
 Hardware-Tutorial
Hardware-Rezension
Google veröffentlicht „Vlogger'-Modell: Ein einzelnes Bild erzeugt ein 10-Sekunden-Video
Hardware-Tutorial
Hardware-Rezension
Google veröffentlicht „Vlogger'-Modell: Ein einzelnes Bild erzeugt ein 10-Sekunden-Video
Google veröffentlicht „Vlogger'-Modell: Ein einzelnes Bild erzeugt ein 10-Sekunden-Video

Google hat ein neues Video-Framework veröffentlicht:
Sie benötigen lediglich ein Bild Ihres Gesichts und eine Aufzeichnung Ihrer Rede, um ein lebensechtes Video Ihrer Rede zu erhalten.
Die Länge des Videos ist variabel und beträgt im aktuell angezeigten Beispiel bis zu 10 Sekunden.
Man sieht, dass sowohl die Mundform als auch der Gesichtsausdruck sehr natürlich sind.
Wenn das Eingabebild den gesamten Oberkörper abdeckt, kann es auch mit verschiedenen Gesten verwendet werden:

Nachdem es gelesen wurde, sagten Internetnutzer:
Damit müssen wir unsere Haare und Kleidung nicht mehr organisieren für Online-Videokonferenzen in der Zukunft.
Nun, machen Sie einfach ein Porträt und zeichnen Sie das Sprachaudio auf (manueller Hundekopf)
Verwenden Sie Ihre Stimme, um das Porträt zu steuern und ein Video zu erstellen
Dieses Framework heißt VLOGGER.
Es basiert hauptsächlich auf dem Diffusionsmodell und besteht aus zwei Teilen:
Einer ist ein zufälliges Diffusionsmodell von Mensch zu 3D-Bewegung.
Das andere ist eine neue Diffusionsarchitektur zur Verbesserung von Text-zu-Bild-Modellen.
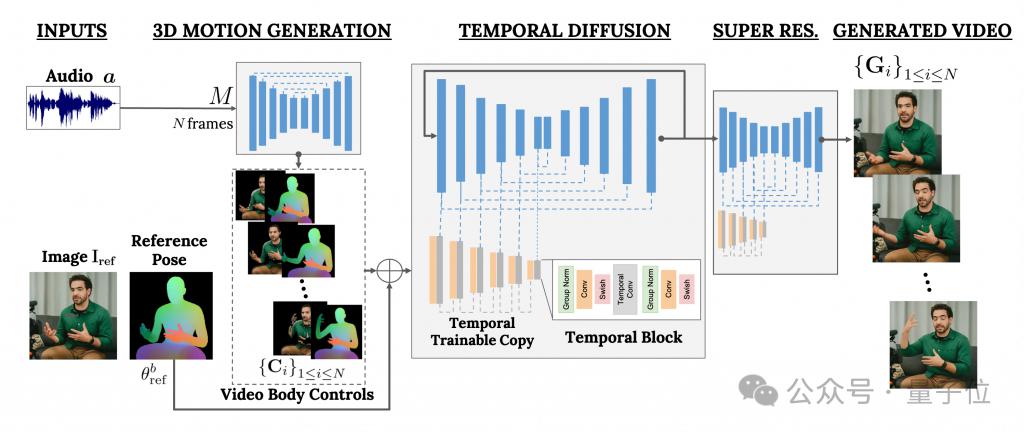
Unter ihnen ist ersterer dafür verantwortlich, die Audiowellenform als Eingabe zu verwenden, um die Körperkontrollaktionen des Charakters zu generieren, einschließlich Augen, Ausdrücke und Gesten, allgemeine Körperhaltung usw.
Letzteres ist ein Bild-zu-Bild-Modell mit zeitlicher Dimension, das verwendet wird, um das groß angelegte Bilddiffusionsmodell zu erweitern und die gerade vorhergesagten Aktionen zu verwenden, um entsprechende Frames zu generieren.
Um die Ergebnisse an ein bestimmtes Charakterbild anzupassen, verwendet VLOGGER auch die Posenkarte des Parameterbilds als Eingabe.
Das Training von VLOGGER wird an einem sehr großen Datensatz (mit dem Namen MENTOR) durchgeführt.
Wie groß ist es? Es ist 2.200 Stunden lang und enthält insgesamt 800.000 Charaktervideos.
Unter anderem beträgt die Videodauer des Testsets ebenfalls 120 Stunden mit insgesamt 4.000 Zeichen.
Google stellte fest, dass die herausragendste Leistung von VLOGGER seine Vielfalt ist:
Wie im Bild unten gezeigt, sind die Aktionen umso reichhaltiger, je dunkler (rot) die Farbe des endgültigen Pixelbilds ist.

Im Vergleich zu früheren ähnlichen Methoden in der Branche besteht der größte Vorteil von VLOGGER darin, dass nicht jeder geschult werden muss, nicht auf Gesichtserkennung und -zuschnitt angewiesen ist und das generierte Video vollständig ist (einschließlich Gesicht und Lippen). , einschließlich Körperbewegungen) usw.

Im Einzelnen, wie in der folgenden Tabelle gezeigt:
Die Gesichtsnachstellungsmethode kann eine solche Videogenerierung mit Audio und Text nicht steuern.
Audio-to-Motion kann Audio erzeugen, indem Audio in 3D-Gesichtsbewegungen kodiert wird, aber der dadurch erzeugte Effekt ist nicht realistisch genug.
Lip Sync kann Videos zu unterschiedlichen Themen verarbeiten, aber nur Mundbewegungen simulieren.
Im Vergleich schneiden die beiden letztgenannten Methoden, SadTaker und Styletalk, am ehesten mit Google VLOGGER ab, haben aber auch den Nachteil, dass sie den Körper nicht kontrollieren und das Video weiter bearbeiten können.

Apropos Videobearbeitung: Wie im Bild unten gezeigt, ist eine der Anwendungen des VLOGGER-Modells folgende: Es kann dazu führen, dass der Charakter den Mund hält, die Augen schließt, nur das linke Auge schließt oder das ganze Auge öffnet mit einem Klick:

Eine weitere Anwendung ist die Videoübersetzung:
Zum Beispiel das Ändern der englischen Sprache im Originalvideo ins Spanische mit der gleichen Mundform.
Internetnutzer haben sich beschwert
Schließlich hat Google das Modell nach der „alten Regel“ nicht veröffentlicht, und jetzt können wir nur noch mehr Effekte und Papiere sehen.
Nun, es gibt viele Beschwerden:
Die Bildqualität des Modells, die Lippensynchronisation stimmt nicht überein, es sieht immer noch sehr roboterhaft aus usw.
Daher haben einige Leute nicht gezögert, negative Bewertungen zu hinterlassen:
Ist das das Niveau von Google?

Entschuldigung für den Namen „VLOGGER“.

——Verglichen mit Sora von OpenAI ist die Aussage des Internetnutzers tatsächlich nicht unvernünftig. .
Was meint ihr?
Mehr Effekte:
https://enriccorona.github.io/vlogger/
Vollständiges Paper:
https://enriccorona.github.io/vlogger/paper.pdf
Das obige ist der detaillierte Inhalt vonGoogle veröffentlicht „Vlogger'-Modell: Ein einzelnes Bild erzeugt ein 10-Sekunden-Video. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Deepseek ist ein leistungsstarkes Informations -Abruf -Tool. .
 So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
Deepseek ist eine proprietäre Suchmaschine, die nur schneller und genauer in einer bestimmten Datenbank oder einem bestimmten System sucht. Bei der Verwendung wird den Benutzern empfohlen, das Dokument zu lesen, verschiedene Suchstrategien auszuprobieren, Hilfe und Feedback zur Benutzererfahrung zu suchen, um die Vorteile optimal zu nutzen.
 Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
In diesem Artikel wird der Registrierungsprozess der Webversion Sesam Open Exchange (GATE.IO) und die Gate Trading App im Detail vorgestellt. Unabhängig davon, ob es sich um eine Webregistrierung oder eine App -Registrierung handelt, müssen Sie die offizielle Website oder den offiziellen App Store besuchen, um die Genuine App herunterzuladen, und dann den Benutzernamen, das Kennwort, die E -Mail, die Mobiltelefonnummer und die anderen Informationen eingeben und eine E -Mail- oder Mobiltelefonüberprüfung abschließen.
 Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden? Bitbit ist eine Kryptowährungsbörse, die den Benutzern Handelsdienste anbietet. Die mobilen Apps der Exchange können aus den folgenden Gründen nicht direkt über AppStore oder Googleplay heruntergeladen werden: 1. App Store -Richtlinie beschränkt Apple und Google daran, strenge Anforderungen an die im App Store zulässigen Anwendungsarten zu haben. Kryptowährungsanträge erfüllen diese Anforderungen häufig nicht, da sie Finanzdienstleistungen einbeziehen und spezifische Vorschriften und Sicherheitsstandards erfordern. 2. Die Einhaltung von Gesetzen und Vorschriften In vielen Ländern werden Aktivitäten im Zusammenhang mit Kryptowährungstransaktionen reguliert oder eingeschränkt. Um diese Vorschriften einzuhalten, kann die Bitbit -Anwendung nur über offizielle Websites oder andere autorisierte Kanäle verwendet werden
 So laden Sie Deepseek herunter
Feb 19, 2025 pm 05:45 PM
So laden Sie Deepseek herunter
Feb 19, 2025 pm 05:45 PM
Stellen Sie sicher, dass Sie auf offizielle Website -Downloads zugreifen, und überprüfen Sie sorgfältig den Domain -Namen und das Design der Website. Scannen Sie nach dem Herunterladen die Datei. Lesen Sie das Protokoll während der Installation und vermeiden Sie die Systemdiskola bei der Installation. Testen Sie die Funktion und wenden Sie sich an den Kundendienst, um das Problem zu lösen. Aktualisieren Sie die Version regelmäßig, um die Sicherheit und Stabilität der Software zu gewährleisten.
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Es ist wichtig, einen formalen Kanal auszuwählen, um die App herunterzuladen und die Sicherheit Ihres Kontos zu gewährleisten.
 Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Eine detaillierte Einführung in den Anmeldungsbetrieb der Sesame Open Exchange -Webversion, einschließlich Anmeldeschritte und Kennwortwiederherstellungsprozess.
 Gate.io Exchange Official Registration Portal
Feb 20, 2025 pm 04:27 PM
Gate.io Exchange Official Registration Portal
Feb 20, 2025 pm 04:27 PM
Gate.io ist ein führender Kryptowährungsaustausch, der eine breite Palette von Krypto -Vermögenswerten und Handelspaaren bietet. Registrierung von Gate.io ist sehr einfach. Vervollständigen Sie die Registrierung. Mit Gate.io können Benutzer ein sicheres und bequemes Kryptowährungshandelserlebnis genießen.
