
 Technologie-Peripheriegeräte
KI
Open Source des Cambridge-Teams: Ermöglichung multimodaler RAG-Anwendungen für große Modelle, der erste vorab trainierte universelle multimodale postinteraktive Wissensabrufer
Technologie-Peripheriegeräte
KI
Open Source des Cambridge-Teams: Ermöglichung multimodaler RAG-Anwendungen für große Modelle, der erste vorab trainierte universelle multimodale postinteraktive Wissensabrufer
Open Source des Cambridge-Teams: Ermöglichung multimodaler RAG-Anwendungen für große Modelle, der erste vorab trainierte universelle multimodale postinteraktive Wissensabrufer

 ... 544-b8d4-53eaa55d. westx .seetacloud.com:8443/
... 544-b8d4-53eaa55d. westx .seetacloud.com:8443/
- Papiertitel: PreFLMR: Scaling Up Fine-Grained Late-Interaction Multi-modal Retriever
- Hintergrund
- Obwohl große multimodale Modelle (wie GPT4-Vision, Gemini usw.) leistungsstarke allgemeine Bild- und Textverständnisfähigkeiten gezeigt haben, ist ihre Leistung im Umgang damit nicht zufriedenstellend Probleme, die Fachwissen erfordern. Selbst GPT4-Vision kann wissensintensive Fragen nicht effektiv beantworten (wie in Abbildung 1 dargestellt), was viele Anwendungen auf Unternehmensebene vor Herausforderungen stellt.
- GPT4-Vision kann relevantes Wissen über den multimodalen Knowledge Retriever PreFLMR abrufen und genaue Antworten generieren. Die Abbildung zeigt die tatsächliche Ausgabe des Modells. Retrieval-Augmented Generation (RAG) bietet eine einfache und effektive Möglichkeit, dieses Problem zu lösen und ermöglicht es großen multimodalen Modellen, zu „Domänenexperten“ auf einem bestimmten Gebiet zu werden. Sein Arbeitsprinzip ist wie folgt: Verwenden Sie zunächst einen einfachen Wissensabrufer (Knowledge Retriever), um relevantes Fachwissen aus professionellen Datenbanken (wie Wikipedia oder Unternehmenswissensdatenbanken) abzurufen. Anschließend verwendet das groß angelegte Modell dieses Wissen und diese Fragen als Eingabe und gibt eine genaue Antwort aus. Die Wissensrückruffähigkeit multimodaler Wissensextraktoren wirkt sich direkt darauf aus, ob groß angelegte Modelle bei der Beantwortung von Argumentationsfragen genaues Fachwissen erlangen können.
Kürzlich hat Das Artificial Intelligence Laboratory des Department of Information Engineering der University of Cambridge das erste vorab trainierte, universelle multimodale Late-Interaction Knowledge Retrieval PreFLMR
(Pre-trained Fine-grained) vollständig als Open Source bereitgestellt (Multimodaler Retriever mit später Interaktion). Im Vergleich zu herkömmlichen Modellen in der Vergangenheit weist PreFLMR die folgenden Merkmale auf:PreFLMR ist ein allgemeines Pre-Training-Modell, das mehrere Unteraufgaben wie Textabruf, Bildabruf und Wissensabruf effektiv lösen kann. Das Modell wurde auf Millionen von Ebenen multimodaler Daten vorab trainiert und eignet sich gut für mehrere nachgelagerte Abrufaufgaben. Darüber hinaus kann sich PreFLMR als hervorragendes Basismodell nach Feinabstimmung für private Daten schnell zu einem hervorragenden domänenspezifischen Modell entwickeln.
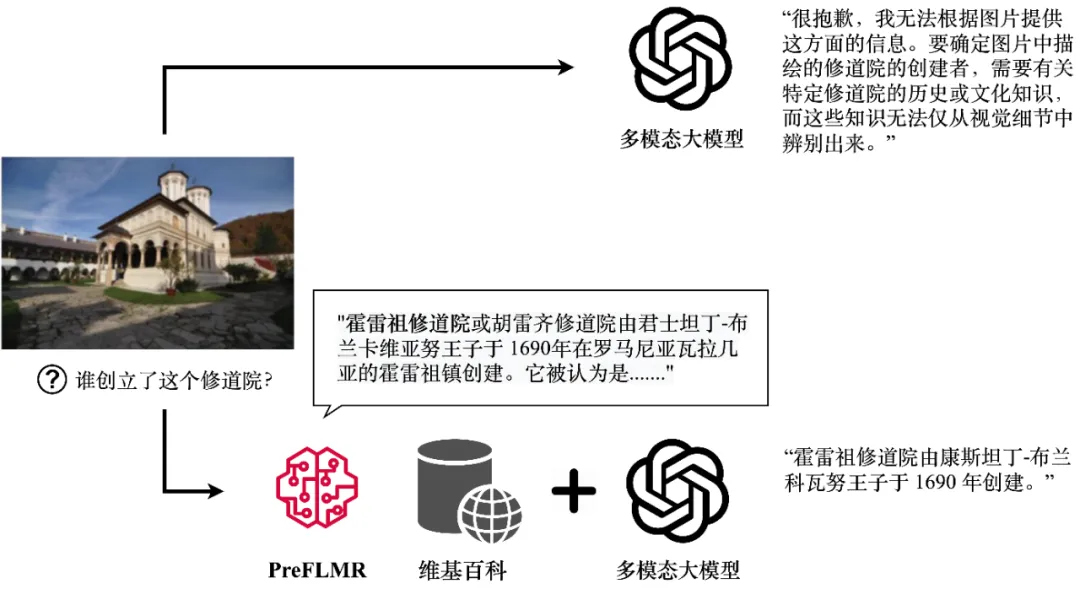
Abbildung 2: Das PreFLMR-Modell erreicht eine hervorragende multimodale Abrufleistung bei mehreren Aufgaben gleichzeitig und ist ein äußerst starkes Basismodell vor dem Training.
2. Traditional Dense Passage Retrieval (DPR) verwendet nur einen Vektor zur Darstellung der Abfrage (Query) oder des Dokuments (Document). Das vom Cambridge-Team auf der NeurIPS 2023 veröffentlichte FLMR-Modell hat bewiesen, dass das Einzelvektor-Darstellungsdesign von DPR zu feinkörnigen Informationsverlusten führen kann, was dazu führt, dass DPR bei Abrufaufgaben, die einen feinen Informationsabgleich erfordern, schlecht abschneidet. Insbesondere bei multimodalen Aufgaben enthält die Abfrage des Benutzers komplexe Szeneninformationen, und ihre Komprimierung in einen eindimensionalen Vektor beeinträchtigt die Ausdrucksfähigkeit von Features erheblich. PreFLMR erbt und verbessert die Struktur von FLMR und bietet ihm einzigartige Vorteile beim multimodalen Wissensabruf.
Abbildung 3: PreFLMR kodiert die Abfrage (Query, 1, 2, 3 links) und das Dokument (Document, 4 rechts) auf Zeichenebene (Token-Ebene), verglichen mit Die Codierung aller DPR-Systeme, die Informationen in eindimensionale Vektoren komprimieren, bietet den Vorteil feinkörniger Informationen.
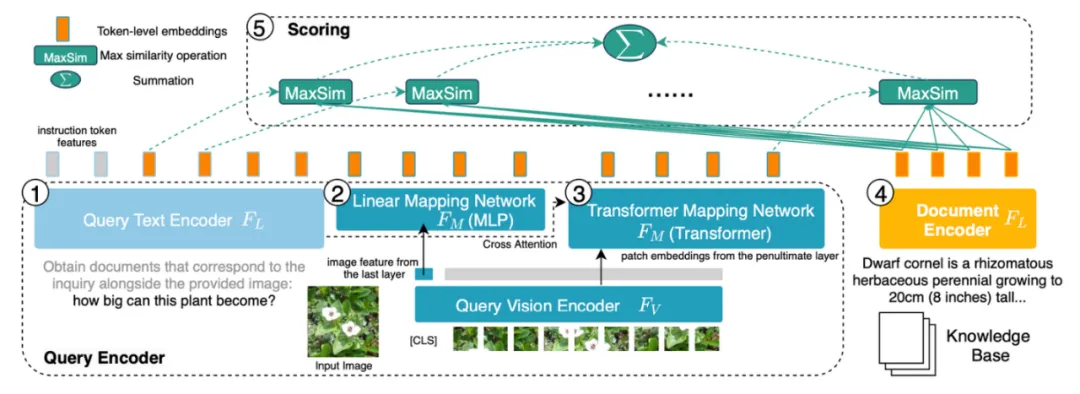
Abbildung 4: PreFLMR kann gleichzeitig multimodale Abfrageaufgaben wie das Extrahieren von Dokumenten basierend auf Bildern, das Extrahieren von Dokumenten basierend auf Fragen und das Extrahieren von Dokumenten basierend auf Fragen und Bildern gleichzeitig verarbeiten . Das Team der Universität Cambridge hat drei Modelle unterschiedlicher Größe als Open Source bereitgestellt. Die Parameter der Modelle von klein bis groß sind: PreFLMR_ViT-B (207M), PreFLMR_ViT-L (422M), PreFLMR_ViT-G (2B) , Damit Benutzer entsprechend den tatsächlichen Bedingungen auswählen können. Neben dem Open-Source-Modell PreFLMR selbst hat dieses Projekt auch zwei wichtige Beiträge in dieser Forschungsrichtung geleistet: Im Folgenden werden der M2KR-Datensatz, das PreFLMR-Modell und die experimentelle Ergebnisanalyse kurz vorgestellt. Um allgemeine multimodale Abrufmodelle im Maßstab vorab zu trainieren und zu bewerten, haben die Autoren zehn öffentlich verfügbare Datensätze zusammengestellt und sie in ein einheitliches Problemdokument-Abrufformat umgewandelt. Zu den ursprünglichen Aufgaben dieser Datensätze gehören Bildunterschriften, multimodale Dialoge usw. Die folgende Abbildung zeigt die Fragen (erste Zeile) und entsprechende Dokumente (zweite Zeile) für fünf der Aufgaben. Abbildung 5: Teil der Wissensextraktionsaufgabe im M2KR-Datensatz Abbildung 6: Modellstruktur von PreFLMR. Die Abfrage wird als Funktion auf Token-Ebene codiert. Für jeden Vektor in der Abfragematrix findet PreFLMR den nächstgelegenen Vektor in der Dokumentmatrix, berechnet das Skalarprodukt und summiert dann diese maximalen Skalarprodukte, um die endgültige Relevanz zu erhalten. Das PreFLMR-Modell basiert auf dem in NeurIPS 2023 veröffentlichten Fine-grained Late-interaction Multi-modal Retriever (FLMR) und durchläuft Modellverbesserungen und ein umfangreiches Vortraining auf M2KR. Im Vergleich zu DPR verwenden FLMR und PreFLMR eine Matrix, die aus allen Token-Vektoren besteht, um Dokumente und Abfragen zu charakterisieren. Zu den Tokens gehören Text-Tokens und Bild-Tokens, die in den Textraum projiziert werden. Bei der späten Interaktion handelt es sich um einen Algorithmus zur effizienten Berechnung der Korrelation zwischen zwei Darstellungsmatrizen. Die spezifische Methode lautet: Suchen Sie für jeden Vektor in der Abfragematrix den nächstgelegenen Vektor in der Dokumentmatrix und berechnen Sie das Skalarprodukt. Diese maximalen Skalarprodukte werden dann summiert, um die endgültige Korrelation zu erhalten. Auf diese Weise kann die Darstellung jedes Tokens explizit die endgültige Korrelation beeinflussen, wodurch feinkörnige Informationen auf Token-Ebene erhalten bleiben. Dank einer speziellen Post-Interaction-Retrieval-Engine benötigt PreFLMR nur 0,2 Sekunden, um 100 relevante Dokumente aus 400.000 Dokumenten zu extrahieren, was die Benutzerfreundlichkeit in RAG-Szenarien erheblich verbessert. Das Vortraining für PreFLMR besteht aus den folgenden vier Phasen: Gleichzeitig zeigen die Autoren, dass PreFLMR auf Teildatensätze (wie OK-VQA, Infoseek) weiter verfeinert werden kann, um eine bessere Abrufleistung bei bestimmten Aufgaben zu erzielen. Beste Abrufergebnisse: Das leistungsstärkste PreFLMR-Modell verwendet ViT-G als Bild-Encoder und ColBERT-base-v2 als Text-Encoder mit insgesamt zwei Milliarden Parametern. Bei 7 M2KR-Abrufunteraufgaben (WIT, OVEN, Infoseek, E-VQA, OKVQA usw.) wird eine Leistung erzielt, die über die Basismodelle hinausgeht. Erweiterte visuelle Kodierung ist effektiver: Der Autor stellte fest, dass ein Upgrade des Bild-Encoders ViT von ViT-B (86M) auf ViT-L (307M) erhebliche Leistungsverbesserungen brachte, ein Upgrade des Text-Encoders ColBERT von Base (110M) jedoch ) auf groß (345 Mio.) erweitert, führte zu Leistungseinbußen und Problemen mit der Trainingsinstabilität. Experimentelle Ergebnisse zeigen, dass für spätere interaktive multimodale Retrieval-Systeme eine Erhöhung der Parameter des visuellen Encoders größere Erträge bringt. Gleichzeitig hat die Verwendung mehrerer Queraufmerksamkeitsebenen für die Bild-Text-Projektion den gleichen Effekt wie die Verwendung einer einzelnen Ebene, sodass das Design des Bild-Text-Projektionsnetzwerks nicht zu kompliziert sein muss. PreFLMR macht RAG effektiver: Bei wissensintensiven visuellen Fragebeantwortungsaufgaben verbessert die Verwendung von PreFLMR zur Abrufverbesserung die Leistung des endgültigen Systems erheblich: Bei Infoseek und EVQA wurden Leistungsverbesserungen von jeweils 94 % und 275 % erzielt Durch einfache Feinabstimmung kann das BLIP-2-basierte Modell das PALI-X-Modell mit Hunderten von Milliarden Parametern und das mit der Google API erweiterte PaLM-Bison+Lens-System besiegen. Das vom Cambridge Artificial Intelligence Laboratory vorgeschlagene PreFLMR-Modell ist das erste allgemeine spätinteraktive multimodale Retrieval-Modell auf Open-Source-Basis. Nach dem Vortraining mit Millionen von Daten auf M2KR zeigt PreFLMR eine starke Leistung bei mehreren Abruf-Unteraufgaben. Der M2KR-Datensatz, die PreFLMR-Modellgewichte und der Code sind auf der Projekthomepage https://preflmr.github.io/ verfügbar. Ressourcen erweitern

M2KR-Datensatz

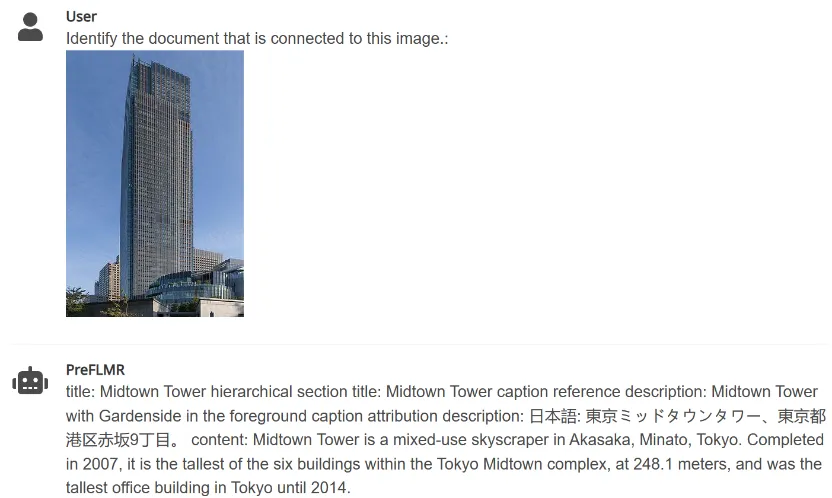
PreFLMR-Abrufmodell
Experimentelle Ergebnisse und vertikale Erweiterung
Fazit
Das obige ist der detaillierte Inhalt vonOpen Source des Cambridge-Teams: Ermöglichung multimodaler RAG-Anwendungen für große Modelle, der erste vorab trainierte universelle multimodale postinteraktive Wissensabrufer. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
Der Befehl zum Neustart des SSH -Dienstes lautet: SystemCTL Neustart SSHD. Detaillierte Schritte: 1. Zugriff auf das Terminal und eine Verbindung zum Server; 2. Geben Sie den Befehl ein: SystemCTL Neustart SSHD; 1. Überprüfen Sie den Dienststatus: SystemCTL -Status SSHD.
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
