
 Technologie-Peripheriegeräte
KI
3140 Parameter Grok-1-Inferenz um das 3,8-fache beschleunigt, PyTorch+HuggingFace-Version ist da
Technologie-Peripheriegeräte
KI
3140 Parameter Grok-1-Inferenz um das 3,8-fache beschleunigt, PyTorch+HuggingFace-Version ist da
3140 Parameter Grok-1-Inferenz um das 3,8-fache beschleunigt, PyTorch+HuggingFace-Version ist da

Musk hat getan, was er gesagt hat, und Grok-1 als Open-Source-Lösung bereitgestellt, und die Open-Source-Community war begeistert.
Allerdings gibt es immer noch einige Schwierigkeiten bei der Durchführung von Änderungen oder der Kommerzialisierung auf der Grundlage von Grok-1:
Grok-1 wird mit Rust+JAX erstellt und ist die Schwelle für Benutzer, die an Mainstream-Software-Ökosysteme wie Python+ gewöhnt sind PyTorch+HuggingFace ist hoch.
△Illustration: Grok steht weltweit an erster Stelle auf der GitHub-Hotlist
Die neuesten Errungenschaften des Colossal-AI-Teams erfüllen alle dringenden Bedürfnisse Bieten bequemes und benutzerfreundliches Python+PyTorch+HuggingFace Grok -1, wodurch Argumentationslatenz implementiert werden kann um fast das Vierfache !
Jetzt wurde das Modell auf HuggingFace und ModelScope veröffentlicht.
HuggingFace-Download-Link:
https://www.php.cn/link/335396ce0d3f6e808c26132f91916eae
ModelScope-Download-Link:
https://www.php.cn/link/7ae7778c9ae86d2ded1 33e8 91995dc9e
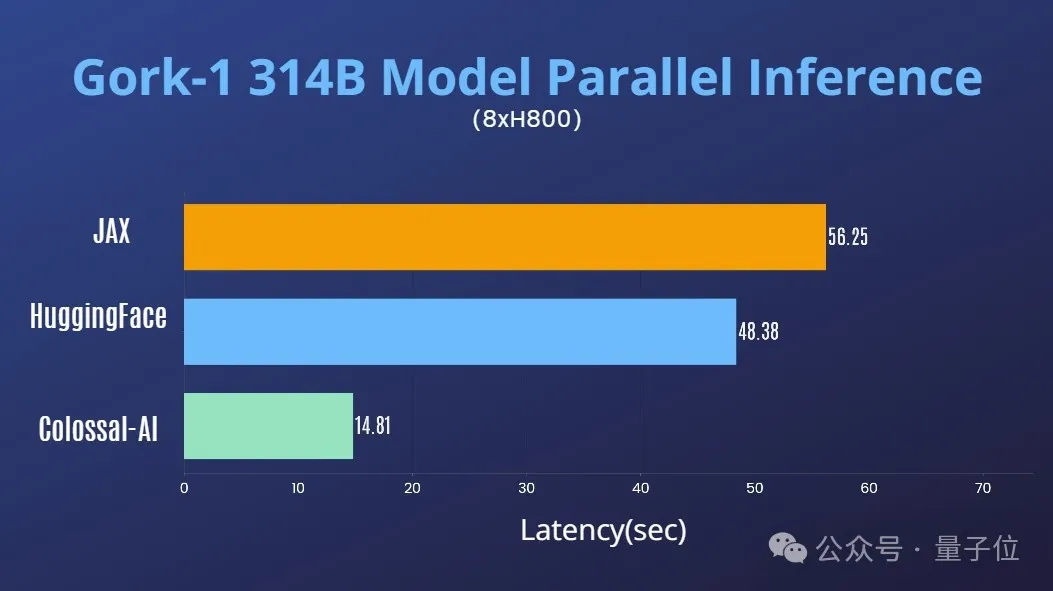
Leistungsoptimierung
In Kombination mit der umfangreichen Erfahrung von Colossal-AI im Bereich der KI-Optimierung großer Modellsysteme hat es schnell die Tensorparallelität für Grok-1 unterstützt.
Auf einem einzelnen 8H800-80-GB-Server wird die Inferenzleistung mit JAX, der automatischen Gerätezuordnung von HuggingFace und anderen Methoden verglichen. Die Inferenzlatenz wird um fast das Vierfache beschleunigt.
Nutzungsanleitung
Nach dem Herunterladen und Installieren von Colossal-AI starten Sie einfach das Inferenzskript.
./run_inference_fast.sh hpcaitech/grok-1
Die Modellgewichte werden automatisch heruntergeladen und geladen und die Inferenzergebnisse bleiben ausgerichtet. Wie in der folgenden Abbildung gezeigt, ist der laufende Test der gierigen Suche von Grok-1.
Weitere Einzelheiten finden Sie im Grok-1-Anwendungsfall:
https://www.php.cn/link/e2575ed7d2c481c414c10e688bcbc4cf
Der Gigant Grok-1
Dieser Open Source wurde von xAI veröffentlicht Grok-1 Die grundlegenden Modellgewichte und Netzwerkarchitektur.
Konkret handelt es sich um das ursprüngliche Basismodell aus der Vortrainingsphase im Oktober 2023, das nicht auf eine bestimmte Anwendung (z. B. Dialog) abgestimmt wurde.
Strukturell verwendet Grok-1 eine gemischte Expertenarchitektur (MoE), enthält 8 Experten und die Gesamtparametermenge beträgt 314B (314 Milliarden). Bei der Verarbeitung von Token werden zwei der Experten und der Aktivierungsparameter aktiviert Der Betrag beträgt 86B.
Allein die Anzahl der aktivierten Parameter hat die 70B des dichten Modells Llama 2 überschritten. Für die MoE-Architektur ist es keine Übertreibung, diese Anzahl an Parametern als Gigant zu bezeichnen.
Weitere Parameterinformationen sind wie folgt:
- Die Fensterlänge beträgt 8192 Token, die Genauigkeit beträgt bf16
- Die Vokabelgröße des Tokenizers beträgt 131072 (2^17), was nahe an GPT-4 liegt;
- Einbettungsgröße beträgt 6144 (48×128);
- Die Anzahl der Transformer-Schichten beträgt 64, und jede Schicht verfügt über eine Decoder-Schicht, einschließlich Multi-Head-Aufmerksamkeitsblöcken
- Die Schlüsselwertgröße beträgt
- In der Multi-Head-Aufmerksamkeit Block, 48 Köpfe werden für die Abfrage verwendet, 8 werden für KV verwendet, die KV-Größe beträgt 128; Auf der GitHub-Seite heißt es offiziell, dass aufgrund des großen Maßstabs des Modells (Parameter 314B) eine Maschine mit ausreichend GPU und Speicher erforderlich ist, um Grok auszuführen.
- Die Implementierungseffizienz der MoE-Schicht ist hier nicht hoch. Diese Implementierungsmethode wurde gewählt, um die Notwendigkeit einer Anpassung des Kernels bei der Überprüfung der Richtigkeit des Modells zu vermeiden.
Magnet-Links bereitgestellt und die Dateigröße beträgt nahezu 300 GB.
bereitgestellt und die Dateigröße beträgt nahezu 300 GB.
kommerziell freundlich.
Aktuell hat die Sternebewertung von Grok-1 auf GitHub 43,9.000 Sterne erreicht. Qubit geht davon aus, dass Colossal-AI in naher Zukunft weitere Optimierungen für Grok-1 einführen wird, wie z. B. Parallelbeschleunigung und quantitative Reduzierung der Grafikspeicherkosten. Wir freuen uns, weiterhin darauf zu achten.
Qubit geht davon aus, dass Colossal-AI in naher Zukunft weitere Optimierungen für Grok-1 einführen wird, wie z. B. Parallelbeschleunigung und quantitative Reduzierung der Grafikspeicherkosten. Wir freuen uns, weiterhin darauf zu achten.
Colossal-AI Open-Source-Adresse:
https://www.php.cn/link/b9531e7d2a8f38fe8dcc73f58cae9530
Das obige ist der detaillierte Inhalt von3140 Parameter Grok-1-Inferenz um das 3,8-fache beschleunigt, PyTorch+HuggingFace-Version ist da. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 Sony bestätigt die Möglichkeit, spezielle GPUs für PS5 Pro zu verwenden, um KI mit AMD zu entwickeln
Apr 13, 2025 pm 11:45 PM
Sony bestätigt die Möglichkeit, spezielle GPUs für PS5 Pro zu verwenden, um KI mit AMD zu entwickeln
Apr 13, 2025 pm 11:45 PM
Mark Cerny, Chefarchitekt von SonyInteractiveStonterment (Siey Interactive Entertainment), hat weitere Hardware-Details der Host-PlayStation5pro (PS5PRO) der nächsten Generation veröffentlicht, darunter ein auf Performance verbessertes Amdrdna2.x-GPU und ein maschinelles Lernen/künstliches Intelligenzprogramm Code-genannt "Amethylst" mit Amd. Der Fokus der PS5PRO-Leistungsverbesserung liegt immer noch auf drei Säulen, darunter eine leistungsstärkere GPU, eine fortschrittliche Ray-Tracing und eine von KI betriebene PSSR-Superauflösung. GPU nimmt eine maßgeschneiderte AMDRDNA2 -Architektur an, die Sony RDNA2.x nennt, und es hat eine rDNA3 -Architektur.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 Was sind die Methoden zur Abstimmung der Leistung von Zookeeper auf CentOS
Apr 14, 2025 pm 03:18 PM
Was sind die Methoden zur Abstimmung der Leistung von Zookeeper auf CentOS
Apr 14, 2025 pm 03:18 PM
Die Zookeper -Leistungsstimmung auf CentOS kann von mehreren Aspekten beginnen, einschließlich Hardwarekonfiguration, Betriebssystemoptimierung, Konfigurationsparameteranpassung, Überwachung und Wartung usw. Hier finden Sie einige spezifische Tuning -Methoden: SSD wird für die Hardwarekonfiguration: Da die Daten von Zookeeper an Disk geschrieben werden, wird empfohlen, SSD zu verbessern, um die I/O -Leistung zu verbessern. Genug Memory: Zookeeper genügend Speicherressourcen zuweisen, um häufige Lesen und Schreiben von häufigen Festplatten zu vermeiden. Multi-Core-CPU: Verwenden Sie Multi-Core-CPU, um sicherzustellen, dass Zookeeper es parallel verarbeiten kann.
 Endlich verändert! Microsoft Windows -Suchfunktion wird ein neues Update einleiten
Apr 13, 2025 pm 11:42 PM
Endlich verändert! Microsoft Windows -Suchfunktion wird ein neues Update einleiten
Apr 13, 2025 pm 11:42 PM
Die Verbesserungen von Microsoft an Windows -Suchfunktionen wurden auf einigen Windows -Insider -Kanälen in der EU getestet. Zuvor wurde die integrierte Windows -Suchfunktion von Benutzern kritisiert und hatte schlechte Erfahrung. Dieses Update teilt die Suchfunktion in zwei Teile auf: lokale Suche und Bing-basierte Websuche, um die Benutzererfahrung zu verbessern. Die neue Version der Suchschnittstelle führt standardmäßig lokale Dateisuche durch. Wenn Sie online suchen müssen, müssen Sie auf die Registerkarte "Microsoft Bingwebsearch" klicken, um zu wechseln. Nach dem Umschalten wird in der Suchleiste "Microsoft Bingwebsearch:" angezeigt, in dem Benutzer Keywords eingeben können. Dieser Schritt vermeidet effektiv das Mischen lokaler Suchergebnisse mit Bing -Suchergebnissen
 Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Effizientes Training von Pytorch -Modellen auf CentOS -Systemen erfordert Schritte, und dieser Artikel bietet detaillierte Anleitungen. 1.. Es wird empfohlen, YUM oder DNF zu verwenden, um Python 3 und Upgrade PIP zu installieren: Sudoyumupdatepython3 (oder sudodnfupdatepython3), PIP3Install-upgradepip. CUDA und CUDNN (GPU -Beschleunigung): Wenn Sie Nvidiagpu verwenden, müssen Sie Cudatool installieren
