
 Technologie-Peripheriegeräte
KI
Tiefenschätzung SOTA! Adaptive Fusion von Monokular- und Surround-Tiefe für autonomes Fahren
Technologie-Peripheriegeräte
KI
Tiefenschätzung SOTA! Adaptive Fusion von Monokular- und Surround-Tiefe für autonomes Fahren
Tiefenschätzung SOTA! Adaptive Fusion von Monokular- und Surround-Tiefe für autonomes Fahren

Vorher geschrieben & persönliches Verständnis
Die Multi-View-Tiefenschätzung hat in verschiedenen Benchmark-Tests eine hohe Leistung erzielt. Allerdings basieren fast alle aktuellen Multi-View-Systeme auf einer vorgegebenen idealen Kameraposition, die in vielen realen Szenarien, wie etwa beim autonomen Fahren, nicht verfügbar ist. Diese Arbeit schlägt einen neuen Robustheits-Benchmark zur Bewertung von Tiefenschätzungssystemen unter verschiedenen verrauschten Poseneinstellungen vor. Überraschenderweise wurde festgestellt, dass aktuelle Multi-View-Tiefenschätzungsmethoden oder Single-View- und Multi-View-Fusion-Methoden bei verrauschten Poseneinstellungen versagen. Um dieser Herausforderung zu begegnen, schlagen wir hier AFNet vor, ein System zur fusionierten Tiefenschätzung mit Einzelansicht und Mehrfachansicht, das hochzuverlässige Mehrfachansichts- und Einzelansichtsergebnisse adaptiv integriert, um eine robuste und genaue Tiefenschätzung zu erreichen. Das adaptive Fusionsmodul führt die Fusion durch, indem es basierend auf der Paketkonfidenzkarte dynamisch hochzuverlässige Regionen zwischen den beiden Zweigen auswählt. Daher wählt das System tendenziell den zuverlässigeren Zweig, wenn es mit texturlosen Szenen, ungenauer Kalibrierung, dynamischen Objekten und anderen beeinträchtigten oder herausfordernden Bedingungen konfrontiert wird. Bei Robustheitstests übertrifft die Methode modernste Multiview- und Fusionsverfahren. Darüber hinaus wird bei anspruchsvollen Benchmarks (KITTI und DDAD) eine hochmoderne Leistung erzielt.
Link zum Papier: https://arxiv.org/pdf/2403.07535.pdf
Name des Papiers: Adaptive Fusion of Single-View and Multi-View Depth for Autonomous Driving
Feldhintergrund
Die Schätzung der Bildtiefe hat schon immer funktioniert Eine Herausforderung im Bereich Computer Vision mit einem breiten Anwendungsspektrum. Für visionsbasierte autonome Fahrsysteme ist die Tiefenwahrnehmung von entscheidender Bedeutung. Sie hilft dabei, Objekte auf der Straße zu verstehen und 3D-Karten der Umgebung zu erstellen. Mit der Anwendung tiefer neuronaler Netze bei verschiedenen visuellen Problemen sind Methoden, die auf Faltungs-Neuronalen Netzen (CNN) basieren, zum Mainstream für Tiefenschätzungsaufgaben geworden.
Je nach Eingabeformat wird es hauptsächlich in Tiefenschätzungen mit mehreren Ansichten und Tiefenschätzungen mit Einzelansichten unterteilt. Die Annahme hinter Multi-View-Methoden zur Tiefenschätzung ist, dass bei korrekter Tiefe, Kamerakalibrierung und Kameraposition die Pixel aller Ansichten ähnlich sein sollten. Sie verlassen sich auf die epipolare Geometrie, um qualitativ hochwertige Tiefenmessungen zu triangulieren. Allerdings hängen die Genauigkeit und Robustheit von Multi-View-Methoden stark von der geometrischen Konfiguration der Kamera und der entsprechenden Übereinstimmung zwischen den Ansichten ab. Zunächst muss die Kamera ausreichend verschoben werden, um eine Triangulation zu ermöglichen. In einem selbstfahrenden Szenario kann es sein, dass das selbstfahrende Fahrzeug an einer Ampel anhält oder abbiegt, ohne vorwärts zu fahren, was dazu führen kann, dass die Triangulation fehlschlägt. Darüber hinaus leiden Multi-View-Methoden unter den Problemen dynamischer Ziele und texturloser Bereiche, die in autonomen Fahrszenarien vorherrschen. Ein weiteres Problem ist die Optimierung der SLAM-Lage bei fahrenden Fahrzeugen. Bei bestehenden SLAM-Methoden ist Rauschen unvermeidlich, ganz zu schweigen von herausfordernden und unvermeidbaren Situationen. Beispielsweise kann ein Roboter oder ein selbstfahrendes Auto jahrelang ohne Neukalibrierung eingesetzt werden, was zu lauten Posen führt. Da Single-View-Methoden im Gegensatz dazu auf semantischem Verständnis der Szene und perspektivischen Projektionshinweisen beruhen, sind sie robuster gegenüber texturlosen Regionen und dynamischen Objekten und verlassen sich nicht auf die Kameraposition. Aufgrund der Mehrdeutigkeit des Maßstabs bleibt seine Leistung jedoch immer noch weit hinter Multi-View-Methoden zurück. Hier neigen wir dazu zu überlegen, ob die Vorteile dieser beiden Methoden für eine robuste und genaue monokulare Videotiefenschätzung in autonomen Fahrszenarien gut kombiniert werden können.
AFNet-Netzwerkstruktur
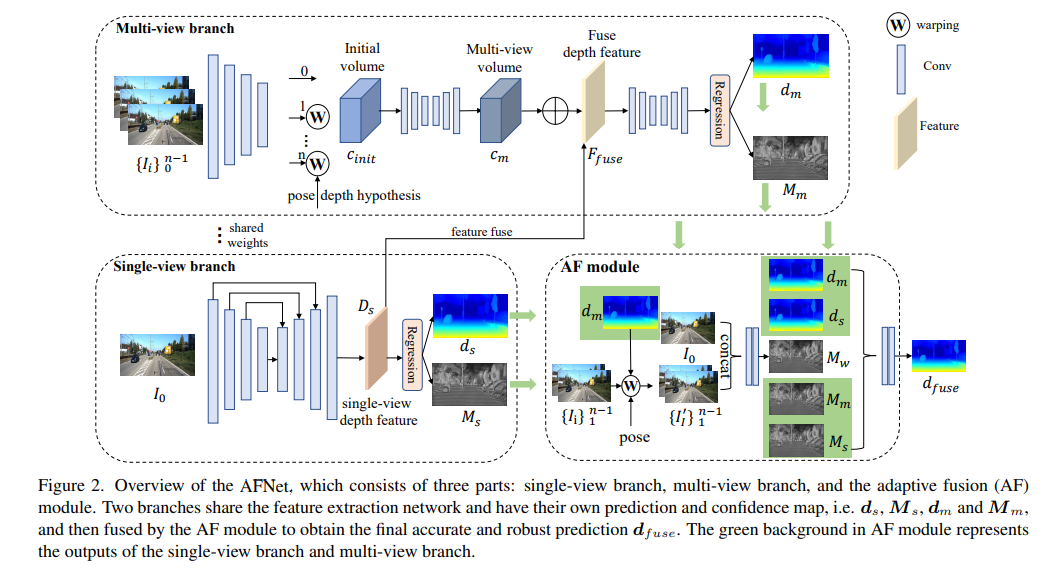
AFNet-Struktur ist unten dargestellt. Sie besteht aus drei Teilen: Single-View-Zweig, Multi-View-Zweig und adaptives Fusionsmodul (AF). Die beiden Zweige teilen sich das Merkmalsextraktionsnetzwerk und verfügen über ihre eigenen Vorhersage- und Konfidenzkarten, d. h. , und , und werden dann vom AF-Modul zusammengeführt, um die endgültige genaue und robuste Vorhersage zu erhalten. Der grüne Hintergrund im AF-Modul stellt die einzelne dar -view-Zweig und Die Ausgabe des Multi-View-Zweigs.
Verlustfunktion:

Single-View- und Multi-View-Tiefenmodule
Um die Backbone-Features zusammenzuführen und die Deep-Features-DS zu erhalten, erstellt AFNet einen Multi-Scale-Decoder. In diesem Prozess wird eine Softmax-Operation an den ersten 256 Kanälen von Ds durchgeführt, um das Tiefenwahrscheinlichkeitsvolumen Ps zu erhalten. Der letzte Kanal in der Tiefenfunktion wird als Einzelansicht-Tiefenkonfidenzkarte Ms verwendet. Abschließend wird die Einzelansichtstiefe durch weiche Gewichtung berechnet.
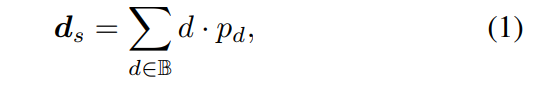
Multi-View-Zweig
Der Multi-View-Zweig teilt das Rückgrat mit dem Single-View-Zweig, um Merkmale des Referenzbilds und des Quellbilds zu extrahieren. Wir verwenden die Entfaltung, um die Merkmale mit niedriger Auflösung auf eine Viertelauflösung zu entfalten und sie mit den anfänglichen Viertelmerkmalen zu kombinieren, die zur Erstellung des Kostenvolumens verwendet werden. Ein Merkmalsvolumen wird gebildet, indem die Quellmerkmale in eine hypothetische Ebene eingewickelt werden, gefolgt von der Referenzkamera. Für ein robustes Matching, das nicht zu viele Informationen erfordert, wird die Kanaldimension des Merkmals in der Berechnung beibehalten und ein 4D-Kostenvolumen erstellt. Anschließend wird die Anzahl der Kanäle durch zwei 3D-Faltungsschichten auf 1 reduziert.
Die Stichprobenmethode der Tiefenhypothese stimmt mit der Einzelansichtsverzweigung überein, die Anzahl der Stichproben beträgt jedoch nur 128 und wird dann mithilfe eines gestapelten 2D-Sanduhrnetzwerks reguliert, um das endgültige Kostenvolumen für mehrere Ansichten zu erhalten. Um die umfangreichen semantischen Informationen von Einzelansichtsmerkmalen und die aufgrund der Kostenregulierung verlorenen Details zu ergänzen, wird eine Reststruktur verwendet, um Einzelansichts-Tiefenmerkmale Ds und Kostenvolumen zu kombinieren, um fusionierte Tiefenmerkmale wie folgt zu erhalten:
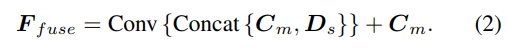
Adaptives Fusionsmodul
Um die endgültige genaue und robuste Vorhersage zu erhalten, ist das AF-Modul so konzipiert, dass es adaptiv die genaueste Tiefe zwischen den beiden Zweigen als endgültige Ausgabe auswählt, wie in Abbildung 2 dargestellt. Die Fusionszuordnung erfolgt über drei Konfidenzen, von denen zwei die von den beiden Zweigen generierten Konfidenzkarten Ms und Mm sind. Die kritischste ist die durch Vorwärtsumbruch generierte Konfidenzkarte Mw, um zu bestimmen, ob die Vorhersage des Multi-View-Zweigs stimmt zuverlässig. .
Experimentelle Ergebnisse
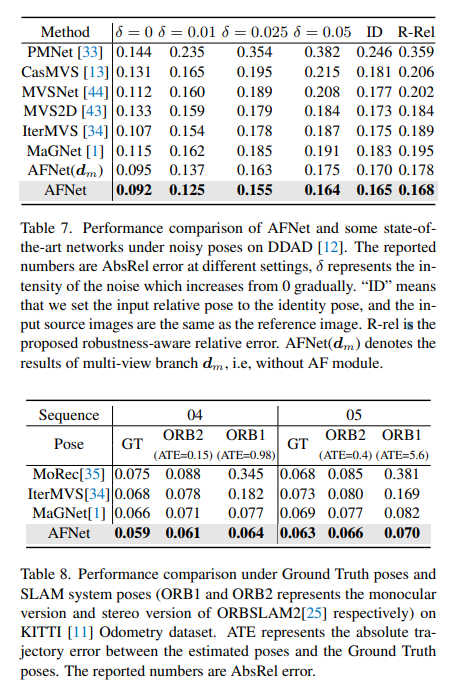
DDAD (Dense Depth for Autonomous Driving) ist ein neuer Benchmark für autonomes Fahren zur Schätzung dichter Tiefen unter anspruchsvollen und vielfältigen städtischen Bedingungen. Es wird von 6 synchronisierten Kameras erfasst und enthält eine genaue Bodentiefe (gesamtes 360-Grad-Sichtfeld), die durch hochdichtes Lidar generiert wird. Es verfügt über 12650 Trainingsbeispiele und 3950 Validierungsbeispiele in einer einzigen Kameraansicht mit einer Auflösung von 1936 x 1216. Alle Daten von 6 Kameras werden für Training und Tests verwendet. Der KITTI-Datensatz liefert stereoskopische Bilder von Außenszenen, die mit fahrenden Fahrzeugen aufgenommen wurden, und entsprechende 3D-Laserscans mit einer Auflösung von etwa 1241×376.
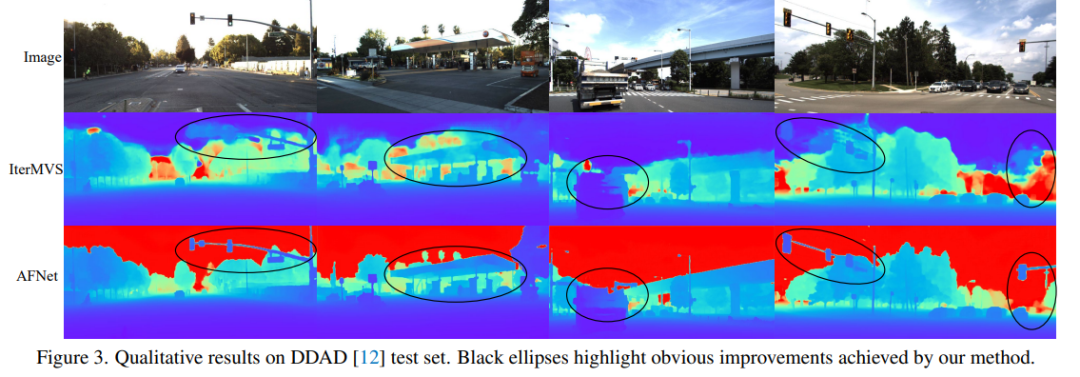
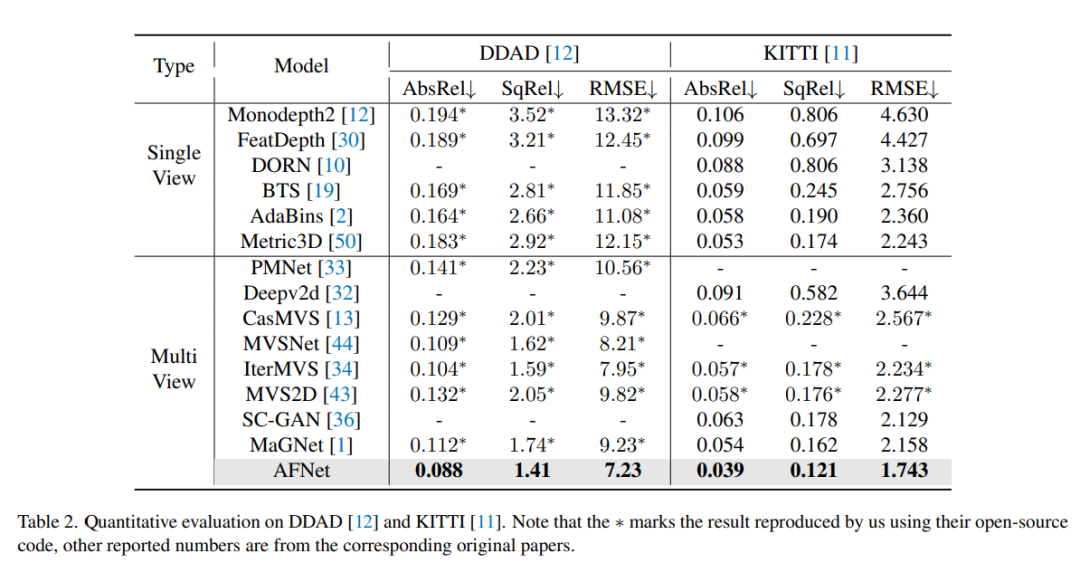
Vergleich der Bewertungsergebnisse zu DDAD und KITTI. Beachten Sie, dass * Ergebnisse kennzeichnet, die mit ihrem Open-Source-Code repliziert wurden, andere gemeldete Zahlen stammen aus den entsprechenden Originalarbeiten.
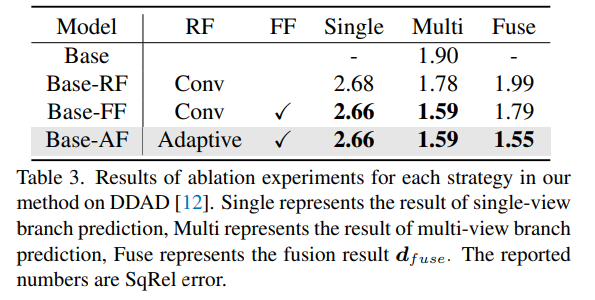
Ablationsexperimentelle Ergebnisse für jede Strategie in der Methode auf DDAD. Single stellt das Ergebnis der Einzelansicht-Zweigvorhersage dar, Multi- stellt das Ergebnis der Mehransicht-Zweigvorhersage dar und Fuse repräsentiert das Fusionsergebnis dfuse.
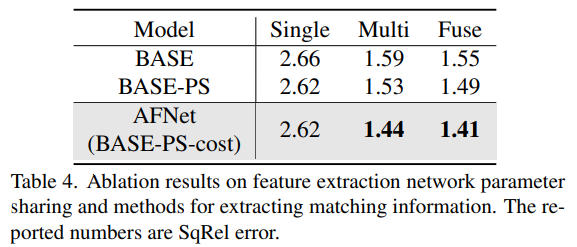
Eine Methode zum Teilen von Netzwerkparametern und zum Extrahieren passender Informationen für die Merkmalsextraktion von Ablationsergebnissen.
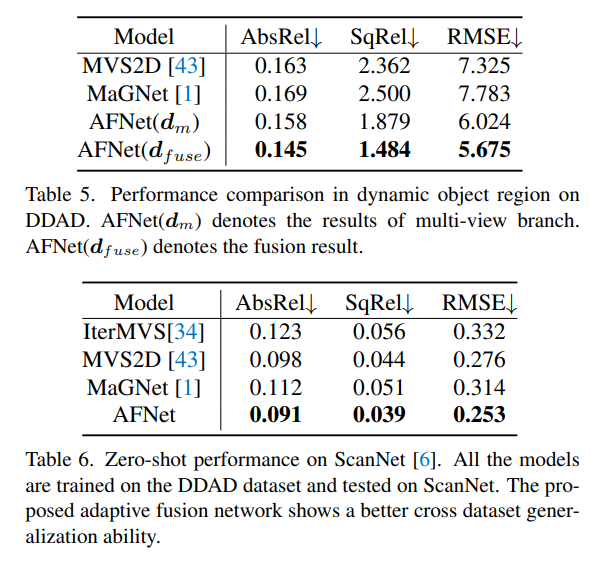

Das obige ist der detaillierte Inhalt vonTiefenschätzung SOTA! Adaptive Fusion von Monokular- und Surround-Tiefe für autonomes Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 CUDAs universelle Matrixmultiplikation: vom Einstieg bis zur Kompetenz!
Mar 25, 2024 pm 12:30 PM
CUDAs universelle Matrixmultiplikation: vom Einstieg bis zur Kompetenz!
Mar 25, 2024 pm 12:30 PM
Die allgemeine Matrixmultiplikation (GEMM) ist ein wesentlicher Bestandteil vieler Anwendungen und Algorithmen und außerdem einer der wichtigen Indikatoren zur Bewertung der Leistung der Computerhardware. Eingehende Forschung und Optimierung der Implementierung von GEMM können uns helfen, Hochleistungsrechnen und die Beziehung zwischen Software- und Hardwaresystemen besser zu verstehen. In der Informatik kann eine effektive Optimierung von GEMM die Rechengeschwindigkeit erhöhen und Ressourcen einsparen, was für die Verbesserung der Gesamtleistung eines Computersystems von entscheidender Bedeutung ist. Ein tiefgreifendes Verständnis des Funktionsprinzips und der Optimierungsmethode von GEMM wird uns helfen, das Potenzial moderner Computerhardware besser zu nutzen und effizientere Lösungen für verschiedene komplexe Computeraufgaben bereitzustellen. Durch Optimierung der Leistung von GEMM
 Das intelligente Fahrsystem Qiankun ADS3.0 von Huawei wird im August auf den Markt kommen und erstmals auf dem Xiangjie S9 eingeführt
Jul 30, 2024 pm 02:17 PM
Das intelligente Fahrsystem Qiankun ADS3.0 von Huawei wird im August auf den Markt kommen und erstmals auf dem Xiangjie S9 eingeführt
Jul 30, 2024 pm 02:17 PM
Am 29. Juli nahm Yu Chengdong, Huawei-Geschäftsführer, Vorsitzender von Terminal BG und Vorsitzender von Smart Car Solutions BU, an der Übergabezeremonie des 400.000sten Neuwagens von AITO Wenjie teil, hielt eine Rede und kündigte an, dass die Modelle der Wenjie-Serie dies tun werden Dieses Jahr auf den Markt kommen Im August wurde die Huawei Qiankun ADS 3.0-Version auf den Markt gebracht und es ist geplant, die Upgrades sukzessive von August bis September voranzutreiben. Das Xiangjie S9, das am 6. August auf den Markt kommt, wird erstmals mit dem intelligenten Fahrsystem ADS3.0 von Huawei ausgestattet sein. Mit Hilfe von Lidar wird Huawei Qiankun ADS3.0 seine intelligenten Fahrfähigkeiten erheblich verbessern, über integrierte End-to-End-Funktionen verfügen und eine neue End-to-End-Architektur von GOD (allgemeine Hinderniserkennung)/PDP (prädiktiv) einführen Entscheidungsfindung und Kontrolle), Bereitstellung der NCA-Funktion für intelligentes Fahren von Parkplatz zu Parkplatz und Aktualisierung von CAS3.0
 Welche Version des Apple 16-Systems ist die beste?
Mar 08, 2024 pm 05:16 PM
Welche Version des Apple 16-Systems ist die beste?
Mar 08, 2024 pm 05:16 PM
Die beste Version des Apple 16-Systems ist iOS16.1.4. Die beste Version des iOS16-Systems kann von Person zu Person unterschiedlich sein. Die Ergänzungen und Verbesserungen im täglichen Nutzungserlebnis wurden auch von vielen Benutzern gelobt. Welche Version des Apple 16-Systems ist die beste? Antwort: iOS16.1.4 Die beste Version des iOS 16-Systems kann von Person zu Person unterschiedlich sein. Öffentlichen Informationen zufolge gilt iOS16, das 2022 auf den Markt kam, als eine sehr stabile und leistungsstarke Version, und die Benutzer sind mit dem Gesamterlebnis recht zufrieden. Darüber hinaus wurden die neuen Funktionen und Verbesserungen des täglichen Nutzungserlebnisses in iOS16 von vielen Benutzern gut angenommen. Insbesondere in Bezug auf die aktualisierte Akkulaufzeit, Signalleistung und Heizungssteuerung war das Feedback der Benutzer relativ positiv. Betrachtet man jedoch das iPhone14
 Immer neu! Upgrade der Huawei Mate60-Serie auf HarmonyOS 4.2: KI-Cloud-Erweiterung, Xiaoyi-Dialekt ist so einfach zu bedienen
Jun 02, 2024 pm 02:58 PM
Immer neu! Upgrade der Huawei Mate60-Serie auf HarmonyOS 4.2: KI-Cloud-Erweiterung, Xiaoyi-Dialekt ist so einfach zu bedienen
Jun 02, 2024 pm 02:58 PM
Am 11. April kündigte Huawei erstmals offiziell den 100-Maschinen-Upgradeplan für HarmonyOS 4.2 an. Dieses Mal werden mehr als 180 Geräte an dem Upgrade teilnehmen, darunter Mobiltelefone, Tablets, Uhren, Kopfhörer, Smart-Screens und andere Geräte. Im vergangenen Monat haben mit dem stetigen Fortschritt des HarmonyOS4.2-Upgradeplans für 100 Maschinen auch viele beliebte Modelle, darunter Huawei Pocket2, Huawei MateX5-Serie, Nova12-Serie, Huawei Pura-Serie usw., mit der Aktualisierung und Anpassung begonnen, was bedeutet, dass dass es mehr Benutzer von Huawei-Modellen geben wird, die das gemeinsame und oft neue Erlebnis von HarmonyOS genießen können. Den Rückmeldungen der Benutzer zufolge hat sich das Erlebnis der Modelle der Huawei Mate60-Serie nach dem Upgrade von HarmonyOS4.2 in allen Aspekten verbessert. Vor allem Huawei M
 Welche Computer-Betriebssysteme gibt es?
Jan 12, 2024 pm 03:12 PM
Welche Computer-Betriebssysteme gibt es?
Jan 12, 2024 pm 03:12 PM
Ein Computerbetriebssystem ist ein System zur Verwaltung von Computerhardware und -software. Es ist auch ein Betriebssystemprogramm, das auf allen Softwaresystemen basiert. Welche Computersysteme gibt es also? Im Folgenden erklärt Ihnen der Herausgeber, was Computer-Betriebssysteme sind. Das sogenannte Betriebssystem dient der Verwaltung von Computerhardware und Softwareprogrammen. Sämtliche Software wird auf Basis von Betriebssystemprogrammen entwickelt. Tatsächlich gibt es viele Arten von Betriebssystemen, darunter solche für den industriellen Einsatz, den kommerziellen Einsatz und den persönlichen Gebrauch, die ein breites Anwendungsspektrum abdecken. Im Folgenden erklärt Ihnen der Herausgeber, was Computer-Betriebssysteme sind. Welche Computer-Betriebssysteme sind Windows-Systeme? Das Windows-System ist ein Betriebssystem, das von der Microsoft Corporation in den Vereinigten Staaten entwickelt wurde. als die meisten
 Unterschiede und Gemeinsamkeiten von cmd-Befehlen in Linux- und Windows-Systemen
Mar 15, 2024 am 08:12 AM
Unterschiede und Gemeinsamkeiten von cmd-Befehlen in Linux- und Windows-Systemen
Mar 15, 2024 am 08:12 AM
Linux und Windows sind zwei gängige Betriebssysteme, die das Open-Source-Linux-System bzw. das kommerzielle Windows-System darstellen. In beiden Betriebssystemen gibt es eine Befehlszeilenschnittstelle, über die Benutzer mit dem Betriebssystem interagieren können. In Linux-Systemen verwenden Benutzer die Shell-Befehlszeile, während Benutzer in Windows-Systemen die cmd-Befehlszeile verwenden. Die Shell-Befehlszeile im Linux-System ist ein sehr leistungsfähiges Tool, das fast alle Systemverwaltungsaufgaben erledigen kann.
 Ausführliche Erklärung zum Ändern des Systemdatums in der Oracle-Datenbank
Mar 09, 2024 am 10:21 AM
Ausführliche Erklärung zum Ändern des Systemdatums in der Oracle-Datenbank
Mar 09, 2024 am 10:21 AM
Ausführliche Erläuterung der Methode zum Ändern des Systemdatums in der Oracle-Datenbank. In der Oracle-Datenbank umfasst die Methode zum Ändern des Systemdatums hauptsächlich das Ändern des Parameters NLS_DATE_FORMAT und die Verwendung der Funktion SYSDATE. In diesem Artikel werden diese beiden Methoden und ihre spezifischen Codebeispiele ausführlich vorgestellt, um den Lesern zu helfen, den Vorgang zum Ändern des Systemdatums in der Oracle-Datenbank besser zu verstehen und zu beherrschen. 1. Ändern Sie die NLS_DATE_FORMAT-Parametermethode. NLS_DATE_FORMAT sind Oracle-Daten
 Wo ist der Speicherpfad für Systemschriftarten?
Feb 19, 2024 pm 09:11 PM
Wo ist der Speicherpfad für Systemschriftarten?
Feb 19, 2024 pm 09:11 PM
In welchem Ordner befinden sich die Systemschriftarten? In modernen Computersystemen spielen Schriftarten eine entscheidende Rolle und beeinflussen unser Leseerlebnis und die Schönheit des Textausdrucks. Für einige Benutzer, die Wert auf Personalisierung und Individualisierung legen, ist es besonders wichtig, den Speicherort von Systemschriftarten zu kennen. In welchem Ordner werden also Systemschriftarten gespeichert? Dieser Artikel wird sie einzeln für jedermann enthüllen. Im Windows-Betriebssystem werden Systemschriftarten in einem Ordner namens „Fonts“ gespeichert. Dieser Ordner befindet sich standardmäßig auf dem Win C-Laufwerk.
