
 Technologie-Peripheriegeräte
KI
WorldGPT ist da: Erstellen Sie einen Sora-ähnlichen Video-KI-Agenten, der Grafiken und Texte „wiederbeleben' kann
Technologie-Peripheriegeräte
KI
WorldGPT ist da: Erstellen Sie einen Sora-ähnlichen Video-KI-Agenten, der Grafiken und Texte „wiederbeleben' kann
WorldGPT ist da: Erstellen Sie einen Sora-ähnlichen Video-KI-Agenten, der Grafiken und Texte „wiederbeleben' kann

Sora von OpenAI feierte im Februar dieses Jahres ein atemberaubendes Debüt und brachte einen neuen Durchbruch bei textgenerierten Videos. Es kann auf der Grundlage von Texteingaben erstaunlich realistische und fantasievolle Videos erstellen, die aussehen, als kämen sie aus Hollywood. Viele Menschen staunten über diese Innovation und glauben, dass die Leistung von OpenAI den Höhepunkt erreicht hat.
Der von Sora verursachte Hype hält ungebrochen an. Gleichzeitig haben Forscher begonnen, das enorme Potenzial der KI-Videogenerierungstechnologie zu erkennen, und dieser Bereich erregt immer mehr Aufmerksamkeit.
Im aktuellen Bereich der KI-Videogenerierung konzentrieren sich die meisten Algorithmenforschungen jedoch auf die Generierung von Videos durch Texteingaben, insbesondere auf Szenarien, in denen Bilder und Text kombiniert werden, und wurden noch nicht ausführlich diskutiert oder umfassend angewendet. Diese Voreingenommenheit verringert die Vielfalt und Kontrollierbarkeit der generierten Videos und schränkt die Möglichkeit ein, statische Bilder in dynamische Videos umzuwandeln.
Andererseits fehlt den meisten bestehenden Videogenerierungsmodellen die Unterstützung für die Bearbeitung generierter Videoinhalte und sie können den Bedarf der Benutzer an personalisierten Anpassungen an generierten Videos nicht erfüllen.


Tipps: Verwandle den Panda in einen Bären und lass ihn tanzen. (Verwandeln Sie den Panda in einen Bären und lassen Sie ihn tanzen.)
In diesem Artikel haben Forscher von SEEKING AI, der Harvard University, der Stanford University und der Peking University gemeinsam ein innovatives einheitliches Framework für die Bild-Text-basierte Videogenerierung und -bearbeitung vorgeschlagen. mit dem Namen WorldGPT. Dieses Framework basiert auf dem von SEEKING AI und den oben genannten Top-Universitäten gemeinsam entwickelten VisionGPT-Framework. Es kann nicht nur die Funktion der direkten Generierung von Videos aus Bildern und Texten realisieren, sondern auch die Stilübertragung und den Hintergrundaustausch der generierten Videos unterstützen einfache Textaufforderungen (Eingabeaufforderung) und eine Reihe von Bearbeitungsvorgängen für das Erscheinungsbild von Videos.
Ein weiterer wesentlicher Vorteil dieses Frameworks besteht darin, dass keine Schulung erforderlich ist, was die technische Hürde erheblich senkt und außerdem die Bereitstellung und Verwendung sehr komfortabel macht. Benutzer können das Modell direkt zum Erstellen verwenden, ohne auf den mühsamen Trainingsprozess dahinter achten zu müssen.

- Papieradresse: https://arxiv.org/pdf/2403.07944.pdf
- Papiertitel: WorldGPT: A Sora-Inspired Video AI Agent as Rich World Models from Text and Image Inputs
Next Let's Schauen Sie sich die Beispieldemonstrationen von WorldGPT in verschiedenen komplexen Steuerungsszenarien für die Videogenerierung an.
Hintergrundaustausch + Video erstellen
Eingabeaufforderung: „Eine Flotte von Schiffen drängte durch den heulenden Sturm, ihre Segel segelten auf den riesigen Wellen des rücksichtslosen Sturms, ihre Segel blähten sich, als sie durch die gewaltigen Wellen des Sturms navigierten unerbittlicher Sturm.)》


Hintergrundersetzung + Stilisierung + Video generieren
Eingabeaufforderung: „Ein süßer Drache auf den Straßen der Stadt, der Feuer spuckt. (Ein süßer Drache spuckt Feuer auf einer städtischen Straße.)“ "


Objektaustausch + Hintergrundaustausch + Video generieren
Tipps: „Ein von Neonlichtern beleuchteter Roboter im Cyberpunk-Stil. Ein Automat im Cyberpunk-Stil raste durch die neonbeleuchtete, dystopische Stadtlandschaft, Reflexionen von Hoch aufragende Hologramme und digitaler Verfall, der auf seinen schlanken Metallkörper projiziert wird.)》


Wie aus dem obigen Beispiel ersichtlich ist, bietet WorldGPT die folgenden Vorteile, wenn es mit komplexen Videos konfrontiert wird Generierungsanweisungen:
1) Es behält die ursprüngliche Eingabestruktur und Umgebung des Bildes besser bei
2) Generiert ein generiertes Video, das der Bildtextbeschreibung entspricht und leistungsstarke Anpassungsmöglichkeiten für die Videogenerierung bietet; Das generierte Video kann per Eingabeaufforderung angepasst und bearbeitet werden.
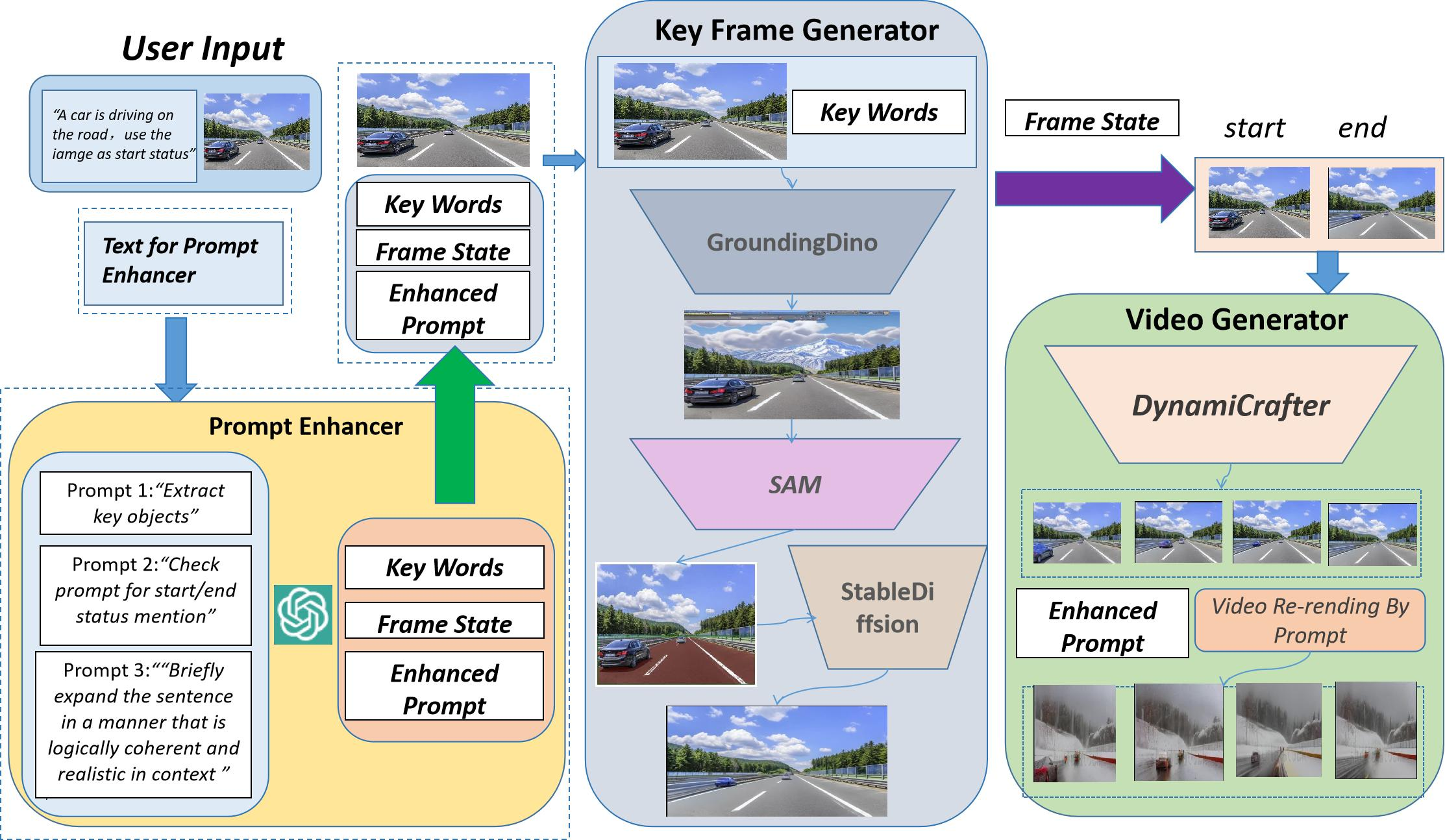
Um mehr über die Prinzipien, Experimente und Anwendungsfälle von WorldGPT zu erfahren, sehen Sie sich bitte das Originalpapier an.
VisonGPT
Wie bereits erwähnt, basiert das WorldGPT-Framework auf dem VisionGPT-Framework. Als nächstes stellen wir kurz Informationen zu VisionGPT vor.
VisionGPT wurde gemeinsam von SeekingAI, der Stanford University, der Harvard University, der Peking University und anderen weltweit führenden Institutionen entwickelt. Es handelt sich um ein bahnbrechendes Open-World-Framework für visuelle Wahrnehmungen. Das Framework bietet leistungsstarke multimodale KI-Bildverarbeitungsfunktionen durch intelligente Integration und Entscheidungsauswahl modernster SOTA-Großmodelle.
Die Innovation von VisionGPT spiegelt sich hauptsächlich in drei Aspekten wider:
- Erstens nimmt es ein großes Sprachmodell (wie LLaMA-2) als Kern, zerlegt die Eingabeaufforderung des Benutzers in detaillierte Schrittanforderungen und ruft automatisch die meisten auf geeignete große Modelle werden verarbeitet;
- Zweitens akzeptiert und fusioniert VisionGPT automatisch multimodale Ausgaben, die von mehreren SOTA-Großmodellen generiert werden, um Bildverarbeitungsergebnisse zu generieren, die auf die Benutzeranforderungen zugeschnitten sind.
- Schließlich verfügt VisionGPT über eine extrem hohe Flexibilität und Vielseitigkeit, ohne dass dies erforderlich ist Damit Benutzer das Modell verfeinern können, kann eine breite Palette von Anwendungsszenarien unterstützt werden, einschließlich textgesteuertem Bildverständnis, -generierung und -bearbeitung.

- Papieradresse: https://arxiv.org/pdf/2403.09027.pdf
- Papiertitel: VisionGPT: Vision-Language Understanding Agent Using Generalized Multimodal Framework
VisionGPT-Anwendungsfall

Wie oben zu sehen ist, kann VisionGPT problemlos 1) Instanzsegmentierung in der offenen Welt ohne Feinabstimmung erreichen; 2) aufforderungsbasierte Bildgenerierungs- und Bearbeitungsfunktionen usw. Der Workflow von VisionGPT ist in der folgenden Abbildung dargestellt.
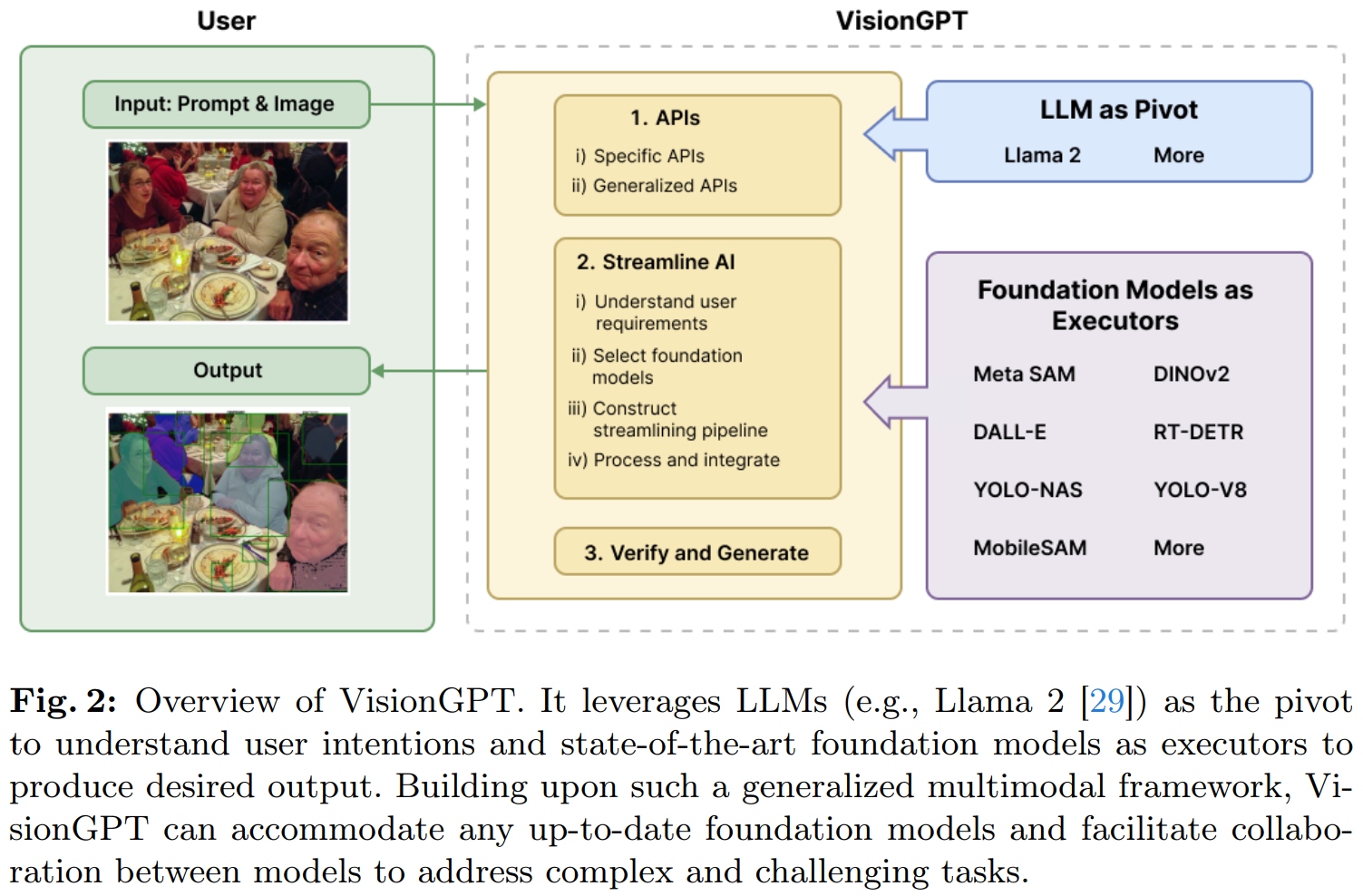
Weitere Einzelheiten finden Sie im Papier.
VisionGPT-3D
Darüber hinaus haben Forscher auch VisionGPT-3D ins Leben gerufen, das darauf abzielt, eine große Herausforderung bei der Umwandlung von Text in visuelle Elemente zu lösen: wie man 2D-Bilder effizient und genau in 3D-Darstellungen umwandelt. Bei diesem Prozess stehen wir häufig vor dem Problem, dass der Algorithmus nicht mit den tatsächlichen Anforderungen übereinstimmt und dadurch die Qualität des Endergebnisses beeinträchtigt wird. VisionGPT-3D schlägt ein multimodales Framework vor, das diesen Konvertierungsprozess durch die Integration mehrerer hochmoderner SOTA-Vision-Großmodelle optimiert. Die Kerninnovation liegt in der Fähigkeit, automatisch das am besten geeignete visuelle SOTA-Modell und den Algorithmus zur Erstellung von 3D-Punktwolken auszuwählen und auf der Grundlage multimodaler Eingaben wie Textaufforderungen eine Ausgabe zu generieren, die den Benutzeranforderungen am besten entspricht.

- Papieradresse: https://arxiv.org/pdf/2403.09530v1.pdf
- Papiertitel: VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
Weitere Informationen finden Sie unter zum Originalpapier.
Das obige ist der detaillierte Inhalt vonWorldGPT ist da: Erstellen Sie einen Sora-ähnlichen Video-KI-Agenten, der Grafiken und Texte „wiederbeleben' kann. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Ein Diffusionsmodell-Tutorial, das Ihre Zeit wert ist, von der Purdue University
Apr 07, 2024 am 09:01 AM
Ein Diffusionsmodell-Tutorial, das Ihre Zeit wert ist, von der Purdue University
Apr 07, 2024 am 09:01 AM
Diffusion kann nicht nur besser imitieren, sondern auch „erschaffen“. Das Diffusionsmodell (DiffusionModel) ist ein Bilderzeugungsmodell. Im Vergleich zu bekannten Algorithmen wie GAN und VAE im Bereich der KI verfolgt das Diffusionsmodell einen anderen Ansatz. Seine Hauptidee besteht darin, dem Bild zunächst Rauschen hinzuzufügen und es dann schrittweise zu entrauschen. Das Entrauschen und Wiederherstellen des Originalbilds ist der Kernbestandteil des Algorithmus. Der endgültige Algorithmus ist in der Lage, aus einem zufälligen verrauschten Bild ein Bild zu erzeugen. In den letzten Jahren hat das phänomenale Wachstum der generativen KI viele spannende Anwendungen in der Text-zu-Bild-Generierung, Videogenerierung und mehr ermöglicht. Das Grundprinzip dieser generativen Werkzeuge ist das Konzept der Diffusion, ein spezieller Sampling-Mechanismus, der die Einschränkungen bisheriger Methoden überwindet.
 Generieren Sie PPT mit einem Klick! Kimi: Lassen Sie zuerst die „PPT-Wanderarbeiter' populär werden
Aug 01, 2024 pm 03:28 PM
Generieren Sie PPT mit einem Klick! Kimi: Lassen Sie zuerst die „PPT-Wanderarbeiter' populär werden
Aug 01, 2024 pm 03:28 PM
Kimi: In nur einem Satz, in nur zehn Sekunden ist ein PPT fertig. PPT ist so nervig! Um ein Meeting abzuhalten, benötigen Sie einen PPT; um einen wöchentlichen Bericht zu schreiben, müssen Sie einen PPT vorlegen, auch wenn Sie jemanden des Betrugs beschuldigen PPT. Das College ähnelt eher dem Studium eines PPT-Hauptfachs. Man schaut sich PPT im Unterricht an und macht PPT nach dem Unterricht. Als Dennis Austin vor 37 Jahren PPT erfand, hatte er vielleicht nicht damit gerechnet, dass PPT eines Tages so weit verbreitet sein würde. Wenn wir über unsere harte Erfahrung bei der Erstellung von PPT sprechen, treiben uns Tränen in die Augen. „Es dauerte drei Monate, ein PPT mit mehr als 20 Seiten zu erstellen, und ich habe es Dutzende Male überarbeitet. Als ich das PPT sah, musste ich mich übergeben.“ war PPT.“ Wenn Sie ein spontanes Meeting haben, sollten Sie es tun
 Zhipu AI steigt in die Videogenerierung ein: „Qingying' ist online, 6 Sekunden lang, kostenlos und unbegrenzt
Jul 26, 2024 pm 03:35 PM
Zhipu AI steigt in die Videogenerierung ein: „Qingying' ist online, 6 Sekunden lang, kostenlos und unbegrenzt
Jul 26, 2024 pm 03:35 PM
Das große Modellteam von Zhipu ist selbst entwickelt und gebaut. Da Kuaishou Keling AI im In- und Ausland populär geworden ist, wird die inländische Videogenerierung immer beliebter, genau wie das große Textmodell im Jahr 2023. Gerade wurde ein weiteres großes Modellprodukt der Videogeneration offiziell vorgestellt: Zhipu AI hat „Qingying“ offiziell veröffentlicht. Solange Sie gute Ideen (einige bis Hunderte Wörter) und etwas Geduld (30 Sekunden) haben, kann „Qingying“ hochpräzise Videos mit einer Auflösung von 1440 x 960 erstellen. Von nun an wird Qingying in der Qingyan-App gestartet und alle Benutzer können die Funktionen Dialog, Bilder, Videos, Codes und Agentengenerierung vollständig nutzen. Neben der Abdeckung des Webs und der App von Zhipu Qingyan können Sie auch das „AI Dynamic Photo Mini-Programm“ nutzen, um schnell dynamische Effekte für Fotos auf Ihrem Telefon zu erzielen.
 Alle CVPR 2024-Auszeichnungen bekannt gegeben! Fast 10.000 Menschen nahmen offline an der Konferenz teil und ein chinesischer Forscher von Google gewann den Preis für den besten Beitrag
Jun 20, 2024 pm 05:43 PM
Alle CVPR 2024-Auszeichnungen bekannt gegeben! Fast 10.000 Menschen nahmen offline an der Konferenz teil und ein chinesischer Forscher von Google gewann den Preis für den besten Beitrag
Jun 20, 2024 pm 05:43 PM
Am frühen Morgen des 20. Juni (Pekinger Zeit) gab CVPR2024, die wichtigste internationale Computer-Vision-Konferenz in Seattle, offiziell die besten Beiträge und andere Auszeichnungen bekannt. In diesem Jahr wurden insgesamt 10 Arbeiten ausgezeichnet, darunter zwei beste Arbeiten und zwei beste studentische Arbeiten. Darüber hinaus gab es zwei Nominierungen für die beste Arbeit und vier Nominierungen für die beste studentische Arbeit. Die Top-Konferenz im Bereich Computer Vision (CV) ist die CVPR, die jedes Jahr zahlreiche Forschungseinrichtungen und Universitäten anzieht. Laut Statistik wurden in diesem Jahr insgesamt 11.532 Arbeiten eingereicht, von denen 2.719 angenommen wurden, was einer Annahmequote von 23,6 % entspricht. Laut der statistischen Analyse der CVPR2024-Daten des Georgia Institute of Technology befassen sich die meisten Arbeiten aus Sicht der Forschungsthemen mit der Bild- und Videosynthese und -generierung (Imageandvideosyn
 Fünf Programmiersoftware für den Einstieg in das Erlernen der C-Sprache
Feb 19, 2024 pm 04:51 PM
Fünf Programmiersoftware für den Einstieg in das Erlernen der C-Sprache
Feb 19, 2024 pm 04:51 PM
Als weit verbreitete Programmiersprache ist die C-Sprache eine der grundlegenden Sprachen, die für diejenigen erlernt werden müssen, die sich mit Computerprogrammierung befassen möchten. Für Anfänger kann das Erlernen einer neuen Programmiersprache jedoch etwas schwierig sein, insbesondere aufgrund des Mangels an entsprechenden Lernwerkzeugen und Lehrmaterialien. In diesem Artikel werde ich fünf Programmiersoftware vorstellen, die Anfängern den Einstieg in die C-Sprache erleichtert und Ihnen einen schnellen Einstieg ermöglicht. Die erste Programmiersoftware war Code::Blocks. Code::Blocks ist eine kostenlose integrierte Open-Source-Entwicklungsumgebung (IDE) für
 Von Bare-Metal bis hin zu einem großen Modell mit 70 Milliarden Parametern finden Sie hier ein Tutorial und gebrauchsfertige Skripte
Jul 24, 2024 pm 08:13 PM
Von Bare-Metal bis hin zu einem großen Modell mit 70 Milliarden Parametern finden Sie hier ein Tutorial und gebrauchsfertige Skripte
Jul 24, 2024 pm 08:13 PM
Wir wissen, dass LLM auf großen Computerclustern unter Verwendung umfangreicher Daten trainiert wird. Auf dieser Website wurden viele Methoden und Technologien vorgestellt, die den LLM-Trainingsprozess unterstützen und verbessern. Was wir heute teilen möchten, ist ein Artikel, der tief in die zugrunde liegende Technologie eintaucht und vorstellt, wie man einen Haufen „Bare-Metals“ ohne Betriebssystem in einen Computercluster für das LLM-Training verwandelt. Dieser Artikel stammt von Imbue, einem KI-Startup, das allgemeine Intelligenz durch das Verständnis der Denkweise von Maschinen erreichen möchte. Natürlich ist es kein einfacher Prozess, einen Haufen „Bare Metal“ ohne Betriebssystem in einen Computercluster für das Training von LLM zu verwandeln, aber Imbue hat schließlich erfolgreich ein LLM mit 70 Milliarden Parametern trainiert der Prozess akkumuliert
 Eine Pflichtlektüre für technische Anfänger: Analyse der Schwierigkeitsgrade von C-Sprache und Python
Mar 22, 2024 am 10:21 AM
Eine Pflichtlektüre für technische Anfänger: Analyse der Schwierigkeitsgrade von C-Sprache und Python
Mar 22, 2024 am 10:21 AM
Titel: Ein Muss für technische Anfänger: Schwierigkeitsanalyse der C-Sprache und Python, die spezifische Codebeispiele erfordert. Im heutigen digitalen Zeitalter ist Programmiertechnologie zu einer immer wichtigeren Fähigkeit geworden. Ob Sie in Bereichen wie Softwareentwicklung, Datenanalyse, künstliche Intelligenz arbeiten oder einfach nur aus Interesse Programmieren lernen möchten, die Wahl einer geeigneten Programmiersprache ist der erste Schritt. Unter vielen Programmiersprachen sind C-Sprache und Python zwei weit verbreitete Programmiersprachen, jede mit ihren eigenen Merkmalen. In diesem Artikel werden die Schwierigkeitsgrade der C-Sprache und von Python analysiert
 KI im Einsatz |. AI hat einen Lebens-Vlog eines allein lebenden Mädchens erstellt, der innerhalb von drei Tagen Zehntausende Likes erhielt
Aug 07, 2024 pm 10:53 PM
KI im Einsatz |. AI hat einen Lebens-Vlog eines allein lebenden Mädchens erstellt, der innerhalb von drei Tagen Zehntausende Likes erhielt
Aug 07, 2024 pm 10:53 PM
Herausgeber des Machine Power Report: Yang Wen Die Welle der künstlichen Intelligenz, repräsentiert durch große Modelle und AIGC, hat unsere Lebens- und Arbeitsweise still und leise verändert, aber die meisten Menschen wissen immer noch nicht, wie sie sie nutzen sollen. Aus diesem Grund haben wir die Kolumne „KI im Einsatz“ ins Leben gerufen, um detailliert vorzustellen, wie KI durch intuitive, interessante und prägnante Anwendungsfälle für künstliche Intelligenz genutzt werden kann, und um das Denken aller anzuregen. Wir heißen Leser auch willkommen, innovative, praktische Anwendungsfälle einzureichen. Videolink: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Vor kurzem wurde der Lebens-Vlog eines allein lebenden Mädchens auf Xiaohongshu populär. Eine Animation im Illustrationsstil, gepaart mit ein paar heilenden Worten, kann in nur wenigen Tagen leicht erlernt werden.
