

Integrierte Big-Data-KI-Interpretation

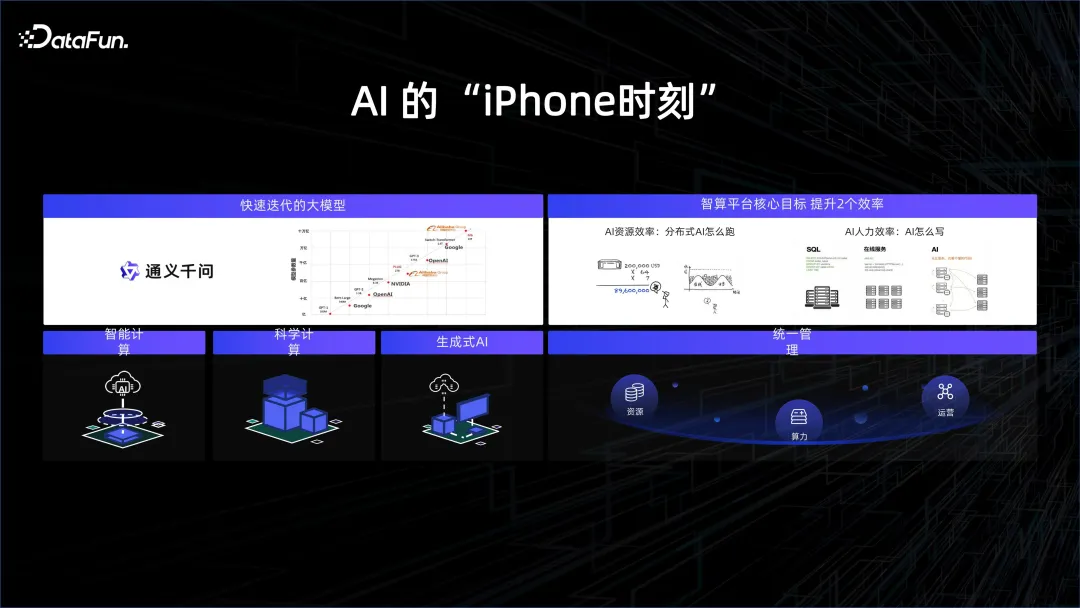
1. Der „iPhone“-Moment der KI
Im vergangenen Jahr haben sich große Modelle sehr schnell entwickelt. Die Kombination von Rechenleistung und Daten hat dem Modell eine gewisse allgemeine Struktur und Fähigkeit verliehen, Fragen zu beantworten. Die Menschen haben das Stadium der künstlichen Intelligenz erreicht, von dem sie immer geträumt haben. Wenn Sie beispielsweise mit einem großen Sprachmodell chatten, werden Sie das Gefühl haben, dass Sie es nicht mit einem stumpfen Roboter, sondern mit einem Menschen aus Fleisch und Blut zu tun haben. Es eröffnet unserer Fantasie mehr Raum. Die ursprüngliche Mensch-Computer-Interaktion erforderte die Verwendung von Tastatur und Maus, um der Maschine mithilfe einiger Formatierungsmethoden unsere Anweisungen zu übermitteln. Jetzt können Menschen über Sprache mit Computern interagieren, und Maschinen können verstehen, was wir meinen, und darauf reagieren.
Um mit dem Trend Schritt zu halten, begannen viele Technologieunternehmen, sich auf die Erforschung großer Modelle zu konzentrieren. 2023 gilt als das erste Jahr der künstlichen Intelligenz, genau wie die Einführung des iPhone eine neue Ära des mobilen Internets eröffnete. Der eigentliche Durchbruch liegt dieses Mal in der Anwendung großer Rechenleistung und riesiger Datenmengen.
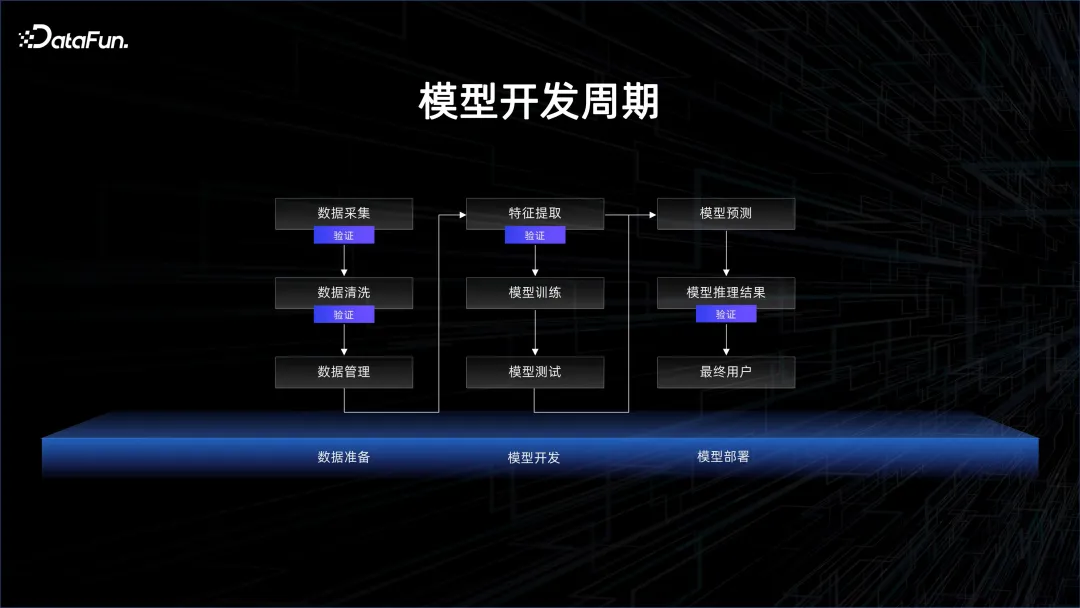
Aus Sicht der Modellstruktur ist die Transformer-Struktur tatsächlich schon seit langer Zeit eingeführt. Tatsächlich wurde das GPT-Modell ein Jahr früher als das Bert-Modell veröffentlicht. Aufgrund der damaligen Einschränkungen der Rechenleistung war GPT jedoch weitaus weniger effektiv als Bert. Daher wurde Bert zuerst für die Übersetzung verwendet sehr gute Ergebnisse. Aber der Fokus liegt in diesem Jahr auf GPT. Der Grund dafür ist die sehr hohe Rechenleistung, die wir aufgrund der Bemühungen der Hardware-Hersteller und einiger Fortschritte bei der Verpackung und Speicherung von Partikeln haben Gemeinsam fördern sie ein tieferes Verständnis von mehr Daten und bringen bahnbrechende Ergebnisse in der KI. Basierend auf der starken Unterstützung der zugrunde liegenden Plattform können Algorithmenstudenten Modelle bequemer und effizienter entwickeln und iterieren und so eine schnelle Modellentwicklung fördern. 2. Modellentwicklungsparadigma 2. Modellentwicklungsparadigma Tatsächlich müssen jedoch vor dem Modelltraining große Datenmengen gesammelt, bereinigt und verwaltet werden. In diesem Prozess können Sie sehen, dass viele Schritte überprüft werden müssen, z. B. ob schmutzige Daten vorliegen und ob die statistische Verteilung der Daten repräsentativ ist. Nachdem das Modell herausgekommen ist, muss es getestet und verifiziert werden. Dies ist auch die Überprüfung der Daten. Die Daten werden verwendet, um Feedback über die Wirksamkeit des Modells zu geben.
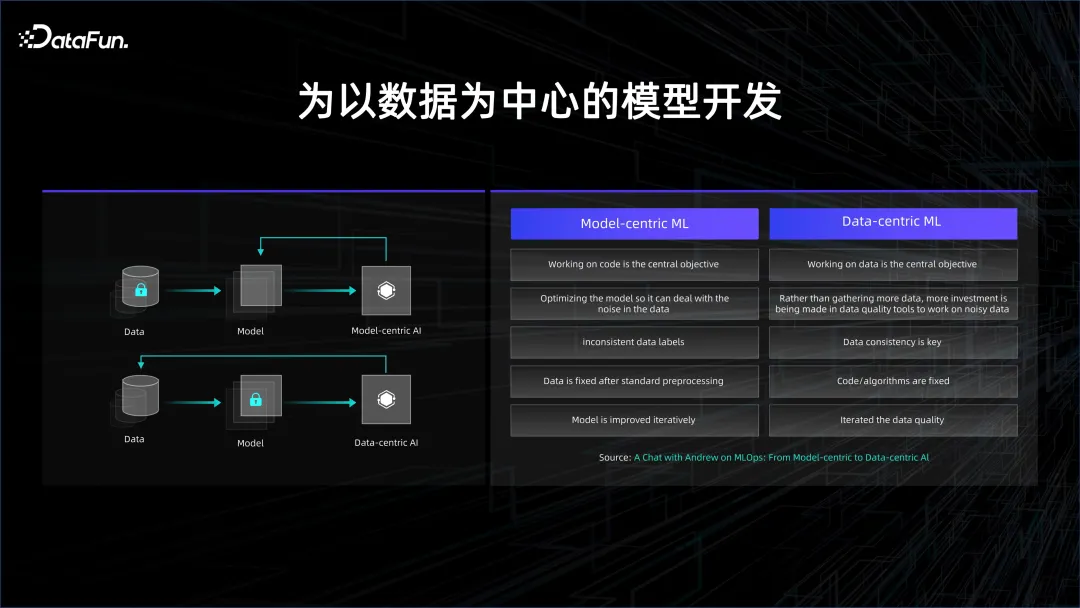
Besseres maschinelles Lernen besteht aus 80 % Daten plus 20 % Modell, und der Fokus sollte auf den Daten liegen.
Dies spiegelt auch den evolutionären Trend der Modellentwicklung wider. Die ursprüngliche Modellentwicklung war modellzentriert, jetzt ist sie datenzentriert.
 In den Anfängen des Deep Learning stand das überwachte Lernen im Mittelpunkt, und das Wichtigste war, beschriftete Daten zu haben. Die gekennzeichneten Daten sind in zwei Kategorien unterteilt: eine sind Trainingsdaten und die andere sind Verifizierungsdaten. Verwenden Sie die Trainingsdaten, um das Modell zu trainieren, und überprüfen Sie dann, ob das Modell mit den Testdaten gute Ergebnisse liefern kann. Die Kosten für die Kennzeichnung von Daten sind sehr hoch, da von den Menschen verlangt wird, sie zu kennzeichnen. Wenn Sie die Wirkung des Modells verbessern möchten, müssen Sie viel Zeit und Arbeitskraft in die Modellstruktur investieren, die Generalisierungsfähigkeit des Modells durch strukturelle Änderungen verbessern und die Überanpassung des Modells verringern. zentriertes Entwicklungsparadigma.
In den Anfängen des Deep Learning stand das überwachte Lernen im Mittelpunkt, und das Wichtigste war, beschriftete Daten zu haben. Die gekennzeichneten Daten sind in zwei Kategorien unterteilt: eine sind Trainingsdaten und die andere sind Verifizierungsdaten. Verwenden Sie die Trainingsdaten, um das Modell zu trainieren, und überprüfen Sie dann, ob das Modell mit den Testdaten gute Ergebnisse liefern kann. Die Kosten für die Kennzeichnung von Daten sind sehr hoch, da von den Menschen verlangt wird, sie zu kennzeichnen. Wenn Sie die Wirkung des Modells verbessern möchten, müssen Sie viel Zeit und Arbeitskraft in die Modellstruktur investieren, die Generalisierungsfähigkeit des Modells durch strukturelle Änderungen verbessern und die Überanpassung des Modells verringern. zentriertes Entwicklungsparadigma.
Mit der Anhäufung von Daten und Rechenleistung wurde nach und nach unüberwachtes Lernen eingesetzt. Durch massive Daten konnte das Modell die in den Daten vorhandenen Beziehungen autonom entdecken. Zu diesem Zeitpunkt trat es in die datenzentrierte Entwicklung ein. Paradigma.

3. Big Data AI-Integration
1. Big Data AI Panorama

Alibaba Cloud hat schon immer Wert auf die Integration von KI und Big Data gelegt. Deshalb haben wir eine Plattform mit einer sehr guten Infrastruktur aufgebaut, einschließlich GPU-Clustern mit hoher Bandbreite, um leistungsstarke KI-Rechenleistung bereitzustellen, und CPU-Clustern, um kostengünstige Speicher- und Datenverwaltungsfunktionen bereitzustellen. Darüber hinaus haben wir eine in Big Data und KI integrierte PaaS-Plattform aufgebaut, die eine Big-Data-Plattform, eine KI-Plattform, eine Plattform mit hoher Rechenleistung, eine Cloud-native Plattform usw. umfasst. Der Engine-Teil umfasst Streaming Computing, Big Data Offline Computing MaxCompute und PAI.
Im Service-Layer gibt es die große Modellanwendungsplattform Bailian und die Open-Source-Modell-Community ModelScope. Alibaba fördert aktiv den Austausch von Modellgemeinschaften und hofft, das Konzept von „Model as a Service“ nutzen zu können, um mehr Benutzer für KI-Anforderungen zu begeistern und die grundlegenden Funktionen dieser Modelle zu nutzen, um schnell KI-Anwendungen zu erstellen.
2. Warum es notwendig ist, Big Data und KI zu kombinieren
Anhand der folgenden zwei Fälle soll erläutert werden, warum die Verknüpfung zwischen Big Data und KI erforderlich ist.
Fall 1: Großes Modell-Frage-Antwort-System mit erweitertem Abruf der Wissensdatenbank
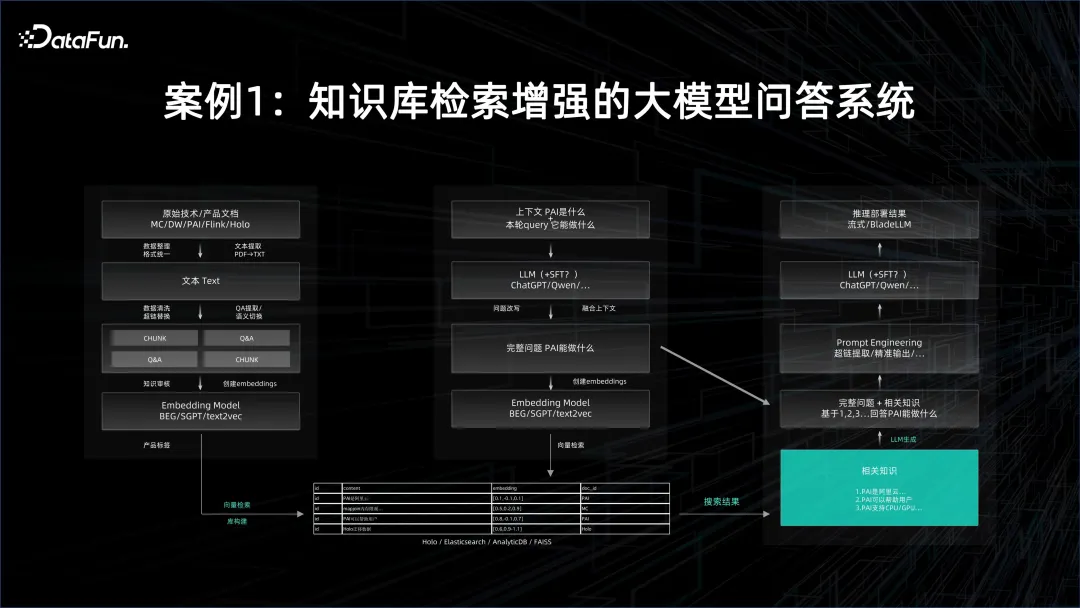
Im großen Modell-Frage-Antwort-System muss zuerst das Grundmodell verwendet werden, und dann sollte das Zieldokument eingebettet und eingebettet werden Die Ergebnisse werden in der Vektordatenbank gespeichert. Die Anzahl der Dokumente kann sehr groß sein, daher sind für die Einbettung Stapelverarbeitungsfunktionen erforderlich. Auch der Inferenzdienst des Basismodells selbst ist sehr ressourcenintensiv. Dies hängt natürlich auch davon ab, wie groß das Basismodell ist und wie es parallelisiert wird. Alle generierten Einbettungen werden in die Vektordatenbank gegossen. Bei der Abfrage muss die Abfrage auch vektorisiert werden, und dann wird durch Vektorabruf das Wissen, das sich möglicherweise auf die Frage und Antwort bezieht, aus der Vektordatenbank extrahiert. Dies erfordert eine sehr gute Leistung des Inferenzdienstes.
Nach dem Extrahieren des Vektors müssen Sie das durch den Vektor dargestellte Dokument als Kontext verwenden, dann dieses große Modell einschränken und auf dieser Grundlage Fragen und Antworten erstellen. Die Wirkung der Antwort ist weitaus besser als die erhaltenen Ergebnisse durch Ihre eigene Suchmethode, und die Antwort ist in menschlicher natürlicher Sprache.
Im oben genannten Prozess ist sowohl eine offline verteilte Big-Data-Plattform erforderlich, um schnell Einbettungen zu generieren, als auch eine KI-Plattform für Schulungen und Dienste für große Modelle, um den gesamten Prozess zu verbinden und ein Frage- und Antwortsystem für große Modelle zu bilden. .
Fall 2: Intelligentes Empfehlungssystem
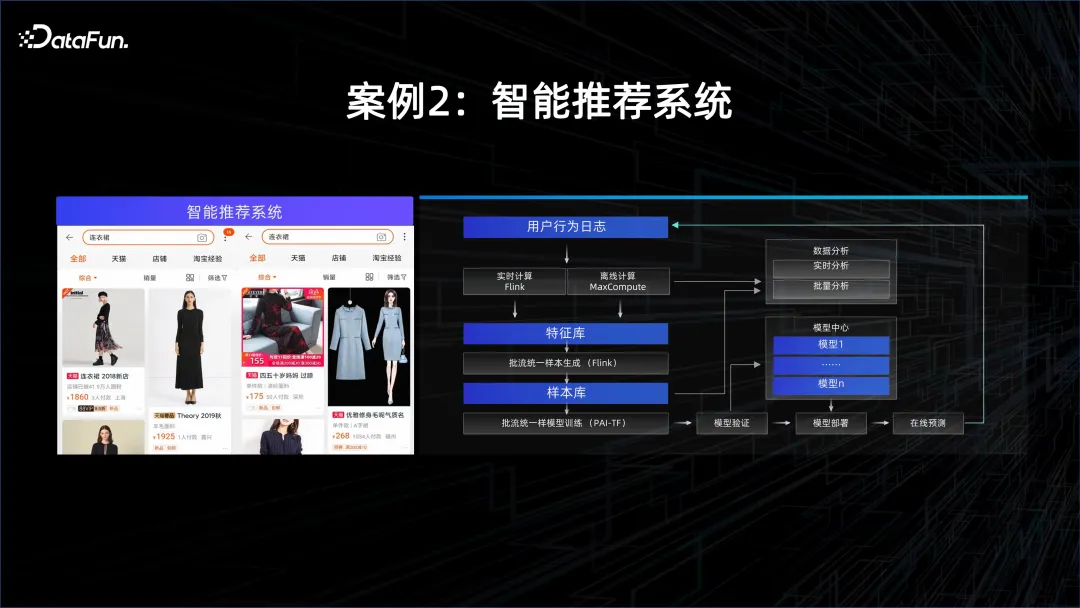
Ein weiteres Beispiel ist die personalisierte Empfehlung, da sich die Interessen und die Persönlichkeit jedes Einzelnen ändern und diese Änderungen erfasst werden müssen Streaming-Computing-System, um die in der APP erhaltenen Daten zu analysieren und das Modell dann kontinuierlich online durch die extrahierten Funktionen lernen zu lassen. Sobald neue Daten eingehen, wird das Modell aktualisiert und dann durch ein neues Modell bedient. Daher sind in diesem Szenario Streaming-Computing-Funktionen sowie Modellbereitstellungs- und Trainingsfunktionen erforderlich.
3. Wie man Big Data mit KI kombiniert
Anhand der oben genannten Fälle können wir erkennen, dass die Kombination von KI und Big Data zu einem unvermeidlichen Entwicklungstrend geworden ist. Basierend auf diesem Konzept benötigen wir zunächst einen Arbeitsbereich, der die Big-Data-Plattform und die KI-Plattform gemeinsam verwalten kann. Aus diesem Grund wurde der KI-Arbeitsbereich geboren.
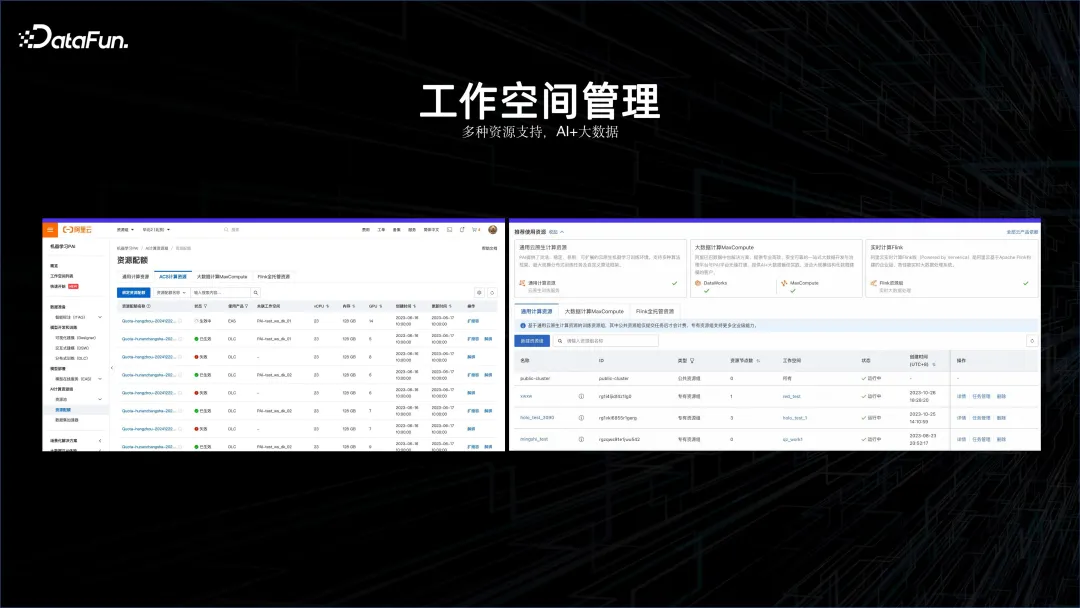
In diesem KI-Arbeitsbereich werden Flink-Cluster, Offline-Computing-Cluster MaxCompute, AI-Plattformen, Container-Service-Computing-Plattformen usw. unterstützt.
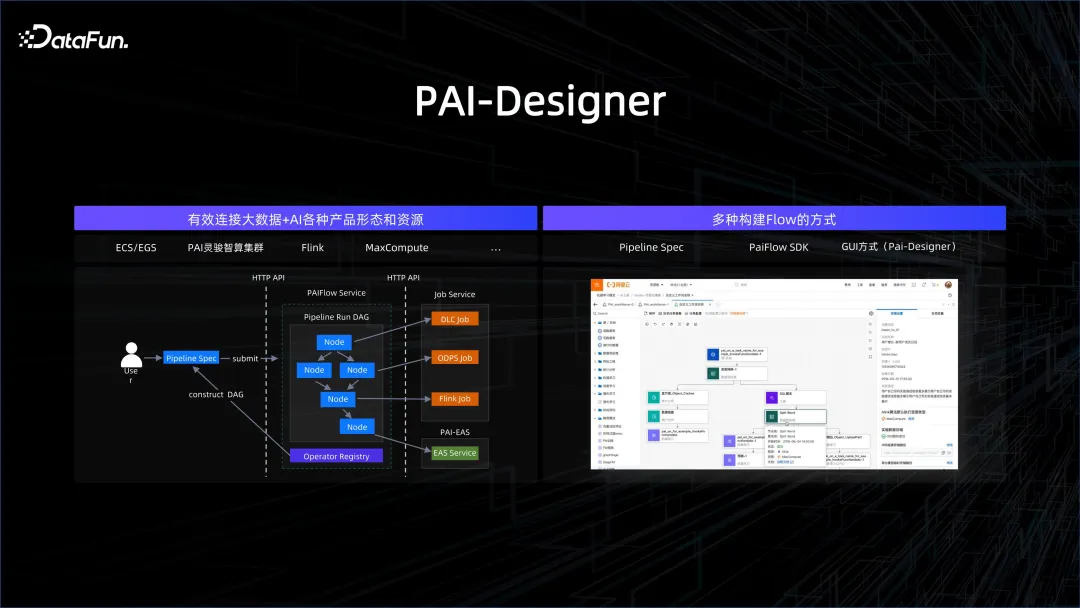
Die Vereinheitlichung von Big Data und KI-Management ist nur der erste Schritt. Wichtiger ist, sie in einem Workflow zu verbinden. Arbeitsabläufe können auf viele Arten eingerichtet werden, z. B. SDK, grafisch, GUI, SPEC-Schreiben usw. Die Knoten im Workflow können Big-Data-Verarbeitungsknoten oder KI-Verarbeitungsknoten sein, sodass komplexe Prozesse gut verbunden werden können.
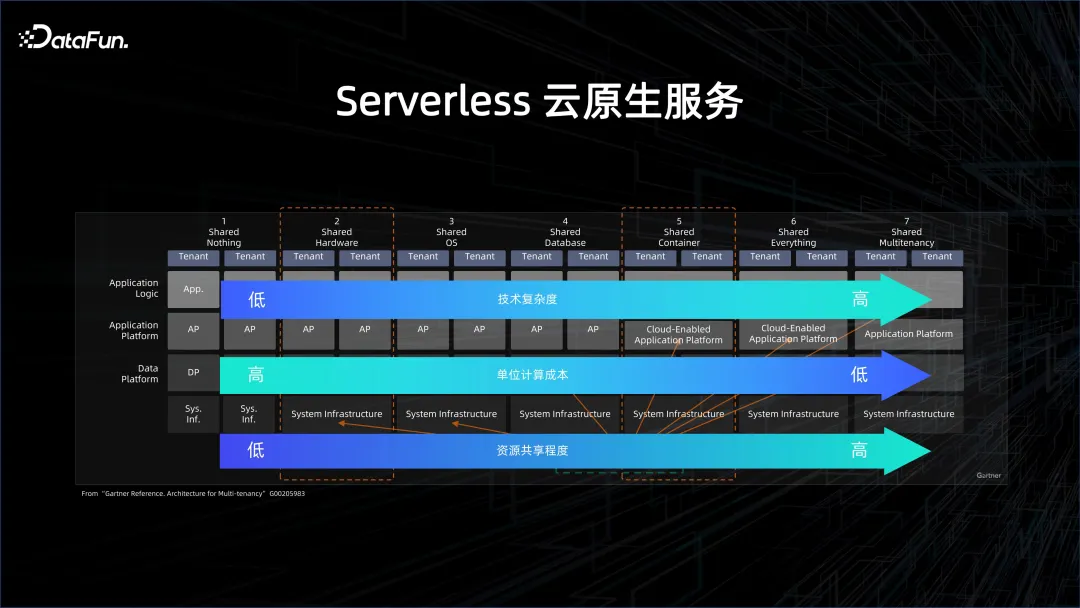
Um die Effizienz weiter zu verbessern und die Kosten zu senken, sind serverlose cloudnative Dienste erforderlich. Was Severless ist, wird im Bild oben ausführlich beschrieben. Cloud Native hat viele verschiedene Ebenen, von „Nichts teilen“ (Nicht-Cloud-Ansatz) bis „Alles teilen“ (stark Cloud-Ansatz). Je höher das Niveau, desto höher der Grad der gemeinsamen Nutzung von Ressourcen, desto geringer sind die Rechenkosten pro Einheit, aber desto größer ist auch der Druck auf das System.

Der Bereich Big Data und Datenbanken hat in den letzten zwei Jahren langsam begonnen, sich in Richtung Serverless zu bewegen, auch aus Kostengründen. Ursprünglich existierten sogar in der Cloud genutzte Server, etwa Datenbanken in der Cloud, in Form von Instanziierungen. Hinter diesen Instanzen liegen die Schatten der Ressourcen, beispielsweise wie viele CPUs und Kerne diese Instanz hat. Die erste Ebene, die sich langsam und schrittweise zu Serverless wandelt, ist das Single-Tenant-Computing, das sich auf die Einrichtung eines Clusters in der Cloud und die anschließende Bereitstellung von Big-Data- oder Datenbankplattformen darin bezieht. Dieser Cluster ist jedoch Single-Tenant-Cluster, das heißt, er teilt die physische Maschine mit anderen Personen. Die physische Maschine wird in eine virtuelle Maschine umgewandelt, die zum Aufbau einer Big-Data-Plattform verwendet wird. Mandantenspeicher sowie Einzelmandantenverwaltung und -kontrolle. Was Benutzer erhalten, ist eine elastische ECS-Maschine in der Cloud, aber die Big-Data-Verwaltung sowie Betriebs- und Wartungslösungen müssen selbst durchgeführt werden. EMR ist in dieser Hinsicht eine klassische Lösung.
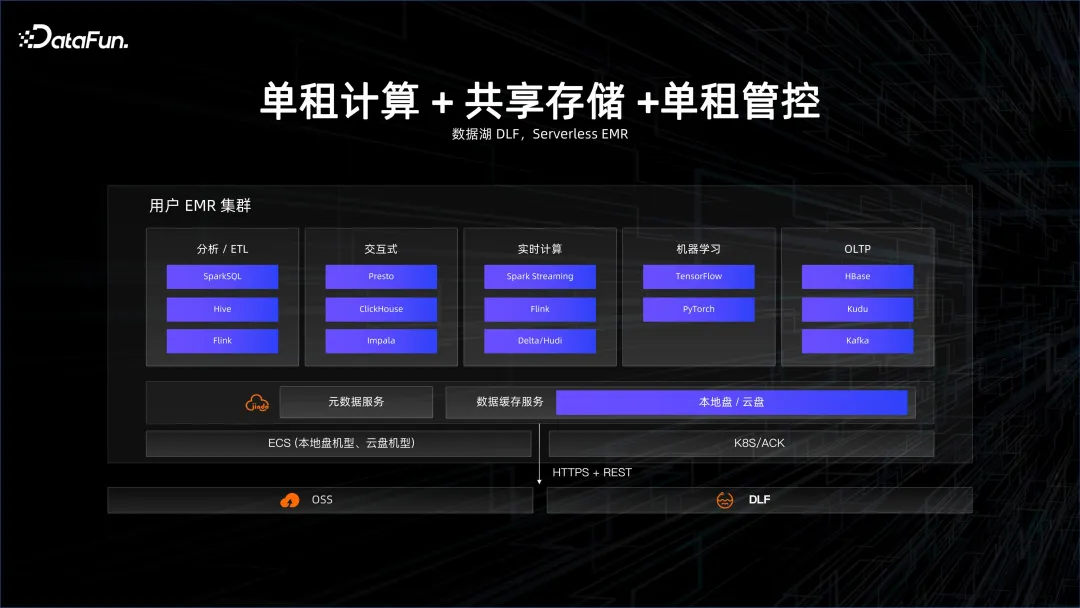
wird langsam vom Single-Tenant-Storage zum Shared Storage, der Data-Lake-Lösung, übergehen. Die Daten befinden sich in einem gemeinsam genutzten Big-Data-System. Nach Abschluss der Berechnung wird ein Cluster dynamisch aufgerufen, die Daten werden jedoch nicht gelöscht, da sie sich auf der Speicherseite einer zuverlässigen Fernbedienung befinden . Dies ist ein gemeinsamer Speicher. Typische Lösungen sind Data Lake DLF und serverlose EMR-Lösungen.

Das Extremste ist Share Everything. Wenn Sie BigQuery oder Alibaba Clouds MaxCompute verwenden, sehen Sie eine Plattform, die einige virtualisierte Projekte verwaltet, und die Plattform führt die Abfrage basierend auf dem aus Abfrage. Abrechnungsmessung.

Das kann viele Vorteile mit sich bringen. Beispielsweise gibt es in Big-Data-Berechnungen viele Knoten, für die kein Benutzercode erforderlich ist, da es sich bei diesen Knoten tatsächlich um integrierte Operatoren wie Join und Aggregator handelt. Für diese deterministischen Ergebnisse ist keine relativ umfangreiche Sandbox erforderlich Operatoren, die streng getestet wurden und keinen Schadcode oder willkürlichen UDF-Code enthalten, können den Overhead der Virtualisierung eliminieren.
Der Vorteil von UDF ist die Flexibilität, die uns die Verarbeitung umfangreicher Daten ermöglicht und eine gute Skalierbarkeit bei großen Datenmengen bietet. Eine Herausforderung, die UDF jedoch mit sich bringen wird, ist das Bedürfnis nach Sicherheit und Isolation.
Sowohl Googles BigQuery als auch MaxComputer basieren auf der Share-Everything-Architektur. Wir glauben, dass nur durch die kontinuierliche Verbesserung der Technologie Ressourcen besser genutzt, Rechenleistungskosten eingespart und mehr Rechenleistung eingespart werden können Unternehmen können es sich leisten, diese Daten zu nutzen, was die Verwendung von Daten im Modelltraining fördert.
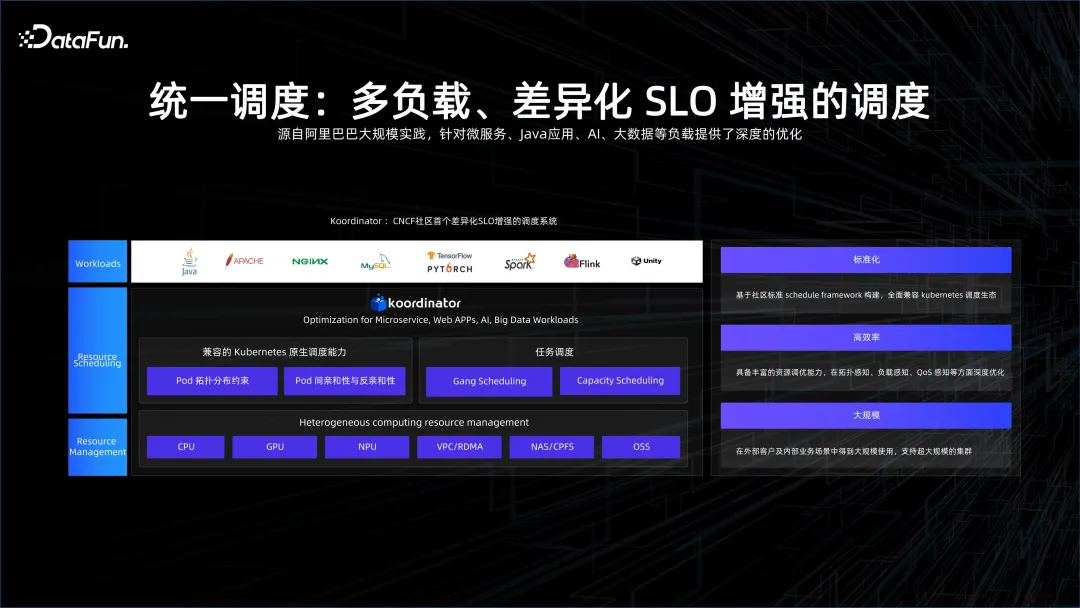
Gerade dank „Alles teilen“ können wir Big Data und KI nicht nur auf einheitliche Weise über den Arbeitsbereich verwalten und über den PAI-Flow verbinden, sondern auch eine einheitliche Planung durchführen, indem wir alles teilen. Auf diese Weise werden die Forschungs- und Entwicklungskosten von Enterprise AI + Big Data weiter gesenkt.
An diesem Punkt gibt es viel zu tun. Die Planung von K8S selbst ist auf Microservices ausgerichtet, die für Big Data vor großen Herausforderungen stehen werden, da die Granularität der Serviceplanung von Big Data sehr gering ist und viele Aufgaben nur wenige Sekunden bis Dutzende von Sekunden überleben um mehrere Größenordnungen erhöhen. Wir müssen vor allem herausfinden, wie wir diese Planungsfunktion auf K8S skalieren können. Das von uns gestartete Open-Source-Projekt Koordinator soll die Planungsfunktion verbessern und Big Data und KI in das K8S-Ökosystem integrieren.

Eine weitere wichtige Aufgabe ist die sichere Isolierung mehrerer Mieter. So implementieren Sie Mehrmandantenfähigkeit in der Serviceschicht und Kontrollschicht von K8S und wie implementieren Sie Mehrmandantenfähigkeit über See im Netzwerk, sodass mehrere Benutzer auf einem K8S bedient werden können und die Daten und Ressourcen jedes Benutzers effektiv genutzt werden können isoliert.
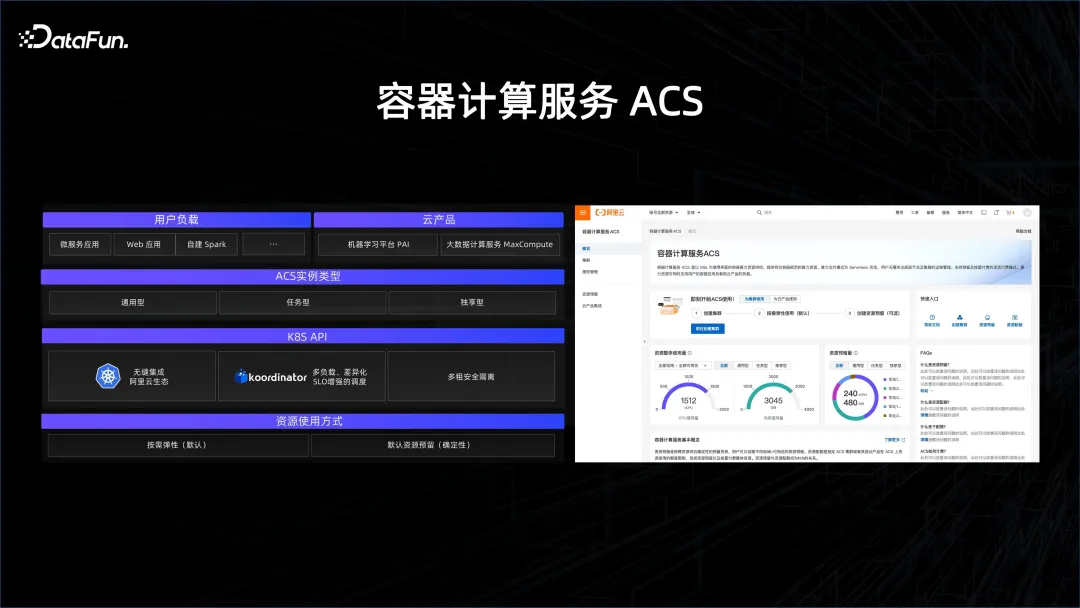
Alibaba hat einen Containerdienst namens ACS gestartet, der die beiden zuvor eingeführten Technologien nutzt, um alle Ressourcen durch Containerisierung verfügbar zu machen, sodass Benutzer die Big-Data-Plattform und die KI-Plattform nahtlos nutzen können. Es handelt sich um eine mandantenfähige Methode, die die Anforderungen von Big Data unterstützen kann. Die Planungsanforderungen von Big Data sind um mehrere Größenordnungen höher als die von Microservices und KI und müssen gut umgesetzt werden. Auf dieser Basis können ACS-Produkte Kunden dabei helfen, ihre Ressourcen gut zu verwalten.
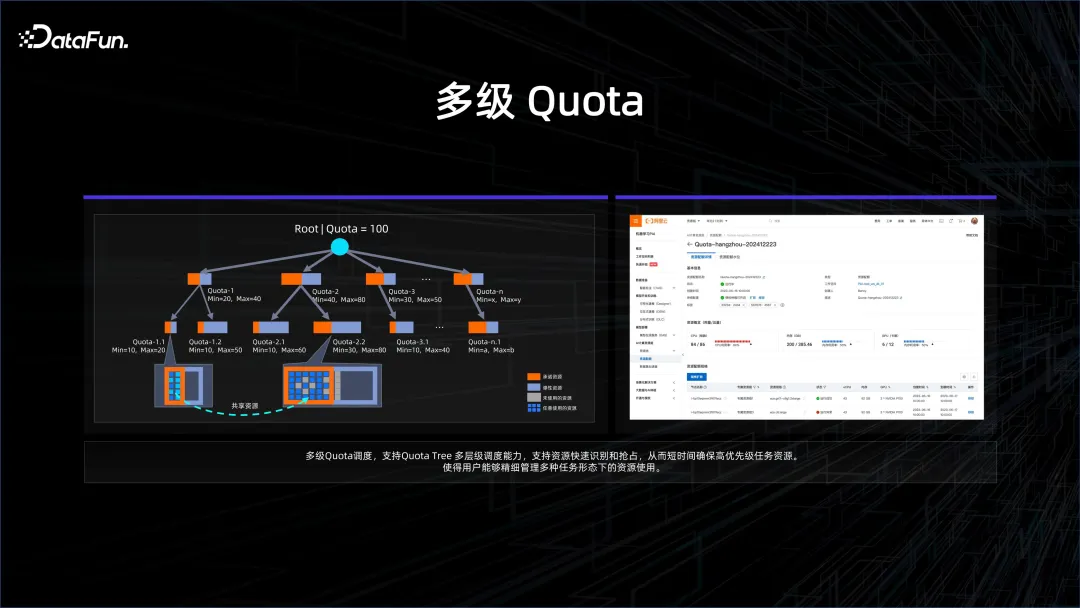
Unternehmen stehen vor vielen Anforderungen und müssen sorgfältiger mit Ressourcen umgehen. Beispielsweise wird ein Unternehmen in verschiedene Abteilungen und Unterteams unterteilt, wobei die Ressourcen in viele Richtungen aufgeteilt werden, um zu sehen, in welchen Szenarien dieses Basismodell gut eingesetzt werden kann. Aber irgendwann möchte ich mich auf große Dinge konzentrieren und die gesamte Rechenleistung und Ressourcen bündeln, um die nächste Iteration des Basismodells zu trainieren. Um dieses Problem zu lösen, haben wir eine mehrstufige Quotenverwaltung eingeführt. Das heißt, wenn Aufgaben mit höheren Anforderungen eintreffen, kann es eine höhere Ebene geben, um alle darunter liegenden Unterquoten zusammenzuführen und zu konsolidieren.
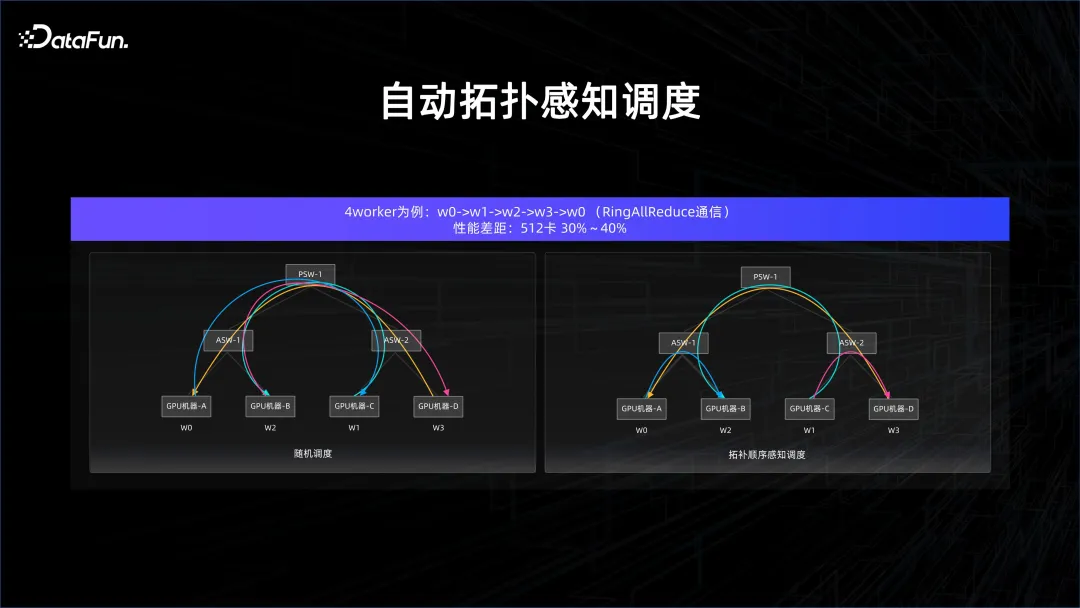
Tatsächlich gibt es im KI-Szenario viele Besonderheiten. In vielen Fällen ist eine synchrone Berechnung erforderlich, und die synchrone Berechnung reagiert sehr empfindlich auf Verzögerungen, und die KI-Berechnungsdichte ist hoch, was ein Netzwerk erfordert sehr hoch. Wenn Sie die Rechenleistung sicherstellen möchten, müssen Sie Daten bereitstellen und Gradienteninformationen austauschen. Wenn das Modell parallel ist, werden mehr Dinge ausgetauscht. In diesen Fällen ist eine topologiebewusste Planung erforderlich, um sicherzustellen, dass es keine Kommunikationsmängel gibt.
Wenn beispielsweise im All Reduce-Link des Modelltrainings eine zufällige Planung durchgeführt wird, gibt es viele Cross-Port-Switch-Verbindungen. Wenn die Reihenfolge jedoch sorgfältig kontrolliert wird, sind die Cross-Port-Switch-Verbindungen sehr hoch sauber, daher wird die Verzögerung sein Es kann gut garantiert werden, da im Switch der oberen Schicht keine Konflikte auftreten.
Nach diesen Optimierungen kann die Leistung erheblich verbessert werden. Die Übertragung dieser topologiebewussten Zeitpläne an den Manager der gesamten Plattform ist ebenfalls ein Thema, das berücksichtigt werden muss, wenn KI das Datenplattformmanagement verbessert.
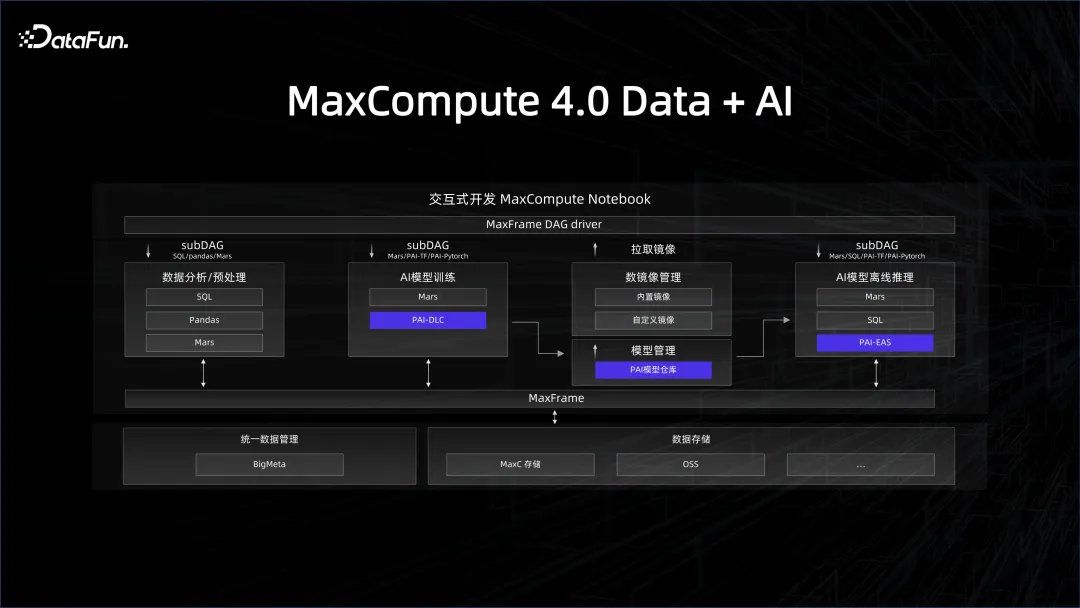
Was wir zuvor eingeführt haben, ist die Verwaltung von Ressourcen und Plattformen. Auch das Datenmanagement, an dem wir gearbeitet haben, ist entscheidend. Um das Datensystem mit dem KI-System zu verknüpfen, muss das Data Warehouse eine KI-freundliche Datenverbindung bereitstellen. Beispielsweise wird im KI-Entwicklungsprozess das Python-Ökosystem verwendet. Wie kann die Datenseite diese Plattform über ein Python-SDK nutzen? Die beliebteste Bibliothek in Python ist eine Datenrahmen-Datenstruktur, die Pandas ähnelt. Wir können die Client-Seite der Big-Data-Engine in eine Pandas-Schnittstelle packen, sodass alle KI-Entwicklungsmitarbeiter, die mit Python vertraut sind, sie gut nutzen können . Dies ist auch die Philosophie hinter dem MaxFrame-Framework, das wir dieses Jahr auf MaxCompute eingeführt haben.
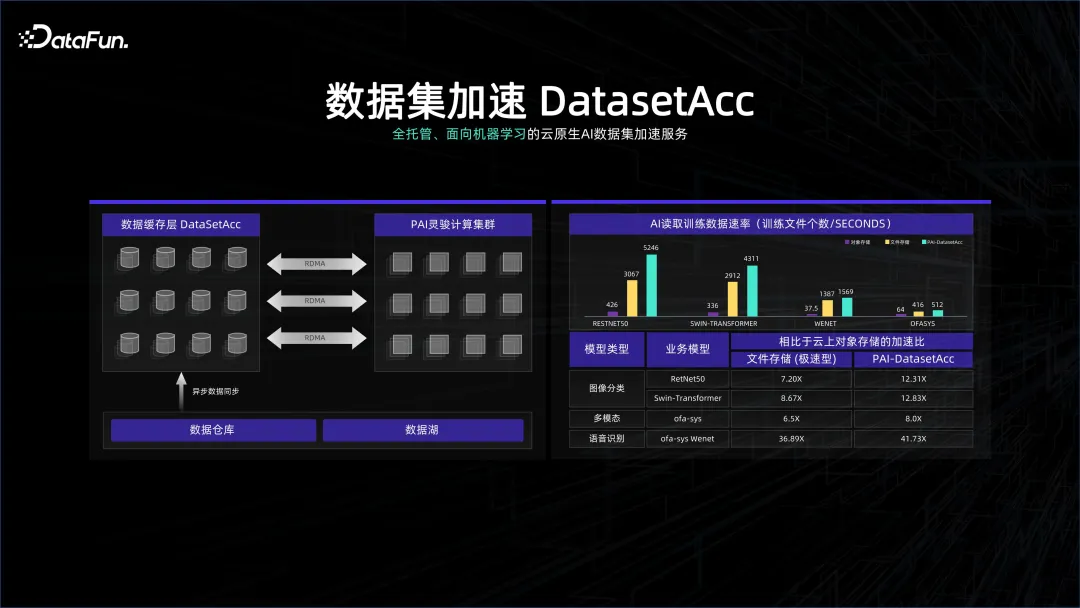
In vielen Fällen reagieren Datenverarbeitungssysteme sehr empfindlich auf die Kosten. Manchmal werden Speichersysteme mit höherer Dichte verwendet, um dieses System nicht zu verschwenden Speichersystem Der Cluster stellt hohe Anforderungen an das Netzwerk und die GPU, und die beiden Systeme sind wahrscheinlich von Speicher und Berechnung getrennt. Unser Datensystem ist möglicherweise auf Governance und Verwaltung ausgerichtet, während das Computersystem möglicherweise auf Berechnungen ausgerichtet ist. Obwohl beide unter der Verwaltung eines K8S stehen, müssen wir das Warten auf Daten während der Berechnung vermeiden haben eine Datensatzbeschleunigung erstellt. DataSetAcc ist eigentlich ein Datencache, der sich nahtlos mit den Daten von Remote-Speicherknoten verbindet und Algorithmusingenieuren dabei hilft, Daten zur Berechnung hinter den Kulissen in den lokalen Speicher oder auf eine SSD zu ziehen.
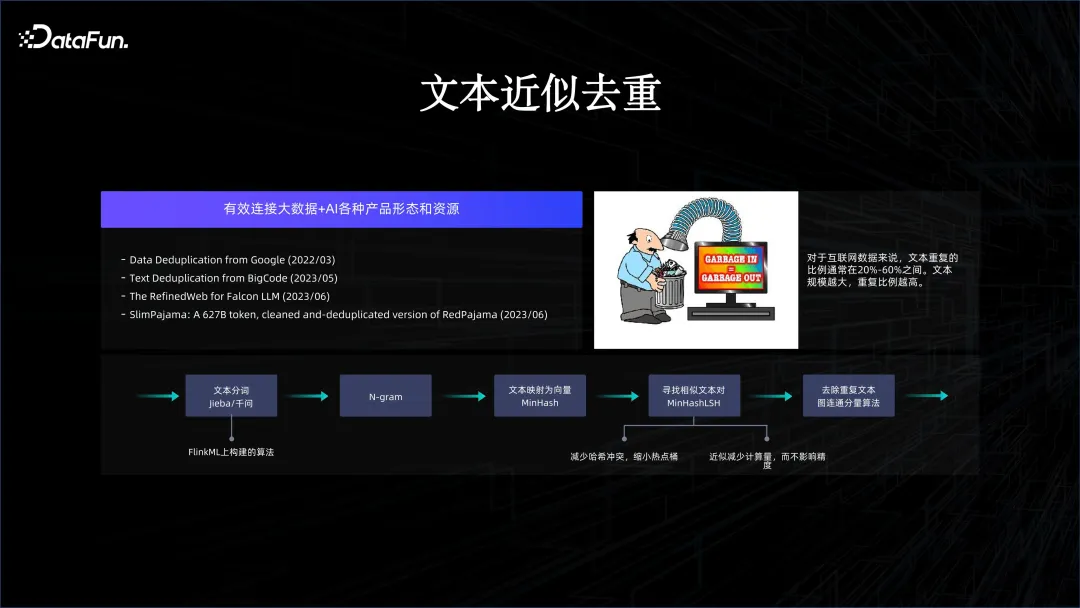
Durch die oben genannten Methoden können die KI- und Big-Data-Plattformen organisch kombiniert werden, sodass wir einige Innovationen durchführen können. Wenn beispielsweise das Modelltraining für viele Serien mit allgemeiner Bedeutung unterstützt wird, müssen viele Daten bereinigt werden, da Internetdaten viele Duplikate aufweisen. Daher ist es von entscheidender Bedeutung, wie Daten über ein Big-Data-System dedupliziert werden. Gerade weil wir die beiden Systeme organisch kombiniert haben, ist es einfach, die Daten auf der Big-Data-Plattform zu bereinigen und die Ergebnisse können sofort in das Modelltraining eingespeist werden.

Der vorherige Artikel stellt hauptsächlich vor, wie Big Data das KI-Modelltraining unterstützt. Andererseits kann KI-Technologie auch zur Unterstützung von Dateneinblicken und zur Entwicklung eines BI + KI-Datenverarbeitungsmodells eingesetzt werden.
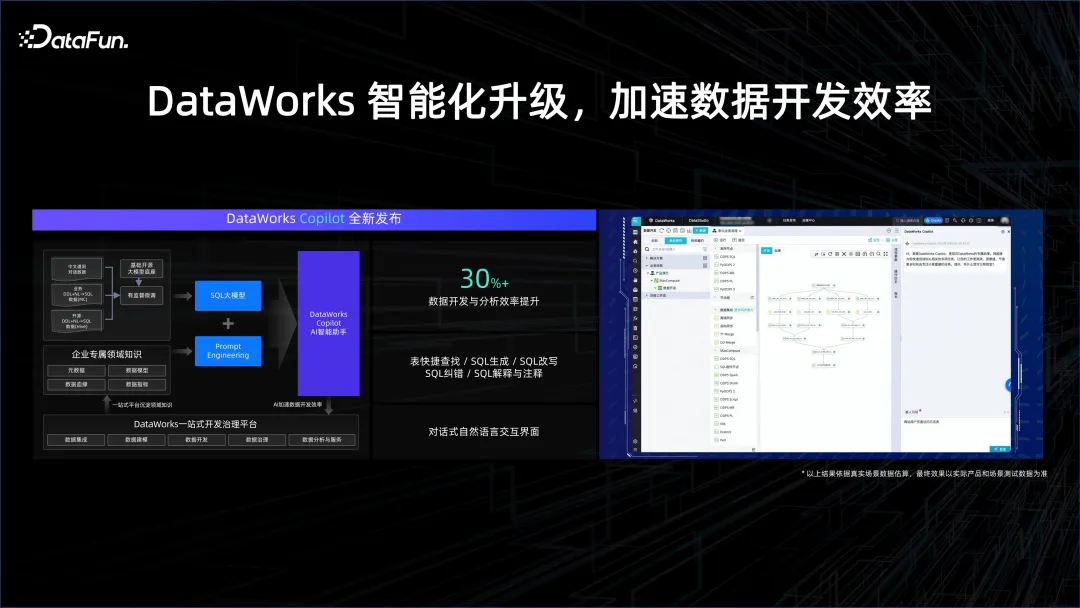
Im Datenverarbeitungsprozess kann es Datenanalysten dabei helfen, einfacher Analysen zu erstellen. Ursprünglich müssen sie möglicherweise SQL schreiben und lernen, wie man Tools für die Interaktion mit dem Datensystem verwendet. Allerdings hat die KI-Ära die Art und Weise der Mensch-Computer-Interaktion verändert und kann über natürliche Sprache mit Datensystemen interagieren. Beispielsweise kann der Copilot-Programmierassistent bei der Generierung von SQL helfen und dabei helfen, verschiedene Schritte im Datenentwicklungsprozess abzuschließen, wodurch die Entwicklungseffizienz erheblich verbessert wird.

Darüber hinaus können Dateneinblicke auch durch KI erfolgen. Mithilfe von KI können beispielsweise Daten, die Anzahl der eindeutigen Schlüssel und die für die Visualisierung geeignete Methode ermittelt werden. KI kann Daten aus allen Blickwinkeln beobachten und verstehen, automatische Datenexploration, intelligente Datenabfrage, Diagrammerstellung und Analyseberichterstellung mit einem Klick usw. realisieren. Dies ist ein intelligenter Analysedienst.
IV. Zusammenfassung
Getrieben durch Big Data und KI gab es in den letzten Jahren einige sehr erfreuliche technologische Entwicklungen. Um in diesem Trend unbesiegbar zu bleiben, ist es notwendig, Big Data und KI zu verknüpfen. Nur wenn sich beide ergänzen, können wir eine bessere Beschleunigung der KI-Iteration und ein besseres Datenverständnis erreichen.
Das obige ist der detaillierte Inhalt vonIntegrierte Big-Data-KI-Interpretation. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Offizielles iPhone 16 Pro und iPhone 16 Pro Max mit neuen Kameras, A18 Pro SoC und größeren Bildschirmen
Sep 10, 2024 am 06:50 AM
Offizielles iPhone 16 Pro und iPhone 16 Pro Max mit neuen Kameras, A18 Pro SoC und größeren Bildschirmen
Sep 10, 2024 am 06:50 AM
Apple hat endlich die Hüllen seiner neuen High-End-iPhone-Modelle entfernt. Das iPhone 16 Pro und das iPhone 16 Pro Max verfügen jetzt über größere Bildschirme im Vergleich zu ihren Gegenstücken der letzten Generation (6,3 Zoll beim Pro, 6,9 Zoll beim Pro Max). Sie erhalten einen verbesserten Apple A1
 Aktivierungssperre für iPhone-Teile in iOS 18 RC entdeckt – möglicherweise Apples jüngster Schlag gegen das Recht auf Reparatur, das unter dem Deckmantel des Benutzerschutzes verkauft wird
Sep 14, 2024 am 06:29 AM
Aktivierungssperre für iPhone-Teile in iOS 18 RC entdeckt – möglicherweise Apples jüngster Schlag gegen das Recht auf Reparatur, das unter dem Deckmantel des Benutzerschutzes verkauft wird
Sep 14, 2024 am 06:29 AM
Anfang des Jahres kündigte Apple an, die Funktion „Aktivierungssperre“ auf iPhone-Komponenten auszuweiten. Dadurch werden einzelne iPhone-Komponenten wie Akku, Display, FaceID-Baugruppe und Kamerahardware effektiv mit einem iCloud-Konto verknüpft.
 Die Aktivierungssperre für iPhone-Teile könnte Apples jüngster Schlag gegen das Recht auf Reparatur sein, das unter dem Deckmantel des Benutzerschutzes verkauft wird
Sep 13, 2024 pm 06:17 PM
Die Aktivierungssperre für iPhone-Teile könnte Apples jüngster Schlag gegen das Recht auf Reparatur sein, das unter dem Deckmantel des Benutzerschutzes verkauft wird
Sep 13, 2024 pm 06:17 PM
Anfang des Jahres kündigte Apple an, die Aktivierungssperre auf iPhone-Komponenten auszuweiten. Dadurch werden einzelne iPhone-Komponenten wie Akku, Display, FaceID-Baugruppe und Kamerahardware effektiv mit einem iCloud-Konto verknüpft.
 Gate.io Trading Platform Offizielle App -Download- und Installationsadresse
Feb 13, 2025 pm 07:33 PM
Gate.io Trading Platform Offizielle App -Download- und Installationsadresse
Feb 13, 2025 pm 07:33 PM
In diesem Artikel werden die Schritte zum Registrieren und Herunterladen der neuesten App auf der offiziellen Website von Gate.io beschrieben. Zunächst wird der Registrierungsprozess eingeführt, einschließlich der Ausgabe der Registrierungsinformationen, der Überprüfung der E -Mail-/Mobiltelefonnummer und dem Ausfüllen der Registrierung. Zweitens wird erläutert, wie Sie die Gate.io -App auf iOS -Geräten und Android -Geräten herunterladen. Schließlich werden Sicherheits-Tipps betont, z. B. die Überprüfung der Authentizität der offiziellen Website, die Ermöglichung von zweistufiger Überprüfung und das Aufmerksamkeit von Phishing-Risiken, um die Sicherheit von Benutzerkonten und -vermögen zu gewährleisten.
 Mehrere iPhone 16 Pro-Benutzer berichten von Problemen mit dem Einfrieren des Touchscreens, die möglicherweise mit der Empfindlichkeit bei der Ablehnung der Handfläche zusammenhängen
Sep 23, 2024 pm 06:18 PM
Mehrere iPhone 16 Pro-Benutzer berichten von Problemen mit dem Einfrieren des Touchscreens, die möglicherweise mit der Empfindlichkeit bei der Ablehnung der Handfläche zusammenhängen
Sep 23, 2024 pm 06:18 PM
Wenn Sie bereits ein Gerät aus der iPhone 16-Reihe von Apple – genauer gesagt das 16 Pro/Pro Max – in die Hände bekommen haben, ist die Wahrscheinlichkeit groß, dass Sie kürzlich ein Problem mit dem Touchscreen hatten. Der Silberstreif am Horizont ist, dass Sie nicht allein sind – Berichte
 Beats erweitert sein Sortiment um Handyhüllen: stellt eine MagSafe-Hülle für die iPhone 16-Serie vor
Sep 11, 2024 pm 03:33 PM
Beats erweitert sein Sortiment um Handyhüllen: stellt eine MagSafe-Hülle für die iPhone 16-Serie vor
Sep 11, 2024 pm 03:33 PM
Beats ist dafür bekannt, Audioprodukte wie Bluetooth-Lautsprecher und -Kopfhörer auf den Markt zu bringen, aber was man am besten als Überraschung bezeichnen kann, hat sich das Apple-Unternehmen auf die Herstellung von Handyhüllen spezialisiert, beginnend mit der iPhone 16-Serie. Das Beats-iPhone
 Wie löste ich das Problem des Fehlers 'Undefined Array Key '' 'Fehler beim Aufrufen von Alipay EasysDK mithilfe von PHP?
Mar 31, 2025 pm 11:51 PM
Wie löste ich das Problem des Fehlers 'Undefined Array Key '' 'Fehler beim Aufrufen von Alipay EasysDK mithilfe von PHP?
Mar 31, 2025 pm 11:51 PM
Problembeschreibung beim Aufrufen von Alipay EasysDK mithilfe von PHP nach dem Ausfüllen der Parameter gemäß dem offiziellen Code wurde während des Betriebs eine Fehlermeldung gemeldet: "undefiniert ...
 ANBI App Offizieller Download V2.96.2 Neueste Version Installation Anbi Offizielle Android -Version
Mar 04, 2025 pm 01:06 PM
ANBI App Offizieller Download V2.96.2 Neueste Version Installation Anbi Offizielle Android -Version
Mar 04, 2025 pm 01:06 PM
Binance App Offizielle Installationsschritte: Android muss die offizielle Website besuchen, um den Download -Link zu finden. Wählen Sie die Android -Version zum Herunterladen und Installieren. Alle sollten auf die Vereinbarung über offizielle Kanäle achten.
