

Die Schätzung der Objektposition spielt eine Schlüsselrolle in vielen realen Anwendungen, wie z. B. verkörperter Intelligenz, geschickter Robotermanipulation und Augmented Reality.
In diesem Bereich ist die erste Aufgabe, die Beachtung findet, die 6D-Posenschätzung auf Instanzebene, die annotierte Daten über das Zielobjekt für das Modelltraining erfordert, wodurch das tiefe Modell objektspezifisch wird und nicht auf On übertragen werden kann neue Objekte. Später verlagerte sich der Forschungsschwerpunkt nach und nach auf die 6D-Posenschätzung auf Kategorieebene, die zur Verarbeitung unsichtbarer Objekte verwendet wird, aber erfordert, dass das Objekt zu einer bekannten Kategorie von Interesse gehört.
Und die Zero-Shot-6D-Poseschätzung ist eine allgemeinere Aufgabenstellung, bei der ein CAD-Modell eines beliebigen Objekts vorliegt und die darauf abzielt, das Zielobjekt in der Szene zu erkennen und seine 6D-Pose abzuschätzen. Trotz ihrer Bedeutung steht diese Zero-Shot-Aufgabeneinstellung vor erheblichen Herausforderungen sowohl bei der Objekterkennung als auch bei der Posenschätzung.

Abbildung 1. Zero-Sample-6D-Objektpositionsschätzungsaufgabe
In letzter Zeit hat das Segmentation-Everything-Modell SAM [1] viel Aufmerksamkeit erregt, und seine hervorragende Zero-Sample-Segmentierungsfähigkeit ist ein Blickfang. SAM erreicht eine hochpräzise Segmentierung durch verschiedene Hinweise wie Pixel, Begrenzungsrahmen, Text und Masken usw., was auch eine zuverlässige Unterstützung für die Null-Probe-6D-Objekthaltungsschätzungsaufgabe bietet und sein vielversprechendes Potenzial demonstriert.
Daher haben Forscher von Interdimensional Intelligence, der Chinesischen Universität Hongkong (Shenzhen) und der South China University of Technology gemeinsam ein innovatives Zero-Sample-6D-Objektpositionsschätzungs-Framework SAM-6D vorgeschlagen. Diese Forschung wurde in CVPR 2024 aufgenommen.

SAM-6D erreicht eine Zero-Sample-6D-Objektpositionsschätzung durch zwei Schritte, einschließlich Instanzsegmentierung und Posenschätzung. Dementsprechend nutzt SAM-6D bei jedem Zielobjekt zwei dedizierte Subnetzwerke, nämlich Instance Segmentation Model (ISM) und Pose Estimation Model (PEM) , um das Ziel aus RGB-D-Szenenbildern zu erreichen, wobei ISM SAM verwendet Als hervorragender Ausgangspunkt, kombiniert mit sorgfältig entwickelten Objekt-Matching-Scores, um eine Instanzsegmentierung beliebiger Objekte zu erreichen, löst PEM das Objekt-Posen-Problem durch einen zweistufigen Punktsatz-Matching-Prozess von lokal zu lokal. Eine Übersicht über den SAM-6D ist in Abbildung 2 dargestellt. Abbildung 2. Überblick über SAM-6D Schätzung Das Framework erreicht anhand eines CAD-Modells eines beliebigen Objekts eine Instanzsegmentierung und Posenschätzung von Zielobjekten aus RGB-D-Bildern und schneidet bei den sieben Kerndatensätzen von BOP hervorragend ab [2].
SAM-6D nutzt die Zero-Shot-Segmentierungsfähigkeit des Segment Everything-Modells, um alle möglichen Kandidaten zu generieren, und entwirft einen neuartigen Objekt-Matching-Score, um Kandidaten zu identifizieren, die Zielobjekten entsprechen. 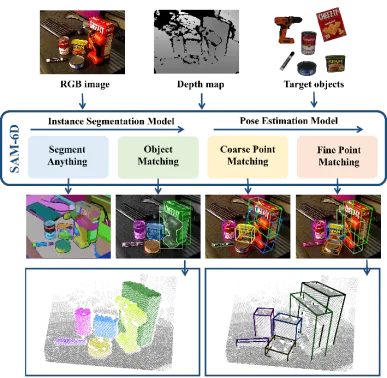
SAM-6D behandelt die Posenschätzung als ein lokales Punktmengen-Matching-Problem, übernimmt ein einfaches, aber effektives Hintergrund-Token-Design und schlägt zunächst ein zweistufiges Punktmengen-Matching-Modell für beliebige Objekte vor. Die erste Stufe wird implementiert Grober Punktsatzabgleich, um die anfängliche Objektpose zu erhalten, und die zweite Stufe verwendet einen neuartigen Punktsatztransformator von dünner bis dichter Dichte, um einen feinen Punktsatzabgleich durchzuführen, um die Pose weiter zu optimieren.
Instance Segmentation Model (ISM)
Der Objekt-Matching-Score wird durch die gewichtete Summe von drei passenden Elementen berechnet:
Semantisches Matching – Für das Zielobjekt rendert ISM Objektvorlagen aus mehreren Perspektiven und verwendet DINOv2 [3], das vorab trainierte ViT-Modell Extrahiert die semantischen Merkmale von Kandidatenobjekten und Objektvorlagen und berechnet den Korrelationswert zwischen ihnen. Die semantische Übereinstimmungsbewertung wird durch Mitteln der höchsten K-Bewertungen erhalten, und die Objektvorlage, die der höchsten Korrelationsbewertung entspricht, wird als die am besten übereinstimmende Vorlage angesehen.
Aussehensanpassung – Für die Vorlage mit der besten Übereinstimmung wird das ViT-Modell verwendet, um Bildblockmerkmale zu extrahieren und die Korrelation zwischen ihm und den Blockmerkmalen des Kandidatenobjekts zu berechnen, um die Darstellungsübereinstimmungsbewertung zu erhalten, die verwendet wird Semantik unterscheiden Objekte, die ähnlich sind, aber unterschiedlich aussehen.
Geometrische Übereinstimmung – Unter Berücksichtigung von Faktoren wie Form- und Größenunterschieden verschiedener Objekte hat ISM auch einen geometrischen Übereinstimmungswert entwickelt. Der Durchschnitt der Drehung entsprechend der am besten passenden Vorlage und der Punktwolke des Kandidatenobjekts kann eine grobe Objekthaltung ergeben, und der Begrenzungsrahmen kann durch starre Transformation und Projektion des Objekt-CAD-Modells unter Verwendung dieser Haltung erhalten werden. Durch Berechnen des Schnittmengen-über-Union-Verhältnisses (IoU) zwischen dem Begrenzungsrahmen und dem Kandidaten-Begrenzungsrahmen kann der geometrische Übereinstimmungswert ermittelt werden.
Für jedes Kandidatenobjekt, das mit einem Zielobjekt übereinstimmt, verwendet SAM-6D ein Pose Estimation Model (PEM), um seine 6D-Pose relativ zum CAD-Modell des Objekts vorherzusagen.
Bezeichnen Sie die Abtastpunktsätze segmentierter Kandidatenobjekte und Objekt-CAD-Modelle als 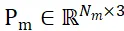 bzw.
bzw. 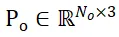 , wobei N_m und N_o gleichzeitig die Anzahl ihrer Punkte darstellen und die Eigenschaften dieser beiden Punktsätze darstellen werden als
, wobei N_m und N_o gleichzeitig die Anzahl ihrer Punkte darstellen und die Eigenschaften dieser beiden Punktsätze darstellen werden als 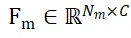 und
und 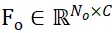 ausgedrückt, wobei C die Anzahl der Kanäle der Funktion darstellt. Das Ziel von PEM besteht darin, eine Zuordnungsmatrix zu erhalten, die die örtliche Korrespondenz von P_m zu P_o darstellt. Aufgrund der Okklusion stimmt P_o nur teilweise mit P_m überein, und aufgrund von Segmentierungsungenauigkeiten und Sensorrauschen stimmt P_m nur teilweise überein. Teilweise UND-Übereinstimmungen P_o.
ausgedrückt, wobei C die Anzahl der Kanäle der Funktion darstellt. Das Ziel von PEM besteht darin, eine Zuordnungsmatrix zu erhalten, die die örtliche Korrespondenz von P_m zu P_o darstellt. Aufgrund der Okklusion stimmt P_o nur teilweise mit P_m überein, und aufgrund von Segmentierungsungenauigkeiten und Sensorrauschen stimmt P_m nur teilweise überein. Teilweise UND-Übereinstimmungen P_o.
Um das Problem der Zuweisung nicht überlappender Punkte zwischen zwei Punktmengen zu lösen, stattet ISM sie mit Hintergrundtoken aus, die als 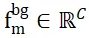 und
und 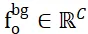 aufgezeichnet sind und auf deren Grundlage effektiv eine lokal-lokale Korrespondenz hergestellt werden kann Merkmalsähnlichkeit. Insbesondere kann die Aufmerksamkeitsmatrix zuerst wie folgt berechnet werden:
aufgezeichnet sind und auf deren Grundlage effektiv eine lokal-lokale Korrespondenz hergestellt werden kann Merkmalsähnlichkeit. Insbesondere kann die Aufmerksamkeitsmatrix zuerst wie folgt berechnet werden:
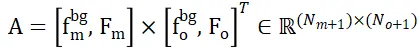
ten die Verteilungsmatrix
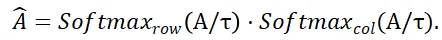
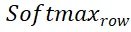 und
und 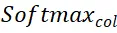 stellen den Softmax -Vorgang entlang der Zeilen bzw. Spalten dar,
stellen den Softmax -Vorgang entlang der Zeilen bzw. Spalten dar, 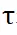 repräsentiert eine Konstante. Der Wert jeder Zeile in
repräsentiert eine Konstante. Der Wert jeder Zeile in 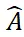 (mit Ausnahme der ersten Zeile) stellt die Übereinstimmungswahrscheinlichkeit jedes Punktes P_m in der Punktmenge P_m mit dem Hintergrund und dem Mittelpunkt von P_o dar. Durch Ermitteln des Index der maximalen Punktzahl wird der Punkt P_m gefunden zu finden sind (inkl. Hintergrund).
(mit Ausnahme der ersten Zeile) stellt die Übereinstimmungswahrscheinlichkeit jedes Punktes P_m in der Punktmenge P_m mit dem Hintergrund und dem Mittelpunkt von P_o dar. Durch Ermitteln des Index der maximalen Punktzahl wird der Punkt P_m gefunden zu finden sind (inkl. Hintergrund).
Sobald 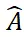 berechnet ist, können alle übereinstimmenden Punktpaare {(P_m,P_o)} und ihre Übereinstimmungswerte gesammelt werden, und schließlich wird die gewichtete SVD zur Berechnung der Objektpose verwendet.
berechnet ist, können alle übereinstimmenden Punktpaare {(P_m,P_o)} und ihre Übereinstimmungswerte gesammelt werden, und schließlich wird die gewichtete SVD zur Berechnung der Objektpose verwendet.
Abbildung 3. Schematische Darstellung des Pose Estimation Model (PEM) in SAM-6D
Unter Verwendung der oben genannten Hintergrund-Token-basierten Strategie werden in PEM zwei Punktsatz-Matching-Stufen und das zugehörige Modell entworfen Die Struktur ist wie in der Abbildung dargestellt. Wie in 3 gezeigt, enthält sie drei Module: Merkmalsextraktion, grobe Punktmengenanpassung und feine Punktmengenanpassung.
Das Modul zur groben Punktmengenanpassung implementiert eine spärliche Korrespondenz, um die anfängliche Objekthaltung zu berechnen, und verwendet diese Haltung dann, um die Punktmenge des Kandidatenobjekts zu transformieren, um ein Lernen der Positionskodierung zu erreichen.
Das Feinpunktsatz-Matching-Modul kombiniert die Positionscodierung der Abtastpunktsätze des Kandidatenobjekts und des Zielobjekts, wodurch in der ersten Stufe die grobe Korrespondenz eingefügt und eine dichte Korrespondenz weiter hergestellt wird, um eine genauere Objekthaltung zu erhalten. Um dichte Wechselwirkungen in dieser Phase effektiv zu erlernen, führt PEM einen neuartigen Punktmengentransformator mit geringer Dichte in eine geringe Dichte ein, der Wechselwirkungen auf dünn besetzten Versionen dichter Merkmale implementiert und den linearen Transformator [5] verwendet, um die verbesserten dünn besetzten Merkmale in Diffusion zurück umzuwandeln in dichte Strukturen.
Für die beiden Untermodelle von SAM-6D basiert das Instanzsegmentierungsmodell (ISM) auf SAM, ohne dass eine Neuschulung und Feinabstimmung des Netzwerks erforderlich ist, während das Posenschätzungsmodell (PEM) Für das Training werden die von MegaPose [4] bereitgestellten groß angelegten synthetischen Datensätze ShapeNet-Objects und Google-Scanned-Objects verwendet.
Um seine Zero-Sample-Fähigkeit zu überprüfen, wurde SAM-6D an sieben Kerndatensätzen von BOP [2] getestet, darunter LM-O, T-LESS, TUD-L, IC-BIN, ITODD, HB und YCB -V. Die Tabellen 1 und 2 zeigen den Vergleich der Instanzsegmentierungs- und Posenschätzungsergebnisse verschiedener Methoden für diese sieben Datensätze. Im Vergleich zu anderen Methoden schneidet SAM-6D bei beiden Methoden sehr gut ab und stellt seine starke Generalisierungsfähigkeit voll unter Beweis.
Tabelle 1. Vergleich der Instanzsegmentierungsergebnisse verschiedener Methoden für die sieben Kerndatensätze von BOP
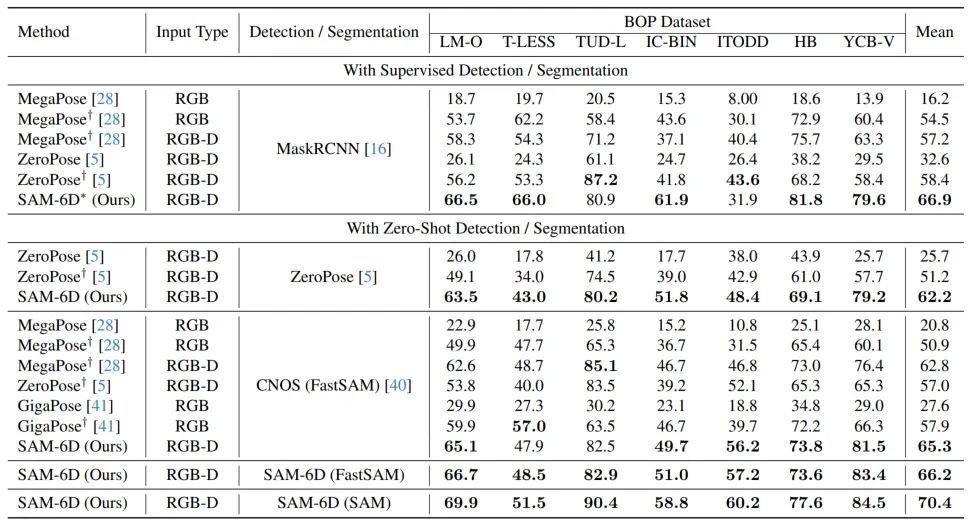
Tabelle 2. Vergleich der Posenschätzungsergebnisse verschiedener Methoden für die sieben Kerndatensätze von BOP
Abbildung 4 zeigt die Visualisierungsergebnisse der Erkennungssegmentierung und der 6D-Positionsschätzung von SAM-6D anhand von sieben BOP-Datensätzen, wobei (a) und (b) die getesteten RGB-Bilder bzw. Tiefenkarten sind, (c) ist ein gegebenes Zielobjekt, während (d) und (e) die Visualisierungsergebnisse der Erkennungssegmentierung bzw. der 6D-Pose sind.

Abbildung 4. Visualisierungsergebnisse von SAM-6D für die sieben Kerndatensätze von BOP.
Für weitere Implementierungsdetails von SAM-6D lesen Sie bitte das Originalpapier.
Das obige ist der detaillierte Inhalt vonSAM-6D, ein Zero-Sample-Framework zur 6D-Objekthaltungsschätzung, ein Schritt näher an der verkörperten Intelligenz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Hongmeng-System
Hongmeng-System
 Welche Datei ist eine Ressource?
Welche Datei ist eine Ressource?
 Wo ist die Taschenlampe des OnePlus-Telefons?
Wo ist die Taschenlampe des OnePlus-Telefons?
 Die Bedeutung der heutigen Schlagzeilen-Anzeigelautstärke
Die Bedeutung der heutigen Schlagzeilen-Anzeigelautstärke
 So lösen Sie das Problem, dass document.cookie nicht abgerufen werden kann
So lösen Sie das Problem, dass document.cookie nicht abgerufen werden kann
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 So erstellen Sie einen Bitmap-Index in MySQL
So erstellen Sie einen Bitmap-Index in MySQL
 Funktionen des Tracert-Befehls
Funktionen des Tracert-Befehls








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



