

Microsoft-Version von Sora ist geboren!
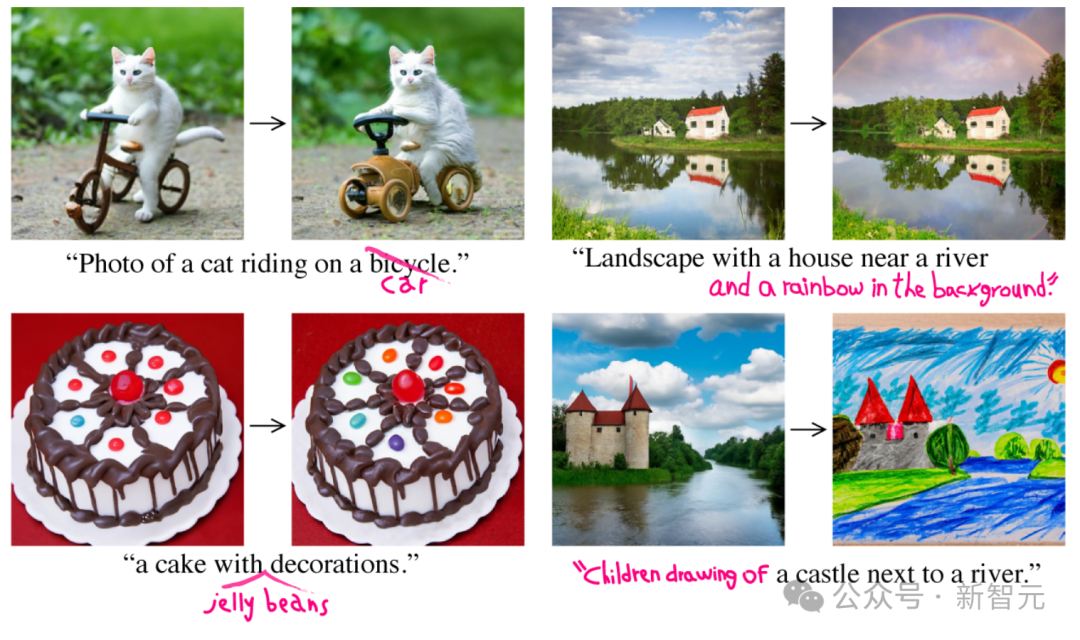
Sora ist beliebt, aber Closed Source, was die akademische Gemeinschaft vor erhebliche Herausforderungen gestellt hat. Wissenschaftler können nur versuchen, Sora mithilfe von Reverse Engineering zu reproduzieren oder zu erweitern.
Obwohl Diffusion Transformer- und Spatial-Patching-Strategien vorgeschlagen wurden, ist es immer noch schwierig, die Leistung von Sora zu erreichen, ganz zu schweigen vom Mangel an Rechenleistung und Datensätzen.
Allerdings steht eine neue Ladungswelle von Forschern zur Reproduktion von Sora bevor!
Gerade hat sich die Lehigh University mit dem Microsoft-Team zusammengetan, um ein neues Multi-KI-Agenten-Framework zu entwickeln – Mora.

Papieradresse: https://arxiv.org/abs/2403.13248
Ja, die Idee der Lehigh University und Microsoft basiert auf KI-Agenten.
Mora ähnelt eher Soras generalistischer Videogeneration. Durch die Integration mehrerer visueller KI-Agenten von SOTA können die von Sora demonstrierten universellen Videogenerierungsfunktionen reproduziert werden.

Konkret ist Mora in der Lage, mehrere visuelle Agenten zu nutzen, um Soras Videogenerierungsfähigkeiten in einer Vielzahl von Aufgaben erfolgreich zu simulieren, darunter:
- Text-zu-Video-Generierung
-basierter Text -Konditionierte Bild-zu-Video-Generierung
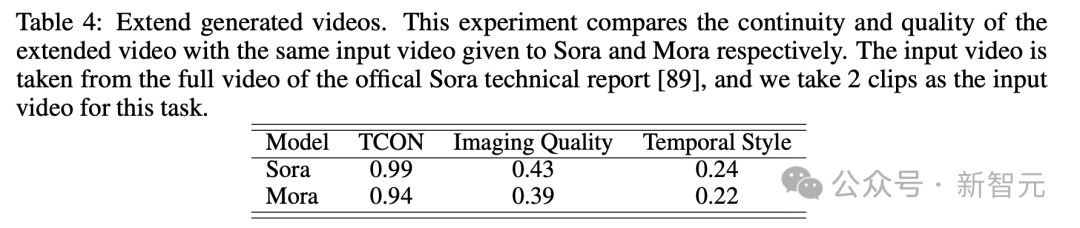
- Erzeugtes Video erweitern
- Video-zu-Video-Bearbeitung
- Video zusammenfügen
- Analoge digitale Welt.
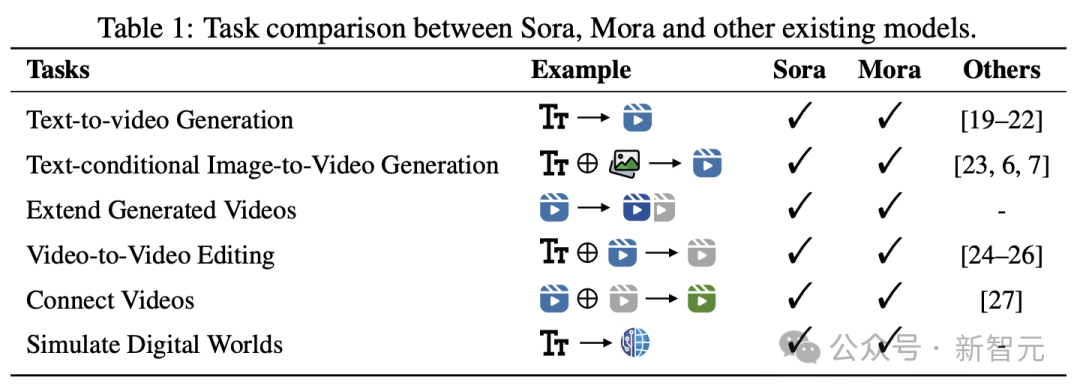
Die Ergebnisse zeigen , Mora erzielte bei diesen Aufgaben eine Leistung, die Sora nahe kam.
Es ist erwähnenswert, dass seine Leistung bei Text-zu-Video-Generierungsaufgaben bestehende Open-Source-Modelle übertrifft und unter allen Modellen an zweiter Stelle steht, nur nach Sora.
Allerdings gibt es bei der Gesamtleistung immer noch einen deutlichen Abstand zu Sora.

Mora kann hochauflösende, zeitkohärente Videos basierend auf Textaufforderungen mit einer Auflösung von 1024 × 576, einer Dauer von 12 Sekunden und insgesamt 75 Bildern generieren.
Mora hat im Grunde alle Fähigkeiten von Sora wiederhergestellt.
Text-to-Video-Generierung

Tipps: Ein lebendiges Korallenriff voller Leben unter dem kristallklaren blauen Ozean, mit bunten Fischen, die zwischen den Korallen schwimmen, Sonnenstrahlen, die durch das Wasser dringen, und eine sanfte Strömung, die die Meerespflanzen bewegt.

Tipps: Eine majestätische, schneebedeckte Bergkette, deren Gipfel die Wolken berühren und an deren Fuß sich ein kristallklarer See befindet, der die Berge und den Himmel reflektiert und so etwas erschafft ein atemberaubender natürlicher Spiegel.

Tipps: Inmitten einer riesigen Wüste erscheint am Horizont eine goldene Wüstenstadt, deren Architektur eine Mischung aus altägyptischen und futuristischen Elementen ist. Die Stadt ist von einer strahlenden Energie umgeben Barriere, während in der Luft, sieben
Generierung eines textbasierten bedingten Bildes zu Video
Geben Sie dieses klassische „realistische Wolkenbild mit dem Wort SORA“ ein.

Tipp: Ein Bild einer realistischen Wolke, die „SORA“ buchstabiert.
Der vom Sora-Modell erzeugte Effekt ist wie folgt.

Das von Mora erstellte Video ist überhaupt nicht schlecht.

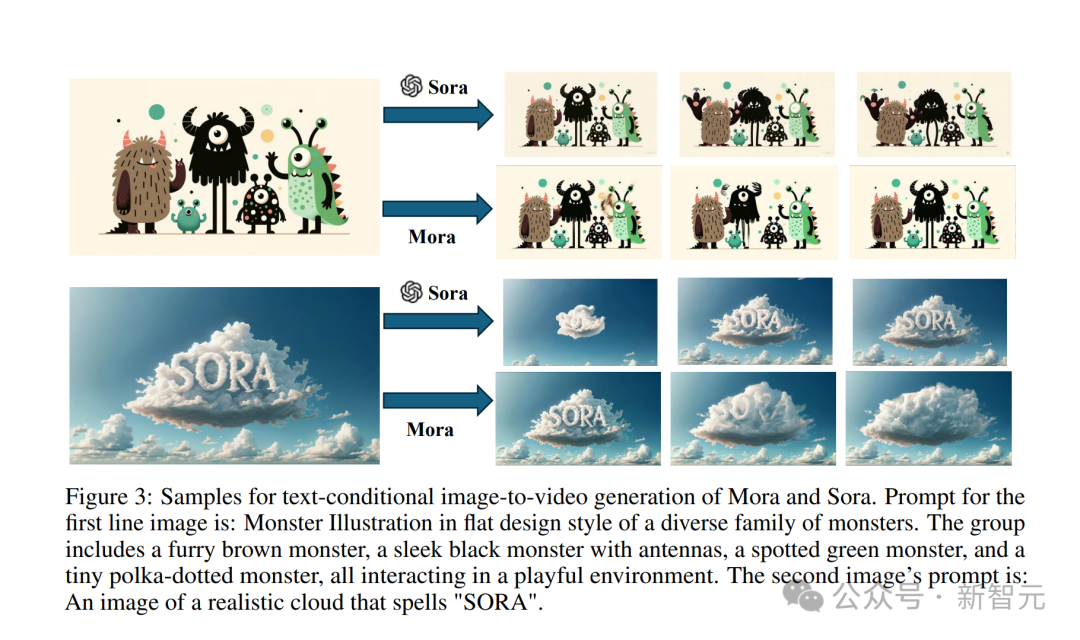
Geben Sie auch ein Bild von einem kleinen Monster ein.

Tipp: Monster-Illustration im Flat-Design-Stil einer vielfältigen Monsterfamilie. Die Gruppe umfasst ein pelziges braunes Monster, ein schlankes schwarzes Monster mit Antennen, ein geflecktes grünes Monster und ein kleines gepunktetes Monster. alle interagieren in einer spielerischen Umgebung.
Sora wandelt es in einen Videoeffekt um und erweckt diese kleinen Monster zum Leben.
Mora bringt die kleinen Monster auch dazu, sich zu bewegen, aber es ist offensichtlich etwas instabil und die Zeichentrickfiguren auf dem Bild sehen nicht einheitlich aus.

Erweitert das generierte Video
Gib mir zuerst ein Video

Sora kann stabile KI-Videos mit konsistentem Stil generieren.

Aber in dem von Mora erstellten Video hatte der Radfahrer vor ihm sein Fahrrad verloren und die Person war deformiert, sodass der Effekt nicht sehr gut war.

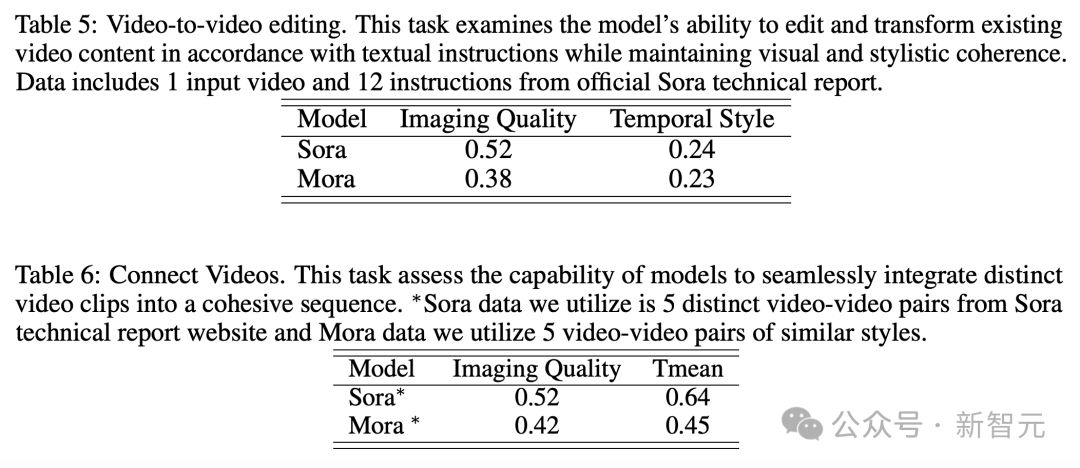
Video-zu-Video-Editor
gibt die Aufforderung „Ändern Sie die Szene zu einem Oldtimer aus den 1920er Jahren“ aus und gibt ein Video ein. 
Sora sieht nach dem Stilwechsel sehr seidig aus.

Moras Kreation eines altmodischen Autos ist aufgrund seiner Baufälligkeit etwas unrealistisch.

Videos verbinden
Geben Sie zwei Videos ein und fügen Sie sie dann fertig zusammen.


Moras gespleißtes Video

Analog zur digitalen Welt

Nach a zahlreiche Demonstrationen, Jeder ist mit Moras Video zufrieden. Die Fähigkeit zur Generierung muss man verstehen.
Im Vergleich zu OpenAI Sora ist Moras Leistung in sechs Aufgaben sehr ähnlich, es gibt aber auch große Mängel.
...In Bezug auf die Objektkonsistenz erzielte Mora einen Wert von 0,95, was dem gleichen Wert wie Sora entspricht, und zeigte im gesamten Video eine hervorragende Konstanz.
Im Bild unten ist die visuelle Wiedergabetreue der Text-zu-Video-Generierung von Mora sehr beeindruckend und spiegelt hochauflösende Bilder und viel Liebe zum Detail sowie eine lebendige Darstellung der Szene wider.
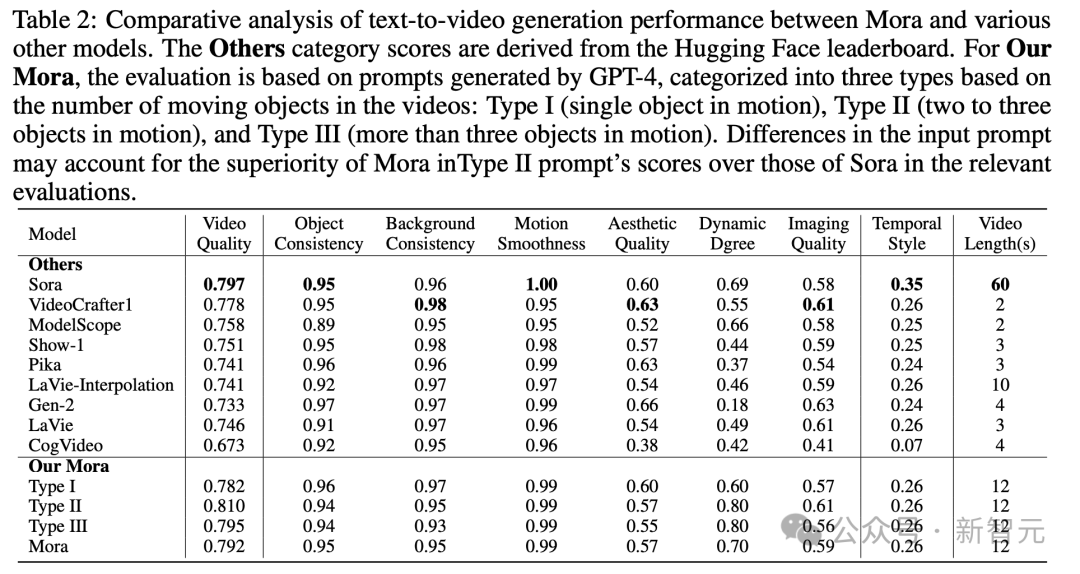
Bei der Bildgenerierungsaufgabe basierend auf Textbedingungen ist Sora definitiv das perfekteste Modell in seiner Fähigkeit, Bilder und Textanweisungen in zusammenhängende Videos umzuwandeln.
Allerdings unterscheiden sich die Ergebnisse von Mora stark von denen von Sora. 
Erweiterungsgeneriertes Video
Obwohl Sora an der Spitze liegt, beweist Moras Fähigkeit, insbesondere Zeitstile einzuhalten und bestehende Videos ohne nennenswerten Qualitätsverlust zu erweitern, seine Wirksamkeit im Bereich der Videoverlängerung.
Video-zu-Video-Bearbeitung + Video-Stitching

In diesem Beispiel wurden sowohl Sora als auch Mora angewiesen, die Umgebung auf den Stil der 1920er Jahre abzuändern und dabei die rote Farbe des Autos beizubehalten.

Simulieren der digitalen Welt
Es gibt auch die letzte Aufgabe, die digitale Welt zu simulieren. Mora kann auch die Fähigkeit haben, eine virtuelle Umgebungswelt wie Sora zu erstellen. Qualitativ ist es jedoch schlechter als Sora.


Wie löst Mora, ein Multiagenten-Framework, die Einschränkungen aktueller Videogenerierungsmodelle?
Der Schlüssel besteht darin, eine Reihe von Videogenerierungsaufgaben flexibel zu erledigen, um den unterschiedlichen Bedürfnissen der Benutzer gerecht zu werden, indem der Videogenerierungsprozess in mehrere Unteraufgaben zerlegt und jeder Aufgabe dedizierte Agenten zugewiesen wird.
Während des Inferenzprozesses generiert Mora ein Zwischenbild oder -video und behält so die visuelle Vielfalt, den Stil und die Qualität bei, die in Text-zu-Bild-Modellen zu finden sind, und verbessert die Bearbeitungsmöglichkeiten.

Durch die effiziente Koordinierung von Agenten, die Konvertierungsaufgaben von Text zu Bild, Bild zu Bild, Bild zu Video und Video zu Video übernehmen, ist Mora in der Lage, eine Reihe komplexer Videogenerierungsaufgaben zu bewältigen und bietet eine hervorragende Bearbeitungsflexibilität und visueller Realismus.
Zusammenfassend sind die Hauptbeiträge des Teams wie folgt:
- Innovatives Multi-Agent-Framework und eine intuitive Benutzeroberfläche, die Benutzern die Konfiguration verschiedener Komponenten und die Anordnung von Aufgabenprozessen erleichtert.
- Der Autor stellte fest, dass durch die Zusammenarbeit mehrerer Agenten (einschließlich der Umwandlung von Text in Bilder, Bilder in Videos usw.) die Qualität der Videogenerierung erheblich verbessert werden kann. Der Prozess beginnt mit der Umwandlung von Text in Bilder, dann werden die Bilder und der Text zusammen in Videos umgewandelt und schließlich werden die Videos optimiert und bearbeitet.
- Mora zeigt eine überlegene Leistung bei 6 videobezogenen Aufgaben und übertrifft damit bestehende Open-Source-Modelle. Dies beweist nicht nur die Effizienz von Mora, sondern zeigt auch sein Potenzial als Mehrzweck-Framework.
Bei verschiedenen Aufgaben der Videogenerierung sind in der Regel mehrere Agenten mit unterschiedlichem Fachwissen erforderlich, um zusammenzuarbeiten, wobei jeder Agent in seinem Fachgebiet Ergebnisse liefert.
Zu diesem Zweck definiert der Autor fünf Grundtypen von Agenten: Eingabeaufforderungsauswahl und -generierung, Text-zu-Bild-Generierung, Bild-zu-Bild-Generierung, Bild-zu-Video-Generierung und Video-zu-Video-Generierung .
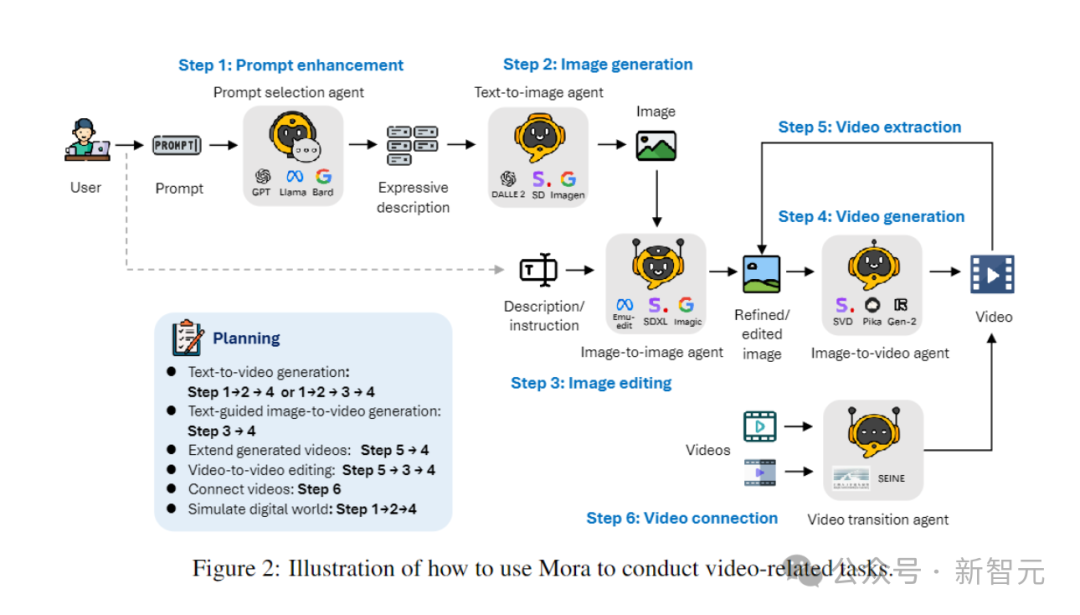
- Prompt-Auswahl- und Generierungsagent:
Bevor mit der Generierung des ersten Bildes begonnen wird, durchläuft der Text-Prompt eine Reihe strenger Verarbeitungs- und Optimierungsschritte. Dieser Agent kann große Sprachmodelle (wie GPT-4) nutzen, um Text genau zu analysieren, wichtige Informationen und Aktionen zu extrahieren und die Relevanz und Qualität der generierten Bilder erheblich zu verbessern.
- Text-to-Image-Generierungsagent:
Dieser Agent ist für die Umwandlung von Rich-Text-Beschreibungen in hochwertige Bilder verantwortlich. Seine Kernfunktion besteht darin, komplexe Texteingaben tiefgreifend zu verstehen und zu visualisieren und so die Erstellung detaillierter, präziser visueller Bilder auf der Grundlage der bereitgestellten Textbeschreibungen zu ermöglichen.
- Bild-zu-Bild-Generierungsagent:
Ändern Sie vorhandene Quellbilder gemäß spezifischen Textanweisungen. Es interpretiert Texthinweise präzise und passt Quellbilder entsprechend an, von geringfügigen Änderungen bis hin zu vollständigen Transformationen. Durch die Verwendung vorab trainierter Modelle können Textbeschreibungen und visuelle Darstellungen effektiv miteinander verbunden werden, was die Integration neuer Elemente, Anpassungen visueller Stile oder Änderungen in der Bildkomposition ermöglicht.
- Agent zur Bild-zu-Video-Generierung:
Nach der ersten Bildgenerierung ist dieser Agent für die Umwandlung statischer Bilder in dynamische Videos verantwortlich. Es analysiert den Inhalt und Stil des Ausgangsbilds, um nachfolgende Frames zu generieren, um die Kohärenz und visuelle Konsistenz des Videos sicherzustellen und die Fähigkeit des Modells zu demonstrieren, das Ausgangsbild zu verstehen, zu reproduzieren und die logische Entwicklung der Szene vorherzusehen und umzusetzen.
- Video-Splicing-Agent:
Dieser Agent sorgt für einen reibungslosen und visuell konsistenten Übergang zwischen zwei Videos, indem er deren Keyframes selektiv verwendet. Es identifiziert gemeinsame Elemente und Stile in zwei Videos genau und erstellt so ein Video, das sowohl kohärent als auch optisch ansprechend ist.
Text-to-Image-Generierung
Die Forscher verwenden vorab trainierte großformatige Text-to-Image-Modelle, um hochwertige und repräsentative erste Bilder zu generieren.
Die erste Implementierung verwendet Stable Diffusion XL.
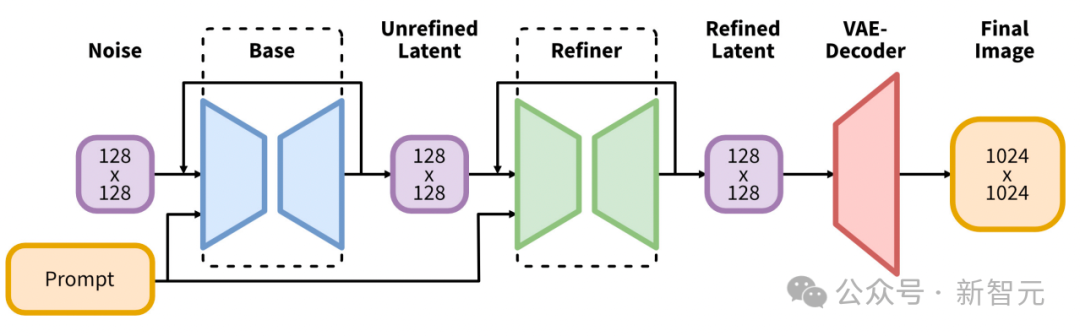
Es führt eine bedeutende Weiterentwicklung der Architektur und Methoden latenter Diffusionsmodelle für die Text-Bild-Synthese ein und setzt neue Maßstäbe auf diesem Gebiet.
Der Kern seiner Architektur ist ein erweitertes UNet-Backbone-Netzwerk, das dreimal größer ist als das in früheren Versionen von Stable Diffusion 2 verwendete Backbone.
Diese Erweiterung wird hauptsächlich durch die Erhöhung der Anzahl von Aufmerksamkeitsblöcken und einem größeren Spektrum an Aufmerksamkeitskontexten erreicht und wird durch die Integration eines Dual-Text-Encoder-Systems erleichtert.
Der erste Encoder basiert auf OpenCLIP ViT-bigG, während der zweite Encoder CLIP ViT-L nutzt, was eine umfassendere und differenziertere Interpretation der Texteingabe ermöglicht, indem die Ausgaben dieser Encoder gespleißt werden.

Diese architektonische Innovation wird durch die Einführung mehrerer neuartiger Konditionierungsschemata ergänzt, die keine externe Aufsicht erfordern, wodurch die Flexibilität und Fähigkeit des Modells, Bilder über mehrere Seitenverhältnisse hinweg zu erzeugen, verbessert wird.
Darüber hinaus verfügt SDXL über ein Verfeinerungsmodell, das eine Post-hoc-Bild-zu-Bild-Transformation verwendet, um die visuelle Qualität der generierten Bilder zu verbessern.
Dieser Verfeinerungsprozess nutzt die Rauschunterdrückungstechnologie, um das Ausgabebild weiter zu verfeinern, ohne die Effizienz oder Geschwindigkeit des Generierungsprozesses zu beeinträchtigen.
Bild-zu-Bild-Generierung
In diesem Prozess nutzte der Forscher das anfängliche Framework, um InstructPix2Pix als Bild-zu-Bild-Generierungsagent zu implementieren.

InstructPix2Pix wurde sorgfältig für eine effektive Bildbearbeitung basierend auf Anweisungen in natürlicher Sprache entwickelt.
Der Kern des Systems integriert das umfangreiche Wissen zweier vorab trainierter Modelle: GPT-3 zur Generierung von Bearbeitungsanweisungen und bearbeiteten Titeln basierend auf Textbeschreibungen; Stable Diffusion zur Umwandlung dieser textbasierten Eingaben in visuelle Ausgaben.
Dieser geniale Ansatz führt zunächst eine Feinabstimmung von GPT-3 anhand eines kuratierten Datensatzes von Bildunterschriften und entsprechenden Bearbeitungsanweisungen durch. Das Ergebnis ist ein Modell, das auf kreative Weise sinnvolle Bearbeitungen vorschlagen und modifizierte Untertitel generieren kann.
Danach generiert das durch die Prompt-to-Prompt-Technologie erweiterte Stable Diffusion-Modell Bildpaare (vor und nach der Bearbeitung) basierend auf den von GPT-3 generierten Untertiteln.
Anschließend trainieren Sie das bedingte Diffusionsmodell des InstructPix2Pix-Kerns anhand des generierten Datensatzes.
InstructPix2Pix nutzt direkt Textanweisungen und Eingabebilder, um die Bearbeitung in einem einzigen Vorwärtsdurchgang durchzuführen.
Diese Effizienz wird durch den Einsatz einer klassifikatorfreien Anleitung für Bild- und Anweisungsbedingungen weiter verbessert, wodurch das Modell die Rohbildtreue und die Einhaltung von Bearbeitungsanweisungen in Einklang bringen kann.
Bild-zu-Video-Generierung
Bei Text-zu-Video-Generierungsagenten spielt der Videogenerierungsagent eine wichtige Rolle bei der Sicherstellung der Videoqualität und -konsistenz.
Die erste Implementierung des Forschers besteht darin, das aktuelle SOTA-Videogenerierungsmodell Stable Video Diffusion zu verwenden, um Videos zu generieren.

Die SVD-Architektur nutzt die Stärken von Stable Diffusion v2.1, LDMs, die ursprünglich für die Bildsynthese entwickelt wurden, erweitert ihre Fähigkeiten, um die inhärente zeitliche Komplexität von Videoinhalten zu bewältigen, und führt so eine Möglichkeit ein, hochauflösende Videos zu generieren fortgeschrittene Methoden.
Der Kern des SVD-Modells folgt einem dreistufigen Trainingssystem, beginnend mit der Text-Bild-Korrelation, und das Modell lernt eine robuste visuelle Darstellung aus einer Reihe verschiedener Bilder. Auf dieser Grundlage kann das Modell komplexe visuelle Muster und Texturen verstehen und erzeugen.
In der zweiten Phase, dem Video-Vortraining, wird das Modell großen Mengen an Videodaten ausgesetzt, wodurch es zeitliche Dynamik und Bewegungsmuster lernen kann, indem es zeitliche Faltung und Aufmerksamkeitsebenen mit ihren räumlichen Gegenstücken kombiniert.
Das Training wird anhand systemverwalteter Datensätze durchgeführt, um sicherzustellen, dass das Modell aus hochwertigen und relevanten Videoinhalten lernt.
Die letzte Phase ist die Feinabstimmung hochwertiger Videos, die sich auf die Verbesserung der Fähigkeit des Modells konzentriert, Videos mit höherer Auflösung und Wiedergabetreue unter Verwendung kleinerer, aber qualitativ hochwertigerer Datensätze zu generieren.
Diese mehrschichtige Trainingsstrategie, ergänzt durch einen neuartigen Datenverwaltungsprozess, ermöglicht es SVD, im Laufe der Zeit eine brillante Text-zu-Video- und Bild-zu-Video-Synthese mit außergewöhnlicher Detailgenauigkeit und Realismus zu erstellen Kohärenz.
Videos zusammenfügen
Für diese Aufgabe verwendeten die Forscher SEINE, um die Videos zusammenzufügen.
SEINE basiert auf dem vorab trainierten T2V-Modell LaVie Agent.
SEINE basiert auf einem stochastischen maskierten Videodiffusionsmodell, das Übergänge basierend auf Textbeschreibungen generiert.
Durch die Integration von Bildern verschiedener Szenen mit textbasierten Steuerelementen kann SEINE Übergangsvideos generieren, die Kohärenz und visuelle Qualität bewahren.
Darüber hinaus kann das Modell auf Aufgaben wie Bild-zu-Video-Animation und weiße Regressionsvideovorhersage erweitert werden.
- Innovatives Framework und Flexibilität:
Mora führt ein revolutionäres Multi-Agent-Framework zur Videogenerierung ein, das die Möglichkeiten in diesem Bereich erheblich erweitert und die Ausführung verschiedener Aufgaben ermöglicht .
Es vereinfacht nicht nur den Prozess der Text-in-Video-Konvertierung, sondern simuliert auch die digitale Welt und zeigt so eine beispiellose Flexibilität und Effizienz.
– Open-Source-Beitrag:
Moras Open-Source-Charakter ist ein wichtiger Beitrag zur KI-Community und legt den Grundstein für zukünftige Forschung, indem er eine solide Grundlage bietet, die weitere Entwicklung und Verbesserung fördert.
Dies wird nicht nur die Popularität fortschrittlicher Videogenerierungstechnologie erhöhen, sondern auch die Zusammenarbeit und Innovation in diesem Bereich fördern.
- Videodaten sind entscheidend:
Die Erfassung der Nuancen menschlicher Bewegungen erfordert hochauflösende, flüssige Videosequenzen. Dadurch können alle Aspekte der Dynamik detailliert dargestellt werden, einschließlich Gleichgewicht, Körperhaltung und Interaktion mit der Umwelt.
Aber hochwertige Videodatensätze stammen meist aus professionellen Quellen wie Filmen, Fernsehsendungen und proprietärem Spielmaterial. Sie enthalten oft urheberrechtlich geschütztes Material, das schwer legal zu sammeln oder zu verwenden ist.
Das Fehlen dieser Datensätze macht es für videogenerative Modelle wie Mora schwierig, menschliche Handlungen in realen Umgebungen zu simulieren, beispielsweise beim Gehen oder Radfahren.
- Der Unterschied zwischen Masse und Länge:
Obwohl Mora ähnliche Aufgaben erledigen kann wie Sora, ist die Qualität des generierten Videos in Szenen mit vielen sich bewegenden Objekten offensichtlich nicht hoch und die Qualität nimmt mit zunehmender Länge des Videos ab, insbesondere wenn es 12 Sekunden überschreitet.
- Anleitung zum Befolgen der Fähigkeit:
Obwohl Mora alle durch die Eingabeaufforderung angegebenen Objekte in das Video einbeziehen kann, ist es schwierig, die in der Eingabeaufforderung beschriebene Bewegungsdynamik, wie z. B. die Bewegungsgeschwindigkeit, genau zu interpretieren und anzuzeigen.
Außerdem kann Mora die Bewegungsrichtung des Objekts nicht steuern, beispielsweise das Objekt nach links oder rechts bewegen.
Diese Einschränkungen sind hauptsächlich darauf zurückzuführen, dass Moras Videogenerierung auf der Bild-zu-Video-Methode basiert und nicht direkt Anweisungen aus Textaufforderungen erhält.
- Ausrichtung menschlicher Präferenzen:
Aufgrund des Mangels an menschlichen Anmerkungsinformationen im Videobereich entsprechen experimentelle Ergebnisse möglicherweise nicht immer den visuellen Vorlieben des Menschen.
Zum Beispiel erfordert eine der oben genannten Aufgaben zum Zusammenfügen von Videos die Erstellung eines Übergangsvideos, in dem sich ein Mann allmählich in eine Frau verwandelt, was sehr unlogisch erscheint.
Das obige ist der detaillierte Inhalt vonSora ist kein Open Source, Microsoft wird es für Sie öffnen! Das weltweit nächstgelegene Sora-Videomodell ist geboren, mit realistischen und explosiven Effekten in 12 Sekunden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So binden Sie Daten in einer Dropdown-Liste
So binden Sie Daten in einer Dropdown-Liste
 Bildschirmsperre;
Bildschirmsperre;
 So kaufen und verkaufen Sie Bitcoin in China
So kaufen und verkaufen Sie Bitcoin in China
 So kündigen Sie ein Douyin-Konto bei Douyin
So kündigen Sie ein Douyin-Konto bei Douyin
 So registrieren Sie einen dauerhaften Website-Domainnamen
So registrieren Sie einen dauerhaften Website-Domainnamen
 So lösen Sie ein Tastendruckereignis aus
So lösen Sie ein Tastendruckereignis aus
 USDT-Preis heute
USDT-Preis heute
 Der Unterschied zwischen Pfeilfunktionen und gewöhnlichen Funktionen
Der Unterschied zwischen Pfeilfunktionen und gewöhnlichen Funktionen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



