
 Technologie-Peripheriegeräte
KI
DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Technologie-Peripheriegeräte
KI
DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!

Dieses Papier untersucht das Problem der genauen Erkennung von Objekten aus verschiedenen Blickwinkeln (z. B. Perspektive und Vogelperspektive) beim autonomen Fahren, insbesondere wie man effektiv von der Perspektivansicht (PV) zum Vogelperspektivenraum (BEV) wechselt Transformationsfunktionen: Diese Transformation wird durch das Visual Transformation (VT)-Modul implementiert. Bestehende Methoden lassen sich grob in zwei Strategien unterteilen: 2D-zu-3D- und 3D-zu-2D-Konvertierung. 2D-zu-3D-Methoden verbessern dichte 2D-Merkmale durch die Vorhersage von Tiefenwahrscheinlichkeiten, aber die inhärente Unsicherheit von Tiefenvorhersagen, insbesondere in entfernten Regionen, kann zu Ungenauigkeiten führen. Während 3D-zu-2D-Methoden normalerweise 3D-Abfragen verwenden, um 2D-Features abzutasten und Aufmerksamkeitsgewichte für die Entsprechung zwischen 3D- und 2D-Features über einen Transformer zu lernen, erhöht dies die Komplexität der Berechnung und Bereitstellung.
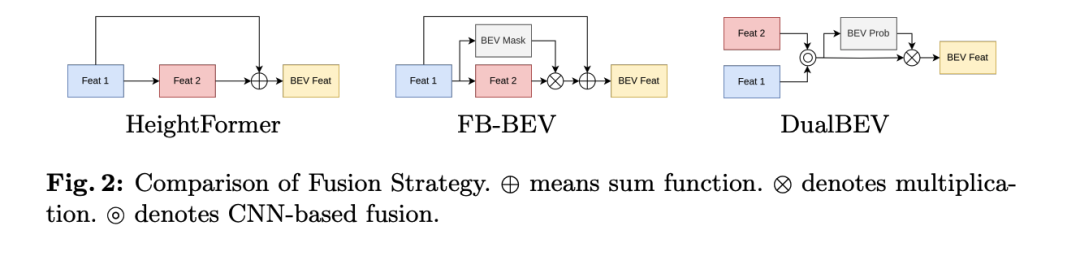
Der Artikel weist darauf hin, dass bestehende Methoden wie HeightFormer und FB-BEV versuchen, diese beiden VT-Strategien zu kombinieren, diese Methoden jedoch aufgrund der unterschiedlichen Merkmalstransformationen der dualen VT normalerweise eine zweistufige Strategie anwenden durch die anfängliche Funktionsleistung begrenzt. Dies behindert die nahtlose Integration zwischen zwei VTs. Darüber hinaus stehen diese Methoden immer noch vor Herausforderungen, wenn es darum geht, autonomes Fahren in Echtzeit umzusetzen.
Als Reaktion auf diese Probleme schlägt das Papier eine einheitliche Methode zur Merkmalskonvertierung vor, die für die visuelle Konvertierung von 2D in 3D und von 3D in 2D geeignet ist, und bewertet die Entsprechung zwischen 3D- und 2D-Merkmalen durch drei Wahrscheinlichkeitsmessungen: BEV-Wahrscheinlichkeit, Projektionswahrscheinlichkeit und Bild Wahrscheinlichkeit. Diese neue Methode zielt darauf ab, die Auswirkungen leerer Bereiche im BEV-Gitter auf die Feature-Konstruktion zu mildern, mehrere Entsprechungen zu unterscheiden und Hintergrund-Features während des Feature-Konvertierungsprozesses auszuschließen.
Durch die Anwendung dieser einheitlichen Merkmalstransformation untersucht der Artikel eine neue Methode der visuellen 3D-zu-2D-Transformation unter Verwendung von Convolutional Neural Networks (CNN) und stellt eine Methode namens HeightTrans vor. Es demonstriert nicht nur seine überlegene Leistung, sondern zeigt auch das Potenzial für Beschleunigung durch Vorberechnung, wodurch es für Anwendungen im autonomen Fahren in Echtzeit geeignet ist. Gleichzeitig wird durch die Integration dieser Merkmalstransformation der traditionelle LSS-Prozess verbessert und seine Universalität für aktuelle Detektoren demonstriert.
Durch die Kombination von HeightTrans und Prob-LSS stellt das Papier DualBEV vor, eine innovative Methode, die die Entsprechungen von BEV und perspektivischen Ansichten in einem Schritt berücksichtigt und zusammenführt und so die Abhängigkeit von anfänglichen Merkmalen beseitigt. Darüber hinaus wird ein leistungsstarkes BEV-Feature-Fusion-Modul namens Dual Feature Fusion (DFF)-Modul vorgeschlagen, um die BEV-Wahrscheinlichkeitsvorhersage durch die Nutzung von Kanalaufmerksamkeitsmodulen und räumlichen Aufmerksamkeitsmodulen weiter zu verfeinern. DualBEV folgt dem Prinzip „umfangreiche Eingabe, strikte Ausgabe“ und versteht und stellt die Wahrscheinlichkeitsverteilung der Szene dar, indem es eine präzise probabilistische Korrespondenz mit zwei Ansichten verwendet.
Die Hauptbeiträge des Artikels lauten wie folgt:
- enthüllt die intrinsische Ähnlichkeit zwischen der visuellen Transformation von 3D zu 2D und von 2D zu 3D und schlägt eine einheitliche Methode zur Merkmalstransformation vor, die sowohl aus BEV- als auch aus perspektivischer Sicht genau ist und eine entsprechende Beziehung herstellt verringert die Lücke zwischen den beiden Strategien erheblich.
- Hat eine neue CNN-basierte visuelle 3D-zu-2D-Konvertierungsmethode HeightTrans vorgeschlagen, die durch Wahrscheinlichkeitsstichproben und Vorberechnung von Nachschlagetabellen effektiv und effizient eine genaue 3D-2D-Korrespondenz herstellt.
- DFF wird für die Dual-View-Feature-Fusion eingeführt. Diese Fusionsstrategie erfasst Informationen von Nah- und Fernregionen in einem Schritt und generiert so umfassende BEV-Features.
- Ihr effizientes Framework DualBEV erreicht 55,2 % mAP und 63,4 % NDS auf dem nuScenes-Testsatz, auch ohne Verwendung von Transformer, was die Bedeutung der Erfassung einer genauen Dual-View-Korrespondenz für die Ansichtstransformation unterstreicht.
Durch diese Innovationen schlägt das Papier eine neue Strategie vor, um die Einschränkungen bestehender Methoden zu überwinden und eine effizientere und genauere Objekterkennung in Echtzeit-Anwendungsszenarien wie dem autonomen Fahren zu erreichen.
Detaillierte Erklärung von DualBEV
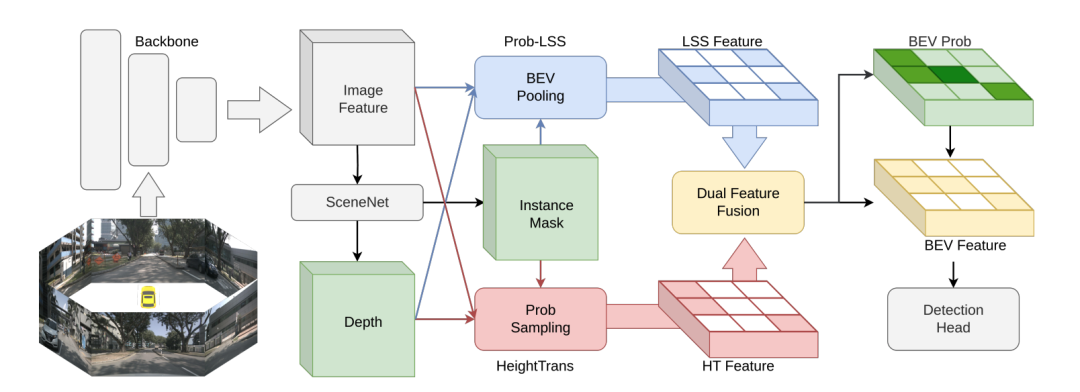
Die in diesem Artikel vorgeschlagene Methode zielt darauf ab, das BEV-Objekterkennungsproblem (Vogelperspektive) beim autonomen Fahren durch ein einheitliches Feature-Konvertierungs-Framework, DualBEV, zu lösen. Nachfolgend finden Sie den Hauptinhalt des Abschnitts „Methoden“ mit einem Überblick über die verschiedenen Unterabschnitte und wichtigsten Neuerungen.
DualBEV-Übersicht
Der Verarbeitungsablauf von DualBEV beginnt mit den Bildfunktionen , die von mehreren Kameras erhalten wurden, und verwendet dann SceneNet, um Instanzmasken und Tiefenkarten zu generieren. Anschließend erfolgt die Extraktion über das HeightTrans-Modul und Prob-LSS Pipeline- und Transformationsfunktionen, und schließlich werden diese Funktionen zusammengeführt und verwendet, um die Wahrscheinlichkeitsverteilung des BEV-Raums vorherzusagen, um die endgültigen BEV-Funktionen für nachfolgende Aufgaben zu erhalten.
HeightTrans
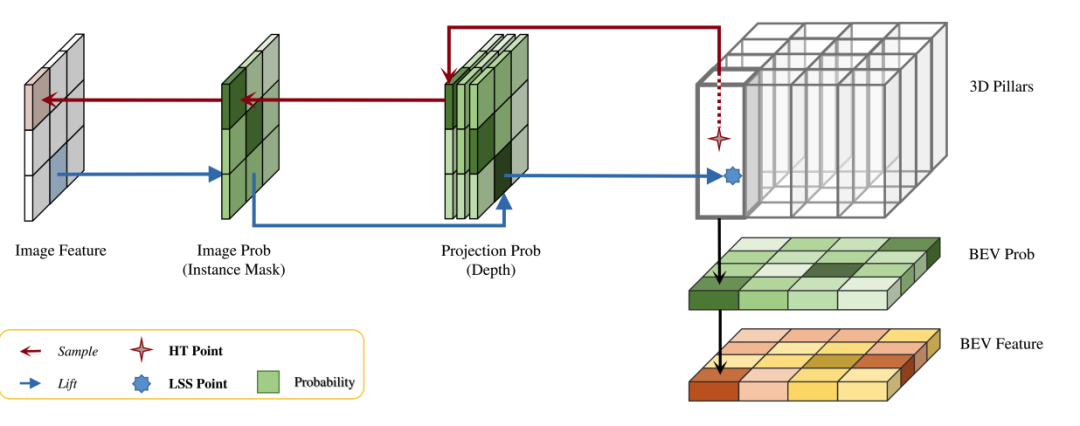
HeightTrans basiert auf dem Prinzip der visuellen Konvertierung von 3D in 2D, indem 3D-Positionen ausgewählt und in den Bildraum projiziert werden und diese 3D-2D-Entsprechungen ausgewertet werden. Diese Methode tastet zunächst eine Reihe von 3D-Punkten in einer vordefinierten BEV-Karte ab und berücksichtigt und filtert dann diese Korrespondenzen sorgfältig, um BEV-Features zu generieren. HeightTrans erhöht die Aufmerksamkeit auf kleine Objekte und löst das durch Hintergrundpixel verursachte irreführende Problem durch die Anwendung einer Multi-Resolution-Sampling-Strategie und einer Wahrscheinlichkeits-Sampling-Methode. Darüber hinaus wird das Problem des leeren BEV-Gitters durch die Einführung der BEV-Wahrscheinlichkeit gelöst . Das HeightTrans-Modul ist eine der in der Arbeit vorgeschlagenen Schlüsseltechnologien und konzentriert sich auf die Verarbeitung und Transformation von Merkmalen durch visuelle Transformation (VT) von 3D in 2D. Es basiert auf der Auswahl von 3D-Standorten aus einer vordefinierten BEV-Karte (Bird's Eye View) und der Projektion dieser Standorte in den Bildraum, wodurch die Entsprechung zwischen 3D und 2D bewertet wird. Im Folgenden finden Sie eine detaillierte Einführung in die Funktionsweise von HeightTrans:
BEV Height
Die HeightTrans-Methode verwendet bei der Höhenverarbeitung eine Abtaststrategie mit mehreren Auflösungen, die den gesamten Höhenbereich (von -5 Metern bis 3 Metern) abdeckt Interessengebiet Die Auflösung innerhalb des ROI (definiert als -2 Meter bis 2 Meter) beträgt 0,5 Meter und die Auflösung außerhalb dieses Bereichs beträgt 1,0 Meter. Diese Strategie trägt dazu bei, die Konzentration auf kleine Objekte zu erhöhen, die bei der Abtastung mit gröberer Auflösung möglicherweise übersehen werden.
Prob-Sampling
HeightTrans übernimmt die folgenden Schritte beim probabilistischen Sampling:
- Definieren von 3D-Sampling-Punkten: Definieren Sie einen Satz von 3D-Sampling-Punkten vor, jeder Punkt wird durch seine Position im 3D-Raum bestimmt Definition.
- Projektion in den 2D-Raum: Projizieren Sie den 3D-Punkt mithilfe der extrinsischen Parametermatrix und der intrinsischen Parametermatrix der Kamera auf einen Punkt im 2D-Bildraum , wobei die Tiefe des Punktes darstellt.
- Feature-Sampling: Verwenden Sie einen bilinearen Grid-Sampler , um Bildmerkmale an der Projektionsposition abzutasten :
- Instanzmaske verwenden : Um zu vermeiden, dass die Projektionsposition auf die Hintergrundpixel fällt, verwenden Sie SceneNet um eine Instanzmaske zu generieren, um die Bildwahrscheinlichkeit darzustellen und sie auf Bildmerkmale anzuwenden, um die Auswirkungen irreführender Informationen zu reduzieren:
- Behandeln Sie mehrere Korrespondenzen : Verwenden Sie einen trilinearen Raster-Sampler in der Tiefenkarte und wertet die aus Situation, in der mehrere 3D-Punkte derselben 2D-Position zugeordnet sind, d Die BEV-Wahrscheinlichkeit wird eingeführt. Stellt die Belegungswahrscheinlichkeit des BEV-Gitters dar, wobei
- die Position im BEV-Raum ist: beschleunigt durch Vorberechnung des Index der 3D-Punkte im BEV-Raum und Festlegung des Bildmerkmalsindex und Tiefenkartenindex während der Inferenz kann HeightTrans den visuellen Konvertierungsprozess beschleunigen. Die letzte HeightTrans-Funktion erweitert die traditionelle LSS-Pipeline (Lift, Splat, Shoot), indem sie Tiefenwahrscheinlichkeiten für jedes Pixel mit vordefiniertem
Prob-LSS
Prob-LSS für jedes BEV-Netz vorhersagt. Es wird in den BEV-Raum projiziert. Diese Methode integriert BEV-Wahrscheinlichkeiten weiter, um LSS-Merkmale über die folgende Formel zu erstellen:
Dadurch kann die Unsicherheit in der Tiefenschätzung besser gehandhabt werden, wodurch redundante Informationen im BEV-Raum reduziert werden.
Dual Feature Fusion (DFF)Das DFF-Modul wurde entwickelt, um Features von HeightTrans und Prob-LSS zu fusionieren und die BEV-Wahrscheinlichkeit effektiv vorherzusagen. Durch die Kombination des Kanalaufmerksamkeitsmoduls und des durch räumliche Aufmerksamkeit erweiterten ProbNet ist DFF in der Lage, die Merkmalsauswahl und die BEV-Wahrscheinlichkeitsvorhersage zu optimieren, um die Darstellung von nahen und entfernten Objekten zu verbessern. Diese Fusionsstrategie berücksichtigt die Komplementarität der Merkmale der beiden Streams und erhöht gleichzeitig die Genauigkeit der BEV-Wahrscheinlichkeit durch Berechnung der lokalen und globalen Aufmerksamkeit.
Kurz gesagt, das in diesem Dokument vorgeschlagene DualBEV-Framework ermöglicht eine effiziente Bewertung und Konvertierung der Korrespondenz zwischen 3D- und 2D-Features durch die Kombination von HeightTrans und Prob-LSS sowie einem innovativen Dual-Feature-Fusion-Modul. Dies schließt nicht nur die Lücke zwischen 2D-zu-3D- und 3D-zu-2D-Konvertierungsstrategien, sondern beschleunigt auch den Feature-Konvertierungsprozess durch Vorberechnung und Wahrscheinlichkeitsmessung, wodurch er für autonome Fahranwendungen in Echtzeit geeignet ist. Der Schlüssel zu dieser Methode liegt in der präzisen Übereinstimmung und effizienten Fusion von Merkmalen aus verschiedenen Blickwinkeln, wodurch eine hervorragende Leistung bei der BEV-Objekterkennung erzielt wird.
ExperimenteDie Variante der DualBEV-Methode (DualBEV* mit einem Sternchen) schnitt unter der Einzelbild-Eingabebedingung am besten ab und erreichte 35,2 % mAP und 42,5 % NDS, was zeigt, dass sie genau ist anderen Methoden hinsichtlich Genauigkeit und umfassender Leistung überlegen. Insbesondere bei mAOE erreicht DualBEV* einen Wert von 0,542, was den besten Wert unter den Single-Frame-Methoden darstellt. Allerdings ist die Leistung auf mATE und mASE nicht wesentlich besser als bei anderen Methoden.
Wenn die Anzahl der Eingaberahmen auf zwei Rahmen erhöht wird, wird die Leistung von DualBEV weiter verbessert, wobei mAP 38,0 % und NDS 50,4 % erreicht. Dies ist der höchste NDS unter allen aufgeführten Methoden, was darauf hinweist, dass DualBEV bei der Verarbeitung umfassender ist komplexere Eingaben die Szene verstehen. Unter den Multi-Frame-Methoden zeigt es auch eine starke Leistung bei mATE, mASE und mAAE, insbesondere eine deutliche Verbesserung bei maOE, was seinen Vorteil bei der Schätzung von Objektrichtungen zeigt.
Anhand dieser Ergebnisse kann analysiert werden, dass DualBEV und seine Varianten bei mehreren wichtigen Leistungsindikatoren gut abschneiden, insbesondere in der Multi-Frame-Einstellung, was darauf hinweist, dass es eine gute Genauigkeit und Genauigkeit für BEV-Objekterkennungsaufgaben aufweist. Darüber hinaus unterstreichen diese Ergebnisse auch die Bedeutung der Verwendung von Multi-Frame-Daten zur Verbesserung der Gesamtleistung und Schätzgenauigkeit des Modells.
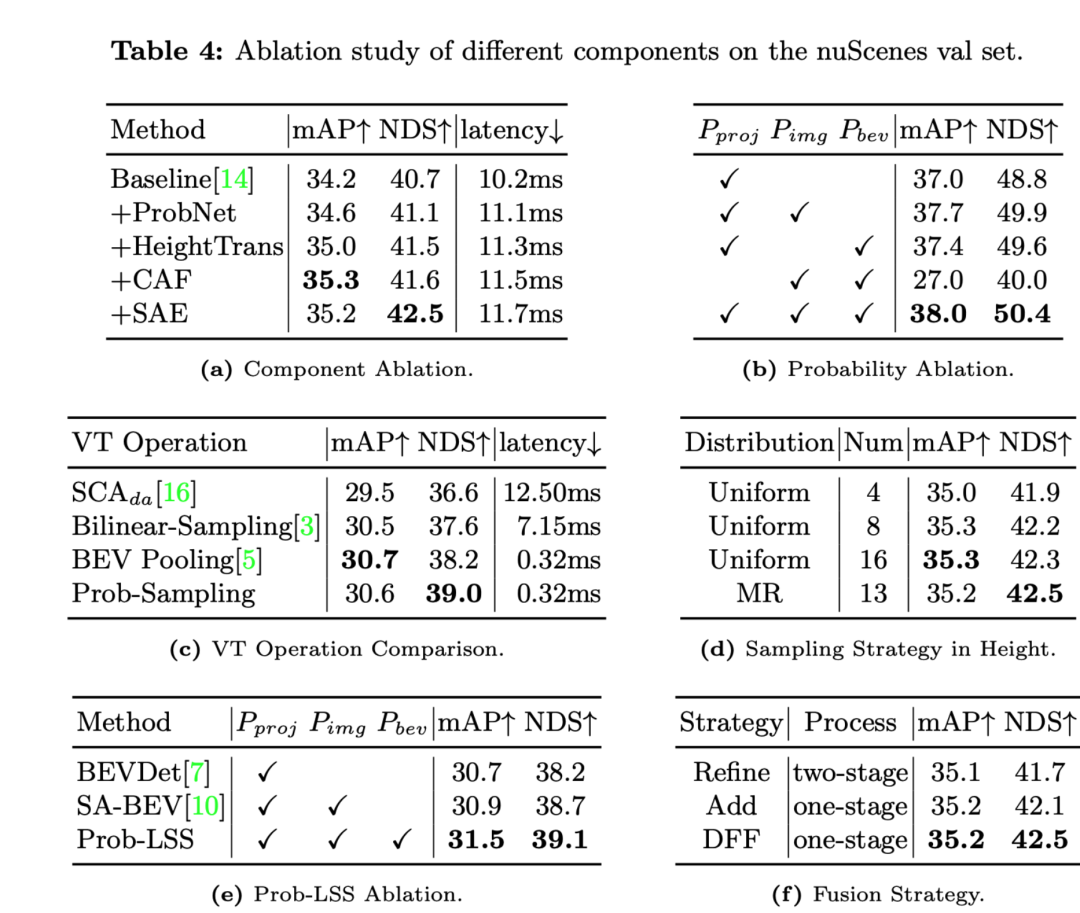
Das Folgende ist eine Analyse der Ergebnisse jedes Ablationsexperiments:
- Das Hinzufügen von Komponenten wie ProbNet, HeightTrans, CAF (Channel Attention Fusion), SAE (Spatial Attention Enhanced) usw. hat die Leistung schrittweise verbessert der Grundlinie.
- Die Hinzufügung von HeightTrans verbessert mAP und NDS erheblich, was zeigt, dass die Einbeziehung von Höheninformationen in die visuelle Transformation effektiv ist.
- CAF verbessert mAP weiter, erhöht jedoch leicht die Latenz.
- Die Einführung von SAE erhöhte den NDS auf maximal 42,5 % und verbesserte auch mAP, was darauf hindeutet, dass der räumliche Aufmerksamkeitsmechanismus die Modellleistung effektiv steigerte.
- Verschiedene Wahrscheinlichkeitsmaße (Projektionswahrscheinlichkeit , Bildwahrscheinlichkeit , BEV-Wahrscheinlichkeit ) werden nach und nach zu den Vergleichsexperimenten hinzugefügt.
- Das Modell erreichte den höchsten mAP und NDS, wenn alle drei Wahrscheinlichkeiten gleichzeitig verwendet wurden, was darauf hindeutet, dass die Kombination dieser Wahrscheinlichkeiten für die Modellleistung entscheidend ist.
- Prob-Sampling hat einen höheren NDS (39,0 %) als andere VT-Operationen bei einer ähnlichen Verzögerung (0,32 ms), was die Leistungsüberlegenheit des probabilistischen Samplings unterstreicht.
- Mit der Multi-Resolution (MR)-Sampling-Strategie kann bei Verwendung der gleichen Anzahl von Sampling-Punkten eine ähnliche oder bessere Leistung erzielt werden als mit der einheitlichen Sampling-Strategie.
- Durch das Hinzufügen von Projektionswahrscheinlichkeit, Bildwahrscheinlichkeit und BEV-Wahrscheinlichkeit zum LSS-Prozess übertrifft Prob-LSS andere LSS-Varianten, verbessert mAP und NDS und zeigt die Wirksamkeit der Kombination dieser Wahrscheinlichkeiten.
- Im Vergleich zur mehrstufigen Verfeinerungsstrategie können sowohl die einstufige Add-Strategie als auch das DFF-Modul einen höheren NDS erzielen, und DFF weist auch eine leichte Verbesserung des mAP auf, was zeigt, dass DFF eine einstufige Fusionsstrategie ist Vorteile hinsichtlich Effizienz und Leistung.
Ablationsexperimente zeigen, dass Komponenten und Strategien wie HeightTrans, probabilistische Maßnahmen, Prob-Sampling und DFF entscheidend für die Verbesserung der Modellleistung sind. Darüber hinaus beweist auch die Verwendung einer Multi-Resolution-Sampling-Strategie für Höheninformationen ihre Wirksamkeit. Diese Ergebnisse stützen das Argument der Autoren, dass jede der im Methodenteil vorgestellten Techniken positiv zur Modellleistung beiträgt.
Diskussion
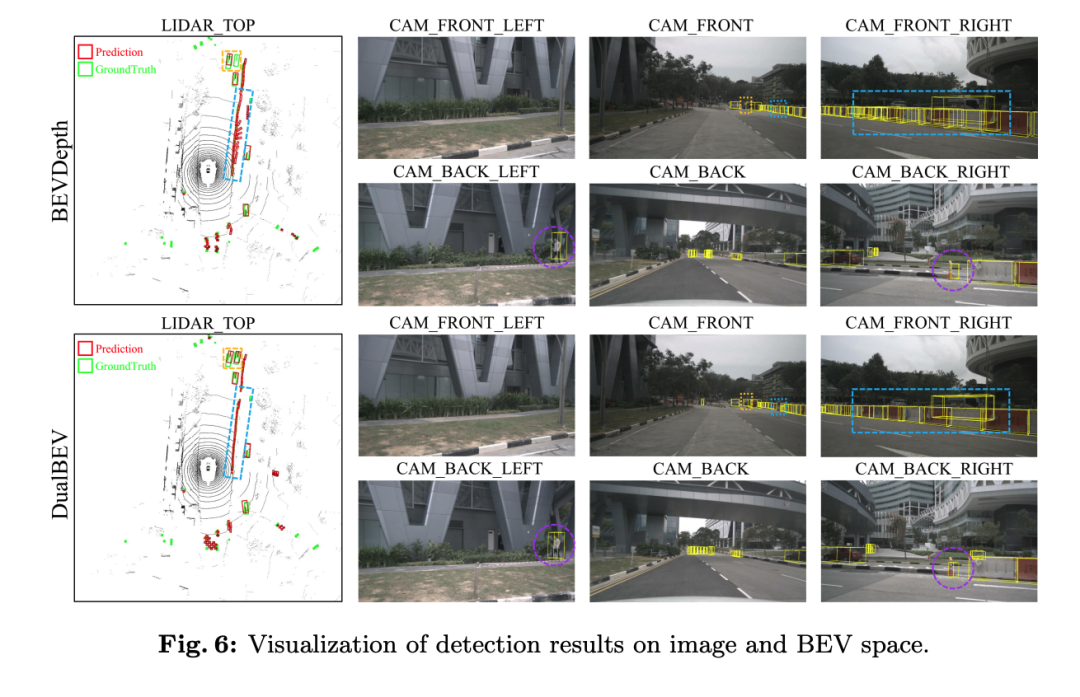
Dieser Artikel demonstriert die Leistung seiner Methode anhand einer Reihe von Ablationsexperimenten. Aus den experimentellen Ergebnissen geht hervor, dass das in der Arbeit vorgeschlagene DualBEV-Framework und seine verschiedenen Komponenten einen positiven Einfluss auf die Verbesserung der Genauigkeit der Objekterkennung aus der Vogelperspektive (BEV) haben.
Die Methode des Papiers führt schrittweise die Module ProbNet, HeightTrans, CAF (Channel Attention Fusion) und SAE (Spatial Attention Enhanced) in das Basismodell ein und zeigt signifikante Verbesserungen sowohl bei den mAP- als auch bei den NDS-Indikatoren spielt eine wichtige Rolle in der Gesamtarchitektur. Insbesondere nach der Einführung von SAE stieg der NDS-Score auf den Höchstwert von 42,5 %, während die Verzögerung nur geringfügig zunahm, was zeigt, dass die Methode ein gutes Gleichgewicht zwischen Genauigkeit und Verzögerung erreicht.
Die experimentellen Ergebnisse der probabilistischen Ablation bestätigen weiterhin die Bedeutung der Projektionswahrscheinlichkeit, der Bildwahrscheinlichkeit und der BEV-Wahrscheinlichkeit für die Verbesserung der Erkennungsleistung. Wenn diese Wahrscheinlichkeiten nacheinander eingeführt werden, verbessern sich die mAP- und NDS-Werte des Systems stetig, was zeigt, wie wichtig es ist, diese Wahrscheinlichkeitsmaße in die BEV-Objekterkennungsaufgabe zu integrieren.
Im Vergleich von visuellen Transformationsoperationen (VT) zeigt die in der Arbeit vorgeschlagene Prob-Sampling-Methode im Vergleich zu anderen Operationen wie SCAda und Bilinear-Sampling eine geringere Latenz und einen höheren NDS-Score, was ihre Leistung in Bezug auf Effizienz und Leistungsvorteile hervorhebt . Darüber hinaus kann bei unterschiedlichen Höhen-Sampling-Strategien die Anwendung einer Multi-Resolution-Strategie (MR) anstelle einer einheitlichen Sampling-Strategie den NDS-Score weiter verbessern, was zeigt, wie wichtig es ist, Informationen in unterschiedlichen Höhen in der Szene zu berücksichtigen, um die Erkennungsleistung zu verbessern.
Darüber hinaus zeigt das Papier für verschiedene Feature-Fusion-Strategien, dass die DFF-Methode immer noch hohe NDS-Scores aufrechterhalten und gleichzeitig das Modell vereinfachen kann, was bedeutet, dass die Fusion von Dual-Stream-Features in einem einstufigen Verarbeitungsfluss effektiv ist.
Obwohl die in der Arbeit vorgeschlagene Methode in vielen Aspekten eine gute Leistung erbringt, führt jede Verbesserung auch zu einer Erhöhung der Systemkomplexität und der Rechenkosten. Beispielsweise erhöht sich die Latenz des Systems jedes Mal, wenn eine neue Komponente eingeführt wird (z. B. ProbNet, HeightTrans usw.). Obwohl die Erhöhung der Latenz subtil ist, ist dies bei Anwendungen mit Echtzeit- oder niedrigen Latenzanforderungen der Fall könnte eine Überlegung werden. Darüber hinaus tragen probabilistische Maßnahmen zwar zu Leistungsverbesserungen bei, erfordern aber auch zusätzliche Rechenressourcen, um diese Wahrscheinlichkeiten abzuschätzen, was möglicherweise zu einem höheren Ressourcenverbrauch führt.
Die in der Arbeit vorgeschlagene DualBEV-Methode hat bemerkenswerte Ergebnisse bei der Verbesserung der Genauigkeit und umfassenden Leistung der BEV-Objekterkennung erzielt, insbesondere durch die Kombination der neuesten Fortschritte im Deep Learning mit der visuellen Transformationstechnologie. Allerdings gehen diese Fortschritte mit einer leicht erhöhten Rechenlatenz und einem höheren Ressourcenverbrauch einher, und praktische Anwendungen müssen diese Faktoren von Fall zu Fall abwägen.
Fazit
Diese Methode funktioniert gut bei der BEV-Objekterkennungsaufgabe und verbessert die Genauigkeit und Gesamtleistung erheblich. Durch die Einführung von probabilistischem Sampling, Höhentransformation, Aufmerksamkeitsmechanismus und räumlichem Aufmerksamkeitserweiterungsnetzwerk verbessert DualBEV erfolgreich mehrere wichtige Leistungsindikatoren, insbesondere die Genauigkeit der Vogelperspektive (BEV) und das Szenenverständnis. Experimentelle Ergebnisse zeigen, dass die Methode des Papiers besonders effektiv bei der Verarbeitung komplexer Szenen und Daten aus verschiedenen Perspektiven ist, was für autonomes Fahren und andere Echtzeitüberwachungsanwendungen von entscheidender Bedeutung ist.
Das obige ist der detaillierte Inhalt vonDualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
