für den Benutzer privat ist. Untersuchungen zeigen, dass böswillige Angreifer durch Injektionsangriffe sogar rohe Trainingsdaten aus Modellen extrahieren können. Daher müssen wir davon ausgehen, dass alle zum Trainieren des Modells verwendeten Daten möglicherweise für zukünftige Benutzer zugänglich sind.
(2) Prompt Engineering
Im Vergleich dazu ist der Datensicherheits-Fußabdruck von Prompt Engineering viel geringer. Da Eingabeaufforderungen für jeden Benutzer isoliert und angepasst werden können, können die in den Eingabeaufforderungen enthaltenen Daten für verschiedene Benutzer unterschiedlich sein. Wir müssen jedoch weiterhin sicherstellen, dass alle in der Eingabeaufforderung enthaltenen Daten nicht vertraulich oder für jeden Benutzer mit Zugriff auf die Eingabeaufforderung zulässig sind.
(3) RAG (Retrieval Enhancement Generation)
RAGs Sicherheit hängt von der Datenzugriffskontrolle im zugrunde liegenden Abrufsystem ab. Wir müssen sicherstellen, dass die zugrunde liegende Vektordatenbank und die Eingabeaufforderungsvorlagen mit geeigneten Datenschutz- und Datenkontrollen konfiguriert sind, um unbefugten Zugriff zu verhindern. Nur so kann die RAG den Datenschutz wirklich gewährleisten.
Insgesamt haben Prompt Engineering und RAG beim Thema Datenschutz klare Vorteile gegenüber Fine-Tuning. Unabhängig davon, welche Methode wir anwenden, müssen wir den Datenzugriff und den Schutz der Privatsphäre sehr sorgfältig verwalten, um sicherzustellen, dass die sensiblen Informationen der Benutzer vollständig geschützt sind.
Unabhängig davon, ob wir uns letztendlich für Fine-Tuning, Prompt Engineering oder RAG entscheiden, sollte der gewählte Ansatz mit den strategischen Zielen, den verfügbaren Ressourcen, den beruflichen Fähigkeiten und der erwarteten Kapitalrendite im Einklang stehen. Es geht nicht nur um rein technische Fähigkeiten, sondern auch darum, wie diese Ansätze zu unserer Geschäftsstrategie, unseren Zeitplänen, aktuellen Arbeitsabläufen und Marktanforderungen passen.
Mit der Fine-Tuning-Option ist ein tiefes Verständnis der Feinheiten der Schlüssel zum Treffen fundierter Entscheidungen. Die technischen Details und die Datenaufbereitung beim Fine-Tuning sind relativ komplex und erfordern ein tiefgreifendes Verständnis des Modells und der Daten. Daher ist es von entscheidender Bedeutung, eng mit einem Partner zusammenzuarbeiten, der über umfassende Erfahrung in der Feinabstimmung verfügt. Diese Partner müssen nicht nur über zuverlässige technische Fähigkeiten verfügen, sondern auch in der Lage sein, unsere Geschäftsprozesse und -ziele vollständig zu verstehen und die für uns am besten geeigneten maßgeschneiderten Technologielösungen auszuwählen.
Wenn wir uns für den Einsatz von Prompt Engineering oder RAG entscheiden, müssen wir ebenfalls sorgfältig abwägen, ob diese Methoden unseren Geschäftsanforderungen, Ressourcenbedingungen und erwarteten Auswirkungen entsprechen können. Letztendlich können wir nur dann erfolgreich sein, wenn wir sicherstellen, dass die gewählte maßgeschneiderte Technologie tatsächlich einen Mehrwert für unser Unternehmen schafft.
Referenz:
- [1] https://medium.com/@younesh.kc/rag-vs-fine-tuning-in-large-lingual-models-a-comparison-c765b9e21328
- [2] https ://kili-technology.com/large-lingual-models-llms/the-ultimate-guide-to-fine-tuning-llms-2023
Das obige ist der detaillierte Inhalt vonEin Artikel zum Verständnis der technischen Herausforderungen und Optimierungsstrategien für die Feinabstimmung großer Sprachmodelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1659
1659
 14
1415
52
1310
25
1258
29
1232
24
14
1415
52
1310
25
1258
29
1232
24

 Wie viel ist Bitcoin wert?
Apr 28, 2025 pm 07:42 PM
Wie viel ist Bitcoin wert?
Apr 28, 2025 pm 07:42 PM
Der Preis von Bitcoin liegt zwischen 20.000 und 30.000 US -Dollar. 1. Bitcoin's Preis hat seit 2009 dramatisch geschwankt und im Jahr 2017 fast 20.000 US -Dollar und im Jahr 2021 in Höhe von fast 60.000 USD erreicht. 2. Die Preise werden von Faktoren wie Marktnachfrage, Angebot und makroökonomischem Umfeld beeinflusst. 3. Erhalten Sie Echtzeitpreise über Börsen, mobile Apps und Websites. V. 5. Es hat eine gewisse Beziehung zu den traditionellen Finanzmärkten und ist von den globalen Aktienmärkten, der Stärke des US-Dollars usw. betroffen. 6. Der langfristige Trend ist optimistisch, aber Risiken müssen mit Vorsicht bewertet werden.
 Welche der zehn besten Währungshandelsplattformen der Welt gehören 2025 zu den zehn Top -Währungshandelsplattformen
Apr 28, 2025 pm 08:12 PM
Welche der zehn besten Währungshandelsplattformen der Welt gehören 2025 zu den zehn Top -Währungshandelsplattformen
Apr 28, 2025 pm 08:12 PM
Zu den zehn Top -Kryptowährungsbörsen der Welt im Jahr 2025 gehören Binance, OKX, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, Kucoin, Bittrex und Poloniex, die alle für ihr hohes Handelsvolumen und ihre Sicherheit bekannt sind.
 Welche der zehn besten Währungsplattformen der Welt sind die neueste Version der zehn besten Währungshandelsplattformen
Apr 28, 2025 pm 08:09 PM
Welche der zehn besten Währungsplattformen der Welt sind die neueste Version der zehn besten Währungshandelsplattformen
Apr 28, 2025 pm 08:09 PM
Zu den zehn Top -Kryptowährungs -Handelsplattformen der Welt gehören Binance, OKX, Gate.io, Coinbase, Kraken, Huobi Global, Bitfinex, Bittrex, Kucoin und Poloniex, die alle eine Vielzahl von Handelsmethoden und leistungsstarken Sicherheitsmaßnahmen bieten.
 Decryption Gate.io Strategy Upgrade: Wie definieren Sie das Krypto -Asset -Management in Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.io Strategy Upgrade: Wie definieren Sie das Krypto -Asset -Management in Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Memebox 2.0 definiert das Krypto -Asset -Management durch innovative Architektur- und Leistungsbrachdurchbrüche. 1) Es löst drei Hauptschmerzpunkte: Vermögenssetsilos, Einkommensverfall und Paradox der Sicherheit und Bequemlichkeit. 2) Durch intelligente Asset-Hubs werden dynamische Risikomanagement- und Renditeverstärkungsmotoren die Übertragungsgeschwindigkeit, die durchschnittliche Ertragsrate und die Reaktionsgeschwindigkeit für Sicherheitsvorfälle verbessert. 3) Nutzern die Integration von Asset Visualisierung, Richtlinienautomatisierung und Governance -Integration zur Verfügung stellen und die Rekonstruktion des Benutzerwerts realisieren. 4) Durch ökologische Zusammenarbeit und Compliance -Innovation wurde die Gesamtwirksamkeit der Plattform verbessert. 5) In Zukunft werden intelligente Vertragsversicherungspools, die Prognosemarktintegration und die KI-gesteuerte Vermögenszuweisung gestartet, um weiterhin die Entwicklung der Branche zu leiten.
 Was sind die zehn Top -Apps für virtuelle Währungshandel? Die neuesten Ranglisten für digitale Währung Exchange
Apr 28, 2025 pm 08:03 PM
Was sind die zehn Top -Apps für virtuelle Währungshandel? Die neuesten Ranglisten für digitale Währung Exchange
Apr 28, 2025 pm 08:03 PM
Die zehn Top -Börsen für digitale Währungen wie Binance, OKX, Gate.io haben ihre Systeme, effiziente diversifizierte Transaktionen und strenge Sicherheitsmaßnahmen verbessert.
 Was sind die Top -Währungshandelsplattformen? Die Top 10 neuesten virtuellen Währungsbörsen
Apr 28, 2025 pm 08:06 PM
Was sind die Top -Währungshandelsplattformen? Die Top 10 neuesten virtuellen Währungsbörsen
Apr 28, 2025 pm 08:06 PM
Derzeit unter den zehn besten Börsen der virtuellen Währung eingestuft: 1. Binance, 2. OKX, 3. Gate.io, 4. Coin Library, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9. Bitcoin, 10. Bit Stamp.
 Empfohlene zuverlässige Handelsplattformen für digitale Währung. Top 10 Digitalwährungsbörsen in der Welt. 2025
Apr 28, 2025 pm 04:30 PM
Empfohlene zuverlässige Handelsplattformen für digitale Währung. Top 10 Digitalwährungsbörsen in der Welt. 2025
Apr 28, 2025 pm 04:30 PM
Empfohlene zuverlässige Handelsplattformen für digitale Währung: 1. OKX, 2. Binance, 3. Coinbase, 4. Kraken, 5. Huobi, 6. Kucoin, 7. Bitfinex, 8. Gemini, 9. Bitstamp, 10. Poloniex, diese Plattformen sind für ihre Sicherheit, Benutzererfahrung und verschiedene Funziktionen, geeignet für Benutzer, geeignet für Benutzer, geeignet für Benutzer, geeignet für Benutzer, geeignet für Ufers, für Benutzer, geeignet für Ufersniveaus, in unterschiedlichen Digitalverkehrsniveaus, in unterschiedlichen Niveaus, bei Digitalwährung, für Nutzer, für Benutzer, in unterschiedliche Ebenen von Digitalwährung, für Benutzer, die für Nutzer, für Benutzer, in unterschiedlichen Digitalverkehrsniveaus, auf Digitalwährung, auf Digitalwährung, auf Digitalwährung, bei Digitalwährung, auf Digitalwährung bekannt
 Wie benutze ich die Chrono -Bibliothek in C?
Apr 28, 2025 pm 10:18 PM
Wie benutze ich die Chrono -Bibliothek in C?
Apr 28, 2025 pm 10:18 PM
Durch die Verwendung der Chrono -Bibliothek in C können Sie Zeit- und Zeitintervalle genauer steuern. Erkunden wir den Charme dieser Bibliothek. Die Chrono -Bibliothek von C ist Teil der Standardbibliothek, die eine moderne Möglichkeit bietet, mit Zeit- und Zeitintervallen umzugehen. Für Programmierer, die in der Zeit gelitten haben.H und CTime, ist Chrono zweifellos ein Segen. Es verbessert nicht nur die Lesbarkeit und Wartbarkeit des Codes, sondern bietet auch eine höhere Genauigkeit und Flexibilität. Beginnen wir mit den Grundlagen. Die Chrono -Bibliothek enthält hauptsächlich die folgenden Schlüsselkomponenten: std :: chrono :: system_clock: repräsentiert die Systemuhr, mit der die aktuelle Zeit erhalten wird. std :: chron
