
 Technologie-Peripheriegeräte
KI
Ein Rückblick auf die Entwicklung des CLIP-Modells, dem Eckpfeiler der vinzentinischen Diagramme
Technologie-Peripheriegeräte
KI
Ein Rückblick auf die Entwicklung des CLIP-Modells, dem Eckpfeiler der vinzentinischen Diagramme
Ein Rückblick auf die Entwicklung des CLIP-Modells, dem Eckpfeiler der vinzentinischen Diagramme

CLIP steht für Contrastive Language-Image Pre-Training, eine Vortrainingsmethode oder ein Modell, das auf kontrastiven Text-Bild-Paaren basiert. Die Trainingsdaten für CLIP bestehen aus Text-Bild-Paaren. Bildpaare, bei denen ein Bild mit der entsprechenden Textbeschreibung gepaart wird. Ziel des Modells ist es, die Beziehung zwischen Text- und Bildpaaren zu verstehen.

Open AI hat DALL-E und CLIP veröffentlicht -modale Modelle, die Bilder und Text kombinieren können. DALL-E ist ein Modell, das Bilder basierend auf Text generiert, während CLIP Text als Überwachungssignal verwendet, um ein übertragbares visuelles Modell zu trainieren.
Im Stable Diffusion-Modell werden die vom CLIP-Text-Encoder extrahierten Textmerkmale durch Queraufmerksamkeit in das UNet des Diffusionsmodells eingebettet. Insbesondere werden Textmerkmale als Schlüssel und Wert der Aufmerksamkeit verwendet, während UNet-Merkmale als Abfrage verwendet werden. Mit anderen Worten, CLIP ist tatsächlich eine wichtige Brücke zwischen Text und Bildern, indem es Textinformationen und Bildinformationen organisch kombiniert. Diese Kombination ermöglicht es dem Modell, Informationen zwischen verschiedenen Modalitäten besser zu verstehen und zu verarbeiten und so bessere Ergebnisse bei der Bewältigung komplexer Aufgaben zu erzielen. Auf diese Weise kann das Stable Diffusion-Modell die Textkodierungsfunktionen von CLIP effektiver nutzen, wodurch die Gesamtleistung verbessert und der Anwendungsbereich erweitert wird.
CLIP
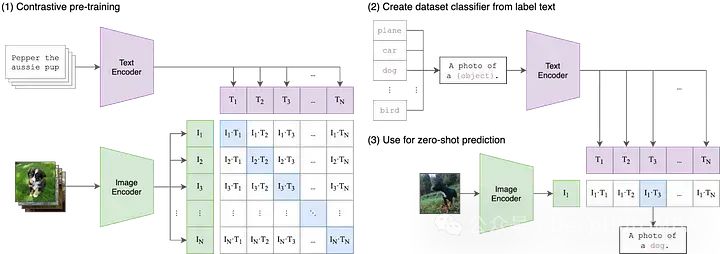
Dies ist das früheste von OpenAI im Jahr 2021 veröffentlichte Papier. Um CLIP zu verstehen, müssen wir das Akronym in drei Komponenten zerlegen: (1)Kontrastiv, (2)Sprache – Bild, ( 3) Vorschulung.
Beginnen wir mit Language-Image.
In herkömmlichen Modellen des maschinellen Lernens kann normalerweise nur eine einzige Modalität der Eingabedaten akzeptiert werden, beispielsweise Text, Bilder, Tabellendaten oder Audio. Wenn Sie Daten aus verschiedenen Modalitäten verwenden müssen, um Vorhersagen zu treffen, müssen Sie mehrere verschiedene Modelle trainieren. In CLIP bedeutet „Language-Image“, dass das Modell sowohl Text- (Sprache) als auch Bildeingabedaten akzeptieren kann. Dieses Design ermöglicht es CLIP, Informationen unterschiedlicher Modalitäten flexibler zu verarbeiten und dadurch seine Vorhersagefähigkeiten und seinen Anwendungsbereich zu verbessern.
CLIP verarbeitet Text- und Bildeingaben mithilfe von zwei verschiedenen Encodern, nämlich Text-Encoder und Bild-Encoder. Diese beiden Encoder bilden die Eingabedaten in einen niedrigerdimensionalen latenten Raum ab und erzeugen für jede Eingabe entsprechende Einbettungsvektoren. Ein wichtiges Detail ist, dass die Text- und Bildencoder die Daten in denselben Raum einbetten, d. h. der ursprüngliche CLIP-Raum ist ein 512-dimensionaler Vektorraum. Dieses Design ermöglicht den direkten Vergleich und Abgleich zwischen Text und Bildern ohne zusätzliche Konvertierung oder Verarbeitung. Auf diese Weise kann CLIP Textbeschreibungen und Bildinhalte im selben Vektorraum darstellen und so modalübergreifende semantische Ausrichtungs- und Abruffunktionen ermöglichen. Das Design dieses gemeinsamen Einbettungsraums verleiht CLIP bessere Generalisierungsfähigkeiten und Anpassungsfähigkeit, sodass es bei einer Vielzahl von Aufgaben und Datensätzen gute Leistungen erbringen kann.
Kontrastiv
Während das Einbetten von Text- und Bilddaten in denselben Vektorraum ein nützlicher Ausgangspunkt sein kann, stellt dies allein nicht sicher, dass das Modell die Darstellung von Text und Bildern effektiv vergleichen kann. Beispielsweise ist es wichtig, einen vernünftigen und interpretierbaren Zusammenhang zwischen der Einbettung von „Hund“ oder „einem Bild eines Hundes“ in einen Text und der Einbettung eines Hundebildes herzustellen. Wir brauchen jedoch eine Möglichkeit, die Lücke zwischen diesen beiden Modellen zu schließen.
Beim multimodalen maschinellen Lernen gibt es verschiedene Techniken, um zwei Modalitäten aufeinander abzustimmen. Die derzeit beliebteste Methode ist jedoch der Kontrast. Kontrastierende Techniken nehmen Eingabepaare aus zwei Modalitäten auf, beispielsweise einem Bild und seiner Bildunterschrift, und trainieren die beiden Encoder des Modells, um diese Eingabedatenpaare so genau wie möglich darzustellen. Gleichzeitig wird das Modell dazu angeregt, ungepaarte Eingaben (z. B. Bilder von Hunden und der Text „Bilder von Autos“) zu nehmen und sie so weit wie möglich entfernt darzustellen. CLIP ist nicht die erste kontrastive Lerntechnik für Bilder und Text, aber seine Einfachheit und Effektivität haben es zu einem festen Bestandteil multimodaler Anwendungen gemacht.
Vorschulung
Während CLIP selbst für Anwendungen wie Zero-Shot-Klassifizierung, semantische Suche und unbeaufsichtigte Datenexploration nützlich ist, wird CLIP auch als Baustein für eine große Anzahl von Multi- Modale Anwendungen, von Stable Diffusion und DALL-E bis StyleCLIP und OWL-ViT. Für die meisten dieser Downstream-Anwendungen gilt das anfängliche CLIP-Modell als Ausgangspunkt für das „Vortraining“ und das gesamte Modell wird für seinen neuen Anwendungsfall feinabgestimmt.
Während OpenAI die zum Training des ursprünglichen CLIP-Modells verwendeten Daten nie explizit spezifiziert oder weitergegeben hat, wurde im CLIP-Papier erwähnt, dass das Modell anhand von 400 Millionen Bild-Text-Paaren trainiert wurde, die aus dem Internet gesammelt wurden.
https://www.php.cn/link/7c1bbdaebec5e20e91db1fe61221228f
ALIGN: Skalierung des visuellen und visuellen Sprachrepräsentationslernens mit verrauschter Textüberwachung

. Mit CLIP nutzt OpenAI 4 Milliarden von Bild-Text-Paaren Da keine Details angegeben werden, ist es unmöglich, genau zu wissen, wie der Datensatz erstellt wurde. Bei der Beschreibung des neuen Datensatzes haben sie sich jedoch von den Conceptual Captions von Google inspirieren lassen – einem relativ kleinen Datensatz (3,3 Millionen Bild-Untertitel-Paare), der teure Filter- und Nachbearbeitungstechniken verwendet, obwohl diese Technologie leistungsstark, aber nicht besonders skalierbar ist. .
Daher sind qualitativ hochwertige Datensätze zur Forschungsrichtung geworden. Kurz nach CLIP löste ALIGN dieses Problem durch Skalenfilterung. ALIGN verlässt sich nicht auf kleine, sorgfältig kommentierte und kuratierte Bildunterschriften-Datensätze, sondern nutzt stattdessen 1,8 Milliarden Bildpaare und Alternativtext.
Während diese Alternativtextbeschreibungen im Durchschnitt viel lauter sind als die Titel, macht die schiere Größe des Datensatzes dies mehr als wett. Die Autoren verwendeten eine einfache Filterung, um Duplikate, Bilder mit über 1.000 relevanten Alternativtexten sowie nicht informativen Alternativtext (entweder zu häufig oder mit seltenen Tags) zu entfernen. Mit diesen einfachen Schritten erreicht oder übertrifft ALIGN den Stand der Technik bei verschiedenen Nullschuss- und Feinabstimmungsaufgaben.
https://arxiv.org/abs/2102.05918
K-LITE: Lernen übertragbarer visueller Modelle mit externem Wissen

Wie ALIGN löst auch K-LITE für das vergleichende Vortraining von hochwertige Bild-Text-Paare für eine begrenzte Anzahl von Problemen.
K-LITE konzentriert sich auf die Erklärung von Konzepten, d. h. Definitionen oder Beschreibungen als Kontext und unbekannte Konzepte können dabei helfen, ein umfassendes Verständnis zu entwickeln. Eine beliebte Erklärung lautet: Wenn Menschen zum ersten Mal Fachbegriffe und ungewöhnliches Vokabular einführen, definieren sie diese normalerweise einfach oder verwenden etwas, das jeder als Analogie kennt!
Um diesen Ansatz umzusetzen, verwendeten Forscher von Microsoft und der UC Berkeley WordNet und Wiktionary, um den Text in Bild-Text-Paaren zu verbessern. Für einige isolierte Konzepte, wie etwa Klassenbezeichnungen in ImageNet, werden die Konzepte selbst verbessert, während für Titel (z. B. von GCC) die am wenigsten verbreiteten Nominalphrasen verbessert werden. Mit diesem zusätzlichen strukturierten Wissen zeigen vorab trainierte Modelle erhebliche Verbesserungen bei Transferlernaufgaben.
https://arxiv.org/abs/2204.09222
OpenCLIP: Reproduzierbare Skalierungsgesetze für kontrastives Sprach-Bild-Lernen
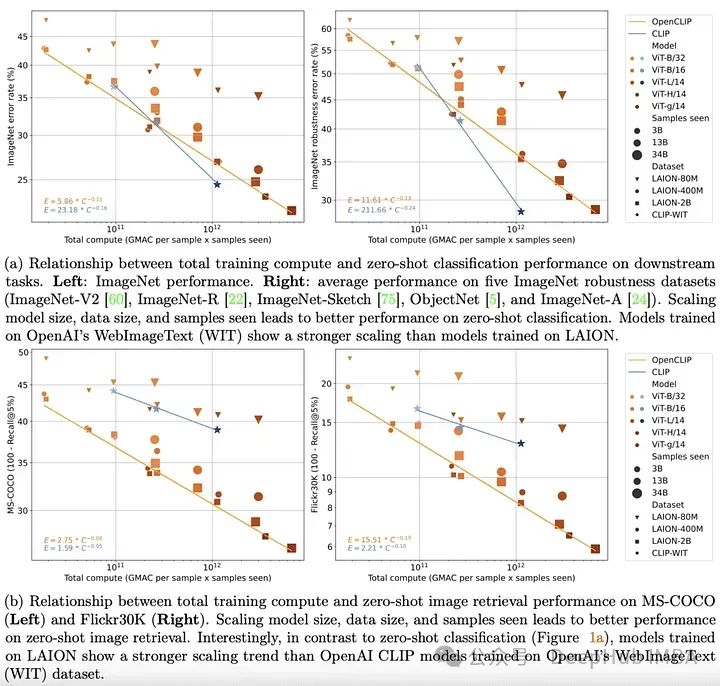
Bis Ende 2022 wurden Transformatormodelle im Text etabliert und visuelle Domänen. Wegweisende empirische Arbeiten in beiden Bereichen haben zudem deutlich gezeigt, dass die Leistung von Transformatormodellen bei unimodalen Aufgaben gut durch einfache Skalierungsgesetze beschrieben werden kann. Dies bedeutet, dass man die Leistung des Modells ziemlich genau vorhersagen kann, wenn die Menge der Trainingsdaten, die Trainingszeit oder die Modellgröße zunehmen.
OpenCLIP untersucht systematisch die Leistung von Trainingsdatenpaarmodellen bei Zero-Shot- und Feinabstimmungsaufgaben, indem es die obige Theorie auf multimodale Szenarien ausdehnt und dabei den größten bisher veröffentlichten Open-Source-Bild-Text-Paardatensatz (5B) verwendet. Auswirkungen . Wie im unimodalen Fall zeigt diese Studie, dass die Modellleistung bei multimodalen Aufgaben mit einem Potenzgesetz in Bezug auf Berechnung, Anzahl der gesehenen Stichproben und Anzahl der Modellparameter skaliert.
Noch interessanter als die Existenz von Potenzgesetzen ist die Beziehung zwischen Potenzgesetzskalierung und Daten vor dem Training. Unter Beibehaltung der CLIP-Modellarchitektur und Trainingsmethode von OpenAI zeigt das OpenCLIP-Modell stärkere Skalierungsfähigkeiten bei Aufgaben zum Abrufen von Beispielbildern. Für die Zero-Shot-Bildklassifizierung auf ImageNet zeigte das Modell von OpenAI (trainiert anhand seines proprietären Datensatzes) stärkere Skalierungsfunktionen. Diese Ergebnisse unterstreichen die Bedeutung von Datenerfassungs- und Filterverfahren für die nachgelagerte Leistung.
https://arxiv.org/abs/2212.07143Kurz nach der Veröffentlichung von OpenCLIP wurde der LAION-Datensatz jedoch aus dem Internet entfernt, da er illegale Bilder enthielt.
MetaCLIP: CLIP-Daten entmystifizieren
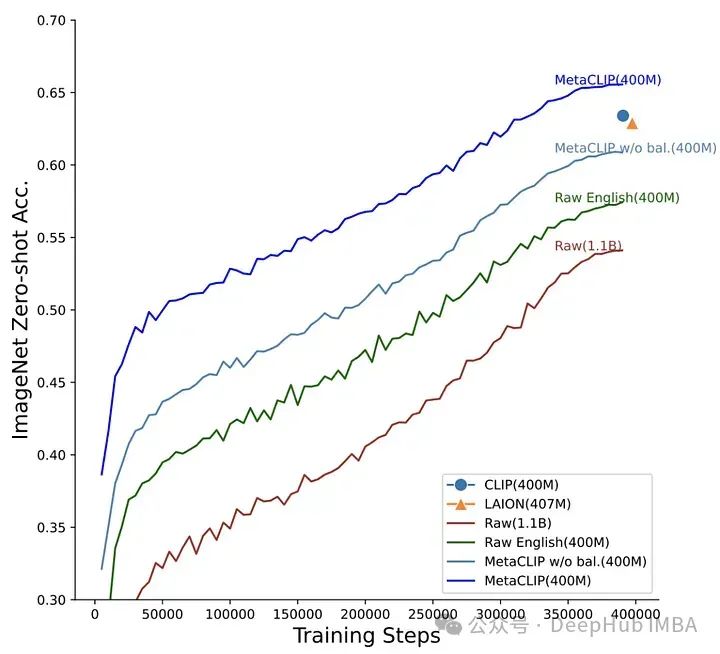
OpenCLIP versucht zu verstehen, wie sich die Leistung nachgelagerter Aufgaben mit der Datenmenge, dem Rechenaufwand und der Anzahl der Modellparameter ändert, während MetaCLIP sich auf die Auswahl von Daten konzentriert. Wie die Autoren sagen: „Wir glauben, dass der Hauptfaktor für den Erfolg von CLIP seine Daten sind und nicht die Modellarchitektur oder die Ziele vor dem Training.“ führte Experimente durch. Das MetaCLIP-Team testete verschiedene Strategien im Zusammenhang mit dem Abgleich von Teilzeichenfolgen, der Filterung und der ausgewogenen Datenverteilung und stellte fest, dass die beste Leistung erzielt wurde, wenn jeder Text maximal 20.000 Mal im Trainingsdatensatz vorkam Auch das Wort „Foto“, das im ursprünglichen Datenpool 54 Millionen Mal vorkam, war in den Trainingsdaten auf 20.000 Bild-Text-Paare beschränkt. Mit dieser Strategie wurde MetaCLIP auf 400 Millionen Bild-Text-Paare aus dem Common Crawl-Datensatz trainiert und übertraf das CLIP-Modell von OpenAI bei verschiedenen Benchmarks.
https://arxiv.org/abs/2309.16671
DFN: Data Filtering NetworksMit der Forschung zu MetaCLIP kann gezeigt werden, dass Datenmanagement ein wichtiges Werkzeug für das Training sein kann -leistungsfähige multimodale Modelle (z. B. CLIP). Die Filterstrategie von MetaCLIP ist sehr erfolgreich, basiert aber auch überwiegend auf heuristischen Methoden. Anschließend untersuchten die Forscher, ob ein Modell trainiert werden könnte, um diese Filterung effizienter durchzuführen. 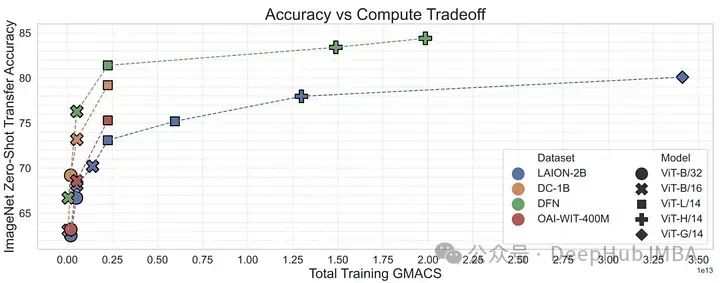
Um dies zu überprüfen, verwendet der Autor hochwertige Daten aus dem konzeptionellen 12M, um das CLIP-Modell zu trainieren, um hochwertige Daten aus Daten geringer Qualität zu filtern. Dieses Data Filtering Network (DFN) wird verwendet, um einen größeren, qualitativ hochwertigen Datensatz zu erstellen, indem nur hochwertige Daten aus einem nicht kuratierten Datensatz (in diesem Fall Common Crawl) ausgewählt werden. CLIP-Modelle, die auf gefilterten Daten trainiert wurden, übertrafen Modelle, die nur auf anfänglichen Daten hoher Qualität trainiert wurden, und Modelle, die auf großen Mengen ungefilterter Daten trainiert wurden.
https://arxiv.org/abs/2309.17425
ZusammenfassungDas CLIP-Modell von OpenAI verändert die Art und Weise, wie wir multimodale Daten verarbeiten, erheblich. Aber CLIP ist nur der Anfang. Von den Daten vor dem Training bis hin zu den Details der Trainingsmethoden und Kontrastverlustfunktionen hat die CLIP-Familie in den letzten Jahren unglaubliche Fortschritte gemacht. ALIGN skaliert verrauschten Text, K-LITE erweitert externes Wissen, OpenCLIP untersucht Skalierungsgesetze, MetaCLIP optimiert das Datenmanagement und DFN verbessert die Datenqualität. Diese Modelle vertiefen unser Verständnis der Rolle von CLIP bei der Entwicklung multimodaler künstlicher Intelligenz und zeigen Fortschritte bei der Verbindung von Bildern und Text.
Das obige ist der detaillierte Inhalt vonEin Rückblick auf die Entwicklung des CLIP-Modells, dem Eckpfeiler der vinzentinischen Diagramme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
Laut Nachrichten dieser Website vom 1. August hat SK Hynix heute (1. August) einen Blogbeitrag veröffentlicht, in dem es ankündigt, dass es am Global Semiconductor Memory Summit FMS2024 teilnehmen wird, der vom 6. bis 8. August in Santa Clara, Kalifornien, USA, stattfindet viele neue Technologien Generation Produkt. Einführung des Future Memory and Storage Summit (FutureMemoryandStorage), früher Flash Memory Summit (FlashMemorySummit), hauptsächlich für NAND-Anbieter, im Zusammenhang mit der zunehmenden Aufmerksamkeit für die Technologie der künstlichen Intelligenz wurde dieses Jahr in Future Memory and Storage Summit (FutureMemoryandStorage) umbenannt Laden Sie DRAM- und Speicheranbieter und viele weitere Akteure ein. Neues Produkt SK Hynix wurde letztes Jahr auf den Markt gebracht
