
 Technologie-Peripheriegeräte
KI
NVIDIA NIM-Microservices beschleunigen die GenAI-Innovation in Unternehmen durchgängig und sind zu einem Highlight für Softwareunternehmen geworden!
Technologie-Peripheriegeräte
KI
NVIDIA NIM-Microservices beschleunigen die GenAI-Innovation in Unternehmen durchgängig und sind zu einem Highlight für Softwareunternehmen geworden!
NVIDIA NIM-Microservices beschleunigen die GenAI-Innovation in Unternehmen durchgängig und sind zu einem Highlight für Softwareunternehmen geworden!


Das Softwareentwicklungsunternehmen Cloudera hat kürzlich eine strategische Partnerschaft mit NVIDIA angekündigt, um die Bereitstellung generativer KI-Anwendungen zu beschleunigen. Die Zusammenarbeit umfasst die Integration der KI-Mikrodienste von NVIDIA in die Cloudera Data Platform (CDP) und soll Unternehmen dabei helfen, schneller benutzerdefinierte große Sprachmodelle (LLMs) auf der Grundlage ihrer Daten zu erstellen und zu skalieren. Diese Initiative wird Unternehmen leistungsfähigere Tools und Technologien zur Verfügung stellen, mit denen sie ihre Datenressourcen besser nutzen und den Entwicklungs- und Bereitstellungsprozess von KI-Anwendungen beschleunigen können. Diese Zusammenarbeit wird den Unternehmen mehr Möglichkeiten bieten und ihnen dabei helfen, effizientere datengesteuerte Entscheidungen zu treffen und die Geschäftsentwicklung voranzutreiben. Die Zusammenarbeit zwischen Cloudera und NVIDIA wird Unternehmen mehr Auswahlmöglichkeiten und Flexibilität bieten und soll die weit verbreitete Anwendung der KI-Technologie in verschiedenen Branchen fördern.
In dieser Zusammenarbeit plant Cloudera, die NVIDIA AI Enterprise-Technologie, einschließlich der NVIDIA Inference Manager (NIM)-Mikrodienste, vollständig zu nutzen, um Erkenntnisse aus mehr als 25 Exabyte an Daten in CDPs zu gewinnen. Diese wertvollen Unternehmensinformationen werden in die Plattform für maschinelles Lernen von Cloudera importiert, einen vom Unternehmen bereitgestellten End-to-End-KI-Workflow-Service, der eine neue Runde generativer KI-Innovationen vorantreiben soll.
Priyank Patel, VP of AI/ML Products bei Cloudera, stellte fest, dass Unternehmensdaten in Kombination mit einer Full-Stack-Plattform, die für große Sprachmodelle optimiert ist, von entscheidender Bedeutung sind, um die generativen KI-Anwendungen eines Unternehmens vom Pilotprojekt in die Produktion zu überführen. Cloudera integriert derzeit NVIDIA NIM- und CUDA-X-Mikrodienste, um seine Plattform für maschinelles Lernen voranzutreiben und Kunden dabei zu helfen, das Potenzial von KI in die geschäftliche Realität umzusetzen.
Diese Zusammenarbeit unterstreicht die Stärke von Cloudera und NVIDIA bei technologischer Innovation und zeigt auch die schnell wachsende Marktnachfrage nach generativen KI-Anwendungen. Durch die Integration der Ressourcen und technischen Vorteile beider Parteien werden wir gemeinsam die praktische Anwendung von KI in Unternehmen fördern und Unternehmen effizientere und intelligentere Lösungen bieten.
Darüber hinaus können Unternehmen durch die Nutzung der riesigen Datenmengen in CDP und deren Kombination mit den leistungsstarken Funktionen der Cloudera-Plattform für maschinelles Lernen tiefer in den Wert von Daten eintauchen und genauere Entscheidungen und effizientere Geschäftsabläufe erzielen. Diese Zusammenarbeit wird den Unternehmen eine intelligentere und automatisiertere Zukunft bescheren und die Entwicklung und den Fortschritt der gesamten Branche fördern.
1. Modelle und Daten verbinden
Bei der Verknüpfung von Modellen und Daten steht die Unternehmens-KI vor einer zentralen Herausforderung: Wie kann das zugrunde liegende Modell mit relevanten Geschäftsdaten verknüpft werden, um genaue und kontextbezogene Ergebnisse zu generieren? Die NIM- und NeMo Retriever-Microservices von NVIDIA zielen darauf ab, diese Lücke zu schließen, indem sie es Entwicklern ermöglichen, LLMs (Large Language Models) mit strukturierten und unstrukturierten Unternehmensdaten zu verbinden, die von Textdokumenten bis hin zu Bildern und Visualisierungen reichen.
Konkret wird Cloudera Machine Learning integrierte NIM-Modellbereitstellungsfunktionen bereitstellen, um die Inferenzleistung zu verbessern und Fehlertoleranz, geringe Latenz und automatische Skalierung in Hybrid- und Multi-Cloud-Umgebungen zu ermöglichen. Die Hinzufügung von NeMo Retriever wird die Entwicklung von Retrieval Augmented Generation (RAG)-Anwendungen vereinfachen, die die Genauigkeit generativer KI durch den Abruf relevanter Daten in Echtzeit verbessern.
Dabei ist NVIDIA NeMo Retriever ein brandneuer Dienst in der NVIDIA NeMo-Framework- und Tool-Reihe. NeMo ist eine Familie von Frameworks und Tools zum Erstellen, Anpassen und Bereitstellen generativer KI-Modelle. Als semantischer Retrieval-Microservice nutzt NeMo Retriever NVIDIA-optimierte Algorithmen, um generative KI-Anwendungen dabei zu unterstützen, genauere Antworten zu liefern. Entwickler, die diesen Microservice nutzen, können ihre KI-Anwendungen mit Geschäftsdaten verbinden, die sich in verschiedenen Clouds und Rechenzentren befinden. Diese Verbindung erhöht nicht nur die Genauigkeit von KI-Anwendungen, sondern ermöglicht Entwicklern auch eine flexiblere Verarbeitung und Nutzung von Unternehmensdaten.
Zusammenfassend lässt sich sagen, dass Microservices wie NIM und NeMo Retriever von NVIDIA Unternehmen eine effektive Möglichkeit bieten, KI-Modelle eng mit Geschäftsdaten zu integrieren, um genauere und nützlichere Ergebnisse zu generieren. Damit stehen Unternehmen leistungsstarke Werkzeuge zur Verfügung, um die Anwendung und Entwicklung von KI in verschiedenen Bereichen weiter voranzutreiben.
2. Von Daten zur generativen KI-Bereitstellung, was die Zeit erheblich verkürzt
Die Zusammenarbeit zwischen NVIDIA und Cloudera öffnet eine neue Tür für Unternehmen und führt sie dazu, riesige Datenmengen effizienter zu nutzen, um individuelle kollaborative Assistenten und Produktivität zu entwickeln Werkzeuge. Justin Boitano, Vizepräsident für Unternehmensprodukte bei NVIDIA, sagte: „Die Integration von NVIDIA NIM-Mikrodiensten mit der Cloudera-Datenplattform bietet Entwicklern eine flexiblere und einfachere Möglichkeit, große Sprachmodelle bereitzustellen und so die Unternehmenstransformation voranzutreiben.“
Durch die Vereinfachung des Wegs von Daten zur generativen KI-Bereitstellung wollen Cloudera und NVIDIA die Einführung transformativer Anwendungen wie Codierungsassistenten, Chatbots, Tools zur Dokumentenzusammenfassung und semantischen Suchtools in Unternehmen beschleunigen. Diese Zusammenarbeit baut auf den früheren Bemühungen der beiden Unternehmen auf, die GPU-Beschleunigung durch die Integration von NVIDIA RAPIDS in CDP zu nutzen.
Patel betonte die geschäftlichen Vorteile der erweiterten Zusammenarbeit und erklärte: „Die Ergebnisse dieser Integration bieten den Kunden nicht nur leistungsstarke generative KI-Funktionen und -Leistungen, sondern ermöglichen es ihnen auch, präzisere und zeitnahere Entscheidungen zu treffen.“ Reduzierung von Ungenauigkeiten, Illusionen und Fehlern in Prognosen – das sind entscheidende Faktoren bei der Navigation in der heutigen Datenumgebung.“ Während führende Unternehmen das Potenzial grundlegender Modelle zur Transformation ihrer Abläufe erkunden, sind Cloudera und NVIDIA davon überzeugt, dass ihre Zusammenarbeit ihre Kunden an die Spitze der aufkommenden Ära der Unternehmens-KI bringen wird.
Das obige ist der detaillierte Inhalt vonNVIDIA NIM-Microservices beschleunigen die GenAI-Innovation in Unternehmen durchgängig und sind zu einem Highlight für Softwareunternehmen geworden!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 „AI Factory' wird die Neugestaltung des gesamten Software-Stacks vorantreiben, und NVIDIA stellt Llama3-NIM-Container für die Bereitstellung durch Benutzer bereit
Jun 08, 2024 pm 07:25 PM
„AI Factory' wird die Neugestaltung des gesamten Software-Stacks vorantreiben, und NVIDIA stellt Llama3-NIM-Container für die Bereitstellung durch Benutzer bereit
Jun 08, 2024 pm 07:25 PM
Laut Nachrichten dieser Website vom 2. Juni stellte Huang Renxun bei der laufenden Keynote-Rede von Huang Renxun 2024 Taipei Computex vor, dass generative künstliche Intelligenz die Neugestaltung des gesamten Software-Stacks fördern wird, und demonstrierte seine cloudnativen Mikrodienste NIM (Nvidia Inference Microservices). . Nvidia glaubt, dass die „KI-Fabrik“ eine neue industrielle Revolution auslösen wird: Am Beispiel der von Microsoft vorangetriebenen Softwareindustrie glaubt Huang Renxun, dass generative künstliche Intelligenz deren Umgestaltung im gesamten Stack vorantreiben wird. Um die Bereitstellung von KI-Diensten durch Unternehmen jeder Größe zu erleichtern, hat NVIDIA im März dieses Jahres die cloudnativen Mikrodienste NIM (Nvidia Inference Microservices) eingeführt. NIM+ ist eine Suite cloudnativer Mikroservices, die darauf optimiert sind, die Markteinführungszeit zu verkürzen
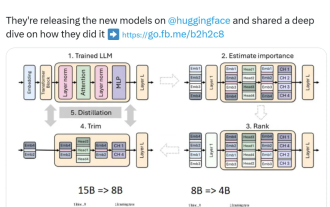 Nvidia spielt mit Beschneidung und Destillation: Halbierung der Llama 3.1 8B-Parameter, um bei gleicher Größe eine bessere Leistung zu erzielen
Aug 16, 2024 pm 04:42 PM
Nvidia spielt mit Beschneidung und Destillation: Halbierung der Llama 3.1 8B-Parameter, um bei gleicher Größe eine bessere Leistung zu erzielen
Aug 16, 2024 pm 04:42 PM
Der Aufstieg kleiner Modelle. Letzten Monat veröffentlichte Meta die Modellreihe Llama3.1, zu der das bisher größte Modell von Meta, das 405B-Modell, und zwei kleinere Modelle mit Parameterbeträgen von 70 Milliarden bzw. 8 Milliarden gehören. Llama3.1 gilt als der Beginn einer neuen Ära von Open Source. Obwohl die Modelle der neuen Generation leistungsstark sind, erfordern sie bei der Bereitstellung immer noch große Mengen an Rechenressourcen. Daher hat sich in der Branche ein weiterer Trend herausgebildet, der darin besteht, kleine Sprachmodelle (SLM) zu entwickeln, die bei vielen Sprachaufgaben eine ausreichende Leistung erbringen und zudem sehr kostengünstig in der Bereitstellung sind. Kürzlich haben Untersuchungen von NVIDIA gezeigt, dass durch strukturierte Gewichtsbereinigung in Kombination mit Wissensdestillation nach und nach kleinere Sprachmodelle aus einem zunächst größeren Modell gewonnen werden können. Turing-Preisträger, Meta Chief A
 ASUS bringt Grafikkarten der Prime GeForce RTX 40-Serie auf den Markt, die der NVIDIA SFF-Ready-Spezifikation entsprechen
Jun 15, 2024 pm 04:38 PM
ASUS bringt Grafikkarten der Prime GeForce RTX 40-Serie auf den Markt, die der NVIDIA SFF-Ready-Spezifikation entsprechen
Jun 15, 2024 pm 04:38 PM
Laut Nachrichten dieser Website vom 15. Juni hat Asus kürzlich die Grafikkarte der Prime-Serie GeForce RTX40 „Ada“ auf den Markt gebracht. Ihre Größe entspricht der neuesten SFF-Ready-Spezifikation von Nvidia, die erfordert, dass die Größe der Grafikkarte 304 nicht überschreitet mm x 151 mm x 50 mm (Länge x Höhe x Dicke). Die von ASUS eingeführte GeForceRTX40-Serie der Prime-Serie umfasst dieses Mal RTX4060Ti, RTX4070 und RTX4070SUPER, derzeit jedoch nicht RTX4070TiSUPER oder RTX4080SUPER. Diese Serie von RTX40-Grafikkarten verwendet ein gemeinsames Leiterplattendesign mit den Abmessungen 269 mm x 120 mm x 50 mm. Die Hauptunterschiede zwischen den drei Grafikkarten sind
 Nvidia veröffentlicht die GDDR6-Speicherversion der GeForce RTX 4070-Grafikkarte, erhältlich ab September
Aug 21, 2024 am 07:31 AM
Nvidia veröffentlicht die GDDR6-Speicherversion der GeForce RTX 4070-Grafikkarte, erhältlich ab September
Aug 21, 2024 am 07:31 AM
Laut Nachrichten dieser Website vom 20. August berichteten mehrere Quellen im Juli, dass Grafikkarten vom Typ Nvidia RTX4070 und höher im August aufgrund des Mangels an GDDR6X-Videospeicher knapp sein werden. Anschließend verbreiteten sich im Internet Spekulationen über die Einführung einer GDDR6-Speicherversion der RTX4070-Grafikkarte. Wie diese Seite bereits berichtete, hat Nvidia heute den GameReady-Treiber für „Black Myth: Wukong“ und „Star Wars: Outlaws“ veröffentlicht. Gleichzeitig wurde in der Pressemitteilung auch die Veröffentlichung der GDDR6-Videospeicherversion der GeForce RTX4070 erwähnt. Nvidia gab an, dass die Spezifikationen des neuen RTX4070 mit Ausnahme des Videospeichers unverändert bleiben (natürlich wird auch weiterhin der Preis von 4.799 Yuan beibehalten) und eine ähnliche Leistung wie die Originalversion in Spielen und Anwendungen bieten und verwandte Produkte auf den Markt gebracht werden aus
 PHP-Frameworks und Microservices: Cloud-native Bereitstellung und Containerisierung
Jun 04, 2024 pm 12:48 PM
PHP-Frameworks und Microservices: Cloud-native Bereitstellung und Containerisierung
Jun 04, 2024 pm 12:48 PM
Vorteile der Kombination des PHP-Frameworks mit Microservices: Skalierbarkeit: Einfaches Erweitern der Anwendung, Hinzufügen neuer Funktionen oder Bewältigung höherer Lasten. Flexibilität: Microservices werden unabhängig voneinander bereitgestellt und gewartet, was die Durchführung von Änderungen und Aktualisierungen erleichtert. Hohe Verfügbarkeit: Der Ausfall eines Microservices hat keine Auswirkungen auf andere Teile und sorgt so für eine höhere Verfügbarkeit. Praxisbeispiel: Bereitstellung von Microservices mit Laravel und Kubernetes Schritte: Erstellen Sie ein Laravel-Projekt. Definieren Sie einen Microservice-Controller. Erstellen Sie eine Docker-Datei. Erstellen Sie ein Kubernetes-Manifest. Stellen Sie Microservices bereit. Testen Sie Microservices.
 NVIDIA führt SFF-Ready-Spezifikation für kleine Gehäuse ein: 15 Hersteller von Grafikkarten und Gehäusen beteiligen sich, um die Kompatibilität von Grafikkarten und Gehäusen sicherzustellen
Jun 07, 2024 am 11:51 AM
NVIDIA führt SFF-Ready-Spezifikation für kleine Gehäuse ein: 15 Hersteller von Grafikkarten und Gehäusen beteiligen sich, um die Kompatibilität von Grafikkarten und Gehäusen sicherzustellen
Jun 07, 2024 am 11:51 AM
Laut Nachrichten dieser Website vom 2. Juni hat Nvidia mit Grafikkarten- und Gehäuseherstellern zusammengearbeitet, um die SFF-Ready-Spezifikation für GeForce RTX-Gaming-Grafikkarten und -Gehäuse offiziell einzuführen und so den Zubehörauswahlprozess für kleine Gehäuse zu vereinfachen. Berichten zufolge nehmen derzeit 15 Grafikkarten- und Gehäusehersteller am SFF-Ready-Projekt teil, darunter ASUS, Cooler Master und Parting Technology. SFF-fähige GeForce-Gaming-Grafikkarten gelten für RTX4070-Modelle und höher. Die Größenanforderungen lauten wie folgt: Maximale Höhe: 151 mm, einschließlich Biegeradius des Netzkabels. Maximale Länge: 304 mm. Maximale Dicke: 50 mm oder 2,5 Steckplätze. Stand: 2. Juni 2024 36 Grafikkarten der GeForce RTX40-Serie entsprechen den Spezifikationen, weitere Grafikkarten werden in Zukunft verfügbar sein
 NVIDIAs leistungsstärkstes Open-Source-Universalmodell Nemotron-4 340B
Jun 16, 2024 pm 10:32 PM
NVIDIAs leistungsstärkstes Open-Source-Universalmodell Nemotron-4 340B
Jun 16, 2024 pm 10:32 PM
Die Leistung übertrifft Llama-3 und wird hauptsächlich für synthetische Daten verwendet. NVIDIAs Allzweck-Großmodell Nemotron hat die neueste Version mit 340 Milliarden Parametern als Open-Source-Version bereitgestellt. Am Freitag gab NVIDIA die Einführung des Nemotron-4340B bekannt. Es enthält eine Reihe offener Modelle, mit denen Entwickler synthetische Daten für das Training großer Sprachmodelle (LLM) generieren können, die für kommerzielle Anwendungen in allen Branchen wie Gesundheitswesen, Finanzen, Fertigung und Einzelhandel verwendet werden können. Qualitativ hochwertige Trainingsdaten spielen eine entscheidende Rolle für die Reaktionsfähigkeit, Genauigkeit und Qualität benutzerdefinierter LLMs – robuste Datensätze sind jedoch oft teuer und unzugänglich. Durch eine einzigartige offene Modelllizenz bietet Nemotron-4340B Entwicklern Folgendes:
